一、备份
数据库备份的作用
数据库备份是数据管理与维护的关键环节,具体作用有:
- 数据恢复:当出现硬件故障、软件错误、数据损坏或人为失误时,可通过备份快速恢复数据,减少业务中断的影响。
- 灾难恢复:遭遇火灾、洪水、地震等自然灾害或其他灾难性事件时,备份能确保数据不丢失。
- 数据完整性:定期备份有助于维持数据的完整性和一致性,保障数据的准确性与可靠性。
- 数据迁移:在系统升级或迁移到新数据库平台时,备份可助力数据平滑过渡。
- 审计和报告:备份可用于审计,提供历史数据供分析和报告使用。
- 测试和开发:可利用备份创建开发和测试环境,无需复制整个生产数据库。
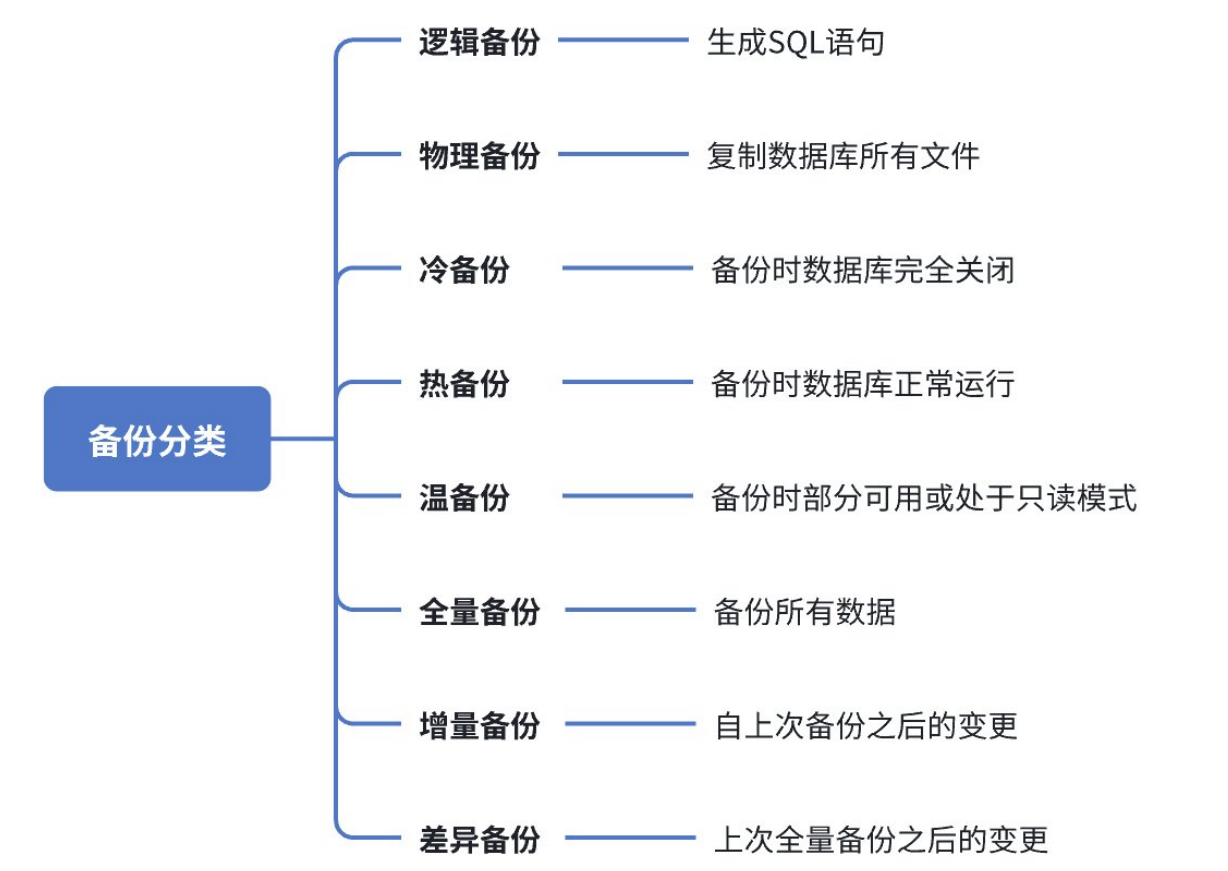
二、分类
数据库备份主要分为:逻辑备份,物理备份,冷备份,热备份,温备份,全量备份,增量备份,差异备份等
逻辑备份
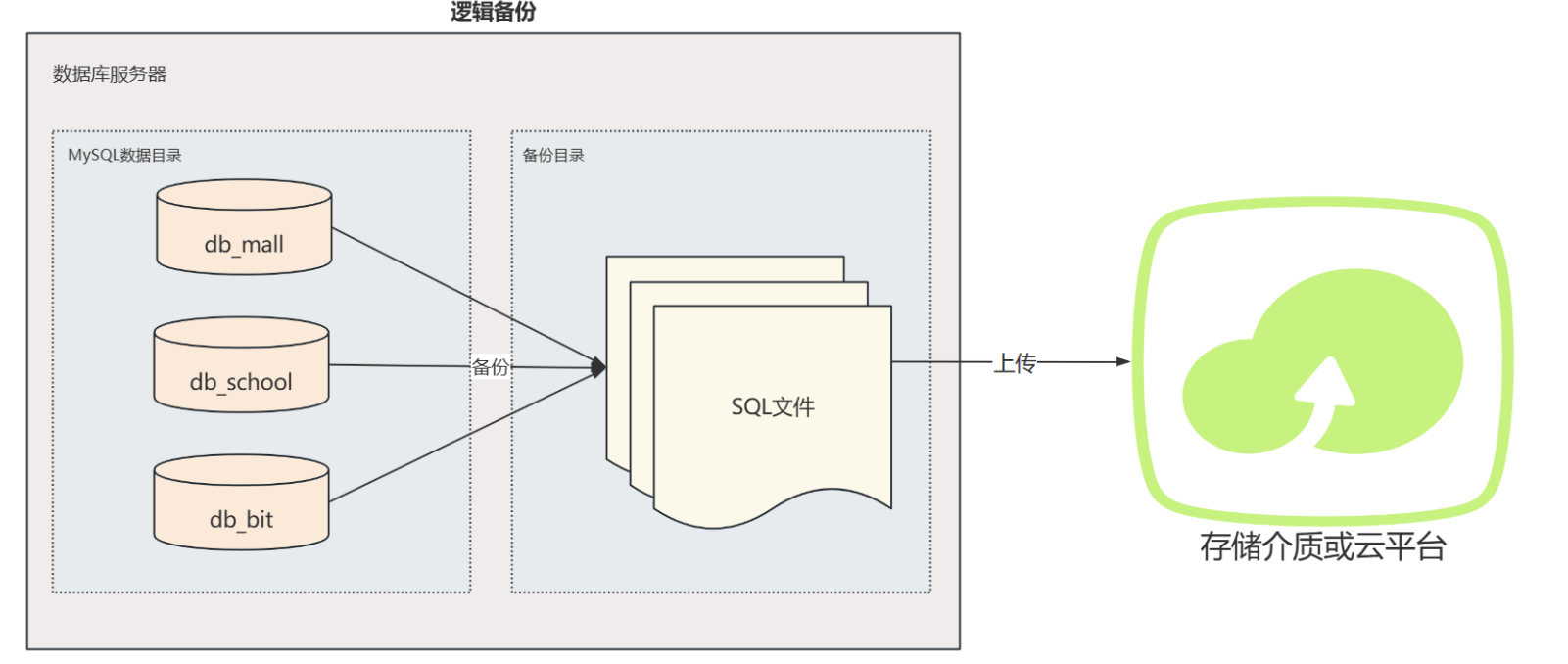
- 定义:逻辑备份指的是备份数据库的逻辑结构和数据,通常是通过导出数据库中的数据和对象(如表结构、视图、存储过程等)来实现的。生成的是数据库可以识别的格式,如 SQL 语句。
- 特点 :
- 备份文件中包含 SQL 语句,稍加修改就可以在不同的数据库系统上执行。
- 可以备份整个数据库或特定的数据库对象。
- 备份和恢复的速度比物理备份慢
物理备份
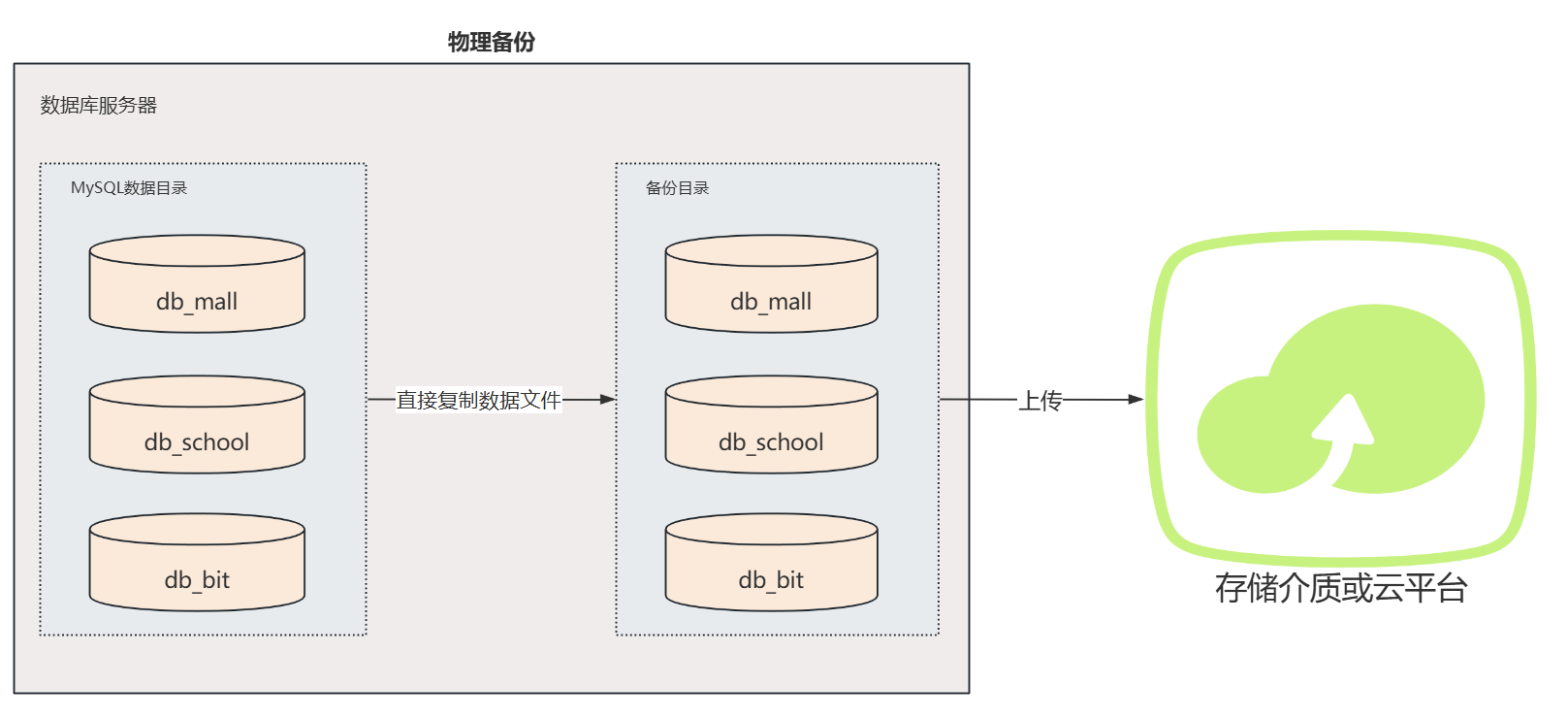
- 定义:物理备份是指直接复制数据库文件,包括数据文件、日志文件等。这种备份方式不涉及数据库的逻辑结构,而是直接在文件系统层面上复制数据库的存储结构。
- 特点 :
- 备份文件是数据库文件的复本,不包含 SQL 语句。
- 通常不能跨数据库厂商进行备份与恢复,比如 MySQL 的备份不能在 Oracle 中恢复。
- 可以非常快速地备份和恢复大型数据库,因为不需要解析 SQL 语句,直接复制文件即可。
| 对比维度 | 物理备份 | 逻辑备份 |
|---|---|---|
| 备份核心内容 | 数据库底层数据文件(如数据文件、日志文件、索引文件等) | 重建数据的 SQL 指令(如 CREATE TABLE、INSERT INTO 等) |
