CRUD简介
- create(创建)
- retrieve(读取)
- update(更新)
- delete(删除)
create新增
"增"指的是向数据库表中插入新记录,使用INSERT
INSERT INTO table_name
(column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
- (column1, column2, ...):指定要插入数据的列名
- VALUES 后面跟对应列的值
插入一条数据
sql
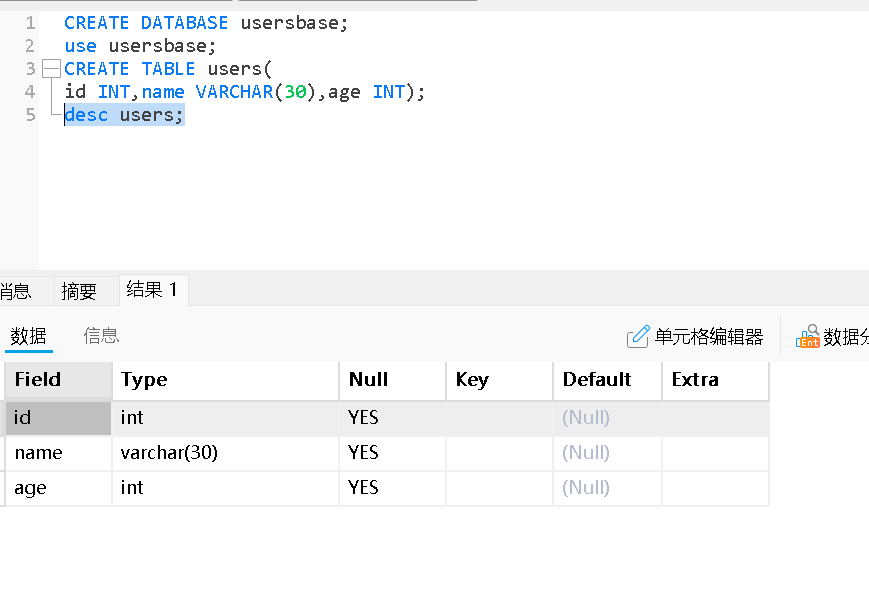
CREATE DATABASE usersbase;
use usersbase;
CREATE TABLE users(
id INT,name VARCHAR(30),age INT);
desc users;
DELETE FROM users WHERE id IS NULL;
-- 然后重新插入
INSERT INTO users (name, age) VALUES ('杰西', 20);
SELECT * FROM users;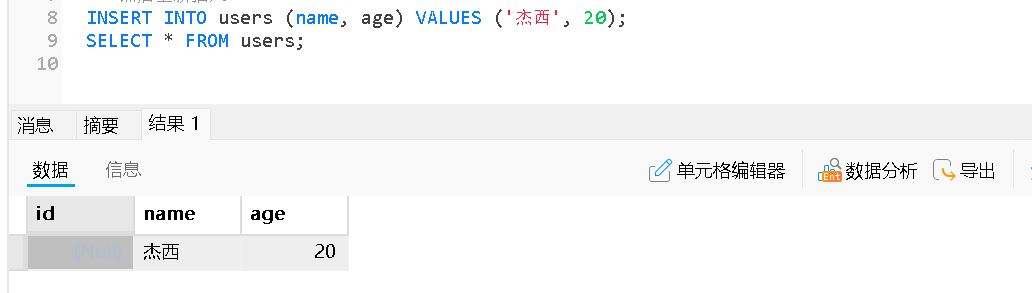
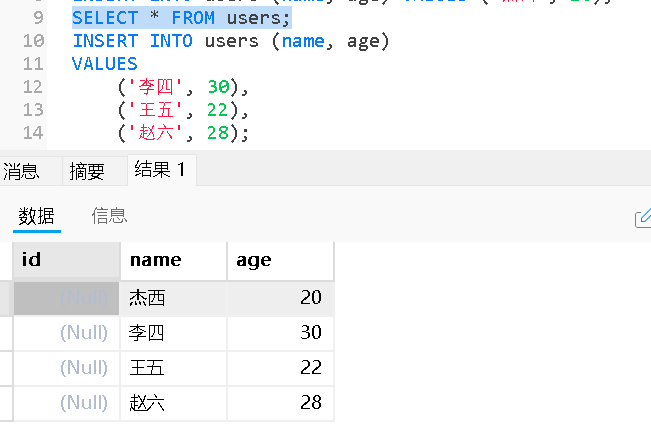
插入多条数据,提高效率
SELECT查询
全列查询
- ❌ 不推荐:
SELECT * FROM 表名;
--*通配符,通配符可以代表各种信息
- ✅ 推荐:
SELECT name, age FROM users;
原因:
- 减少网络传输开销
- 避免读取大量的硬盘访问与网络访问
- 提高缓存效率
- 防止因表结构变更导致程序出错
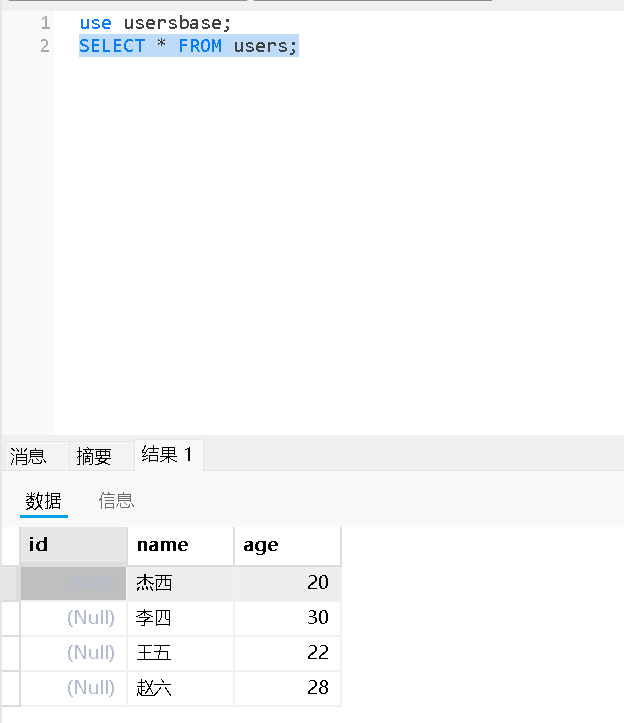
指定列查询
SELECT 列名,列名......FROM 表名;
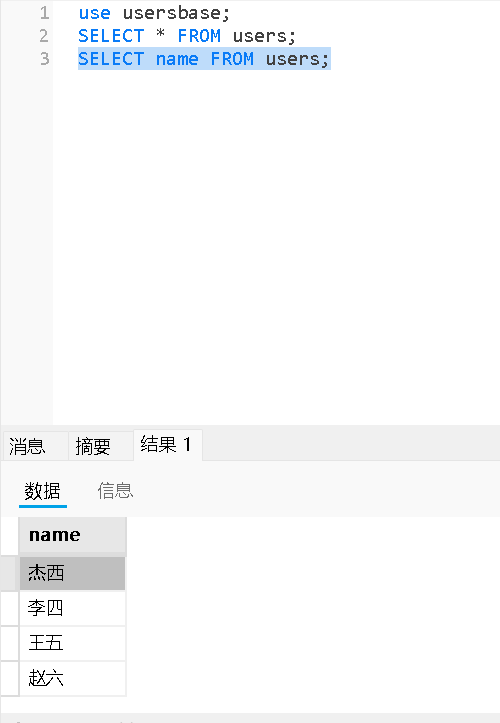
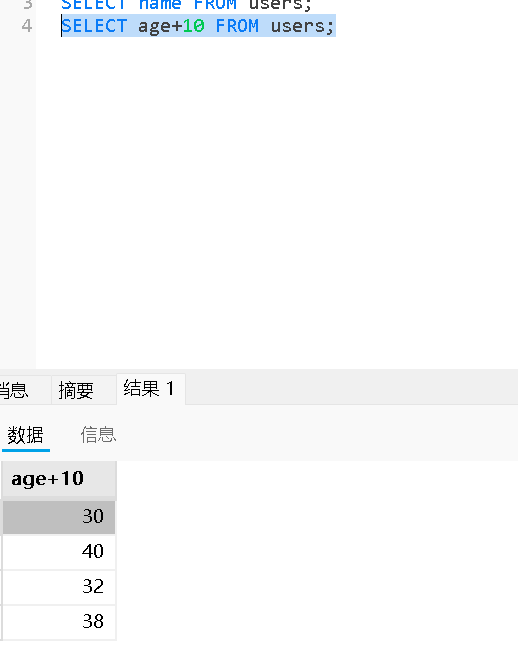
查询时带有表达式
SELECT 表达式 FROM 表名;
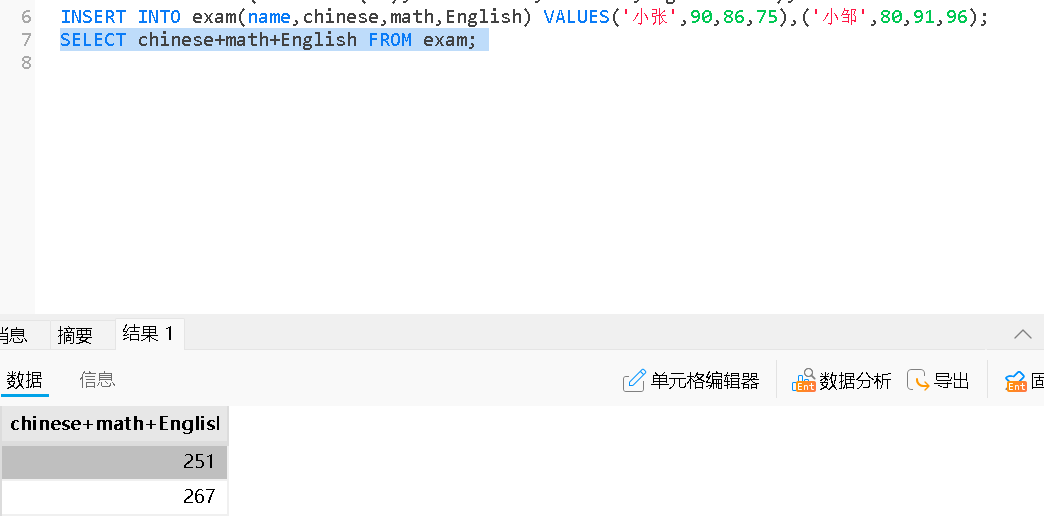
查询带有别名的
SElECT 表达式 AS 别名 FROM 表名;
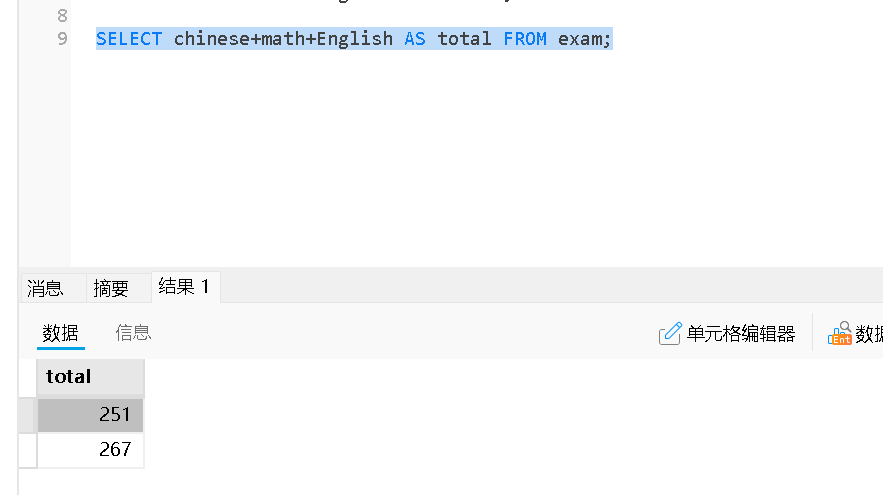
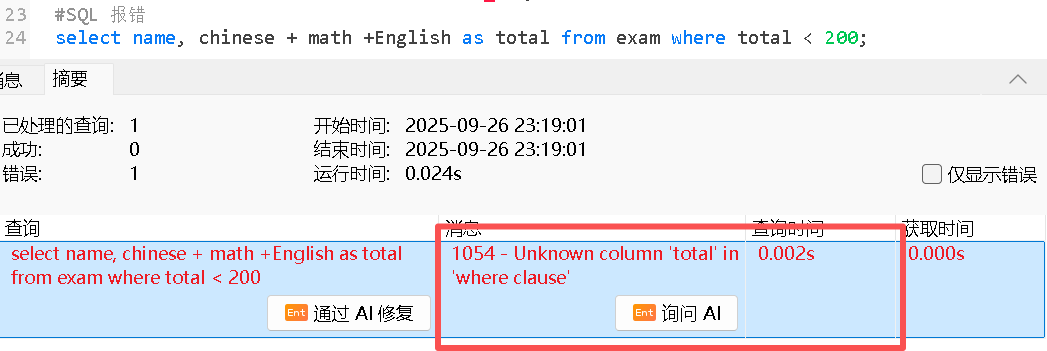
❌ total 是一个别名(alias),在 WHERE 子句中不能直接使用
WHERE 子句在 SELECT 之前执行,所以,你在 SELECT 中定义的别名 total,在 WHERE 子句中还不存在
MySQL 在执行查询时的处理顺序:
FROMWHERESELECT(包括别名)ORDER BY等
去重查询
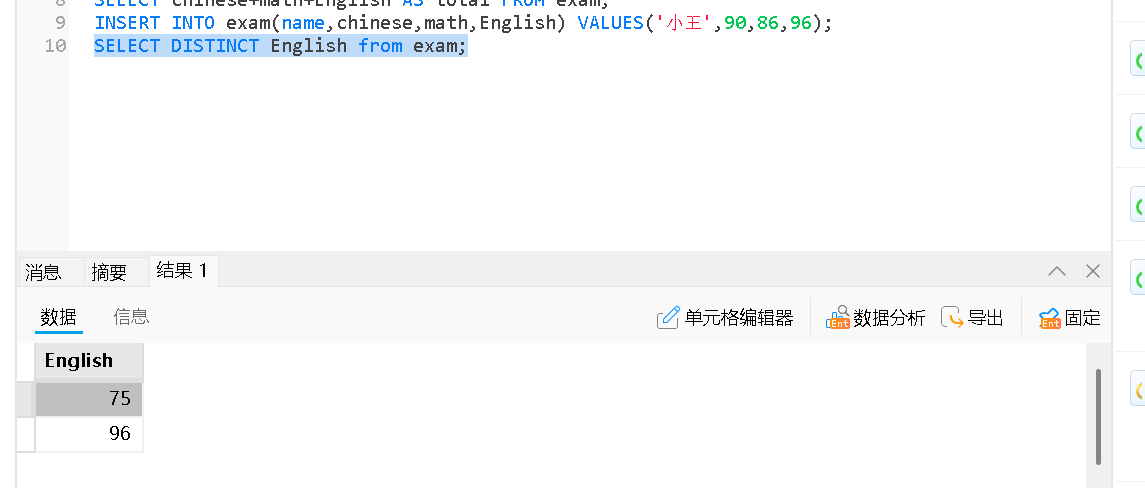
