目录
[一、AI 绘画爱好者的两大"痛点":硬件与时间](#一、AI 绘画爱好者的两大“痛点”:硬件与时间)
[二、Z-Image-Turbo 是什么?一场"以小博大"的技术突围](#二、Z-Image-Turbo 是什么?一场“以小博大”的技术突围)
[四、Z-Image 的现实意义:AI 绘画的"工业革命"](#四、Z-Image 的现实意义:AI 绘画的“工业革命”)

🎬 攻城狮7号 :个人主页
🔥 个人专栏 :《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 阿里开源 Z-Image
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
近年来,AI 绘画技术经历了一场"军备竞赛",模型参数从数亿一路狂飙至数百亿,画质也随之达到了令人惊叹的高度。但在这场竞赛的背后,是普通用户日益增长的"显存焦虑"和"等待之痛"。一个强大的模型,往往意味着一块昂贵的显卡和一段漫长的出图时间。阿里通义开源的 Z-Image,正是对这一趋势的一次"逆行",它向我们证明:顶级的图像质量,并不一定需要顶级的硬件门槛。
一、AI 绘画爱好者的两大"痛点":硬件与时间
对于每一个热衷于在本地部署和运行 AI 绘画模型的玩家来说,都或多或少经历过两种困扰:
(1)硬件门槛下的"显存焦虑"
随着 Stable Diffusion XL 等新一代模型的普及,AI 绘画对显存(VRAM)的要求水涨船高。12GB 显存逐渐成为"入门级",而 24GB 的旗舰显卡(如 RTX 4090)似乎才能让人获得真正的"创作自由"。这道由硬件构筑的高墙,将无数持有 8GB 或 12GB 主流显卡的用户挡在了门外,让他们只能"望洋兴叹",或者忍受各种降速优化。
(2)创作流程中的"等待之痛"
即便你拥有顶级的硬件,创作过程也难言"丝滑"。点击"生成"按钮后,等待几十秒甚至几分钟才能看到结果,是家常便饭。这种延迟,极大地破坏了创作的"心流"。它让 AI 绘画的过程更像是"开盲盒"或"抽卡",你投入一个想法,然后只能被动地等待结果,而无法进行实时的、交互式的调整。灵感在等待中消磨,创意也因此大打折扣。
