Python基础(二)
第四章:字符串
在网站登录场景中,用户输入的账号密码、页面展示的文字信息,本质上都是字符串------ 由字母、数字、符号组成的字符序列。
4.1 字符串基础:定义与转义
4.1.1 字符串的 3 种定义方式
Python 支持单引号、双引号、三引号三种定义形式,适配不同使用场景:
| 定义方式 | 适用场景 | 代码示例 | 输出结果 |
|---|---|---|---|
单引号 ' ' |
单行字符串(无嵌套单引号) | print('使用单引号在一行输出') |
使用单引号在一行输出 |
双引号 " " |
单行字符串(可嵌套单引号) | print("let's go") |
let's go |
三引号 """ """/''' ''' |
多行字符串、保留格式 | print("""使用三引号\n进行多行输出""") |
使用三引号进行多行输出 |
4.1.2 转义字符:处理特殊符号
当字符串中包含与定义符号冲突的字符(如单引号内套单引号),或需要表示不可见字符(如换行、回车)时,需使用反斜杠 \ 进行转义:
常见转义字符表
| 转义字符 | 含义 | 示例 | 输出 |
|---|---|---|---|
\' |
单引号 | print('let\'s go') |
let's go |
\" |
双引号 | print("He said \"Hello\"") |
He said "Hello" |
\\ |
反斜杠 | print('E:\\python\\code') |
E:\python\code |
\n |
换行 | print('第一行\n第二行') |
第一行第二行 |
\t |
制表符(Tab) | print('姓名\t年龄') |
姓名 年龄 |
\r |
回车(覆盖当前行) | print('Hello\rHi') |
Hi |
\b |
退格(删除前一个字符) | print('abc\bd') |
abd |
4.1.3 字符串遍历
字符串是可迭代对象,可通过 for 循环遍历每个字符:
python
s = "Python"
for i in s:
print(i, end=" ") # 输出:P y t h o n4.2 格式化字符串:3 种核心方式
格式化字符串的核心需求是:将变量 / 数据嵌入字符串指定位置,生成自定义格式的新字符串。Python 提供 3 种主流方式,各有优劣:
4.2.1 方式 1:% 格式化(传统方式)
通过 % 连接格式化模板和数据,模板中用格式符占位,适用于简单场景。
语法结构
python
模板字符串 % (数据1, 数据2, ...)常见格式符表
| 格式符 | 对应数据类型 | 说明 |
|---|---|---|
%s |
字符串(万能格式符,可兼容数字 / 对象) | 推荐优先使用 |
%d |
整数(十进制) | 支持正负整数 |
%f |
浮点数 | 可指定小数位数(如 %.2f 保留 2 位) |
%x |
整数(十六进制) | 小写字母 |
%X |
整数(十六进制) | 大写字母 |
实战示例
python
# 1. 单个数据格式化
age = 20
print("我今年%d岁" % age) # 输出:我今年20岁
# 2. 多个数据格式化(需用元组包裹)
name = "jerry"
height = 1.75
print("姓名:%s,年龄:%d,身高:%.2f米" % (name, age, height))
# 输出:姓名:jerry,年龄:20,身高:1.75米
# 3. 万能格式符 %s(兼容所有类型)
print("数字:%s,列表:%s" % (100, [1,2,3]))
# 输出:数字:100,列表:[1, 2, 3]注意事项
- 数据个数需与格式符数量一致,否则报错
- 数据类型需与格式符匹配(如
%d不能接收字符串),否则抛出TypeError
4.2.2 方式 2:format () 方法
Python 2.6+ 新增的格式化方法,通过 {} 占位,无需关注数据类型,支持灵活的位置指定和格式控制,比 % 更直观、强大。
语法结构
python
模板字符串.format(数据1, 数据2, ...)核心用法
| 用法 | 代码示例 | 输出结果 |
|---|---|---|
| 按顺序占位 | print("姓名:{},年龄:{}".format("tom", 20)) |
姓名:tom,年龄:20 |
| 按索引占位 | print("年龄:{1},姓名:{0}".format("tom", 20)) |
年龄:20,姓名:tom |
| 按名称占位 | print("姓名:{name},年龄:{age}".format(name="tom", age=20)) |
姓名:tom,年龄:20 |
| 格式化浮点数 | print("身高:{:.2f}米".format(1.753)) |
身高:1.75 米 |
| 格式化整数(补零) | print("编号:{:03d}".format(5)) |
编号:005 |
| 千位分隔符 | print("收入:{:,}元".format(1234567)) |
收入:1,234,567 元 |
优势
- 无需匹配数据类型,兼容性更强
- 支持灵活的位置 / 名称指定,不易出错
- 提供丰富的格式控制(如小数精度、补零、千分位)
4.2.3 方式 3:f-string 格式化(Python 3.6+)
以 f 或 F 开头的字符串,直接在 {} 中嵌入变量 / 表达式,语法最简洁、执行效率最高,是 Python 3.6+ 推荐的格式化方式。
语法结构
python
f"字符串内容{变量/表达式}"实战示例
python
# 1. 嵌入变量
name = "tom"
age = 20
print(f"姓名:{name},年龄:{age}") # 输出:姓名:tom,年龄:20
# 2. 嵌入表达式(直接计算)
a = 10
b = 20
print(f"{a} + {b} = {a + b}") # 输出:10 + 20 = 30
# 3. 格式化控制(与format()语法一致)
height = 1.753
print(f"身高:{height:.2f}米") # 输出:身高:1.75米
# 4. 嵌套字典/列表
person = {"name": "jerry", "age": 22}
print(f"姓名:{person['name']},年龄:{person['age']}") # 输出:姓名:jerry,年龄:22优势
- 语法极简,直接嵌入变量,可读性最高
- 支持表达式计算,无需额外拼接
- 执行效率比
%和format()更高 - 格式控制灵活,兼容
format()的所有格式语法
4.2.4 三种格式化方式对比
| 格式化方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
% 格式化 |
语法简单,兼容 Python 2 | 类型匹配严格,扩展性差 | 简单场景、老项目维护 |
format() 方法 |
类型无关,格式灵活,兼容性好 | 语法略繁琐 | Python 2.6+ 项目,复杂格式控制 |
| f-string | 语法简洁,效率最高,支持表达式 | 仅支持 Python 3.6+ | Python 3.6+ 新项目(推荐) |
4.3 实战案例:打印 99 乘法表(字符串格式化应用)
结合字符串格式化和循环,打印格式整齐的 99 乘法表:
python
for i in range(1, 10):
for j in range(1, i + 1):
# 使用f-string格式化,\t保证对齐
print(f"{i} x {j} = {i*j}", end="\t")
print() # 换行输出结果:
plaintext
1 x 1 = 1
2 x 1 = 2 2 x 2 = 4
3 x 1 = 3 3 x 2 = 6 3 x 3 = 9
4 x 1 = 4 4 x 2 = 8 4 x 3 = 12 4 x 4 = 16
5 x 1 = 5 5 x 2 = 10 5 x 3 = 15 5 x 4 = 20 5 x 5 = 25
6 x 1 = 6 6 x 2 = 12 6 x 3 = 18 6 x 4 = 24 6 x 5 = 30 6 x 6 = 36
7 x 1 = 7 7 x 2 = 14 7 x 3 = 21 7 x 4 = 28 7 x 5 = 35 7 x 6 = 42 7 x 7 = 49
8 x 1 = 8 8 x 2 = 16 8 x 3 = 24 8 x 4 = 32 8 x 5 = 40 8 x 6 = 48 8 x 7 = 56 8 x 8 = 64
9 x 1 = 9 9 x 2 = 18 9 x 3 = 27 9 x 4 = 36 9 x 5 = 45 9 x 6 = 54 9 x 7 = 63 9 x 8 = 72 9 x 9 = 81 注意:
- 字符串定义:优先使用单 / 双引号(单行)、三引号(多行),冲突时用转义字符
- 转义字符:
\n(换行)、\t(制表符)、\\(反斜杠)是高频使用场景 - 格式化方案:
- 简单场景:
%格式化 - 兼容需求:
format()方法 - 现代开发:f-string(推荐,简洁高效)
- 简单场景:
- 实战技巧:结合字符串格式化和循环,可快速实现格式化输出需求(如报表、表格)
4.4:字符串的常见操作
字符串是 Python 中最基础且常用的数据类型之一,在文本处理、数据清洗、爬虫开发等场景中都有着广泛应用。Python 内置了丰富的字符串方法,能轻松实现查找、替换、分割、拼接等核心操作。需要注意的是:字符串是不可变对象,所有修改操作都会返回新字符串,不会改变原字符串。
4.4.1:字符串的查找与替换
1. 查找子串:find () 方法
find() 用于判断字符串中是否包含指定子串,返回子串首次出现的索引(从 0 开始),若未找到则返回 -1。
语法格式
python
str.find(sub[, start[, end]])sub:必需,指定要查找的目标子串start:可选,查找起始索引(默认 0)end:可选,查找结束索引(默认字符串长度,不包含该索引)
实用示例
python
# 基础查找
string = "Python编程:从入门到精通"
print(string.find("编程")) # 结果:6("编"字的索引)
print(string.find("Java")) # 结果:-1(未找到)
# 指定查找范围(索引3~10)
print(string.find("从", 3, 10)) # 结果:92. 替换子串:replace () 方法
replace() 用于将字符串中的指定子串替换为新子串,返回替换后的新字符串。
语法格式
python
str.replace(old, new[, count])old:必需,被替换的旧子串new:必需,替换后的新子串count:可选,替换次数(默认 - 1,表示全部替换)
实用示例
python
# 全部替换
poem = "八百标兵奔北坡,北坡炮兵并排跑。炮兵怕把标兵碰,标兵怕碰炮兵炮。"
new_poem = poem.replace("标兵", "战士")
print(new_poem)
# 输出:八百战士奔北坡,北坡炮兵并排跑。炮兵怕把战士碰,战士怕碰炮兵炮。
# 指定替换次数(只替换前2个)
new_poem2 = poem.replace("标兵", "战士", 2)
print(new_poem2)
# 输出:八百战士奔北坡,北坡炮兵并排跑。炮兵怕把战士碰,标兵怕碰炮兵炮。4.4.2:字符串的分割与拼接
分割与拼接是文本处理的高频操作,常用于日志解析、数据格式化等场景。
1. 字符串分割:split () 方法
split() 按照指定分隔符分割字符串,返回由子串组成的列表。
语法格式
python
str.split(sep=None, maxsplit=-1)sep:可选,分隔符(默认 None,以空格、制表符、换行符等空白字符分割)maxsplit:可选,最大分割次数(默认 - 1,不限制次数)
实用示例
python
# 以空白字符分割(默认行为)
text = "八百标兵奔北坡 北坡炮兵并排跑 炮兵怕把标兵碰"
print(text.split()) # 结果:['八百标兵奔北坡', '北坡炮兵并排跑', '炮兵怕把标兵碰']
# 以指定字符分割
print(text.split("兵")) # 结果:['八百标', '奔北坡 北坡炮', '并排跑 炮', '怕把标', '碰']
# 限制分割次数(只分割2次)
print(text.split("兵", 2)) # 结果:['八百标', '奔北坡 北坡炮', '并排跑 炮兵怕把标兵碰']2. 字符串拼接:join () 方法 + 运算符
(1)join () 方法(推荐)
join() 用指定字符连接可迭代对象(字符串、列表等)中的元素,返回新字符串(效率高于 + 运算符)。
语法格式
python
str.join(iterable)str:连接符(如-、|、空格等)iterable:必需,可迭代对象(元素必须是字符串类型)
(2)运算符拼接
+:直接连接两个字符串*:重复拼接字符串(倍数连接)
实用示例
python
# join() 方法拼接
symbol = "-"
word = "Python"
print(symbol.join(word)) # 结果:P-y-t-h-o-n
# 拼接列表元素
fruits = ["苹果", "香蕉", "橙子"]
print("、".join(fruits)) # 结果:苹果、香蕉、橙子
# 运算符拼接
a = "Py"
b = "thon"
print(a + b) # 结果:Python(直接连接)
print(b * 3) # 结果:thonthonthon(重复3次)4.4.3:删除字符串的指定字符
常用于清理字符串前后的空白字符、特殊符号(如 *、#)等无用字符。
核心方法对比
| 方法 | 功能描述 |
|---|---|
strip() |
删除字符串首尾指定字符(默认空白字符) |
lstrip() |
删除字符串开头(左侧)指定字符 |
rstrip() |
删除字符串结尾(右侧)指定字符 |
实用示例
python
# 清理空白字符
text = " 人生苦短,我用Python! "
print(text.strip()) # 结果:人生苦短,我用Python!(首尾去空格)
print(text.lstrip()) # 结果:人生苦短,我用Python! (仅去左侧空格)
print(text.rstrip()) # 结果: 人生苦短,我用Python!(仅去右侧空格)
# 清理特殊符号
text2 = "***Python编程入门***"
print(text2.strip("*")) # 结果:Python编程入门(首尾去*)
print(text2.lstrip("*")) # 结果:Python编程入门***(仅去左侧*)4.4.4:字符串大小写转换
主要用于英文文本的格式标准化(如用户输入统一、文档标题格式化等)。
核心方法对比
| 方法 | 功能描述 |
|---|---|
upper() |
全部字符转换为大写 |
lower() |
全部字符转换为小写 |
capitalize() |
字符串首字母大写,其余小写 |
title() |
每个单词首字母大写(以空白字符分隔) |
实用示例
python
string = "Life is short. I use Python"
print(string.upper()) # 结果:LIFE IS SHORT. I USE PYTHON
print(string.lower()) # 结果:life is short. i use python
print(string.capitalize()) # 结果:Life is short. i use python
print(string.title()) # 结果:Life Is Short. I Use Python4.4.5:字符串对齐
用于字符串格式化输出(如控制台日志、报表生成等场景),支持居中、左对齐、右对齐。
核心方法对比
| 方法 | 功能描述 |
|---|---|
center(width, fillchar) |
居中对齐,指定总长度和填充字符(默认空格) |
ljust(width, fillchar) |
左对齐,指定总长度和填充字符(默认空格) |
rjust(width, fillchar) |
右对齐,指定总长度和填充字符(默认空格) |
实用示例
python
string = "hello world"
# 总长度15,填充字符为"-"
print(string.center(15, "-")) # 结果:--hello world--(居中)
# 总长度15,填充字符为"*"
print(string.ljust(15, "*")) # 结果:hello world****(左对齐)
# 总长度15,填充字符为"%"
print(string.rjust(15, "%")) # 结果:%%%%hello world(右对齐)第五章:组合数据类型
在大数据时代,程序常需处理多种类型的混合数据。Python 的组合数据类型可将多个相同或不同类型的数据组织为整体,让数据表示更清晰,同时简化开发、提升效率。
5.1:认识组合数据类型
组合数据类型按组织方式分为三类,核心特性与适用场景各有侧重:
1. 序列类型
- 核心代表:字符串(str)、列表(list)、元组(tuple)
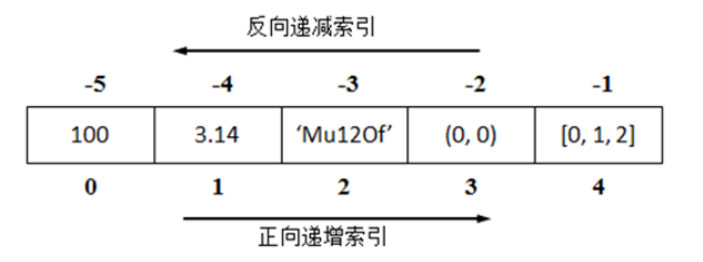
- 关键特性:支持双向索引(正向从 0 开始,反向从 - 1 开始),元素有序可访问
