秒杀-库存超卖&流量削峰
- [1. 秒杀场景核心定义🔥](#1. 秒杀场景核心定义🔥)
- [2. 核心方案代码示例与解析💻](#2. 核心方案代码示例与解析💻)
-
- [2.1 基础表结构🔍](#2.1 基础表结构🔍)
- [2.2 第0步:原始裸奔时代(问题暴露)📜](#2.2 第0步:原始裸奔时代(问题暴露)📜)
- [2.3 第1步演进:粗暴的守护神(悲观锁 `SELECT ... FOR UPDATE`)🔒](#2.3 第1步演进:粗暴的守护神(悲观锁
SELECT ... FOR UPDATE)🔒) - [2.4 第2步演进:乐观尝试(乐观锁-版本号 `version`)🔄](#2.4 第2步演进:乐观尝试(乐观锁-版本号
version)🔄) - [2.5 第3步演进:釜底抽薪(数据库原子操作 `WHERE stock > 0`)⚡](#2.5 第3步演进:釜底抽薪(数据库原子操作
WHERE stock > 0)⚡) - [2.6 第4步演进:化整为零(库存分段/分桶)🧩](#2.6 第4步演进:化整为零(库存分段/分桶)🧩)
- [2.7 第5步演进:质的飞跃(Redis缓存 + 异步化)🚀](#2.7 第5步演进:质的飞跃(Redis缓存 + 异步化)🚀)
- [2.8 演进总结💎](#2.8 演进总结💎)
- [2.9 大厂方案的拼图🏢](#2.9 大厂方案的拼图🏢)
- [3. 流量削峰:让系统在高并发中优雅呼吸](#3. 流量削峰:让系统在高并发中优雅呼吸)
-
- [3.1 什么是流量削峰?🌟](#3.1 什么是流量削峰?🌟)
- [3.2 为什么需要流量削峰?📈](#3.2 为什么需要流量削峰?📈)
-
- [1. 现实场景的痛点](#1. 现实场景的痛点)
- [2. 为什么不能直接用"升级服务器"解决?](#2. 为什么不能直接用"升级服务器"解决?)
- [3.3 流量削峰的本质🔧](#3.3 流量削峰的本质🔧)
- [3.4 流量削峰的实现方案🛠️](#3.4 流量削峰的实现方案🛠️)
-
- [1. MQ消息队列实现削峰(最常用方案)](#1. MQ消息队列实现削峰(最常用方案))
- [2. 分层过滤机制(漏斗式设计)](#2. 分层过滤机制(漏斗式设计))
- [3. 验证机制(延缓请求)](#3. 验证机制(延缓请求))
- [4. 限流机制(有损方案)](#4. 限流机制(有损方案))
- [3.5 流量削峰的分类💡](#3.5 流量削峰的分类💡)
- [3.6 大厂实战:阿里双11的流量削峰🌐](#3.6 大厂实战:阿里双11的流量削峰🌐)
- [3.7 流量削峰的终极意义🌟](#3.7 流量削峰的终极意义🌟)
1. 秒杀场景核心定义🔥
- 什么是秒杀? 秒杀是电商中一种高并发、低库存、短时间的营销活动(如"1元抢购"、"限量发售"),典型特征:
- 超高并发:10万+ 用户同时请求(如双11峰值58.3万笔/秒)。
- 超低库存:商品库存通常为100-1000件。
- 极低容忍度 :
超卖(库存为负)是致命问题。
- 核心挑战 :在毫秒级时间内,并发请求量远超数据库处理能力,导致库存超卖、系统崩溃、用户体验差。
- 在一个典型电商秒杀中,某商品库存
1000件,秒杀开始瞬间,数十万甚至上百万请求涌向系统 ,目标都是抢这1000件商品。系统的核心使命是 :准确无误地让最多1000个请求成功,其余全部优雅地失败,同时保证系统不崩溃。本质上是 "海量请求 vs 有限资源" 的矛盾。
2. 核心方案代码示例与解析💻
2.1 基础表结构🔍
sql
-- 商品库存表
CREATE TABLE `sku_stock` (
`id` bigint(20) PRIMARY KEY COMMENT '主键',
`sku_id` bigint(20) NOT NULL COMMENT '商品ID',
`stock` int(11) NOT NULL DEFAULT '0' COMMENT '可用库存',
PRIMARY KEY (`id`),
UNIQUE KEY `si_un` (`sku_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;2.2 第0步:原始裸奔时代(问题暴露)📜
这是所有噩梦的起点,超卖(卖出超过1000件)的根源。
1. 逻辑:查询库存,如果够,就更新。
java
// 问题代码(伪代码),展示问题逻辑
// skuId:商品ID,quantity:要购买的商品数量
public boolean deductStock(Long skuId, Integer quantity) {
// 1. 查询库存(实时值)
Integer stock = skuStockMapper.selectStock(skuId); // 假设此时 stock = 1
if (stock < quantity) {
return false; // 库存不足
}
// 2. 更新库存(基于旧的值)
int rows = skuStockMapper.updateStock(skuId, quantity); // 问题在此!!!
return rows > 0;
}2. 对应的简单SQL:
sql
-- 查询
SELECT stock FROM sku_stock WHERE sku_id = #{skuId};
-- 更新(问题巨大!!!)