| 备份本质 | 复制文件系统层面的存储文件 | 导出数据库逻辑结构和数据的文本指令 |
| 恢复方式 | 直接将备份文件放回原路径,数据库启动后即可读取 | 执行备份的 SQL 语句,重新生成数据文件和数据 |
| 跨平台兼容性 | 差,通常不能跨数据库厂商使用(如 MySQL 备份无法在 Oracle 恢复) | 好,SQL 语句可修改适配不同数据库系统 |
| 备份 / 恢复速度 | 快,直接复制文件,无需解析指令 | 慢,需导出 / 执行 SQL,数据量越大速度越慢 |
| 备份灵活性 | 一般只能全量备份(或按文件级拆分) | 可灵活备份单个表、视图等特定对象 |
| 存储占用 | 与数据库实际文件大小相当,占用空间较大 | 仅存储 SQL 指令,占用空间相对较小 |
- 执行的 SQL 指令(建表、插入数据等),数据库执行后会直接转化为数据文件(比如表结构、实际数据),不会单独保存这些原始 SQL。
- 逻辑备份是 "主动导出" SQL 指令,比如用 mysqldump 工具,它会扫描数据库的结构和数据,反向生成对应的 CREATE、INSERT 等 SQL,再保存成备份文件。
- 逻辑备份:备份的是 "重建数据的 SQL 指令"(比如 CREATE TABLE、INSERT INTO),恢复时需要重新执行这些 SQL 来生成数据文件。
- 物理备份:备份的是 "SQL 执行后的结果文件",恢复时直接把文件放回原位,数据库启动后就能直接读取,不用再执行 SQL。
冷备份
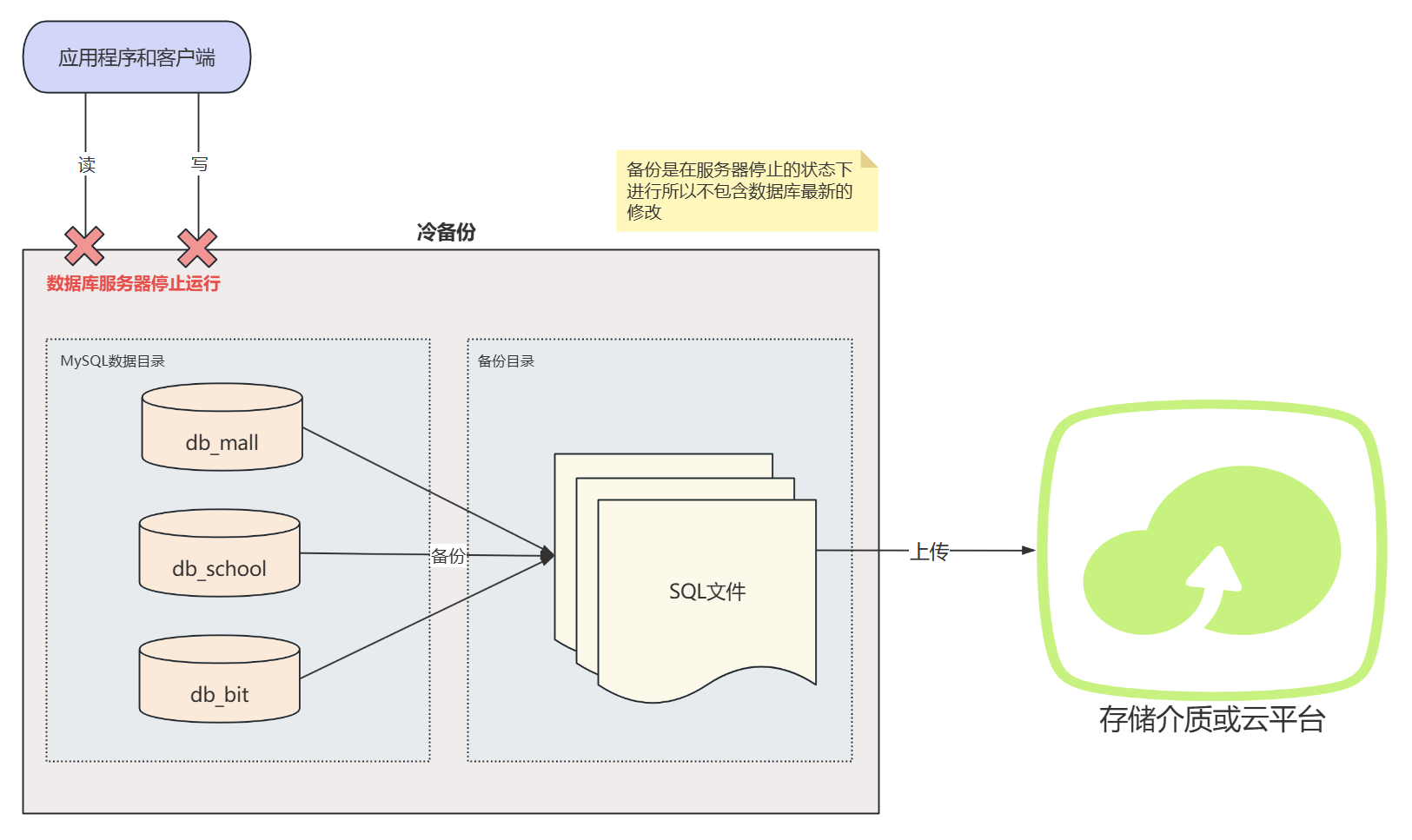
- 定义:冷备份是指在数据库完全关闭的情况下进行的备份。在备份过程中,数据库服务不可用。
- 特点 :
- 简单易行,因为不需要考虑数据一致性问题。
- 备份过程中不会对数据库性能产生影响。
- 备份窗口期间数据库不可用,可能影响业务连续性。
热备份
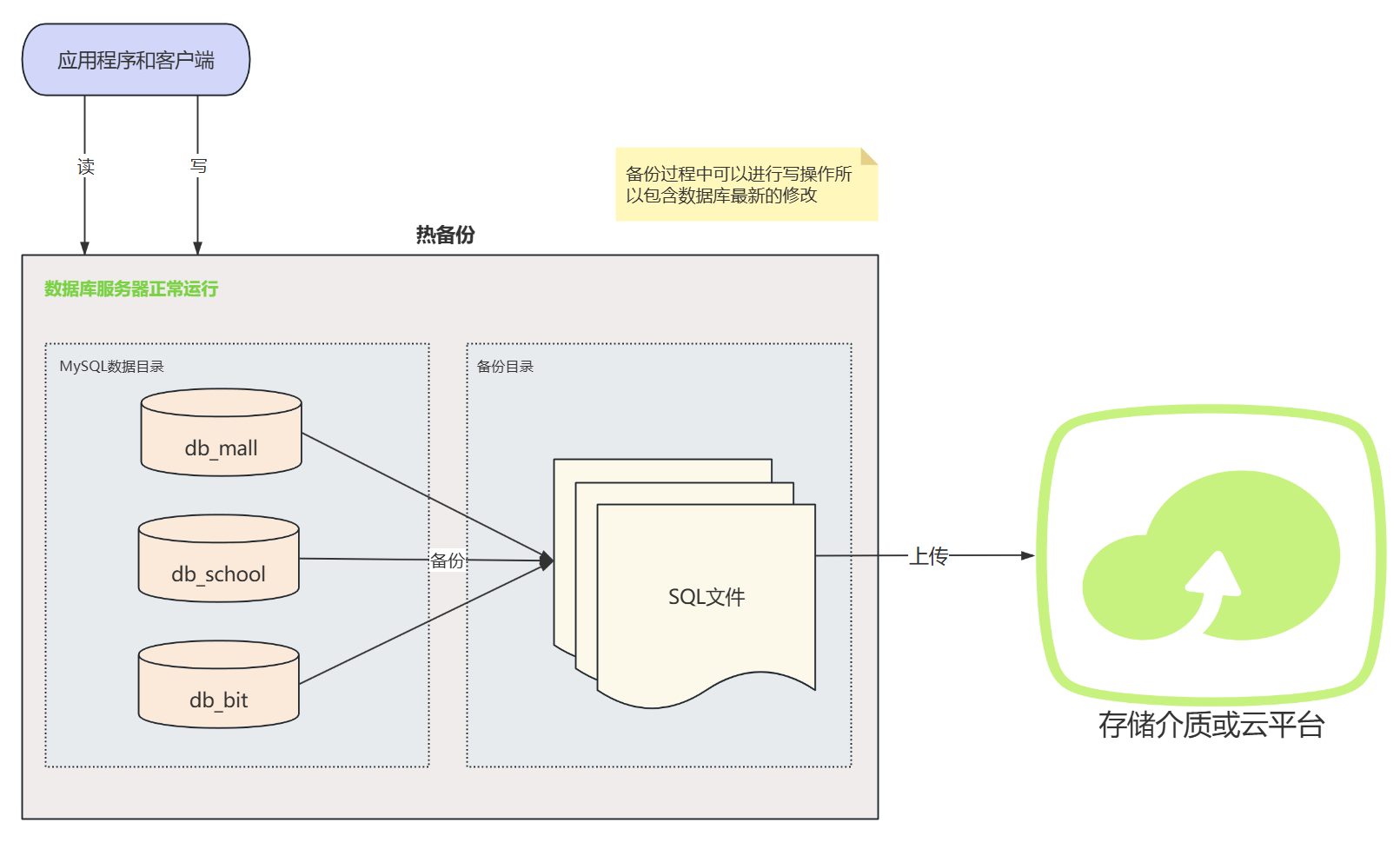
- 定义:热备份是指在数据库正常运行的情况下进行的备份,备份过程中数据库服务仍然可用。
- 特点 :
- 可以在数据库运行时进行备份,所以备份的数据是系统当前最新的。
- 不需要停止数据库服务,对业务影响最小。
