文章目录
摘要
本周阅读了DreamText的论文,并尝试复现论文,虽然设备上很难达到,但是如果通过微调和量化,可以减小模型的参数、训练和推理时间,也是一项有意义的工作。
Abstract
This week, I read the DreamText paper and tried to replicate it. Although it is difficult to achieve on my device, if we use fine-tuning and quantization, it can reduce the model's parameters, training, and inference time, which is also a meaningful task.
1 DreamText
本周阅读了论文DreamText: High Fidelity Scene Text Synthesis,文章描述的是场景文本合成,过去的方式会导致合成的文字重复、错位。

于是作者提出一种注意力引导布局掩码的方式来排布字体和风格。
作者注意到某些注意力缺失导致字符复制或错位;
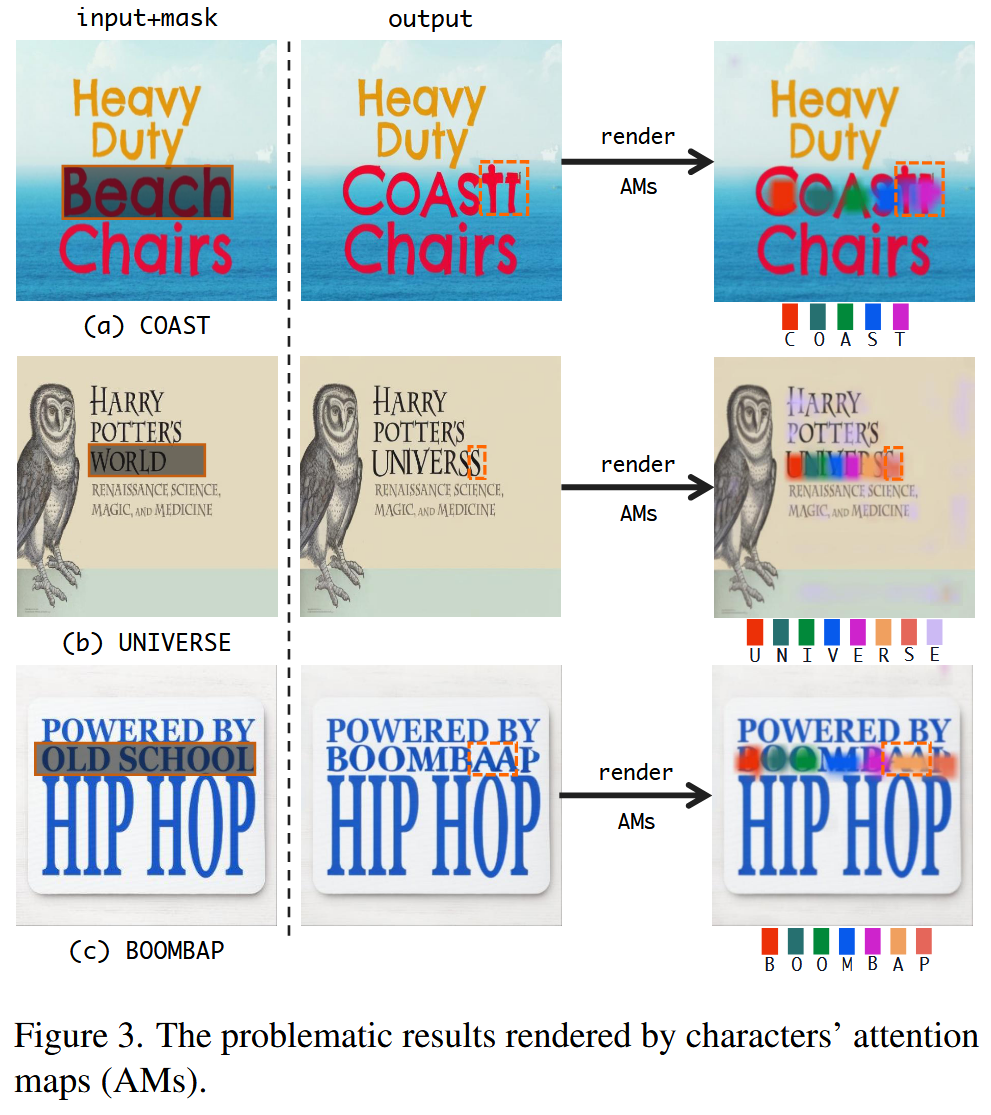
于是作者重构了扩散模型的训练过程,提供更细致的引导:
(1)通过分析扩散模型中的交叉注意力图(cross-attention maps),提取每个字符可能应生成的位置信息。
(2)将这些信息转化为潜在字符掩码(latent character masks),用于告诉模型"每个字符应该关注图像的哪一部分"。
(3)利用这些掩码反过来优化文本编码器(text encoder)中对应字符的表示,从而让模型在下一轮迭代中更准确地聚焦于正确的区域。