UPDATE sku_stock SET stock = stock - #{quantity} WHERE sku_id = #{skuId};3. 问题根源 :在第1步查询和第2步更新之间,存在一个时间窗口。两个线程可能同时查询到 stock=1,都认为可以购买,然后依次执行更新,最终 stock = -1,超卖发生。
4. 结论 :超卖是 并发请求时 查询与更新之间存在间隙导致 ,不是数据库问题,而是 业务逻辑未原子化。
2.3 第1步演进:粗暴的守护神(悲观锁 SELECT ... FOR UPDATE)🔒
1. 思路 :在查询时就用数据库的排他锁锁住这行记录,让其他请求排队,强行将并发转为串行。
java
@Transactional // (spring声明式事务)事务是关键
// skuId:商品ID,quantity:要购买的商品数量
public boolean deductStockWithPessimisticLock(Long skuId, Integer quantity) {
// 1. 查询并加锁(InnoDB行锁 ------ 通过行锁确保同一时间只有一个事务能操作库存)
SkuStock stock = skuStockMapper.selectForUpdate(skuId); // 关键在此!!!
if (stock.getStock() < quantity) {
return false; // 库存不足
}
// 2. 更新(此时这行记录仍被锁住)
int rows = skuStockMapper.updateStock(skuId, quantity);
return rows > 0;
}2. SQL变化:
sql
-- 加锁查询
SELECT * FROM sku_stock WHERE id = #{skuId} FOR UPDATE;3. 解决了什么:
- 彻底杜绝超卖:InnoDB行锁,通过行锁确保同一时间只有一个事务能操作库存,锁保证了串行化。
4. 带来的新问题:
- 性能灾难 :每个请求都要排队等锁。如果有
1000件商品,就意味着前1000个事务要串行执行,数据库连接瞬间被打满,响应时间飙升,系统吞吐量几乎降为零。 - 容易死锁:在多条记录或复杂事务中容易引发死锁。
5. 结论 :在真正的秒杀场景中,此方案 不可用。
2.4 第2步演进:乐观尝试(乐观锁-版本号 version)🔄
1. 思路:相信冲突不经常发生。先不加锁地查,更新时带上版本号条件,如果被其他事务改过(版本号变了),则更新失败,让应用层重试或放弃。
2. 表结构变化
sql
-- 商品库存表
CREATE TABLE `sku_stock` (
`id` bigint(20) PRIMARY KEY COMMENT '主键',
`sku_id` bigint(20) NOT NULL COMMENT '商品ID',
`stock` int(11) NOT NULL DEFAULT '0' COMMENT '可用库存',
`version` int(11) NOT NULL DEFAULT '0' COMMENT '版本号,用于乐观锁',
PRIMARY KEY (`id`),
UNIQUE KEY `si_un` (`sku_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;3. 代码
java
public boolean deductStockWithOptimisticLock(Long skuId, Integer quantity) {
int retryTimes = 3; // 乐观锁典型操作:有限重试
for (int i = 0; i < retryTimes; i++) {
// 1. 无锁查询(获取当前值和版本号)
SkuStock stock = skuStockMapper.selectById(skuId);
if (stock.getStock() < quantity) {
return false;
}
// 2. 带版本号的更新
int rows = skuStockMapper.updateStockWithVersion(
skuId,
quantity,
stock.getVersion() // 将之前查出的版本号作为条件
);
if (rows > 0) {
return true; // 更新成功,说明期间没有冲突
}
// 3. 更新失败(rows==0),说明有冲突,版本号变了,循环重试
// 可以稍作睡眠(Thread.sleep(10)),避免活锁
}
// 重试多次后仍然失败
throw new RuntimeException("系统繁忙,请重试");
}4. SQL变化:
sql
-- 更新语句的WHERE条件变复杂了
UPDATE sku_stock
SET
stock = stock - #{quantity},
version = version + 1 -- 版本号自增
WHERE
id = #{skuId}
AND version = #{oldVersion} -- 核心:只有版本号没变才能更新
AND stock >= #{quantity}; -- 通常也会加上库存判断,双保险5. 解决了什么:
- 释放了锁压力:读操作不再阻塞,数据库并发能力提升。
6. 带来的新问题:
- 高冲突下的"惊群效应" :在秒杀场景下,
1000个库存面对10万请求,会有大量请求在第2步更新失败(rows==0)。这些失败请求会不断重试,导致数据库UPDATE压力巨大,且用户体验极差(频繁提示"请重试")。 - 实现复杂:需要管理重试逻辑,处理失败流程。
7. 结论 :适用于 并发冲突较低 的场景(如普通商品编辑),不适用于 瞬时极高冲突 的秒杀。
2.5 第3步演进:釜底抽薪(数据库原子操作 WHERE stock > 0)⚡
1. 思路 :这是最关键的飞跃!将"判断库存"和"扣减库存"两个操作,融合成数据库一条原子性的SQL语句。把业务逻辑下推到数据库引擎,利用其事务和行锁保证绝对安全。
java
public boolean deductStockWithAtomicUpdate(Long skuId, Integer quantity) {
// 无需先查询!!! 直接更新!!!
