roll 强化学习框架 怎么调用到 megatron 进行模型执行的呢?
megatron 这个forward_backward_func 接口,对外使用的,会做前向,backward 和optimizer.step.
roll 可以获取forward_backward_func 接口
总结一下, forward_step_func 这个函数可以自己定义, 调用这个函数最终会调用到megatron 模型的forward 函数,进行推理。
比roll 中。forward_step_func, 自定义为inner_forward_step, 这个函数最终会调用到model.forward. 这里用了partial 语法,C++中的模版类。

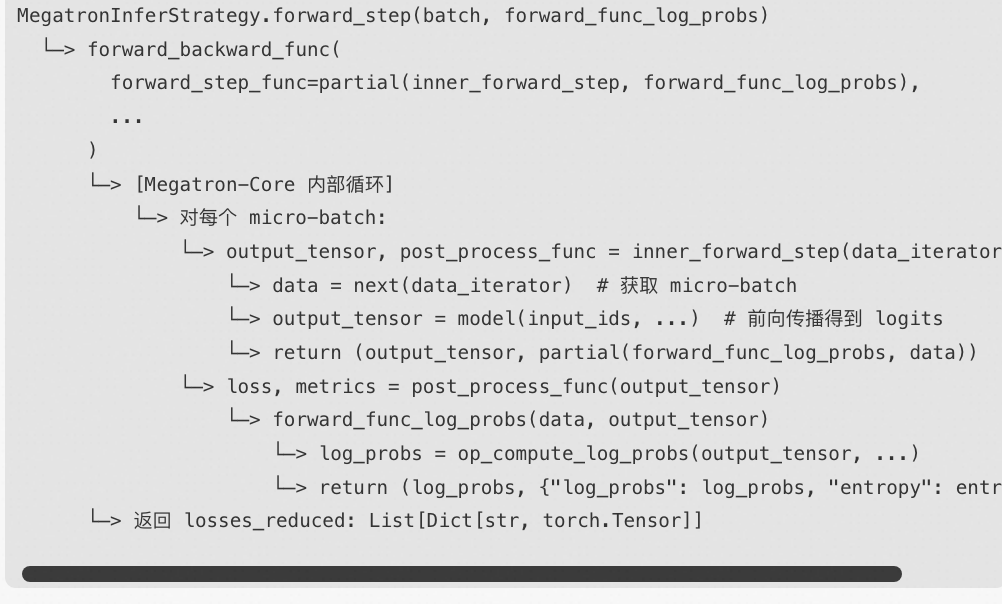
megatron 中也可以使用这个接口forward_backward_func
pretrain_gpt.py
定义 forward_step pretrain()
接收 forward_step_func train_step()
传递 forward_step_func forward_backward_func
传递 forward_step_func forward_step()
调用 forward_step_func 执行用户定义的
forward_step model.forward()
模型前向传播
您询问的是 Megatron-LM 从模型前向传播到损失函数计算再到梯度更新的完整流程 。
整体流程概览
Megatron-LM 的训练流程从 train_step() 开始,经过前向传播、损失计算、反向传播,最后进行参数更新。 1
详细执行步骤
1. 训练步骤入口
train_step() 是单次训练迭代的入口函数: 2
首先清零梯度缓冲区和优化器梯度: 3
2. 前向和反向传播
调用 forward_backward_func 执行前向和反向传播: 4
forward_backward_func 是通过 get_forward_backward_func() 获取的调度函数,根据 pipeline 配置选择不同的实现: 5
3. 前向传播详细流程
3.1 调用 forward_step()
在调度函数内部,会调用 forward_step() 处理每个 microbatch: 6
3.2 执行用户定义的 forward_step_func
forward_step() 内部调用用户提供的 forward_step_func: 7
以 pretrain_gpt.py 为例,forward_step_func 执行以下操作: 8
- 获取 batch 数据 (tokens, labels, loss_mask 等)
- 调用
model()进行前向传播,传入labels参数 - 返回
output_tensor(损失张量) 和partial(loss_func, loss_mask, model=model)
3.3 模型前向传播
当调用 model(tokens, position_ids, attention_mask, labels=labels) 时,执行 GPTModel.forward(): 9
模型前向传播包括:
- Embedding 层处理输入
- Transformer decoder 处理 hidden states
_postprocess()生成 logits 并计算损失
如果启用了 MTP,在 _postprocess() 中会额外处理 MTP 层并通过 MTPLossAutoScaler 附加辅助损失。 10
4. 损失函数计算
4.1 调用 forward_step_calc_loss()
forward_step() 获取 output_tensor 后,调用 forward_step_calc_loss() 处理损失: 11
4.2 执行 loss_func
在 forward_step_calc_loss() 中,如果是最后一个 pipeline stage,会调用之前返回的 loss_func: 12
loss_func (来自 pretrain_gpt.py) 执行: 13
- 应用 loss mask
- 计算加权损失和
- 跨数据并行组归约损失用于日志记录
- 返回
(loss, num_tokens, {'lm loss': reporting_loss})
4.3 设置辅助损失缩放
对于 MoE 和 MTP,forward_step_calc_loss() 会设置辅助损失的缩放因子: 14
这确保辅助损失的梯度与主损失使用相同的缩放。
5. 反向传播
5.1 调用 backward_step()
在非 pipeline 并行的情况下,每个 microbatch 的前向传播后立即执行反向传播: 15
backward_step() 执行标准的 PyTorch 反向传播: 16
关键步骤:
- 保留输入张量的梯度
- 如果是最后一个 stage,应用梯度缩放
- 调用
torch.autograd.backward()计算梯度 - 收集输入张量的梯度用于 pipeline 传递
5.2 MTP 辅助损失的反向传播
MTP 的辅助损失通过 MTPLossAutoScaler 自动触发反向传播: 17
在 backward() 中,生成缩放后的梯度并返回,使得 MTP 损失的梯度自动累加到主模型的梯度流中。
6. 梯度同步和参数更新
6.1 梯度同步
反向传播完成后,如果启用了数据并行,会进行梯度同步。对于 interleaved pipeline,在 cooldown 阶段会启动剩余的梯度归约: 18
然后调用 finalize_model_grads_func 完成梯度的最终处理: 19
6.2 优化器更新
回到 train_step(),调用 optimizer.step() 更新参数: 20
优化器会:
- 应用梯度裁剪
- 执行参数更新 (如 Adam)
- 返回更新是否成功、梯度范数等信息
最后跨模型并行组同步更新状态: 21
完整流程图
train_step 清零梯度 forward_backward_func forward_step forward_step_func
用户定义 model.forward
前向传播 返回 output_tensor
和 loss_func forward_step_calc_loss 调用 loss_func
计算最终损失 设置辅助损失缩放
MoE/MTP backward_step torch.autograd.backward
反向传播 梯度同步
DP/PP optimizer.step
参数更新 返回损失和指标
Notes
这个流程支持多种并行策略 (TP, PP, DP, CP, EP) 的组合。对于 pipeline 并行,会使用 1F1B (one-forward-one-backward) 调度来减少 pipeline bubble。 22 对于 MTP 等辅助损失,通过自定义 autograd 函数优雅地集成到主训练流程中,无需显式管理多个损失项。
Wiki pages you might want to explore:
Citations
File: megatron/training/training.py (L1228-1297)
python
def train_step(forward_step_func, data_iterator, model, optimizer, opt_param_scheduler, config, forward_backward_func):
"""Single training step."""