具体做法是同时训练文本编码器和图像生成器(generator),利用训练数据中丰富的字体样式,扩展字符的表示能力(character representation space)。这种联合训练能与上述的迭代优化过程无缝结合,使得字符表示学习和位置注意力校准相互促进(synergistic interplay)。
在训练初期,模型还不知道字符该放在哪里,因此作者使用字符分割掩码(character segmentation masks)作为外部监督信号,帮助模型"热身"(warm-up),校准初始注意力。之后模型初步学会估计理想位置(比如几十个训练 epoch 后),就移除外部监督,让模型自主学习和优化。这种策略避免了像以往方法那样强制约束注意力(rigidly constrain attention),既提供了初期引导,又保留了后期的灵活性。
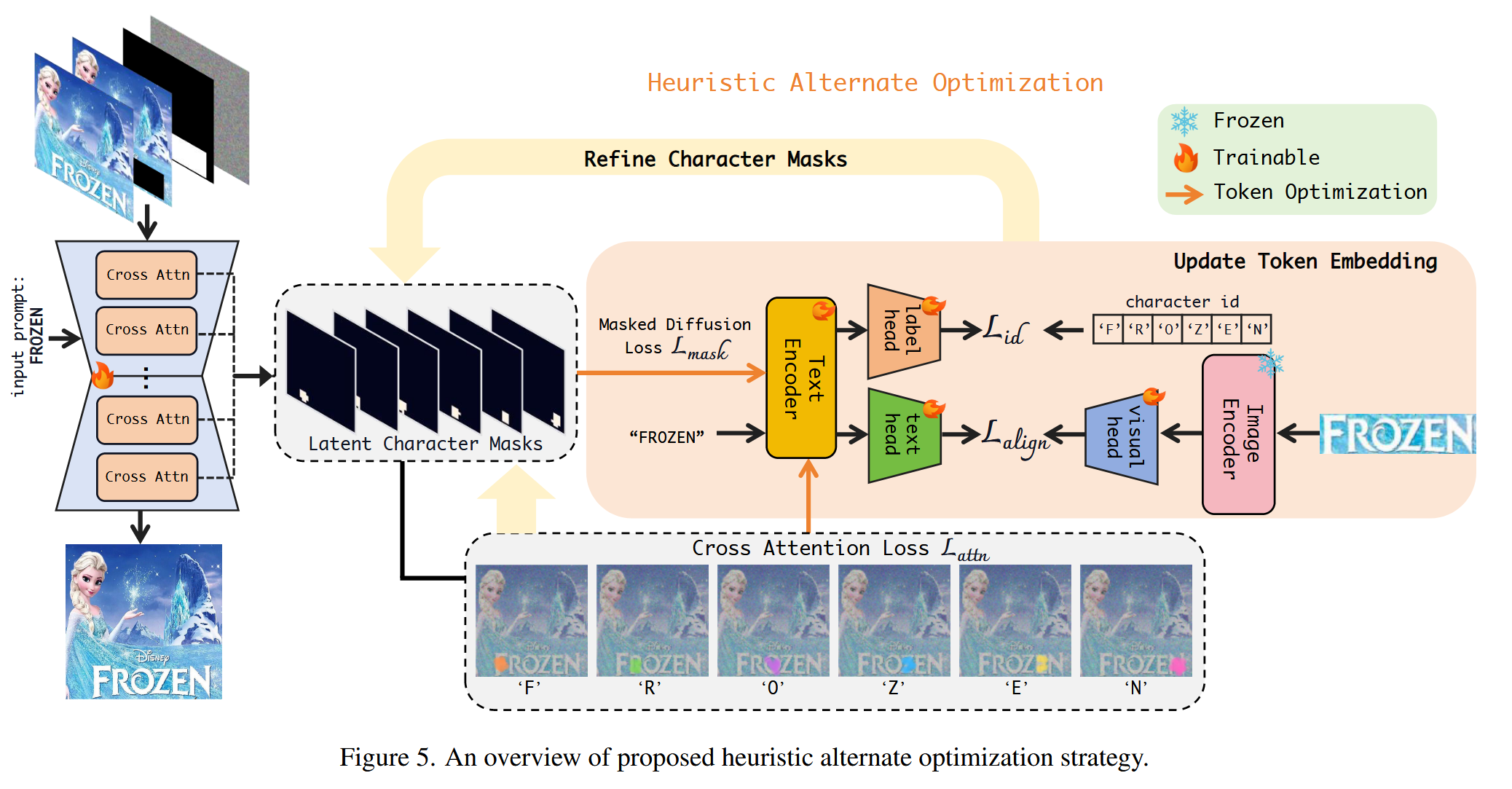
模型的效果如下图
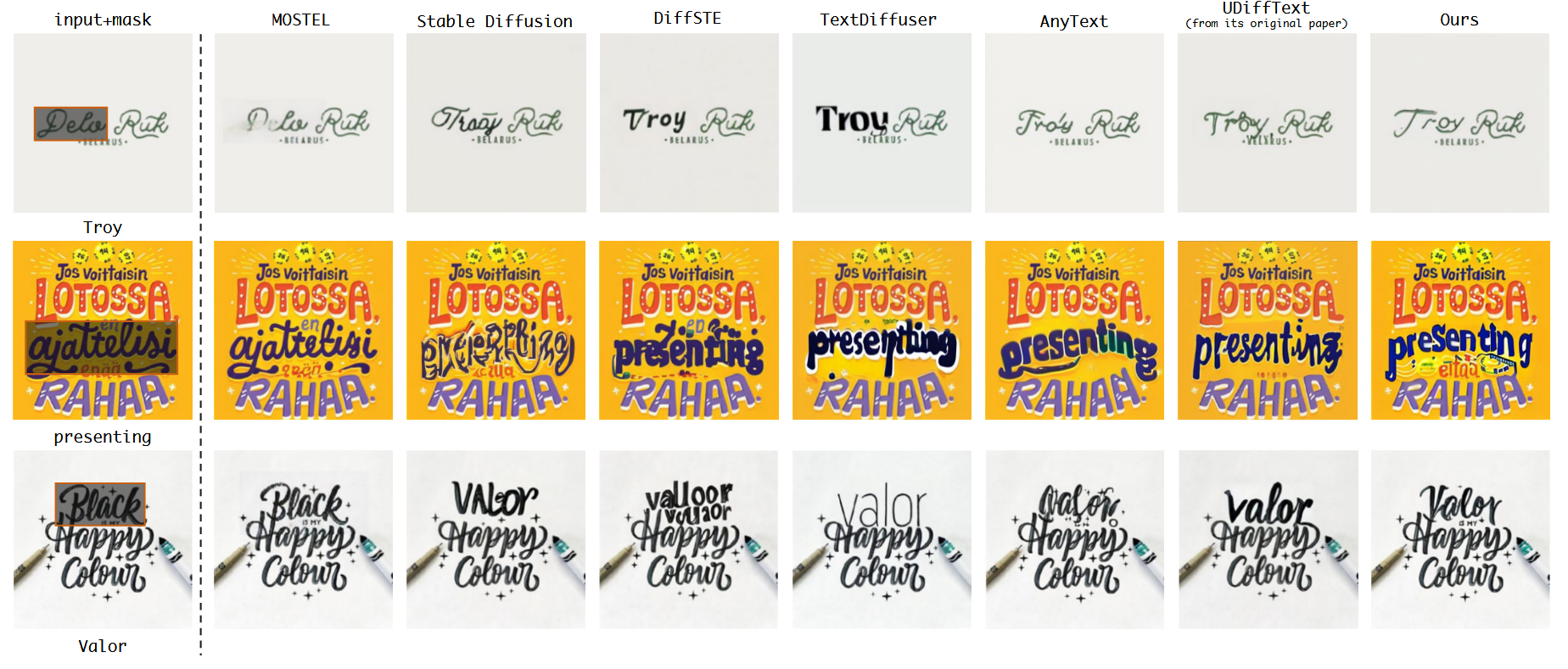
在数据集上的选择有SynthText、LAION-OCR、ICDAR13、TextSeg四个数据集,分别在这四个数据集上训练模型150k、200k、10k和50k步,这个模型是一个比较大的模型,在四张A100上训练,最后的推理时间为8.5s一张图片。
2 Stable Diffusion
第一节所说的论文是在Stable Diffusionv2的baseline上实现的,阅读了stable diffusin的源码后,对之前本人实现的ddpm进行了修改,数据集采用的是anime数据集,其他实现对于Cifar数据集的模型参数已经达到了30M左右,而受限于设备原因,实现的DDPM模型只有8M,对于anime数据集(36464大小),得到的推理效果并不好,当然也不完全是参数的原因,还有损失函数的实现的问题。
