本章内容
- 初识 Spring AI 的评估器(evaluators)
- 检查相关性(relevancy)
- 判断回答的正确性(correctness)
- 在运行时应用评估器
为你的代码编写测试是一种重要实践。自动化测试不仅能确保应用没有被破坏,还能提供有助于设计与实现的反馈。对应用中的生成式 AI 组件进行测试,丝毫不比其他部分的测试不重要。
只有一个问题:如果你把相同的提示多次发送给一个 LLM,你很可能每次都会得到不同的答案。生成式 AI 的非确定性意味着测试中无法采用"断言相等(assert equals)"的套路。
在第 1 章里,你看到如何使用 WireMock 来模拟 API 的响应,从而在测试中获得确定性的 结果。这种测试方式非常适合测试"围绕向生成式 AI API 发起请求"的代码,但它并不能测试提示本身 以及模型如何对该提示作出响应。幸运的是,Spring AI 提供了另一种判断"生成响应是否可接受"的方式:评估器(Evaluators) 。
一个评估器会拿到提交给 LLM 的提示中的用户文本,以及模型返回的内容,然后据此判断这份响应内容是否通过某些准则。从内部机制看,评估器可以用任何适合其评估类型的方式实现。但如图 2.1 所示,评估器通常会**借助一个 LLM(通过 ChatClient)**来判断生成的响应与所提交提示之间的契合度。
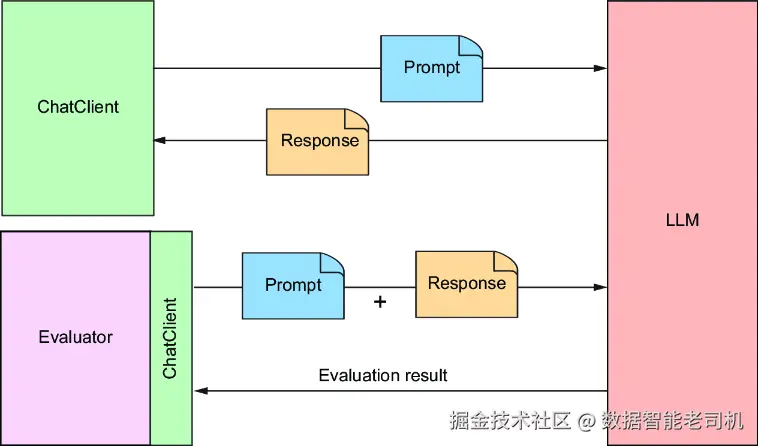
图 2.1 Spring AI 评估器把提示与生成的响应一并发送给 LLM,以评估响应质量。
接下来我们看看如何使用评估器,为 BoardGameService (Board Game Buddy 应用中使用生成式 AI 的那个组件)编写一份集成测试。
2.1 确保答案相关(Ensuring relevant answers)
最基础的评估形式,就是判断 LLM 是否回答了所提的问题 。也就是:生成的响应至少与提示同一话题吗?
例如,用户问 "Why is the sky blue?",LLM 回答 "Because of Rayleigh scattering"(或类似回答),那么这个答案是相关的 。反之,若 LLM 回答 "The moon is approximately 239,900 miles from Earth.",尽管它可能是正确事实,但与天空为何是蓝色 这一问题不相关。
判断答案是否与给定问题相关,正是 Spring AI 的 RelevancyEvaluator 要做的事。为了理解它如何工作,让我们用它来为 BoardGameService 写一个测试。下面的清单展示了该测试类。
清单 2.1 测试 LLM 的响应是否与问题相关
typescript
package com.example.boardgamebuddy;
import org.assertj.core.api.Assertions;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.evaluation.RelevancyEvaluator;
import org.springframework.ai.evaluation.EvaluationRequest;
import org.springframework.ai.evaluation.EvaluationResponse;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
public class SpringAiBoardGameServiceTests {
@Autowired
private BoardGameService boardGameService;
@Autowired
private ChatClient.Builder chatClientBuilder;
private RelevancyEvaluator relevancyEvaluator;
@BeforeEach
public void setup() {
this.relevancyEvaluator = new RelevancyEvaluator(chatClientBuilder);
}
@Test
public void evaluateRelevancy() {
String userText = "Why is the sky blue?";
Question question = new Question(userText);
Answer answer = boardGameService.askQuestion(question);
EvaluationRequest evaluationRequest = new EvaluationRequest(
userText, answer.answer());
EvaluationResponse response = relevancyEvaluator
.evaluate(evaluationRequest);
Assertions.assertThat(response.isPass())
.withFailMessage("""
========================================
The answer "%s"
is not considered relevant to the question
"%s".
