AI测试(含大模型)与普通测试的区别及实施方法
一、核心区别:从"确定性验证"到"概率性与场景化评估"
普通测试与AI测试(尤其是大模型测试)的本质差异,源于测试对象的"逻辑特性"不同------普通软件是"代码驱动的确定性系统",AI大模型是"数据驱动的概率性系统",具体差异可通过你提到的场景直观对比:
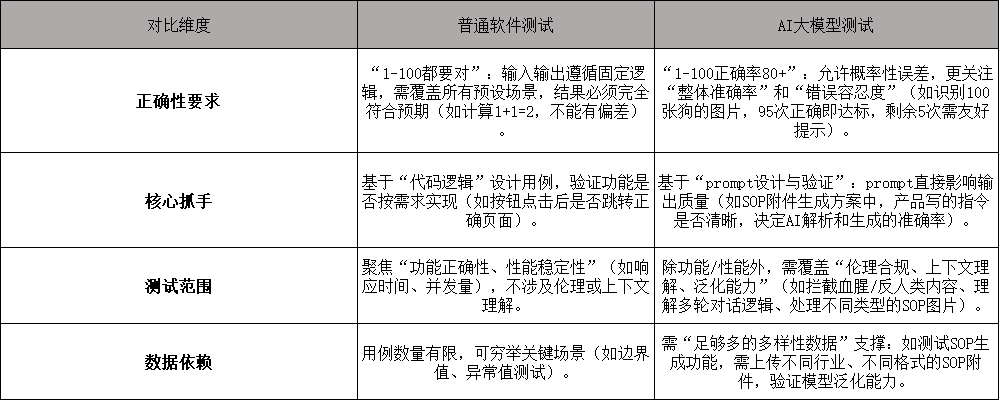

二、AI大模型测试的实施方法(结合你的工作场景)
以你参与的"上传SOP附件→AI自动生成方案"需求为例,AI测试的核心流程和测试点如下:
- 核心测试流程(基于工具链实操)
- 工具与工作流搭建:通过dify构建agent,配置"上传附件→prompt指令→AI解析→生成结果→返回业务方"的工作流(这是AI测试的前置基础,需确认工作流逻辑无漏洞)。
- prompt有效性验证:产品编写prompt后,测试需验证指令的"清晰度"和"业务贴合度"(如prompt是否明确"解析SOP的核心要素(目标、步骤、责任人)→按业务方常用格式生成方案",直接影响输出准确率)。
- 多场景数据测试:上传不同类型的SOP(如制造业生产SOP、互联网运营SOP;图片/文档格式),观察AI解析是否完整、生成的方案是否符合业务逻辑。
- 关键测试点(聚焦"效果+稳定性")
- 功能效果测试:生成的方案是否覆盖SOP核心信息?格式是否符合业务方要求?(如业务方需要"分点式方案",AI是否避免生成大段文字)。
- 性能与稳定性测试:模型响应速度是否在可接受范围(如上传10MB附件,生成方案耗时≤10秒)?高并发下是否崩掉(如同时上传5个附件,是否出现超时或结果丢失)?
- 异常与伦理测试:上传非SOP附件(如图片、空白文档),AI是否友好提示"无法解析"?上传含敏感内容的SOP(如违规操作步骤),模型是否拦截或警示?
三、例子






四、总结:AI测试的核心能力要求
bash
与普通测试相比,AI测试更需要"业务+工具+场景思维":
1. 懂业务:能理解SOP等需求的业务逻辑,才能判断AI生成结果是否合理;
2. 会用工具:熟悉dify等AI平台的工作流配置,能定位"工具-模型-数据"链路中的问题;
3. 场景化测试:不局限于"功能对不对",更关注"不同场景下模型表现好不好、安不安全"。