指针基础概念
在讲解指针之前,首先对变量有个概念。
变量由三个部分组成:1.类型。2.变量值.3.变量的起始地址。
int a=10;这里面就包含第1,2点。那么第三点呢?
获取变量的起始地址:&变量。(这里要注意,这个地址是起始地址,后面的数组会有所关联)
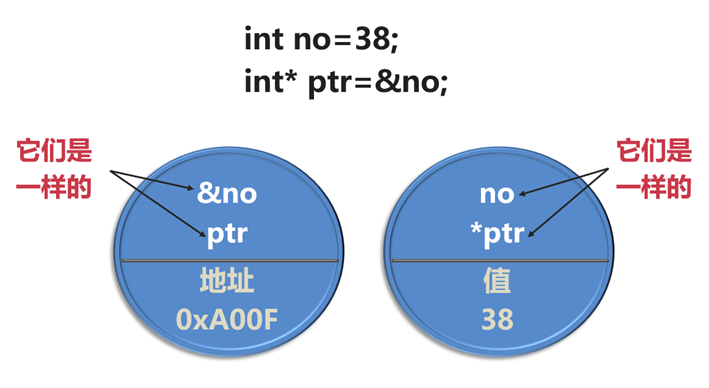
现在可以引进指针的概念了,所谓的指针是一种特殊的变量,专用于存放变量在内存中的起始地址。
指针语法:数据类型*变量名(从另一个角度理解,指针=变量,类型为(数据类型*))
指针赋值,使用&。传入的是地址。
声明指针变量后,在没有赋值之前,里面是乱七八糟的值,这时候不能使用指针。
指针存放变量的地址,因此,指针名表示的是地址(就像变量名可以表示变量的值一样)
*运算符被称为间接值 或**解除引用(解引用)**运算符,将它用于指针,可以得到该地址的内存中存储的值,*也是乘法符号,C++根据上下文来确定所指的是乘法还是解引用。
int *ptr=&a;
cpp
#include <iostream>
using namespace std;
int main()
{
SetConsoleOutputCP(65001);
int a = 10; int b = 20;
cout << "a = " << a << endl;
cout << "&a =:" << &a << endl;
int* ptr = &a;
cout << "ptr = " << ptr << endl;
cout << "*ptr = " << *ptr << endl;
ptr = &b;
cout << "b = " << b << endl;
cout << "&b =:" << &b << endl;
cout << "ptr = " << ptr << endl;
cout << "*ptr = " << *ptr << endl;
}指针可以用于函数的参数
如果把函数的形参声明为指针,调用的时候把实参的地址传进去,形参中存放的是实参的地址,在函数中通过解引用的方法直接操作内存中的数据,可以修改实数的值,这种方法被通俗的称为地址传递 或传地址。
简单来说,在函数定义的时候,形参存放地址(数据类型*变量a),而函数内部调用的时候通过解引用进行使用(*变量a)。
cpp
#include <windows.h>
#include <iostream>
using namespace std;
void add( int* num1, int* num2)
{
int sum = *num1 + *num2;
cout << "Sum = " << sum << endl;
*num1 = 100; // 修改num1所指向的值
}
int main()
{
SetConsoleOutputCP(65001);
int a = 10; int b = 20;
cout << "a = " << a << endl;
cout << "&a =:" << &a << endl;
int* ptr = &a;
cout << "ptr = " << ptr << endl;
cout << "*ptr = " << *ptr << endl;
ptr = &b;
cout << "b = " << b << endl;
cout << "&b =:" << &b << endl;
cout << "ptr = " << ptr << endl;
cout << "*ptr = " << *ptr << endl;
add(&a, &b);
cout << "a = " << endl;
}现在我们基本上对指针有个概念了,指针就是指向变量的起始地址。他就向一个箭头,那么这个箭头还是有自由度进行操作的,例如:指向谁?能否通过指针进行更改变量值?
这时候引入了const
1.常量指针 const 数据类型*变量名
这个东西是规定这个指针指向的变量值无法更,但是可以更改它的指向。这时候的指针就相当于只能读取,而无法更改。一般用于修饰函数的形参,表示不希望在函数里修改内存地址中的值。
2.指针常量 数据类型*const 变量名
这个东西是规定这个指只能指向某个变量,无法更换指向,但是可以读取以及更改变量值。
3.常指针常量 const 数据类型 * const 变量名
指向的变量(对象)不可改变,不能通过解引用的方法修改内存地址中的值。
这时候我们考虑另外的问题,指针除了用来指向单纯的变量还能做什么?还能指向什么?