去重:多个相同的值,合并为一个
SELECT DISTINCT 列名 FROM 表名;
WHERE 条件
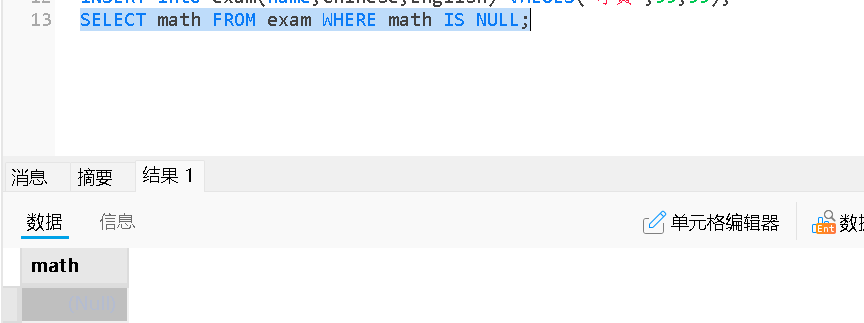
注意 NULL 值的处理:不能用 = NULL,要用 IS NULL 或 IS NOT NULL
-- 错误 ❌
SELECT * FROM users WHERE age = NULL;
-- 正确 ✅
SELECT * FROM users WHERE age IS NULL;
⽐较运算符
| 运算符 | 含义 |
|---|---|
=,<=> |
=,对于NULL比较不安全,NULL=NULL结果NULL, <=>,对于NULL比较安全,NULL<=>NULL结果TRUE(1) |
<> 或 != |
不等于 |
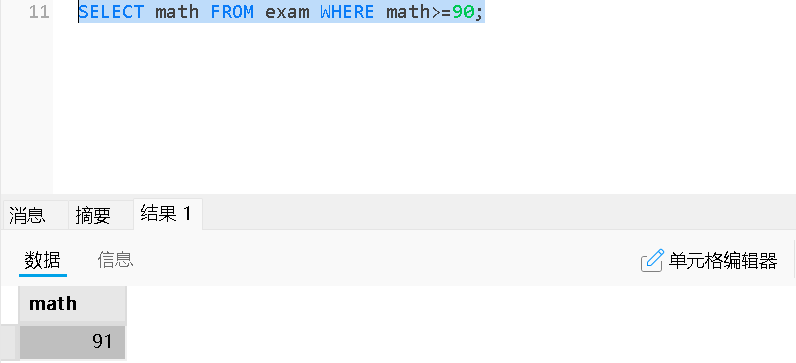
<,<=,>,>= |
小于,小于等于,大于,大于等于 |
IS NULL / IS NOT NULL |
判断是否为 NULL |
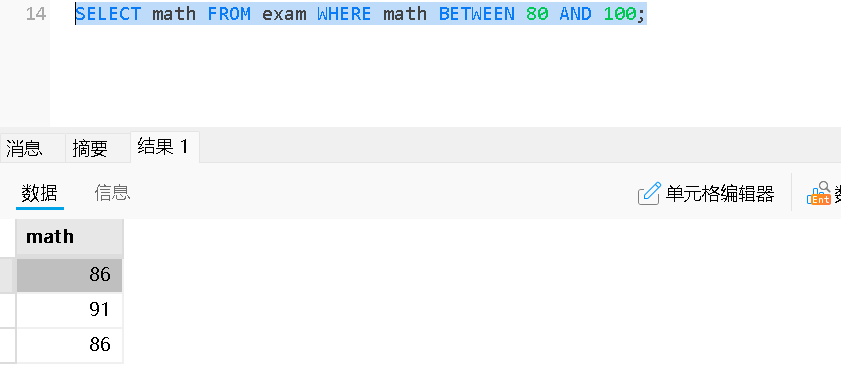
BETWEEN ... AND ... |
判断值是否在某个闭区间范围内 ✅包含边界值(闭区间) |
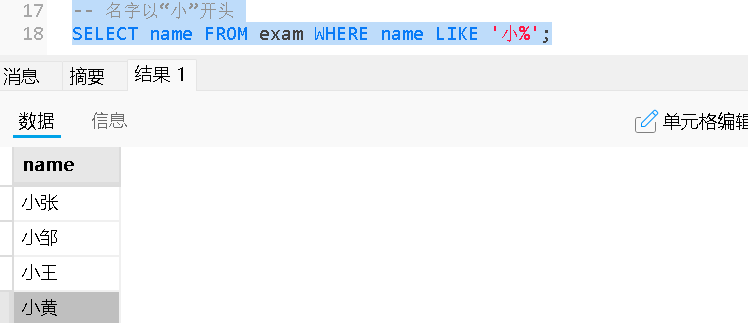
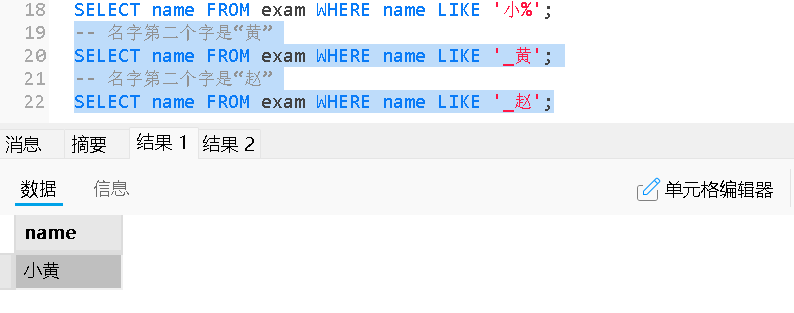
LIKE / NOT LIKE |
用于字符串模糊匹配 %匹配任意数量字符(包括零个) _匹配单个字符 |
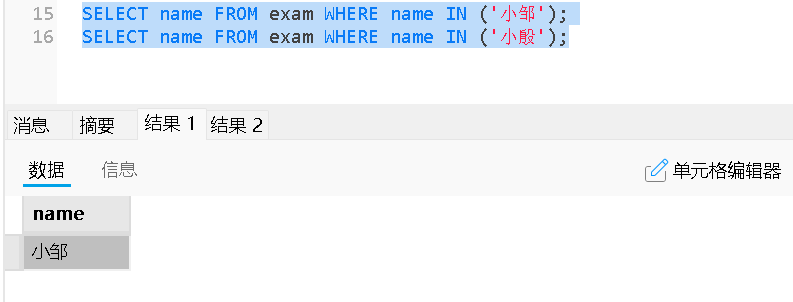
| IN / NOT IN | 判断值是否在给定的列表中 |
逻辑运算符
| 运算符 | 含义 |
|---|---|
AND 或 && |
只有当所有条件都为 TRUE 时,结果才为 TRUE |
OR 或 ` |
只要有一个条件为 TRUE,结果就为 TRUE |
NOT 或 ! |
逻辑非(取反) |
MySQL 会按照以下优先级顺序执行逻辑运算:
NOT(或!)AND(或&&)OR(或||)
NULL 值的逻辑运算
| 表达式 | 结果 | 说明 |
|---|---|---|
TRUE AND NULL |
NULL |
未知 |
FALSE AND NULL |
FALSE |
因为 FALSE 与任何值 AND 都为 FALSE |
TRUE OR NULL |
TRUE |
因为 TRUE 与任何值 OR 都为 TRUE |
FALSE OR NULL |
NULL |
未知 |
NOT NULL |
NULL |
取反仍为未知 |
注意:
- WHERE条件可以使用表达式,但不能使用别名
- AND的优先级高于OR,同时使用,建议使用小括号()包裹优先执行的部分
- 过滤NULL时不要使用=与!=,<>
- NULL与任何值运算结果为NULL
Order by排序
SELECT column1, column2, ...