- 在高负载情况下,可能会对数据库性能产生一定影响
- 技术实现复杂,需要考虑数据一致性和并发控制。
温备份
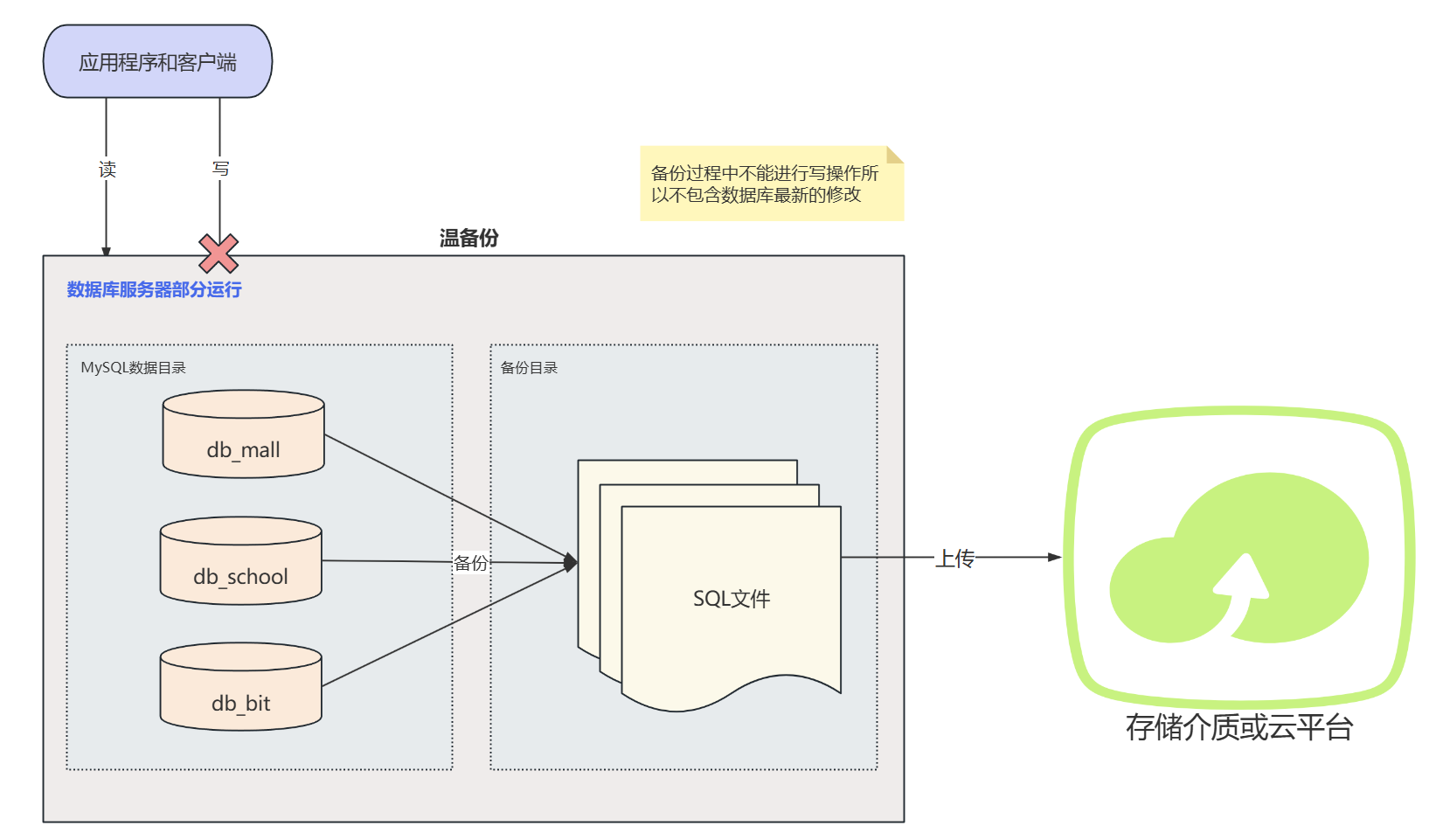
- 定义:温备份是介于冷备份和热备份之间的一种备份方式,数据库在备份过程中部分可用或处于只读模式。
- 特点 :
- 可以在数据库运行时进行备份,减少业务中断时间。
- 需要数据库支持部分备份功能,如只读模式。
- 相对于热备份,技术实现简单一些,因为不需要处理所有的并发写入操作。

全量备份
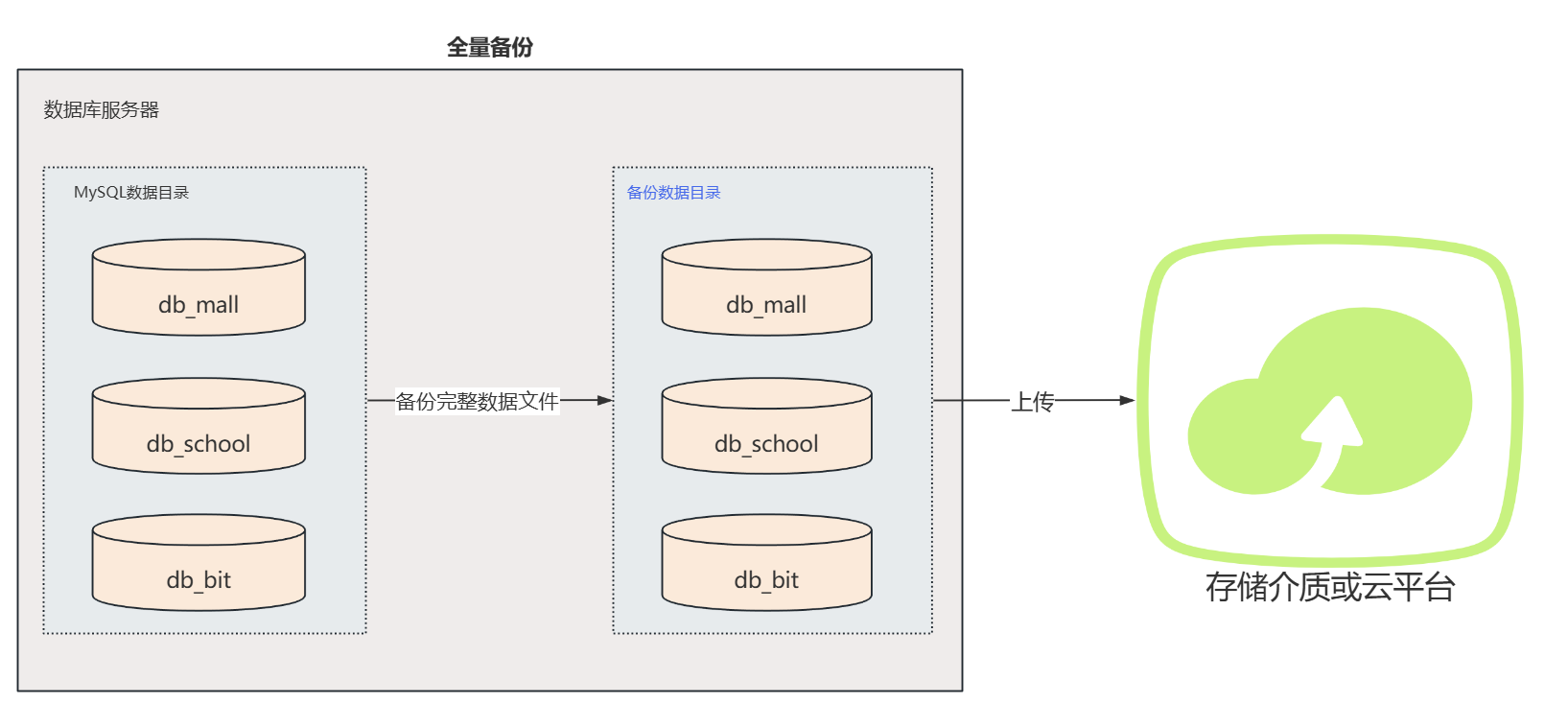
- 定义:全量备份是指备份整个数据库或文件系统的所有数据,包括所有的文件、数据库表、配置文件等。它不依赖于其他备份,可以独立恢复数据。
- 特点 :
- 恢复简单,一个全量备份就可以恢复所有数据。
- 易于理解和管理。
- 备份时间较长,因为需要备份所有数据。
- 占用的存储空间较大。
- 如果数据量很大,可能会影响业务系统的性能。
增量备份
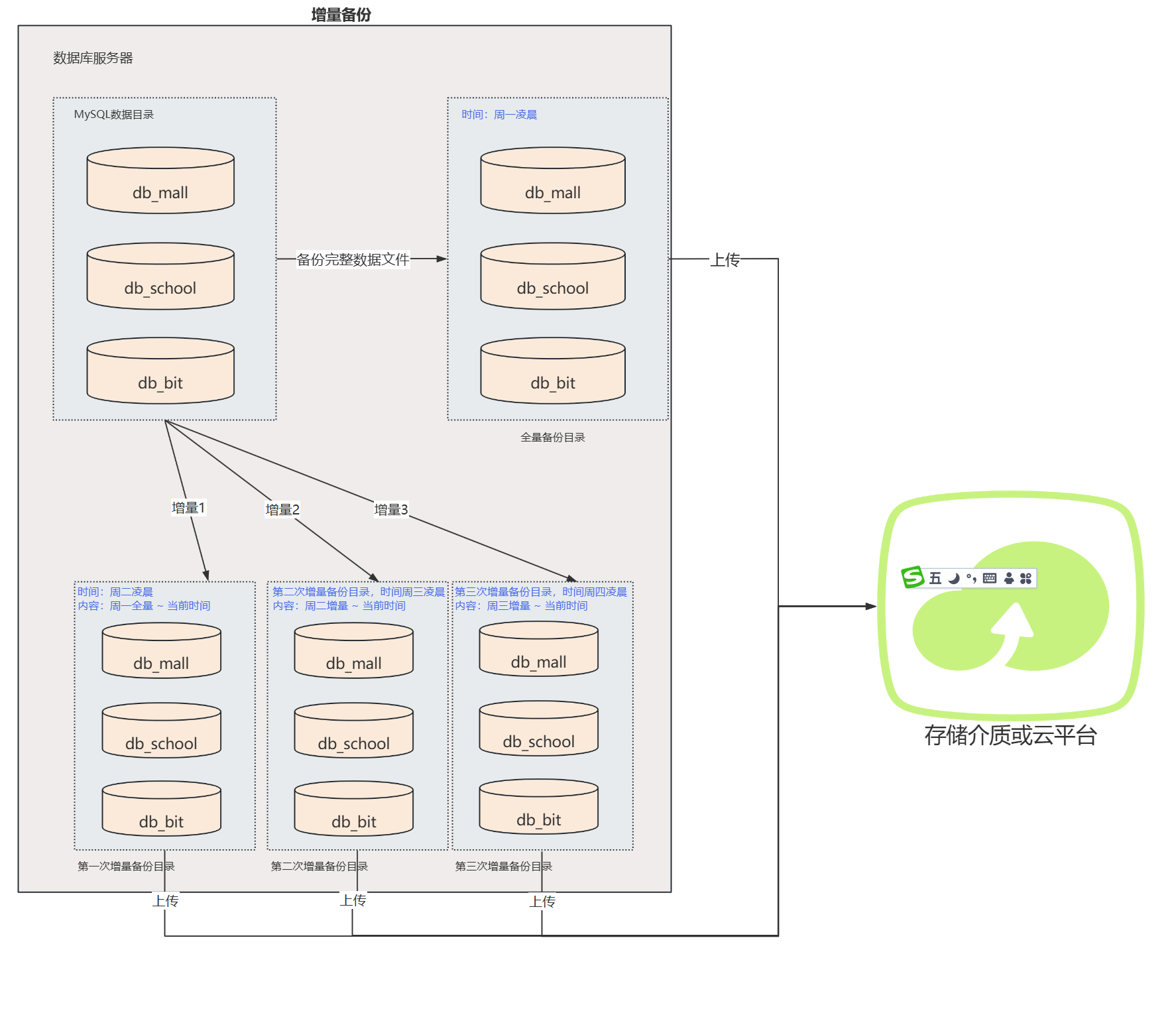
- 定义:增量备份是指只备份自上次备份以来发生变化的数据。可以是上次全量备份以后,也可以是上次增量备份以后。
- 特点 :
- 备份速度快,只需要备份变化的数据。
- 占用的存储空间较小。
- 可以节省时间和资源,特别是对于大型数据库或文件系统。
- 恢复复杂,需要多个备份文件
- 管理较为复杂,需要跟踪多个备份文件。
差异备份
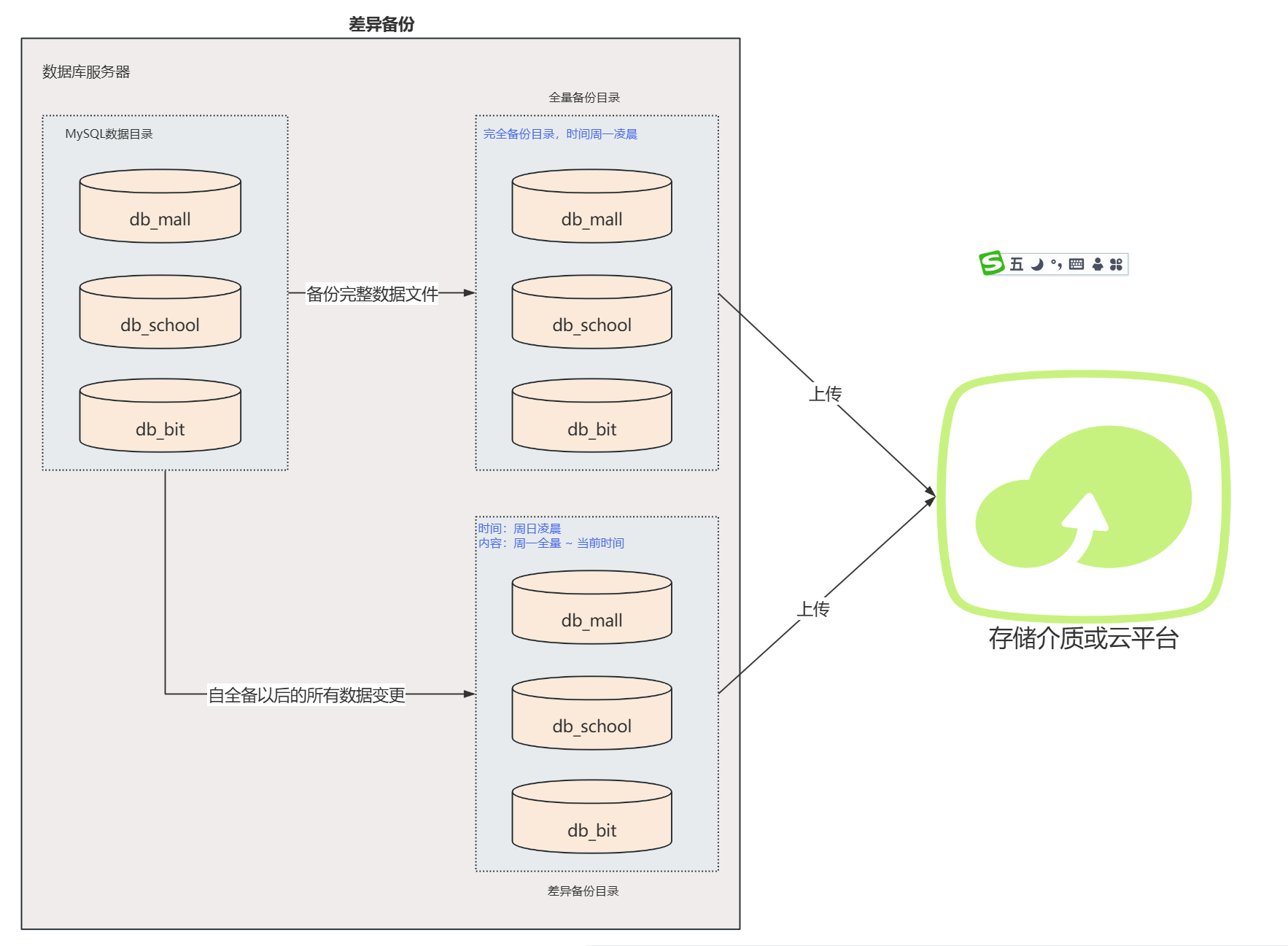
- 定义:差异备份是指只备份自上次全量备份以来所有变化的数据。
- 优点 :
- 恢复速度比增量备份快,只需要最后一次全量备份和最后一次差异备份。
- 管理相对简单。
- 随着时间的推移,备份的数据量可能会增加,导致备份时间变长和存储空间需求增加。

| 对比项 | 增量备份 | 差异备份 |
|---|---|---|
| 备份基准 | 上一次任意备份(全量 / 增量 / 差异) | 最近一次全量备份 |
| 备份速度 | 最快(仅备份最新变更) | 中等(备份全量后所有变更) |
