作者:稚柳
前言
作为数据处理领域的经典模式,ETL(Extract-Transform-Load)通过提取、转换、加载三个步骤,高效地处理着各类结构化数据。然而,面对 AI 时代海量、异构、实时的"数据洪流",传统 ETL 链路,尤其是其核心的转换(Transform)环节,正面临严峻挑战。本文将从一个初级开发者也能理解和上手的视角,探讨 AI 时代的数据处理新范式:如何利用基于 Transformer 架构的大语言模型(LLM)重塑传统数据处理中的转换(Transform)环节,并结合事件驱动架构(Event-Driven Architecture, EDA),为 AI 数据处理链路"注入实时智能"。
传统 ETL 在 AI 时代的困境:"T"不仅是"转换",更是"痛点"
ETL(Extract-Transform-Load)是数据处理的核心流程。它负责从不同数据源中提取数据,经过清洗、转换和整合后,加载到统一的数据仓库,为后续的数据分析与商业智能提供支撑。
我们可以将 ETL 生动地比作一个"中央厨房":"提取(Extract)" 是采购生鲜食材(原始数据),"加载(Load)" 是将精美菜肴(可用数据)端上餐桌,而 "转换(Transform)" 则是至关重要的烹饪环节。在过去,厨房采购的多是规格统一的食材(结构化数据),依靠"老菜谱"(固定的规则代码)便能高效、稳定地完成处理。然而,AI 时代带来了形态各异、数量庞大的"山珍海味"------文本、图片、音频、视频等非结构化数据,且往往要求实时处理。这使得厨房里最关键的烹饪环节(Transform)不堪重负,那套为标准食材设计的"老菜谱"已然捉襟见肘。

以一个常见的地址信息标准化场景为例。用户输入的地址格式五花八门,可能是文本、文档、扫描图片以及客服对话等。后端系统为了便于入库与分析,必须将这些信息精准地解析为"省-市-区-街道"的标准化结构。更棘手的是,原始地址信息还可能存在错别字、信息缺失或语义模糊等问题。在传统 ETL 模式下,工程师不得不编写数千行复杂的正则表达式和判断逻辑,并维护一个庞大的地址库。这种方式不仅开发和维护成本高、扩展性差,而且难以覆盖所有非标准格式和异常情况。
这正是传统 ETL 在 AI 时代"力不从心"的缩影,但也只是冰山一角。在 AI 应用中,数据转换的需求远不止于此,例如:从用户评论中提取情感倾向、为非结构化文档打标签、从图片中识别特定内容等。传统基于固定规则的 Transform 工具,面对这些充满"语义"和"不确定性"的任务,几乎束手无策。最终,数据处理链路变得难以扩展、运维复杂且稳定性差,严重拖慢了 AI 应用的创新步伐。