长期以来,速度、质量、资源占用这三者,似乎构成了一个难以调和的"不可能三角"。想要高质量?那就得牺牲速度和资源。想要速度快?那画质可能就得妥协。而 Z-Image-Turbo 的出现,正是为了挑战这个定律。

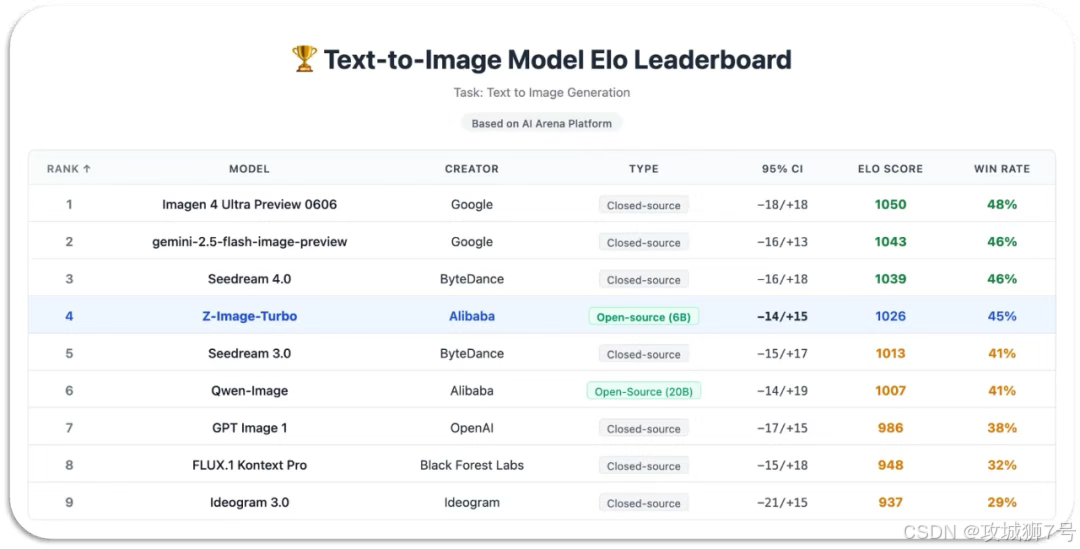
二、Z-Image-Turbo 是什么?一场"以小博大"的技术突围
Z-Image-Turbo 是阿里通义团队推出的一个仅有 60 亿(6B)参数的图像生成模型。它没有参与"百亿参数俱乐部"的竞赛,而是另辟蹊径,致力于在有限的资源下,实现效率与质量的极致平衡。

根据官方公布的信息和社区的实际测试,Z-Image-Turbo 的核心竞争力可以概括为以下几点:
(1)1. 6B 参数:终结显存焦虑
相比动辄上百亿参数的"庞然大物",6B 的体量显得极为轻巧。这意味着它对硬件的需求大幅降低。根据官方信息,模型能在 16G 显存下流畅运行,甚至在 8G 或 12G 显存的消费级显卡上也能部署使用。这无疑为广大主流用户打开了通往高质量 AI 绘画的大门。
(2)1 秒出图:从"等待"到"实时"的革命
Z-Image-Turbo 实现了亚秒级的推理速度。在合适的硬件上,生成一张高质量图像仅需约 1 秒。这带来的体验是颠覆性的。创作者的思维不再被打断,你的每一个想法、每一次对提示词的微调,几乎都能瞬时在屏幕上看到反馈。AI 绘画从此告别了"抽卡"模式,真正进入了"实时交互"的时代。
(3)照片级真实感:质量不妥协
通常,模型的轻量化和高速化,往往伴随着画质的牺牲。但 Z-Image-Turbo 在这一点上表现出了惊人的实力。它生成的图像,尤其在人物写真方面,达到了"照片级"的真实感。无论是皮肤的纹理、发丝的细节,还是复杂环境光下的光影反射,都处理得相当到位。
更重要的是,它拥有丰富的"世界知识"。这意味着模型本身就认识许多名人、理解各种文化概念,并且对亚洲人脸的生成效果尤为出色。在很多场景下,用户不再需要像过去一样,为了生成特定人物或风格而费力地寻找和加载一堆 LoRA 模型。Z-Image 的"底模"本身,就像一部小型的百科全书。

