一.什么是requests?
之前我们使用from urllib.request import urlopen这个包进行爬虫。
requests也是Python的一个爬虫时可以选择使用的包,而且功能更强大。
二.下载Requests
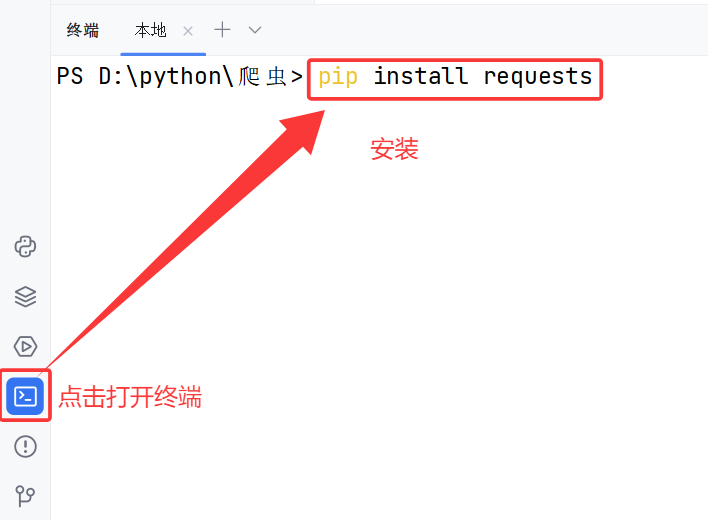
三.使用Requests写一个爬虫小程序
爬豆瓣的电影页面的html
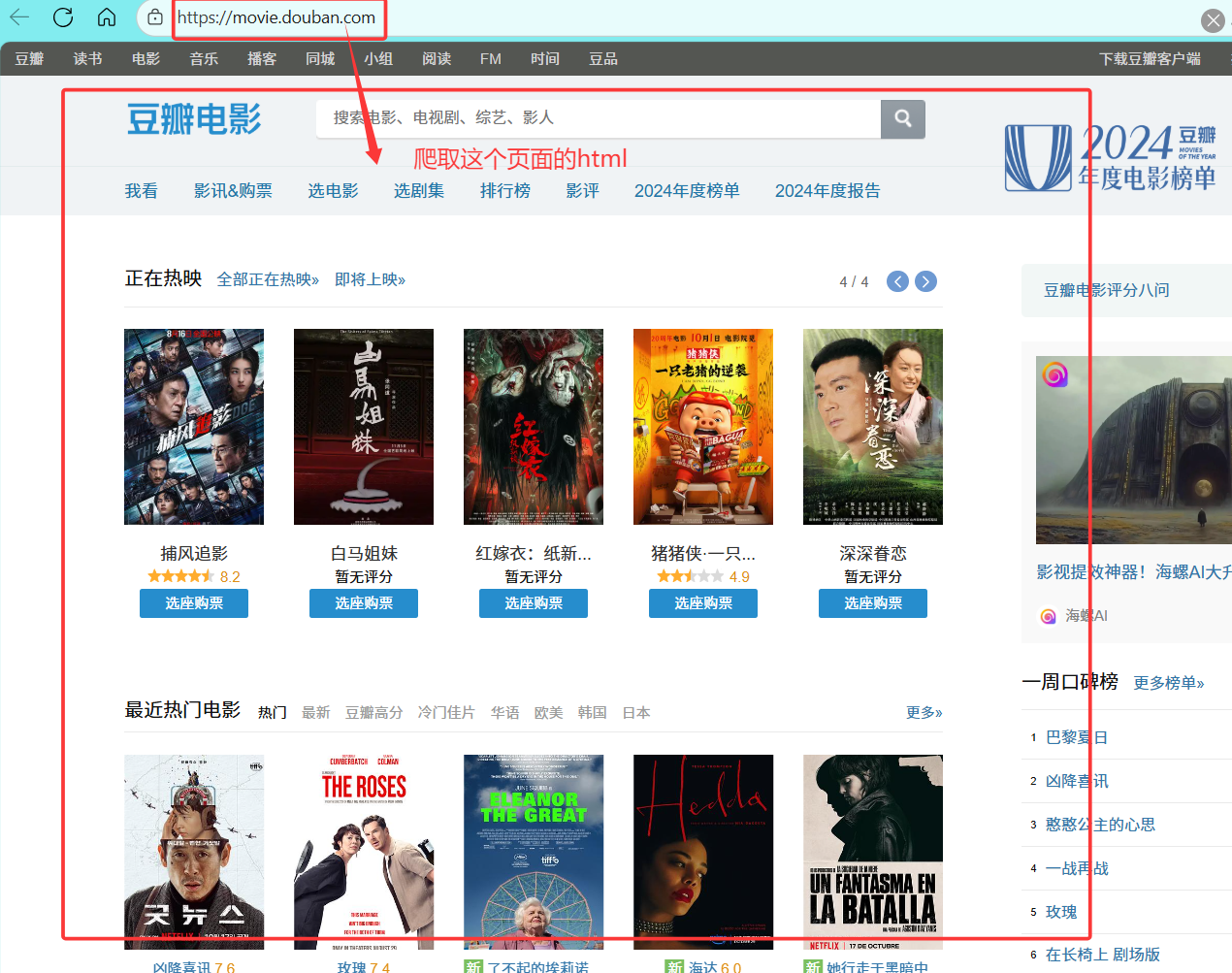
1.初步代码
python
import requests
#要爬的url
url = "https://movie.douban.com/"
#使用requests爬上面的url,并获取响应数据
resp = requests.get(url)
#打印响应数据
print(resp)
