引言:多线程世界里的变量隔离艺术
在Java并发编程的舞台上,线程安全始终是开发者必须跨越的鸿沟。当多个线程共享资源时,同步机制往往带来性能损耗,而ThreadLocal的出现为我们提供了另一种思路------通过变量的线程私有化实现线程安全。这种机制在Spring事务管理、MyBatis会话管理等框架中被广泛应用,成为构建高并发系统的隐形基石。但你真的了解ThreadLocal背后的存储奥秘吗?当线程池遇上ThreadLocal时为何会出现数据错乱?本文将带你从源码实现到架构设计,全面掌握ThreadLocal的技术精髓与实战智慧。
ThreadLocal的核心原理:线程私有变量的存储哲学
线程局部变量的存储机制
每个Thread对象内部都维护着一个ThreadLocalMap实例,这个特殊的Map正是线程私有变量的"秘密仓库"。与传统集合不同,ThreadLocalMap是以ThreadLocal实例为键、以目标变量为值的存储结构。当我们通过threadLocal.set(value)方法存储变量时,实际上是将数据存入当前线程的ThreadLocalMap中;而threadLocal.get()则是从当前线程的Map中取出对应的值。这种设计使得每个线程都拥有独立的变量副本,自然避免了线程间的竞争问题。

JVM内存模型视角下的ThreadLocal
从JVM内存模型来看,ThreadLocal涉及三个关键角色:
- ThreadLocal实例:作为静态变量存在于方法区
- Thread对象:存在于堆内存中,其threadLocals字段引用ThreadLocalMap
- ThreadLocalMap:每个线程独有的哈希表,键为ThreadLocal实例的弱引用
这里需要特别注意弱引用(WeakReference) 的设计。ThreadLocalMap的Entry继承自WeakReference,当ThreadLocal实例不再被外部强引用时,即使Map中仍有Entry,该键也会被GC回收。这种机制在一定程度上缓解了内存泄漏风险,但如果value是强引用且未手动删除,仍可能导致"键消失但值残留"的内存泄漏问题。
ThreadLocal的实现细节:ThreadLocalMap的精妙设计
ThreadLocalMap的内部结构
ThreadLocalMap是JDK精心设计的定制化哈希表,与HashMap相比有诸多特殊之处:
java
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
// 初始容量必须是2的幂
private static final int INITIAL_CAPACITY = 16;
// 存储Entry的数组
private Entry[] table;
// 元素数量
private int size = 0;
// 扩容阈值,默认为容量的2/3
private int threshold;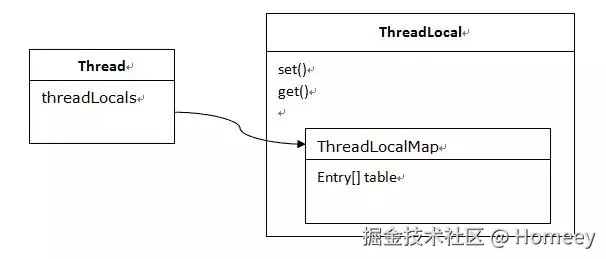
与HashMap的拉链法解决哈希冲突不同,ThreadLocalMap采用开放地址法------当发生哈希冲突时,会尝试下一个空闲的数组位置。这种设计虽然节省空间,但在高冲突场景下性能可能下降,不过考虑到单个线程中ThreadLocal实例通常不会过多,这种权衡是合理的。
ThreadLocalMap的初始化与扩容机制
ThreadLocalMap的初始化是延迟加载的,只有当第一次调用set()或get()方法时才会创建实例。其扩容机制也颇具特色:
- 当元素数量超过阈值(容量的2/3)时触发扩容
- 新容量为原容量的2倍(保持2的幂特性)
- 扩容过程中会重新计算所有Entry的哈希位置,并清理过期Entry(键为null的Entry)
以下是扩容核心代码的简化版:
java
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
int count = 0;
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null; // 帮助GC
} else {
