
大家好,我是Tony Bai。
欢迎来到《分布式系统:原理、哲学与实战》微专栏的第三讲。
在上一讲中,我们为所处的现实世界绘制了一张精准的地图。我们知道了节点会崩溃,通信会延迟,时间会撒谎。面对这样一个充满不确定性的环境,一个孤立的节点就像一叶扁舟,随时可能在风暴中倾覆。
那么,为了让我们的系统能抵御风暴,活下去,我们能使用的第一件,也是最符合直觉的武器是什么?
答案是:不要把所有鸡蛋放在一个篮子里。
这句古老的谚语,在分布式系统中被翻译成一个核心的技术术语:复制 (Replication)。
复制的核心思想极其简单:将相同的数据,在多个独立的节点上,保存多个副本。它的动机主要有两个:
-
高可用性 (High Availability): 当持有数据的某个节点宕机时,其他持有副本的节点可以顶上,服务不中断。这是我们对抗节点故障的主要手段。
-
性能扩展 (Performance Scaling): 尤其是读性能。多个副本可以同时处理读请求,从而分摊负载,降低延迟。
今天,我们将深入探讨实现复制的最经典、最广泛的架构模式------主从复制 (Leader-Follower Replication)**。但我们不会孤立地看待它。我们将引入一把衡量所有复制系统正确性的"黄金标尺"------**一致性模型 (Consistency Models),并以此为准绳,去度量主从架构在追求秩序的过程中,所能达到的高度,以及必须付出的代价。
理论的标尺:什么是一致性模型?
在只有一个数据副本的单体世界里,"一致性"这个词几乎无需被提及。你写入一个值,下一次读取,必然能读到这个新值。这似乎是天经地义的。
但一旦引入复制,这个"天经地义"就被打破了。当一个写请求在 Leader 上完成,但还未同步到某个 Follower 时,客户端从这个 Follower 读取,就会读到"旧"的数据。这就是不一致。
一致性模型,就是系统向客户端做出的一个关于"读写顺序和数据可见性"的"契约"或"保证"。它精确地定义了,当多个客户端并发读写时,他们可能看到怎样的数据,以及不可能看到怎样的数据。
理解一致性模型至关重要,因为它直接决定了系统的性能、可用性以及开发者编程的难易度。
理解操作的表示法
不过,在深入探讨各个模型之前,我们首先需要一种标准的方式来描述和可视化并发操作。我们将借鉴学术界(如 Herlihy & Wing, 1990)的经典表示法。
- 操作的可视化: 每个操作(如读或写)都有一个开始时间 (Invocation) 和一个结束时间 (Response)。我们将它表示为一个在时间轴上延伸的水平条。
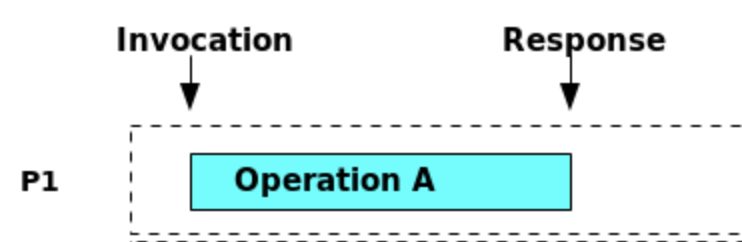
- 顺序操作 (Sequential Operations): 如果操作A的结束时间早于操作B的开始时间(如下图),我们就说 A 先于 (precedes) B,记为
A -> B。它们之间没有时间重叠,顺序是明确的。
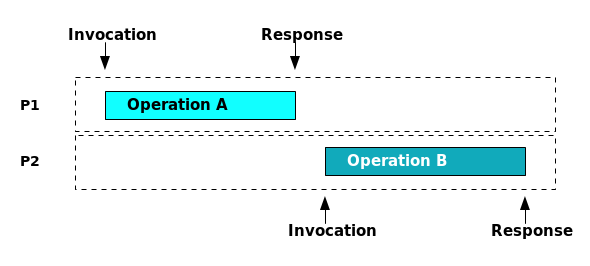
- 并发操作 (Concurrent Operations): 如果操作A在操作B结束前开始,并且操作B在操作A结束前开始,我们就说A和B是并发的,再直白地说两个操作在时间上是有重叠的,它们的"真实"顺序是不确定的。如下图,A操作和B操作是并发的,其真实顺序可能是
A -> B,亦可能是B -> A。
注:上述几个示意图来自"Linearizability: A Correctness Condition for Concurrent Objects"(
http://www.calebgossler.com/notes/Papers/linearizability.html)。
我们的核心示例场景:
我们将使用一个贯穿始终的场景来对比各个模型。假设一个简单的分布式键值存储,其中有两个键 x 和 y,初始值均为 0。有两个客户端 P1 和 P2 进行写操作,另外两个客户端 P3 和 P4 作为观察者进行读操作。