========================================
""", answer.answer(), userText)
.isTrue();
}
}阅读 SpringAiBoardGameServiceTests 可以看到,测试前几行在做评估所需的准备 。类上标注了 @SpringBootTest,表明这是集成测试 :会创建一个 Spring 应用上下文(包含应用中的所有 bean)。从该上下文中,通过 @Autowired 注入了 BoardGameService 与 ChatClient.Builder。随后在 setup() 方法里,用 ChatClient.Builder 创建了一个 RelevancyEvaluator,以供测试方法使用。
evaluateRelevancy() 测试方法首先创建一个 Question,并将其发送给注入的 BoardGameService#askQuestion() 来获得 Answer。接着用原始用户文本与答案创建 EvaluationRequest,传给 RelevancyEvaluator#evaluate()。其内部会向 LLM 发送一个提示,要求它判断答案与问题的相关性。
evaluate() 返回 EvaluationResponse,随后调用 isPass() 判断评估是否通过。若返回 true,说明答案被认为与问题相关;否则返回 false,表示不相关,断言失败。
有了这个测试,你就能快速、自动 检查:通过 SpringAiBoardGameService#askQuestion() 提出的一个问题是否得到契合话题 的回答。当然,相关 并不等于正确 。我们再把测试提升一档,检查答案是否正确。
2.2 测试事实正确性(Testing for factual accuracy)
假设当被问到"天空为什么是蓝色"时,LLM 回答:"The sky is blue because there are a gazillion tiny bubbles filled with blueberry jam floating in the atmosphere."(天空之所以蓝,是因为大气中漂浮着无数装满蓝莓酱的小气泡。)这个回答看起来相关 ,但显然不正确 。它也许能"躲过" RelevancyEvaluator 的法眼,但并不适合直接展示给你的用户。
Spring AI 的 FactCheckingEvaluator 与 RelevancyEvaluator 类似,但它不是让 LLM 判断相关性 ,而是让 LLM 判断这个回答是否正确地回答了问题。
在把事实正确性测试加进 SpringAiBoardGameServiceTests 之前,需要稍微调整一下 setup() 方法,创建一个 FactCheckingEvaluator 并赋给实例变量:
typescript
private FactCheckingEvaluator factCheckingEvaluator;
@BeforeEach
public void setup() {
this.relevancyEvaluator = new RelevancyEvaluator(chatClientBuilder);
this.factCheckingEvaluator = new FactCheckingEvaluator(
chatClientBuilder);
}现在编写事实核查测试方法:
ini
@Test
public void evaluateFactualAccuracy() {
var userText = "Why is the sky blue?";
var question = new Question(userText);
var answer = boardGameService.askQuestion(question);
var evaluationRequest =
new EvaluationRequest(userText, answer.answer());
var response =
factCheckingEvaluator.evaluate(evaluationRequest);
Assertions.assertThat(response.isPass())
.withFailMessage("""
========================================
The answer "%s"
is not considered correct for the question
"%s".
========================================
""", answer.answer(), userText)
.isTrue();
}evaluateFactualAccuracy() 与之前的 evaluateRelevancy() 很相似。与相关性测试一样,仍然通过 EvaluationResponse#isPass() 进行断言:若生成的答案被判定为不正确,断言就会失败。
当 isPass() 返回 false 导致断言失败时,失败信息会解释原因。举例来说,如果生成的答案是 "There are tiny bubbles filled with blueberry jam high in the atmosphere.",那么 FactCheckingEvaluator 会判定该回答不正确,断言失败,输出的失败信息可能如下:
csharp
========================================
The answer "The sky is blue because there are a gazillion tiny bubbles filled
with blueberry jam floating in the atmosphere."
is not considered correct for the question
"Why is the sky blue?".