python
import math
import os
import torch
import torch.nn as nn
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
torch.manual_seed(42)
def embed(t, d_model, max_len=1000):
half = d_model // 2
freqs = torch.exp(-math.log(max_len) * torch.arange(start=0, end=half, dtype=torch.float32) / half).to(
device=t.device)
args = t[:, None].float() * freqs[None]
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
if d_model % 2:
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
return embedding
def forward(x, t, beta, device='cpu'):
alpha = 1 - beta
alpha_bar = torch.cumprod(alpha, dim=0)
alpha_bar_t = alpha_bar[t].view(-1, 1, 1, 1) # 适应图像维度
noise = torch.randn_like(x, device=device)
x_t = torch.sqrt(alpha_bar_t) * x + torch.sqrt(1 - alpha_bar_t) * noise
return x_t, noise
def sample(model, num_images=5, image_size=(3, 64, 64), device='cpu'):
model.eval()
beta = torch.linspace(0.0001, 0.02, 1000, device=device)
alpha = 1 - beta
alpha_bar = torch.cumprod(alpha, dim=0)
with torch.no_grad():
x = torch.randn(num_images, *image_size, device=device)
for t in reversed(range(1000)):
t_tensor = torch.tensor([t] * num_images, device=device)
output = model(x, t_tensor)
alpha_bar_t = alpha_bar[t]
alpha_t = alpha[t]
mean = (1 / torch.sqrt(alpha_t)) * (x - ((1 - alpha_t) / torch.sqrt(1 - alpha_bar_t)) * output)
if t > 0:
alpha_prev = alpha_bar[t - 1]
sigma_t = torch.sqrt((1 - alpha_prev) / (1 - alpha_bar_t) * beta[t])
noise = torch.randn_like(x, device=device)
x = mean + sigma_t * noise # 关键:添加随机性!