FROM table_name
WHERE condition ORDER BY column1 ASC \| DESC, column2 ASC \| DESC, ...;
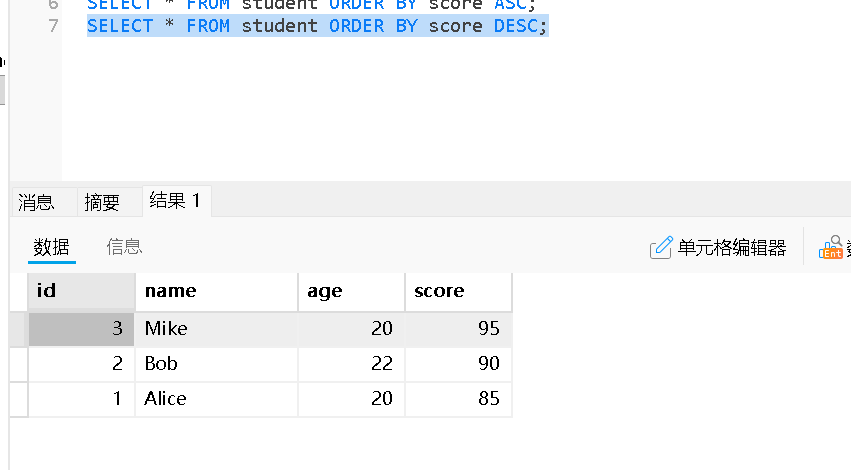
单列排序
ASC:升序排序(默认),从小到大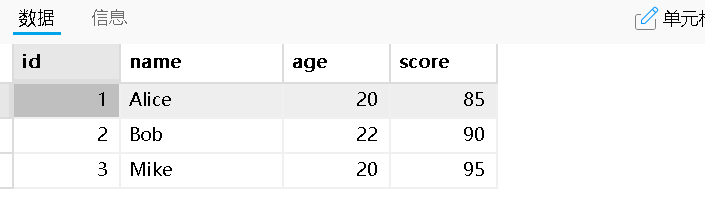
DESC:降序排序,从大到小
多列排序
score 相同时,按 age 升序排列
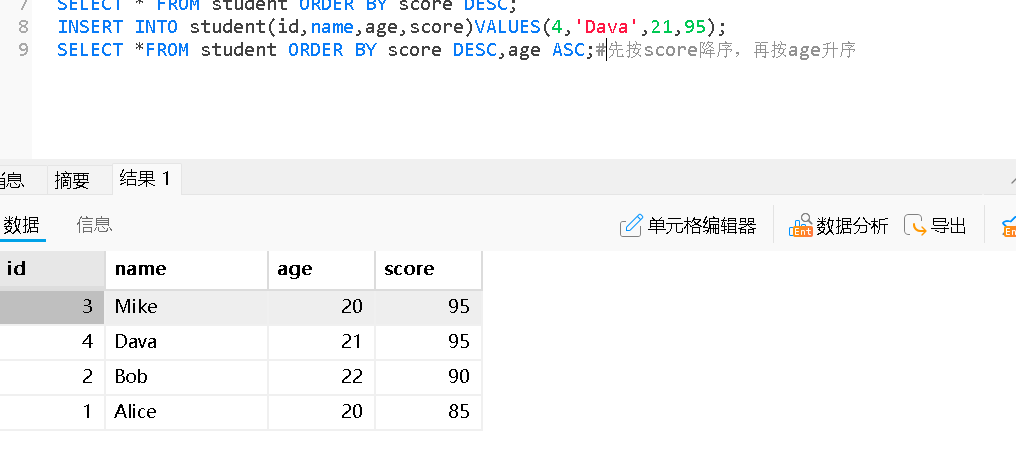
Order by默认升序排序
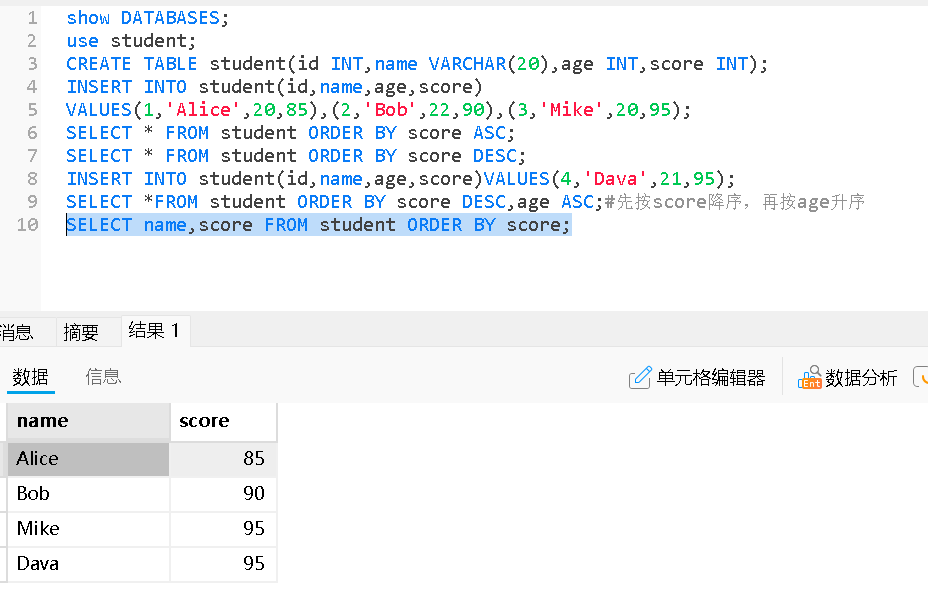
含有NULL的排序
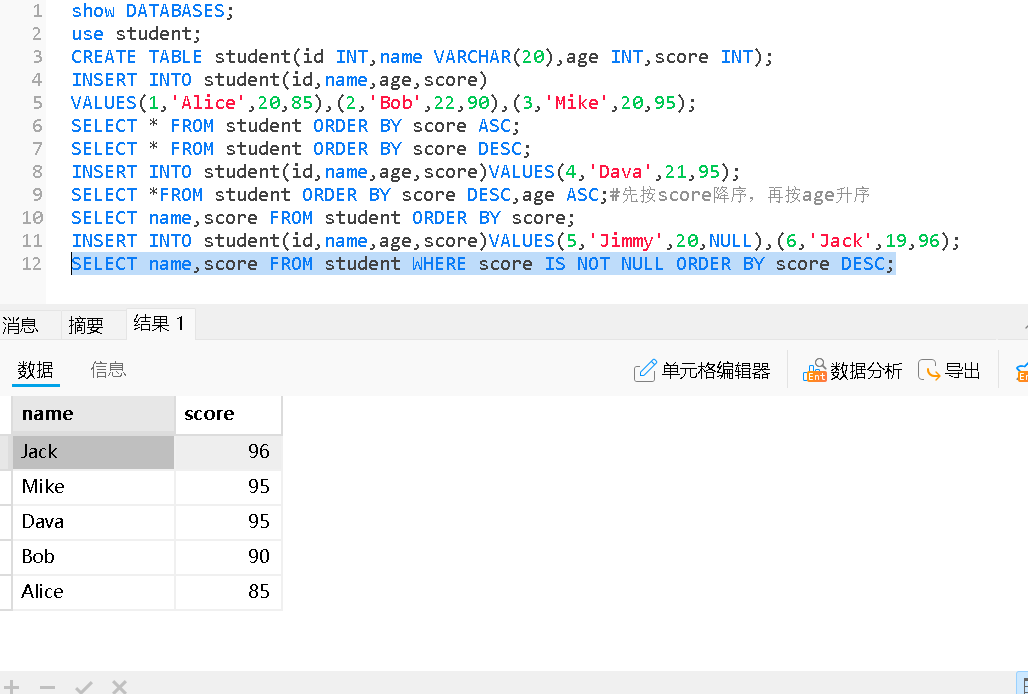
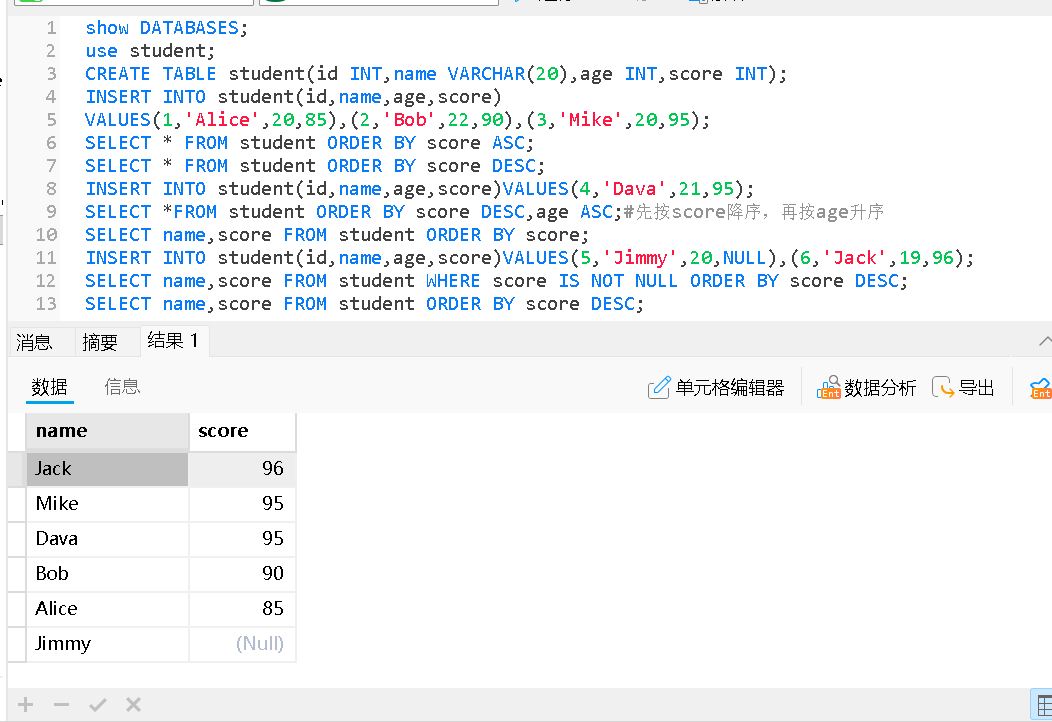
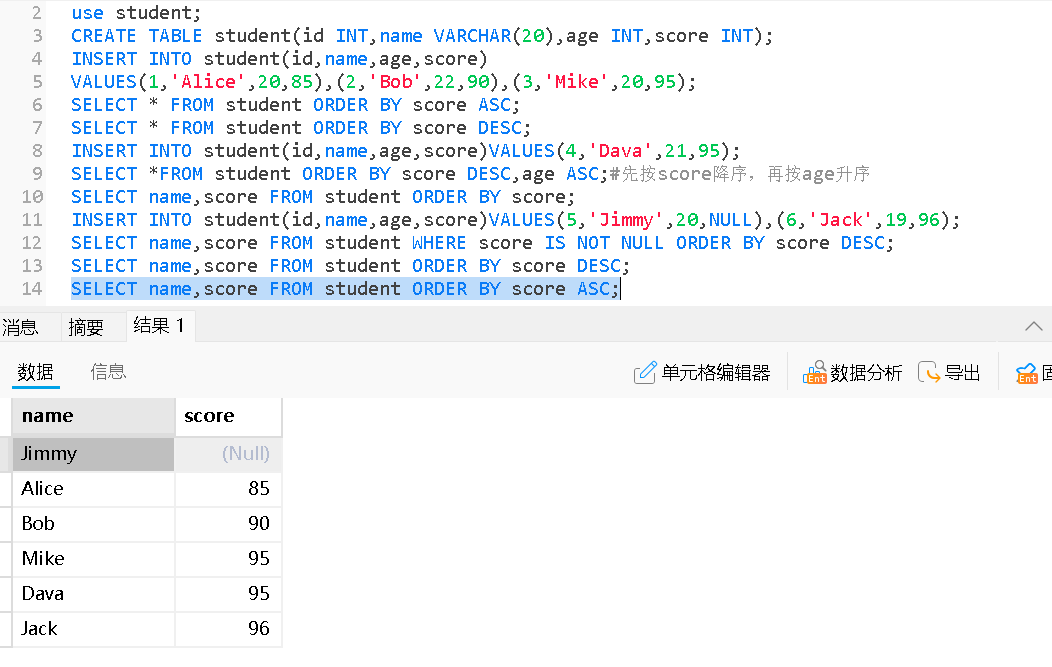 • NULL进⾏排序时,视为⽐任何值都⼩,升序出现在最上⾯,降序出现在最下⾯
