TL;DR
- 场景:离线同步 MySQL/HDFS/Hive/OTS/ODPS 等异构数据源,批量迁移与数仓 ETL。
- 结论:DataX 用 Framework + Reader/Writer 插件把"网状对接"降维成"星型链路",关键靠 Job 切分 + TaskGroup 并发 + speed/errorLimit 控制。
- 产出:可直接落地的安装运行口径、版本依赖矩阵、以及常见报错的定位与修复卡片。

版本矩阵
| 项目 | 说明 |
|---|---|
| 已验证说明 | DataX 核心定位:离线数据同步框架,Reader/Writer 插件抽象异构数据源同步 |
| 运行环境口径 | Linux + JDK 1.8 或以上(推荐 1.8)+ Python 2 或 3 |
| 官方下载与运行入口口径 | 解压后进入 bin,通过 python datax.py job.json 运行 |
| 作业核心配置口径 | job.setting.speed + job.setting.errorLimit 作为常用控制面 |

基本概述
DataX是阿里巴巴集团自主研发并在内部广泛使用的一款高性能离线数据同步工具/平台。作为阿里大数据生态体系中的重要组件,它专门用于解决企业级数据集成过程中的异构数据源同步难题。
在数据源支持方面,DataX具备强大的兼容性,目前已实现对多种主流数据库和大数据存储系统的支持,包括:
- 关系型数据库:MySQL、Oracle、SQL Server、PostgreSQL等
- 大数据生态组件:HDFS、Hive、HBase等
- 阿里云服务:AnalyticDB(ADS)、TableStore(OTS)、MaxCompute(ODPS)
- 分布式数据库:DRDS(阿里云分布式关系型数据库服务)
在实际应用中,DataX通过创新的架构设计解决了传统数据同步方案面临的复杂性问题。传统的网状同步架构中,每个数据源之间都需要建立直接连接,当存在N个数据源时,理论上需要建立N*(N-1)个连接通道,这不仅增加了系统复杂度,也带来了巨大的维护成本。
DataX采用星型拓扑结构重构了数据同步链路:
- 核心层:DataX作为中央调度和传输引擎
- 接入层:各数据源通过插件化方式接入DataX核心
- 传输层:统一的数据格式转换和传输通道
这种架构的优势体现在:
- 扩展性:新增数据源只需开发对应插件,无需修改核心架构
- 维护性:所有同步任务通过统一平台管理
- 可靠性:内置故障检测和重试机制
- 性能优化:支持并发控制和流量控制
典型应用场景包括:
- 数据仓库ETL过程:将业务系统数据定期同步到数据仓库
- 跨云数据迁移:在不同云服务商之间转移数据
- 数据备份:实现重要数据的异地备份
- 数据分析:为机器学习等场景准备训练数据
通过这种设计,DataX成功将复杂的数据同步网络简化为标准化的星型结构,显著降低了企业数据集成门槛,提高了数据流转效率。

DataX作为阿里巴巴开源的高性能离线数据同步工具,其核心架构采用Framework+plugin模式设计,这种模块化架构使得系统具有高度的灵活性和可扩展性。该框架将数据同步过程中的关键功能抽象为三大核心组件:
-
Reader数据采集模块:
- 负责从各类数据源采集数据,支持多种数据格式和协议
- 内置丰富的数据源插件,包括:
- 关系型数据库:MySQL、Oracle、SQL Server等
- NoSQL数据库:MongoDB、HBase等
- 文件系统:FTP、HDFS等
- 通过分片策略实现并行数据抽取,提高采集效率
- 示例场景:从MySQL数据库中读取千万级订单数据
-
Writer数据写入模块:
- 负责将处理后的数据写入目标存储系统
- 支持多种写入模式:
- 全量覆盖
- 增量追加
- 条件更新
- 提供数据校验和错误重试机制
- 典型应用:将清洗后的数据写入Hive数据仓库
-
Framework核心框架:
- 作为数据传输中枢,实现Reader和Writer的高效对接
- 关键技术特性:
- 内存缓冲管理:平衡内存使用和传输效率
- 流量控制:防止目标系统过载
- 并发调度:优化资源利用率
- 数据转换:支持字段映射和格式转换
- 脏数据处理:异常数据记录和告警
经过多年发展和社区贡献,DataX已经构建了完善的插件生态体系:
- 支持30+种数据源插件
- 覆盖主流数据库系统(MySQL/Oracle/PostgreSQL等)
- 兼容大数据生态系统(HDFS/Hive/HBase等)
- 支持文件系统(FTP/SFTP等)
- 持续集成新兴数据存储系统(如ClickHouse、Doris等)
这种插件化架构使得DataX能够快速适配各类数据同步场景,同时保持核心框架的稳定性。用户可以根据实际需求灵活组合不同的Reader和Writer插件,构建定制化的数据同步解决方案。
DataX3.0开源版本目前支持单机多线程模式完成同步作业运行: 
核心模块
-