为 ETL 更换"AI 大脑":用 Transformer(AI)代替 Transform
既然传统 Transform 难以理解数据背后的"语义",为何不让擅长此道的 AI 来主导这个环节呢?
本文巧妙地运用了"Transformer"一词的双关含义:它既指代 ETL 中的"转换器"(Transform-er),更特指驱动大语言模型(LLM)的核心架构------Transformer。
这正是"用 Transformer 代替 Transform"的核心思想:将大语言模型(LLM)的智能直接注入 ETL 的数据转换环节。许多过去需要复杂代码才能实现的数据转换任务,如今通过与 AI 交互即可轻松完成。
回到我们的"中央厨房"比喻,现在负责加工菜品的,不再是一本固化的菜谱,而是一位拥有米其林星级水准、能理解并处理任何食材的全能大厨。
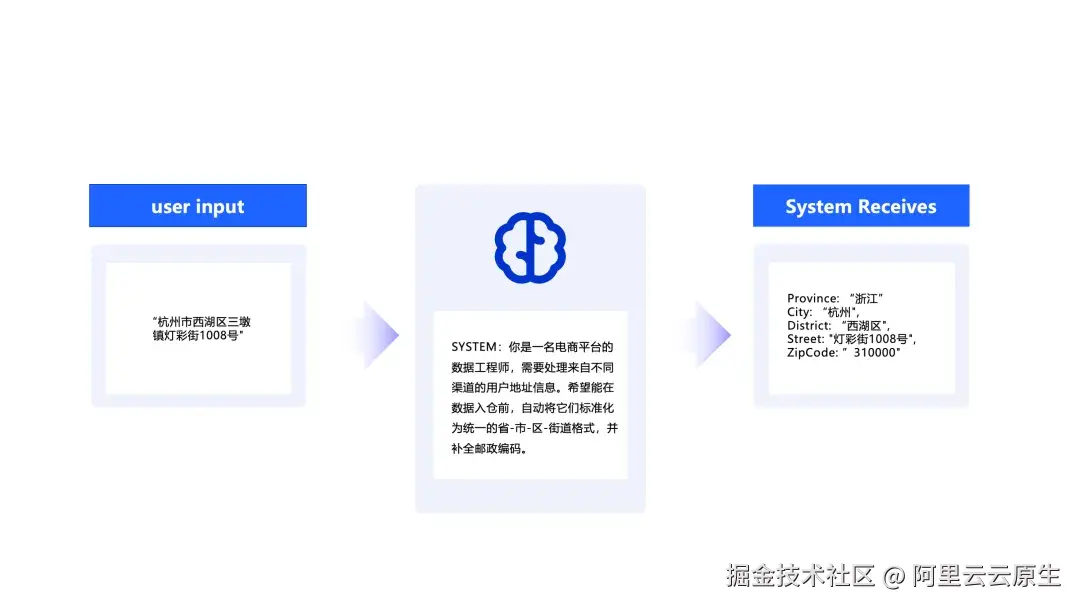
以前文提到的"地址信息标准化"场景为例,集成了 LLM 的数据管道能做到:
- 结构化解析:利用大模型的语义理解能力,即使地址格式不规范、字段顺序混乱,也能准确识别出省、市、区、街道等核心要素。例如,对于"北京市海淀区中关村大街1号",大模型能准确解析出结构化字段:省份为"北京",城市为"北京",区县为"海淀区",街道为"中关村大街1号"。
- 自动识别纠错:基于大模型强大的语言知识与上下文推理,自动识别并纠正地址信息中的错别字或格式错误,再结合地理知识库,能够进一步确保纠正的准确性。例如,将"北京市海定区"纠正为"北京市海淀区",将"中关村大街一号"标准化为"中关村大街1号"。
- 智能信息补全:借助大模型的上下文推理能力,并集成完整的地理信息数据库,能够根据已有地址信息智能补全缺失的部分。例如,通过详细地址自动推断邮政编码,根据区县信息补全城市和省份。
- 格式标准化:最终,所有解析后的信息将被统一输出为标准格式,如结构化的字段信息(省、市、区、街道、邮政编码等)和规范化的地址字符串,确保下游系统能够直接、高效地进行数据处理和分析。
这样,我们就不再需要维护复杂的规则库,只需在数据流中集成大语言模型的能力,即可实现智能化的数据清洗和标准化处理。