• NULL进⾏排序时,视为⽐任何值都⼩,升序出现在最上⾯,降序出现在最下⾯
Order by别名排序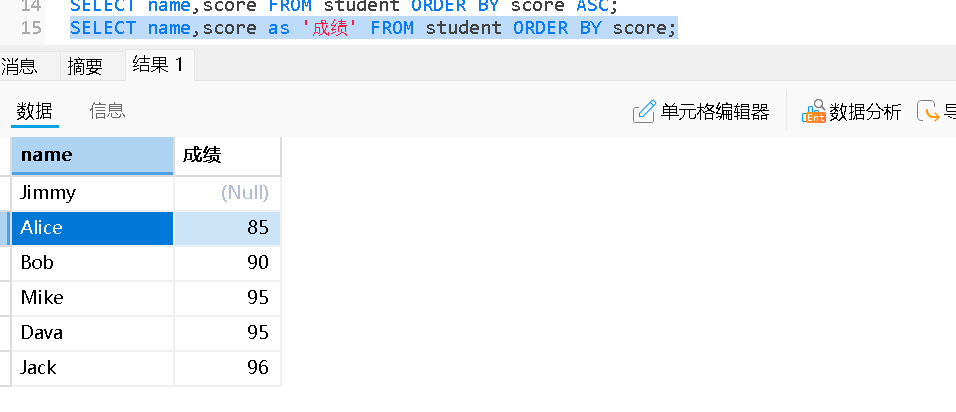
• ORDERBY⼦句中可以使⽤列的别名进行排序
分页查询
SELECT column1, column2, ...
FROM table_name
WHERE condition
ORDER BY column \[ASC \| DESC\]
LIMIT row_count OFFSET offset;
LIMIT offset, row_count
- row_count:每页显示的记录数(页大小)
- offset:跳过的记录数(从 0 开始)
每页显示 3 条,查询第 1 页
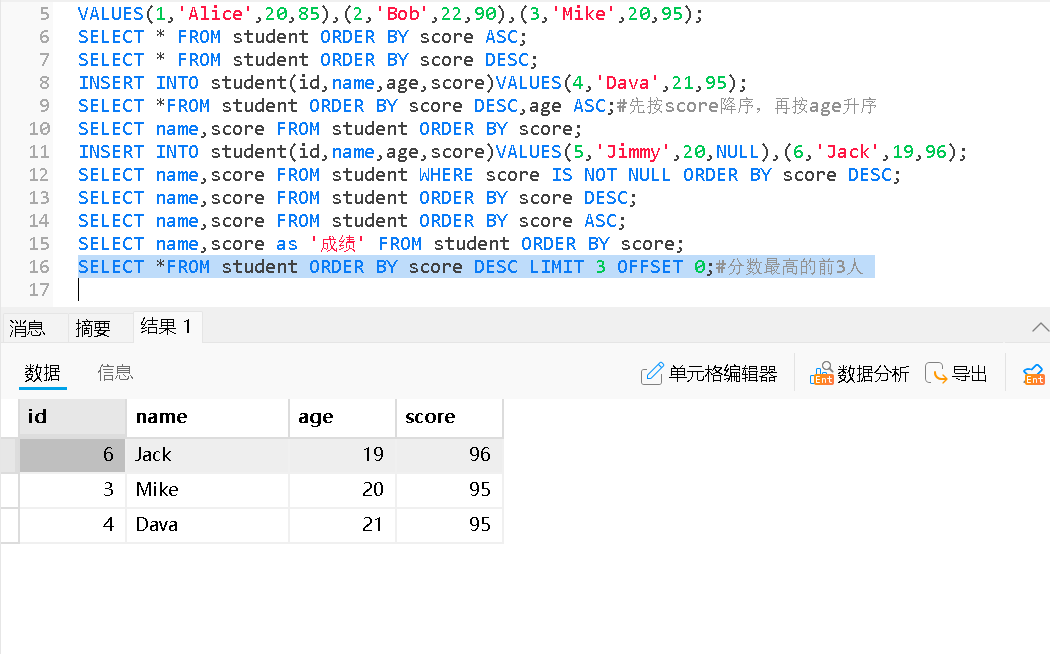
查询第 2 页(跳过前3条)
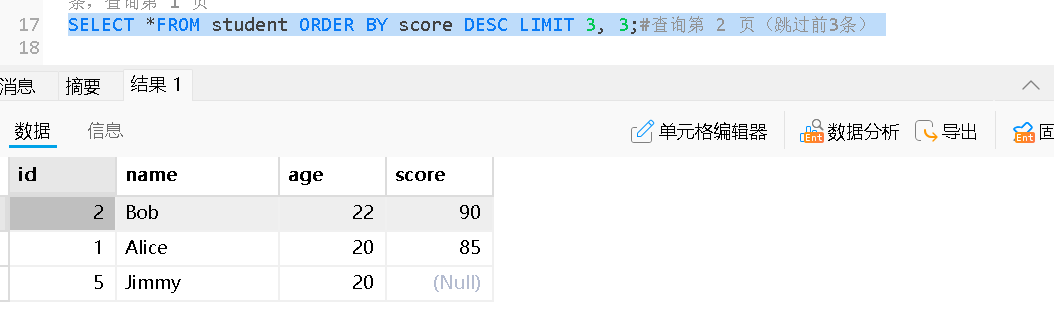
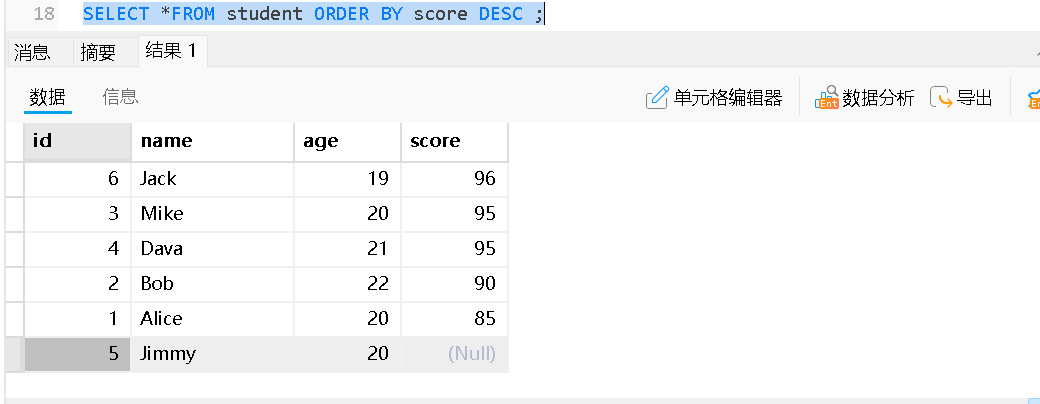
总查询
Update修改