(4)精准的双语文本渲染:攻克行业"顽疾"
在图像中准确地生成文字,一直是 AI 绘画领域的一大难题,尤其是对于结构复杂的汉字。许多顶级模型在面对包含文字的提示词时,常常生成不知所云的"鬼画符"。Z-Image-Turbo 在这一点上取得了重大突破,它能够精准、清晰地渲染中英文文本,无论是招牌上的店名,还是海报上的段落,都能做到高保真输出。


三、背后是什么"黑科技"?效率的艺术
Z-Image-Turbo "以小博大"的成功,并非偶然,而是源于其在模型架构和训练策略上的深度优化。
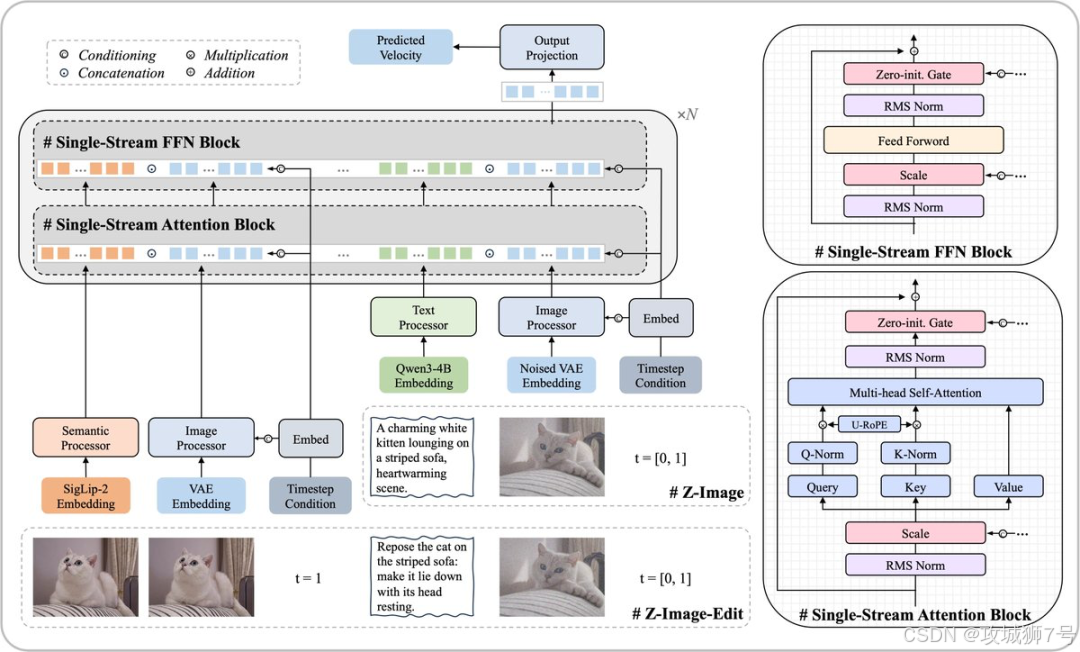
(1)更高效的 S3-DiT 架构
传统的一些图像生成模型采用"双流"架构,即文本信息和图像信息在两条独立的通道中处理,最后再进行融合。而 Z-Image 采用了一种名为 S3-DiT(可扩展的单流数字图像处理)的架构。它巧妙地将文本、视觉语义和图像本身的特征,在序列层面就连接成一个统一的输入流。这种"单流"设计,最大限度地提升了参数的利用效率,让文本和图像信息在模型的每一层都能进行更充分的交互,从而用更少的参数实现了更强的效果。
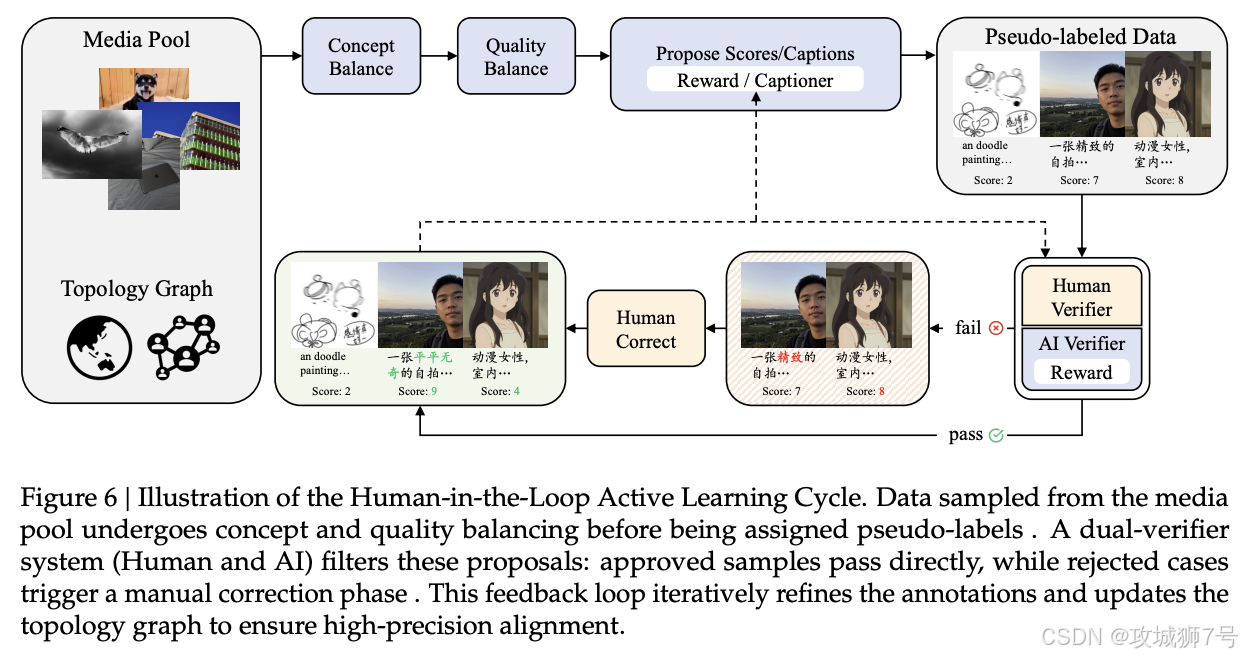
(2)算法优化与数据蒸馏
为了将模型压缩至 6B,团队采用了多种先进技术。例如,通过数据蒸馏 ,让这个小模型去学习一个更强大的大模型的"精华",相当于老师给学生划重点;通过优化模型结构,如采用更高效的注意力机制,来减少冗余的计算,确保每一份算力都花在刀刃上。
(3)8 步出图的"快速收敛"能力
传统扩散模型通常需要 20-50 步的"去噪"过程才能生成一张清晰的图像。Z-Image-Turbo 仅需 8 步左右就能"收敛"到高质量结果。这并非魔术,而是得益于其高效的训练方法和优化的预训练模型。模型在训练中,就学会了用最快的路径找到通往高质量图像的"捷径",从而在推理时大幅缩短了迭代步数。