事件驱动架构(EDA):ETL for AI Date 的"天选载体"
解决了数据"如何转换"的问题后,我们还需要一个现代化的架构来承载整个流程。相较于传统的批量处理模式,事件驱动架构(Event-Driven Architecture, EDA) 已被公认为是 AI 时代数据处理的理想选择。
如果说"用 Transformer 代替 Transform"是为数据管道植入"AI 大脑",那么 EDA 就是构建这套智能系统的"神经网络",让数据和 AI 指令高效地流动起来。它将系统中的每一次状态变化(如"新文件上传"、"新评论产生")都视为一个独立的"事件",实时触发相应的处理动作,并准确地将处理结果路由到指定的下游系统。
阿里云事件总线 EventBridge:AI 时代的事件中枢
作为 AI 时代的企业级事件枢纽,事件总线 EventBridge 为 AI 数据处理提供强大的事件驱动能力。它能够帮你轻松构建高效、智能的 ETL 数据管道,无缝集成 AI 能力,并且原生支持实时推理 和异步推理两种模式,以满足不同场景的需求。其核心价值体现在以下几个方面:
- 实时智能决策: 将 AI 推理能力无缝融入数据处理流程,使系统能对实时数据进行智能分析与决策,极大提升业务的智能化水平。
- 系统解耦、灵活扩展: 数据源、AI 模型和业务系统通过 EventBridge 完全解耦,任何组件的变更都不会影响其他部分,让系统更加灵活、更易于维护和扩展。
- AI 能力沉淀与复用: 相同的 AI 推理服务可被多个业务场景复用,避免重复开发,最大化 AI 模型的价值与利用率。
- Serverless 与易用性: 作为全托管的 Serverless 服务,EventBridge 免去了繁琐的部署和运维工作。通过简单的控制台配置或 API 调用,即可快速构建和管理事件驱动的数据处理流程,并支持事件过滤、转换、路由、重试等高级能力。
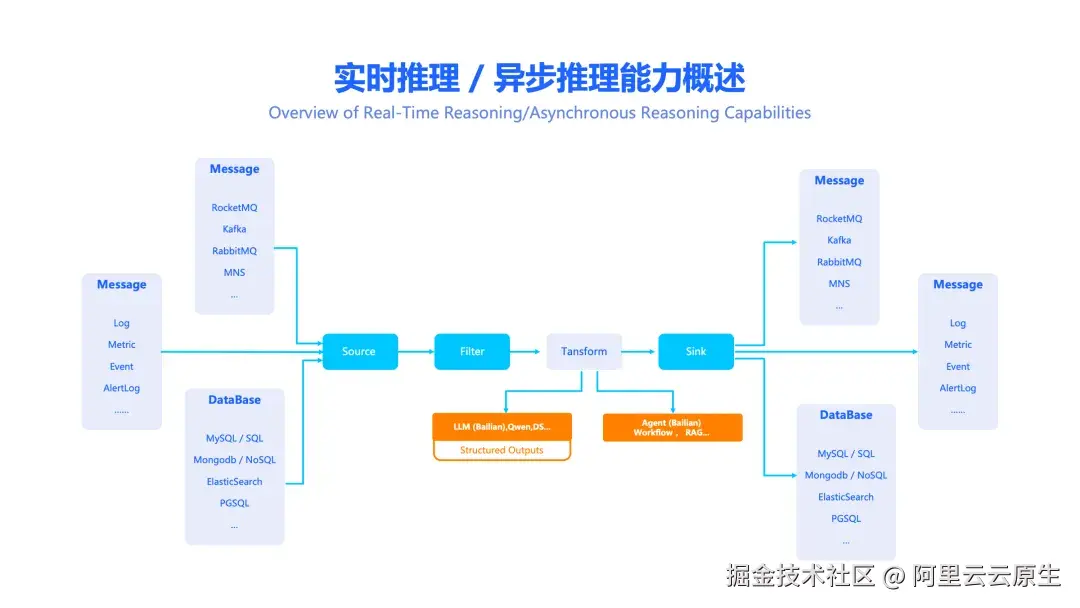
核心能力:从不确定到确定的"结构化输出"
在 ETL 的 "转换(Transform)" 环节中,EventBridge 允许用户直接调用大语言模型(例如通义千问或百炼大模型服务平台上的模型),甚至是更复杂的 AI Agent。
但问题来了:LLM 的输出具有不确定性,有时像"开盲盒",这在要求稳定可靠的企业级应用中是无法接受的。