args = get_args()
timers = get_timers()
rerun_state_machine = get_rerun_state_machine()
while rerun_state_machine.should_run_forward_backward(data_iterator):
# Set grad to zero.
for model_chunk in model:
model_chunk.zero_grad_buffer()
optimizer.zero_grad()
if has_nvidia_modelopt:
# [ModelOpt]: Pipeline-parallel Distillation stacks student and teacher tensors
adjust_tensor_shapes_fn = get_tensor_shapes_adjust_fn_for_distillation(
model, args.seq_length, args.micro_batch_size, args.decoder_seq_length
)
else:
adjust_tensor_shapes_fn = None
# For the mxfp8_param with reuse_grad_buf_for_mxfp8_param_ag and dp_ag_overlap,
# we need to call the _copy_main_params_to_param_buffer() after the grad buffer
# is zeroed by zero_grad_buffer() because param and grad buffer are shared.
if args.reuse_grad_buf_for_mxfp8_param_ag and args.overlap_param_gather:
for optim_instance in optimizer.chained_optimizers:
if isinstance(optim_instance, DistributedOptimizer):
optim_instance._copy_main_params_to_param_buffer()
# Forward pass.
losses_reduced = forward_backward_func(
forward_step_func=forward_step_func,
data_iterator=data_iterator,
model=model,
num_microbatches=get_num_microbatches(),
seq_length=args.seq_length,
micro_batch_size=args.micro_batch_size,
decoder_seq_length=args.decoder_seq_length,
forward_only=False,
adjust_tensor_shapes_fn=adjust_tensor_shapes_fn,
)
should_checkpoint, should_exit, exit_code = rerun_state_machine.should_checkpoint_and_exit()
if should_exit:
return {}, True, should_checkpoint, should_exit, exit_code, None, None
# Empty unused memory.
if args.empty_unused_memory_level >= 1:
torch.cuda.empty_cache()
# Vision gradients.
if args.vision_pretraining and args.vision_pretraining_type == "dino":
unwrapped_model = unwrap_model(model[0])
unwrapped_model.cancel_gradients_last_layer(args.curr_iteration)
# Update parameters.
timers('optimizer', log_level=1).start(barrier=args.barrier_with_L1_time)
update_successful, grad_norm, num_zeros_in_grad = optimizer.step()
timers('optimizer').stop()
# when freezing sub-models we may have a mixture of successful and unsucessful ranks,
# so we must gather across mp ranks
update_successful = logical_and_across_model_parallel_group(update_successful)
# grad_norm and num_zeros_in_grad will be None on ranks without trainable params,
# so we must gather across mp ranks
grad_norm = reduce_max_stat_across_model_parallel_group(grad_norm)
if args.log_num_zeros_in_grad:
num_zeros_in_grad = reduce_max_stat_across_model_parallel_group(num_zeros_in_grad)
# Vision momentum.
if args.vision_pretraining and args.vision_pretraining_type == "dino":File: megatron/core/pipeline_parallel/schedules.py (L40-132)
python
def get_forward_backward_func():
"""Retrieves the appropriate forward_backward function given the
configuration of parallel_state.
Returns a function that will perform all of the forward and
backward passes of the model given the pipeline model parallel
world size and virtual pipeline model parallel world size in the
global parallel_state.
Note that if using sequence parallelism, the sequence length component of
the tensor shape is updated to original_sequence_length /
tensor_model_parallel_world_size.
The function returned takes the following arguments:
forward_step_func (required): A function that takes a data
iterator and a model as its arguments and return the model's
forward output and the loss function. The loss function should
take one torch.Tensor and return a torch.Tensor of loss and a
dictionary of string -> torch.Tensor.
A third argument, checkpoint_activations_microbatch, indicates
that the activations for this microbatch should be
checkpointed. A None value for this argument indicates that
the default from the configuration should be used. This is
used when the
num_microbatches_with_partial_activation_checkpoints is used.
For example:
def loss_func(loss_mask, output_tensor):
losses = output_tensor.float()
loss_mask = loss_mask.view(-1).float()
loss = torch.sum(losses.view(-1) * loss_mask) / loss_mask.sum()
# Reduce loss for logging.
averaged_loss = average_losses_across_data_parallel_group([loss])
return loss, {'lm loss': averaged_loss[0]}
def forward_step(data_iterator, model):
data, loss_mask = next(data_iterator)
output = model(data)
return output, partial(loss_func, loss_mask)
forward_backward_func(forward_step_func=forward_step, ...)
data_iterator (required): an iterator over the data, will be
passed as is to forward_step_func. Expected to be a list of
iterators in the case of interleaved pipeline parallelism.
model (required): the actual model. Expected to be a list of modules in the case of interleaved
pipeline parallelism. Must be a (potentially wrapped) megatron.core.models.MegatronModule.
num_microbatches (int, required):
The number of microbatches to go through
seq_length (int, required): Sequence length of the current global batch. If this is a dual-stack
transformer, this is the encoder's sequence length. This is ignored if variable_seq_lengths
in the config is True. Otherwise, each microbatch in the current global batch size must use
this sequence length.
micro_batch_size (int, required): The number of sequences in a microbatch.
decoder_seq_length (int, optional): The sequence length for the decoder in a dual-stack
transformer. This is ignored for a single-stack transformer.
forward_only (optional, default = False): Perform only the forward step
collect_non_loss_data (optional, bool, default=False): TODO
first_val_step (bool, optional): Is the first step of the validation phase. Used by
Transformer Engine modules to only update their fp8 weights only on the first validation
step.
adjust_tensor_shapes_fn (Callable, optional): A function that adjusts the receive and send
tensor shapes. Only applicable in forward_backward_pipelining_without_interleaving for now.
Takes in a list of receive shapes and a list of send shapes and returns the adjusted
respective list of shapes. Thus it is not used in the other forward-backward functions
which have different shape handling.
"""
pipeline_model_parallel_size = parallel_state.get_pipeline_model_parallel_world_size()
if pipeline_model_parallel_size > 1:
if parallel_state.get_virtual_pipeline_model_parallel_world_size() is not None:
forward_backward_func = forward_backward_pipelining_with_interleaving
else:
forward_backward_func = forward_backward_pipelining_without_interleaving
else:
forward_backward_func = forward_backward_no_pipelining
return forward_backward_funcFile: megatron/core/pipeline_parallel/schedules.py (L232-248)
python
num_tokens = torch.tensor(0, dtype=torch.int)
if is_last_stage:
if not collect_non_loss_data:
outputs = loss_func(output_tensor)
if len(outputs) == 3:
output_tensor, num_tokens, loss_reduced = outputs
if not config.calculate_per_token_loss:
# Protect against division by zero when all tokens are masked
# in a microbatch.
output_tensor /= torch.clamp(num_tokens, min=1)
output_tensor /= num_microbatches
else:
# preserve legacy loss averaging behavior (ie, over the number of microbatches)
assert len(outputs) == 2
output_tensor, loss_reduced = outputs
output_tensor *= cp_group_size
output_tensor /= num_microbatchesFile: megatron/core/pipeline_parallel/schedules.py (L257-285)
python
# Set the loss scale for the auxiliary loss of the MoE layer.
# Since we use a trick to do backward on the auxiliary loss, we need to set the scale
# explicitly.
if hasattr(config, 'num_moe_experts') and config.num_moe_experts is not None:
# Calculate the loss scale based on the grad_scale_func if available, else default to 1.
loss_scale = (
config.grad_scale_func(torch.ones(1, device=output_tensor.device))
if config.grad_scale_func is not None
else torch.ones(1, device=output_tensor.device)
)
# Set the loss scale
if config.calculate_per_token_loss:
MoEAuxLossAutoScaler.set_loss_scale(loss_scale)
else:
MoEAuxLossAutoScaler.set_loss_scale(loss_scale / num_microbatches)
# Set the loss scale for Multi-Token Prediction (MTP) loss.
if hasattr(config, 'mtp_num_layers') and config.mtp_num_layers is not None:
# Calculate the loss scale based on the grad_scale_func if available, else default to 1.
loss_scale = (
config.grad_scale_func(torch.ones(1, device=output_tensor.device))
if config.grad_scale_func is not None
else torch.ones(1, device=output_tensor.device)
)
# Set the loss scale
if config.calculate_per_token_loss:
MTPLossAutoScaler.set_loss_scale(loss_scale)
else:
MTPLossAutoScaler.set_loss_scale(loss_scale / num_microbatches)File: megatron/core/pipeline_parallel/schedules.py (L290-422)
python
def forward_step(
forward_step_func,
data_iterator,
model,
num_microbatches,
input_tensor,
forward_data_store,
config,
cp_group_size,
collect_non_loss_data=False,
checkpoint_activations_microbatch=None,
is_first_microbatch=False,
current_microbatch=None,
vp_stage=None,
is_last_stage=True,
):
"""Forward step for passed-in model.