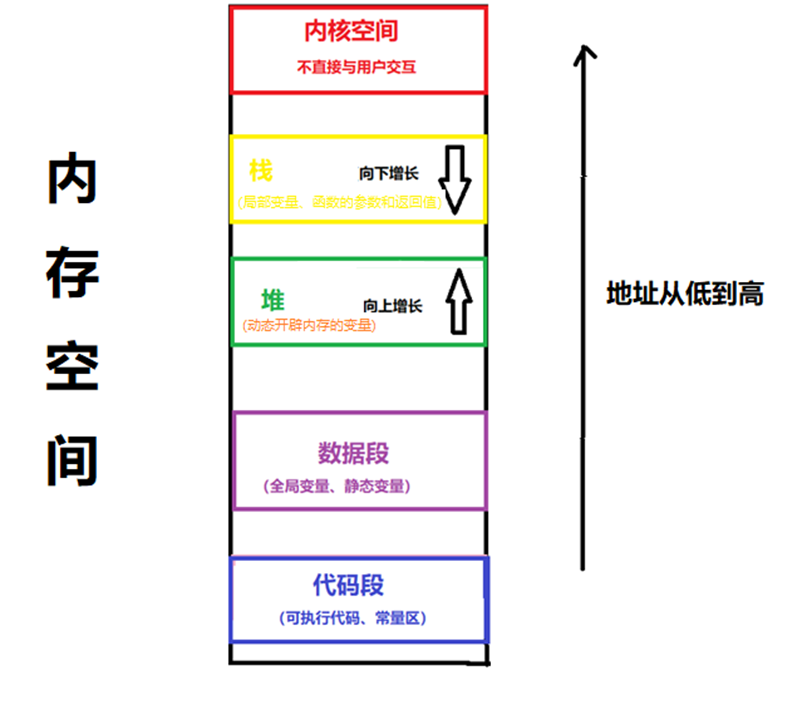
我们先看这个c++的内存空间图
栈: 存储局部变量、函数参数和返回值。
堆: 存储动态开辟内存的变量。
数据段: 存储全局变量和静态变量。
代码段: 存储可执行程序的代码和常量(例如字符常量),此存储区不可修改。
栈是系统管理的,无需我们来操作,但是堆不同,这块是我们动态分配,需要自己创建以及销毁,不销毁的话会消耗资源的。
这时候为了在堆上变量进行跟踪,确保生成以及消耗,我们使用指针来跟踪它。什么意思呢?
我们在堆上申请一块内存空间,然后用指针指向它,当我们不用的时候将内存中的信息清空,指针消失,以此来管理堆,以此完成动态分配(new,detlete)
步骤:
1)声明一个指针;
2)用new运算符向系统申请一块内存,让指针指向这块内存;
3)通过对指针解引用的方法,像使用变量一样使用这块内存;
4)如果这块内存不用了,用delete运算符释放它。
cpp
int* p = new int(5);
cout << "*p=" << *p << endl;
*p = 8;
cout << "*p=" << *p << endl;
delete p;int* p = new int(5);
重点理解这个:
- 在堆(heap)上动态分配一块足够存放一个
int类型的内存;- 将这块内存中的值初始化为 5;
- 把这块内存的地址赋值给指针变量
p。
指针上面讲的是指向某个变量的起始位置,那如果我们想让指针改变指向的话我们可以通过改变地址对吧,例如int*ptr=&a。但是在函数值传递的时候不行,为什么?
举个例子:
cpp
#include <iostream>
using namespace std;
void badFunction(int* p) {
p = new int(100); // 想让主函数的指针指向新内存
cout << "badFunction *p = " << *p << endl; // 输出 100
}
int main() {
int* ptr = nullptr;
badFunction(ptr);
// 问题来了:ptr 改变了吗?
if (ptr == nullptr) {
cout << "main ptr = nullptr!" << endl; // 会输出这行!
}
delete ptr;
// 如果这里 delete ptr; 就会出错(因为是 nullptr)
return 0;
}这时候我们运行发现是不改变的,为什么?因为是值传递!
