本文讲解redis的数据结构底层机制。
我们学习 java 集合 HashMap 时,我们都知道其底层原理是 数组 + 哈希索引 + 链表/红黑树 ,由这些技术实现了 HashMap , 我们把一个集合进行分解,从微观上学习每个组成部分,和学习每个组成部分之间是如何协调工作的,这个过程叫做底层原理的学习。
我们上文学习了的九种数据结构,其实这九种数据结构就像是对外暴露的接口,让外部便捷的操作 redis。上文讲述的数据结构都是封装好的东西,本文我们要扒开这些封装好的东西,看一看 string ,list 等结构底层是由什么组成,内部之间如何协调工作,探索 redis 性能强悍的奥秘。
引入:从哪里开始学习底层?
我在整理Redis底层设计时,发现网上其实是有很多资料的,但是缺少一种自上而下的承接。这里我将收集很多网上的资料并重新组织,来帮助你更好的理解Redis底层设计。
首先看下图:
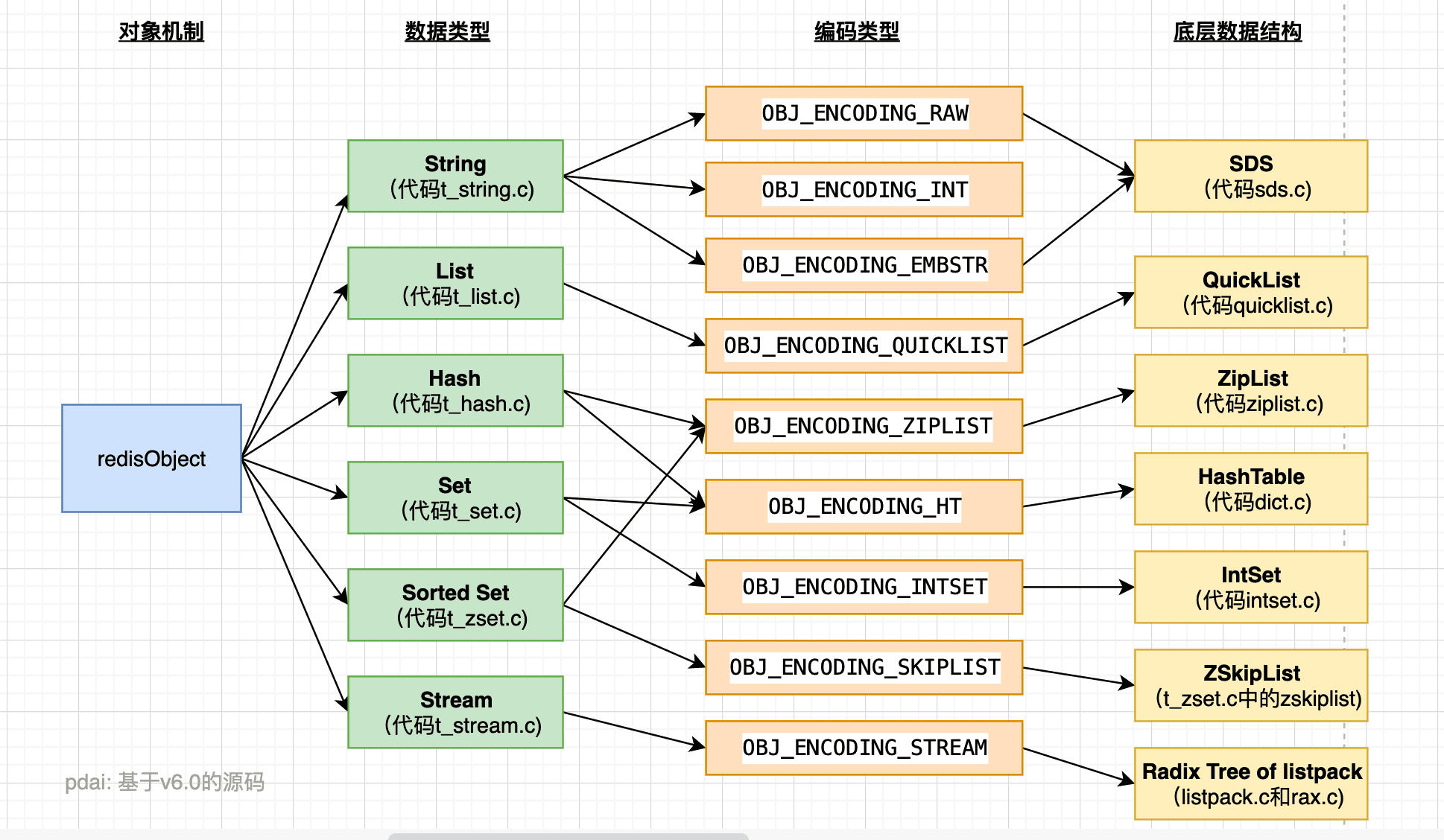
它反映了Redis的每种对象其实都由对象结构(redisObject) 与 对应编码的数据结构组合而成,而每种对象类型对应若干编码方式,不同的编码方式所对应的底层数据结构是不同的。
比如:string 用了OBJ_ENCODING_RAW 编码方式,那么它的底层结构一定是 SDS .