int rows = skuStockMapper.updateStockAtomic(skuId, quantity);
// 根据影响行数判断结果
if (rows > 0) {
// 扣减成功,可以继续创建订单等
return true;
} else {
// 扣减失败,要么库存不足,要么商品不存在
// 注意:这里无法区分具体是哪种原因,通常需要查一下确认
return false;
}
}2. 核心SQL(请刻在脑海里):
sql
UPDATE sku_stock
SET stock = stock - #{quantity}
WHERE id = #{skuId} AND stock >= #{quantity}; -- 原子性的核心!3. 解决了什么:
- 完美解决超卖,且性能极高 :一条SQL完成所有事情,无锁竞争,只在更新瞬间有行锁。数据库自身保证
stock不会变成负数。 - 简化应用逻辑:代码变得极其简洁。
4. 仍存在的问题:
- 热点瓶颈 :所有请求最终都落到数据库 同一行 记录上更新。在秒杀级别,即使是毫秒级的行锁,也会因海量并发导致数据库CPU和连接资源耗尽,成为系统瓶颈。
- 无状态记录 :仅凭
rows无法知道是"库存不足" 还是 "重复请求",需要额外机制(如订单流水表)实现幂等性。
5. 结论 :这是所有数据库方案中最正确、最核心的一步,但它只解决了数据一致性问题,没解决"海量并发冲击单一数据库热点行"的性能问题。
6. 状态记录(幂等性实现)
sql
-- 流水表
CREATE TABLE `sku_stock_flow` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`sku_id` bigint(20) NOT NULL COMMENT '商品ID',
`order_sn` varchar(64) NOT NULL COMMENT '唯一订单号,用于幂等',
`quantity` int(11) NOT NULL COMMENT '扣减数量',
`status` tinyint(4) NOT NULL COMMENT '状态:1预扣成功 2扣减成功 3已回滚',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_order_sn` (`order_sn`) -- 唯一约束,防重复处理
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
java
@Service
@Transactional(rollbackFor = Exception.class)
public class StockServiceV3 {
@Autowired
private SkuStockMapper skuStockMapper;
@Autowired
private SkuStockFlowMapper flowMapper;
/**
* 扣减库存(方案三核心)
* @param skuId 商品ID
* @param orderSn 唯一订单号(幂等关键)
* @param quantity 数量
* @return 是否成功
*/
public boolean deductStock(Long skuId, String orderSn, Integer quantity) {
// 1. 幂等性检查:查询流水,防止重复扣减[citation:2]
SkuStockFlow existingFlow = flowMapper.selectByOrderSn(orderSn);
if (existingFlow != null) {
return existingFlow.getStatus() == 2; // 已成功则返回true
}
// 2. 插入预扣流水(状态为"预扣成功")
SkuStockFlow flow = new SkuStockFlow(skuId, orderSn, quantity, 1);
try {
flowMapper.insert(flow);
} catch (DuplicateKeyException e) {
// 并发下重复插入,说明其他请求已处理,转查询
return deductStock(skuId, orderSn, quantity);
}
// 3. 核心:原子更新库存
int affectedRows = skuStockMapper.updateStock(skuId, quantity);
if (affectedRows == 0) {
// 库存不足,更新流水状态为"回滚"(实际可能异步处理)
flowMapper.updateStatus(orderSn, 3);
throw new RuntimeException("库存不足");
}
// 4. 更新流水状态为"扣减成功"
flowMapper.updateStatus(orderSn, 2);
return true;
}
}2.6 第4步演进:化整为零(库存分段/分桶)🧩
1. 思路 :既然一个热点行 (sku_id=1) 撑不住,就把它拆成10个热点行 (sku_id=1_bucket_1 到 sku_id=1_bucket_10),将并发压力分散。
java
public boolean deductStockWithBucket(Long skuId, Integer quantity) {
// 策略1:随机选一个桶尝试
int bucketId = ThreadLocalRandom.current().nextInt(bucketCount);
// 策略2:根据用户ID哈希选桶(更均匀)
// int bucketId = userId.hashCode() % bucketCount;
int rows = skuStockMapper.updateStockAtomicOnBucket(skuId, bucketId, quantity);
if (rows > 0) {
// 扣减成功,记录这个订单是从哪个桶扣的,后续可能用到
return true;
}
// 当前桶库存不足,可以尝试其他桶(复杂度剧增)
return false;
}2. SQL和表结构变化:
sql
-- 表结构:增加了分桶字段
CREATE TABLE `sku_stock` (
`id` bigint(20) PRIMARY KEY COMMENT '主键',
`sku_id` bigint(20) NOT NULL COMMENT '商品ID',
`bucket_id` int(3) NOT NULL COMMENT '分桶编号',
`stock` int(11) NOT NULL DEFAULT '0' COMMENT '可用库存',
PRIMARY KEY (`id`),
UNIQUE KEY `sbi_un` (`sku_id`, `bucket_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 更新特定桶的库存
UPDATE sku_stock_bucket
SET stock = stock - 1
WHERE sku_id = #{skuId} AND bucket_id = #{bucketId} AND stock >= #{quantity};3. 解决了什么:
- 分散了数据库热点(消除单点瓶颈) :将
1个1000的库存行,变成10个100的库存行,理论上并发能力提升近10倍。
4. 带来的新问题:
- 逻辑复杂度飙升:如何路由请求?某个桶提前卖完怎么办?如何查询和展示总库存?如何防止某个桶成为新的小热点?
