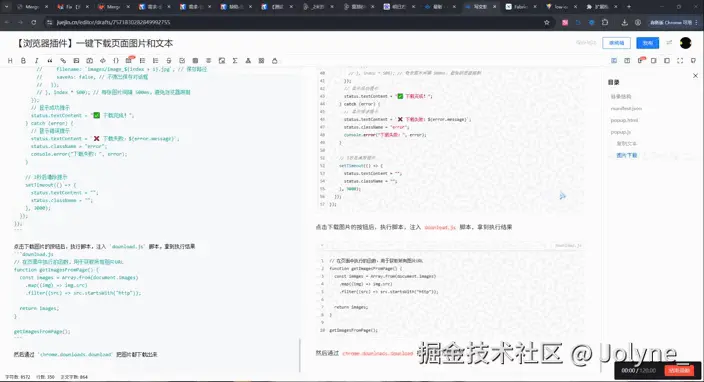
最近我的朋友们工作上好像没事就要下载页面的图片和文本,于是我干脆写了个谷歌浏览器插件,下载当前页面所有的图片和文本,方便省事嘿嘿
目录结构
bash
image-text-plugin/
├── icons/ # 插件图标(可使用在线图标替代)
│ ├── icon16.png
│ ├── icon48.png
│ └── icon128.png
├── manifest.json # 插件配置文件
├── popup.html # 弹出窗口界面
├── popup.js # 弹出窗口逻辑
├── content.js # 页面内容处理脚本
└── download.js # 页面图片处理脚本manifest.json
json
{
"manifest_version": 3,
"name": "文本复制、图片下载",
"version": "1.0",
"description": "点击即可复制当前网页的所有文本内容到剪贴板,或者下载当前页面的所有图片",
"icons": {
"16": "icons/copy.png",
"48": "icons/copy.png",
"128": "icons/copy.png"
},
"action": {
"default_popup": "popup.html",
"default_icon": "icons/copy.png"
},
"permissions": ["activeTab", "scripting", "contextMenus", "downloads"]
}当点击浏览器拓展程序时,要显示 popup.html 的内容
popup.html
html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<style>
body {
width: 180px;
padding: 15px;
font-family: Arial, sans-serif;
background-color: #f8f9fa;
}
.container {
text-align: center;
}
#copyBtn, #downloadBtn {
width: 100%;
padding: 10px;
color: white;
border: none;
border-radius: 4px;
cursor: pointer;
font-size: 14px;
font-weight: bold;
transition: background-color 0.3s;
}
#copyBtn {
background-color: #4285f4;
}
#downloadBtn {
margin-top: 12px;
background-color: #df42f4;
}
#copyBtn:hover {
background-color: #3367d6;
}
#downloadBtn:hover{
background-color: #b42fc5;
}
#status {
margin-top: 12px;
font-size: 14px;
color: #333;
}
.success {
color: #198754 !important;
}
.error {
color: #dc3545 !important;
}
</style>
</head>
<body>
<div class="container">
<button id="copyBtn">复制当前页面所有文本</button>
<button id="downloadBtn">下载当前页面所有图片</button>
<div id="status"></div>
</div>
<script src="popup.js"></script>
</body>
</html>两个按钮,分别复制文本、下载图片。然后再加上一个状态提示是否成功
并注入脚本 popup.js
popup.js
脚本的代码在页面加载完成后才执行
js
document.addEventListener("DOMContentLoaded", () => {
//...
});复制文本
先看复制文本的脚本
js
document.addEventListener("DOMContentLoaded", () => {
const copyBtn = document.getElementById("copyBtn");
const status = document.getElementById("status");
copyBtn.addEventListener("click", async () => {
try {
// 获取当前活跃标签页
const [tab] = await chrome.tabs.query({
active: true,
currentWindow: true,
});
// 向页面注入内容脚本,获取所有文本
const results = await chrome.scripting.executeScript({
target: { tabId: tab.id },
files: ["content.js"],
});
// 提取文本内容
const pageText = results[0].result;
if (!pageText.trim()) {
throw new Error("当前页面没有可复制的文本");
}
// 复制到剪贴板
await navigator.clipboard.writeText(pageText);
// 显示成功提示
status.textContent = "✅ 复制成功!";
status.className = "success";
} catch (error) {
// 显示错误提示
status.textContent = `❌ 复制失败:${error.message}`;
status.className = "error";
console.error("复制失败:", error);
}
// 3秒后清除提示
setTimeout(() => {
status.textContent = "";
status.className = "";
}, 3000);
});
//...