- 调用
badFunction(ptr)时,把ptr的值(即地址)复制给了形参p。 - 所以
p是ptr的一个副本。 - 在函数里修改
p = new int(100);只是改了副本,不影响主函数的ptr!
那么如果我们形参是地址的话确实是可以改变的
cpp
#include <iostream>
using namespace std;
void badFunction(int* p) {
p = new int(100); // 想让主函数的指针指向新内存
cout << "badFunction *p = " << *p << endl; // 输出 100
}
void goodFunction(int* &p) {
p = new int(100); // 直接修改主函数的指针
}
int main() {
int* ptr = nullptr;
badFunction(ptr);
// 问题来了:ptr 改变了吗?
if (ptr == nullptr) {
cout << "main ptr = nullptr!" << endl; // 会输出这行!
}
goodFunction(ptr);
cout << *ptr << endl;
delete ptr;
// 如果这里 delete ptr; 就会出错(因为是 nullptr)
return 0;
}我们看看这个形参int* &p
这个像什么?是不是相当于一个指针指向了指针的地址啊,所以引入了二级指针
二级指针: 数据类型** 指针名;
注意几个点,形参使用数据类型**变量名,而在调用的时候输入的实参是地址&指针名。
cpp
#include <iostream>
using namespace std;
void badFunction(int* p) {
p = new int(100); // 想让主函数的指针指向新内存
cout << "badFunction *p = " << *p << endl; // 输出 100
}
void goodFunction(int*&p) {
p = new int(100); // 直接修改主函数的指针
}
void Function(int** p) {
*p = new int(100); // 直接修改主函数的指针
}
int main() {
int* ptr = nullptr;
badFunction(ptr);
// 问题来了:ptr 改变了吗?
if (ptr == nullptr) {
cout << "main ptr = nullptr!" << endl; // 会输出这行!
}
goodFunction(ptr);
cout << *ptr << endl;
Function(&ptr);
cout << *ptr << endl;
delete ptr;
// 如果这里 delete ptr; 就会出错(因为是 nullptr)
return 0;
}野指针就是指针指向的不是一个有效(合法)的地址。
在程序中,如果访问野指针,可能会造成程序的崩溃。
出现野指针的情况主要有三种:
1)指针在定义的时候,如果没有进行初始化,它的值是不确定的(乱指一气)。
cpp
int* p; // 危险!p 的值是随机垃圾地址
*p = 10; // ❌ 试图写入未知内存 → 崩溃 or 隐蔽错误2)如果用指针指向了动态分配的内存,内存被释放后,指针不会置空,但是,指向的地址已失效。
cpp
int* p = new int(42);
delete p;
// 此时 p 仍保存着原地址,但该内存已归还系统
cout << *p; // ❌ 读取已释放内存 → 野指针!3)指针指向的变量已超越变量的作用域(变量的内存空间已被系统回收),让指针指向了函数的局部变量,或者把函数的局部变量的地址作为返回值赋给了指针。
cpp
int* getPtr() {
int x = 100;
return &x; // ❌ x 是局部变量,函数结束即销毁
}
int main() {
int* p = getPtr();
cout << *p; // ❌ 野指针!x 的内存已被回收
}规避方法:
1)指针在定义的时候,如果没地方指,就初始化为nullptr。
2)动态分配的内存被释放后,将其置为nullptr。
3)函数不要返回局部变量的地址。
注意:野指针的危害比空指针要大很多,在程序中,如果访问野指针,可能 会造成程序的崩溃。是可能,不是一定,程序的表现是不稳定,增加了调试程序的难度。
我们不仅通过指针调用变量,还想使用指针调用函数。
函数指针是一个变量,它存储的是"函数在代码段中的入口地址" 。因为函数的二进制代码存放在内存四区中的代码段,函数的地址是它在内存中的起始地址。如果把函数的地址作为参数传递给函数,就可以在函数中灵活的调用其它函数。
使用函数指针的三个步骤:
a)声明函数指针;
cpp
返回类型 (*指针名)(参数类型列表);b)让函数指针指向函数的地址;
cpp
函数名就是函数的地址。
函数指针的赋值:函数指针名=函数名;c)通过函数指针调用函数。
cpp
(*函数指针名)(实参);
函数指针名(实参);| 场景 | 使用方式 | 声明方式 |
|---|---|---|
| 普通 int 指针 | *p 得到 int 值 |
int *p; |
| 函数指针 | callback(5) 调用函数 |
int (*callback)(int); |
cpp
void process(int x, int (*callback)(int)) {
int result = callback(x);
cout << "Processed: " << result << endl;
}
int square(int n) { return n * n; }
int main() {
process(5, square); // 把 square 作为回调传入
}讲完变量以及指针,就引入数组。为什么要数组,原因很简单,因为实用,可以存储信息等等。
一维数组:是一组数据类型相同的变量,可以存放一组数据。
1.创建数组:数据类型 数组名数组长度
数组长度必须是整数,可以是常量,也可以是变量和表达式。
2.数组的使用 数组名数组下标
有两种方式:
第一种: 下标访问 下标从 0 到 size-1;
cpp
arr[0] = 10; // 第一个元素
arr[i] = arr[i-1]; // i 是变量也可以第二种:指针访问,指针指向数组的起始位置
cpp
int arr[5] = { 1,2,3,4,5 };
int* p = arr; // arr 自动转为 &arr[0]
cout << *(p + 2) << endl; // 输出 3
//注意!!!