- 核心优势:可按位置精准操作元素,适合需要保持顺序的数据存储
2. 集合类型
- 核心特性:确定性(元素是否存在明确)、互异性(元素无重复)、无序性(顺序不影响集合相等)
- 元素要求:仅支持不可变类型(整型、浮点型、字符串、元组),不支持列表、字典、集合本身
- 核心优势:自动去重,适合数据去重、关系判断(交集、并集等)场景
3. 映射类型
- 核心代表:字典(dict),唯一内置映射类型
- 存储形式:键值对(key-value),键与值存在映射关系
- 键的规则:每个键仅对应一个值(不可重复),且键必须是不可变类型
- 核心优势:通过键快速查找值,适合存储具有关联关系的数据
5.2:列表(list):灵活多变的序列王者
列表是 Python 最灵活的序列类型,无长度限制,可包含任意类型元素,支持增删改查、排序等全方位操作。
5.2.1 创建列表:两种常用方式
列表创建简单直接,支持空列表、非空列表,以及从可迭代对象转换:
python
# 1. 中括号[]创建(推荐,简洁高效)
list_empty = [] # 空列表
list_mix = [1, "python", 3.14, [2, 3]] # 混合类型元素(基本类型+组合类型)
list_same = [1, 2, 3, 4] # 同类型元素
# 2. list()函数创建(适合从可迭代对象转换)
list_from_str = list("python") # 从字符串转换:['p','y','t','h','o','n']
list_from_iter = list([1,2,3]) # 从其他可迭代对象转换
list_empty2 = list() # 空列表- 可迭代对象说明:支持 for...in... 循环的对象(字符串、列表、集合、字典、文件等)
- 判断方法:
isinstance(对象, Iterable),返回 True 则为可迭代对象
5.2.2 访问列表元素:三种核心方式
(1)索引访问
通过正向 / 反向索引直接定位元素,类似图书目录快速查找:
python
list_dev = ['java', 'c#', 'python', 'php']
print(list_dev[0]) # 正向索引:取第一个元素,输出'java'
print(list_dev[-3]) # 反向索引:取倒数第三个元素,输出'c#'(2)切片访问
截取列表部分元素,返回新列表,格式:list[起始索引:结束索引:步长](左闭右开):
python
list_char = ['w','o','r','l','d']
print(list_char[1:4:2]) # 步长2,取索引1-3(不含4):['o', 'l']
print(list_char[2:]) # 从索引2到末尾:['r', 'l', 'd']
print(list_char[:3]) # 从开头到索引2(不含3):['w', 'o', 'r']
print(list_char[:]) # 复制整个列表:['w', 'o', 'r', 'l', 'd'](3)循环访问与成员判断
- 循环遍历:直接通过 for...in... 逐个访问元素
- 成员判断:用
in(存在)/not in(不存在)判断元素是否在列表中
python
# 循环遍历
list_char = ['w','o','r','l','d']
for i in list_char:
print(i, end=' ') # 输出:w o r l d
# 成员判断
li = [1,3,5,7,9]
print(1 in li) # 输出True
print(2 not in li) # 输出True5.2.3 添加列表元素:三种方法对比
| 方法 | 功能描述 | 示例代码 | 运行结果 |
|---|---|---|---|
| append() | 在列表末尾添加单个元素 | list_one = [1,2,3]; list_one.append(10) |
[1,2,3,10] |
| extend() | 在末尾添加另一个列表的所有元素 | list_str = ['a','b']; list_str.extend([1,2]) |
['a','b',1,2] |
| insert() | 按索引插入元素(插入位置后移) | names = ['chen','tom']; names.insert(1,'xingyun') |
['chen','xingyun','tom'] |
5.2.4 列表排序:三种核心方式
(1)sort () 方法:原地排序(修改原列表)
python
li_one = [6,2,5,3]
li_one.sort() # 默认升序:[2,3,5,6]
li_two = [7,3,5,4]
li_two.sort(reverse=True) # 降序:[7,5,4,3]
# 按字符串长度排序
li_three = ['python','java','php']
li_three.sort(key=len) # 按长度升序:['php','java','python']- 参数说明:
key指定排序规则(如len按长度),reverse控制升降序(默认 False 升序)
(2)sorted () 方法:生成新列表(不修改原列表)
python
li_one = [4,3,2,1]
li_two = sorted(li_one) # 原列表不变,新列表升序:[1,2,3,4]
print(li_one) # 输出[4,3,2,1](原列表未变)(3)reverse () 方法:逆置列表(原地修改)
python
li_one = ['a','b','c']
li_one.reverse() # 逆置后:['c','b','a']5.2.5 删除列表元素:四种常用方式
| 方法 / 语句 | 功能描述 | 示例代码 | 运行结果 |
|---|---|---|---|
| del 语句 | 删除指定索引元素或整个列表 | names = ['chen','tom']; del names[0] |
删除后:'tom' |
| remove() | 删除第一个匹配的元素 | chars = ['w','e','e','l']; chars.remove('e') |
['w','e','l'] |
| pop() | 删除指定索引元素(默认最后一个) | numbers = [1,2,3]; numbers.pop(1) |
删除索引 1,输出 2,列表变为 1,3 |
| clear() | 清空列表(保留列表对象) | names = [1,2,3]; names.clear() |
清空后:\[\] |
5.2.6 列表推导式:简洁构建新列表
列表推导式用复合表达式快速构建满足需求的列表,语法简洁高效,支持多场景扩展:
(1)基础格式:表达式 for 元素 in 可迭代对象
python
# 示例:将列表元素转为平方
ls = [1,2,3,4]
ls_square = [x*x for x in ls] # 输出:[1,4,9,16](2)带 if 判断:表达式 for 元素 in 可迭代对象 if 条件
python
# 示例:保留平方后大于4的元素
ls = [1,2,3,4]
ls_filter = [x*x for x in ls if x*x >4] # 输出:[9,16](3)嵌套循环:表达式 for 元素 1 in 列表 1 for 元素 2 in 列表 2
python
# 示例:取两个列表元素的和
ls1 = [1,2]
ls2 = [3,4]
ls_sum = [x+y for x in ls1 for y in ls2] # 输出:[4,5,5,6](4)带多条件 + 多循环
python
# 示例:多循环+多条件
ls1 = [1,2,3]
ls2 = [2,3,4]
result = [x+y for x in ls1 if x>1 for y in ls2 if y<4] # 输出:[3,4,4,5]5.3:元组(tuple):不可变的序列容器
元组与列表类似,但核心区别是不可变(元素无法修改、添加、删除),适合存储无需变更的数据(如配置信息、固定集合)。
5.3.1 创建元组:两种方式 + 注意事项
python
# 1. 圆括号()创建
tuple_empty = () # 空元组
tuple_single = (1,) # 单个元素必须加逗号(否则视为普通类型)
tuple_mix = (1, "python", (2,3)) # 混合类型元素
# 2. tuple()函数创建
tuple_from_str = tuple("python") # 从字符串转换:('p','y','t','h','o','n')
tuple_from_list = tuple([1,2,3]) # 从列表转换:(1,2,3)
tuple_empty2 = tuple() # 空元组- 关键注意:单个元素的元组必须加逗号,否则 Python 会解析为对应基本类型(如