print(resp.text)运行结果:
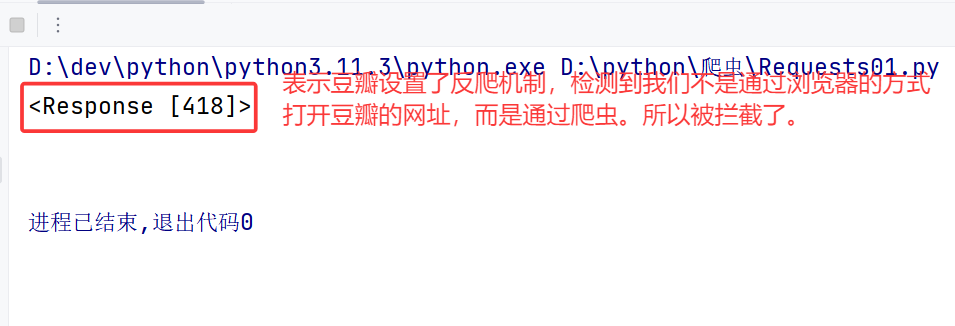
2.设置请求头的User-Agent(请求者),解决反爬
第一步:获取豆瓣网的任意请求的请求头携带的User-Agent,并复制到粘贴板
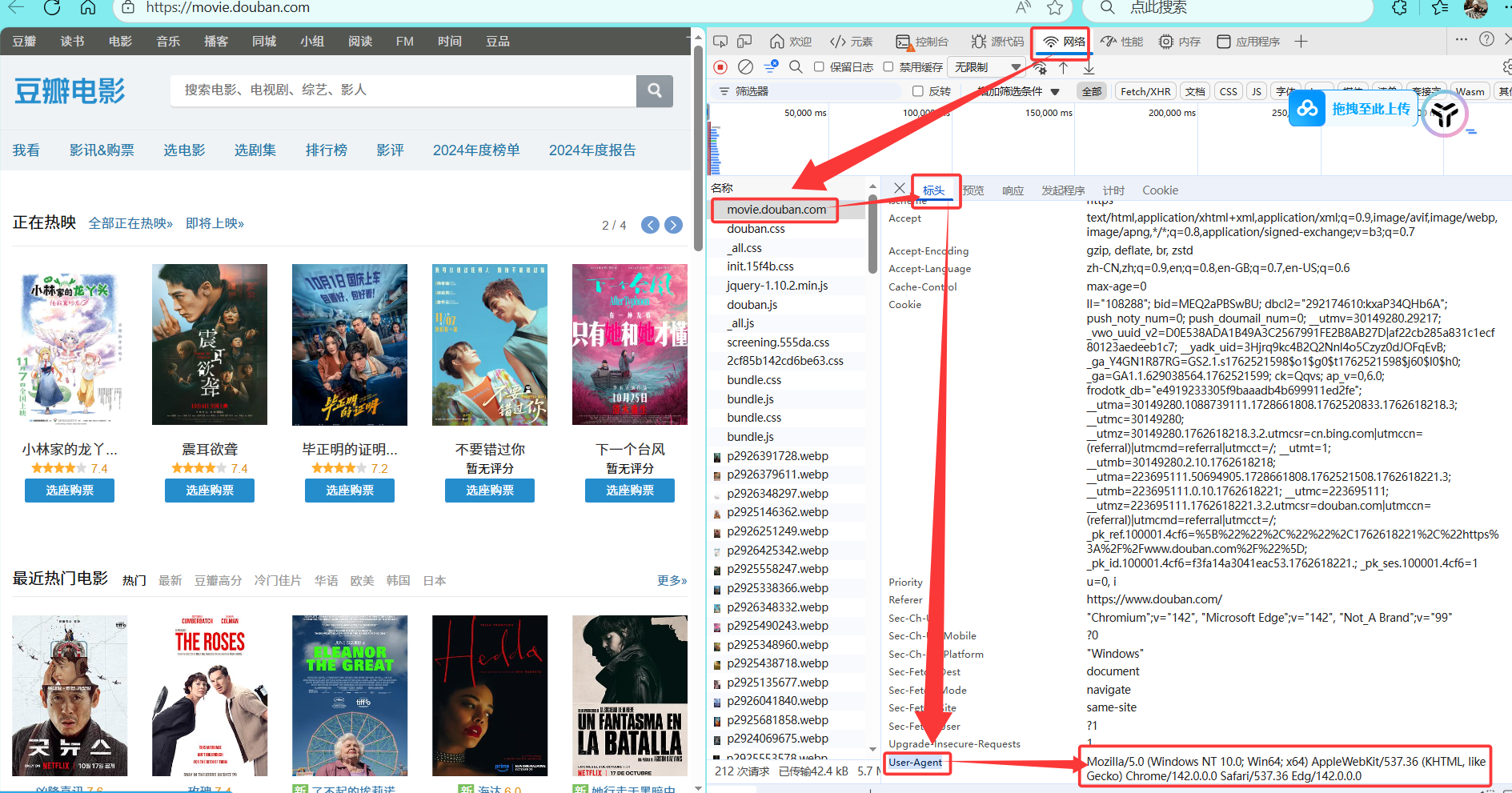
第二步:修改爬虫代码
主要是将豆瓣的User-Agent的值,设置到代码的请求头即可。
python
import requests
#要爬的url
url = "https://movie.douban.com/"
#解决豆瓣的反爬机制:设置请求头的请求者
myHeaders = {
#从豆瓣获取即可:检查->网络->点击请求->标头->User-Agent
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0"
