不想依赖于第三方远程api的方式。
比如之前写过的调用重排模型的方式,如果后端使用该模型,需要经过python 提供接口才能调用大模型,这样服务器就需要维护2套项目。为了解决这个问题,采用下面的方式。
(简单提一下:虽然目前不管是 重排、向量、模型都可以转onnx格式,但是目前我后端使用的是LangChain4j,它仅提供了向量模型使用onnx格式的方法)
好了,开始将向量模型转换成onnx吧~~~
一:使用pyCharm工具安装依赖
这里建议使用python3.8版本,尝试了高版本执行此命令不支持!!!
python
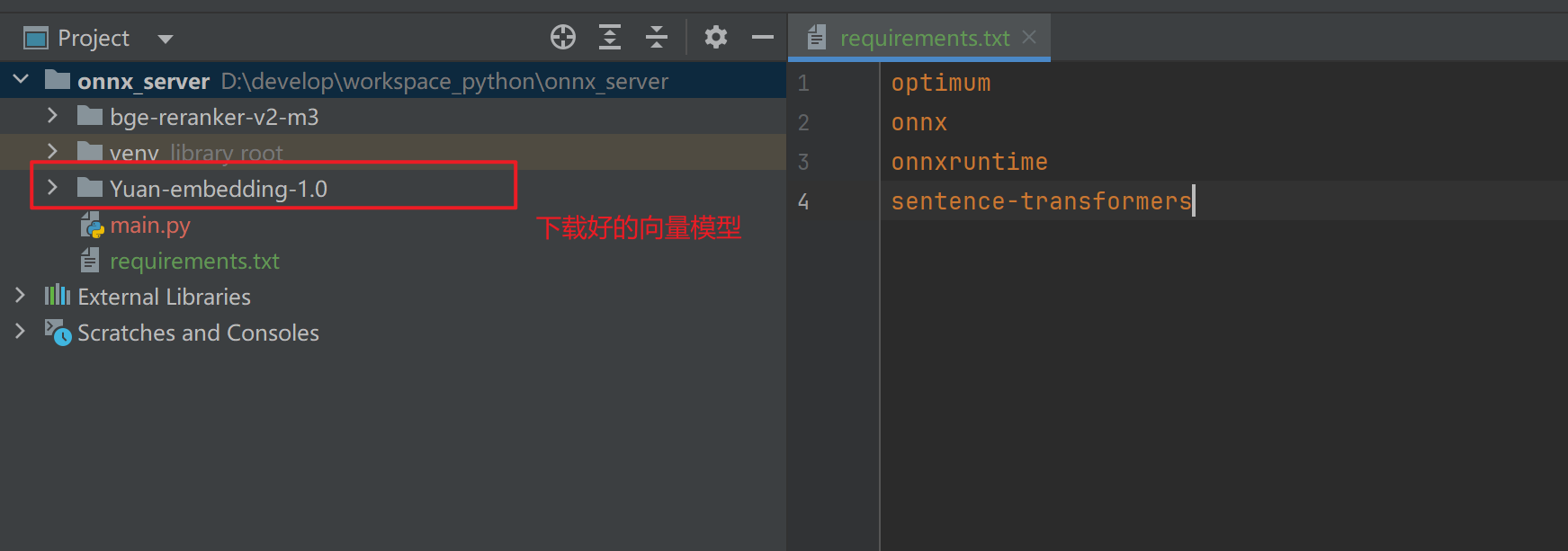
pip install optimum onnx onnxruntime sentence-transformers
二: 下载模型到本地,可以放到当前项目目录。
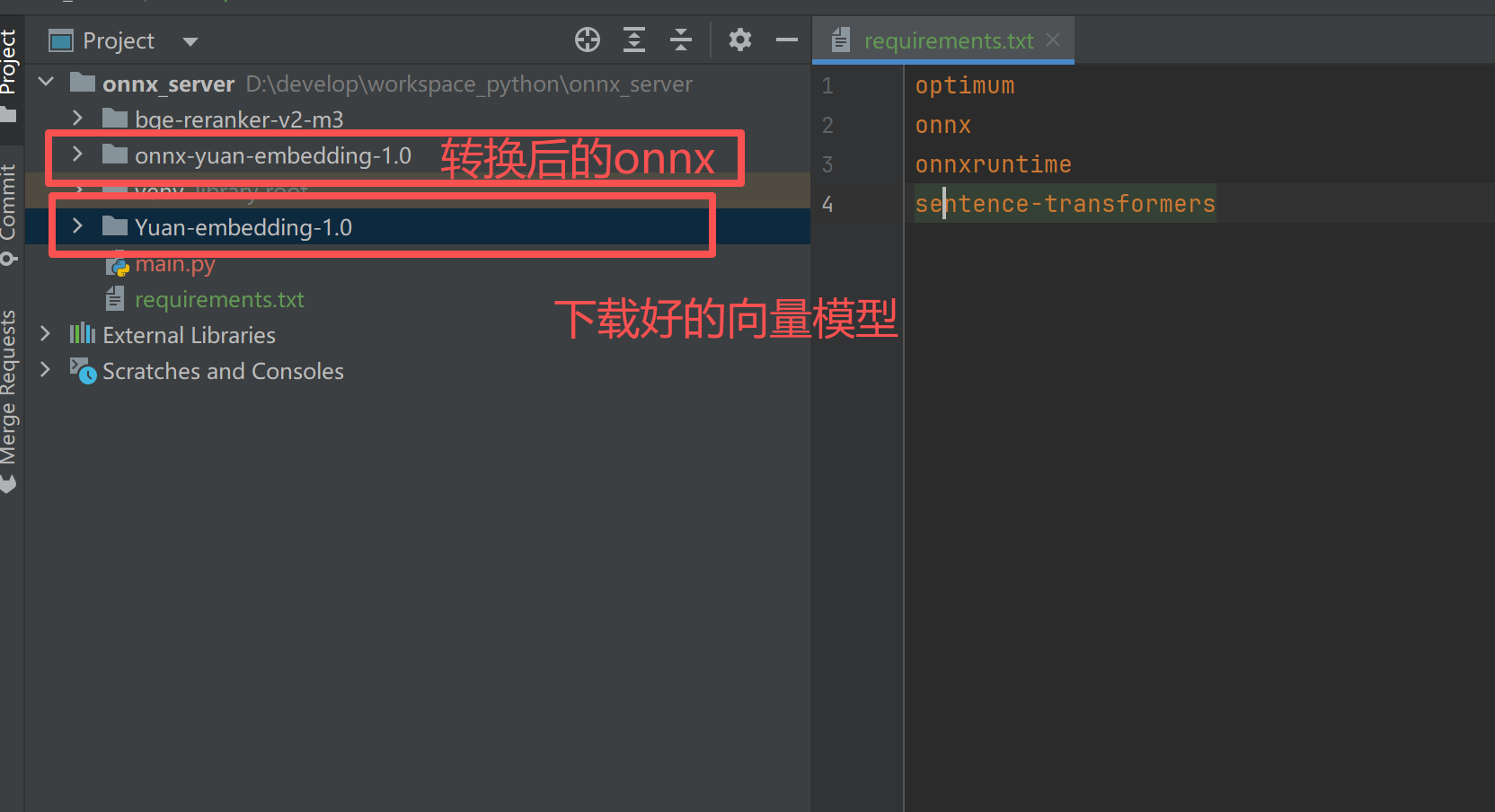
三:模型下载后,转换为onnx格式
--model (指定的model) (解压后的onnx存放目录名)
python
optimum-cli export onnx --task sentence-similarity --model Yuan-embedding-1.0 onnx-yuan-embedding-1.0
四、LangChain4j本地运行Onnx模型
1、使用转换后的ONNX模型进行文本嵌入
java
/**
* 测试本地ONNX嵌入模型 (验证本地ONNX格式嵌入模型数据的功能)
*/
@Test
public void testLocalEmbeddingInsert(){
// 从文件系统加载文档