(5)会被视为整型 5)
5.3.2 访问元组元素:与列表一致
元组支持索引、切片、循环遍历,用法与列表完全相同:
python
tuple_dev = ('java', 'python', 'php')
print(tuple_dev[1]) # 索引访问:'python'
print(tuple_dev[1:]) # 切片访问:('python', 'php')
for item in tuple_dev:
print(item) # 循环遍历:依次输出三个元素5.3.3 核心特性:不可变性
元组的不可变性是核心,不支持任何修改元素的操作:
- 不支持添加元素(无 append ()、extend ())
- 不支持删除元素(无 remove ()、pop (),del 仅能删除整个元组)
- 不支持排序(无 sort ()、reverse (),可通过 sorted () 生成新列表)
python
tuple_test = (1,2,3)
tuple_test[0] = 4 # 报错:TypeError(不允许修改元素)
del tuple_test[0] # 报错:TypeError(不允许删除指定元素)5.4 集合(set):无序唯一的元素集合
集合是可变类型 的数据结构,但要求集合中的元素必须是不可变类型 (如整数、字符串、元组等),列表、字典等可变类型不能作为集合元素。其核心特性是:元素无序、自动去重。
5.4.1 创建集合
创建集合有两种常用方式,注意空集合的创建特殊规则:
| 创建方式 | 语法示例 | 说明 |
|---|---|---|
| 直接赋值({}) | s1 = {1, 'b', (2, 5)} |
多元素集合,元素需为不可变类型 |
| 直接赋值(单元素) | s2 = {1} |
单元素集合,不能省略大括号内的逗号({} 是空字典) |
| 内置函数 set () | s3 = set() |
创建空集合(唯一方式) |
| set () 接收可迭代对象 | s4 = set([1,2,3]) s5 = set('python') s6 = set(range(5)) |
可接收列表、元组、字符串、range 等可迭代对象,自动去重 |
代码演示:
python
# 直接创建
s1 = {1, 'b', (2, 5)} # 合法:元素均为不可变类型
s2 = {1} # 单元素集合
# s3 = {[1,2]} # 报错:列表是可变类型,不能作为集合元素
# set() 创建
s4 = set() # 空集合
print(type(s4)) # <class 'set'>
s5 = set([1,2,2,3]) # 传入列表,自动去重
s6 = set('python') # 传入字符串,无序排列
s7 = set(range(5)) # 传入 range 对象
print(s5) # {1, 2, 3}
print(s6) # {'h', 'p', 'n', 'o', 'y', 't'}(顺序不固定)
print(s7) # {0, 1, 2, 3, 4}5.4.2 集合的常用操作
集合是可变的,支持元素的添加、删除、复制等操作,核心方法如下:
| 方法名 | 功能描述 | 示例 |
|---|---|---|
| add(x) | 向集合添加元素 x(x 必须是不可变类型),已存在则不报错 | s.add('s') |
| remove(x) | 删除元素 x,x 不存在则报错 | s.remove(3) |
| discard(x) | 删除元素 x,x 不存在则不报错(推荐) | s.discard('p') |
| pop() | 随机删除并返回一个元素(纯数字集合删除最小值) | s.pop() |
| clear() | 清空集合 | s.clear() |
| copy() | 复制集合,返回新集合 | s2 = s.copy() |
| isdisjoint(s2) | 判断两个集合是否无交集,无交集返回 True | s1.isdisjoint(s2) |
关键说明:
pop()基于哈希表实现,看似随机,但若集合元素是纯数字,会按从小到大排序后删除最小值。remove()和discard()的区别:删除不存在的元素时,remove()抛异常,discard()静默处理。
代码演示:
python
s1 = set([1,2,3])
s2 = set((2,3,4))
# 添加元素
s1.add('s')
print(s1) # {1, 2, 3, 's'}
# 删除元素
s2.remove(3) # 删除存在的元素
print(s2) # {2, 4}
s2.discard(5) # 删除不存在的元素,无报错
# 随机删除(纯数字集合删除最小值)
s4 = set(range(5)) # {0,1,2,3,4}
s4.pop()
print(s4) # {1,2,3,4}(删除了最小值 0)
# 清空与复制
s3 = set('python')
s3.clear()
print(s3) # set()(空集合)
s5 = s2.copy()
print(s5) # {2,4}
# 判断是否无交集
print(s4.isdisjoint(s2)) # False(s4 含 2,s2 含 2,有交集)5.4.3 集合推导式
集合推导式用于快速生成满足条件的集合,格式与列表推导式类似,仅将 [] 改为 {},自动去重。
语法:
python
{表达式 for 变量 in 可迭代对象 if 条件}代码演示:
python
# 生成 1-8 中的偶数集合
ls = {1,2,3,4,5,6,7,8}
even_set = {data for data in ls if data % 2 == 0}
print(even_set) # {8, 2, 4, 6}(无序,自动去重)
# 去重示例:从列表生成无重复元素的集合
num_list = [1,2,2,3,3,3]
unique_set = {x for x in num_list}
print(unique_set) # {1,2,3}5.5:字典(dict):键值对的映射集合
字典是 Python 中最常用的数据结构之一,以键值对(key-value) 形式存储数据,核心特性是:键唯一、元素无序、通过键快速查找值(映射关系)。
5.5.1 字典的核心规则
- 键(key):必须是不可变类型(整数、字符串、元组等),不能是列表、字典等可变类型;键必须唯一,重复赋值会覆盖原有值。
- 值(value):可以是任意类型(包括列表、字典、集合等)。
- 无序性:Python 3.7+ 中字典会保留插入顺序,但本质上仍基于哈希表,不依赖索引访问。
5.5.2 创建字典
创建字典有两种常用方式,支持空字典和非空字典的快速定义:
| 创建方式 | 语法示例 | 说明 |
|---|---|---|
| 直接赋值({}) | d1 = {'A':'123', 'B':'135'} |
键值对用 : 分隔,元素用 , 分隔 |
| 直接赋值(空字典) | d2 = {} |
空字典(与空集合区分:set() 是空集合) |
| 内置函数 dict () | d3 = dict() |
空字典 |
| dict () 接收键值对 | d4 = dict(A='123', B='135') |
无需引号包裹键(键为字符串时) |
| dict () 接收字典 | d5 = dict({'A':'123', 'B':'135'}) |
接收已有的字典作为参数 |
代码演示:
python
# 直接创建
d1 = {} # 空字典
d2 = {'A': '123', 'B': '135', 'C': '680'} # 字符串键
d3 = {'A': 123, 12: 'python', (1,2): 'tuple_key'} # 混合类型键(合法)
# d4 = {'A': 123, [1,2]: 'list_key'} # 报错:列表是可变类型,不能作为键
# dict() 创建
d5 = dict() # 空字典
d6 = dict(A='123', B='135') # 简化语法,键无需引号
d7 = dict({'A': '123', 'B': '135'}) # 接收字典参数
print(d6) # {'A': '123', 'B': '135'}5.5.3 字典的访问
字典的访问核心是 "通过键找值",支持直接访问和 get() 方法,还可批量获取键、值、键值对。
1. 访问单个值
| 访问方式 | 语法 | 说明 |
|---|---|---|
| 直接访问 | 字典[键] |
键不存在则抛 KeyError 异常 |
| get () 方法 | 字典.get(键, 默认值) |
键不存在返回默认值(默认值可选,默认 None) |
代码演示:
python