- 数据碎片化:管理、对账、补货都变得复杂。
- 分片数量需动态调整:流量大时需扩容。
5. 结论 :这是一个在"数据库-centric"时代缓解热点问题的过渡方案,治标不治本。在引入缓存后,其价值大大降低。
2.7 第5步演进:质的飞跃(Redis缓存 + 异步化)🚀
1. 思路 :认识到数据库不适合扛瞬时流量,必须引入内存缓存 (Redis) 作为"防洪坝 "。绝大部分请求在缓存层被处理,只有少量成功请求异步地、平缓地写入数据库。
这个方案不再是一个简单的Service方法,而是一个 架构。其核心流程如下图所示:
sql
// mermaid
sequenceDiagram
participant C as 海量用户请求
participant G as 网关/限流层
participant R as Redis集群
participant MQ as 消息队列(MQ)
participant W as 异步工作服务
participant DB as 数据库
C->>G: 1. 秒杀请求
G->>C: 2. 限流、排队、答题<br/>大部分请求在此被过滤
C->>R: 3. 通过Lua脚本原子扣减缓存库存
Note over R: 关键步骤:<br/>"查询&扣减"原子完成
alt 扣减成功
R->>MQ: 4. 发送秒杀成功消息
MQ->>W: 5. 消息被异步消费者获取
W->>DB: 6. 创建订单、最终扣减DB库存
W->>C: 7. 异步通知用户"抢购成功"
else 库存不足/失败
R->>C: 立即返回"已售罄"
end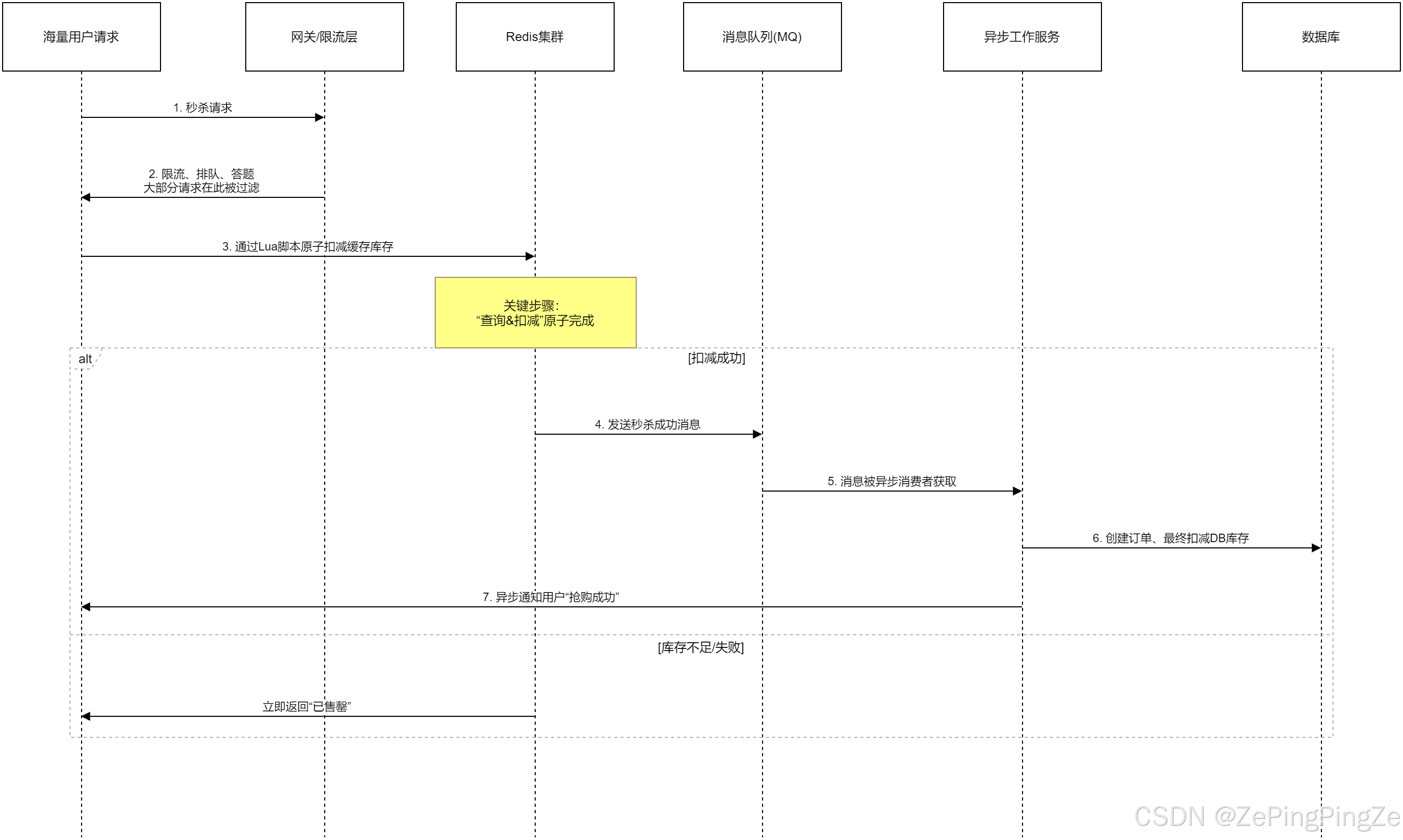
2. 代码实现的关键部分(Redis层):
java
// 使用Redis Lua脚本保证原子性
public class SecKillService {
private static final String LUA_SCRIPT =
"local stockKey = KEYS[1];"
+ "local orderKey = KEYS[2];"
+ "local quantity = tonumber(ARGV[1]);"
+ "local orderSn = ARGV[2];"
+ "local stock = tonumber(redis.call('get', stockKey));"
+ "if (stock == nil or stock < quantity) then "
+ "return 0;" // 库存不足
+ "end;"
+ "redis.call('decrby', stockKey, quantity);" // 扣减库存
+ "redis.call('hset', orderKey, orderSn, 'PRE_DEDUCT');" // 记录预扣流水,防重复
+ "return 1;";
public boolean trySecKillInRedis(Long skuId, String orderSn) {
