【Android】Android内存缓存LruCache与DiskLruCache的使用及实现原理
在Android中,通常会通过缓存策略来优化性能,同时也会减少不必要的流量消耗。比如,用户第一次使用网络加载一张图片后,下次加载这张图片的时候,并不会从网络加载,而是会从内存或者磁盘加载这张图片。
1.LRU缓存淘汰算法
由于缓存的大小并不是无限制的,因此在使用缓存时总是要为缓存指定一个最大的容量。如果当缓存容量满了,但是程序还需要向其添加缓存,这就需要删除一些旧的缓存并添加新的缓存,如何定义缓存的新旧就对应着不同的缓存算法。最常用的一种缓存算法是LRU (Least Recently Used)最近最少使用算法 ,它的基本理念是:当缓存空间不足时,优先淘汰最久未被访问的数据。常见缓存淘汰策略还有:
1、随机策略: 使用一个随机数生成器随机地选择要被淘汰的数据块;
2、FIFO 先进先出策略: 记录各个数据块的访问时间,最早访问的数据最先被淘汰;
3、LRU (Least Recently Used)最近最少策略: 记录各个数据块的访问 "时间戳" ,最近最久未使用的数据最先被淘汰。与前 2 种策略相比,LRU 策略平均缓存命中率更高,这是因为 LRU 策略利用了 "局部性原理":最近被访问过的数据,将来被访问的几率较大,最近很久未访问的数据,将来访问的几率也较小;
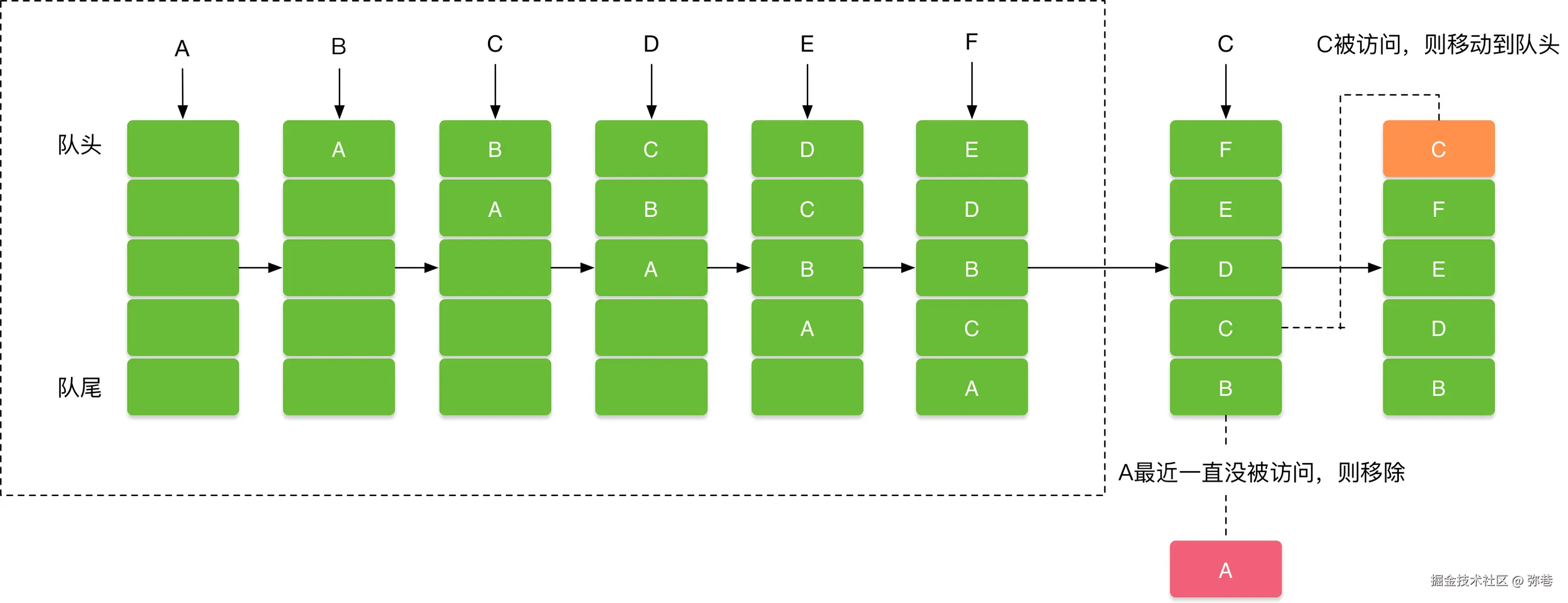
4、LFU (Least Frequently Used)最不经常使用策略: 与 LRU 相比,LFU 更加注重使用的 "频率" 。LFU 会记录每个数据块的访问次数,最少访问次数的数据最先被淘汰。但是有些数据在开始时使用次数很高,以后不再使用,这些数据就会长时间污染缓存。可以定期将计数器右移一位,形成指数衰减。
而在Android中,Lru对应LruCache和DiskLruCache两种缓存类。
2. LruCache的使用
java
int maxMemory = (int) (Runtime.getRuntime().maxMemory() / 1024);
//初始化大小:当前进程的可用内存的1/8
int cacheSize = maxMemory / 8;
memorySize = new LruCache<String, Bitmap>(cacheSize) {
@Override
protected int sizeOf(String key, Bitmap value) {
//重写该方法,完成每张要缓存的图片大小的计算
return bitmap.getRowBytes() * bitmap.getHeight() / 1024;
}
};使用非常简单,只需要提供缓存的总容量大小并重写sizeOf方法即可。总容量大小为当前进程可用内存的1/8,sizeOf方法完成对Bitmap对象大小的计算。
除了创建缓存,还有下面一些常用方法:
| 方法 | 描述 |
|---|---|
| get(K) | 通过K获取缓存 |
| put(K,V) | 设置K的值为V |
| remove(K) | 删除K缓存 |
| evictAll() | 清除缓存 |
| resize(int) | 设置最大缓存大小 |
| snapshot() | 获取缓存内容的镜像 |
3.DiskLruCache的使用
DiskLruCache不是Android SDK的一部分,而是由Jake Wharton在JakeWharton/DiskLruCache提供的一个开源实现。所以使用之前要先引入依赖:
groovy
implementation 'com.jakewharton:disklrucache:2.0.2'3.1 DiskLruCache的创建
DiskLruCache并不能通过构造方法来创建,它提供了open方法用于创建自身:
java
import com.jakewharton.disklrucache.DiskLruCache;
import java.io.*;
public class DiskCacheHelper {