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition ORDER BY ... LIMIT row_count;
SET:指定要更新的列及其新值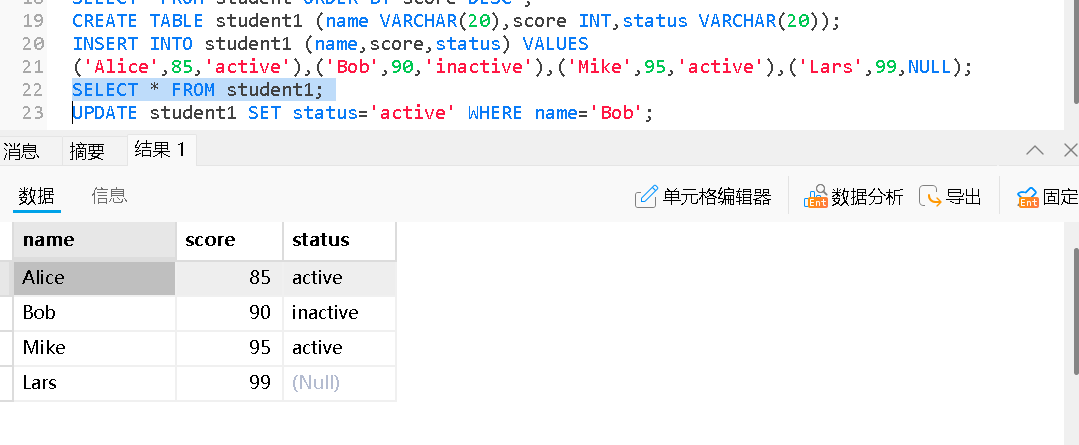 更新单列
更新单列
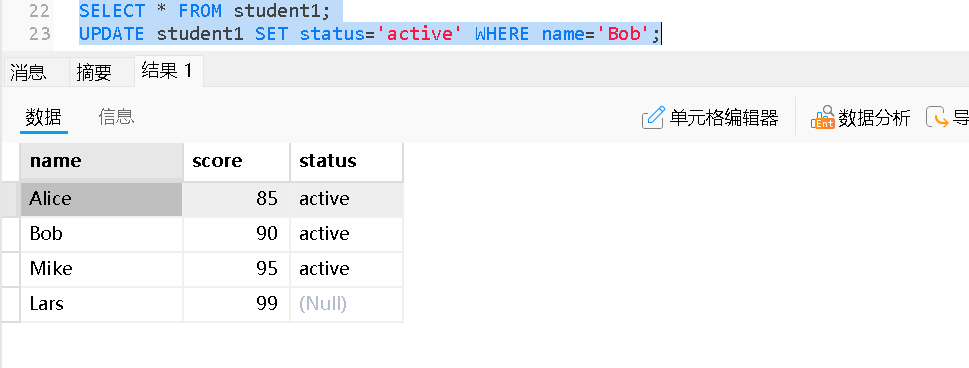
更新多列
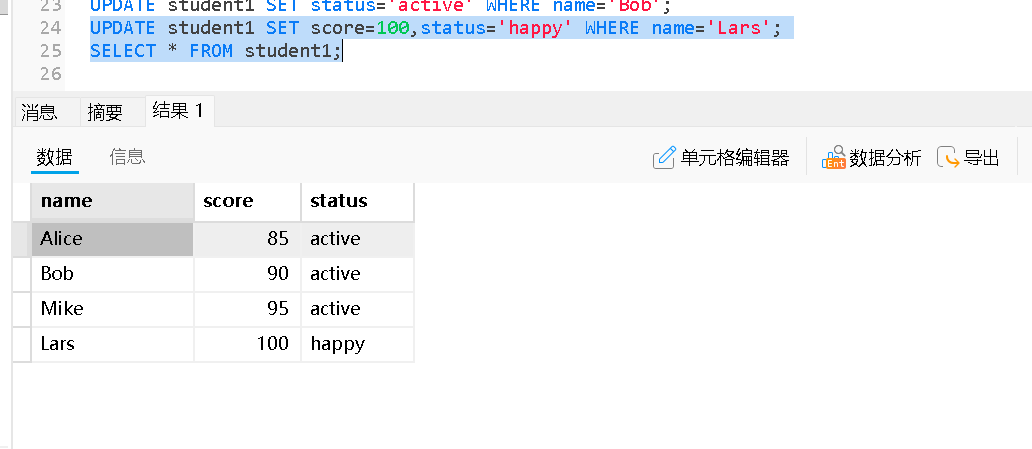
使用表达式更新
Delete删除
DELETE FROM table_name WHERE condition ORDER BY ... LIMIT row_count;
初始表
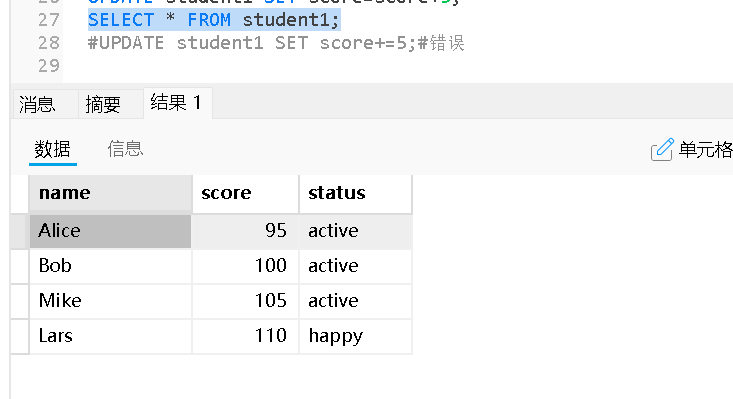
删除满足条件的特定行
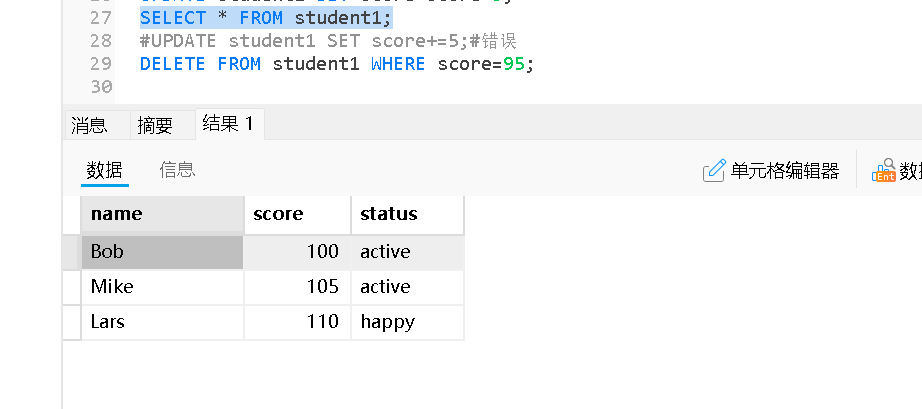
删除所有数据(清空表)
DELETE FROM table_name;
⚠️ 警告 :如果没有
WHERE子句,DELETE会删除表中所有数据!务必谨慎操作!
