多年来,SEO从业者始终致力于破解谷歌搜索这个黑匣子,而如今他们面临的挑战似乎更加晦涩------如何赢得人工智能引用的青睐。
乍看之下,被纳入人工智能答案的机制似乎比传统SEO更神秘莫测,但好消息是:一旦掌握识别方法,人工智能引擎确实会透露其对优质内容的评判标准。
本文将提供发现AI引擎青睐内容的分步指南,并为获取AI引用提供实施蓝图。
采取系统化方法优化AI引擎
构建高效AI搜索优化策略的关键,始于理解AI爬虫的行为模式。通过分析这些机器人与网站的交互方式,可识别哪些内容能引起AI系统的共鸣,进而制定数据驱动的优化方案。
尽管谷歌仍占据主导地位,但ChatGPT、Perplexity和Claude等AI驱动的搜索引擎正日益成为用户获取快速权威答案的首选资源。这些平台并非凭空生成答案------它们依赖爬取的网络内容训练模型并提供实时信息。
这既是机遇也是挑战。机遇在于让您的内容被这些AI系统发现并引用;挑战则在于理解如何针对运作机制与传统搜索引擎截然不同的算法进行优化。
答案在于系统化方法
- 通过爬虫行为解析AI引擎青睐的内容类型
- 传统日志文件分析
- SEO批量管理AI爬虫监控
- 反向工程提示词设计
- 内容分析
- 技术分析
- 构建蓝图
什么是AI爬虫及如何利用它们获益
AI爬虫是由人工智能公司部署的自动化机器人,用于系统性地浏览和摄取网络内容。不同于主要关注排名信号的传统搜索引擎爬虫,AI爬虫收集内容用于训练语言模型并填充知识库。
主要人工智能爬虫包括:
- GPTBot(OpenAI的ChatGPT)
- PerplexityBot(Perplexity AI)
- ClaudeBot(Anthropic的Claude)
- Googlebot crawlers(谷歌AI)。
这些爬虫通过两种关键方式影响您的内容策略:
- 训练数据采集
- 实时信息检索
训练数据采集