d2 = {'A': '123', 'B': '135', 'C': '680'}
# 直接访问
print(d2['A']) # '123'
# print(d2['D']) # 报错:KeyError: 'D'
# get() 方法(推荐,避免异常)
print(d2.get('A')) # '123'
print(d2.get('D', '默认值')) # '默认值'(键不存在时返回默认值)
print(d2.get('D')) # None(无默认值时返回 None)2. 批量访问键、值、键值对
Python 提供 3 个内置方法,返回可迭代对象,支持循环遍历:
| 方法名 | 功能 | 示例 |
|---|---|---|
| keys() | 获取所有键 | d.keys() |
| values() | 获取所有值 | d.values() |
| items() | 获取所有键值对(元组形式) | d.items() |
代码演示:
python
dic = {'name': 'tom', 'age': 18, 'height': 180}
# 批量获取
print(dic.keys()) # dict_keys(['name', 'age', 'height'])
print(dic.values()) # dict_values(['tom', 18, 180])
print(dic.items()) # dict_items([('name', 'tom'), ('age', 18), ('height', 180)])
# 循环遍历
print("所有键:", end="")
for key in dic.keys():
print(key, end=" ") # name age height
print("\n所有值:", end="")
for value in dic.values():
print(value, end=" ") # tom 18 180
print("\n所有键值对:", end="")
for key, value in dic.items():
print(f"{key}:{value}", end=" ") # name:tom age:18 height:1805.5.4 字典元素的添加与修改
字典支持动态添加和修改元素,核心逻辑是 "通过键赋值",update() 方法可批量操作。
1. 添加元素
当键不存在时,赋值操作会新增键值对;也可使用 update() 批量添加。
代码演示:
python
dic = {'name': 'tom', 'age': 18}
# 单个添加(键不存在)
dic['height'] = 180
print(dic) # {'name': 'tom', 'age': 18, 'height': 180}
# 批量添加(update())
dic.update(score=90, gender='male') # 关键字参数形式
print(dic) # {'name': 'tom', 'age': 18, 'height': 180, 'score': 90, 'gender': 'male'}
# 接收字典批量添加
dic.update({'address': 'China', 'phone': '123456'})
print(dic) # 新增 address 和 phone 键值对2. 修改元素
当键已存在时,赋值操作会覆盖原有值;update() 方法也支持批量修改。
代码演示:
python
info = {'stu1': '张三', 'stu2': '李四', 'stu3': '王五'}
# 单个修改(键存在)
info['stu3'] = '田七'
print(info) # {'stu1': '张三', 'stu2': '李四', 'stu3': '田七'}
# 批量修改(update())
info.update(stu2='赵六', stu1='张三三')
print(info) # {'stu1': '张三三', 'stu2': '赵六', 'stu3': '田七'}5.5.5 字典元素的删除
字典支持删除单个元素、随机删除元素和清空字典,核心方法如下:
| 方法名 | 功能 | 示例 |
|---|---|---|
| pop(key) | 根据键删除元素,返回对应值;键不存在抛异常 | d.pop('key') |
| popitem() | 随机删除一个键值对(3.7+ 删最后插入的),返回该键值对 | d.popitem() |
| clear() | 清空字典,返回空字典 | d.clear() |
代码演示:
python
stu_info = {'001': '张三', '002': '李四', '003': '王五', '004': '赵六'}
# pop():按键删除
delete_value = stu_info.pop('003')
print(delete_value) # '王五'(返回删除的值)
print(stu_info) # {'001': '张三', '002': '李四', '004': '赵六'}
# popitem():随机删除(3.7+ 删最后插入的)
delete_item = stu_info.popitem()
print(delete_item) # ('004', '赵六')(返回删除的键值对)
print(stu_info) # {'001': '张三', '002': '李四'}
# clear():清空字典
stu_info.clear()
print(stu_info) # {}(空字典)5.5.6 字典推导式
字典推导式用于快速生成字典,格式需包含键和值两部分,外侧用 {} 包裹。
语法:
python
{键表达式: 值表达式 for 变量 in 可迭代对象 if 条件}常见场景:
- 快速交换字典的键和值
- 过滤字典元素
- 从可迭代对象生成字典
代码演示:
python
# 场景 1:交换键和值
original_dict = {'A': '123', 'B': '135', 'C': '680'}
swapped_dict = {value: key for key, value in original_dict.items()}
print(swapped_dict) # {'123': 'A', '135': 'B', '680': 'C'}
# 场景 2:过滤值大于 18 的键值对
person = {'name': 'tom', 'age': 18, 'height': 180, 'score': 90}
filtered_dict = {k: v for k, v in person.items() if isinstance(v, int) and v > 18}
print(filtered_dict) # {'height': 180, 'score': 90}
# 场景 3:从列表生成字典(键值对应)
keys = ['a', 'b', 'c']
values = [1, 2, 3]
new_dict = {k: v for k, v in zip(keys, values)}
print(new_dict) # {'a': 1, 'b': 2, 'c': 3}5.6:组合数据类型应用运算符
在 Python 中,除了数字类型,字符串、列表、元组、集合、字典等组合数据类型也支持部分常用运算符。其中 +、*、in、not in 是最实用的四类,本文将详细拆解它们的用法、适用场景及注意事项,帮你快速掌握组合数据类型的运算符技巧。
5.6.1 + 运算符:拼接组合数据
作用说明
+ 运算符用于拼接两个同类型的组合数据,生成一个新的对象(原对象不会被修改)。
适用类型
仅支持 字符串(str)、列表(list)、元组(tuple) ,不支持集合(set)和字典(dict)(集合会报 TypeError,字典不支持 + 运算)。
代码示例
python
# 1. 字符串拼接
str1 = "Hello"
str2 = "Python"
print(str1 + " " + str2) # 输出:Hello Python
# 2. 列表拼接
list1 = [1, 2, 3]
list2 = ["a", "b"]
print(list1 + list2) # 输出:[1, 2, 3, 'a', 'b']
# 3. 元组拼接
tuple1 = (10, 20)
tuple2 = (30, 40)
print(tuple1 + tuple2) # 输出:(10, 20, 30, 40)