private DiskLruCache diskLruCache;
public DiskCacheHelper(File cacheDir) throws IOException {
// 创建缓存目录
if (!cacheDir.exists()) {
cacheDir.mkdirs();
}
// 初始化DiskLruCache
// 参数:缓存目录, 版本号, 每个key对应的文件数, 最大缓存大小(字节)
diskLruCache = DiskLruCache.open(cacheDir, 1, 1, 10 * 1024 * 1024); // 10MB
}
}open方法有四个参数,其中第一个参数表示磁盘缓存在文件系统中的存储路径。第二个参数表示应用的版本号,一般设为1即可;第三个参数表示单个节点所对应的数据的个数,一般设为1即可;第四个参数表示缓存的总大小,比如10MB,当缓存大小超出这个设定值后,DiskLruCache会清除一些缓存从而保证总大小不大于这个设定值。
3.2 DiskLruCache的缓存添加
java
public void saveToCache(String key, String data) throws IOException {
// 获取编辑器
DiskLruCache.Editor editor = diskLruCache.edit(key);
if (editor == null) return;
// 写入数据
OutputStream outputStream = editor.newOutputStream(0);
outputStream.write(data.getBytes());
outputStream.close();
// 提交保存
editor.commit();
}要添加缓存,首先要通过key获取缓存对象的Editor(编辑对象),对于这个key来说如果当前不存在其他Editor对象。那么edit()就会返回一个新的Editor对象,接着通过这个Editor就可以得到一个文件输出流,有了文件输出流,数据就可以通过这个文件输出流写入到文件系统上。最后要注意的是,单单通过outputStream.write(data.getBytes());,数据其实并没有真正地写入文件系统,还必须通过Editor的commit()来提交写入操作。如果数据下载过程中发生了异常还可以通过Editor的abort()来回退整个操作:
java
try {
try (OutputStream os = editor.newOutputStream(0)) {
os.write(data.getBytes());
}
editor.commit();
} catch (IOException e) {
editor.abort(); // 回退
throw e;
}这样数据就成功写入到文件系统了,接下来数据(比如图片)的获取就不需要网络了。
3.3 DiskLruCache的缓存查找
java
public String readFromCache(String key) throws IOException {
// 获取快照
DiskLruCache.Snapshot snapshot = diskLruCache.get(key);
if (snapshot == null) return null;
// 读取数据
InputStream inputStream = snapshot.getInputStream(0);
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
StringBuilder stringBuilder = new StringBuilder();
String line;
while ((line = reader.readLine()) != null) {
stringBuilder.append(line);
}
reader.close();
snapshot.close();