AI模型需基于海量网页内容数据集进行训练。被频繁抓取的页面在训练数据中的占比可能更高,从而提升您的内容被AI响应引用概率。
实时信息检索
某些人工智能系统会实时爬取网站,以便在响应中提供最新信息。这意味着新鲜且可爬取的内容能直接影响人工智能生成的答案。
例如当ChatGPT响应查询时,其实是在整合其底层AI爬虫收集的信息。同样,以引用来源能力著称的Perplexity AI也会主动爬取并处理网页内容以生成答案。Claude同样依赖海量数据采集来生成智能响应。
这些AI爬虫在您网站上的存在与活动,直接影响您在新AI生态系统中的可见度。它们决定您的内容是否被视为信息源、是否用于解答用户问题,最终决定您能否从AI驱动的搜索体验中获得归因或流量。
了解AI爬虫最常访问的页面,能洞悉AI系统认为有价值的内容类型。这些数据将成为优化整体内容策略的基础。
如何追踪AI爬虫活动:查找并使用日志文件分析
便捷方案:我们通常通过分析服务器日志文件来实现。
当然,您也可以采用手动方式操作。
服务器日志分析仍是理解爬虫行为的标准方法。您的服务器日志详细记录了每次机器人访问,包括那些可能不会出现在传统分析平台中的AI爬虫------这些平台通常只关注用户访问。
日志文件分析必备工具
多款企业级工具可协助解析日志文件:
- Screaming Frog Log File Analyser:技术型SEO人员数据处理的理想选择
- Botify:具备强大爬虫分析功能的企业级解决方案
- Semrush:在其综合SEO套件中提供日志文件分析功能
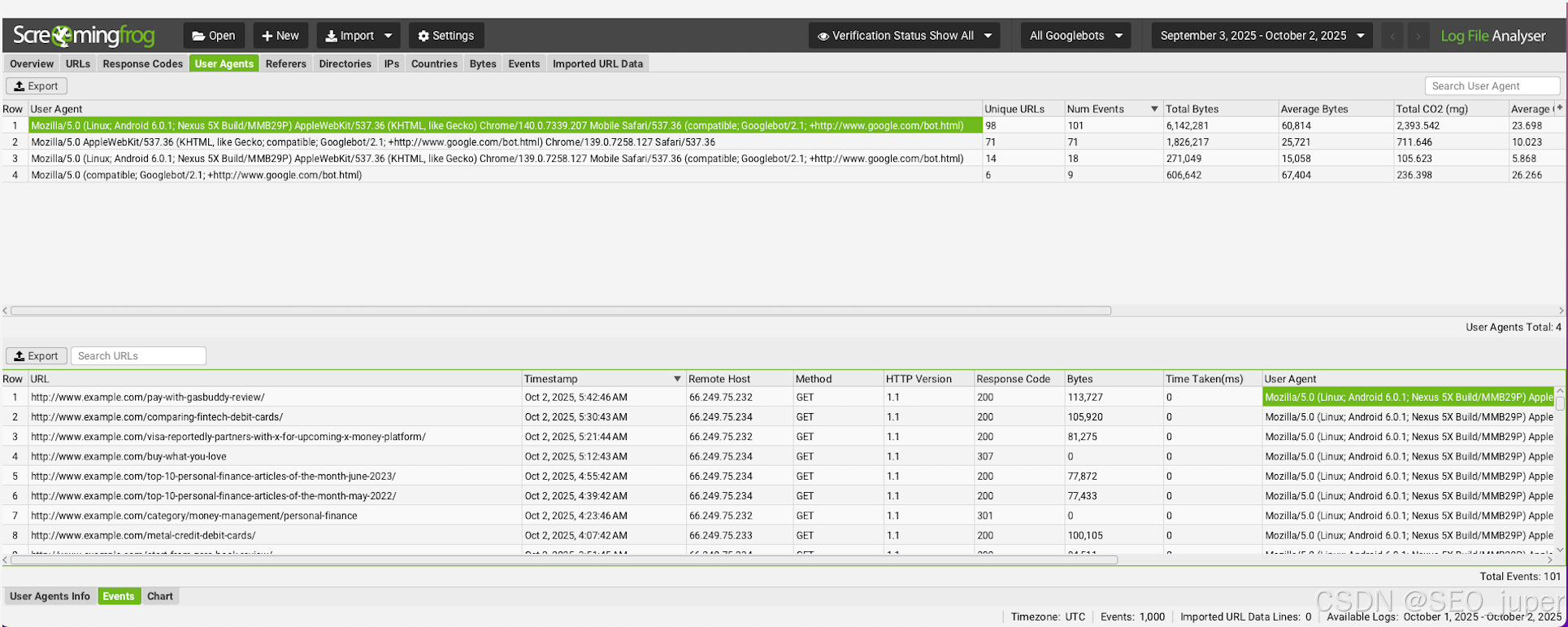
日志文件分析的复杂性挑战
要精确了解哪些机器人访问了您的网站、访问了哪些内容以及访问频率,最细致的方法就是通过服务器日志文件分析。
您的网络服务器会自动记录所有访问请求,包括来自爬虫的请求。通过解析这些日志,您可以识别出与AI爬虫相关的特定用户代理。