Job(作业)管理:DataX完成单个数据同步的作业称为Job。当DataX接收到一个Job请求时,会启动一个独立的进程来执行整个数据同步流程。Job模块作为作业的中枢管理节点,主要负责以下核心功能:
- 数据清理(包括预处理和后处理)
- 子任务切分(将单一作业分解为多个并行Task)
- 任务调度和状态监控
- 例如:一个从MySQL同步到HDFS的Job,会首先检查源表和目标路径的可用性
-
Task切分机制:Job启动后,会根据源端数据特性采用不同的切分策略:
- 对于RDBMS数据源,通常按照主键范围或分片键切分
- 对于HDFS等文件系统,可按文件块切分
- 每个Task负责处理一部分数据,如一个MySQL表可能被切分为10个Task,每个Task处理100万条记录
-
任务调度(Scheduler):切分后的Task会通过Scheduler模块进行重组:
- 默认每个TaskGroup包含5个并发Task
- TaskGroup数量 = ceil(总Task数/并发数)
- 例如:20个Task会被分配到4个TaskGroup(5x4=20)
-
Task执行流程:每个Task启动后遵循标准处理流程:
- Reader线程:从数据源读取数据
- Channel线程:负责数据传输和缓冲
- Writer线程:将数据写入目标端
- 三线程通过内存队列实现高效流水线作业
-
作业状态管理:Job运行期间会持续监控所有TaskGroup:
- 成功条件:所有TaskGroup均完成且无错误
- 失败处理:任一TaskGroup失败即整体失败
- 状态反馈:通过进程退出码标识(0成功,非0失败)
- 例如:5个TaskGroup中有1个失败,整个Job会立即终止并返回错误码1
核心优势
- 可靠的数据质量监控
- 丰富的数据转换功能
- 精准的速度控制
- 强劲的同步性能
- 健壮的容错机制
- 极简的使用体验
官方网站:
shell
https://github.com/alibaba/DataX/blob/master/introduction.md下载项目
shell
cd /opt/software
wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz执行结果如下图所示:  解压配置到server的目录下:
解压配置到server的目录下: 
环境变量
shell
vim /etc/profile
# datax
export DATAX_HOME=/opt/servers/datax
export PATH=$PATH:$DATAX_HOME/bin写入内容如下所示: 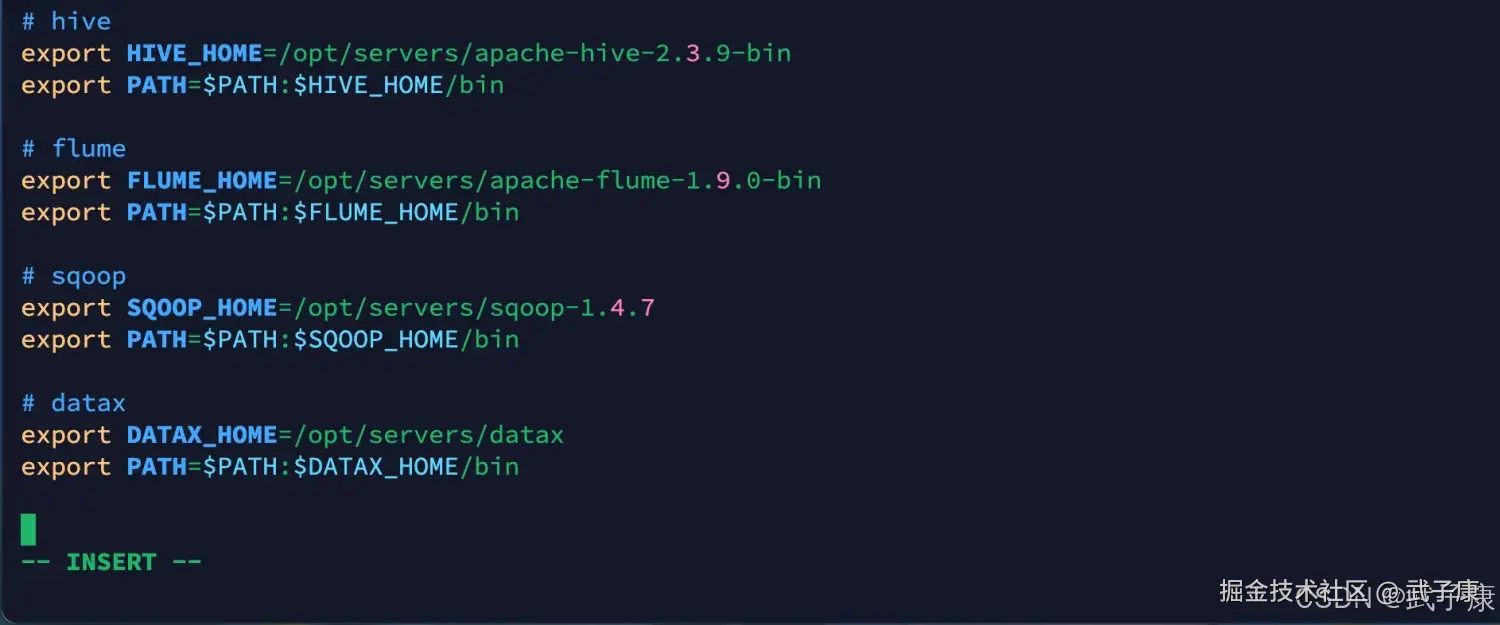
Reader、Writer
Data3.0提供Reader插件和Writer插件,每种插件都有一种和多种切分策略:
json
"reader": {
"name": "mysqlreader", #从mysql数据库获取数据(也支持
sqlserverreader,oraclereader)
"name": "txtfilereader", #从本地获取数据
"name": "hdfsreader", #从hdfs文件、hive表获取数据
"name": "streamreader", #从stream流获取数据(常用于测试)
"name": "httpreader", #从http URL获取数据
}
"writer": {
"name":"hdfswriter", #向hdfs,hive表写入数据
"name":"mysqlwriter ", #向mysql写入数据(也支持
sqlserverwriter,oraclewriter)
"name":"streamwriter ", #向stream流写入数据。(常用于测试)
}各种Reader插件、Writter插件的参考文档:
shell
https://github.com/alibaba/DataX
JSON模板
- 整个配置文件就是一个Job描述
- Job下面有两个配置项,content和setting,其中content用来描述该任务的源和目的端的信息,setting用来描述任务本身的信息
- content又分为两部分,reader和writer,分别用来描述源端和目的端的信息
- setting中的speed项表示同时起几个并发执行该任务
Job基本配置
json
{
"job": {
"content": [{
"reader": {
"name": "",
"parameter": {}
},
"writer": {
"name": "",
"parameter": {}
}
}],
"setting": {
"speed": {},
"errorLimit": {}
}
}
}Job Setting配置
json
{
"job": {
"content": [{
"reader": {
"name": "",