所以,我们需要从几个个角度来着手底层研究:
- 对象设计机制: 对象结构(redisObject)
- 编码类型和底层数据结构: 对应编码的数据结构
redisObject数据结构和意义
redisObject 数据结构如下:
c
/*
* Redis 对象
*/
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码方式
unsigned encoding:4;
// LRU - 24位, 记录最末一次访问时间(相对于lru_clock); 或者 LFU(最少使用的数据:8位频率,16位访问时间)
unsigned lru:LRU_BITS; // LRU_BITS: 24
// 引用计数
int refcount;
// 指向底层数据结构实例
void *ptr;
} robj;图对应上面的结构
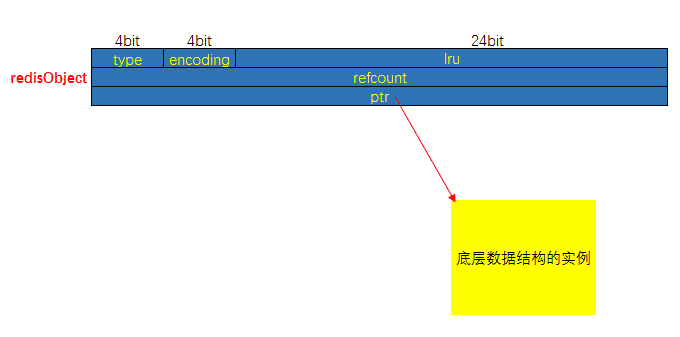
其中type、encoding和ptr是最重要的三个属性。
- type记录了对象所保存的值的类型,它的值可能是以下常量中的一个:
bash
/*
* 对象类型
*/
#define OBJ_STRING 0 // 字符串
#define OBJ_LIST 1 // 列表
#define OBJ_SET 2 // 集合
#define OBJ_ZSET 3 // 有序集
#define OBJ_HASH 4 // 哈希表- encoding记录了对象所保存的值的编码,它的值可能是以下常量中的一个:
bash
/*
* 对象编码
*/
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* 注意:版本2.6后不再使用. */
#define OBJ_ENCODING_LINKEDLIST 4 /* 注意:不再使用了,旧版本2.x中String的底层之一. */
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */- ptr是一个指针,指向实际保存值的数据结构 ,这个数据结构由type和encoding属性决定。举个例子, 如果一个redisObject 的type 属性为
OBJ_LIST, encoding 属性为OBJ_ENCODING_QUICKLIST,那么这个对象就是一个Redis 列表(List),它的值保存在一个QuickList的数据结构内,而ptr 指针就指向quicklist的对象; - lru属性: 记录了对象最后一次被命令程序访问的时间
- 空转时长:当前时间减去键的值对象的lru时间,就是该键的空转时长。Object idletime命令可以打印出给定键的空转时长
重新思考:原来redis中没有 string 等数据结构, 有的仅仅是 redisObject 数据结构,所谓的 string 数据结构是逻辑上的概念,并非真实的代码,string 逻辑概念通过 redisObject 的 type 属性,加上 encoding 与 ptr 指针实现了所谓的 string 类型。
所有数据类型的差异,只存在于 type、encoding、ptr 的组合 !
