引言
大家好!大家都知道seata是分布式事务的解决方案之一,它不仅使您轻松快捷地通过注解就可以实现分布式事务,而且还有AT,XA,TCC,Saga四种模式可以选择,可以为您的项目提供最适合的方案。随着seata不断发展,它也在不断地覆盖更多的业务场景。在未发布的2.6.0版本中,seata就可以支持Oracle的批量插入语法了!接下来让我们解析一下它到底是怎么做到的吧❤️
问题起源
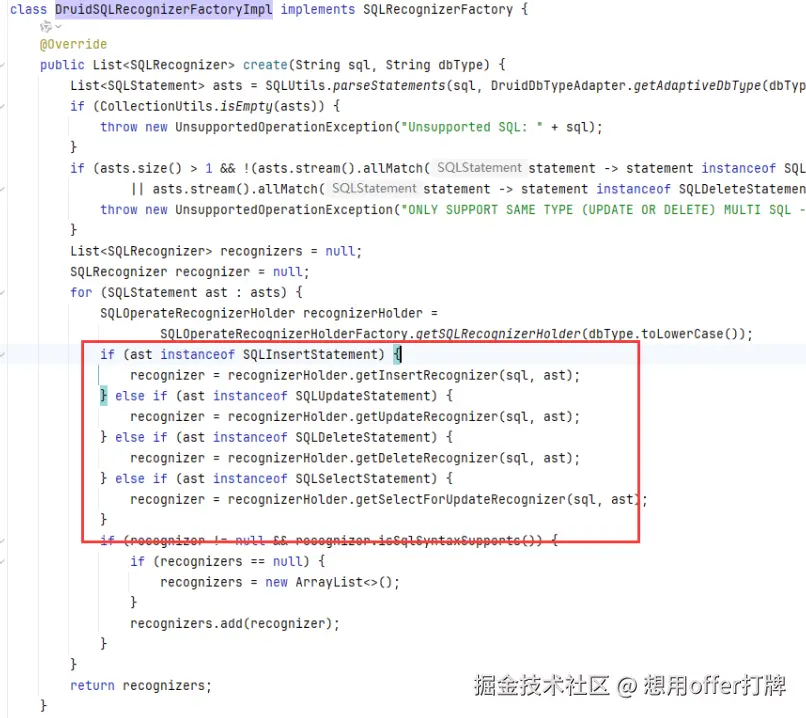
现在有一个SQL语句:insert all into a (id) values(1) into a (id) values(2) SELECT 1 FROM DUAL 进入seata就会被解析成OracleMultiInsertStatement这个对象,但是在原来seata的代码中,DruidSQLRecognizerFactoryImpl这个工厂实现类,并不支持解析获取到OracleMultiInsertStatement这个对象(只支持最通用的增删改查)
解决步骤
问题分析
要支持这个语法,我们就必须先明白,Oracle Insert Batch语法到底是什么样的?以及我们seata到底要支持这个语法到哪一步?没有全支持的原因到底是什么?这三个问题我们会在下面一一解答。
什么是 Oracle Multi-Insert?
Oracle 支持一种特殊的 INSERT 语法,可以在一条语句中向多个表插入数据,根据条件决定插入到哪个(或哪些)表。例如下面这个SQL语句:
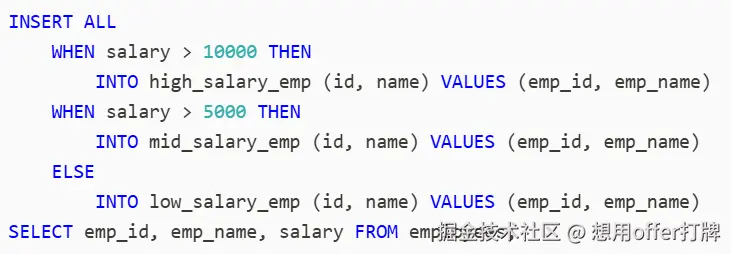
什么是INSERT ALL / FIRST?
1.INSERT FIRST ,它根据条件,将一条源数据插入到多个目标表中的"第一个满足条件"的表中(仅插入一次),从上到下依次判断 WHEN 条件 ,一旦某个条件为真,就执行对应的 INTO,然后跳过后续所有分支 ,每行源数据最多只被插入一次 (即使多个条件都满足),ELSE 是可选的;如果没有 ELSE 且所有条件都不满足,则该行被丢弃。
2.INSERT ALL和INSERT FIRST相反,满足多个条件就插入多次
ps:这种语法在标准 SQL 中不存在,是 Oracle 的扩展。
java
public class OracleMultiInsertStatement extends OracleStatementImpl这是一个 AST(抽象语法树)节点类 ,用于表示上述 INSERT ALL / FIRST 语句
核心字段解释
| 字段 | 类型 | 说明 |
|---|---|---|
option |
Option enum (ALL, FIRST) |
表示是 INSERT ALL 还是 INSERT FIRST |
subQuery |
SQLSelect |
最后的 SELECT ... 子查询,提供数据源 |
entries |
List<Entry> |
插入规则列表,每个 Entry 是一个插入分支(可能是条件分支或无条件插入) |
hints |
List<SQLHint> |
Oracle 的优化器提示(如 /*+ APPEND */) |
内部类详解
1.Entry接口
java
public static interface Entry extends OracleSQLObject这是 entries 列表中元素的通用接口。目前有两个实现:
ConditionalInsertClause(带WHEN/ELSE的条件插入)InsertIntoClause(无条件直接插入)
这样写是为了可以支持混合写法
- ConditionalInsertClauseItem
代表一个 WHEN ... THEN ... 分支。
when:SQLExpr→ 条件表达式(如dept = 'IT')then:InsertIntoClause→ 满足条件时要执行的INSERT INTO ...