四、Z-Image 的现实意义:AI 绘画的"工业革命"
Z-Image-Turbo 的开源,其意义远不止于为社区增添了一个新选择。
**(1)创作门槛的"民主化":**它让高质量的 AI 图像生成技术,真正"飞入寻常百姓家"。独立设计师、小型工作室、内容创作者和广大学生、爱好者,不再需要为昂贵的硬件而烦恼,就能享受到最前沿的 AI 创作工具。
**(2)催生新的应用场景:**1 秒出图的实时性,为许多过去难以想象的应用打开了大门。例如,在直播中根据观众的评论实时生成互动画面;在游戏中动态生成符合玩家选择的场景和角色;在设计软件中,让设计师的想法实时转化为可见的原型。
**(3)推动开源生态的繁荣:**作为一个强大、高效且友好的基础模型,Z-Image 无疑会成为开源社区二次创新的绝佳土壤。我们可以预见,未来将有大量的风格化模型、ControlNet 控制插件和创新应用会基于 Z-Image 构建起来,进一步丰富整个 AI 绘画的生态。
结论
Z-Image-Turbo 的出现,是对当前 AI 绘画领域"唯大模型论"的一次有力回应。它雄辩地证明了,通过精巧的架构设计、高效的训练策略和深度的工程优化,"小模型"同样可以爆发出巨大的能量。
它不仅解决了困扰广大用户的核心痛点,更重要的是,它代表了一种趋势------AI 技术正在从追求极限性能的"实验室"阶段,走向注重效率、成本和普适性的"工业化"阶段。当最先进的生产力工具不再是少数人的专属,而是能够被大众轻易掌握时,一个真正由 AI 驱动的创意大爆发时代,或许才刚刚开始。
项目地址
开源仓库:https://github.com/QwenLM/Qwen-Image
技术论文:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/Qwen_Image.pdf
在线体验:https://huggingface.co/spaces/Qwen/Qwen-Image
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!