这便是RedisObject的意义,通过 type 、encodign 和 ptr 实现了逻辑上的五个基本数据结构。
(特殊的数据结构没有深入探索)
命令的类型检查和多态
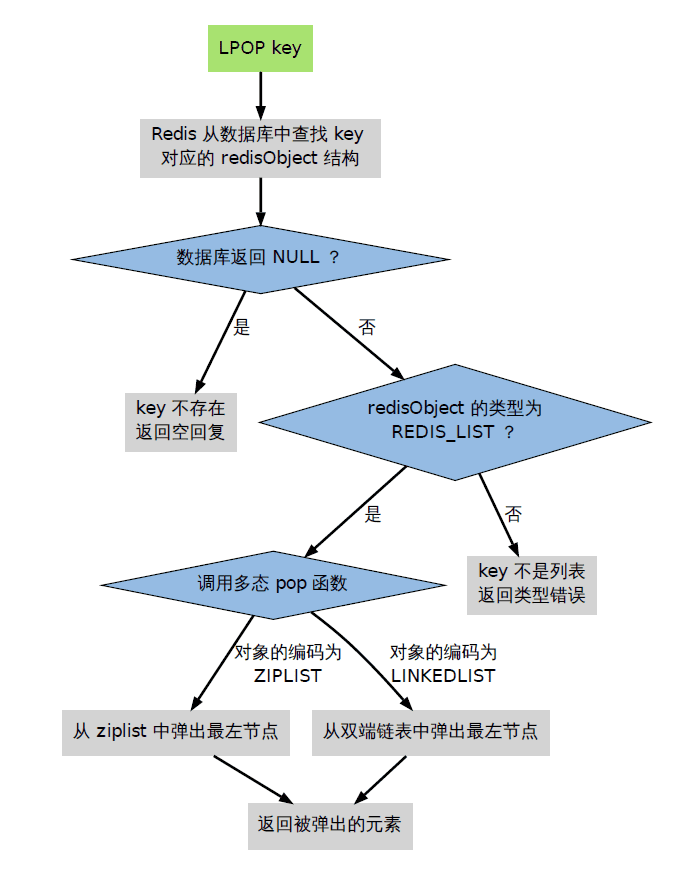
那么Redis是如何处理一条命令的呢?
当执行一个处理数据类型命令的时候,redis执行以下步骤
- 根据给定的key,在数据库字典中查找和他相对应的redisObject,如果没找到,就返回NULL;
- 检查redisObject的type属性和执行命令所需的类型是否相符,如果不相符,返回类型错误;
- 根据redisObject的encoding属性所指定的编码,选择合适的操作函数来处理底层的数据结构;
- 返回数据结构的操作结果作为命令的返回值。
比如现在执行LPOP命令:
对象共享
redis一般会把一些常见的值放到一个 全局共享池 (类似于JVM 字符串常量池),这样可使程序避免了重复分配的麻烦,也节约了一些CPU时间。
原理: Redis 共享对象就是让多个 RedisObject 的 ptr 指向同一个底层容器(SDS 或其他结构),从而实现对象复用和节省内存。
共享对象的典型场景:
- 整数(Integer objects)
-
- Redis 内部维护了一组共享对象
shared.integers - 范围通常是
-10000 ~ 10000(可配置) - 当你 SET
"123"时,如果是整数且在共享范围内,Redis 直接复用这个对象,不会创建新的 RedisObject
- Redis 内部维护了一组共享对象
- 小字符串(Commonly used small strings)
-
- 如
"OK","PONG","QUEUED"等 Redis 内部常用响应字符串 - 使用共享对象,避免重复分配
- 如
为什么redis不共享列表对象、哈希对象、集合对象、有序集合对象,只共享字符串对象?
- 列表对象、哈希对象、集合对象、有序集合对象,本身可以包含字符串对象,复杂度较高。
- 如果共享对象是保存字符串对象,那么验证操作的复杂度为O(1)
- 如果共享对象是保存字符串值的字符串对象,那么验证操作的复杂度为O(N)
- 如果共享对象是包含多个值的对象,其中值本身又是字符串对象,即其它对象中嵌套了字符串对象,比如列表对象、哈希对象,那么验证操作的复杂度将会是O(N的平方)
如果对复杂度较高的对象创建共享对象,需要消耗很大的CPU,用这种消耗去换取内存空间,是不合适的
RedisObject 对象引用计数
redisObject中 有 refcount 属性,是对象的引用计数,显然计数0那么就是可以回收。
- 每个redisObject结构都带有一个refcount属性,指示这个对象被引用了多少次;
- 当新创建一个对象时,它的refcount属性被设置为1;
- 当对一个对象进行共享时,redis将这个对象的refcount加一;
- 当使用完一个对象后,或者消除对一个对象的引用之后,程序将对象的refcount减一;
- 当对象的refcount降至0 时,这个RedisObject结构,以及它引用的数据结构的内存都会被释放。
有点像java对象回收机制, 没有对象引用的内存会被gc回收,不同的是JVM的gc触发根据年轻代/老年代内存压力动态触发,而 redis 是没有条件,立即触发回收。