# 不支持的类型(报错示例)
# set1 = {1,2}, set2={3,4}; print(set1 + set2) # TypeError: unsupported operand type(s) for +: 'set' and 'set'
# dict1 = {"name":"Tom"}, dict2={"age":18}; print(dict1 + dict2) # TypeError: unsupported operand type(s) for +: 'dict' and 'dict'注意事项:
- 必须是同类型数据拼接(如列表只能和列表拼,字符串只能和字符串拼),否则报错;
- 拼接后生成新对象,原对象保持不变(适合不可变类型如字符串、元组)。
5.6.2 * 运算符:重复拼接数据
作用说明
* 运算符用于将组合数据重复指定整数倍,生成一个新的对象(原对象不变)。
适用类型
同样支持 字符串(str)、列表(list)、元组(tuple),不支持集合和字典。
代码示例
python
# 1. 字符串重复
str3 = "Hi"
print(str3 * 3) # 输出:HiHiHi(重复3次)
# 2. 列表重复
list3 = [0]
print(list3 * 5) # 输出:[0, 0, 0, 0, 0](重复5次)
# 3. 元组重复
tuple3 = ("a",) # 注意:单个元素的元组需加逗号
print(tuple3 * 4) # 输出:('a', 'a', 'a', 'a')
# 特殊情况:乘以0或负数,返回空对象
print("Test" * 0) # 输出:''
print([1,2] * -2) # 输出:[]注意事项:
-
右侧必须是非负整数(负数等价于 0,返回空对象);
-
列表重复时,若列表包含可变元素(如子列表),会存在 "浅拷贝" 问题(所有重复项共享同一个子元素):
pythonlist4 = [[1]] * 3 list4[0][0] = 99 # 修改第一个子列表,所有子列表都会变 print(list4) # 输出:[[99], [99], [99]]
5.6.3 in / not in 运算符:判断成员归属
作用说明
in:判断某个元素是否属于 目标组合数据(返回True/False);not in:判断某个元素是否不属于 目标组合数据(返回True/False)。
适用类型
支持 字符串、列表、元组、集合、字典(全组合类型支持),但字典的判断逻辑特殊。
代码示例
1. 字符串(判断子串是否存在)
python
str4 = "Python编程"
print("thon" in str4) # 输出:True(子串存在)
print("java" not in str4) # 输出:True(子串不存在)2. 列表 / 元组(判断元素是否存在)
python
list5 = [1, "a", True]
tuple4 = (10, 20, 30)
print(1 in list5) # 输出:True
print("b" not in list5) # 输出:True
print(20 in tuple4) # 输出:True3. 集合(判断元素是否存在,效率最高)
python
set1 = {1, 2, 3, 4}
print(3 in set1) # 输出:True
print(5 not in set1) # 输出:True4. 字典(特殊!仅判断 "键" 是否存在,不判断值)
python
dict1 = {"name": "Tom", "age": 18, "city": "Beijing"}
print("name" in dict1) # 输出:True(判断键)
print("Tom" in dict1) # 输出:False(不判断值)
print("gender" not in dict1) # 输出:True(键不存在)
# 若需判断值是否存在,需用 dict.values()
print("Tom" in dict1.values()) # 输出:True注意事项
- 字符串判断的是子串(而非单个字符,除非子串长度为 1);
- 字典默认判断键 ,判断值需显式使用
dict.values(),判断键值对需用(key, value) in dict.items(); - 成员判断效率:集合(O (1))> 字典(O (1))> 列表 / 元组(O (n))> 字符串(O (n)),数据量大时优先用集合判断成员。
5.6.4 组合数据类型运算符支持表
| 运算符 | 字符串(str) | 列表(list) | 元组(tuple) | 集合(set) | 字典(dict) |
|---|---|---|---|---|---|
+ |
✅ 拼接 | ✅ 拼接 | ✅ 拼接 | ❌ 不支持 | ❌ 不支持 |
* |
✅ 重复拼接 | ✅ 重复拼接 | ✅ 重复拼接 | ❌ 不支持 | ❌ 不支持 |
in |
✅ 子串判断 | ✅ 元素判断 | ✅ 元素判断 | ✅ 元素判断 | ✅ 键判断 |
not in |
✅ 子串判断 | ✅ 元素判断 | ✅ 元素判断 | ✅ 元素判断 | ✅ 键判断 |
通过以上运算符,可快速实现组合数据的拼接、重复、成员判断等常见操作,合理运用能大幅简化代码。
第六章:函数
函数是 Python 中组织代码的核心方式,能将重复逻辑模块化,提升代码复用性、可读性和可维护性。
6.1:函数概述:为什么需要函数?
函数是封装单一功能或关联功能的代码段,可通过 "函数名 ()" 在任意位置调用。
核心价值
- 减少冗余代码:避免重复编写相同逻辑
- 程序结构清晰:将复杂程序拆分为多个功能模块
- 提升开发效率:直接调用已定义函数,无需重复开发
- 便于维护扩展:修改函数逻辑只需改动一处
无函数 vs 有函数对比
无函数(冗余示例):重复编写打印正方形的代码
python
# 打印边长为2的正方形
for i in range(2):
for j in range(2):
print('*', end=' ')
print()
# 打印边长为3的正方形
for i in range(3):
for j in range(3):
print('*', end=' ')
print()有函数(简洁示例):定义一次,多次调用
python
# 定义打印正方形函数
def print_square(length):
for i in range(length):
for j in range(length):
print('*', end=' ')
print()
# 调用函数
print_square(2)
print_square(3)6.2:函数的定义与调用
6.2.1 定义函数
Python 中自定义函数的基本语法:
python
def 函数名([参数列表]):
函数体(功能实现代码)
[return 返回值]
def:定义函数的关键字- 函数名:遵循变量命名规范,建议见名知义
- 参数列表:可选,用于接收外部传入的数据
- 函数体:缩进编写(通常 4 个空格),实现具体功能
- return:可选,用于返回数据给调用者
6.2.2 调用函数
函数定义后不会自动执行,需通过 "函数名 (实参列表)" 触发执行。
调用流程
- 程序在调用位置暂停执行
- 将实参传递给函数形参
- 执行函数体代码
- 执行完毕后回到暂停位置继续执行
示例:无参 vs 有参函数
python
# 无参函数
def add():
result = 11 + 22
print(result)
# 有参函数
def add_modify(a, b):
result = a + b
print(result)
# 调用函数
add() # 输出:33
add_modify(10, 20) # 输出:306.2.3 嵌套特性
嵌套调用:函数内部调用其他函数
python
def add():
return 11 + 22
def add_modify(a, b):
result = a + b
print(add()) # 嵌套调用add()
print(result)
add_modify(10, 20) # 输出:33、30嵌套定义:函数内部定义另一个函数
python
def outer():
print("外层函数")
def inner(): # 内层函数
print("内层函数")
inner() # 外层函数内调用内层函数
outer() # 输出:外层函数、内层函数
# inner() # 错误:外部无法直接调用内层函数6.3:函数参数传递:5 种核心方式
定义函数时的参数称为形参 ,调用时传入的参数称为实参,参数传递是将实参赋值给形参的过程。
6.3.1 位置参数传递
实参按顺序依次赋值给形参,必须保证实参数量与形参一致。
python
# 比较两数大小
def get_max(a, b):
print('max:', a if a > b else b)
get_max(5, 8) # 输出:max: 8(5传给a,8传给b)6.3.2 关键字参数传递
通过 "形参名 = 实参" 的形式关联,无需遵守位置顺序。
python
def connect(ip, port):
print(f'设备{ip}:{port}连接!')