| 存储占用 | 最小 | 中等(随时间推移逐渐增大) |
| 恢复复杂度 | 最高(需全量 + 所有增量备份) | 较低(仅需全量 + 最新差异备份) |
| 数据安全性 | 较低(某一增量备份损坏则后续失效) | 较高(仅依赖全量和最新差异) |
- 增量备份的 "改动":是 "上一次备份后" 的增量(可能是全量、增量或差异之后),范围 "窄而新"。
- 差异备份的 "改动":是 "上次全量后" 的所有累积改动,范围 "随时间扩大",但永远不包含全量本身。
- 增量是 "每次只抓最新的一小段改动";
- 差异是 "每次都抓从全量开始到现在的所有改动",相当于 "自动汇总了全量后所有增量的内容"
备份策略
介绍
- 数据库的备份策略是指⼀系列计划和⽅法,⽤于确保数据库数据的安全性、完整性和可恢复性。⼀ 个良好的备份策略可以保护数据免受硬件故障、软件错误、数据损坏、⼈为失误和⾃然灾害等⻛险 的影响。
- 制定⼀个详细数据备份策略需要考虑多个因素,包括类型选择、执⾏计划、恢复计划、资源管理 等。如下图所⽰例:
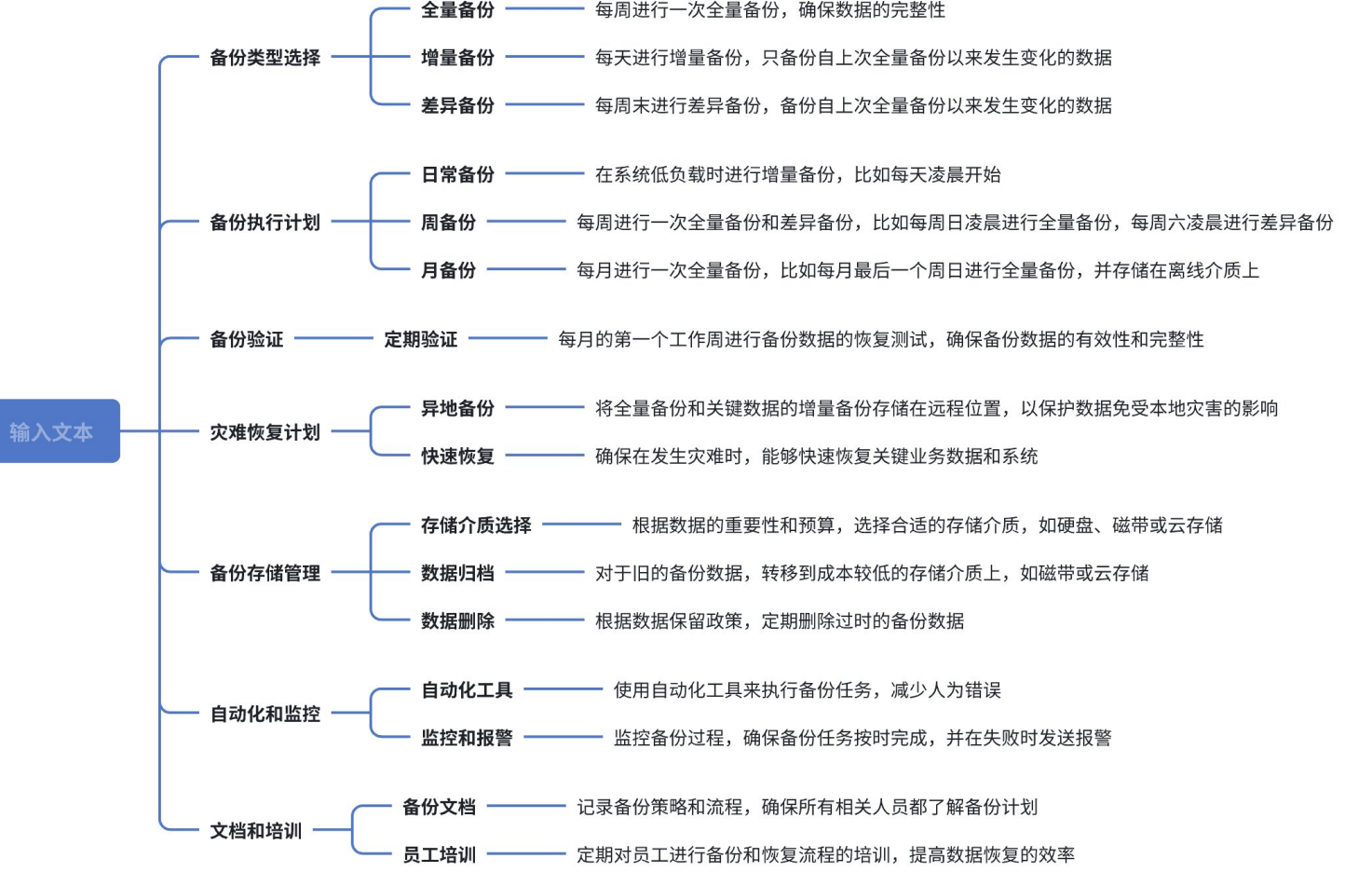
实施备份策略的⽬的是为了确保数据的安全性、完整性和可恢复性,同时满⾜业务需求和合规性要 求。
注意事项
- 检查备份服务器的磁盘空间,磁盘可用空间必须大于当前数据库所占容量
- 检查备份服务器 MySQL 超时时间参数设置,防止超时时间过小导致备份过程中连接中断
- 检查备份服务器 MySQL 数据包大小限制参数设置,防止数据包过大造成的数据丢失
- 检查备份用户是否被授予了适当的权限
- 检查业务系统当前负载,备份过程对系统性能有所影响,应在系统负载较低的状态下进行备份
备份⽅法⼀:Mysqldump⼯具
介绍
mysqldump客户端程序可以执行逻辑备份 并生成一组 SQL 语句,其中包含原始数据库和表的定义以及表中的数据,以便实现对数据库的简单备份或复制。mysqldump命令可以生成 CSV、或 XML 格式的文件。- 简单灵活:是一个命令行工具,使用相对简单不需要复杂的配置,提供了各种选项和参数,可以按需备份数据库的结构和数据,包括表结构、数据、触发器、存储过程等。
- 跨平台支持:适用于多个操作系统,包括 Windows、Linux 和 Mac 等。