cout << sizeof(arr) << endl; // 返回 5 * sizeof(int) → 整个数组大小
cout << sizeof(p) << endl; // 返回 sizeof(int*) → 指针大小(8 字节)3.内存布局
- 连续存储;
&arr[0],&arr[1], ... 地址依次递增sizeof(元素);arr == &arr[0](值相等,但类型不同:int*vsint(*)[5])。
4.数组初始化
数据类型 数组名数组长度 = { 值1,值2,值3, ...... , 值n};
数据类型 数组名 = { 值1,值2,值3, ...... , 值n};
数据类型 数组名数组长度 = { 0 }; // 把全部的元素初始化为0。
数据类型 数组名数组长度 = { }; // 把全部的元素初始化为0。
5.清空 & 复制数组
清空:memset()函数
cpp
#include <cstring> // C++ 中推荐 <cstring>,而非 <string.h>
int arr[100];
memset(arr, 0, sizeof(arr)); // 全部字节设为 0 → 对 int/char 等有效复制: memcpy 复制数组
cpp
int src[5] = {1,2,3,4,5};
int dest[5];
memcpy(dest, src, sizeof(src)); 在这里浅说一下,最好使用stl的array以及vector
| 容器 | 适用场景 | 特点 |
|---|---|---|
std::array<T, N> |
大小固定且已知 (编译期确定) 例如:坐标 {x,y,z}、RGB 颜色、月份名等 |
- 栈上分配(快) - 零额外开销(和传统数组性能一样) - 支持所有容器接口 |
std::vector<T> |
大小未知或会变化 例如:读取用户输入的数字列表、动态链表缓存等 | - 堆上分配 - 自动管理内存 - 支持 push_back, resize 等 |
详细讲讲一维数组和指针的关系
1.指针的算术
将一个整型变量加1后,其值将增加1。
但是,将指针变量(地址的值)加1后,增加的量等于它指向的数据类型的字节数。
2.数组的地址
a)数组在内存中占用的空间是连续的。
b)C++将数组名解释为数组第0个元素的地址。
c)数组第0个元素的地址和数组首地址的取值是相同的。
d)数组第n个元素的地址是:数组首地址+n
e)C++编译器把 数组名下标 解释为 *(数组首地址+下标)
3数组的本质
数组是占用连续空间的一块内存,数组名被解释为数组第0个元素的地址。C++操作这块内存有两种方法:数组解释法和指针表示法,它们是等价的。
4.数组名不总是被解释为地址
两种例外情况(数组名不会退化为指针):
| 情况 | 行为 |
|---|---|
1. sizeof(数组名) |
返回整个数组的字节数,不是指针大小 |
2. &数组名 |
返回"整个数组的地址",类型是 int(*)[N](指向数组的指针),不是 int* |
5.一维数组用于函数参数
一、核心事实
当一维数组作为函数参数传递时,它会自动退化为指向首元素的指针。
因此,函数无法知道原数组的长度。
二、参数声明的两种等价写法
void func(int* arr, int len); // 明确是指针
void func(int arr[], int len); // 语义更清晰(推荐)-
两者在编译器眼中完全相同;
-
即使写成
int arr[100],100也会被忽略!
