目录
摘要
今天学习了聚类这一无监督学习算法,特别是k-means算法的原理和步骤。聚类与有监督学习不同,它没有标签数据,而是自动发现数据中的内在结构。k-means通过随机初始化簇中心,然后交替执行"分配点到最近簇"和"重新计算簇中心"两个步骤,直到算法收敛。这种算法在新闻分类、DNA分析和天文研究等领域都有广泛应用。
Abstract
Today's lesson introduced clustering as an unsupervised learning algorithm, focusing on the k-means method. Unlike supervised learning, clustering works with unlabeled data to discover inherent structures. The k-means algorithm initializes cluster centers randomly, then iteratively assigns points to nearest clusters and recomputes cluster centers until convergence. This technique finds applications in news categorization, DNA analysis, and astronomical research.
一、什么是聚类
聚类算法会查看多个数据点,并自动找到相关或相似的数据点,先让我们对比一下聚类,有个无监督算法,与之前的在有监督学习中的二元分类相比,给定一个包含特征x1和x2的数据集
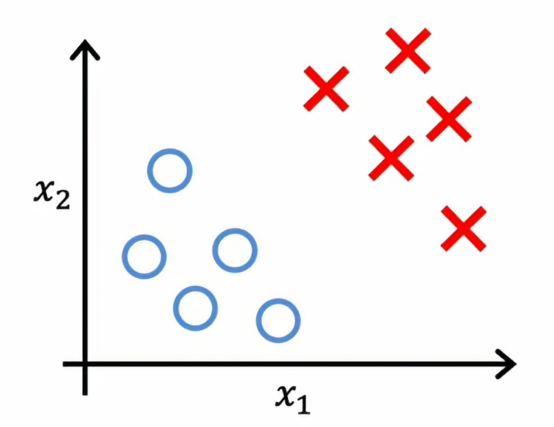
在有监督学习中,我们有一个包含输入特征x以及标签y的训练集比如使用逻辑回归或神经网络来学习这样的决策边界,在有监督学习中,数据集包括输入x以及目标输出y,相比之下,无监督学习中,我们得到的数据集只有x而没有标签或目标,这就是为什么它看起来是这样,如下图所示:
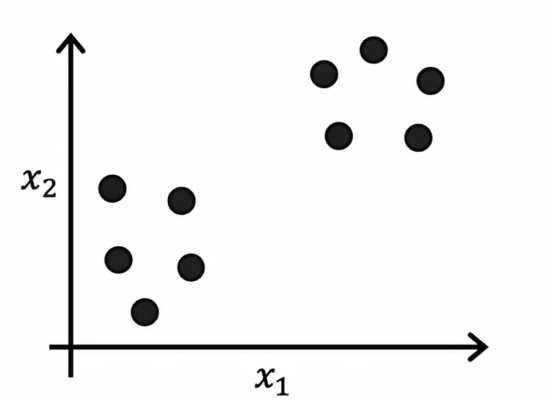
只有黑点,而不是用叉和圈来表示的两类,因为我们没有目标标签,我们无法告诉算法我们想要的正确答案y,相反,我们会要求算法发现数据中一些有趣的东西,但我们学习的第一个无监督学习算法叫做聚类算法,它在数据中寻找一种特定的结构类型,也就是说,它们会像这样查看数据集并尝试查看是否可以将其分组为聚类即彼此相邻的点组,所以在这种情况下,聚类算法可能会发现这个数据集由这里展示的两个聚类的数据组成