If it is the first stage, the input tensor is obtained from the data_iterator.
Otherwise, the passed-in input_tensor is used.
Args:
forward_step_func (callable):
The forward step function for the model that takes the
data iterator as the first argument, and model as the second.
This user's forward step is expected to output a tuple of two elements:
1. The output object from the forward step. This output object needs to be a
tensor or some kind of collection of tensors. The only hard requirement
for this object is that it needs to be acceptible as input into the second
function.
2. A function to reduce (optionally) the output from the forward step. This
could be a reduction over the loss from the model, it could be a function that
grabs the output from the model and reformats, it could be a function that just
passes through the model output. This function must have one of the following
patterns, and depending on the pattern different things happen internally:
a. A tuple of reduced loss and some other data. Note that in this case
the first argument is divided by the number of global microbatches,
assuming it is a loss, so that the loss is stable as a function of
the number of devices the step is split across.
b. A triple of reduced loss, number of tokens, and some other data. This
is similar to case (a), but the loss is further averaged across the
number of tokens in the batch. If the user is not already averaging
across the number of tokens, this pattern is useful to use.
c. Any arbitrary data the user wants (eg a dictionary of tensors, a list
of tensors, etc in the case of inference). To trigger case 3 you need
to specify `collect_non_loss_data=True` and you may also want to
specify `forward_only=True` in the call to the parent forward_backward
function.
data_iterator (iterator):
The data iterator.
model (nn.Module):
The model to perform the forward step on.
num_microbatches (int):
The number of microbatches.
input_tensor (Tensor or list[Tensor]):
The input tensor(s) for the forward step.
forward_data_store (list):
The list to store the forward data. If you go down path 2.a or
2.b for the return of your forward reduction function then this will store only the
final dimension of the output, for example the metadata output by the loss function.
If you go down the path of 2.c then this will store the entire output of the forward
reduction function applied to the model output.
config (object):
The configuration object.
collect_non_loss_data (bool, optional):
Whether to collect non-loss data. Defaults to False.
This is the path to use if you want to collect arbitrary output from the model forward,
such as with inference use cases. Defaults to False.
checkpoint_activations_microbatch (int, optional):
The microbatch to checkpoint activations.
Defaults to None.
is_first_microbatch (bool, optional):
Whether it is the first microbatch. Defaults to False.
current_microbatch (int, optional):
The current microbatch. Defaults to None.
vp_stage (int, optional):
The virtual pipeline stage. Defaults to None.
is_last_stage (bool, optional):
Whether it is the last stage. Defaults to True.
Also considering virtual stages.
In case of PP/VPP, is_last_stage/is_vp_last_stage.
Returns:
Tensor or list[Tensor]: The output object(s) from the forward step.
Tensor: The number of tokens.
"""
from megatron.core.transformer.multi_token_prediction import MTPLossAutoScaler
if config.timers is not None:
config.timers('forward-compute', log_level=2).start()
if is_first_microbatch and hasattr(model, 'set_is_first_microbatch'):
model.set_is_first_microbatch()
if current_microbatch is not None:
set_current_microbatch(model, current_microbatch)
unwrap_output_tensor = False
if not isinstance(input_tensor, list):
input_tensor = [input_tensor]
unwrap_output_tensor = True
set_input_tensor = get_attr_wrapped_model(model, "set_input_tensor")
set_input_tensor(input_tensor)
if config.enable_autocast:
context_manager = torch.autocast("cuda", dtype=config.autocast_dtype)
else:
context_manager = contextlib.nullcontext()
with context_manager:
if checkpoint_activations_microbatch is None:
output_tensor, loss_func = forward_step_func(data_iterator, model)
else:
output_tensor, loss_func = forward_step_func(
data_iterator, model, checkpoint_activations_microbatch
)
output_tensor, num_tokens = forward_step_calc_loss(
model,
output_tensor,
loss_func,
config,
vp_stage,
collect_non_loss_data,
num_microbatches,
forward_data_store,
cp_group_size,
is_last_stage,
)
if unwrap_output_tensor:
return output_tensor, num_tokens
return [output_tensor], num_tokensFile: megatron/core/pipeline_parallel/schedules.py (L425-486)
python
def backward_step(input_tensor, output_tensor, output_tensor_grad, model_type, config):
"""Backward step through passed-in output tensor.
If last stage, output_tensor_grad is None, otherwise gradient of loss
with respect to stage's output tensor.
Returns gradient of loss with respect to input tensor (None if first
stage)."""
# NOTE: This code currently can handle at most one skip connection. It
# needs to be modified slightly to support arbitrary numbers of skip
# connections.
if config.timers is not None:
config.timers('backward-compute', log_level=2).start()
# Retain the grad on the input_tensor.
unwrap_input_tensor_grad = False
if not isinstance(input_tensor, list):
input_tensor = [input_tensor]
unwrap_input_tensor_grad = True
for x in input_tensor:
if x is not None:
x.retain_grad()
if not isinstance(output_tensor, list):
output_tensor = [output_tensor]
if not isinstance(output_tensor_grad, list):
output_tensor_grad = [output_tensor_grad]
# Backward pass.
if output_tensor_grad[0] is None and config.grad_scale_func is not None:
output_tensor[0] = config.grad_scale_func(output_tensor[0])
# In multi-modal models like VLM, some batches may not have images.
# When no image is present, the vision encoder (as a separate pipeline stage)
# will not participate in the computation.
# This results in a tensor that does not require gradients.
# In such cases, we intentionally skip the backward pass while preserving zero gradients.
if output_tensor[0].requires_grad:
if config.deallocate_pipeline_outputs:
custom_backward(output_tensor[0], output_tensor_grad[0])
else:
torch.autograd.backward(output_tensor[0], grad_tensors=output_tensor_grad[0])
# Collect the grad of the input_tensor.
input_tensor_grad = [None]
if input_tensor is not None:
input_tensor_grad = []
for x in input_tensor:
if x is None:
input_tensor_grad.append(None)
else:
input_tensor_grad.append(x.grad)
if unwrap_input_tensor_grad:
input_tensor_grad = input_tensor_grad[0]
if config.timers is not None:
config.timers('backward-compute').stop()
return input_tensor_gradFile: megatron/core/pipeline_parallel/schedules.py (L593-634)
python
with no_sync_func():
for i in range(num_microbatches - 1):
output_tensor, num_tokens = forward_step(
forward_step_func,
data_iterator,
model,
num_microbatches,
input_tensor,
forward_data_store,
config,
pg_collection.cp.size(),
collect_non_loss_data,
is_first_microbatch=check_first_val_step(first_val_step, forward_only, i == 0),
current_microbatch=i,
)
total_num_tokens += num_tokens
if not forward_only:
backward_step(
input_tensor, output_tensor, output_tensor_grad, model_type, config
)