String stockKey = "sec:stock:" + skuId;
String orderKey = "sec:order:" + skuId;
// 执行原子脚本
Long result = (Long) redisTemplate.execute(
new DefaultRedisScript<>(LUA_SCRIPT, Long.class),
Arrays.asList(stockKey, orderKey),
1, // 本次扣减数量
orderSn
);
return result == 1L;
}
}3. 解决了什么:
- 扛住瞬时流量(流量削峰):Redis单机QPS可达数万,集群更高,是数据库的百倍以上。
- 保护数据库:数据库只处理最终成功订单的落库,压力平缓。
- 快速响应:用户能立刻知道"抢购中"还是"已售罄"。
4. 带来的新挑战:
- 架构复杂度:需要引入消息队列、异步任务、独立服务。
- 数据一致性:缓存和数据库之间的数据同步是最大挑战(缓存预扣了,但用户没支付怎么办?系统崩溃了如何恢复?)。
- 幂等与恢复 :需要设计基于
orderSn的全局唯一流水,实现所有环节的幂等性,并建立定时对账任务修复不一致。
2.8 演进总结💎
| 阶段 | 方案 | 核心思想 | 主要矛盾 | 演进原因 |
|---|---|---|---|---|
| 0 | 裸奔查询更新 | 想当然 | 超卖 | 认知起点 |
| 1 | 悲观锁 (FOR UPDATE) |
用锁强行串行 | 性能差,死锁 | 解决超卖,但方式粗暴 |
| 2 | 乐观锁 (Version) |
无锁读,写时校验 | 高冲突下大量失败重试 | 试图提升读并发 |
| 3 | 数据库原子操作 (WHERE stock>0) |
逻辑下推,原子化 | 数据库热点行瓶颈 | 解决超卖的正确姿势,性能佳 |
| 4 | 库存分桶 | 分散热点 | 逻辑复杂,治标不治本 | 试图缓解阶段3的瓶颈 |
| 5 | Redis缓存+异步化 | 读写分离,内存扛量 | 架构复杂,数据一致性 | 根本性解决数据库扛不住瞬时流量的问题 |
| 方案 | 核心思路 | 解决了什么 | 存在什么问题 | 适用场景 |
|---|---|---|---|---|
方案一:SELECT ... FOR UPDATE |
悲观锁,在事务中先加锁再查询更新。 | 初步解决超卖,保证了隔离性。 | 性能瓶颈 :串行处理,高并发下数据库连接迅速耗尽,大量请求超时。死锁风险:事务顺序不当易引发。 | 低频、库存充足的普通抢购,不适用于真正的高并发秒杀。 |
| 方案二:乐观锁 (Version) | 更新时带版本号,冲突则重试或失败。 | 避免长事务锁等待,提升并发吞吐。 | 高冲突下的性能骤降 :大量请求因版本冲突失败,用户体验差。ABA问题:需配合业务逻辑处理。 | 并发冲突可控(如普通商品编辑)、或作为"最终一致性"场景下的并发控制手段。 |
方案三:UPDATE ... WHERE stock > 0 |