========================================在通读本书的过程中,你会对发送给 LLM 的提示 做出许多改动。借助 evaluateRelevancy() 与 evaluateFactualAccuracy() 这样的测试,你可以确保:无论提示如何调整 ,依然能获得恰当且正确的回答。
即便如此,还有一点可能不那么显而易见:你也许会希望在测试之外(运行时)使用评估器,以确保实际运行中返回给用户的回答同样相关 且正确 。接下来我们看看如何在应用代码中直接应用评估器。
2.3 在运行时应用自评估(Applying self-evaluation at runtime)
即使在构建应用时基于评估器的测试全部通过,运行时 仍可能出现不相关 或不正确 的回答。生成式 AI 的非确定性意味着:测试阶段也许"运气不错"拿到了好回答,但到生产环境时情况却可能"跑偏"。在运行时应用评估器,可以帮助避免把糟糕答案返回给应用用户。
事实证明,评估器并不限于 用于集成测试。下面的清单展示了如何把 RelevancyEvaluator 与 Spring Retry 结合,避免返回与用户问题不相关的答案。
清单 2.2 在运行时代码中校验相关性(Verifying relevancy in runtime code)
java
package com.example.boardgamebuddy;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.evaluation.RelevancyEvaluator;
import org.springframework.ai.chat.prompt.ChatOptions;
import org.springframework.ai.evaluation.EvaluationRequest;
import org.springframework.ai.evaluation.EvaluationResponse;
import org.springframework.retry.annotation.Recover;
import org.springframework.retry.annotation.Retryable;
import java.util.List;
@Service
public class SelfEvaluatingBoardGameService implements BoardGameService {
private final ChatClient chatClient;
private final RelevancyEvaluator evaluator;
public SelfEvaluatingBoardGameService(ChatClient.Builder chatClientBuilder) {
var chatOptions = ChatOptions.builder()
.model("gpt-4o-mini")
.build();
this.chatClient = chatClientBuilder
.defaultOptions(chatOptions)
.build();
this.evaluator = new RelevancyEvaluator(chatClientBuilder);
}
@Override
@Retryable(retryFor = AnswerNotRelevantException.class)
public Answer askQuestion(Question question) {
var answerText = chatClient.prompt()
.user(question.question())
.call()
.content();
evaluateRelevancy(question, answerText);
return new Answer(answerText);
}
@Recover
public Answer recover(AnswerNotRelevantException e) {
return new Answer("I'm sorry, I wasn't able to answer the question.");
}
private void evaluateRelevancy(Question question, String answerText) {
var evaluationRequest =
new EvaluationRequest(question.question(), answerText);
var evaluationResponse = evaluator.evaluate(evaluationRequest);
if (!evaluationResponse.isPass()) {
throw new AnswerNotRelevantException(question.question(), answerText);
}
}
}SelfEvaluatingBoardGameService 与 SpringAiBoardGameService 很相似,只是 askQuestion() 方法上添加了 @Retryable 注解。这个来自 Spring Retry 的注解表示:如果该方法抛出了 AnswerNotRelevantException,则重试该方法。
在 askQuestion() 中,会调用 evaluateRelevancy() 来进行相关性评估。evaluateRelevancy() 使用构造器里创建的 RelevancyEvaluator。若 isPass() 返回 false,evaluateRelevancy() 会抛出 AnswerNotRelevantException,该异常向外传播至 askQuestion(),从而触发重试。
至于 AnswerNotRelevantException,它是一个简单的非受检异常,类似如下:
scala
package com.example.boardgamebuddy;
public class AnswerNotRelevantException extends RuntimeException {
public AnswerNotRelevantException(String question, String answer) {
super("The answer '" + answer + "' is not relevant to the question '" + question + "'.");
}
}默认情况下,带有 @Retryable 的方法会最多重试三次 。你可以通过 maxAttempts 属性进行调整。例如,将重试上限设为 5 次:
python
@Retryable(retryFor = AnswerNotRelevantException.class, maxAttempts=5)尽管可以通过 maxAttempts 增加重试次数,但要注意:每次重试都意味着对 LLM 多发送一次提示,同时评估器也会反复向 LLM 发送评估提示。这会增加费用 (因为在得到相关答案前可能发送了更多 token),并且如果在短时间内连续发送同样的提示,也可能触发限流 。因此把 maxAttempts 设得较低可以避免这些问题。
如果在三次(或你通过 maxAttempts 指定的次数)尝试后仍未生成相关答案,控制流程会进入 recover() 方法。recover() 用 @Recover 注解标注,是 Spring Retry 提供的兜底 机制:当重试持续失败时调用。在 SelfEvaluatingBoardGameService 中,recover() 只是返回一个表示无法回答 的 Answer。
关于 Spring AI 的评估器,还有最后一点:虽然开箱即用的只有 RelevancyEvaluator 与 FactCheckingEvaluator,但它们都是基于 Spring AI 的如下 Evaluator 接口构建的:
java
package org.springframework.ai.evaluation;
import java.util.List;
import java.util.stream.Collectors;
import org.springframework.ai.document.Document;
import org.springframework.util.StringUtils;
@FunctionalInterface
public interface Evaluator {
EvaluationResponse evaluate(EvaluationRequest evaluationRequest);
default String doGetSupportingData(EvaluationRequest evaluationRequest) {
List<Document> data = evaluationRequest.getDataList();
return data.stream()
.map(Document::getText)
.filter(StringUtils::hasText)
.collect(Collectors.joining(System.lineSeparator()));
}
}若 RelevancyEvaluator 或 FactCheckingEvaluator 不能满足 你的评估需求,你可以实现 Evaluator 接口自定义评估器。
小结(Summary)
- 生成式 AI 的非确定性使测试变得棘手。
- Spring AI 提供评估器 ,可用于对生成的响应进行断言。
- 评估器通过向 LLM 发送提示,来判断响应的相关性 与事实正确性。
- 评估器可在运行时 应用;若返回不满意的结果,可以重试提示。