# Run computation for last microbatch out of context handler (want to
# synchronize gradients).
output_tensor, num_tokens = forward_step(
forward_step_func,
data_iterator,
model,
num_microbatches,
input_tensor,
forward_data_store,
config,
pg_collection.cp.size(),
collect_non_loss_data,
is_first_microbatch=check_first_val_step(
first_val_step, forward_only, num_microbatches == 1
),
current_microbatch=num_microbatches - 1,
)
total_num_tokens += num_tokens
if not forward_only:
backward_step(input_tensor, output_tensor, output_tensor_grad, model_type, config)File: megatron/core/pipeline_parallel/schedules.py (L1870-1877)
python
# Launch any remaining grad reductions.
enable_grad_sync()
if config.grad_sync_func is not None:
for model_chunk_id in range(num_model_chunks):
if model_chunk_id not in synchronized_model_chunks:
config.grad_sync_func[model_chunk_id](model[model_chunk_id].parameters())
synchronized_model_chunks.add(model_chunk_id)
nvtx_range_pop(suffix="cooldown")File: megatron/core/pipeline_parallel/schedules.py (L1887-1903)
python
if config.finalize_model_grads_func is not None and not forward_only:
# If defer_embedding_wgrad_compute is enabled we need to do the
# weight gradient GEMM's here.
finish_embedding_wgrad_compute(
config, embedding_module, is_pp_last_stage(p2p_communicator.pp_group), tp_group
)
# Finalize model grads (perform full grad all-reduce / reduce-scatter for
# data parallelism, layernorm all-reduce for sequence parallelism, and
# embedding all-reduce for pipeline parallelism).
config.finalize_model_grads_func(
model,
total_num_tokens if config.calculate_per_token_loss else None,
pg_collection=pg_collection,
)File: megatron/core/pipeline_parallel/schedules.py (L1949-1965)
python
def forward_backward_pipelining_without_interleaving(
*,
forward_step_func,
data_iterator: Union[Iterator, List[Iterator]],
model: Union[torch.nn.Module, List[torch.nn.Module]],
num_microbatches: int,
seq_length: int,
micro_batch_size: int,
decoder_seq_length: Optional[int] = None,
forward_only: bool = False,
collect_non_loss_data: bool = False,
first_val_step: Optional[bool] = None,
adjust_tensor_shapes_fn: Optional[Callable] = None,
p2p_communicator: Optional[P2PCommunicator] = None,
pg_collection: Optional[ProcessGroupCollection] = None,
):
"""Run non-interleaved 1F1B schedule, with communication between pipelineFile: pretrain_gpt.py (L59-118)
python
def loss_func(
loss_mask: torch.Tensor, output_tensor: torch.Tensor, model: Optional[GPTModel] = None
):
"""Loss function.
Args:
loss_mask (torch.Tensor): Used to mask out some portions of the loss
output_tensor (torch.Tensor): The tensor with the losses
model (GPTModel, optional): The model (can be wrapped)
Returns:
the loss scalar for this micro-batch
the number of non-padded tokens in this microbatch
a dict containing reporting metrics on the loss and number of tokens across
the data parallel ranks
"""
args = get_args()
if has_nvidia_modelopt and modelopt_args_enabled(args): # [ModelOpt]
return loss_func_modelopt(loss_mask, output_tensor, model=model)
losses = output_tensor.view(-1).float()
loss_mask = loss_mask.view(-1).float()
loss = torch.sum(losses * loss_mask)
# Check individual rank losses are not NaN prior to DP all-reduce.
rerun_state_machine = get_rerun_state_machine()
if args.check_for_nan_in_loss_and_grad:
rerun_state_machine.validate_result(
result=loss,
rejection_func=torch.isnan,
message="found NaN in local forward loss calculation",
tolerance=0.0, # forward pass calculations are determinisic
fatal=True,
)
rerun_state_machine.validate_result(
result=loss,
rejection_func=torch.isinf,
message="found Inf in local forward loss calculation",
tolerance=0.0, # forward pass calculations are determinisic
fatal=True,
)
# Check for spiky loss
if args.check_for_spiky_loss:
rerun_state_machine.validate_result(
result=loss,
rejection_func=partial(
rerun_state_machine.is_unexpectedly_large,
threshold=SPIKY_LOSS_FACTOR,
context="loss",
),
message="Spiky loss",
tolerance=0.0, # forward pass calculations are determinisic
fatal=False,
)
num_tokens = loss_mask.sum().clone().detach().to(torch.int)
reporting_loss = torch.cat([loss.clone().detach().view(1), num_tokens.view(1)])
return (loss, num_tokens, {'lm loss': reporting_loss})File: pretrain_gpt.py (L121-157)
python
def forward_step(data_iterator, model: GPTModel, return_schedule_plan: bool = False):
"""Forward training step.
Args:
data_iterator : Input data iterator
model (GPTModel): The GPT Model
return_schedule_plan (bool): Whether to return the schedule plan instead of the output tensor
"""
args = get_args()
timers = get_timers()
# Get the batch.
timers('batch-generator', log_level=2).start()
global stimer
with stimer(bdata=True):
vp_stage = get_attr_wrapped_model(model, "vp_stage")
tokens, labels, loss_mask, attention_mask, position_ids = get_batch(data_iterator, vp_stage)
timers('batch-generator').stop()
with stimer:
if args.use_legacy_models:
output_tensor = model(tokens, position_ids, attention_mask, labels=labels)
else:
if return_schedule_plan:
assert args.overlap_moe_expert_parallel_comm, \
"overlap_moe_expert_parallel_comm must be enabled to return the schedule plan"
schedule_plan = model.build_schedule_plan(
tokens, position_ids, attention_mask, labels=labels, loss_mask=loss_mask
)
return schedule_plan, partial(loss_func, loss_mask, model=model)
else:
output_tensor = model(
tokens, position_ids, attention_mask, labels=labels, loss_mask=loss_mask
)
# [ModelOpt]: model is needed to access ModelOpt distillation losses
return output_tensor, partial(loss_func, loss_mask, model=model)File: megatron/core/models/gpt/gpt_model.py (L486-580)
python
def _postprocess(
self,
hidden_states,
input_ids,
position_ids,
labels,
rotary_pos_emb,
rotary_pos_cos,
rotary_pos_sin,
mtp_in_postprocess=None,
loss_mask=None,
decoder_input=None,
attention_mask=None,
inference_params=None,
packed_seq_params=None,
sequence_len_offset=None,
runtime_gather_output=None,
extra_block_kwargs=None,
inference_context=None,
):
"""Postprocesses decoder hidden states to generate logits or compute loss.
Applies Multi-Token Prediction if enabled, generates output logits through
the output layer, and computes language model loss when labels are provided.