- 兼容性好:SQL 文件是纯文本格式,易于编辑和传输,支持几乎所有的 MySQL 版本。
- 易于恢复:导出的 SQL 文件可以直接用于恢复数据库,通过简单的命令即可重新导入数据。
- 数据恢复缓慢:由于恢复时是将备份产生的 SQL 语句逐条执行,对于大型数据库、高频率备份和快速恢复等需求不太合适
- 无增量备份:不支持增量备份,每次备份都需要导出整个数据库。
应⽤场景
- 数据库版本升级
- 只备份表结构或⼩于10GB以下的数据库
- 跨数据库类型迁移,⽐如MySQL升级到Oracle
- 云平台之间的迁移,⽐如阿⾥云迁移到腾讯云
语法
mysqldump的⽅法通常有以下使⽤,可以转储⼀个或多个表或数据库,如下所⽰:
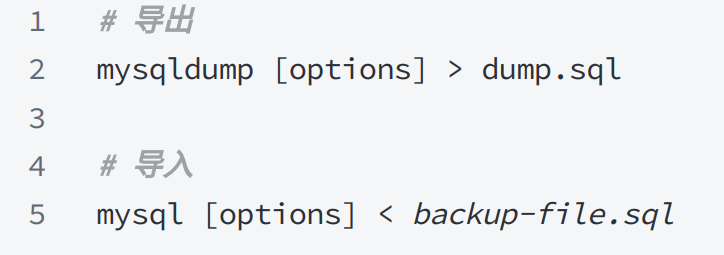
- 导出(备份) :命令格式为
mysqldump [options] > dump.sql。作用是将数据库(或表、对象)的结构和数据以 SQL 语句的形式导出到dump.sql文件中,实现备份。 - 导入(恢复) :命令格式为
mysql [options] < backup-file.sql。作用是将备份好的backup-file.sql中的 SQL 语句在目标数据库执行,从而恢复数据。
mysqldump 常用选项说明
这些选项用于控制 mysqldump 的备份行为(如备份范围、对象、格式等),以下是关键选项解析:
| 选项 | 说明 |
|---|---|
--add-drop-database |
在每个 CREATE DATABASE 语句前添加 DROP DATABASE 语句,恢复时先删除再重建数据库 |
--add-drop-table |
在每个 CREATE TABLE 语句前添加 DROP TABLE 语句,恢复时先删除再重建表 |
--add-drop-trigger |
在每个 CREATE TRIGGER 语句前添加 DROP TRIGGER 语句,恢复时先删除再重建触发器 |
--add-locks |
用 LOCK TABLES 和 UNLOCK TABLES 包裹每个表的备份过程,保证备份时表数据的一致性 |
--all-databases, -A |