return stringBuilder.toString();
}和缓存的添加类似,查找缓存首先通过DiskLruCache的get方法传入key获取到Snapshot对象,接下里通过Snapshot对象就能得到缓存的文件输入流,拿到文件输入流,就能很轻松的得到原始数据。
3.4 DiskLruCache的缓存删除
删除就非常简单了,DiskLruCache提供了remove方法实现缓存的删除操作:
java
public void removeFromCache(String key) throws IOException {
diskLruCache.remove(key);
}4. LruCache的源码实现
LruCahche其实使用了LinkedHashMap双向链表结构,以下是LinkedHashMap的构造方法:
java
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}布尔变量accessOrder为true时,LinkedHashMap会以访问顺序排列元素,也就是访问了之后就将这个元素放到集合的最后面,否则以插入顺序排列元素。
可以发现,在LiskHashMap中,当accessOrder为true时,最后被访问的元素会被移动到表尾,而LruCache也是从表尾访问数据,在表头删除元素,这正是符合我们预期的,接下来看看LruCache是如何进行缓存的写入、获取和删除的。
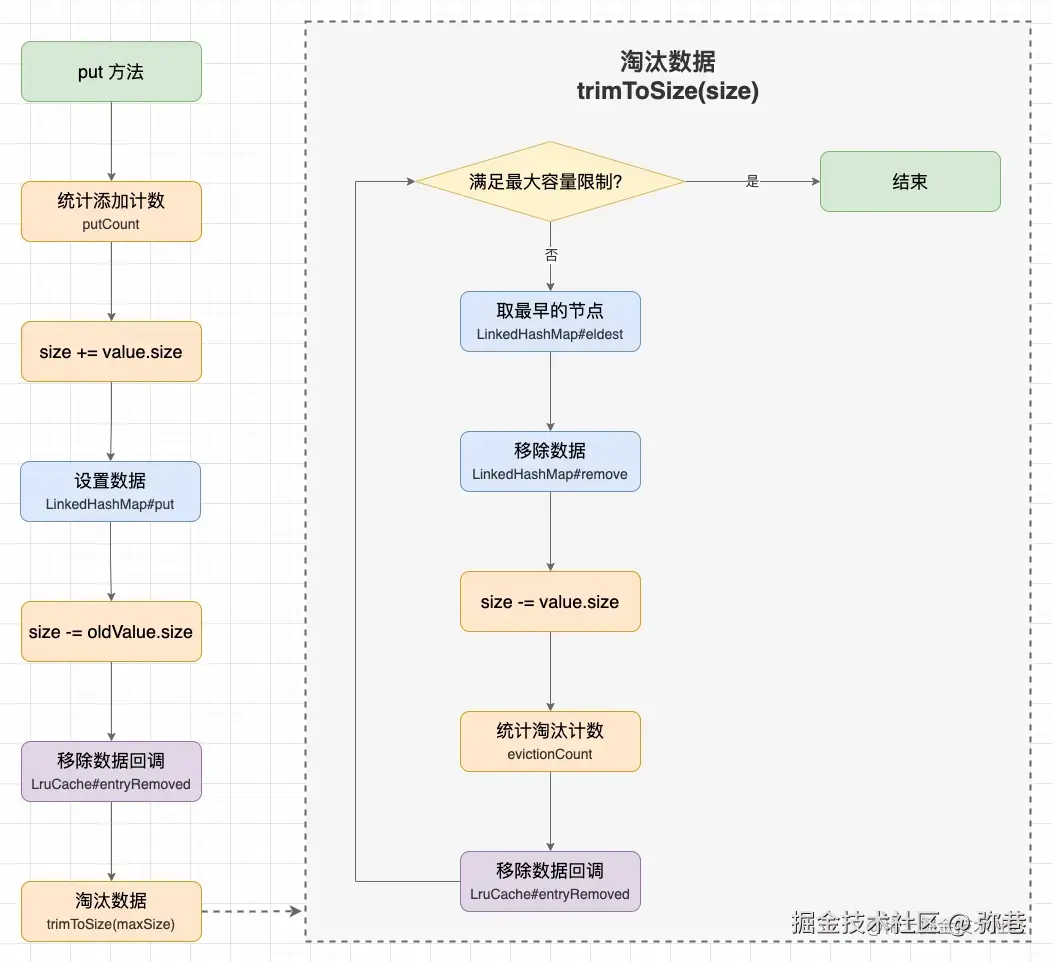
4.1 LruCache的put()方法分析:
写入缓存是通过LruChche的put方法实现的,源码如下:
java
public final V put(K key, V value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
// 这个变量用于保存被替换的旧值(如果有的话)
V previous;
// 加锁,确保线程安全
synchronized (this) {
// 缓存数量自增
putCount++;
// 计算缓存总大小,safeSizeOf方法计算当前键值对的大小
size += safeSizeOf(key, value);
// 通过LinkedHashMap中的put方法将键值对存入map中
// 如果键已存在,map.put会返回被替换的旧值,否则返回null
previous = map.put(key, value);
// 旧值存在(就是更新键所对应的值)
if (previous != null) {
// 从总大小中减去旧值的大小,注意新值大小已经添加
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
// 用于资源回收清理
entryRemoved(false, key, previous, value);
}
// 检查并调整缓存大小,使用Lru算法确保当前缓存总大小不会超出最大容量限制
trimToSize(maxSize);
// 返回被替换的旧值(如果存在)
return previous;
}
public void trimToSize(int maxSize) {
// 无限循环删除最老缓存直到大小满足要求
while (true) {
// 用于保存被删除的键值对
K key;
V value;
synchronized (this) {
// 参数检查
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
// 循环终止条件:当前大小小于等于最大容量,不需要删除最老缓存
if (size <= maxSize) {
break;
}
// 核心:eldest()方法返回最近最少使用的缓存,也就是链表的表头元素
Map.Entry<K, V> toEvict = eldest();
// 异常判断:没有可移除的缓存
if (toEvict == null) {
break;
}
// 最近最少使用的缓存的键值对