connect(ip='127.0.0.1', port=8080) # 输出:设备127.0.0.1:8080连接!
connect(port=3306, ip='127.0.0.1') # 顺序无关,输出相同参数传递限制(Python3.8+)
- 使用
/分隔:左侧参数必须用位置传递 - 使用
*分隔:右侧参数必须用关键字传递
python
def func(a, /, b, *, c):
print(a, b, c)
func(10, 20, c=30) # 正确
func(10, b=20, c=30) # 正确
# func(a=10, 20, c=30) # 错误:a在/左侧,不能用关键字传递
# func(10, 20, 30) # 错误:c在*右侧,必须用关键字传递6.3.3 默认参数传递
定义形参时指定默认值,调用时可省略该参数(使用默认值)。
python
def connect(ip, port=8080): # port默认值8080
print(f'设备{ip}:{port}连接!')
connect(ip='127.0.0.1') # 省略port,使用默认值:设备127.0.0.1:8080连接!
connect(ip='127.0.0.1', port=3306) # 传入port,覆盖默认值6.3.4 参数的打包与解包
应对参数数量不确定的场景,或简化多参数传递。
1) 打包(收集参数)
*args:将多个位置实参打包为元组**kwargs:将多个关键字实参打包为字典
python
# 元组打包
def test(*args):
print(args, type(args)) # 输出:(11, 22, 33) <class 'tuple'>
test(11, 22, 33)
# 字典打包
def test(**kwargs):
print(kwargs, type(kwargs)) # 输出:{'a':1, 'b':2} <class 'dict'>
test(a=1, b=2)2) 解包(拆分参数)
- 元组 / 列表前加
*:拆分为位置参数 - 字典前加
**:拆分为关键字参数(键名需与形参一致)
python
def test(A, B, C, D):
print(A, B, C, D)
# 元组解包
numbers = (10, 20, 30, 40)
test(*numbers) # 输出:10 20 30 40
# 字典解包
dic = {'A':11, 'B':33, 'C':22, 'D':44}
test(**dic) # 输出:11 33 22 446.3.5 混合传递
前面介绍的参数传递的方式在定义函数或调用函数时可以混合使用,但是需要遵循一定的规则,具体规则如下。
- 优先按位置参数传递的方式。
- 然后按关键字参数传递的方式。
- 之后按默认参数传递的方式。
- 最后按打包传递的方式。
在定义函数时:
- 带有默认值的参数必须位于普通参数之后。
- 带有 * 标识的参数必须位于带有默认值的参数之后。
- 带有 * * 标识的参数必须位于带有 * 标识的参数之后。
python
def test(a, b, c=33, *args, **kwargs):
print(a, b, c, args, kwargs)
test(1, 2) # 输出:1 2 33 () {}
test(1, 2, 3) # 输出:1 2 3 () {}
test(1, 2, 3, 4) # 输出:1 2 3 (4,) {}
test(1, 2, 3, 4, e=5) # 输出:1 2 3 (4,) {'e':5}6.4:函数的返回值
通过return语句将函数执行结果返回给调用者,同时终止函数执行。
6.4.1 基本用法
python
def re_values(words):
if "牛逼" in words:
return words.replace('牛逼', '厉害') # 返回替换后的值
return words # 无匹配时返回原字符串
result = re_values("这次考试全班第一,非常牛逼")
print(result) # 输出:这次考试全班第一,非常厉害6.4.2 返回多个值
返回多个值时,会自动打包为元组:
python
def move(a, b, step):
next_a = a + step
next_b = b - step
return next_a, next_b # 多个返回值用逗号分隔
result = move(10, 20, 5)
print(result) # 输出:(15, 15)
print(type(result)) # 输出:<class 'tuple'>
# 解包接收
x, y = move(10, 20, 5)
print(x, y) # 输出:15 156.5:变量作用域:LEGB 原则
变量的访问权限取决于定义位置,有效范围称为作用域,Python 遵循 LEGB 搜索顺序。
6.5.1 局部变量与全局变量
局部变量
- 函数内部定义,仅在函数内部可访问
- 函数执行结束后自动释放
python
def test():
number = 10 # 局部变量
print(number) # 输出:10(函数内可访问)
test()
# print(number) # 错误:函数外无法访问全局变量
- 函数外部定义,可在程序任意位置访问(函数内仅可读取,不可直接修改)
python
number = 10 # 全局变量
def test():
print(number) # 输出:10(函数内可读取)
test()
print(number) # 输出:10(函数外可访问)6.5.2 LEGB 搜索原则
Python 搜索变量时按以下顺序查找,找到即停止:
- L(Local):局部作用域(函数内变量、形参)
- E(Enclosing):嵌套作用域(外层函数变量)
- G(Global):全局作用域(程序顶层变量)
- B(Built-in):内置作用域(Python 内置函数 / 变量)
python
import math # 内置模块
g_number = 10 # 全局变量
def outer():
e_number = 20 # 嵌套作用域变量
def inner():
l_number = 30 # 局部变量
print(l_number) # 查找L:30
print(math.pi) # 查找B:3.14159...
inner()
print(e_number) # 查找E:20
outer()
print(g_number) # 查找G:106.5.3 修改全局 / 嵌套变量
函数内部无法直接修改全局变量或在嵌套函数的外层函数声明的变量,但可以使用global或nonlocal关键字修饰变量以间接修改以上变量。
global 关键字:修改全局变量
python
number = 10 # 全局变量
def test():
global number # 声明使用全局变量
number += 1 # 可修改
print(number) # 输出:11
test()
print(number) # 输出:11(全局变量已修改)nonlocal 关键字:修改嵌套作用域变量
python
def outer():
number = 20 # 嵌套作用域变量
def inner():
nonlocal number # 声明使用嵌套作用域变量
number += 10 # 可修改
print(number) # 输出:30
inner()
print(number) # 输出:30(嵌套变量已修改)
outer()6.6:特殊形式的函数
在 Python 中,除了标准定义的函数外,还有两种特殊形式的函数 ------递归函数 和匿名函数。它们在特定场景下能极大简化代码逻辑,提升开发效率。本文将从定义、核心原理、使用场景到实战案例,全面拆解这两种特殊函数。
6.6.1 递归函数:自己调用自己的 "循环艺术"
6.6.1.1 什么是递归函数?
函数内部直接或间接调用自身 的函数,称为递归函数。它的核心思想是 "大事化小"------ 将复杂问题拆解为多个与原问题结构相似的子问题,直到子问题简化到可直接求解(边界条件),再反向合并结果。
6.6.1.2 递归函数的两大核心条件
递归函数必须同时满足以下两个条件,否则会陷入无限递归(最终导致栈溢出):
- 边界条件 :最小化的子问题,是递归终止的 "出口"(比如
n=1时返回固定值); - 递归公式 :将原问题转化为子问题的逻辑(比如
n! = n * (n-1)!)。
6.6.1.3 递归的执行流程
递归执行分为两个阶段,以 "递" 和 "归" 的方式完成:
- 递推阶段:递归本次的执行都基于上一次的运算结果;
- 回溯阶段:遇到终止条件时,则沿着递推往回一级一级地把值返回来。
6.6.1.4 递归函数的一般定义格式
python
def 函数名([参数列表]):
if 边界条件:
rerun 结果
else:
return 递归公式6.6.1.5 经典实战案例
案例 1:计算阶乘(n!)