要记住的是,ConditionalInsertClause包含了ConditionalInsertClauseItem全部。
seata支持该语法到哪一步呢?
目前,seata只支持同一个表的多插入(列一致),而且也不支持条件插入与Insert First语法。 那这样读者就会有疑问了,那这样岂不是和SQL多插入语法差不多吗?是的,你的猜测不错。
对于上述不支持的情况,seata会抛出NotSupportYetException这个自定义异常给上游应用层捕获,代表seata不支持这种情况。
没有全支持Oracle批量插入的语法原因是什么?
首先我们不是为了支持而支持,seata是一个分布式事务中间件,如果是涉及到不同表的更改,我们更加推荐在分支事务来进行更改,而不是在同一个SQL语句里面进行更改。拆成多个单表 SQL,在多个分支事务中执行,是更安全、可回滚的做法。
关于条件插入和Insert First语法,我们更推荐是在服务层处理条件逻辑,而不是留到数据层再进行处理。数据库应聚焦于高效存储与查询,而非复杂业务逻辑
这样做的核心考量包括:保障分布式事务的可靠性、提升代码可维护性、避免数据库方言绑定,以及确保业务逻辑的统一管控,而不仅仅是执行效率。
支持步骤一: OracleMultiInsertRecognizer
ok,讲完了定义与原因,接下来就应该来讲如何实现了这种简化的Oracle批量插入语法了。
我们首先应该实现OracleMultiInsertRecognizer这个识别器类,这里运用了策略模式,模板方法模式,单一职责等多种设计模式与原则。
java
public class OracleMultiInsertRecognizer extends BaseOracleRecognizer implements SQLInsertRecognizer设计模式
策略模式的体现
OracleMultiInsertRecognizer实现了SQLInsertRecognizer接口。- Seata 在运行时会根据 SQL 的 AST 类型(如
SQLInsertStatement,OracleMultiInsertStatement等)动态选择对应的 Recognizer 实现类
模板方法模式的体现
- 继承自
BaseOracleRecognizer(基类),该基类定义了通用解析流程,子类可以直接继承复用抽象父类的方法。
单一职责原则 + 接口隔离
SQLInsertRecognizer接口只定义 INSERT 相关的方法(getTableName,getInsertColumns,getInsertRows等);OracleMultiInsertRecognizer只负责识别一种特定语法,不处理 UPDATE/DELETE;- 校验逻辑(
validateSingleTableConsistency)与数据提取逻辑(getInsertRows)分离。
具体逻辑
这里挑几个重要的讲即可,剩下大家去看源码即可。
validateSingleTableConsistency()
这是最核心的校验逻辑:
-
遍历所有
Entry(每个INTO ...子句); -
如果遇到
ConditionalInsertClause(即WHEN...THEN)→ 抛出异常,说明并不支持这种语法; -
对每个
InsertIntoClause:- 提取表名(通过
OracleOutputVisitor渲染 AST 得到字符串); - 提取列名(只支持
SQLIdentifierExpr,即普通列名); - 与第一个子句对比:表名必须相同(忽略大小写),列列表必须完全一致;
- 提取表名(通过
-
成功后缓存
validatedTableName和validatedColumns
2.getInsertRows(...)
用于提取所有要插入的具体值(用于生成 undo log) :
-
遍历每个
InsertIntoClause的VALUES列表; -
对每个表达式做类型判断:
SQLNullExpr→ 转为Null.get()(Seata 内部空值表示)SQLValuableExpr(如字符串、数字)→ 取.getValue()SQLVariantRefExpr(如:var绑定变量)→ 保留变量名SQLMethodInvokeExpr(如SYSDATE)→ 标记为SqlMethodExpr.get()SQLSequenceExpr(如seq.nextval)→ 封装为SqlSequenceExpr- 其他复杂表达式 → 若该位置是主键,则报错;否则标记为
NotPlaceholderExpr.get()
支持步骤二:OracleOperateRecognizerHolder
这个容器可以根据ast语法的不同,从而返回不同的识别器,有策略模式的思想在里面。 我们在这新添一个可以返回我们第一步做的批量插入的识别器。
java
public SQLRecognizer getMultiInsertRecognizer(String sql, SQLStatement ast) {
return new OracleMultiInsertRecognizer(sql, ast);
}支持步骤三:DruidSQLRecognizerFactoryImpl
当在druid识别器工厂类识别到相关的sqlStatement,我们就可以对应入座,不同的sqlStatement分配不同的识别器
java
else if (sqlStatement instanceof OracleMultiInsertStatement) {
OracleMultiInsertStatement stmt = (OracleMultiInsertStatement) sqlStatement;
if (stmt.getOption() == OracleMultiInsertStatement.Option.FIRST) {
throw new NotSupportYetException("INSERT FIRST not supported yet");
}
// Use specialized methods to handle Oracle bulk inserts
recognizer =
((OracleOperateRecognizerHolder) recognizerHolder).getMultiInsertRecognizer(sql, sqlStatement);
}总结
那么以上就是seata将要支持的oracle批量插入的解析了,后面我将更新更多有关于seata的解析,喜欢的可以点个关注,谢谢你们