int h = k.threadLocalHashCode & (newLen - 1);
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
setThreshold(newLen);
size = count;
table = newTab;
}变量存取的完整流程解析
set()方法的执行逻辑:
- 获取当前线程的ThreadLocalMap
- 若Map不存在则创建(调用createMap())
- 计算ThreadLocal实例的哈希码
- 遍历Entry数组寻找合适位置(处理哈希冲突)
- 替换已有Entry或新增Entry
- 清理过期Entry并检查是否需要扩容
get()方法的执行逻辑:
- 获取当前线程的ThreadLocalMap
- 若Map不存在则初始化并返回初始值(通过initialValue())
- 计算哈希码并查找对应Entry
- 若找到有效Entry则返回值,否则返回初始值
- 查找过程中会顺便清理过期Entry
这种"懒加载+按需初始化"的策略,既节省了内存空间,又保证了线程首次访问时的正确性。
ThreadLocal的典型应用场景与架构价值
数据库连接管理:事务隔离的基石
在JDBC编程中,一个数据库连接(Connection)通常不能被多线程共享。ThreadLocal完美解决了这一问题------为每个线程分配独立的连接实例,确保事务操作的原子性。Spring框架的TransactionSynchronizationManager正是采用这种机制,将数据库连接与当前线程绑定,实现了声明式事务的优雅封装。
java
public class ConnectionHolder {
private static final ThreadLocal<Connection> connectionHolder = new ThreadLocal<>();
public static Connection getConnection() {
Connection conn = connectionHolder.get();
if (conn == null) {
conn = DriverManager.getConnection(DB_URL, USER, PASS);
connectionHolder.set(conn);
}
return conn;
}
public static void releaseConnection() {
Connection conn = connectionHolder.get();
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
// 异常处理
}
connectionHolder.remove(); // 必须清理,否则可能导致内存泄漏
}
}
}分布式追踪:跨服务调用的上下文传递
在微服务架构中,分布式追踪系统(如Zipkin、SkyWalking)需要在跨服务调用时传递追踪上下文。ThreadLocal可以暂存当前线程的追踪信息(如TraceId、SpanId),通过拦截器在服务调用前后自动传递这些信息。这种方式避免了在方法参数中显式传递上下文,极大简化了代码实现。
状态管理:无状态服务的状态持有方案
RESTful API设计倡导服务的无状态性,但实际业务中往往需要维护用户会话、请求头等状态信息。ThreadLocal提供了请求级别的状态存储能力,配合Servlet的Filter机制,可以将用户认证信息、请求参数等上下文数据绑定到当前处理线程,在整个请求生命周期内随时访问。Spring Security的SecurityContextHolder就是典型应用案例。
ThreadLocal的局限性:隐藏在便利背后的陷阱
线程池环境下的数据污染风险
线程池的线程复用特性与ThreadLocal的生命周期管理存在天然矛盾。当线程任务执行完毕后,ThreadLocal变量若未显式清理,则下次复用该线程时可能读取到旧数据,导致难以排查的"幽灵数据"问题。以下是一个典型的错误案例:
java
// 错误示例:线程池环境下未清理ThreadLocal