这里是聚类的一些应用,在我们之前学习的例子中,我们谈到过将相似的新闻文章分组,比如关于熊猫的故事和市场的分类,在学术交流会上我们发现有许多学习者来到这里,因为我们可能想要拓展我们的技能或职业生涯或与时俱进,了解AI如何影响到我们的工作领域,我们希望帮助每个人实现自己的目标,聚类还被应用于分析DNA数据,你会查看来自不同个体的基因表达数据并尝试将它们分组为表现出相同特征的人群,比如我对天文学和太空探索充满兴趣,所以我觉得一个非常令人兴奋的应用是天文学家使用聚类进行天文数据分析,将太空中的天体进行分组,以便他们分析太空中的情况,所以我发现一个令人着迷的应用是天文学家使用聚类将天体分组,以确定哪些天体构成一个星系或哪些天体构成太空中的连贯结构
那我们如何构建一个聚类呢?这就引出我们下一个讨论的话题,一个聚类算法,叫做k-means算法
二、 k-means算法
让我们看看k均值聚类算法的作用,这里我们绘制了一个包含30个未标记训练样本的数据集
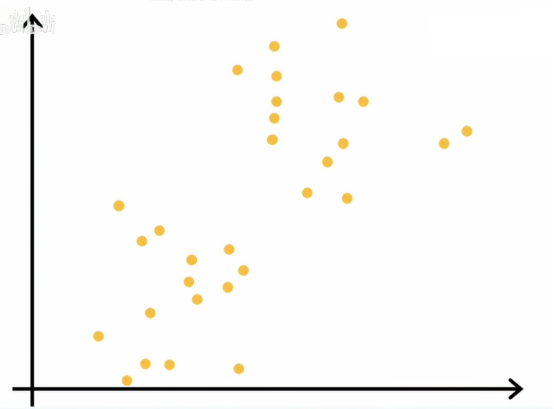
这里有30个点,我们想做的是在这个数据集上运行k均值算法,k均值算法首先会随机猜测两个中心位置,在这个例子中,我们希望能够找到两个簇,在之后的学习中,我们才会讨论如何决定找到多少个簇,但第一步它会随机选择两个点,正如下图所示
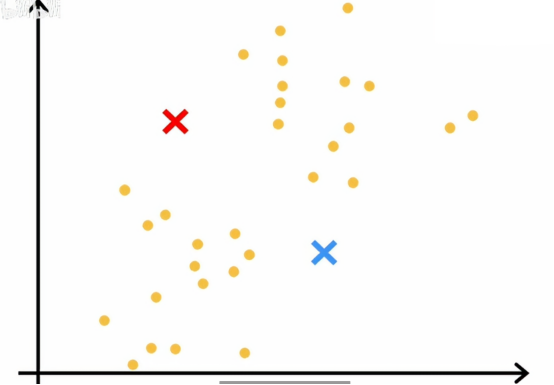
一个红色叉号,一个蓝色叉号,可能是两个不同簇的中心,这只是一个随机的初步猜测,我们需要知道的是,k均值算法会反复做两件事情,第一是将点分配到簇的质心,第二是移动簇的质心,这两步的第一步是,它会遍历每个点,看看它更接近红色叉号还是更接近蓝色叉号,k均值算法的第一步是随机猜测簇中心的位置,簇的中心被称为是簇质心,它会遍历所有这些样本,从x1到x30这30个数据点,它会检查更接近红色簇中心,由红色叉号表示,还是更接近蓝色簇质心,由蓝色叉号表示,它会将每个点分配到离它更近的簇质心,也就是说根据示例接近红色或蓝色簇质心,将被涂成红色或蓝色,这就是为什么它被涂成红色和蓝色,如下图所示
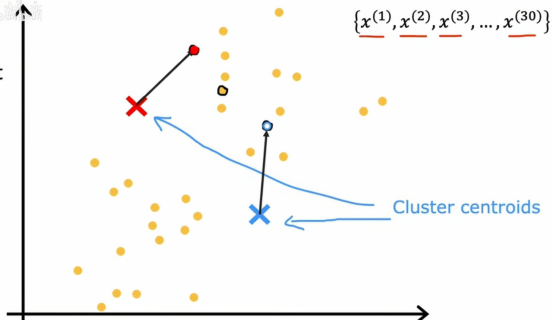
所以这就是k均值重复进行的两步中的第一步,即将点分配到簇质心,其第一次结果如下
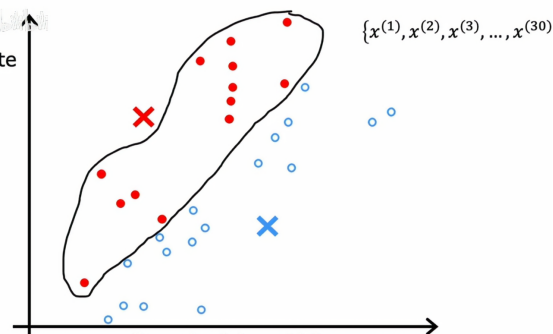