else:
x = mean
x = (x + 1) / 2
x = torch.clamp(x, 0.0, 1.0)
return x
class MyDataset(Dataset):
def __init__(self, path, transform=None):
self.path = path
self.transform = transform
self.data = [f for f in os.listdir(self.path)]
def __len__(self):
return len(self.data)
def __getitem__(self, index):
img_name = self.data[index]
img_path = os.path.join(self.path, img_name)
image = self.transform(Image.open(img_path).convert('RGB'))
return image
def Normalize(in_channels, num_groups=32):
return torch.nn.GroupNorm(num_groups=num_groups, num_channels=in_channels, eps=1e-6, affine=True)
class ResnetBlock(nn.Module):
def __init__(self, in_channels, out_channels, time_channels, dropout):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.conv1 = nn.Sequential(
Normalize(in_channels),
nn.SiLU(),
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
)
self.time_emb = nn.Sequential(
nn.SiLU(),
nn.Linear(time_channels, out_channels)
)
self.conv2 = nn.Sequential(
Normalize(out_channels),
nn.SiLU(),
nn.Dropout(p=dropout),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
)
if self.in_channels != self.out_channels:
self.shortcut = nn.Conv2d(in_channels, out_channels, kernel_size=1)
else:
self.shortcut = nn.Identity()
def forward(self, x, t):
h = self.conv1(x)
h += self.time_emb(t)[:, :, None, None]
h = self.conv2(h)
return h + self.shortcut(x)
class Attention(nn.Module):
def __init__(self, d_k):
super().__init__()
self.d_k = d_k
def forward(self, q, k, v, pos=None, mask=None):
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)
if pos is not None:
scores = scores + pos
if mask is not None:
scores = scores + mask * (-100)
attention_weights = torch.softmax(scores, dim=-1)
attention = torch.matmul(attention_weights, v)
return attention
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
assert d_model % num_heads == 0, "向量大小与头数要整除"
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.attention = Attention(self.d_k)
self.linear = nn.Linear(d_model, d_model)
def forward(self, q, k, v, pos=None, mask=None):
batch_size, seq_len = q.size(0), q.size(1)
q = self.w_q(q)
k = self.w_k(k)
v = self.w_v(v)
q = q.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
k = k.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
v = v.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
attention_output = self.attention(q, k, v, pos, mask)
attention_output = attention_output.transpose(1, 2).contiguous().view(
batch_size, seq_len, self.d_model)
output = self.linear(attention_output)
return output
class DownSample(nn.Module):
def __init__(self, d_model, use_conv):
super().__init__()
self.use_conv = use_conv
if use_conv:
self.layer = nn.Conv2d(d_model, d_model, kernel_size=3, stride=2, padding=1)
else:
self.layer = nn.AvgPool2d(kernel_size=2,stride=2)
def forward(self, x):
return self.layer(x)
class UpSample(nn.Module):
def __init__(self, d_model, use_conv):
super().__init__()
self.use_conv = use_conv
if use_conv:
self.conv = nn.Conv2d(d_model, d_model, kernel_size=3, stride=1, padding=1)
def forward(self, x):
x = nn.functional.interpolate(x, scale_factor=2, mode="nearest")
if self.use_conv:
x = self.conv(x)
return x
class Unet(nn.Module):
def __init__(self,
in_channels=3,
model_channels=128,
out_channels=None,
num_res_blocks=2,
attention_resolutions=(16, 8),
dropout=0.1,
channel_mult=(1, 2, 2, 2),
num_heads=4,
max_len=1000
):
super().__init__()
if out_channels is None:
out_channels = in_channels
self.in_channels = in_channels
self.model_channels = model_channels
self.out_channels = out_channels
self.max_len = max_len
time_embed_dim = model_channels * 4
self.time_embed = nn.Sequential(
nn.Linear(model_channels, time_embed_dim),
nn.SiLU(),
nn.Linear(time_embed_dim, time_embed_dim),
)
self.input_blocks = nn.ModuleList([
nn.Conv2d(in_channels, model_channels, 3, padding=1)
])
input_block_chans = [model_channels]
ch = model_channels
ds = 1 # current resolution downsample factor
for level, mult in enumerate(channel_mult):
for _ in range(num_res_blocks):
layers = [ResnetBlock(ch, mult * model_channels, time_embed_dim, dropout)]
ch = mult * model_channels
if ds in attention_resolutions:
layers.append(MultiHeadAttention(ch, num_heads))
self.input_blocks.append(nn.Sequential(*layers))
input_block_chans.append(ch)
if level != len(channel_mult) - 1:
self.input_blocks.append(DownSample(ch, use_conv=True))
input_block_chans.append(ch)
ds *= 2
self.middle_block = nn.Sequential(
ResnetBlock(ch, ch, time_embed_dim, dropout),
MultiHeadAttention(ch, num_heads),
ResnetBlock(ch, ch, time_embed_dim, dropout),
)
self.output_blocks = nn.ModuleList([])
for level, mult in list(enumerate(channel_mult))[::-1]:
for i in range(num_res_blocks + 1):
ich = input_block_chans.pop()
layers = [ResnetBlock(ch + ich, model_channels * mult, time_embed_dim, dropout)]
ch = model_channels * mult
if ds in attention_resolutions:
layers.append(MultiHeadAttention(ch, num_heads))
if level and i == num_res_blocks:
layers.append(UpSample(ch, use_conv=True))
ds //= 2
self.output_blocks.append(nn.Sequential(*layers))
self.out = nn.Sequential(
Normalize(ch),
nn.SiLU(),
nn.Conv2d(ch, out_channels, 3, padding=1),
)
def forward(self, x, t):
t_emb = embed(t, self.model_channels, self.max_len)
t_emb = self.time_embed(t_emb)
hs = []
h = x
for module in self.input_blocks:
if isinstance(module, (nn.Conv2d, DownSample)):
h = module(h)
elif isinstance(module, ResnetBlock):
h = module(h, t_emb)
elif isinstance(module, MultiHeadAttention):
b, c, h_, w_ = h.shape
h_flat = h.view(b, c, -1).transpose(1, 2) # [B, HW, C]
h_attn = module(h_flat, h_flat, h_flat)
h = h_attn.transpose(1, 2).view(b, c, h_, w_)
elif isinstance(module, nn.Sequential):
for layer in module:
if isinstance(layer, ResnetBlock):
h = layer(h, t_emb)
elif isinstance(layer, MultiHeadAttention):
b, c, h_, w_ = h.shape
h_flat = h.view(b, c, -1).transpose(1, 2)
h_attn = layer(h_flat, h_flat, h_flat)
h = h_attn.transpose(1, 2).view(b, c, h_, w_)
else:
h = layer(h)
hs.append(h)
h = self.middle_block[0](h, t_emb)
b, c, h_, w_ = h.shape
h_flat = h.view(b, c, -1).transpose(1, 2)
h_attn = self.middle_block[1](h_flat, h_flat, h_flat)
h = h_attn.transpose(1, 2).view(b, c, h_, w_)
h = self.middle_block[2](h, t_emb)
for module in self.output_blocks:
h_skip = hs.pop()
h = torch.cat([h, h_skip], dim=1)
if isinstance(module, nn.Sequential):
for layer in module:
if isinstance(layer, ResnetBlock):
h = layer(h, t_emb)
elif isinstance(layer, MultiHeadAttention):
b, c, h_, w_ = h.shape
h_flat = h.view(b, c, -1).transpose(1, 2)
h_attn = layer(h_flat, h_flat, h_flat)
h = h_attn.transpose(1, 2).view(b, c, h_, w_)
elif isinstance(layer, UpSample):
h = layer(h)
else:
h = layer(h)
else:
h = module(h)
return self.out(h)
def train(model, epoches, train_loader, loss_func, optimizer, device):
model.train()
beta = torch.linspace(0.0001, 0.02, 1000, device=device) # 预先定义好的variance schedule
for epoch in range(epoches):
total_loss = 0
total = 0
for _, image in enumerate(train_loader):
image = image.to(device)
batch_size = image.shape[0]
t = torch.randint(0, 1000, (batch_size,), device=device)
x, noise = forward(image, t, beta, device)
output = model(x, t)
loss = loss_func(output, noise)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
total += 1
print(f'Epoch {epoch + 1}, Loss: {total_loss / total:.4f}')
def test(model, device, num=5):
image = sample(model, num, device=device)
for i in range(num):
img = transforms.ToPILImage()(image[i].cpu())
save_path = os.path.join('./data/result', f'anime_{i}.png')
img.save(save_path)
if __name__ == '__main__':
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# train_dataset = torchvision.datasets.MNIST(root='./data', train=True, download=False,
# transform=transforms.ToTensor())
# train_loader = DataLoader(dataset=train_dataset, batch_size=256, shuffle=True)
train_dataset = MyDataset(path='./data/anime', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
model = Unet(model_channels=64).to(device)
print(f"模型参数量: {sum(p.numel() for p in model.parameters())}")
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
train(
model=model,
epoches=10,
train_loader=train_loader,
loss_func=loss_func,
optimizer=optimizer,
device=device
)
test(
model=model,
device=device,
num=5
总结
本周完成了 DreamText 论文的系统性研读,明确了模型核心原理与训练逻辑;在复现受阻时规划了可行的优化路径;同时推进了 DDPM 模型的修改与调试,为后续模型性能提升积累了实践经验。