ExecutorService executor = Executors.newFixedThreadPool(1);
ThreadLocal<Integer> threadLocal = new ThreadLocal<>();
executor.submit(() -> {
threadLocal.set(100);
System.out.println("任务1: " + threadLocal.get()); // 输出100
});
executor.submit(() -> {
System.out.println("任务2: " + threadLocal.get()); // 可能输出100(数据污染)
});
executor.shutdown();内存泄漏的潜在威胁
尽管ThreadLocalMap的Entry键是弱引用,但值仍然是强引用。如果ThreadLocal实例被回收(如静态变量被卸载),而线程仍在运行(如线程池核心线程),则Entry的键会变为null,但值对象仍被Entry强引用,导致内存泄漏。正确的做法是在使用完毕后主动调用remove()方法清理:
java
try {
threadLocal.set(value);
// 业务逻辑处理
} finally {
threadLocal.remove(); // 确保清除,避免内存泄漏
}跨线程传递的天然障碍
ThreadLocal设计的初衷就是变量的线程隔离,因此无法直接在父子线程间传递数据。在异步编程场景下(如CompletableFuture、消息队列消费),主线程设置的ThreadLocal变量在子线程中无法访问,这极大限制了其在分布式系统中的应用范围。
TTL:ThreadLocal的跨线程传递解决方案
TransmittableThreadLocal的设计理念
面对ThreadLocal的跨线程传递难题,阿里巴巴开源的TTL(Transmittable ThreadLocal)框架给出了优雅的解决方案。其核心思想是在任务提交给线程池时,自动捕获当前线程的ThreadLocal状态,并在任务执行前将这些状态复制到目标线程,执行完毕后再恢复目标线程的原有状态。
TTL的实现原理深度剖析
TTL通过字节码增强技术对线程池的submit()、execute()等方法进行拦截,在任务提交和执行的关键节点完成ThreadLocal状态的传递:
- 状态捕获:当提交任务时,TTL会扫描当前线程的所有TransmittableThreadLocal实例,将其键值对存入临时容器
- 状态注入:任务在线程池执行前,TTL会将捕获的状态注入到执行线程
- 状态恢复:任务执行完毕后,TTL会恢复执行线程原有的ThreadLocal状态
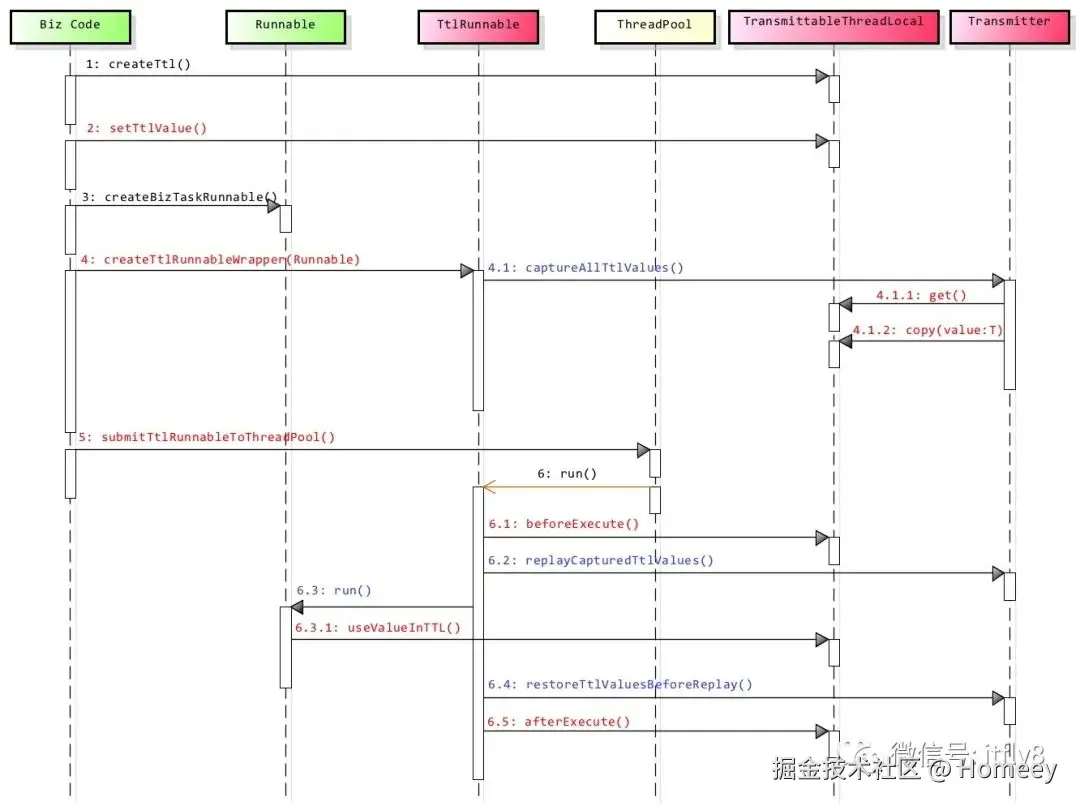
这种机制确保了线程池环境下变量传递的透明性,同时避免了对业务代码的侵入。TTL的核心实现类TransmittableThreadLocal继承自InheritableThreadLocal,但扩展了状态传递的能力。
TTL的实战应用:从代码改造到性能优化
引入TTL依赖
在Maven项目中添加TTL依赖:
xml
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>transmittable-thread-local</artifactId>
<version>2.14.2</version>
</dependency>线程池场景下的TTL使用示例
以下是在线程池中传递用户上下文的典型案例:
java
// 1. 定义可传递的ThreadLocal
public class UserContext {
private static final TransmittableThreadLocal<UserInfo> context = new TransmittableThreadLocal<>();
public static void set(UserInfo userInfo) {
context.set(userInfo);
}
public static UserInfo get() {
return context.get();
}