具体操作步骤如下:
- 访问服务器日志:通常可在托管控制面板中找到,或通过SSH/FTP直接访问服务器(如Apache访问日志、Nginx访问日志)。
- 识别AI用户代理:需掌握AI爬虫使用的特定用户代理字符串。虽然这些字符串可能变化,但常见类型包括:
- OpenAI(用于ChatGPT,如
ChatGPT-User或变体) - Perplexity AI(如
PerplexityBot) - Anthropic(Claude相关,但特征较弱或可能使用通用云服务商UA)
- 其他大型语言模型相关机器人(如谷歌AI项目的"GoogleBot"和Google-Extended,以及可能用于数据抓取的
Vercelbot等云基础设施机器人)
- OpenAI(用于ChatGPT,如
- 解析与分析:此处便需要前文提及的日志分析工具发挥作用。将原始日志文件上传至分析器后,即可开始筛选结果以识别AI爬虫和搜索机器人的活动。对于具备技术专长的用户,也可配置Python脚本或Splunk、Elasticsearch等工具来解析日志、识别特定用户代理并可视化数据。
尽管日志文件分析能提供最全面的数据,但对多数SEO从业者而言存在显著障碍:
- 技术门槛:需具备服务器访问权限、日志格式认知及数据解析技能。
- 资源密集型:大型网站产生的海量日志文件处理难度极高。
- 时间投入:建立完善的分析流程需前期投入大量精力。
- 解析难题:区分不同AI爬虫需掌握详细用户代理知识。
对于缺乏专职技术团队的企业而言,这些障碍可能使日志分析难以实施,尽管其价值显著。
更便捷的AI访问监控方案:SEO批量管理工具
日志文件分析虽能提供精细化数据,但其复杂性对技术水平较低的用户而言构成显著障碍。所幸SEO批量管理工具等解决方案能提供简化替代方案。