});当我们执行复制操作时,会往当前页面注入 content.js 的脚本,拿到执行结果
js
// content.js - 保留换行的文本提取逻辑
function getAllPageTextWithLineBreaks() {
const tempDoc = document.cloneNode(true);
// 移除不需要的标签(脚本、样式、iframe等)
const removeTags = ['script', 'style', 'noscript', 'iframe', 'svg', 'canvas'];
removeTags.forEach(tag => {
const elements = tempDoc.querySelectorAll(tag);
elements.forEach(el => el.remove());
});
// 定义需要自动换行的块级元素和重要行内元素
const blockElements = [
'div', 'p', 'h1', 'h2', 'h3', 'h4', 'h5', 'h6',
'ul', 'ol', 'li', 'dl', 'dt', 'dd', 'table', 'tr', 'td',
'header', 'footer', 'section', 'article', 'nav', 'aside',
'blockquote', 'pre', 'address', 'figure', 'figcaption'
];
// 收集所有文本节点,同时记录元素类型以添加换行
const textParts = [];
const walker = document.createTreeWalker(tempDoc.body, NodeFilter.SHOW_TEXT, (node) => {
// 过滤掉纯空白文本节点
return node.textContent.trim() ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_REJECT;
});
let currentNode;
let prevElement = null;
while (currentNode = walker.nextNode()) {
const text = currentNode.textContent.trim();
if (!text) continue;
// 获取当前文本节点的父元素
const parentEl = currentNode.parentElement;
const parentTag = parentEl.tagName.toLowerCase();
// 逻辑:添加换行的情况
const shouldAddLineBreak = (() => {
// 1. 如果前一个元素是块级元素,添加换行
if (prevElement && blockElements.includes(prevElement.tagName.toLowerCase())) {
return true;
}
// 2. 如果当前父元素是块级元素,且不是第一个元素,添加换行
if (blockElements.includes(parentTag) && textParts.length > 0) {
return true;
}
// 3. 如果前一个元素和当前元素是不同的行内兄弟元素,添加换行
if (prevElement &&
prevElement.parentElement === parentEl.parentElement &&
!blockElements.includes(prevElement.tagName.toLowerCase()) &&
!blockElements.includes(parentTag)) {
return true;
}
// 4. 列表项特殊处理:每个li前加换行
if (parentTag === 'li' && textParts.length > 0) {
return true;
}
return false;
})();
// 根据判断添加换行符
if (shouldAddLineBreak) {
// 避免连续多个换行
const lastPart = textParts[textParts.length - 1];
if (!lastPart || !lastPart.endsWith('\n\n')) {
textParts.push('\n');
}
}
// 添加当前文本(清理内部多余空白)
const cleanedText = text.replace(/\s+/g, ' '); // 只清理文本内部的多余空白
textParts.push(cleanedText);
// 更新前一个元素记录
prevElement = parentEl;
}
// 合并所有部分,处理首尾换行
let finalText = textParts.join('')
.replace(/^\n+/, '') // 移除开头的换行
.replace(/\n+$/, '') // 移除结尾的换行
.replace(/\n{3,}/g, '\n\n'); // 最多保留两个连续换行(模拟段落间距)
return finalText;
}
// 将结果返回给popup
getAllPageTextWithLineBreaks();然后通过 navigator.clipboard.writeText(pageText) 复制文本
这里面主要是复制文本后,保持换行。比如文本是 11 222 复制出来的就是
html
11
222换行的
图片下载
图片下载也一样的
js
document.addEventListener("DOMContentLoaded", () => {
const downloadBtn = document.getElementById("downloadBtn");
const status = document.getElementById("status");
downloadBtn.addEventListener("click", async () => {
try {
// 获取当前活跃标签页
const [tab] = await chrome.tabs.query({
active: true,
currentWindow: true,
});
// 向页面注入内容脚本,获取所有文本
const results = await chrome.scripting.executeScript({
target: { tabId: tab.id },
files: ["download.js"],
});
// 获取执行结果
if (!results || !results[0]?.result || results[0].result.length === 0) {
console.log("未找到图片");
return;
}
status.textContent = "✅ 正在下载";
status.className = "success";
const images = results[0].result;
// 批量下载图片
images.forEach(async (url, index) => {
await chrome.downloads.download({
url: url,
filename: `images/image_${index + 1}.jpg`, // 保存路径
saveAs: false, // 不弹出保存对话框
})
// setTimeout(() => {
// chrome.downloads.download({
// url: url,
// filename: `images/image_${index + 1}.jpg`, // 保存路径
// saveAs: false, // 不弹出保存对话框
// });
// }, index * 500); // 每张图片间隔 500ms,避免浏览器限制
});
// 显示成功提示
status.textContent = "✅ 下载完成!";
} catch (error) {
// 显示错误提示
status.textContent = `❌ 下载失败:${error.message}`;
status.className = "error";
console.error("下载失败:", error);
}
// 3秒后清除提示
setTimeout(() => {
status.textContent = "";
status.className = "";
}, 3000);
});
});点击下载图片的按钮后,执行脚本,注入 download.js 脚本,拿到执行结果
download.js
// 在页面中执行的函数,用于获取所有图片URL
function getImagesFromPage() {
const images = Array.from(document.images)
.map((img) => img.src)
.filter((src) => src.startsWith("http"));
return images;
}
getImagesFromPage();然后通过 chrome.downloads.download 把图片都下载出来
效果演示