三、必须显式传递数组长度
-
函数内部不能用
sizeof(arr)获取数组大小(它返回的是指针大小,如 8 字节); -
正确做法:由调用者传入长度:
cppint data[5] = {1,2,3,4,5}; func(data, 5); // 显式传长度
四、函数内部使用方式
-
可以用数组语法 :
arr[i] -
也可以用指针语法 :
*(arr + i) -
两者完全等价,任选其一。
五、例外情况(无需传长度)
仅当数组有结束标志时可省略长度,例如:
-
C 风格字符串(以
\0结尾):cppvoid printStr(const char* s); // 遇到 '\0' 停止
用new动态创建一维数组
为什么需要动态数组?
| 类型 | 分配位置 | 大小限制 | 生命周期 | 是否需手动释放 |
|---|---|---|---|---|
普通数组(int arr[N]) |
栈(stack) | 小(通常几 MB) | 函数结束自动销毁 | ❌ 不需要 |
动态数组(new int[N]) |
堆(heap) | 大(可达 GB 级) | 手动控制 | ✅ 必须 delete[] |
二、动态创建与释放语法
- 创建
cpp
数据类型* 指针 = new 数据类型[数组长度];示例:
cpp
int* p = new int[10]; // 分配 10 个 int
double* q = new double[n]; // n 是变量(运行时确定)- 释放
cpp
delete[] 指针;
指针 = nullptr; // 避免悬空指针(good practice)⚠️ 必须用
delete[],不能用delete!
二维数组:
二维数组的本质
二维数组是"数组的数组" ------ 它是一个一维数组,其中每个元素又是一个一维数组。
二、创建二维数组
- 基本语法
cpp
数据类型 数组名[行数][列数];示例:
cpp
int matrix[3][4]; // 3 行 4 列的整数矩阵三、内存布局:连续存储(行优先)
cpp
int arr[2][3] = {
{10, 20, 30},
{40, 50, 60}
};内存布局(地址递增):
cpp
[10][20][30][40][50][60]
↑
&arr[0][0]-
总字节数:
行数 × 列数 × sizeof(元素) -
sizeof(arr)返回整个数组大小(仅在定义处有效)
四、访问元素
cpp
arr[i][j] // 第 i 行、第 j 列(i ∈ [0, 行数-1], j ∈ [0, 列数-1])等价于指针运算:
cpp
*(*(arr + i) + j)因为:
-
arr是int[3]类型的数组(假设列数=3); -
arr + i指向第 i 行(类型为int(*)[3]); -
*(arr + i)是第 i 行(类型为int[3],退化为int*); -
再加
j得到具体元素。
五、初始化方式
- 按行初始化(推荐)
cpp
int mat[2][3] = {
{1, 2, 3},
{4, 5, 6}
};- 扁平初始化(按内存顺序)
cpp
int mat[2][3] = {1, 2, 3, 4, 5, 6}; // 效果同上- 自动推导行数
cpp
int mat[][3] = {{1,2,3}, {4,5,6}}; // 行数自动为 2- 全零初始化
cpp
int mat[3][4] = {0}; // 全部为 0
int mat[3][4] = {}; // C++11 起,更推荐⚠️ 注意:如果初始化列表不足,剩余元素自动补 0。
六、清空与复制(传统方式)
- 清零(仅适用于 POD 类型)
cpp
#include <cstring>
memset(mat, 0, sizeof(mat)); // 安全,因为 mat 是连续内存- 复制
cpp
int src[2][3] = {{1,2,3},{4,5,6}};
int dest[2][3];
memcpy(dest, src, sizeof(src)); // 安全,因为内存连续优势:二维数组是连续内存,所以
memset/memcpy可以直接作用于整个数组(不像指针数组)。
七、二维数组作为函数参数
二维数组传参时,必须让函数知道"每行有多少列" ,因为编译器需要据此计算元素地址。
因此,列数必须在参数中显式指定,而行数可以省略(通过额外参数传入)。
为什么需要"行指针"?