执⾏Delete时不加条件会删除整张表的数据,谨慎操作
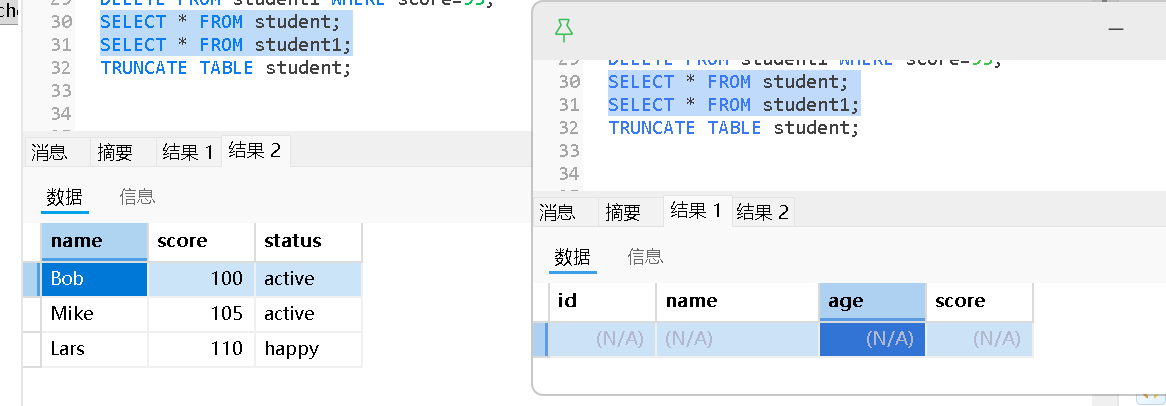
截断表
"截断表"指的是使用 TRUNCATE TABLE 命令来快速清空一个表中的所有数据
TRUNCATE TABLE table_name;
初始表
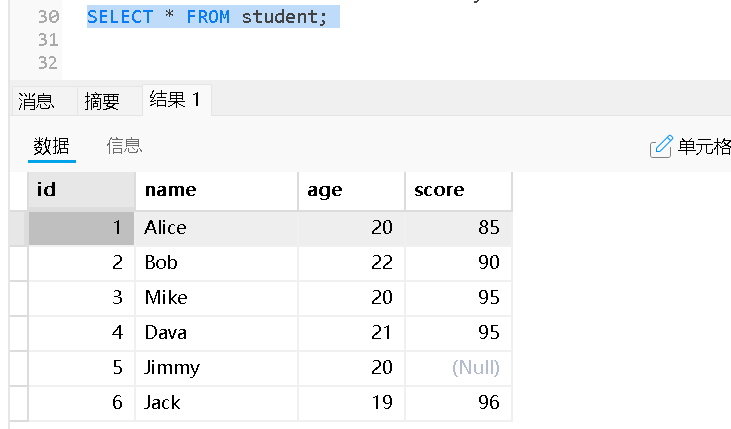
截断后的表结构

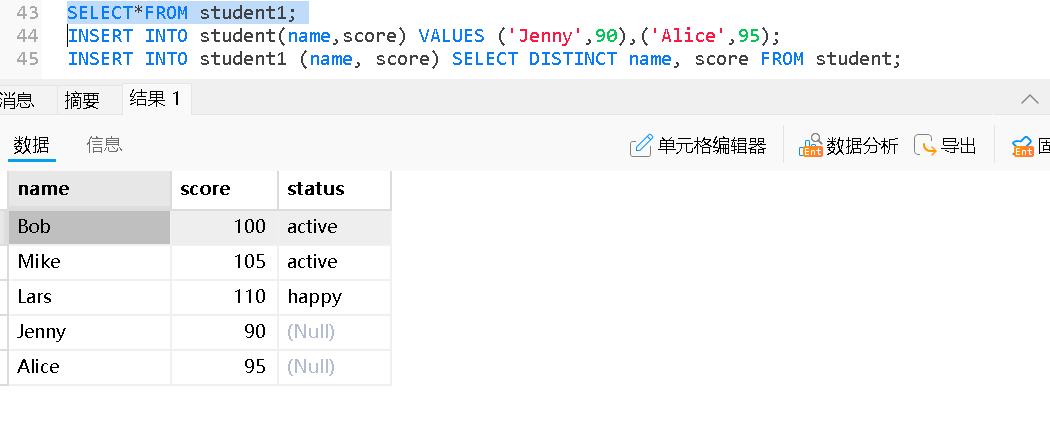
插入查询结果
INSERT INTO 目标表名 (列1, 列2, ...) SELECT 列A, 列B, ... FROM 源表名 WHERE 条件;
| 部分 | 说明 |
|---|---|
INSERT INTO 目标表名 (列列表) |
指定要插入数据的目标表和对应的列 |
SELECT ... FROM 源表名 |
查询要插入的数据来源 |
WHERE 条件 |
可选,用于筛选需要插入的数据 |
聚合函数
| 函数 | 说明 | 示例 |
|---|---|---|
COUNT() |
统计行数(非 NULL 值的数量) | COUNT(*)、COUNT(column) |
SUM() |
求和 | SUM(salary) |
AVG() |
计算平均值 | AVG(score) |
MAX() |
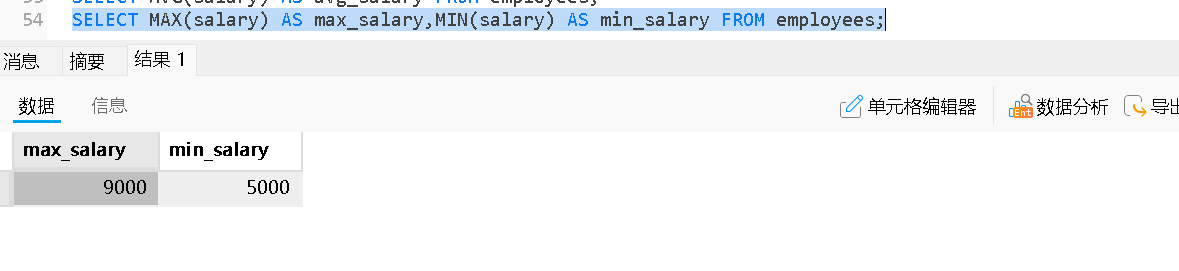
返回最大值 | MAX(price) |
MIN() |
返回最小值 | MIN(age) |
GROUP_CONCAT() |
将分组中的值连接成字符串 | GROUP_CONCAT(name) |
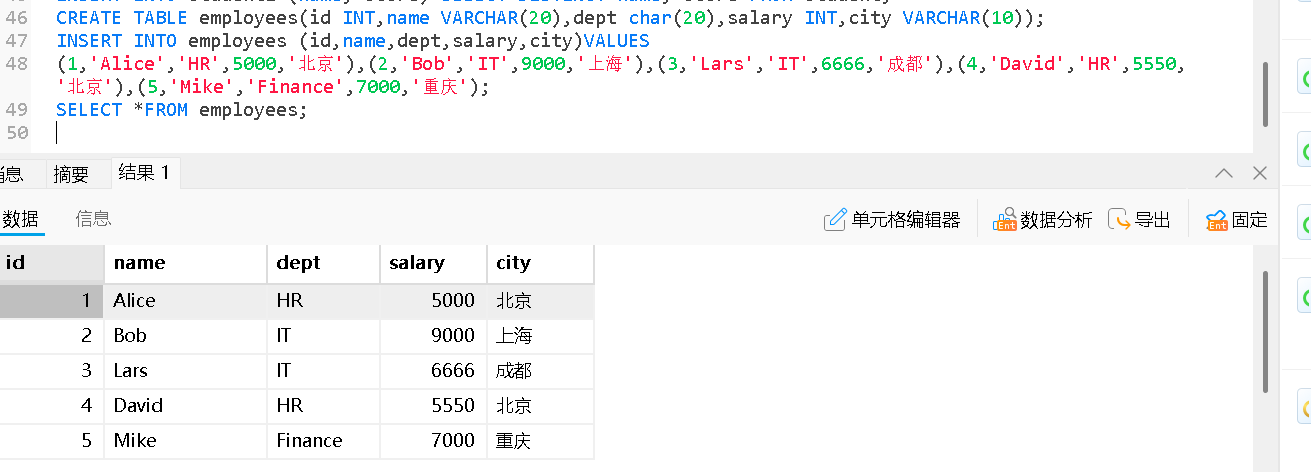
COUNT():统计数量
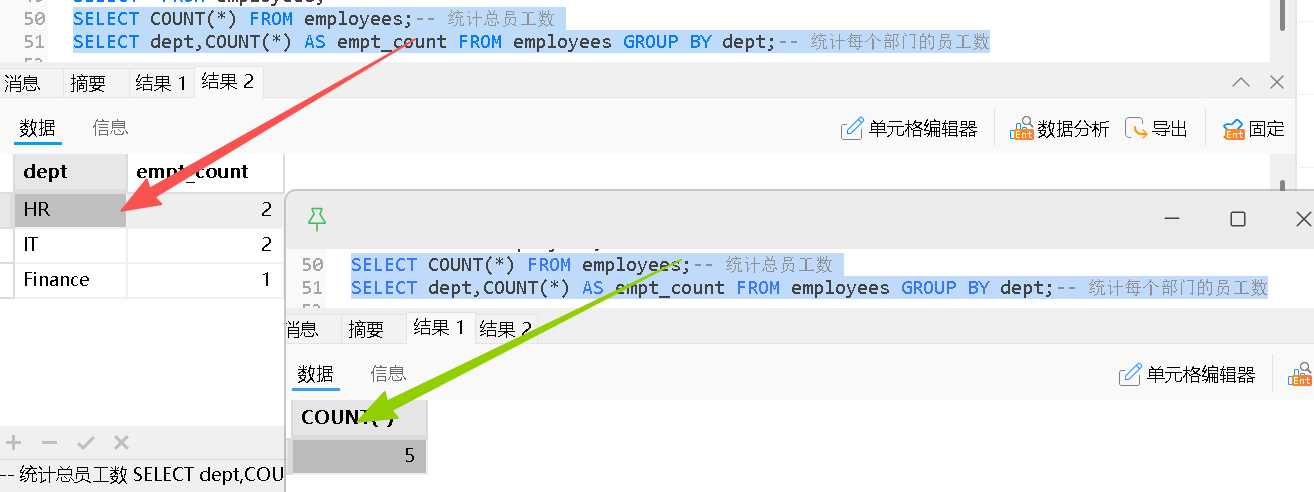
💡 COUNT(*) 包括 NULL;COUNT(column) 只统计非 NULL 值
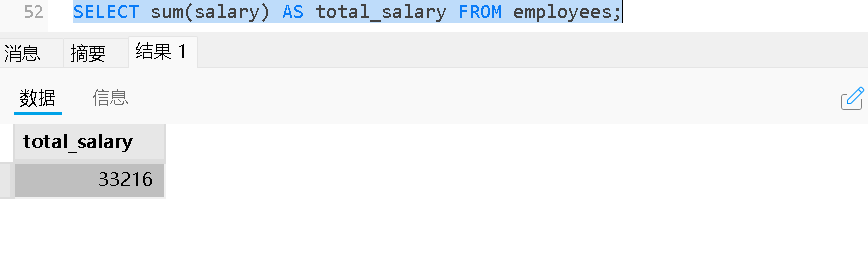
SUM:求和
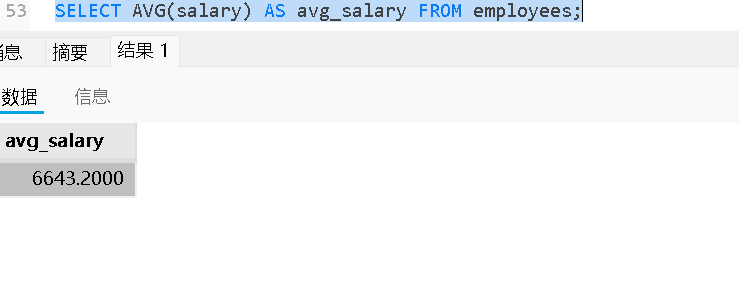
AVG:计算平均值
Max与Min:最大值与最小值
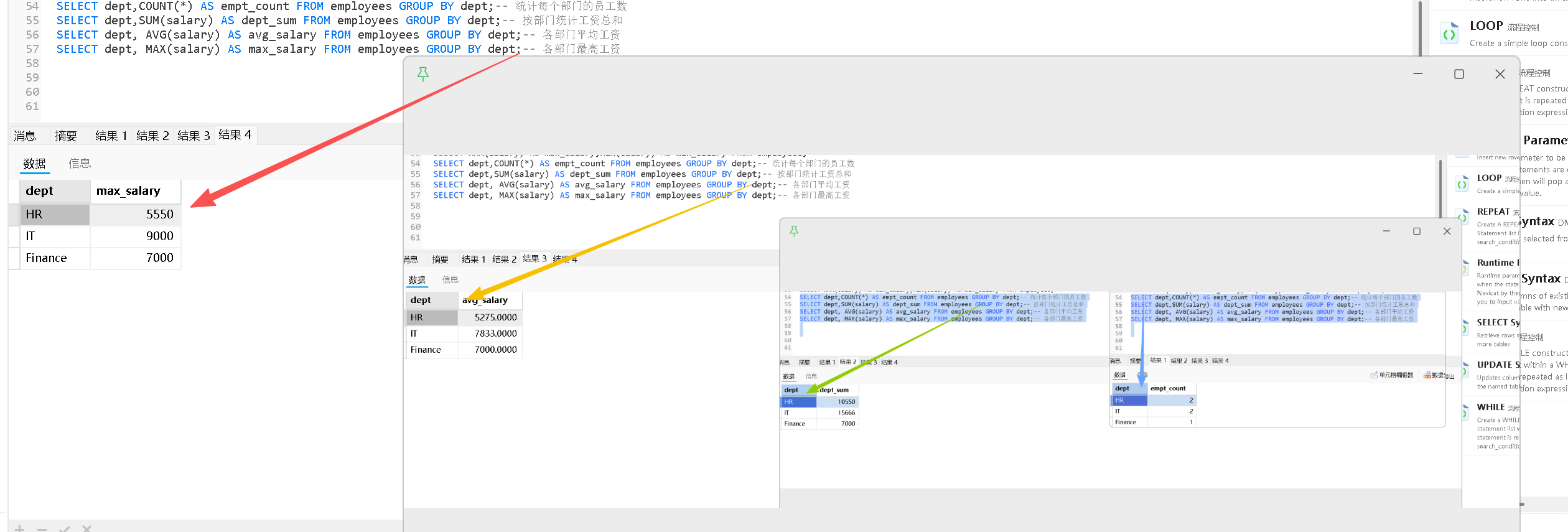
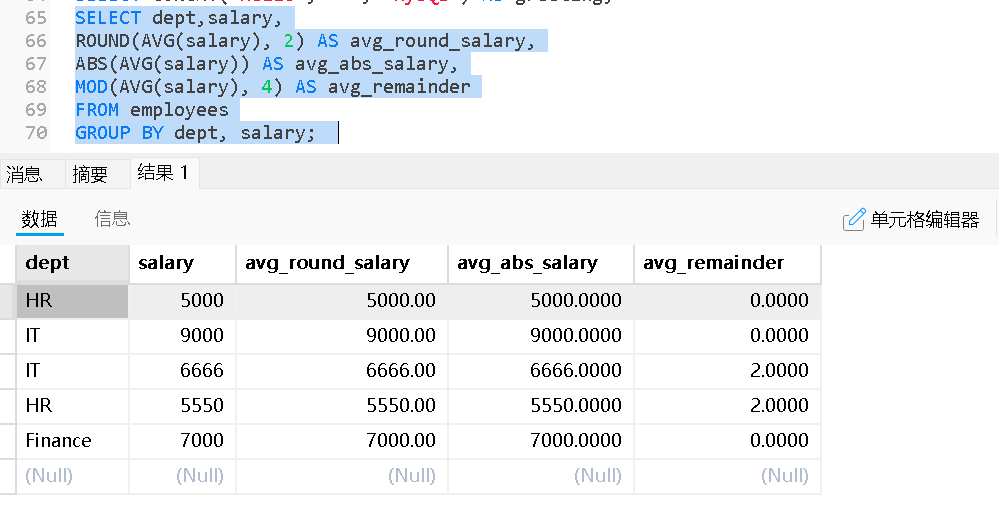
Group by分组查询