"parameter": {}
},
"writer": {
"name": "",
"parameter": {}
}
}],
"setting": {
"speed": {
"channel": 1,
"byte": 104857600
},
"errorLimit": {
"record": 10,
"percentage": 0.05
}
}
}
}- job.setting.speed 流量控制:Job支持用户对速度的自定义控制,channel的值可以控制同步时的并发数,byte的值可以控制同步时的速度
- job.setting.errorLimit 脏数据控制:job支持用户对于脏数据的自定义监管和告警,包括对脏数据最大记录阈值(record)值或者脏数据占比阈值(percentage),当Job传输过程中出现脏数据大于用户指定的数量、百分比,DataJob报错退出。
应用案例
Stream => Stream
json
{
"job": {
"content": [{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [{
"type": "String",
"value": "hello DataX"
},
{
"type": "string",
"value": "DataX Stream To Stream"
},
{
"type": "string",
"value": "数据迁移工具"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "GBK",
"print": true
}
}
}],
"setting": {
"speed": {
"channel": 2
}
}
}
}执行脚本:
shell
python $DATAX_HOME/bin/datax.py
/data/lagoudw/json/stream2stream.json错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
python: command not found / 运行报 Python 版本异常 |
机器未装 Python,或默认 python 指向不兼容版本 |
which python / python -V / python3 -V 安装 Python(2 或 3),并确保启动命令使用实际存在的解释器(python3 datax.py ... 或配置软链) |
java: command not found / 启动即失败 |
未安装 JDK 或 PATH 未生效 | java -version / echo $JAVA_HOME 安装 JDK 1.8+,配置环境变量并重新加载 profile |
Permission denied(执行脚本/写目标路径失败) |
DataX 目录或目标目录无权限 | ls -l / 查看目标路径属主与权限 调整目录权限/属主;目标路径提前创建;避免用无权限用户写入 |
| 任务跑着跑着整体失败(非 0 退出码) | 任一 TaskGroup 失败导致 Job 失败 | 先看 log/控制台失败栈;定位失败的 reader/writer 先缩小并发(channel),再定位插件参数/连通性;必要时开更细日志 |
| 报错后立刻退出,提示脏数据超限 | job.setting.errorLimit 触发(record/percentage 超阈值) |
看错误输出是否出现 record/percentage 相关信息 调整 errorLimit 阈值;或修正源数据字段/类型映射;把脏数据落库/落文件再回溯 |
| 速度远低于预期 / 目标端压力大 | speed 未配置或不合理(channel/byte),或目标端写入瓶颈 |
对比源端读速、Channel 速率、目标端写入 TPS 先调 channel 控并发,再用 byte 做限速;以目标端可承受为上限逐步压测 |
Connection refused / 超时(MySQL 等) |
网络不通、端口/账号权限、白名单/防火墙 | telnet host port / nc -vz / 数据库登录测试 修通网络与鉴权;确认库表权限与时区/字符集等连接参数 |
| 字符集乱码(控制台/落地文件) | writer/reader encoding 配置与实际不一致 | 对比源库字符集、任务 JSON encoding、落地结果 统一编码;文件类 writer 明确设置 encoding;避免混用 GBK/UTF-8 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-207 RabbitMQ Direct 交换器路由:RoutingKey 精确匹配、队列多绑定与日志分流实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解