将库存检查下推到数据库,利用原子更新。 | 高效解决超卖 ,无需在应用层先查后改,是最基础的数据库层面防超卖方案。 | 无状态记录 :仅返回影响行数,无法区分"库存不足"和"重复请求"。事务隔离要求 :在READ COMMITTED下,配合此方案是经典组合。 |
几乎所有需要 防超卖的数据库写操作的基础条件。 |
| 方案四:库存分段 | 将总库存拆到多行记录,分散锁竞争。 | 提升并发扣减上限,将一个热点拆分为多个热点。 | 逻辑复杂 :需解决某分段库存耗尽后的路由和负载均衡问题。数据碎片化:管理和查询总库存变得麻烦。 | 早期用于缓解单一数据库行锁压力,现代架构中多被更彻底的解耦方案替代。 |
| 方案五:Redis缓存 | 在内存中预扣库存,快速拦截请求。 | 扛住流量洪峰,将绝大部分请求挡在数据库之外,保护数据库。 | 数据一致性 :缓存与数据库的数据同步是最大挑战,处理不当会导致超卖或少卖。复杂度高:需设计完整的异步落库、恢复、对账流程。 | 现代高并发秒杀的标配起点,但必须配套后续的完整流程。 |
这个演进过程,本质上是从 "把所有逻辑压在数据库上 " 到 "在内存中处理并发,让数据库安心做它擅长的持久化" 的架构思想转变。
2.9 大厂方案的拼图🏢
大厂方案是以上所有方案的集大成者,并增加了更多保障层 分层过滤机制(漏斗式设计):
- 前置层层过滤(限流) :Nginx令牌桶 + 业务层限流
- CDN/静态化:活动页面静态化,推送到CDN。静态资源(图片、页面)缓存至边缘节点,拦截90%以上非核心请求。
- 答题/验证码(延缓请求):在秒杀开始前弹出,拉长用户操作时间,打散峰值。
- 请求排队:在网关层设置队列,按批次放行请求到后端服务。
- 服务与数据隔离:秒杀系统使用独立的域名、服务器集群、数据库实例,避免影响主站。
- 极致性能与兜底 :
- Redis集群采用
Proxy或Cluster模式,内存优化。Redis缓存商品库存、用户资格校验,减少数据库查询。 - 异步消费者服务无状态化,可水平扩展。
- 强力的最终一致性对账:定时扫描比对Redis预扣量、数据库库存量、订单成单量,自动修复差异(如将超时未支付的库存加回)。
- Redis集群采用
3. 流量削峰:让系统在高并发中优雅呼吸
3.1 什么是流量削峰?🌟
流量削峰 是分布式系统服务治理中的关键技术,简单来说就是:将瞬时的请求高峰转化为平稳的流量处理,避免系统被突如其来的流量洪峰"冲垮"。
举个生活化的例子:想象一下早高峰的地铁站。如果所有上班族都在同一时间涌入地铁站,会瞬间造成拥挤甚至踩踏。而流量削峰就像在地铁站设置"错峰进站"机制,让乘客分批进入,使整个系统平稳运行。
3.2 为什么需要流量削峰?📈
1. 现实场景的痛点
- 秒杀场景:300万人在凌晨0点抢购一件数量只有500件的商品。
- 春运抢票:数百万用户同时抢购火车票。
- 大促活动:双十一、618期间,系统瞬间从日常流量跃升到峰值的10-100倍。
💡 关键点 :秒杀活动的 核心目标 是让 "有效请求"(能买到商品的请求)尽可能多,但 无效请求(库存不足时的请求)越多,系统压力越大。
2. 为什么不能直接用"升级服务器"解决?