"""
in_inference_mode = inference_context is not None and not self.training
if in_inference_mode:
assert runtime_gather_output, "Inference must always gather TP logits"
# logits and loss
output_weight = None
if self.share_embeddings_and_output_weights:
output_weight = self.shared_embedding_or_output_weight()
if mtp_in_postprocess:
hidden_states = self.mtp(
input_ids=input_ids,
position_ids=position_ids,
hidden_states=hidden_states,
attention_mask=attention_mask,
inference_params=inference_params,
rotary_pos_emb=rotary_pos_emb,
rotary_pos_cos=rotary_pos_cos,
rotary_pos_sin=rotary_pos_sin,
packed_seq_params=packed_seq_params,
sequence_len_offset=sequence_len_offset,
embedding=self.embedding,
**(extra_block_kwargs or {}),
)
if not self.post_process:
return hidden_states
if self.mtp_process:
mtp_labels = labels.clone()
hidden_states_list = torch.chunk(hidden_states, 1 + self.config.mtp_num_layers, dim=0)
hidden_states = hidden_states_list[0]
if loss_mask is None:
# if loss_mask is not provided, use all ones as loss_mask
loss_mask = torch.ones_like(mtp_labels)
for mtp_layer_number in range(self.config.mtp_num_layers):
# output
mtp_logits, _ = self.output_layer(
hidden_states_list[mtp_layer_number + 1],
weight=output_weight,
runtime_gather_output=runtime_gather_output,
)
# Calc loss for the current Multi-Token Prediction (MTP) layers.
mtp_labels, _ = roll_tensor(mtp_labels, shifts=-1, dims=-1, cp_group=self.cp_group)
loss_mask, num_tokens = roll_tensor(
loss_mask, shifts=-1, dims=-1, cp_group=self.cp_group
)
mtp_loss = self.compute_language_model_loss(mtp_labels, mtp_logits)
mtp_loss = loss_mask * mtp_loss
if self.training:
# TODO(shifangx): remove the use of parallel_state here
# after moving loss logging to loss_func in pretrain_gpt.py
MTPLossLoggingHelper.save_loss_to_tracker(
torch.sum(mtp_loss) / num_tokens,
mtp_layer_number,
self.config.mtp_num_layers,
avg_group=parallel_state.get_data_parallel_group(
with_context_parallel=True
),
)
mtp_loss_scale = self.config.mtp_loss_scaling_factor / self.config.mtp_num_layers
if self.config.calculate_per_token_loss:
hidden_states = MTPLossAutoScaler.apply(
hidden_states, mtp_loss_scale * mtp_loss
)
else:
hidden_states = MTPLossAutoScaler.apply(
hidden_states, mtp_loss_scale * mtp_loss / num_tokens
)
sequence_parallel_override = FalseFile: megatron/core/transformer/multi_token_prediction.py (L356-389)
python
class MTPLossAutoScaler(torch.autograd.Function):
"""An AutoScaler that triggers the backward pass and scales the grad for mtp loss."""
main_loss_backward_scale: torch.Tensor = torch.tensor(1.0)
@staticmethod
def forward(ctx, output: torch.Tensor, mtp_loss: torch.Tensor):
"""Preserve the mtp by storing it in the context to avoid garbage collection.
Args:
output (torch.Tensor): The output tensor.
mtp_loss (torch.Tensor): The mtp loss tensor.
Returns:
torch.Tensor: The output tensor.
"""
ctx.save_for_backward(mtp_loss)
return output
@staticmethod
def backward(ctx, grad_output: torch.Tensor):
"""Compute and scale the gradient for mtp loss..
Args:
grad_output (torch.Tensor): The gradient of the output.
Returns:
Tuple[torch.Tensor, torch.Tensor]: The gradient of the output, scaled mtp loss
gradient.
"""
(mtp_loss,) = ctx.saved_tensors
mtp_loss_backward_scale = MTPLossAutoScaler.main_loss_backward_scale
scaled_mtp_loss_grad = torch.ones_like(mtp_loss) * mtp_loss_backward_scale
return grad_output, scaled_mtp_loss_grad您询问的是 forward_step_func 是谁传递过来的,以及调用它会执行到哪里 。
forward_step_func 的来源
forward_step_func 是在 pretrain() 函数中作为参数传入的。 1
传递路径
-
在训练脚本中定义 : 在
pretrain_gpt.py中,定义了forward_step函数 2 -
传递给 pretrain() : 在
pretrain_gpt.py的主函数中,将forward_step作为forward_step_func参数传递给pretrain()2 -
传递给 train_step() :
pretrain()函数内部调用train_step()时,将forward_step_func继续传递 3 -
传递给 forward_backward_func :
train_step()调用forward_backward_func时,将forward_step_func作为参数传入 4 -
在调度函数中使用 : 调度函数(如
forward_backward_no_pipelining) 接收forward_step_func参数 5
调用 forward_step_func 执行到哪里
当 forward_step_func 被调用时,实际执行的是用户在训练脚本中定义的函数。
调用位置
在 forward_step() 函数中调用 forward_step_func 6
执行内容(以 pretrain_gpt.py 为例)
调用 forward_step_func(data_iterator, model) 会执行 pretrain_gpt.py 中的 forward_step 函数 2
具体执行步骤:
-
获取 batch 数据 : 调用
get_batch()获取 tokens, labels, loss_mask 等 7 -
模型前向传播 : 调用
model()执行前向传播,传入 tokens, position_ids, attention_mask, labels 8 -
返回结果 : 返回
output_tensor和partial(loss_func, loss_mask, model=model)9
其他训练脚本的实现
不同的训练脚本有不同的 forward_step_func 实现:
- pretrain_mamba.py : 类似的实现模式,但针对 Mamba 模型
- train_rl.py : 针对强化学习训练,计算 GRPO 损失 10
- 测试代码 : 在单元测试中也定义了简化版的
forward_step_func11
完整调用链
pretrain_gpt.py
定义 forward_step pretrain()
接收 forward_step_func train_step()
传递 forward_step_func forward_backward_func
传递 forward_step_func forward_step()
调用 forward_step_func 执行用户定义的
forward_step model.forward()
模型前向传播
Notes
这种设计模式使得 Megatron-LM 的训练框架非常灵活,用户可以在训练脚本中自定义 forward_step_func 来适配不同的模型和训练任务,而核心的调度逻辑(如 pipeline 并行、梯度累积等)保持不变。 在评估时,evaluate() 函数也使用相同的 forward_step_func,只是设置 forward_only=True 12
Wiki pages you might want to explore:
Citations
File: megatron/training/training.py (L530-543)
python
def pretrain(
train_valid_test_dataset_provider,
model_provider,
model_type,
forward_step_func,
process_non_loss_data_func=None,
extra_args_provider=None,
args_defaults={},
get_embedding_ranks=None,
get_position_embedding_ranks=None,
non_loss_data_func=None,
store=None,
inprocess_call_wrapper: Optional[CallWrapper] = None,
):File: megatron/training/training.py (L1228-1228)
python
def train_step(forward_step_func, data_iterator, model, optimizer, opt_param_scheduler, config, forward_backward_func):File: megatron/training/training.py (L1257-1267)
python
losses_reduced = forward_backward_func(
forward_step_func=forward_step_func,
data_iterator=data_iterator,
model=model,
num_microbatches=get_num_microbatches(),
seq_length=args.seq_length,
micro_batch_size=args.micro_batch_size,
decoder_seq_length=args.decoder_seq_length,
forward_only=False,
adjust_tensor_shapes_fn=adjust_tensor_shapes_fn,
)File: megatron/training/training.py (L2508-2517)
python
loss_dicts = forward_backward_func(
forward_step_func=forward_step_func,
data_iterator=data_iterator,
model=model,
num_microbatches=eval_num_microbatches,
seq_length=args.seq_length,
micro_batch_size=args.micro_batch_size,
decoder_seq_length=args.decoder_seq_length,
forward_only=True,
)File: pretrain_gpt.py (L121-157)
python
def forward_step(data_iterator, model: GPTModel, return_schedule_plan: bool = False):
"""Forward training step.