GROUP BY 是一个非常重要的子句,用于将结果集按一个或多个列进行分组 ,通常与聚合函数 (如 COUNT、SUM、AVG 等)一起使用,以便对每个分组进行统计分析
SELECT column1, 聚合函数(column2) FROM table_name WHERE 条件(可选) GROUP BY column1;
WHERE与HAVING的区别
- 作用对象不同
WHERE :
- 用于过滤行(记录)
- 在分组前对原始数据进行筛选
- 不能使用聚合函数(如
COUNT,SUM,AVG等)作为条件
HAVING:
- 用于过滤分组(Groups)
- 在分组后对分组结果进行筛选
- 可以使用聚合函数作为条件
2.执行顺序不同
FROM→ 2.WHERE→ 3.GROUP BY→ 4.HAVING→ 5.SELECT→ 6.ORDER BY
WHERE在GROUP BY之前执行,先筛选出符合条件的行HAVING在GROUP BY之后执行,对分组后的结果进行再筛选
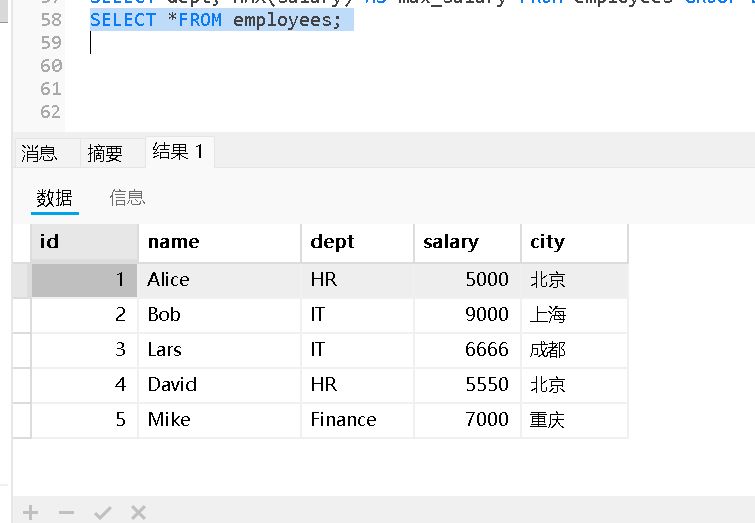
初始employees表
WHERE条件的使用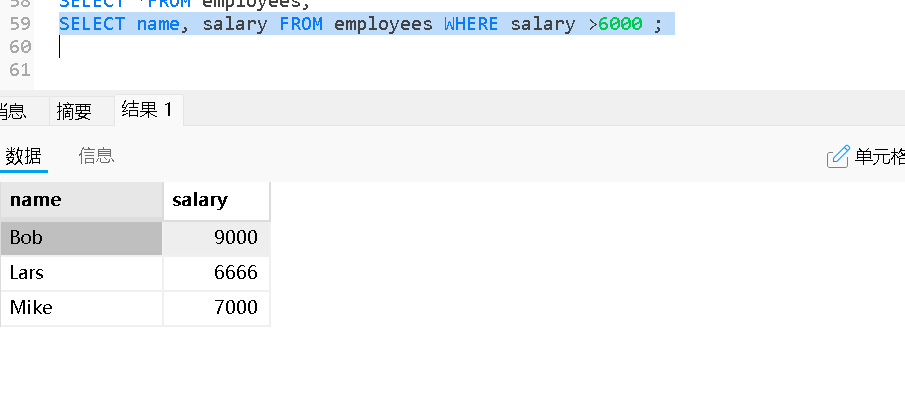
HAVING条件的使用
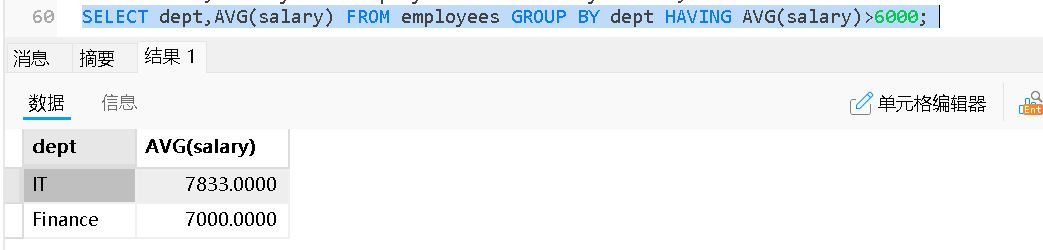
| 特性 | WHERE | HAVING |
|---|---|---|
| 作用对象 | 行(记录) | 分组(Group) |
| 执行时机 | 分组前 | 分组后 |
| 能否用聚合函数 | ❌ 不能 | ✅ 能 |
| 是否必需 | 否 | 否(常与 GROUP BY 一起使用) |
| 典型用途 | 筛选特定条件的原始数据 | 筛选满足聚合条件的分组 |
内置函数
字符串函数
| 函数 | 说明 | 示例 |
|---|---|---|
UPPER(str) |
转大写 | UPPER('hello') → 'HELLO' |
LOWER(str) |
转小写 | LOWER('HELLO') → 'hello' |
TRIM(str) |
去除首尾空格 | TRIM(' abc ') → 'abc' |
SUBSTRING(str, start, len) |
截取子串 | SUBSTRING('hello', 2, 3) → 'ell' |
CONCAT(str1, str2) |
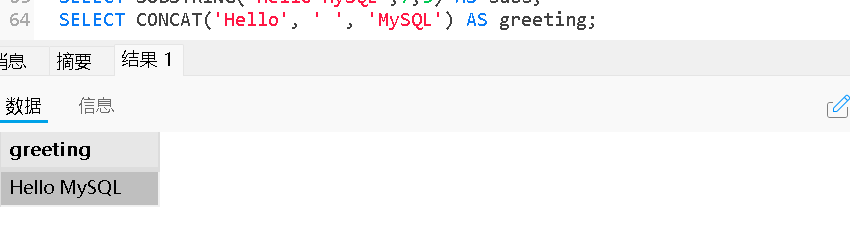
拼接字符串 | CONCAT('a', 'b') → 'ab' |