- 成本高昂:为峰值流量准备的服务器,平时90%时间处于闲置状态。
- 响应慢:硬件扩容需要时间,无法应对"瞬时峰值"(通常只有几秒到几十秒)。
- 资源浪费:峰值过后,大量服务器闲置。
3.3 流量削峰的本质🔧
削峰的本质:让流量"平滑"下来。
瞬时峰值流量(10万请求/秒) → 消息队列缓冲 → 平稳流量(1万请求/秒) → 数据库处理类比:就像水库调节洪水。洪水(瞬时流量)涌入水库(消息队列),水库缓慢放水(平稳流量)到下游河道(数据库)。
3.4 流量削峰的实现方案🛠️
1. MQ消息队列实现削峰(最常用方案)
原理 :把 同步的直接调用 转换成 异步的间接推送,中间通过 mq消息队列 缓冲瞬时流量。下面这张图清晰地展示了最典型的 "请求排队"模型 的工作流程:
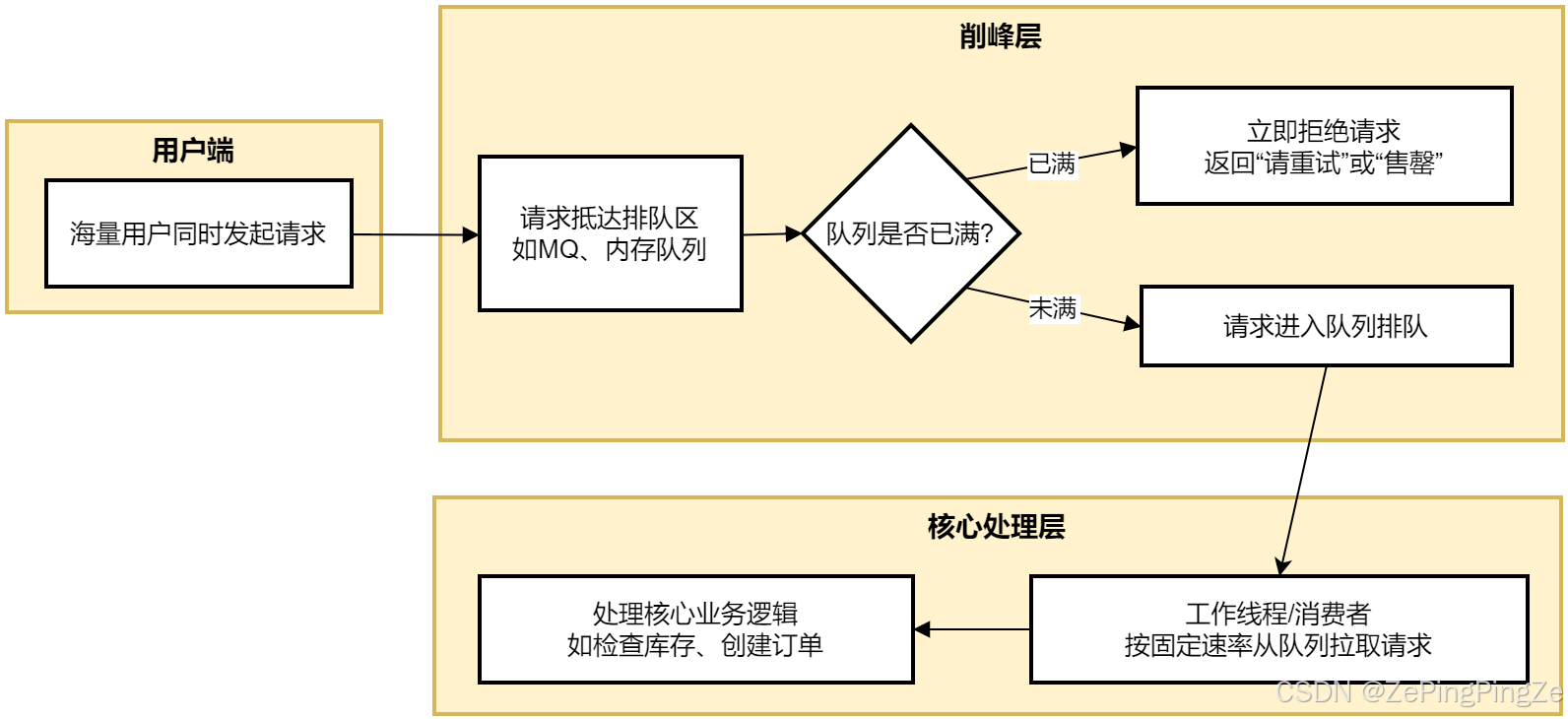
如流程图所示,这是最直接的削峰方式。
-
实现方式 :使用队列(内存队列如
Disruptor,或分布式消息队列如RocketMQ、Kafka)作为缓冲区。 -
工作原理:
- 所有请求先进入队列,而不是直接处理业务(如查库、扣减)。
- 后端的业务处理服务(消费者)以自己的恒定处理能力(例如每秒处理1000个请求)从队列中拉取请求进行处理。
- 队列满了之后,新来的请求直接被快速拒绝(返回 "活动太火爆,请稍后重试" )。
-
优点:将不规则的突发流量整形为规则流量,彻底保护下游业务系统。
-
代码示例(利用MQ):
java@Service public class SecKillRequestService { @Autowired private RocketMQTemplate rocketMQTemplate; // 1. 接收秒杀请求,直接入队 public boolean receiveRequest(Long userId, Long skuId) { SecKillMessage message = new SecKillMessage(userId, skuId, createOrderSn()); try { SendResult result = rocketMQTemplate.syncSend("SEC_KILL_TOPIC", message); return SendStatus.SEND_OK.equals(result.getSendStatus()); } catch (Exception e) { // 发送失败,可能是队列满或系统错误,快速告知用户失败 return false; } } } @Service @RocketMQMessageListener(topic = "SEC_KILL_TOPIC", consumerGroup = "secKill-group") public class SecKillConsumer implements RocketMQListener<SecKillMessage> { // 2. 消费者以固定速率处理消息 @Override public void onMessage(SecKillMessage message) { // 这里执行真正的、耗时的业务逻辑:检查库存、创建订单等 realSecKillService.processSecKill(message); } } -
大厂实践:
- 淘宝/京东:使用RocketMQ/Kafka处理秒杀请求。