Args:
data_iterator : Input data iterator
model (GPTModel): The GPT Model
return_schedule_plan (bool): Whether to return the schedule plan instead of the output tensor
"""
args = get_args()
timers = get_timers()
# Get the batch.
timers('batch-generator', log_level=2).start()
global stimer
with stimer(bdata=True):
vp_stage = get_attr_wrapped_model(model, "vp_stage")
tokens, labels, loss_mask, attention_mask, position_ids = get_batch(data_iterator, vp_stage)
timers('batch-generator').stop()
with stimer:
if args.use_legacy_models:
output_tensor = model(tokens, position_ids, attention_mask, labels=labels)
else:
if return_schedule_plan:
assert args.overlap_moe_expert_parallel_comm, \
"overlap_moe_expert_parallel_comm must be enabled to return the schedule plan"
schedule_plan = model.build_schedule_plan(
tokens, position_ids, attention_mask, labels=labels, loss_mask=loss_mask
)
return schedule_plan, partial(loss_func, loss_mask, model=model)
else:
output_tensor = model(
tokens, position_ids, attention_mask, labels=labels, loss_mask=loss_mask
)
# [ModelOpt]: model is needed to access ModelOpt distillation losses
return output_tensor, partial(loss_func, loss_mask, model=model)File: megatron/core/pipeline_parallel/schedules.py (L401-406)
python
if checkpoint_activations_microbatch is None:
output_tensor, loss_func = forward_step_func(data_iterator, model)
else:
output_tensor, loss_func = forward_step_func(
data_iterator, model, checkpoint_activations_microbatch
)File: megatron/core/pipeline_parallel/schedules.py (L497-511)
python
def forward_backward_no_pipelining(
*,
forward_step_func,
data_iterator: Union[Iterator, List[Iterator]],
model: Union[torch.nn.Module, List[torch.nn.Module]],
num_microbatches: int,
seq_length: int, # unused
micro_batch_size: int, # unused
decoder_seq_length: Optional[int] = None, # unused
forward_only: bool = False,
collect_non_loss_data: bool = False,
first_val_step: Optional[bool] = None,
adjust_tensor_shapes_fn: Optional[Callable] = None, # unused
pg_collection: Optional[ProcessGroupCollection] = None,
):File: train_rl.py (L156-215)
python
def forward_step(data_iterator, model: GPTModel):
"""Forward training step.
Args:
data_iterator : Input data iterator
model (GPTModel): The GPT Model
"""
args = get_args()
timers = get_timers()
timers('batch-generator', log_level=2).start()
global stimer
with stimer(bdata=True):
(
tokens,
advantages,
old_logprobs,
loss_mask,
position_ids,
ref_logprobs,
inference_logprobs,
) = next(data_iterator)
timers('batch-generator').stop()
tokens = tokens.cuda()
position_ids = position_ids.cuda()
old_logprobs = old_logprobs.cuda()
ref_logprobs = ref_logprobs.cuda()
advantages = advantages.cuda()
inference_logprobs = (
inference_logprobs.cuda() if args.rl_inference_logprobs_is_correction else None
)
with stimer:
current_logprobs = get_logprobs(model, tokens, position_ids, None, no_grad=False)
loss, kl_term, ratios, entropy_term, truncated_from_above, truncated_from_below = (
calculate_grpo_loss(
current_logprobs=current_logprobs,
old_logprobs=old_logprobs,
ref_logprobs=ref_logprobs,
advantages=advantages,
clamp_eps_lower=args.grpo_clamp_eps_lower,
clamp_eps_upper=args.grpo_clamp_eps_upper,
kl_beta=args.grpo_kl_beta,
entropy_weight=args.grpo_entropy_term_weight,
inference_logprobs=inference_logprobs,
is_truncation_coef=args.rl_importance_sampling_truncation_coef,
)
)
# loss_mask will not be applied to 0th token as we do not have a logprob for it.
return loss, partial(
loss_func,
loss_mask[:, 1:].contiguous(),
kl_term,
ratios,
entropy_term,
truncated_from_above,
truncated_from_below,
)File: tests/unit_tests/pipeline_parallel/test_schedules.py (L138-147)
python
def forward_step_func(data_iterator, model):
import os
rank = int(os.environ['LOCAL_RANK'])
dummy_data = torch.ones(1, 4)
def loss_func(output_tensor):
return rank, {'loss_reduced': rank}
return model(dummy_data), loss_func您询问的是 forward_backward_func 的作用以及为什么需要它 。 1
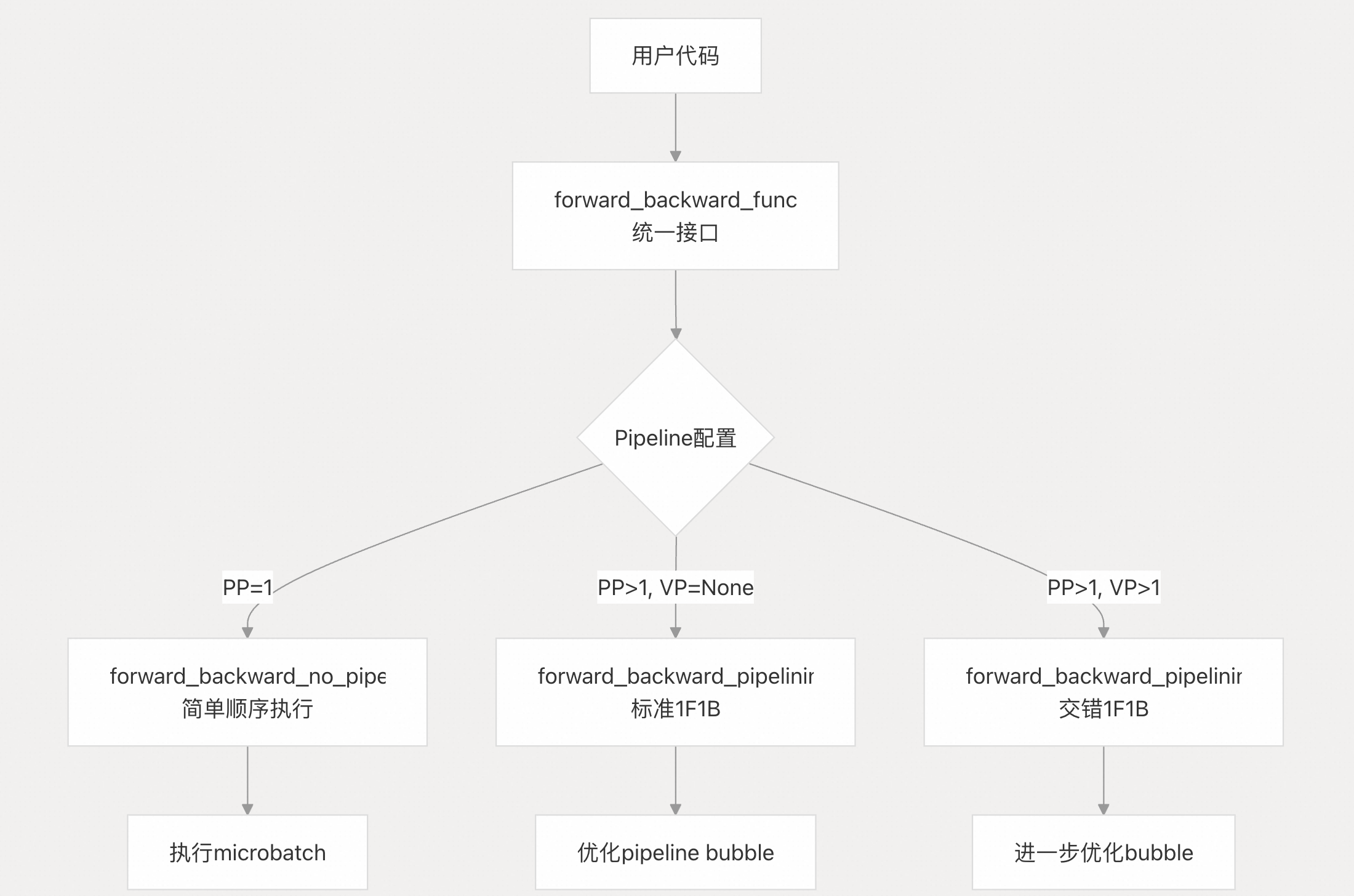
核心作用
forward_backward_func 是一个调度函数 ,负责协调整个训练过程中的前向传播和反向传播执行顺序,特别是在使用 pipeline 并行时。 2
为什么需要它
1. 支持多种并行策略
get_forward_backward_func() 根据 pipeline 配置自动选择合适的调度策略: 3
-
无 pipeline 并行 (
pipeline_model_parallel_size == 1): 返回forward_backward_no_pipelining,简单地顺序执行所有 microbatch 4 -
有 pipeline 但无 virtual pipeline : 返回
forward_backward_pipelining_without_interleaving,使用标准的 1F1B 调度 5 -
有 virtual pipeline : 返回
forward_backward_pipelining_with_interleaving,使用交错的 1F1B 调度以减少 pipeline bubble 6
2. 统一的接口抽象
通过统一的函数接口,训练代码无需关心底层的并行策略细节。在 train_step() 中,只需调用 forward_backward_func 并传入标准参数: 7
这种设计使得切换并行配置时,训练代码本身不需要修改。
3. 优化 Pipeline Bubble
对于 pipeline 并行,forward_backward_func 实现了 1F1B (one-forward-one-backward) 调度策略,这是一种优化的执行顺序: 8
- Warmup 阶段: 先执行若干个前向传播填充 pipeline
- 1F1B 阶段: 交替执行一个前向和一个反向,保持 pipeline 满载
- Cooldown 阶段: 完成剩余的反向传播
这种调度显著减少了 pipeline bubble,提高了 GPU 利用率。
4. 支持 CUDA Graph 等优化
forward_backward_func 可以被包装以支持额外的优化,例如 Full Iteration CUDA Graph: 9
通过 FullCudaGraphWrapper 包装后,整个前向反向过程可以被 CUDA Graph 捕获和重放,进一步提升性能。 10
实际使用示例
在训练循环中的使用: 11
在评估时也使用相同的接口: 12
在快速入门示例中的使用: 13
设计优势
PP=1 PP>1, VP=None PP>1, VP>1 用户代码 forward_backward_func
统一接口 Pipeline配置 forward_backward_no_pipelining
简单顺序执行 forward_backward_pipelining_without_interleaving
标准1F1B forward_backward_pipelining_with_interleaving
交错1F1B 执行microbatch 优化pipeline bubble 进一步优化bubble
Notes
这种设计体现了策略模式 的思想:将不同的调度算法封装成可互换的函数,通过工厂函数 get_forward_backward_func() 根据配置选择合适的实现。 这使得 Megatron-LM 能够灵活支持从单 GPU 到数千 GPU 的各种训练规模,而用户代码保持简洁统一。 测试代码也验证了这种设计的正确性。 14
Wiki pages you might want to explore:
Wiki pages you might want to explore:
Citations
File: megatron/core/pipeline_parallel/schedules.py (L40-132)
python
def get_forward_backward_func():
"""Retrieves the appropriate forward_backward function given the
configuration of parallel_state.
Returns a function that will perform all of the forward and
backward passes of the model given the pipeline model parallel
world size and virtual pipeline model parallel world size in the
global parallel_state.
Note that if using sequence parallelism, the sequence length component of
the tensor shape is updated to original_sequence_length /
tensor_model_parallel_world_size.
The function returned takes the following arguments:
forward_step_func (required): A function that takes a data
iterator and a model as its arguments and return the model's
forward output and the loss function. The loss function should
take one torch.Tensor and return a torch.Tensor of loss and a
dictionary of string -> torch.Tensor.
A third argument, checkpoint_activations_microbatch, indicates
that the activations for this microbatch should be
checkpointed. A None value for this argument indicates that
the default from the configuration should be used. This is
used when the
num_microbatches_with_partial_activation_checkpoints is used.
For example:
def loss_func(loss_mask, output_tensor):
losses = output_tensor.float()
loss_mask = loss_mask.view(-1).float()
loss = torch.sum(losses.view(-1) * loss_mask) / loss_mask.sum()
# Reduce loss for logging.
averaged_loss = average_losses_across_data_parallel_group([loss])
return loss, {'lm loss': averaged_loss[0]}
def forward_step(data_iterator, model):
data, loss_mask = next(data_iterator)
output = model(data)
return output, partial(loss_func, loss_mask)
forward_backward_func(forward_step_func=forward_step, ...)
data_iterator (required): an iterator over the data, will be
passed as is to forward_step_func. Expected to be a list of
iterators in the case of interleaved pipeline parallelism.
model (required): the actual model. Expected to be a list of modules in the case of interleaved
pipeline parallelism. Must be a (potentially wrapped) megatron.core.models.MegatronModule.
num_microbatches (int, required):
The number of microbatches to go through
seq_length (int, required): Sequence length of the current global batch. If this is a dual-stack
transformer, this is the encoder's sequence length. This is ignored if variable_seq_lengths
in the config is True. Otherwise, each microbatch in the current global batch size must use
this sequence length.
micro_batch_size (int, required): The number of sequences in a microbatch.
decoder_seq_length (int, optional): The sequence length for the decoder in a dual-stack
transformer. This is ignored for a single-stack transformer.
forward_only (optional, default = False): Perform only the forward step
collect_non_loss_data (optional, bool, default=False): TODO
first_val_step (bool, optional): Is the first step of the validation phase. Used by
Transformer Engine modules to only update their fp8 weights only on the first validation
step.
adjust_tensor_shapes_fn (Callable, optional): A function that adjusts the receive and send
tensor shapes. Only applicable in forward_backward_pipelining_without_interleaving for now.
Takes in a list of receive shapes and a list of send shapes and returns the adjusted
respective list of shapes. Thus it is not used in the other forward-backward functions
which have different shape handling.
"""
pipeline_model_parallel_size = parallel_state.get_pipeline_model_parallel_world_size()
if pipeline_model_parallel_size > 1:
if parallel_state.get_virtual_pipeline_model_parallel_world_size() is not None:
forward_backward_func = forward_backward_pipelining_with_interleaving
else:
forward_backward_func = forward_backward_pipelining_without_interleaving
else:
forward_backward_func = forward_backward_no_pipelining
return forward_backward_funcFile: megatron/core/pipeline_parallel/schedules.py (L497-512)
python
def forward_backward_no_pipelining(
*,
forward_step_func,
data_iterator: Union[Iterator, List[Iterator]],
model: Union[torch.nn.Module, List[torch.nn.Module]],
num_microbatches: int,
seq_length: int, # unused
micro_batch_size: int, # unused
decoder_seq_length: Optional[int] = None, # unused
forward_only: bool = False,
collect_non_loss_data: bool = False,
first_val_step: Optional[bool] = None,
adjust_tensor_shapes_fn: Optional[Callable] = None, # unused
pg_collection: Optional[ProcessGroupCollection] = None,
):
"""Run forward and backward passes with no pipeline parallelism"""File: megatron/core/pipeline_parallel/schedules.py (L1234-1348)
python
def backward_step_helper_preprocess(virtual_microbatch_id, model_chunk_id):
"""Preprocess for backward_step_helper"""
# launch grad synchronization (default)
if config.grad_sync_func is None and is_last_microbatch_for_model_chunk(
virtual_microbatch_id
):
enable_grad_sync()
synchronized_model_chunks.add(model_chunk_id)
# pylint: disable=E0606
if _is_vp_last_stage(vp_stage=model_chunk_id) and is_pp_last_stage(pp_group):
if len(output_tensor_grads[model_chunk_id]) == 0:
output_tensor_grads[model_chunk_id].append(None)
input_tensor = input_tensors[model_chunk_id].pop(0)
output_tensor = output_tensors[model_chunk_id].pop(0)
output_tensor_grad = output_tensor_grads[model_chunk_id].pop(0)
return input_tensor, output_tensor, output_tensor_grad
def backward_step_helper_postprocess(virtual_microbatch_id):
"""Postprocess for backward_step_helper"""