这款WordPress插件无需访问服务器日志或复杂配置,即可自动追踪并报告AI爬虫活动。其核心功能包括:
- 自动检测:无需手动配置即可识别主流AI爬虫(包括GPTBot、PerplexityBot和ClaudeBot)
- 用户友好仪表盘:通过直观界面呈现爬虫数据,满足各类技术水平的SEO从业者需求
- 实时监控:即时追踪AI爬虫访问行为,提供即时爬虫行为洞察
- 页面级分析:显示AI爬虫高频访问的具体页面,助力精准优化工作
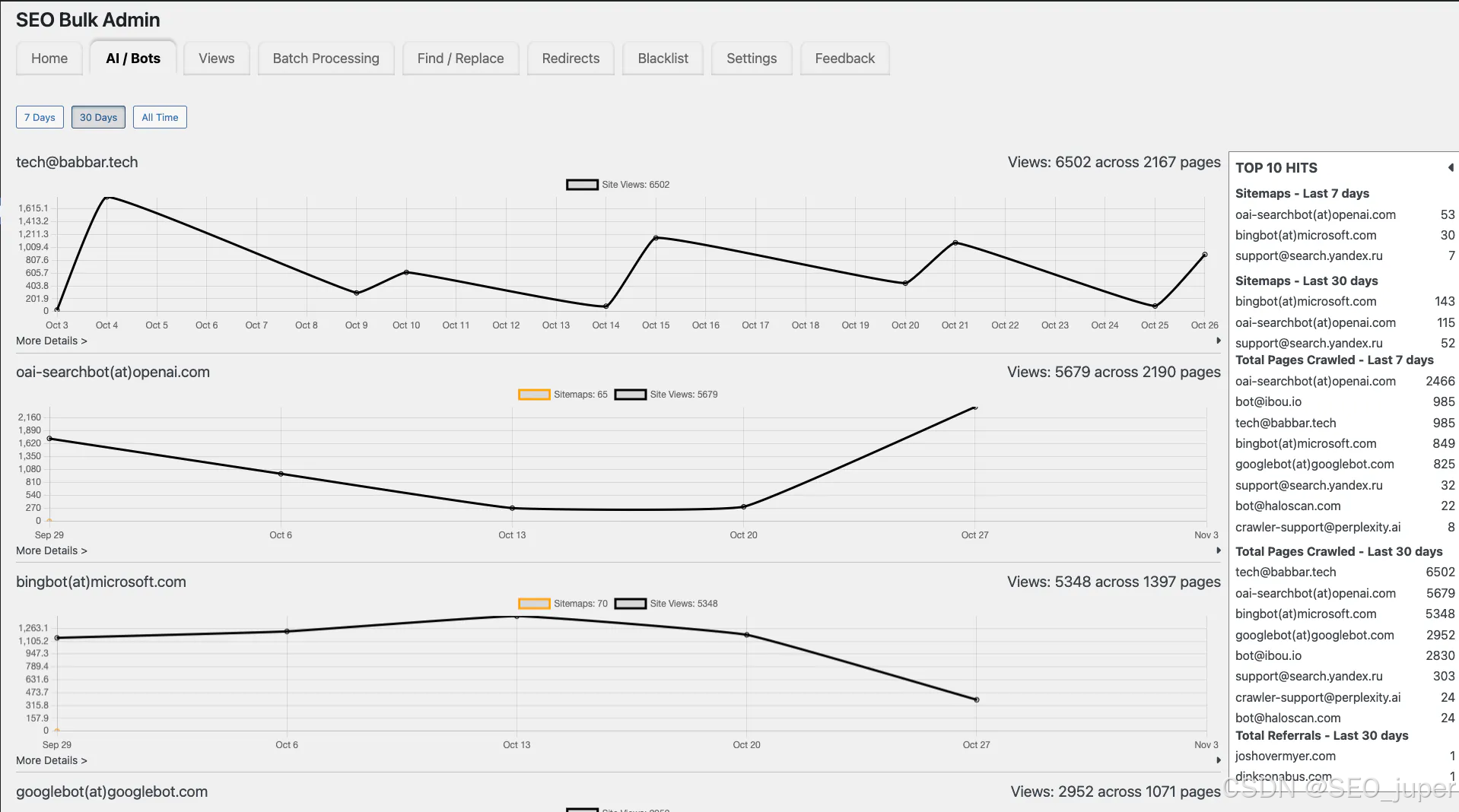
这使SEO从业者能够即时了解哪些页面被AI引擎访问------无需解析服务器日志或编写脚本。
SEO批量管理与日志文件分析对比
| 功能 | 日志文件分析 | SEO批量管理 |
|---|---|---|
| 数据来源 | 原始服务器日志 | WordPress仪表盘 |
| 技术门槛 | 高 | 低 |
| 机器人识别 | 手动 | 自动 |
| 爬取追踪 | 详细 | 自动化 |
| 适用场景 | 企业级SEO团队 | 内容导向型SEO与营销人员 |
对于无法直接访问服务器日志的团队,可基于数据做出优化决策。
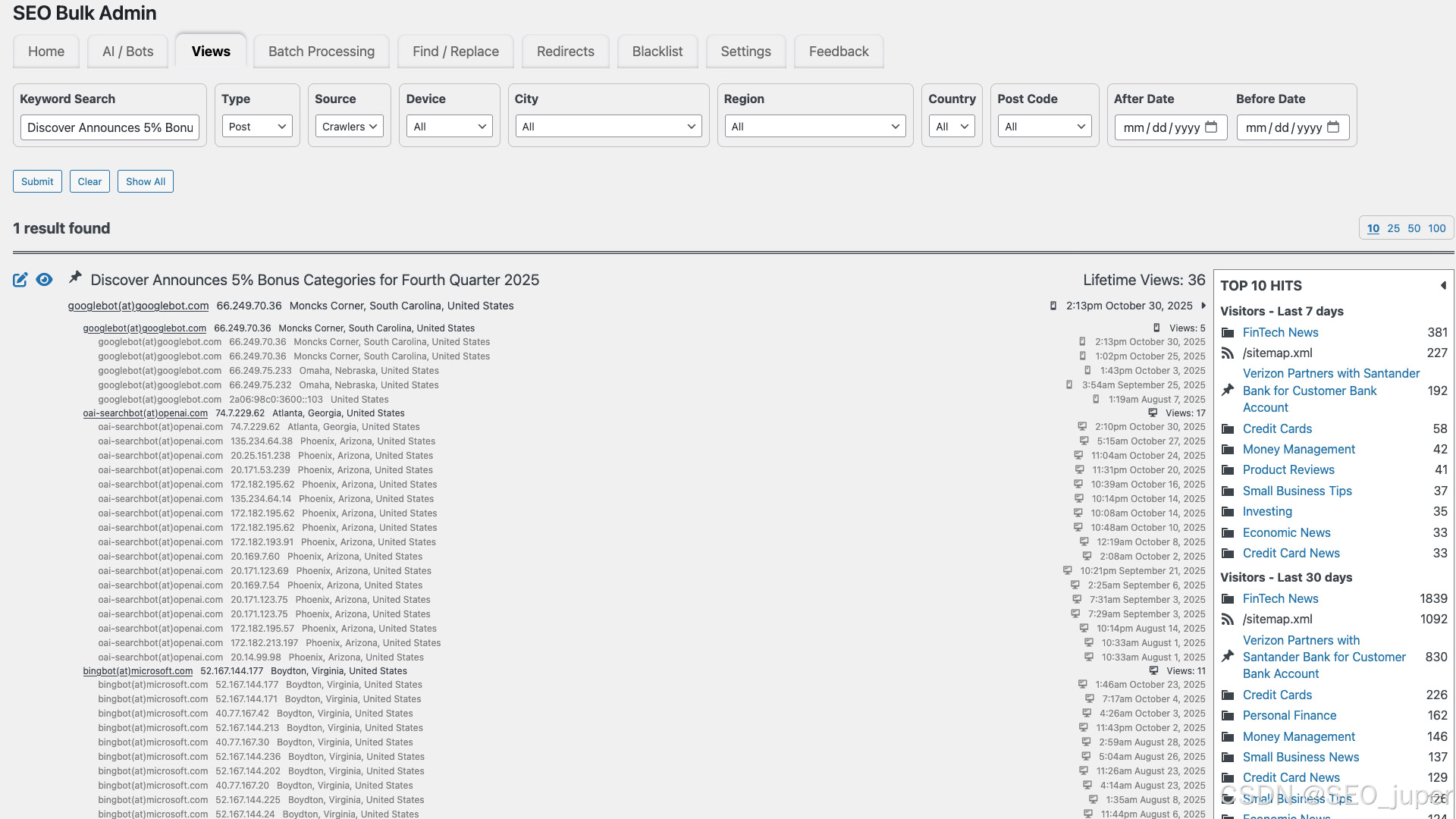
利用AI爬虫数据优化内容策略
一旦开始追踪AI爬虫活动,真正的优化工作才正式启动。AI爬虫数据揭示的规律能将内容策略从猜测转变为数据驱动的决策。
以下是运用这些洞察的方法:
1. 识别AI青睐的内容
- 高频访问页面:识别AI爬虫最常访问的页面。这些内容因其相关性、权威性或高频更新特性,持续吸引爬虫关注------往往正是用户搜索的热点领域。
- 特定内容类型:您的"操作指南"、术语解释页、研究摘要或常见问题板块是否获得异常高的爬虫关注?这揭示了AI模型最渴求的信息类型。
2. 识别大型语言模型偏好的内容模式