备份所有数据库中的所有表 |
--databases, -B |
备份指定的多个数据库(多个数据库名用空格隔开),会包含数据库的创建语句 |
--comments, -i |
在备份文件中添加注释,便于理解备份内容 |
--complete-insert, -c |
使用包含列名的完整 INSERT 语句,恢复时更鲁棒(即使表结构列顺序变化也可能正常插入) |
--events, -E |
备份数据库中的事件(定时任务类对象) |
--extended-insert, -e |
使用多行 INSERT 语法,减少 SQL 语句数量,提升备份和恢复效率 |
--flush-logs, -F |
备份前刷新日志,常用于二进制日志的管理,方便后续基于日志的恢复 |
--force, -f |
即使备份过程中出现 SQL 错误,也继续执行备份 |
--ignore-table |
排除指定的表(格式:--ignore-table=db_name.table_name,多个表用空格隔开) |
--lock-all-tables, -x |
锁定所有数据库的所有表,保证全局数据一致性(备份大库时可能影响业务) |
--lock-tables, -l |
只锁定要备份的表,备份完立即解锁,对业务影响相对较小 |
--no-autocommit |
将每个表的 INSERT 语句包裹在 SET autocommit = 0 和 COMMIT 中,保证插入原子性 |
--no-create-db, -n |
不生成 CREATE DATABASE 语句,适用于仅恢复表结构 / 数据到已有数据库的场景 |
--no-create-info, -t |
不生成 CREATE TABLE 语句,仅备份表数据(需保证目标库已有表结构) |
--no-data, -d |
仅备份表结构(不备份表内容) |
--routines |
备份数据库中的存储过程和函数 |
--skip-add-drop-table |
不在 CREATE TABLE 前添加 DROP TABLE 语句,恢复时不会删除已有表 |
--skip-add-locks |
不添加 LOCK TABLES/UNLOCK TABLES 语句,备份时不锁表 |