# launch grad synchronization (custom grad sync)
# Note: Asynchronous communication tends to slow down compute.
# To reduce idling from mismatched microbatch times, we launch
# asynchronous communication at the same time across the
# pipeline-parallel group.
if config.grad_sync_func is not None:
grad_sync_virtual_microbatch_id = virtual_microbatch_id - pipeline_parallel_rank
if grad_sync_virtual_microbatch_id >= 0 and is_last_microbatch_for_model_chunk(
grad_sync_virtual_microbatch_id
):
grad_sync_chunk_id = get_model_chunk_id(
grad_sync_virtual_microbatch_id, forward=False
)
enable_grad_sync()
config.grad_sync_func[grad_sync_chunk_id](model[grad_sync_chunk_id].parameters())
synchronized_model_chunks.add(grad_sync_chunk_id)
disable_grad_sync()
def backward_step_helper(virtual_microbatch_id):
"""Helper method to run backward step with model split into chunks"""
nonlocal output_tensor_grads
model_chunk_id = get_model_chunk_id(virtual_microbatch_id, forward=False)
input_tensor, output_tensor, output_tensor_grad = backward_step_helper_preprocess(
virtual_microbatch_id, model_chunk_id
)
input_tensor_grad = backward_step(
input_tensor, output_tensor, output_tensor_grad, model_type, config
)
backward_step_helper_postprocess(virtual_microbatch_id)
return input_tensor_grad
def forward_backward_helper_wrapper(
f_virtual_microbatch_id=None,
b_virtual_microbatch_id=None,
pre_forward=None,
pre_backward=None,
post_forward=None,
post_backward=None,
checkpoint_activations_microbatch=None,
):
"""
wrap forward_helper, backward_helper, and combined_forward_backward_helper in a unified way
"""
if config.overlap_moe_expert_parallel_comm and not forward_only: # Combined 1F1B path
return combined_1f1b_schedule_for_interleaved_pipelining(
config,
forward_step_func,
data_iterator,
model,
num_microbatches,
forward_data_store,
forward_step_helper_preprocess,
forward_step_helper_postprocess,
backward_step_helper_preprocess,
backward_step_helper_postprocess,
get_microbatch_id_in_model_chunk,
get_model_chunk_id,
partial(check_first_val_step, first_val_step, forward_only),
is_first_microbatch_for_model_chunk,
collect_non_loss_data,
f_virtual_microbatch_id=f_virtual_microbatch_id,
b_virtual_microbatch_id=b_virtual_microbatch_id,
pre_forward=pre_forward,
pre_backward=pre_backward,
post_forward=post_forward,
post_backward=post_backward,
)
else: # Conventional interleaved 1F1B path
forward_output_tensor = None
backward_input_tensor_grad = None
# forward pass
if f_virtual_microbatch_id is not None:
forward_model_chunk_id = get_model_chunk_id(f_virtual_microbatch_id, forward=True)
if pre_forward is not None:
pre_forward()
forward_output_tensor = forward_step_helper(
f_virtual_microbatch_id, checkpoint_activations_microbatch
)
if post_forward is not None:
forward_output_tensor = post_forward(forward_output_tensor)
# Backward pass.
if b_virtual_microbatch_id is not None:
backward_model_chunk_id = get_model_chunk_id(b_virtual_microbatch_id, forward=False)
if pre_backward is not None:
pre_backward()
backward_input_tensor_grad = backward_step_helper(b_virtual_microbatch_id)
if post_backward is not None:
backward_input_tensor_grad = post_backward(backward_input_tensor_grad)
return forward_output_tensor, backward_input_tensor_gradFile: megatron/training/training.py (L1257-1267)
python
losses_reduced = forward_backward_func(
forward_step_func=forward_step_func,
data_iterator=data_iterator,
model=model,
num_microbatches=get_num_microbatches(),
seq_length=args.seq_length,
micro_batch_size=args.micro_batch_size,
decoder_seq_length=args.decoder_seq_length,
forward_only=False,
adjust_tensor_shapes_fn=adjust_tensor_shapes_fn,
)File: megatron/training/training.py (L2103-2105)
python
forward_backward_func = get_forward_backward_func()
if args.enable_cuda_graph and args.cuda_graph_scope=="full_iteration":
forward_backward_func = FullCudaGraphWrapper(forward_backward_func, cuda_graph_warmup_steps=args.cuda_graph_warmup_steps)File: megatron/training/training.py (L2268-2270)
python
) = train_step(
forward_step_func, train_data_iterator, model, optimizer, opt_param_scheduler, config, forward_backward_func
)File: megatron/training/training.py (L2508-2517)
python
loss_dicts = forward_backward_func(
forward_step_func=forward_step_func,
data_iterator=data_iterator,
model=model,
num_microbatches=eval_num_microbatches,
seq_length=args.seq_length,
micro_batch_size=args.micro_batch_size,
decoder_seq_length=args.decoder_seq_length,
forward_only=True,
)File: megatron/core/full_cuda_graph.py (L94-104)
python
class FullCudaGraphWrapper:
"""Wrapper class to enable FullIterationCUDAgraph."""
curr_iteration = {'training': 0, 'validation': 0}
cuda_graph = {'training': None, 'validation': None}
result = {'training': None, 'validation': None}
def __init__(self, forward_backward_func, cuda_graph_warmup_steps=1):
self.forward_backward_func = forward_backward_func
self.static_loader = StaticBufferLoader()
self.cuda_graph_warmup_steps = cuda_graph_warmup_stepsFile: megatron/core/QuickStart.md (L223-237)
markdown
forward_backward_func = get_forward_backward_func()
# Running the model for 5 iterations
for _ in range(5):
optim.zero_grad()
losses_reduced = forward_backward_func(
forward_step_func=forward_step_func,
data_iterator=train_iterator,
model=gpt_model,
num_microbatches=1,
seq_length=64,
micro_batch_size=8,
decoder_seq_length=64,
forward_only=False)File: tests/unit_tests/pipeline_parallel/test_schedules.py (L37-66)
python
def test_get_forward_backward_func():
Utils.initialize_model_parallel(tensor_model_parallel_size=2, pipeline_model_parallel_size=1)
assert schedule.get_forward_backward_func() == schedule.forward_backward_no_pipelining
Utils.destroy_model_parallel()
Utils.initialize_model_parallel(tensor_model_parallel_size=2, pipeline_model_parallel_size=4)
assert (
schedule.get_forward_backward_func()
== schedule.forward_backward_pipelining_without_interleaving
)
Utils.destroy_model_parallel()
Utils.initialize_model_parallel(
tensor_model_parallel_size=2,
pipeline_model_parallel_size=4,
virtual_pipeline_model_parallel_size=2,
)
assert (
schedule.get_forward_backward_func()
== schedule.forward_backward_pipelining_with_interleaving
)
Utils.destroy_model_parallel()
Utils.initialize_model_parallel(
tensor_model_parallel_size=2,
pipeline_model_parallel_size=2,
virtual_pipeline_model_parallel_size=4,
)
assert (
schedule.get_forward_backward_func()
== schedule.forward_backward_pipelining_with_interleaving
)
Utils.destroy_model_parallel()