Document document = FileSystemDocumentLoader.loadDocument("E:\\hotelquestion.txt");
String saveDir = "D:/develop/workspace_python/onnx_server/onnx-yuan-embedding-1.0";
// 构建嵌入模型
OnnxEmbeddingModel onnxEmbeddingModel = new OnnxEmbeddingModel(saveDir + "/model.onnx", saveDir + "/tokenizer.json", PoolingMode.MEAN);
System.out.println("Embedding dimension: " + onnxEmbeddingModel.dimension());
// 创建文档分段器,将文档分割成最大长度为300,重叠部分为10的段落
DocumentSplitter documentSplitter = DocumentSplitters.recursive(300, 10);
// 执行分段
List<TextSegment> textSegments = documentSplitter.split(document);
textSegments.forEach(segment -> {
Metadata metadata = segment.metadata();
metadata.put(Constants.KB_ID, 1l);
});
System.out.println("文档分段数量: " + textSegments.size());
// 创建内存中的嵌入存储(可替换为milvus等持久化存储)
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
embeddingStore = MilvusEmbeddingStore.builder()
.host("192.168.1.19")
.port(19530)
.databaseName("default")//默认数据库
.collectionName("vector_store_test")//表
.dimension(onnxEmbeddingModel.dimension())
.idFieldName("embeddingId")// 指定存储唯一标识符的字段名
.textFieldName("text")// 指定存储原始文本的字段名
.vectorFieldName("embedding") // 指定存储向量数据的字段名
.metadataFieldName("metadata")// 指定存储元数据的字段名
.build();
// 逐个处理文本段落,生成嵌入并存储
for (int i = 0; i < textSegments.size(); i++) {
TextSegment textSegment = textSegments.get(i);
// 为单个文本段落生成嵌入向量
Response<Embedding> embeddingResponse = onnxEmbeddingModel.embed(textSegment);
Embedding embedding = embeddingResponse.content();
// 将嵌入向量和文本段落添加到向量数据库中