LENGTH(str) |
字符串长度 | LENGTH('abc') → 3 |
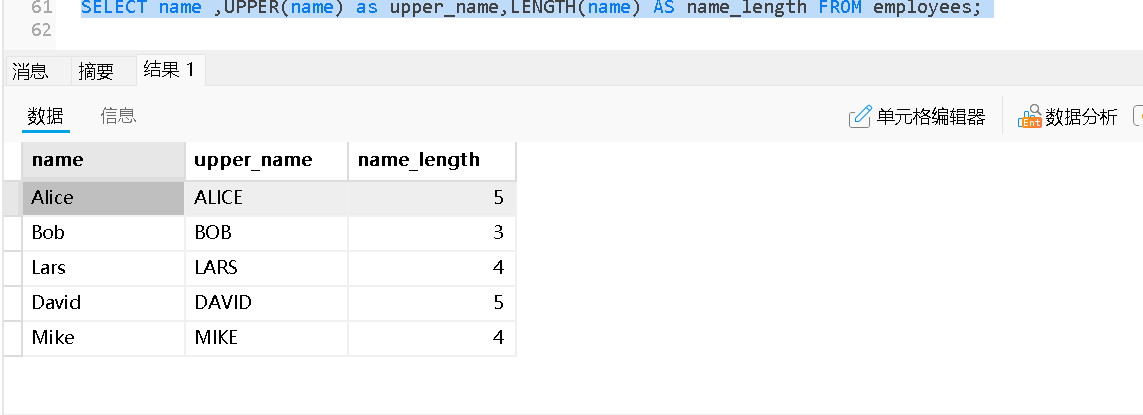
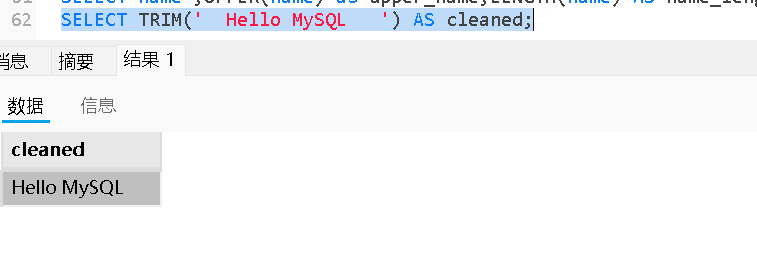
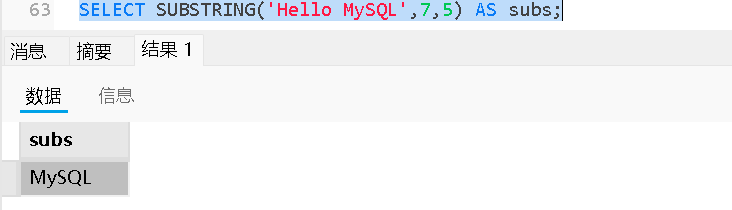
数值函数
| 函数 | 说明 | 示例 |
|---|---|---|
ROUND(num, d) |
四舍五入 | ROUND(3.14159, 2) → 3.14 |
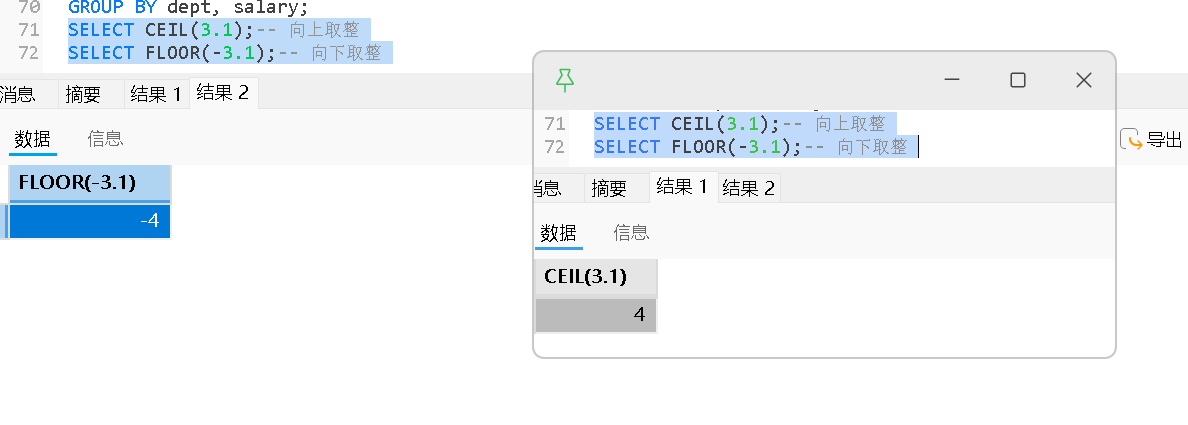
CEIL(num) |
向上取整 | CEIL(3.1) → 4 |
FLOOR(num) |
向下取整 | FLOOR(3.9) → 3 |
ABS(num) |
绝对值 | ABS(-5) → 5 |
MOD(a, b) |
取余 | MOD(10, 3) → 1 |
日期和时间函数
| 函数 | 说明 | 示例 |
|---|---|---|
NOW() |
当前日期时间 | NOW() → '2025-10-05 18:30:00' |
CURDATE() |
当前日期 | CURDATE() → '2025-10-05' |
CURTIME() |
当前时间 | CURTIME() → '18:30:00' |
DATE(date) |
提取日期部分 | DATE('2025-10-05 18:30') → '2025-10-05' |
YEAR(date) |
提取年份 | YEAR(NOW()) → 2025 |
DATEDIFF(date1, date2) |
两个日期相差天数 | DATEDIFF('2025-10-10', '2025-10-05') → 5 |
DATE_ADD(date, INTERVAL n DAY/MONTH/YEAR) |
日期加减 | DATE_ADD(NOW(), INTERVAL 7 DAY) |
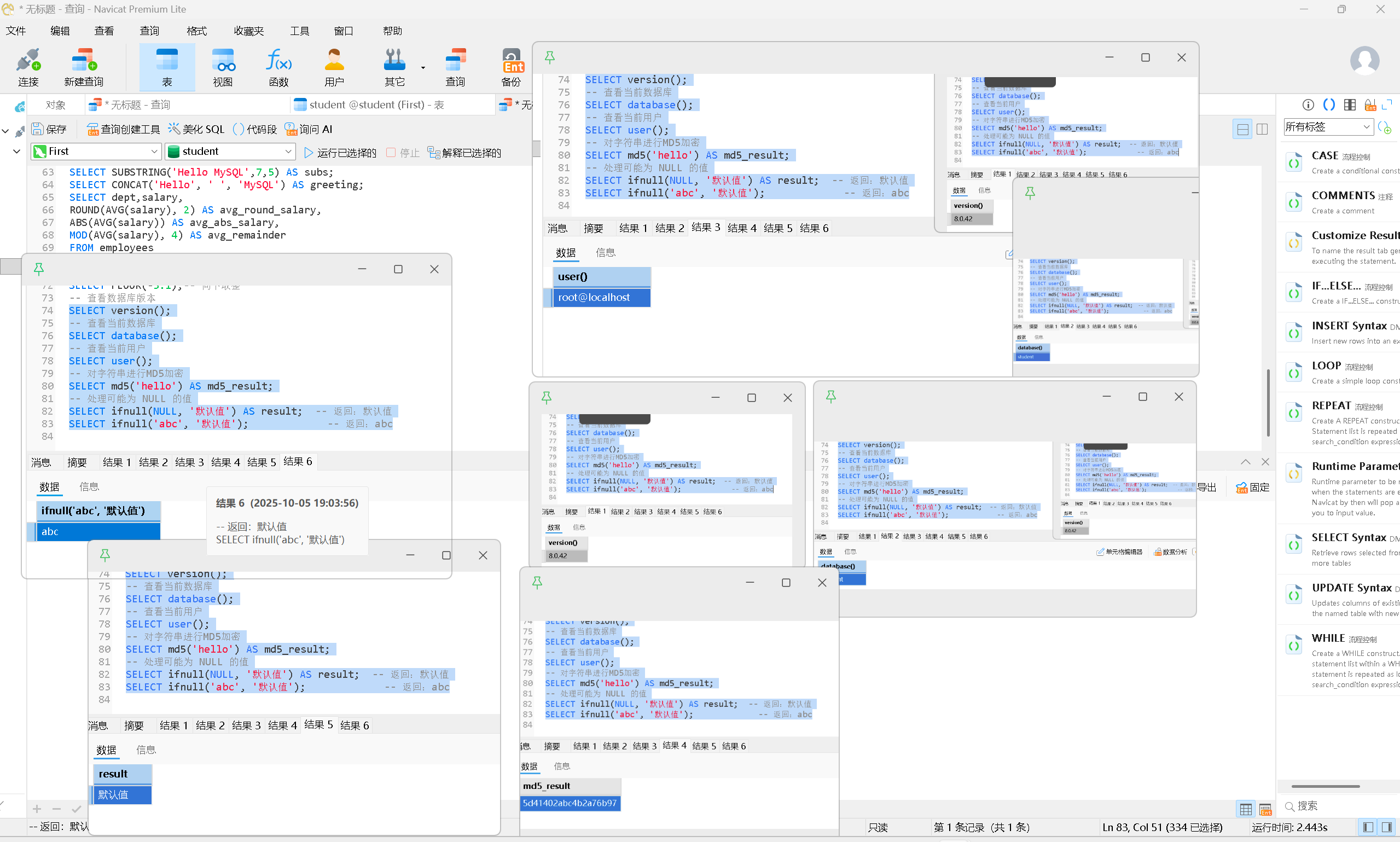
其他常⽤函数
| 函数 | 说明 |
|---|---|
version() |
显示当前数据库版本 |
database() |
显示当前正在使用的数据库 |
user() |
显示当前用户 |
md5(str) |
对一个字符串进行 MD5 摘要,摘要后得到一个 32 位字符串 |
ifnull(val1, val2) |
如果 val1 为 NULL,返回 val2;否则返回 val1 |