k均值的第二步就是查看所有的红色点并取它们的平均值,它会将红叉移动到红点的平均位置,因此原来的红叉需要重新标记出来,如下图所示
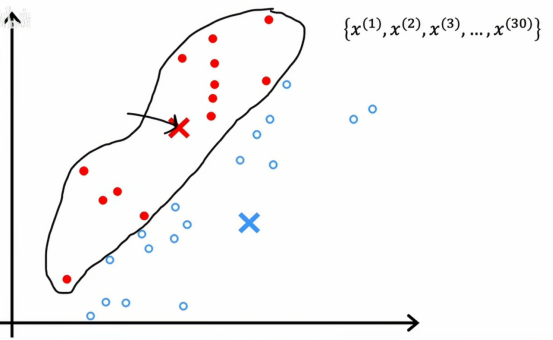
同样的,我们将蓝色的小点全部包围起来,然后我们对蓝色点做相同的操作,查看所有蓝色点并取平均值,然后将蓝色叉号移动到下一个地方,这样我们也得到了蓝色簇质心的新位置
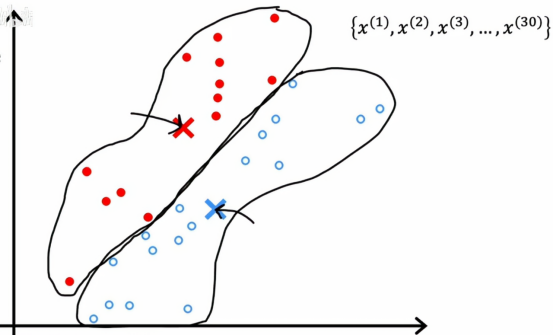
但现在我们有了两个簇中心的新位置,我们将再次查看所有30个训练样本,并检查每一个它是否更接近新位置的红色或蓝色簇质心,用颜色再次标记,如果这样做,我们将会看到一些点会变色,例如,这个点之前是红色的,因为它更接近红色簇质心
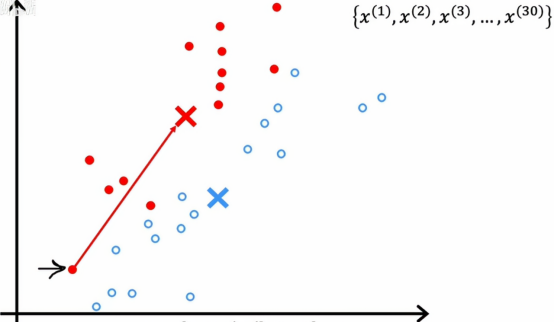
但如果我们现在再看的话,它实际上更接近蓝色簇质心,因为蓝色和红色的簇质心已经移动,所以如果我们依次将每个点与更近的簇质心关联,我们会得到这个结果
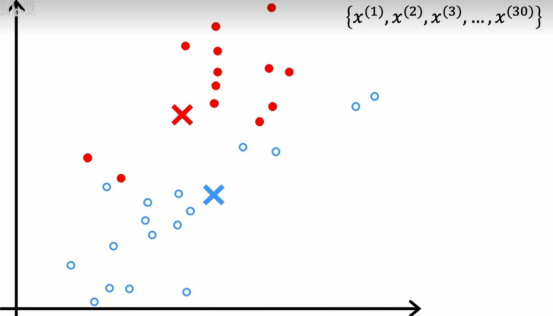
就是这些原本红色的小点,只要离现在的蓝色点更近,只要离现在的红色点更近,都被划为红色,然后我们再重复k均值的第二部分,查看红色的点并取平均值,同时查看所有的蓝色点并计算所有蓝色点的平均位置,结果如下图
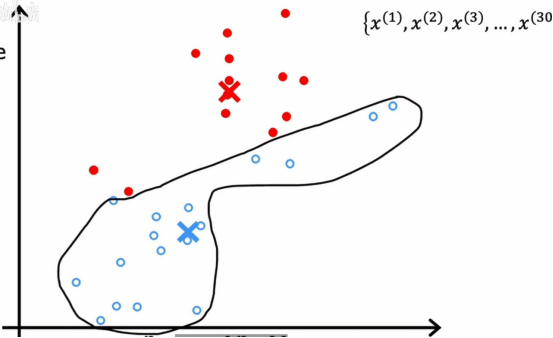
然后我们再重复,再次查看所有的点,冲洗涂成蓝色或红色,取决于它更接近哪个簇质心,接着再查看所有红点,取平均位置,再看看所有蓝点,取平均位置,并将簇移动到新位置,如此往复,直到我们发现点的颜色和质心的位置都不会再发生变化,这就意味着此时,k均值聚类算法已经收敛,因为不断重复这两个步骤不会再有进一步的变化,无论是点分配给质心,还是簇质心的位置
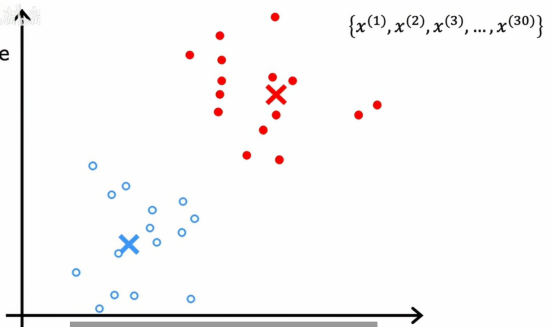
总结
今天的学习让我对无监督学习有了全新认识。聚类算法不需要标签就能自动发现数据中的模式,这很神奇。k-means算法的两步迭代过程很巧妙:先按距离分配点到簇,再重新计算簇中心位置,不断重复直到稳定。我特别喜欢老师举的天文学例子,用聚类分析天体数据来识别星系结构。相比之前学的有监督算法,聚类更适合探索性数据分析,当我们没有明确标签但又想发现数据内在分组时特别有用。算法虽然简单,但应用范围很广,从文本分类到基因研究都能发挥作用。