embeddingStore.add(embedding, textSegment);
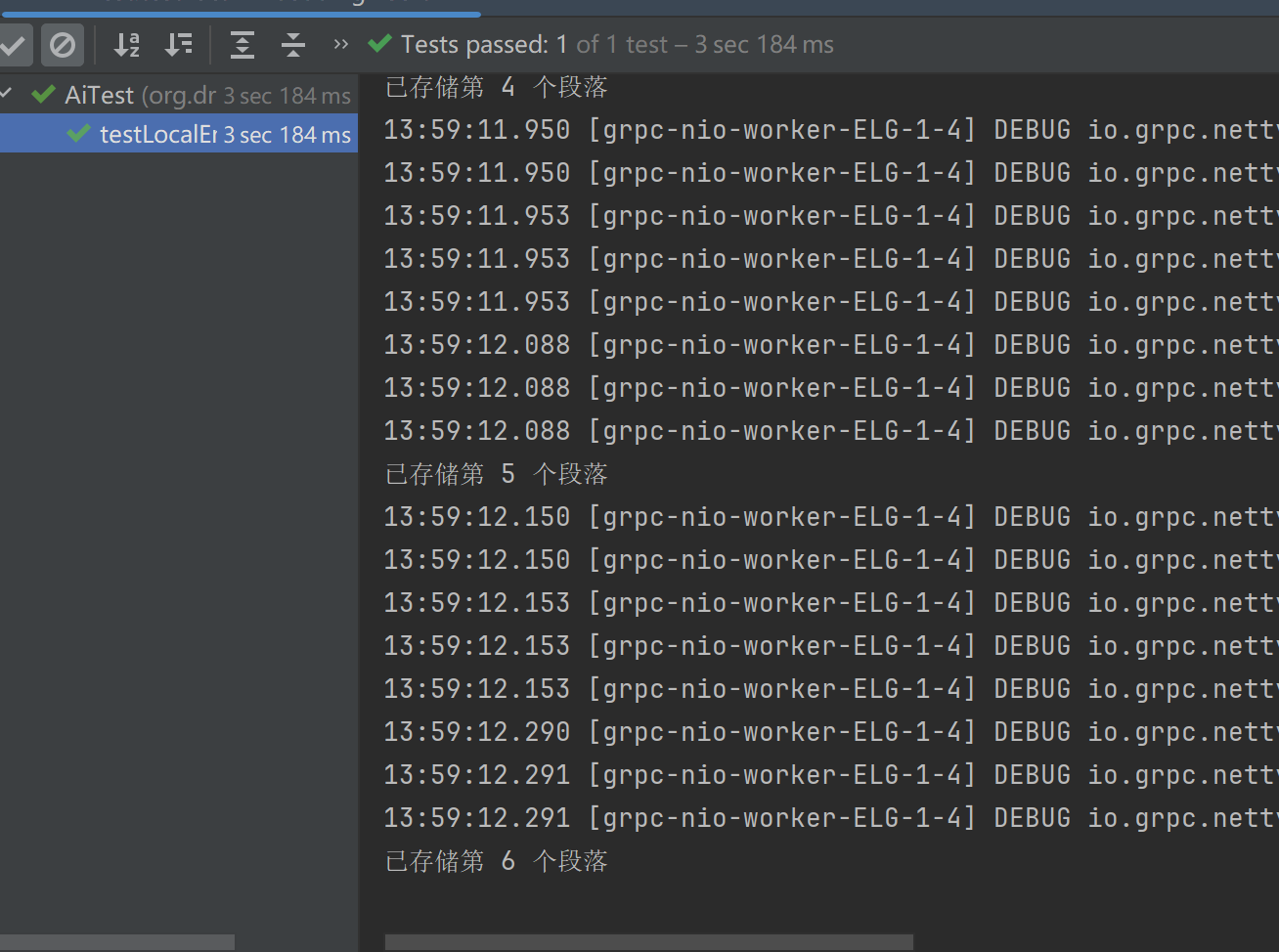
System.out.println("已存储第 " + (i + 1) + " 个段落");
}
}效果
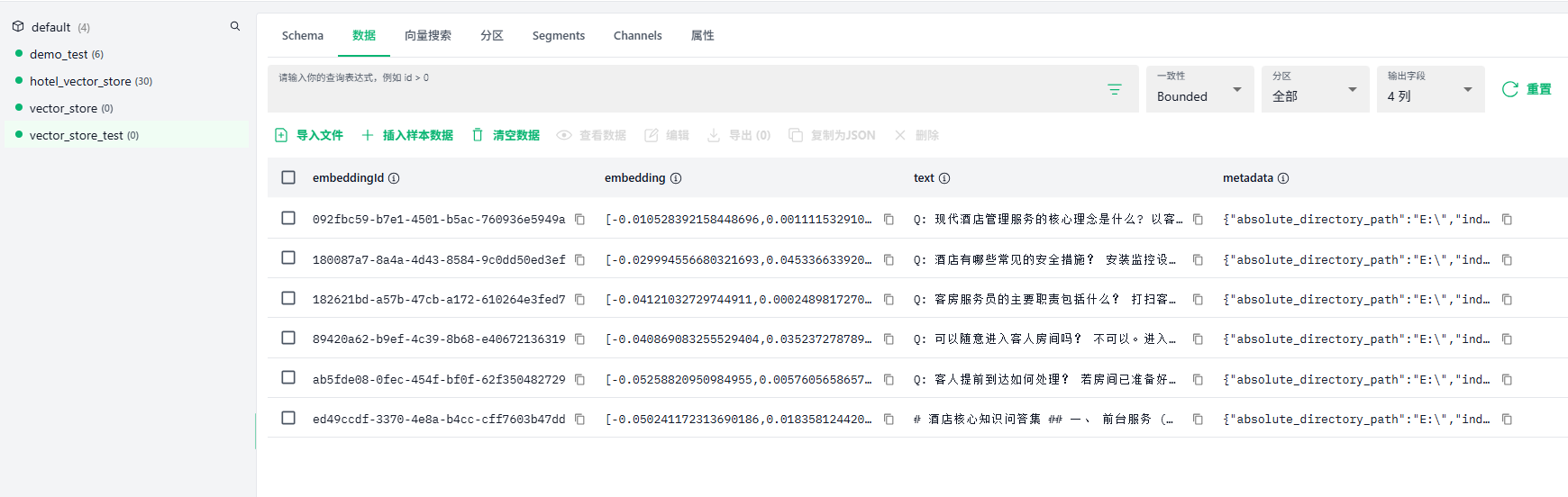
2、使用转换后的ONNX模型进行向量搜索
java
/**
* 测试本地ONNX嵌入模型 (验证本地ONNX格式嵌入模型的功能)
*/
@Test
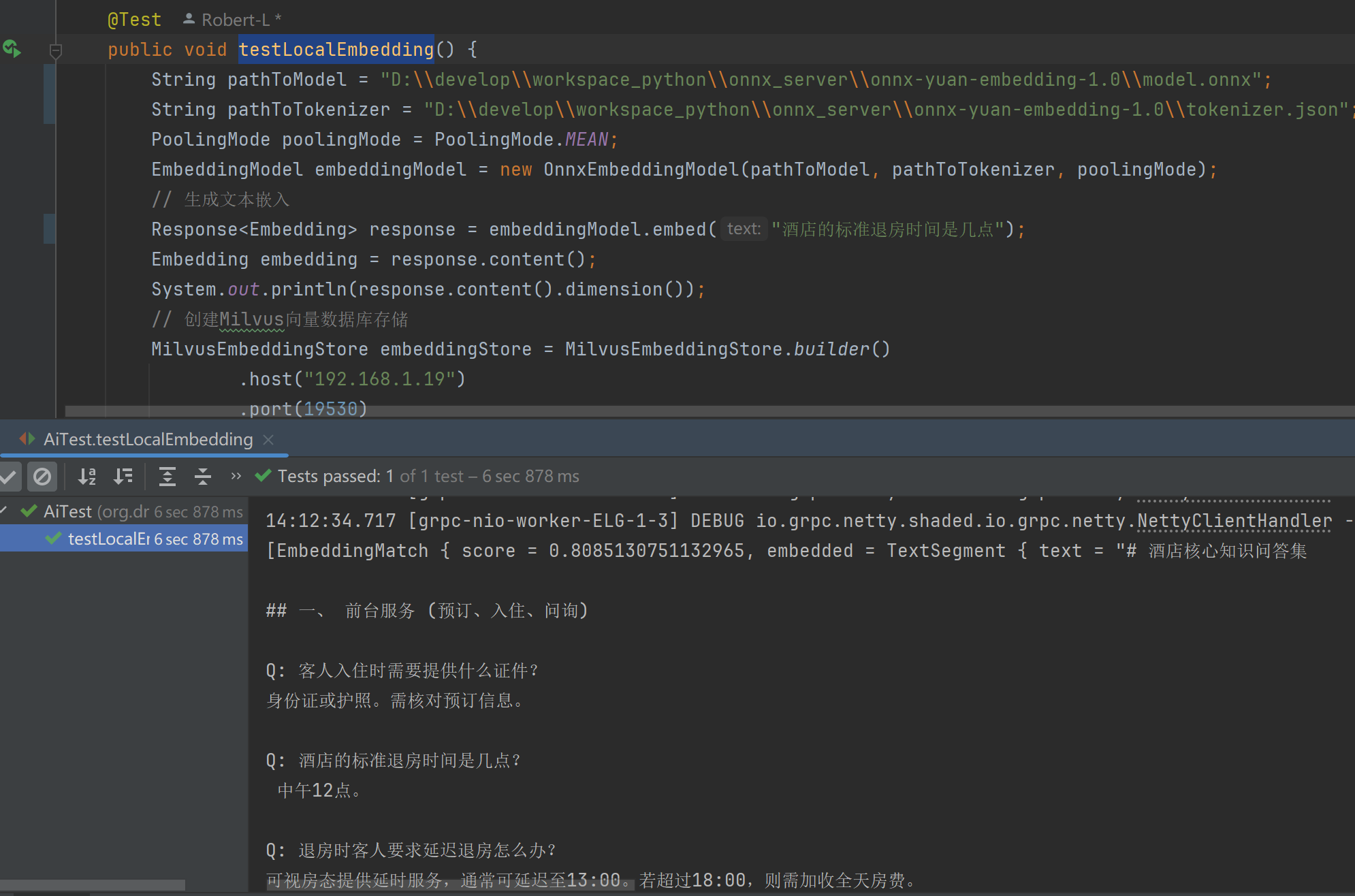
public void testLocalEmbedding() {
String pathToModel = "D:\\develop\\workspace_python\\onnx_server\\onnx-yuan-embedding-1.0\\model.onnx";
String pathToTokenizer = "D:\\develop\\workspace_python\\onnx_server\\onnx-yuan-embedding-1.0\\tokenizer.json";
PoolingMode poolingMode = PoolingMode.MEAN;
EmbeddingModel embeddingModel = new OnnxEmbeddingModel(pathToModel, pathToTokenizer, poolingMode);
// 生成文本嵌入
Response<Embedding> response = embeddingModel.embed("酒店的标准退房时间是几点");
Embedding embedding = response.content();
System.out.println(response.content().dimension());
// 创建Milvus向量数据库存储
MilvusEmbeddingStore embeddingStore = MilvusEmbeddingStore.builder()
.host("192.168.1.100")
.port(19530)
.databaseName("default")//默认数据库
.collectionName("vector_store_test")//表
.idFieldName("embeddingId")// 指定存储唯一标识符的字段名
.textFieldName("text")// 指定存储原始文本的字段名
.vectorFieldName("embedding") // 指定存储向量数据的字段名
.metadataFieldName("metadata")// 指定存储元数据的字段名
.build();
// 构建搜索请求
EmbeddingSearchRequest request = EmbeddingSearchRequest.builder().queryEmbedding(embedding).filter(new IsEqualTo("kb_id", 1l)).build();
// 执行搜索
EmbeddingSearchResult<TextSegment> result = embeddingStore.search(request);
System.out.println(result.matches());
}