key = toEvict.getKey();
value = toEvict.getValue();
// 使用LinkedHashMap的remove方法移除该缓存
map.remove(key);
// 从总大小中减去删除的缓存大小
size -= safeSizeOf(key, value);
// 移除计数器自增
evictionCount++;
}
// 资源回收,true表示由于缓存空间不足而被删除,null表示新值
entryRemoved(true, key, value, null);
}
}put方法主要是添加缓存后,然后调用trimToSize方法使用Lru算法来删除最近最少使用的缓存,保证缓存大小。同时两个方法都使用了同步方法块确保线程安全,简要概括来讲就是先插入后检查,以下图示很清楚地展示了put方法的工作流程:
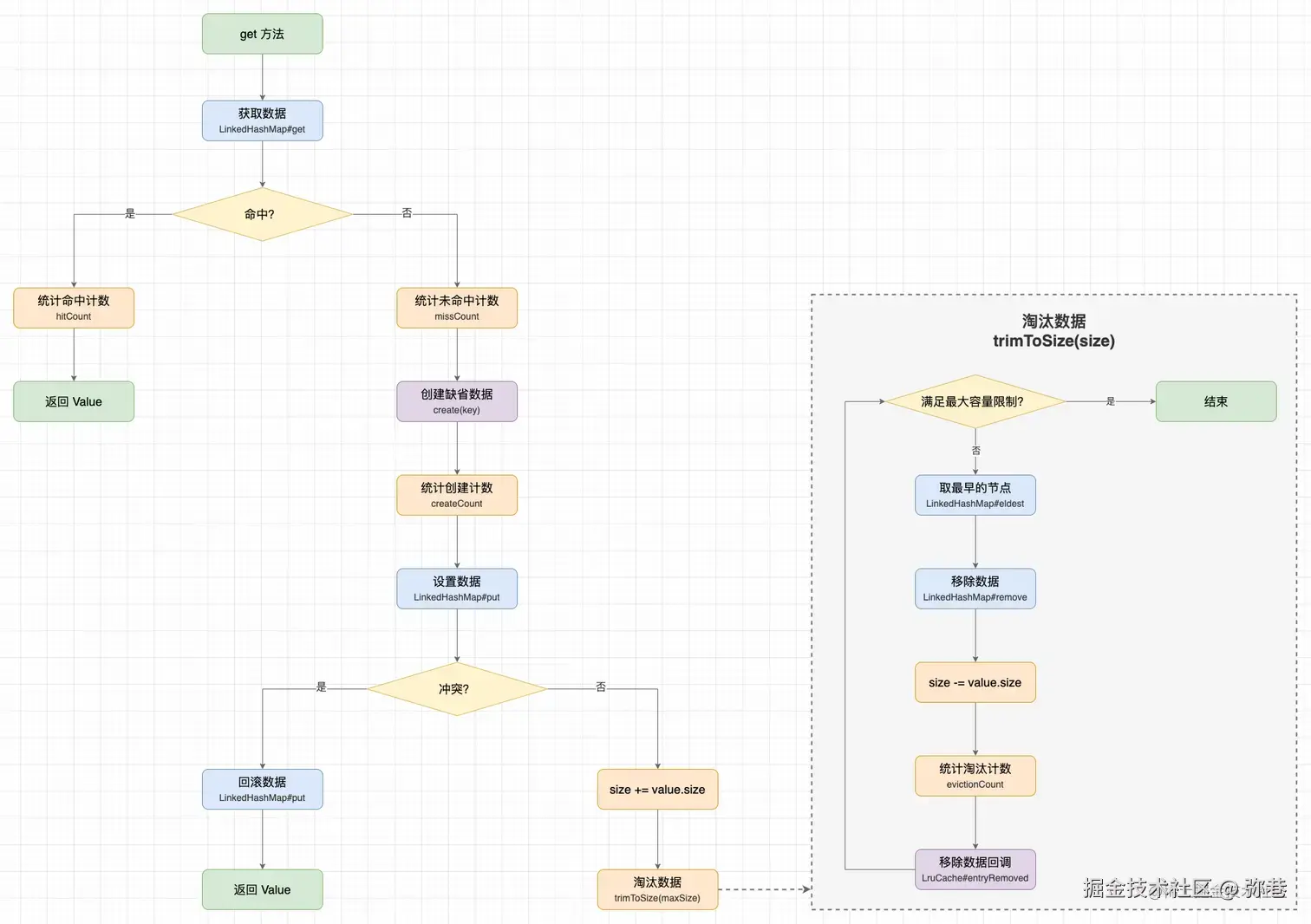
4.2 LruCache的get()方法分析:
get()方法实现了LruCache的读取缓存操作:
java
public final V get(K key) {
// 键的非空判断
if (key == null) {
throw new NullPointerException("key == null");
}
V mapValue;
// 尝试从缓存中获取值
synchronized (this) {
//调用LinkedHashMap的get()方法,注意如果该元素存在,且accessOrder为true,这个方法会将该元素移动到表尾
mapValue = map.get(key);
// 缓存命中:
if (mapValue != null) {
hitCount++; // 命中计数器自增
return mapValue; // 返回找到的值,get()方法结束
}
// 缓存没有命中:
missCount++; // 未命中计数器自增
}
// 缓存未命中处理:创建值
V createdValue = create(key);
// creat()方法返回null,创建失败,get()直接返回null
if (createdValue == null) {
return null;
}
// 将创建的值存入缓存
synchronized (this) {
createCount++; // 创建计数器自增
// 尝试将创建的值存入map
// 注:在释放锁和重新加锁的间隙,其他线程可能已经存入相同的键,所以这里使用put()方法,可能会返回已经存在的值
mapValue = map.put(key, createdValue);
// 如果mapValue不为空,说明创建过程中发生了冲突,也就是其他线程在我们创建值的同时也插入了相同的键
if (mapValue != null) {
// There was a conflict so undo that last put
// 撤销刚才的put操作,就是把其他线程插入的值恢复
map.put(key, mapValue);
} else {
// 没有冲突,正常更新缓存大小
size += safeSizeOf(key, createdValue);
}
}
if (mapValue != null) {
// 发生冲突,通知创建的值被丢弃,回调entryRemoved完方法成资源的回收工作
entryRemoved(false, key, createdValue, mapValue);
return mapValue; // 返回其他线程插入的值(就是最终缓存中的值)
} else {
// 没有冲突,正常进行容量检查
trimToSize(maxSize);
// 返回创建的值
return createdValue;
}
}逻辑很清楚,首先通过LinkedHashMap的get方法通过键key获取值,如果存在,并且且accessOrder为true,整个方法会将元素移动到表尾,实现Lru的缓存逻辑。