- 阿里双11:每秒处理58.3万笔订单,其中90%的请求通过消息队列缓冲。
-
效果对比:
| 指标 | 无MQ(传统模式) | 有MQ(流量削峰) |
|---|---|---|
| 最大并发处理量 | 受数据库连接数限制(100) | 队列可缓冲无限量请求 |
| 响应时间 | 平均200ms(直接处理) | 立即返回(<10ms) |
| 系统稳定性 | 峰值时易崩溃 | 平稳处理,无崩溃风险 |
| 资源利用率 | 峰值时资源耗尽,平时闲置 | 按固定速率使用资源 |
2. 分层过滤机制(漏斗式设计)
原理:在不同层次过滤无效请求,让"漏斗"最末端才是有效请求。
三层过滤:
- 第一层(CDN):静态资源(图片、页面)缓存至边缘节点,拦截90%以上非核心请求。
- 第二层(缓存层):Redis缓存商品库存、用户资格校验,减少数据库查询。
- 第三层(服务层):限流算法(令牌桶、漏桶)控制请求速率。
大厂实践:
- 淘宝:商品详情页的图片通过CDN分发,减少源站压力。
- 京东:将库存预加载至Redis集群,单节点QPS可达10万+。
3. 验证机制(延缓请求)
原理:增加请求的复杂度,延缓请求,同时过滤恶意请求。
常见方式:
- 图形验证码/滑动验证码。
- 答题验证(如"1+1=?")。
- 短信验证码。
大厂实践:
- 早期秒杀只有"点击秒杀按钮",后来增加了答题验证。
- 作用:将下单时间从<1秒延长到<10秒,大大减轻服务器压力。
4. 限流机制(有损方案)
原理:控制请求速率,防止瞬间爆发的流量把系统击垮。
常见算法:
- 令牌桶算法:系统以固定速率生成令牌,请求需要获取令牌。
- 漏桶算法:请求像水一样流入桶中,桶以固定速率流出。
- 滑动窗口:统计最近一段时间内的请求量。
大厂实践:
- 京东:对用户ID/IP实施动态限流策略,将瞬时请求从100万/秒平滑至5万/秒。
- 阿里:在服务层设置限流,保证核心业务不受影响。
3.5 流量削峰的分类💡
| 方案 | 类型 | 是否损失请求 | 适用场景 |
|---|---|---|---|
| 消息队列 | 无损 | ❌ 不损失 | 核心业务(订单、库存) |
| 分层过滤 | 无损 | ❌ 不损失 | 通用高并发场景 |
| 验证机制 | 无损 | ❌ 不损失 | 防止恶意刷单 |
| 限流 | 有损 | ✅ 损失部分请求 | 保护系统稳定性 |
✅ 关键点 :在秒杀场景中,流量削峰 的核心不是 "减少请求",而是 "让有效请求能被处理"。无效请求(库存不足时的请求)被过滤掉,有效请求(能买到商品的请求)被平稳处理。
3.6 大厂实战:阿里双11的流量削峰🌐
阿里双11的秒杀架构是流量削峰的典范:
- CDN层:商品图片、页面静态资源通过CDN分发,减少源站压力。
- Redis缓存层 :
库存预加载至Redis集群,单节点QPS可达10万+。 - 消息队列层:RocketMQ缓冲瞬时请求,将100万请求/秒平滑至1万请求/秒。
- 数据库层:库存分片+UPDATE条件,确保数据一致性。
3.7 流量削峰的终极意义🌟
流量削峰不是 "技术炫技",而是 让系统在高并发中优雅呼吸 的必要手段:
- 保障用户体验:避免"页面转圈"、"按钮无反应"的糟糕体验。
- 保证数据一致性:避免因流量冲击导致的数据错乱。
- 节约成本:避免为峰值流量准备的闲置资源。
- 提升系统稳定性:从"被流量压垮"到"从容应对"。