为了解决这个核心痛点,EventBridge 提供了强大的结构化输出(Structured Output) 能力,确保 AI 的每一次处理结果都以稳定、可靠的格式返回。
例如,当需要模型分析用户评论的情感时,我们期望的不是"我觉得这句话是积极的"这类模棱两可的文本,而是一个清晰的 JSON 对象,如:{ "sentiment": "积极", "summary": "产品设计和性能出色,客户非常满意" }。

EventBridge 通过以下两项核心技术,产品化地实现了这一关键能力:
- JsonSchema 原生支持: 对于支持 JsonSchema 的模型,EventBridge 会利用其原生能力,确保模型输出严格遵循用户定义的格式,实现高性能与高可靠性。
- 智能提示词注入: 对于不支持 JsonSchema 的模型,EventBridge 会采用智能提示词注入技术,引导模型生成稳定、可靠的结构化输出,并确保多轮对话格式的一致性。
这项能力极大地降低了在 ETL 流程中使用 AI 的门槛,为企业级应用的稳定性提供了坚实保障。
场景实践:EventBridge+百炼,让 AI 赋能数据链路
我们以一个具体的场景为例,展示如何通过阿里云的事件总线 EventBridge 与大模型服务平台百炼的结合,构建 AI 赋能的数据链路。
通过在 EventBridge 的事件流中原生集成百炼大模型服务,使开发者可以在数据流中直接调用 AI,从而轻松、高效地完成传统 ETL 中复杂的转换(Transform)任务。
应用场景:敏感信息过滤与数据脱敏
本方案将演示如何利用 AI 对实时数据流进行清洗与脱敏处理,自动发现并屏蔽业务数据中的敏感关键词,从而保障业务的数据合规性。
方案架构与实施步骤
该方案的核心是利用 EventBridge 作为数据中枢,将来自不同数据源的实时数据流,分发给百炼 AI 模型进行推理,再将推理结果通过 EventBridge 路由到下游的业务系统或数据存储中。
下图展示了该方案的参考架构:
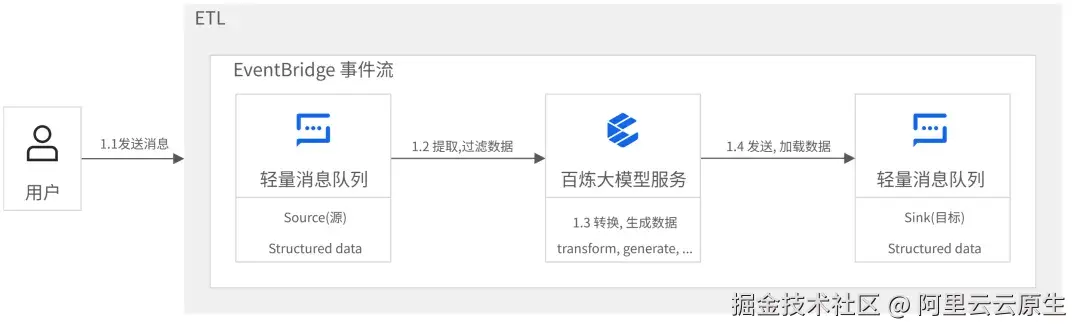
实施该方案主要包括以下三个步骤:
1. 构建数据管道: 创建一个 EventBridge 事件流,作为整个数据处理的核心链路。
2. 配置数据源与目标: 创建两个轻量消息队列,分别作为事件流的源(Source)和目标(Sink)。
3. 集成 AI 能力: 在事件流的转换(Transform)环节,配置调用已开通的阿里云百炼大模型服务,将 AI 的智能处理能力无缝嵌入数据管道中。