阶乘定义:n! = 1 × 2 × 3 × ... × n,满足:
- 边界条件:
n=1时,1! = 1; - 递归公式:
n! = n × (n-1)!(n>1)。
代码实现:
python
def factorial(num):
# 边界条件:n=1 时直接返回1
if num == 1:
return 1
# 递归公式:拆解为子问题 num-1 的阶乘
else:
return num * factorial(num - 1)
# 测试
num = int(input("请输入一个正整数:"))
result = factorial(num)
print(f"{num}! = {result}")运行结果:
plaintext
请输入一个正整数:5
5! = 120执行流程:
- 递推:
factorial(5) → 5×factorial(4) → 5×4×factorial(3) → 5×4×3×factorial(2) → 5×4×3×2×factorial(1) - 回溯:
5×4×3×2×1 → 120
案例 2:汉诺塔问题
问题描述:3 根杆子(A、B、C),A 杆有 N 个圆盘(大盘在下、小盘在上),需将所有圆盘移到 C 杆,规则:
-
每次只能移动 1 个圆盘;
-
大盘不能叠在小盘上。
求最少移动次数。
- 核心思路:
- 边界条件:
N=1时,直接将圆盘从 A 移到 C,移动次数 = 1; - 递归公式:
- 将 A 杆上 N-1 个圆盘通过 C 杆移到 B 杆(移动次数 =
hanoi(N-1)); - 将 A 杆最后 1 个大盘移到 C 杆(移动次数 + 1);
- 将 B 杆上 N-1 个圆盘通过 A 杆移到 C 杆(移动次数 +
hanoi(N-1))。
- 将 A 杆上 N-1 个圆盘通过 C 杆移到 B 杆(移动次数 =
- 总次数:
hanoi(N) = 2×hanoi(N-1) + 1。
- 边界条件:
代码实现:
python
def hanoi(n):
# 边界条件:1个圆盘只需移动1次
if n == 1:
return 1
# 递归公式:2×n-1个圆盘移动次数 + 1
else:
return 2 * hanoi(n-1) + 1
# 测试:3个圆盘的移动次数(预期7次)
print(f"3个圆盘的最少移动次数:{hanoi(3)}") # 输出:7案例 3:归并排序(分治思想的递归实现)
归并排序是基于 "分治策略" 的排序算法,核心流程:
- 拆分:将待排序序列递归拆分为两个子序列,直到每个子序列长度为 1(边界条件,长度为 1 的序列已有序);
- 合并:将两个有序子序列合并为一个有序序列。
代码实现:
python
def merge_sort(arr):
# 边界条件:序列长度≤1时直接返回(已有序)
if len(arr) <= 1:
return arr
# 拆分:分成左右两个子序列
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
# 合并:将两个有序子序列合并
return merge(left, right)
# 辅助函数:合并两个有序序列
def merge(left, right):
res = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
res.append(left[i])
i += 1
else:
res.append(right[j])
j += 1
# 追加剩余元素
res.extend(left[i:])
res.extend(right[j:])
return res
# 测试
test_arr = [3, 1, 4, 1, 5, 9, 2, 6]
sorted_arr = merge_sort(test_arr)
print(f"归并排序结果:{sorted_arr}") # 输出:[1, 1, 2, 3, 4, 5, 6, 9]6.6.1.5 递归函数的优缺点
- 优点:代码简洁、逻辑清晰,能直观表达分治思想(如汉诺塔、归并排序);
- 缺点 :
- 递归调用会占用栈空间,深度过大会导致栈溢出(可通过尾递归优化,但 Python 不支持);
- 重复计算(如斐波那契数列的递归实现),效率较低(可通过缓存优化)。
6.6.2 匿名函数:无名称的 "轻量级函数"
6.6.2.1 什么是匿名函数?
匿名函数是无需定义标识符(函数名) 的函数,仅用于实现简单逻辑(单个表达式),Python 中通过 lambda 关键字定义,因此也常被称为 "lambda 函数"。
6.6.2.2 语法格式
python
lambda <形式参数列表>: <表达式>- 形式参数列表:可接收 0 个或多个参数(用逗号分隔);
- 表达式:函数体唯一的执行逻辑,计算结果直接作为返回值(无需写
return)。
6.6.2.3 匿名函数与普通函数的区别
| 特性 | 普通函数 | 匿名函数(lambda) |
|---|---|---|
| 函数名称 | 必须定义名称 | 无名称 |
| 函数体 | 可包含多条语句 | 仅允许一个表达式 |
| 功能复杂度 | 可实现复杂逻辑 | 仅实现简单逻辑(如计算、判断) |
| 复用性 | 可被其他程序调用(复用) | 不可直接复用(需赋值给变量) |
| 返回值 | 可通过 return 自定义 |
表达式结果即为返回值 |
6.6.2.4 使用场景与实战示例
匿名函数本身不能直接调用,需通过以下两种方式使用:
- 赋值给变量,通过变量间接调用;
- 作为参数传递给高阶函数(如
sorted()、map()、filter())。
示例 1:基础使用(赋值给变量)
python
# 1. 单参数:计算x的平方(pow(x,2)等价于x**2)
square = lambda x: pow(x, 2)
print(square(10)) # 输出:100
# 2. 多参数:计算x+y的和
add = lambda x, y: x + y
print(add(10, 20)) # 输出:30
# 3. 无参数:返回固定值
hello = lambda: "Hello, Python!"
print(hello()) # 输出:Hello, Python!示例 2:结合高阶函数使用(核心场景)
匿名函数最常用的场景是作为高阶函数的参数,简化代码:
python
# 1. 排序字典列表(按字典的某个key排序)
students = [
{"name": "Alice", "age": 20},
{"name": "Bob", "age": 18},
{"name": "Charlie", "age": 22}
]
# 按age升序排序(key参数接收lambda函数)
sorted_students = sorted(students, key=lambda x: x["age"])
print(sorted_students)
# 输出:[{'name': 'Bob', 'age': 18}, {'name': 'Alice', 'age': 20}, {'name': 'Charlie', 'age': 22}]
# 2. map():对序列中每个元素执行操作
nums = [1, 2, 3, 4]
# 计算每个元素的平方
square_nums = list(map(lambda x: x**2, nums))
print(square_nums) # 输出:[1, 4, 9, 16]
# 3. filter():过滤序列中满足条件的元素
# 筛选偶数
even_nums = list(filter(lambda x: x % 2 == 0, nums))
print(even_nums) # 输出:[2, 4]6.6.2.5 匿名函数的优缺点
- 优点:代码简洁、轻量化,避免定义冗余的普通函数(如简单计算、排序 key);
- 缺点:功能单一,仅支持单个表达式,无法实现复杂逻辑;无名称,可读性较差(复杂逻辑建议用普通函数)。
两种特殊函数各有侧重,合理使用能让 Python 代码更简洁、高效~
`