如果get方法获取不到值,那么就创建键值对通过LinkedHashMap的put方法存入map,和put方法的逻辑类似,不过中间会进行线程安全的判断,保证不会重复插入键。
get方法图示:
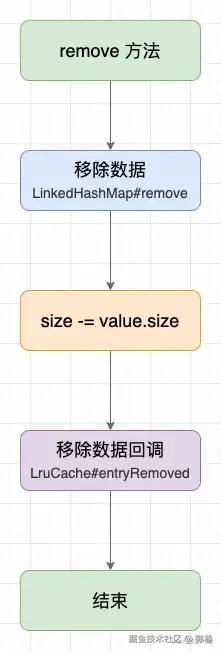
4.3 LruCache删除缓存方法分析:
LruCache中删除缓存是通过remove()方法实现的:
java
public final V remove(K key) {
if (key == null) {
throw new NullPointerException("key == null");
}
// 保存被移除的值
V previous;
// 确保线程安全地移除操作
synchronized (this) {
// 从map中移除缓存
// 如果存在key所对应地值,返回被移除的值
// 不存在就返回null
previous = map.remove(key);
// 成功移除了缓存
if (previous != null) {
// 更新缓存总大小
size -= safeSizeOf(key, previous);
}
}
// 成功移除缓存,回调entryRemoved方法进行资源回收工作
if (previous != null) {
entryRemoved(false, key, previous, null);
}
// 返回被移除的值,如果键不存在就返回null
return previous;
}同样非常简单,调用LinkedHashMap的remove方法删除key所对应的值,也是使用了同步方法块来确保线程安全
图示:
5. DiskLruCache的源码实现
5.1 DiskLruCache的open()方法分析
DiskLruCache的使用从DiskLruCache的创建开始,也就是从open方法开始,接下来看看open方法的实现:
java
/**
* 打开或创建磁盘LRU缓存实例
* 这是DiskLruCache的主入口方法,负责缓存的初始化、恢复和重建
*
* @param directory 缓存目录,缓存文件将存储在此目录下
* @param appVersion 应用版本号,用于版本管理(版本变更时会清空缓存)
* @param valueCount 每个缓存条目对应的文件数量(通常为1)
* @param maxSize 缓存的最大容量(字节)
* @return 初始化好的DiskLruCache实例
* @throws IOException 如果发生I/O错误
* @throws IllegalArgumentException 如果参数不合法
*/
public final class DiskLruCache implements Closeable {
public static DiskLruCache open(File directory, int appVersion, int valueCount, long maxSize)
throws IOException {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
if (valueCount <= 0) {
throw new IllegalArgumentException("valueCount <= 0");
}
File backupFile = new File(directory, JOURNAL_FILE_BACKUP);
//如果备份文件存在
if (backupFile.exists()) {
File journalFile = new File(directory, JOURNAL_FILE);
// 如果journal文件存在,则把备份文件journal.bkp是删了
if (journalFile.exists()) {
backupFile.delete();
} else {
//如果journal文件不存在,则将备份文件命名为journal
renameTo(backupFile, journalFile, false);