public static void remove() {
context.remove();
}
}
// 2. 创建增强的线程池
ExecutorService executor = TtlExecutors.getTtlExecutorService(
Executors.newFixedThreadPool(5)
);
// 3. 在主线程设置上下文
UserContext.set(new UserInfo("1001", "张三"));
// 4. 提交任务到线程池
executor.submit(() -> {
// 子线程中可以获取到主线程设置的上下文
UserInfo user = UserContext.get();
System.out.println("子线程获取用户信息: " + user.getName()); // 输出"张三"
});
// 5. 清理上下文
UserContext.remove();
executor.shutdown();与Spring框架的集成方案
在Spring Boot应用中,我们可以通过自定义TaskExecutor实现TTL的自动配置:
java
@Configuration
public class TtlTaskExecutorConfig {
@Bean
public Executor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setQueueCapacity(20);
executor.initialize();
// 包装为TTL增强的线程池
return TtlExecutors.getTtlExecutor(executor);
}
}这样配置后,@Async注解的异步方法就能自动传递TransmittableThreadLocal中的上下文信息。
ThreadLocal与TTL的选型策略:架构视角的权衡
技术特性对比分析
| 特性 | ThreadLocal | TransmittableThreadLocal |
|---|---|---|
| 线程隔离 | ✅ 完美支持 | ✅ 支持且可配置传递规则 |
| 跨线程传递 | ❌不支持 | ✅ 原生支持线程池传递 |
| 内存占用 | 低 | 中(需额外存储传递状态) |
| 性能损耗 | 极低 | 低(字节码增强带来微小开销) |
| 使用复杂度 | 简单 | 中等(需理解传递机制) |
| 兼容性 | JDK原生支持 | 需引入第三方依赖 |
架构设计中的决策指南
优先选择ThreadLocal的场景:
- 简单的单线程场景(如Servlet请求处理)
- 无需跨线程传递变量的场景
- 对性能要求极高且资源受限的系统
推荐使用TTL的场景:
- 基于线程池的异步任务处理
- 微服务架构中的上下文传递
- 分布式追踪、链路监控系统
- 任何需要跨线程共享上下文的场景
最佳实践总结
- 始终手动清理:无论使用ThreadLocal还是TTL,都应在finally块中调用remove()方法
- 避免存储大对象:ThreadLocal中存储大对象可能导致内存占用过高,尤其在核心线程长期运行的场景
- 谨慎使用静态ThreadLocal:静态实例生命周期与类相同,更容易引发内存泄漏
- 线程池必须配合TTL:在任何使用线程池的场景,若需传递上下文,TTL是目前最成熟的解决方案
- 监控与告警:通过JVM监控工具(如VisualVM)定期检查ThreadLocal的使用情况,防止滥用
结语:理解本质,方能善用其力
ThreadLocal作为Java并发编程的重要工具,其价值不仅在于提供线程安全的变量隔离方案,更在于它启发我们思考**"空间换时间"**的架构设计思想。从JDK源码中的精妙实现,到TTL框架对跨线程传递难题的破解,每一步技术演进都体现着开发者对并发本质的深刻理解。
在实际项目中,没有放之四海而皆准的银弹。唯有深入理解技术原理,结合具体业务场景,才能做出合理的技术选型。无论是原生ThreadLocal的简单直接,还是TTL的灵活强大,最终的目标都是构建更健壮、更易维护的系统架构。希望本文能帮助你真正掌握ThreadLocal的精髓,在并发编程的世界中从容前行。