整个流程通过在 EventBridge 控制台进行简单的点击和配置即可完成,无需编写复杂的代码来连接数据源、AI 模型和下游系统,大大提升了开发效率。
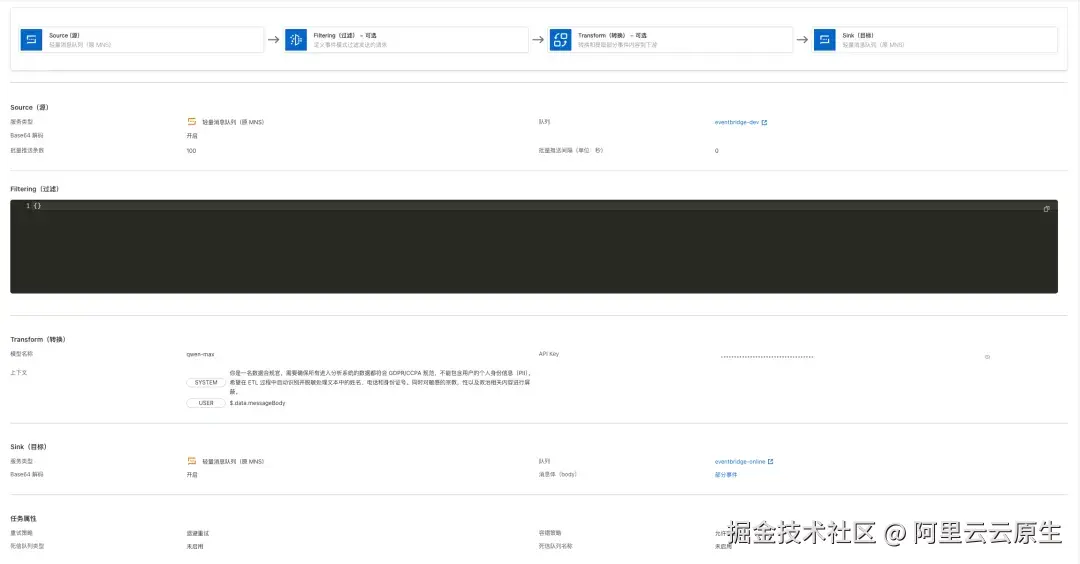
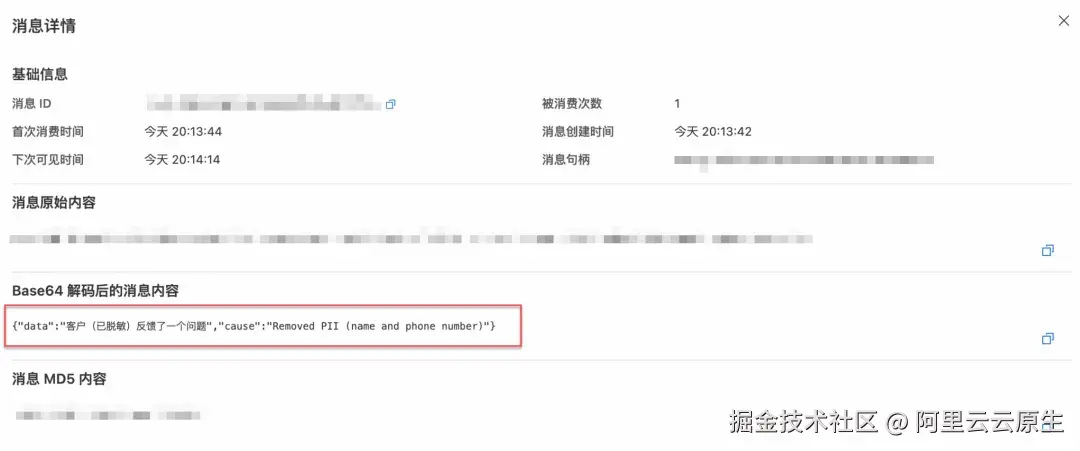
实现效果
部署完成后,可以通过以下方式验证数据脱敏效果:从 Source(源)队列发送带有敏感信息的数据,然后在 Sink(目标)队列接收经过事件流处理后的数据。
- 输入示例:包含敏感信息的数据,如
["客户张三(13812345678)反馈了一个问题..."] - 输出示例:经过 AI 脱敏后的数据,如
["客户***(138*****5678)反馈了一个问题..."]
注:由于大模型生成结果存在随机性,实际测试时输出结果的格式可能存在差异。在生产环境中,可以结合 EventBridge 的结构化输出能力与提示词工程,获得稳定可靠的输出结果。
开发者关心的问题(Q&A)
问:每次数据转换都调用 LLM,成本会不会很高?
答:成本是大家最关心的问题。首先,EventBridge 本身是 Serverless 服务,按实际处理的事件数量付费。主要的成本来自 LLM 调用,但你可以根据场景需求灵活选择不同规模和成本的模型。对于简单任务,轻量级模型已足够,成本较低。对于非实时场景,可采用异步批量调用的方式,进一步优化成本。
问:LLM 推理有延迟,会影响实时性吗?
答:事件驱动架构的异步和解耦特性天然适合这种情况。数据源发送事件后无需等待处理结果,整个系统流程不会被阻塞。EventBridge 支持实时和异步两种推理模式,你可以根据业务对延迟的敏感度进行选择,确保用户体验不受影响。
总结
用 Transformer(LLM)升级 Transform(转换),并以事件驱动架构(EDA)作为承载,是 AI 时代数据处理范式的一次"智"变。阿里云 EventBridge 与百炼的结合,为开发者提供了一条低门槛、高灵活性的路径,将强大的 AI 能力无缝融入实时数据流,让你的应用轻松实现智能化。
目前,该解决方案已在阿里云官网上线,欢迎点击此处即可部署体验~
钉钉搜索群号:44552972 加入 EventBridge 用户交流群,探索更多产品功能,与我们共同定义和构建 AI 数据处理的未来!