}
}
// 尝试从现有缓存恢复:优先复用已有的缓存数据
DiskLruCache cache = new DiskLruCache(directory, appVersion, valueCount, maxSize);
//判断journal文件是否存在
if (cache.journalFile.exists()) {
//如果日志文件以及存在
try {
// 恢复现有缓存的三步流程:
// 1. readJournal(): 读取日志文件内容到内存
cache.readJournal();
// 2. processJournal(): 处理日志条目,重建缓存状态
cache.processJournal();
// 3. 创建追加模式的日志写入器,用于后续操作
cache.journalWriter = new BufferedWriter(
new OutputStreamWriter(new FileOutputStream(cache.journalFile, true), Util.US_ASCII));
return cache;
} catch (IOException journalIsCorrupt) {
System.out
.println("DiskLruCache "
+ directory
+ " is corrupt: "
+ journalIsCorrupt.getMessage()
+ ", removing");
cache.delete();
}
}
// Create a new empty cache.
//创建新的缓存目录
directory.mkdirs();
cache = new DiskLruCache(directory, appVersion, valueCount, maxSize);
//调用新的方法建立新的journal文件
cache.rebuildJournal();
return cache;
}
}DiskLruCache的构造方法并没有做别的事情,只是简单的将对应成员变量进行初始化,open()方法主要围绕着journal文件的创建与读写而展开的,如下所示:
- readJournal():读取journal文件,主要是读取文件头里的信息进行检验,然后调用readJournalLine()逐行去读取,根据读取的内容,执行相应的缓存 添加、移除等操作。
- rebuildJournal():重建journal文件,重建journal文件主要是写入文件头(上面提到的journal文件都有的前面五行的内容)。
- rocessJournal():计算当前缓存容量的大小。
至于journal文件,则是一个日志文件,主要用于记录缓存的所有操作和状态。这里关于journal文件的创建和读写流程就不展开了,感兴趣的朋友可以看看它的具体原理。接下来主要围绕DiskLruCache的写入,查找以及删除缓存来介绍。
5.2 DiskLruCache的edit()方法分析:
DiskLruCache缓存的写入是通过edit()方法来完成的,源码如下:
java
private synchronized Editor edit(String key, long expectedSequenceNumber) throws IOException {
// 检查DiskLruCache是否已关闭,关闭则抛出异常
checkNotClosed();
// 验证键的有效性(通常检查是否包含空格等非法字符)
validateKey(key);
// 从之前的缓存中读取对应的entry
Entry entry = lruEntries.get(key);
// 无法修改
if (expectedSequenceNumber != ANY_SEQUENCE_NUMBER && (entry == null
|| entry.sequenceNumber != expectedSequenceNumber)) {
return null; // Snapshot is stale.