- 二维数组的本质
cpp
int bh[2][3] = {{11,12,13}, {21,22,23}};-
bh是一个包含 2 个元素 的数组; -
每个元素是
int[3]类型(即长度为 3 的整型数组); -
所以
bh的类型是:int[2][3]
- 数组名的退化规则
-
在表达式中,
bh退化为 指向第一个"行"的指针; -
第一个"行"是
int[3],所以bh退化为:int (*)[3](读作:"指向含3个int的数组的指针")
因此:
cpp
int (*p)[3] = bh; // 正确!p 是行指针
int* q = bh; // ❌ 错误!类型不匹配(除非强制转换)💡
int (*)[3]≠int*:前者知道"每行3个int",后者只知道"一个int"。
二维数组传参的两种等价写法
写法 1:显式使用行指针(更清晰底层机制)
cpp
void func(int (*p)[3], int rows);写法 2:数组语法(更易读,推荐)
cpp
void func(int p[][3], int rows);
// 或
void func(int p[2][3], int rows); // 2 会被忽略,实际仍是 int (*)[3]🔍 编译器视角:两者完全等价!都表示参数
p的类型是int (*)[3]
为什么列数不能省略?
因为地址计算依赖列数!
访问 p[i][j] 时,编译器实际计算:
cpp
*( *(p + i) + j )-
p + i需要知道 一行占多少字节 →3 * sizeof(int) -
如果不知道列数(即不知道每行大小),就无法定位第
i行!
📌 类比:你知道书有若干页,但不知道每页多少行,就无法快速跳到第 N 行。
cpp
#include <iostream>
// 方式1:使用行指针(显式指针语法)
void printMatrix1(int (*p)[3], int rows) {
std::cout << "=== Using row pointer int (*)[3] ===\n";
for (int i = 0; i < rows; ++i) {
for (int j = 0; j < 3; ++j) {
std::cout << p[i][j] << " "; // 数组表示法
// 或:std::cout << *(*(p + i) + j) << " "; // 指针表示法
}
std::cout << "\n";
}
}
// 方式2:使用数组语法(更易读,推荐)
void printMatrix2(int p[][3], int rows) {
std::cout << "=== Using array syntax int p[][3] ===\n";
for (int i = 0; i < rows; ++i) {
for (int j = 0; j < 3; ++j) {
std::cout << p[i][j] << " ";
}
std::cout << "\n";
}
}
int main() {
// 定义一个 2x3 的二维数组
int bh[2][3] = {
{11, 12, 13},
{21, 22, 23}
};
// 验证地址关系
std::cout << "Address verification:\n";
std::cout << "bh = " << bh << "\n"; // 行地址(类型 int(*)[3])
std::cout << "&bh[0] = " << &bh[0] << "\n"; // 第0行地址(同上)
std::cout << "bh[0] = " << bh[0] << "\n"; // 第0行首元素地址(类型 int*)
std::cout << "&bh[0][0] = " << &bh[0][0] << "\n"; // 首元素地址(同上)
std::cout << "*bh = " << *bh << "\n"; // 等价于 bh[0]
std::cout << "\n";
//(*bh) 指向的是二维数组的第0行(即第0行的首地址)
//(*bh)[1] 就是第0行第1列的元素,也就是 bh[0][1]
std::cout << "(*bh)[1]=" << (*bh)[1] << std::endl; // 12
std::cout << "(*bh)[2]=" << (*bh)[2] << std::endl; // 13
//(*bh + 1) 是第0行首地址加1,指向第0行的第1个元素,也就是 bh[0] + 1,类型还是 int*。
//(*bh + 1)[1] 实际上是先移动到 bh[0][1],再取下标为1的元素,也就是 bh[0][2]。
std::cout << "(*bh+1)[1]=" << (*bh + 1)[1] << std::endl; // 21
//二维数组在内存中是这样排的:
//11 12 13 21 22 23
//(*bh + 1)[2] 就是 *( (*bh + 1) + 2 ),也就是 *(bh[0] + 3),即 bh[1][0],值为 21
std::cout << "(*bh+1)[2]=" << (*bh + 1)[2] << std::endl; // 21
//*(bh+1) 把这个指针解引用,得到第1行本身,类型是 int[3],等价于 bh[1]。
//(*(bh+1))[1] 就是第1行第1列的元素,也就是 bh[1][1]。
std::cout << "(*(bh+1))[1]=" << (*(bh+1))[1] << std::endl; // 22
std::cout << "*(bh[0]+1)=" << *(bh[0] + 1) << std::endl; // 12
std::cout << "*(bh[1]+1)=" << *(bh[1] + 1) << std::endl; // 22
// 调用函数(两种方式完全等价)
printMatrix1(bh, 2); // 传 bh,自动退化为 int(*)[3]
printMatrix2(bh, 2);
return 0;
}