--skip-comments |
备份文件中不添加注释 |
--skip-triggers |
不备份触发器 |
--tables |
备份指定的多个表(多个表名用空格隔开),需结合数据库名使用 |
--triggers |
备份每个表中的触发器 |
通过灵活组合这些选项,你可以精准控制 mysqldump 的备份范围、内容和行为,满足不同场景下的数据库备份需求(比如全库备份、单表结构备份、包含存储过程和触发器的备份等)。
注意事项
- 转储表时必须要有
SELECT权限; - 转储视图时必须要有
SHOW VIEW权限; - 转储触发器时必须要有
TRIGGER权限; - 如果没有使用
--single-transaction选项时必须要有LOCK TABLES权限; - 如果没有使用
--no-tablespaces选项时必须要有PROCESS权限; - 重新导入转储文件时,也需要有相应的权限;
- 由于
mysqldump是逐行转储数据,所以不适用于大数据量的转储与导入,一般适用于 50G 以下的数据备份,50G 以上使用物理备份; - 默认不备份
INFORMATION_SCHEMA,performance_schema,sys,需要备份时显示指定; mysqldump是单线程,数据量大时备份时间长,在备份过程中会对非事务表 (MyISAM) 长时间锁定,可能会对业务造成影响;- 备份结果是 SQL 形式,数据恢复时间也相对较长,大概是备份时间的 5-10 倍。
简单⽰例
步骤 1:打开 3 个 cmd 窗口(分工明确,避免切换混乱)
- 窗口 1:用于 MySQL 客户端操作(加锁、验证、解锁)
- 窗口 2:用于执行
mysqldump备份命令 - 窗口 3(可选):用于模拟业务写操作(验证锁生效)
步骤 2:窗口 1 - 登录 MySQL 并加全局读锁
# 窗口 1 中执行:登录 MySQL 客户端
mysql -u root -p
# 输入密码后,执行加锁命令(阻止所有写操作,允许读,保证备份一致性)
FLUSH TABLES WITH READ LOCK;
# 验证锁状态(可选,确认锁已生效)
SHOW OPEN TABLES WHERE In_use > 0;