}
// key所对应的缓存不存在,创建新的键值对并存入LinkedHashMap中
if (entry == null) {
entry = new Entry(key);
lruEntries.put(key, entry);
} else if (entry.currentEditor != null) {
// 如果当前缓存正在被其他Editor编辑,拒绝并发编辑
return null; // Another edit is in progress.
}
// 创建新的Editor实例,与缓存相关联
Editor editor = new Editor(entry);
entry.currentEditor = editor; // 当前缓存为编辑状态
// Flush the journal before creating files to prevent file leaks.
// 写入DIRTY记录表示开始编辑操作
journalWriter.write(DIRTY + ' ' + key + '\n');
journalWriter.flush(); // 强制刷新到磁盘,确保日志持久化
// 返回Editor实例以供后续编辑使用
return editor;
}至于DIRTY,DIRTY是DiskLruCache的一种状态标记。向日志文件中写入DIRTY ,则表示当前缓存条目正在被编辑但尚未完成。
一般格式为DIRTY + 空格+key,比如:
bash
DIRTY key123 # 表示 key123 这个条目正在被修改一般来说DIRTY 记录与 CLEAN/REMOVE 记录成对出现,构成一个完整的操作单元:
正常完成:
objectivec
DIRTY key123 ← 表示缓存条目开始编辑
...(文件操作)...
CLEAN key123 ← 表示缓存条目编辑成功完成异常终止:
markdown
DIRTY key123 ← 表示缓存条目开始编辑
...(程序崩溃)...
← 缺少 CLEAN,表示操作未完成而lruEntries则是一个LinkedHashMap对象,表示实际的缓存条目表,负责实际的缓存存储。

edit()方法主要就是构建了一个Editor对象,它主要干了两件事:
- 从集合中找到对应的实例(如果没有创建一个放到集合中),然后创建一个editor,将editor和entry关联起来。
- 向journal中写入一行操作数据(DITTY 空格 和key拼接的文字),表示这个key当前正处于编辑状态。
在前面使用DiskLruCache的例子中,我们调用了Editor的newOutputStream()方法创建了一个OutputStream来写入缓存文件:
java
/**
* 获取缓存条目指定索引值文件的输入流
* 用于读取缓存数据,通常在Snapshot对象中使用
*
* @param index 值文件的索引(从0开始,小于valueCount)
* @return 文件的输入流,如果文件不存在返回null
* @throws IOException 如果发生I/O错误
* @throws IllegalStateException 如果Snapshot已关闭或无效
*/
public InputStream newInputStream(int index) throws IOException {
synchronized (DiskLruCache.this) {
// 确保当前Editor仍然有效
if (entry.currentEditor != this) {
// 两种情况:
// 1. Snapshot已被关闭
// 2. 或者条目已被新的Editor占用
throw new IllegalStateException();
}
// 检查条目是否可读:entry.readable为true表示条目处于CLEAN状态
// 如果为false,说明条目可能正在编辑或已被移除
if (!entry.readable) {
return null;
}
try {
// entry.getCleanFile(index) 获取指定索引的缓存数据文件
return new FileInputStream(entry.getCleanFile(index));
} catch (FileNotFoundException e) {
return null;
}
}
}这个方法的形参index就是我们开始在open()方法里传入的valueCount,这个valueCount表示了一个key对应几个value,也就是说一个key对应几个缓存文件。那么现在传入的这个index就表示 要缓存的文件时对应的第几个value。
有了输出流,我们在接着调用Editor的commit()方法就可以完成缓存文件的写入了:
java
public void commit() throws IOException {
if (hasErrors) {
// 如果写入缓存出错就把集合中的缓存条目移除掉
completeEdit(this, false);
remove(entry.key); // The previous entry is stale.