- 结构化数据相关性:高爬取率页面是否也富含结构化数据(模式标记)?这虽存有争议,但有观点认为AI模型常借助结构化数据更高效精准地提取信息。
- 清晰简洁性:AI模型擅长处理清晰无歧义的语言。在AI爬虫中表现优异的内容通常包含直接答案、简短段落和明确的主题分段。
- 权威性与引用度:被AI模型认定为可靠的内容往往被大量引用或有可信来源支撑。请追踪您权威性更强的页面是否也吸引了更多AI爬虫访问。
3. 从高绩效内容中创建蓝图
- 逆向分析成功要素:针对AI爬虫最青睐的内容,记录其特征。
- 内容结构:标题、副标题、项目符号、编号列表。
- 内容形式:纯文本、混合媒体、交互元素。
- 主题深度:全面性与专业性。
- 关键词/实体:高频出现的特定术语与实体。
- 结构化数据实现:采用何种模式类型?
- 内部链接模式:该内容如何关联其他相关页面?
- 优化低效内容:将成功属性应用于当前AI爬虫关注度较低的内容。
- 精炼内容结构:拆分冗长段落,增加标题层级,列表采用项目符号。
- 注入结构化数据:在缺失页面添加相关Schema标记(如
Q&A、HowTo、Article、FactCheck)。 - 提升清晰度:重写段落以实现简洁直接,重点清晰解答潜在用户疑问。
- 增强权威性:添加参考文献、链接权威来源或更新内容至最新见解。
- 优化内部链接:确保表现欠佳的相关页面与AI青睐的内容相互链接,形成主题集群信号。
最后
在AI驱动的搜索时代,追踪分析AI爬虫行为已成为SEO从业者保持竞争力的必选项。
通过日志分析工具------或借助SEO Bulk Admin简化流程------您可构建数据驱动策略,确保内容获得AI引擎青睐。
采取主动策略,识别AI爬虫活动的趋势,优化表现优异的内容,并对表现欠佳的页面应用最佳实践。
随着人工智能引领搜索引擎的进化浪潮,现在正是适应变革、把握对话式搜索引擎带来的新流量机遇的时机。