# 输出结果中若有表的 In_use = 1,说明锁已加上注意:加锁后,所有数据库的表无法执行 INSERT/UPDATE/DELETE,需在业务低峰期操作!
步骤 3:窗口 3(可选)- 验证锁的有效性
# 窗口 3 中执行:登录另一个 MySQL 客户端
mysql -u root -p
# 尝试修改 testdb.t1 表数据(模拟业务写操作)
USE testdb;
INSERT INTO t1 VALUES (112, 'test_lock');
# 此时命令会卡住(等待锁释放),说明锁生效,避免备份时数据被修改步骤 4:窗口 2 - 执行带日期命名的备份命令
# 窗口 2 中执行:设置日期变量(用于备份文件名)
for /f "tokens=1-3 delims=/ " %a in ('date /t') do set "date=%a-%b-%c"
# 执行 mysqldump 备份(包含表结构、数据、触发器,锁已在窗口 1 加好)
mysqldump -u root -p --add-drop-table --complete-insert testdb > D:\backup\testdb_%date%.sql- 输入 MySQL 密码后,等待备份完成(窗口 2 无报错且回到命令提示符,说明备份成功)。
步骤 5:窗口 1 - 循环验证表结构 / 数据(直到备份完成)
-- 窗口 1 的 MySQL 客户端中,反复执行以下命令,确认数据未变更
USE testdb;
-- 查看表结构(确认无修改)
DESCRIBE t1;
-- 查看表数据(确认与备份前一致,无新增/删除/修改)
SELECT * FROM t1;
-- 若备份完成,执行解锁命令(关键!否则业务写操作会一直卡住)
UNLOCK TABLES;- 解锁后,窗口 3 中之前卡住的
INSERT命令会自动执行(或报错,根据业务场景处理)。
步骤 6:验证备份文件(可选)
打开 D:\backup\testdb_日期.sql(如 testdb_11-10-2025.sql),用记事本查看:
-
包含
CREATE TABLE t1 (...)(表结构) -
包含
INSERT INTO t1 VALUES (...)(数据) -
包含
DROP TABLE IF EXISTS t1;(--add-drop-table 选项生效)窗口 1 中执行:删除 testdb 数据库(模拟数据丢失场景)
DROP DATABASE testdb;
重建 testdb 数据库(恢复的前提:目标库存在)
CREATE DATABASE IF NOT EXISTS testdb DEFAULT CHARACTER SET utf8mb4;
退出 MySQL 客户端
exit;
窗口 2 中执行:导入备份文件恢复数据
mysql -u root -p testdb < D:\backup\testdb_%date%.sql
验证恢复结果:窗口 1 登录 MySQL 查看
mysql -u root -p
USE testdb;
SELECT * FROM t1;能看到备份前的所有数据,说明恢复成功
步骤 7:模拟删库后恢复(完整验证备份可用性)
关键参数与说明
-
加锁命令 :
FLUSH TABLES WITH READ LOCK;- 作用:锁定所有数据库的所有表,仅允许读操作,杜绝备份期间数据写入导致的不一致。
- 适用场景:MyISAM 表(不支持事务)、需要严格一致性的 InnoDB 表场景。
-
备份参数 :
--add-drop-table+--complete-insert--add-drop-table:恢复时先删除旧表,避免表结构冲突。--complete-insert:生成带列名的INSERT语句,即使表结构列顺序变化也能正常恢复。
-
解锁命令 :
UNLOCK TABLES;- 必须在备份完成后立即执行,否则会阻塞业务写操作,造成线上故障!
InnoDB 表优化方案(无需手动加锁)
如果你的表是 InnoDB 引擎(默认推荐),可省略手动加锁步骤,用 --single-transaction 实现无锁一致性备份,更适合线上业务:
# 窗口 2 直接执行备份(无需窗口 1 加锁)
for /f "tokens=1-3 delims=/ " %a in ('date /t') do set "date=%a-%b-%c"
mysqldump -u root -p --single-transaction --add-drop-table --complete-insert testdb > D:\backup\testdb_%date%.sql原理:利用 InnoDB 的事务隔离级(REPEATABLE READ),备份时生成数据快照,既保证一致性,又不影响业务读写。
存在问题
- 上述的备份流程在备份之前会对所有表进行加锁,也就意味着,在备份完成之前,正常业务产生的相关插入、删除、truncate 操作都在处于锁等待状态,会对业务造成严重的影响,不建议在生产环境使用。
- 同时由于备份过程中会产生数据不一致问题:
- 数据可能已经改变,但是这些改变尚未提交,因此备份可能包含未提交的事务中的数据更改。
- 如果备份期间发生了事务回滚,备份中可能包含已经删除或修改了的数据,这些数据在恢复后可能不存在。
- 如果备份期间有新的数据插入,那么这些新数据可能不会被备份。
解决问题
一致性备份
为什么需要一致性备份?
在传统加锁备份(如 FLUSH TABLES WITH READ LOCK 全局锁)中,会阻塞业务的插入、删除等操作,且可能出现数据不一致(如包含未提交事务、丢失新插入数据等)。而 --single-transaction 选项 是解决这些问题的关键,它利用 InnoDB 事务的 MVCC(多版本并发控制) 特性,在不阻塞业务的前提下,保证备份数据的一致性。
--single-transaction 一致性备份的执行流程(9 个步骤)
| 步骤 | 操作 | 作用与说明 |
|---|---|---|
| 1 | Connect |
建立数据库连接,为备份做准备。 |
| 2 | FLUSH TABLES |
关闭实例上所有打开的表,避免大事务干扰备份初始化。 |
| 3 | FLUSH TABLES WITH READ LOCK |
加全局读锁,阻塞所有 DML(插入、更新、删除)和 DDL(建表、改结构)操作,目的是获取一致的日志位点(后续步骤会释放)。 |
| 4 | SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ |
设置事务隔离级别为可重复读,保证备份过程中读取的数据是 "快照一致" 的(通过 MVCC 实现)。 |
| 5 | START TRANSACTION |
开启备份专用事务,--single-transaction 选项会触发该逻辑。 |
| 6 | SHOW MASTER STATUS |
获取备份时的二进制日志位点(POS 信息),若后续做增量备份,可基于该位点续传日志。 |
| 7 | UNLOCK TABLES |
释放全局读锁,此时业务的 DML、DDL 操作恢复正常,备份不再阻塞业务。 |
| 8 | SELECT /*!40001 SQL_NO_CACHE */ * FROM t1`` |
执行查询语句获取数据并备份。由于已释放全局锁,只有 InnoDB 表能通过 MVCC 保证一致性,MyISAM 等非事务表无法保证(因此建议核心表用 InnoDB)。 |
| 9 | COMMIT |
备份完成后提交事务,整个备份流程结束。 |
核心优势
- 不阻塞业务:步骤 7 释放全局锁后,业务可正常读写,解决了传统锁备份的 "业务影响" 问题。
- 数据一致性:通过 InnoDB 事务的可重复读隔离级别和 MVCC,保证备份数据是 "某一时刻的一致快照",不会包含未提交事务、回滚数据或丢失新插入数据。
适用场景与限制
- 适用:InnoDB 存储引擎的业务核心表(如订单、用户表),需要在不影响业务的前提下做一致性备份。
- 限制 :仅对 InnoDB 表有效;若数据库中包含 MyISAM 等非事务表,这些表的备份仍可能不一致(因此建议统一使用 InnoDB)。简单来说,
--single-transaction是 MySQL 中 "无锁一致性备份 " 的最优解,它通过事务和 MVCC 机制,既保证了数据一致性,又避免了对业务的阻塞,是生产环境备份的推荐方案。