}
#使用requests爬上面的url,并获取响应数据
resp = requests.get(url,headers=myHeaders)
#打印响应数据
print(resp)
print(resp.text)查看运行效果:

四.一些细节的问题
1.上述爬虫代码,用的为什么是get请求,而不是post?
因为我们要爬的页面,它侧重于获取后端的电影数据,因此判断为get(可能会判断失误,到时候多试试别的请求也是没问题的)
2.requests的结果(resp)中,都包含哪些内容?我们为什么要打印resp.text?
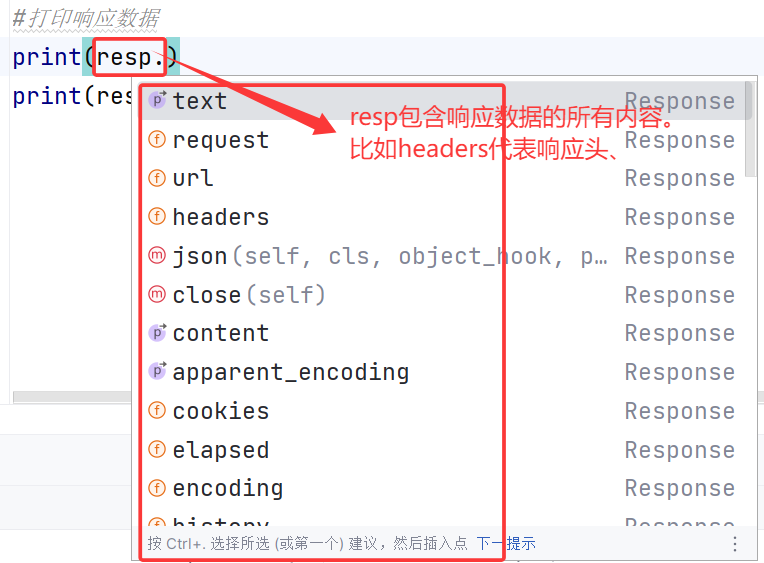
而resp中的text,就代表所爬页面的html代码。
以上就是本篇文章的全部内容,喜欢的话可以留个免费的关注呦~~~