} else {
// 编辑成功则提交更改
completeEdit(this, true);
}
// 标记本次编辑已提交,防止重复提交
committed = true;
}通过completeEdit方法来完成最终的缓存写入,completeEdit方法负责处理编辑的提交或中止。当编辑成功时,它将编辑过程中使用的临时工作文件转换为最终的缓存数据文件,更新缓存大小统计,并在日志中写入 CLEAN 记录;当编辑失败时,则删除临时文件进行操作撤销。 至此,缓存的插入就完成了。
3.3 读取缓存
读取缓存是由DiskLruCache的get()方法来完成的,如下所示:
java
public final class DiskLruCache implements Closeable {
public synchronized Snapshot get(String key) throws IOException {
checkNotClosed();
validateKey(key);
// 获取key对应的entry
Entry entry = lruEntries.get(key);
if (entry == null) {
return null;
}
// 如果entry不可读,说明可能在编辑,则返回空。
if (!entry.readable) {
return null;
}
// 打开所有缓存文件的输入流,等待被读取。
InputStream[] ins = new InputStream[valueCount];
try {
// 为每个值文件创建输入流
for (int i = 0; i < valueCount; i++) {
// 获取正式缓存文件(非临时文件)的输入流
ins[i] = new FileInputStream(entry.getCleanFile(i));
}
} catch (FileNotFoundException e) {
// A file must have been deleted manually!
for (int i = 0; i < valueCount; i++) {
if (ins[i] != null) {
Util.closeQuietly(ins[i]);
} else {
break;
}
}
return null;
}
// 增加冗余操作计数
redundantOpCount++;
// 向journal写入一行READ开头的记录,表示执行了一次读取操作
journalWriter.append(READ + ' ' + key + '\n');
// 如果缓存总大小已经超过了设定的最大缓存大小或者操作次数超过了2000次,就开一个线程将集合中的数据删除到小于最大缓存大小为止并重新写journal文件
if (journalRebuildRequired()) {
executorService.submit(cleanupCallable);
}
// 返回一个缓存文件快照,包含缓存文件大小,输入流等信息。
return new Snapshot(key, entry.sequenceNumber, ins, entry.lengths);
}
}读取操作主要完成了以下几件事情:
- 获取对应的entry。
- 打开所有缓存文件的输入流,等待被读取。
- 向journal写入一行READ开头的记录,表示执行了一次读取操作。
- 如果缓存总大小已经超过了设定的最大缓存大小或者操作次数超过了2000次,就开一个线程将集合中的数据删除到小于最大缓存大小为止并重新写journal文件。
- 返回一个缓存文件快照,包含缓存文件大小,输入流等信息。
该方法最终返回一个缓存文件快照,包含缓存文件大小,输入流等信息。利用这个快照我们就可以读取缓存文件了。
3.4 删除缓存
删除缓存是由DiskLruCache的remove()方法来完成的,如下所示:
java
public final class DiskLruCache implements Closeable {
public synchronized boolean remove(String key) throws IOException {
checkNotClosed();
validateKey(key);
// 获取对应的entry
Entry entry = lruEntries.get(key);
if (entry == null || entry.currentEditor != null) {
return false;
}
// 删除对应的缓存文件,并将缓存大小置为0.
for (int i = 0; i < valueCount; i++) {
File file = entry.getCleanFile(i);
if (file.exists() && !file.delete()) {
throw new IOException("failed to delete " + file);
}
size -= entry.lengths[i];
entry.lengths[i] = 0;
}
redundantOpCount++;
// 向journal文件添加一行REMOVE开头的记录,表示执行了一次删除操作。
journalWriter.append(REMOVE + ' ' + key + '\n');
lruEntries.remove(key);
// 如果缓存总大小已经超过了设定的最大缓存大小或者操作次数超过了2000次,就开一个线程将集合中的数据删除到小于最大缓存大小为止并重新写journal文件
if (journalRebuildRequired()) {
executorService.submit(cleanupCallable);
}
return true;
}
}删除操作主要做了以下几件事情:
- 获取对应的entry。
- 删除对应的缓存文件,并将缓存大小置为0.
- 向journal文件添加一行REMOVE开头的记录,表示执行了一次删除操作。
- 如果缓存总大小已经超过了设定的最大缓存大小或者操作次数超过了2000次,就开一个线程将集合中的数据删除到小于最大缓存大小为止并重新写journal文件。