过去两周,我们对开源之夏活动中表现优异的开发者们进行了简单的采访,初步粗略地了解了一下他们的开发过程和心得体会。今天,我们将通过同学们的完整结项报告,深入了解项目的开发技术细节,希望能够帮助大家更好地了解 Apache SeaTunnel 项目的最新进展。
接下来是关于Apache SeaTunnel支持metalake开发这一项目的完整报告:
一、项目背景
目前,Apache SeaTunnel 的任务配置中,数据源的用户名和密码等敏感信息直接写死在任务脚本中,这种方式 存在以下问题:
- 安全隐患:敏感信息暴露在脚本中,易导致数据源信息泄漏。
- 维护困难: 数据源配置信息发生变更时,需手动修改所有相关任务脚本,效率低下且易出错。
为解决上述问题,本项目旨在通过集成metalake,实现数据源信息的集中存储和管理。通过数据源 ID 映射机 制,用户可方便地更新和管理数据源配置。本项目的目标是支持主流数据目录 Apache Gravitino,并通过预留 接口,方便扩展支持其他第三方数据目录服务。
Apache Gravitino获取数据源配置信息的REST API示例见于:https://gravitino.apache.org/docs/0.9.0- incubating/api/rest/load-catalog
代码仓库见于: https://github.com/apache/seatunnel
-
完成metalake配置信息适配
将metalake配置信息配置在seatunnel-env中,任务启动后加载到任务配置脚本的env中。
1.1 任务启动时读取
seatunnel-env中的配置项。1.2 将配置集成到任务脚本的
env中,确保任务能够正确加载metalake配置。 -
完成source和sink的数据源配置信息改造
读取
env中是否开启metalake标识,在source和sink中增加sourceId作为查询metalake的唯一标识,获取数据 源信息并替换source/sink配置项中的占位符。2.1 在source和sink配置中增加sourceId配置项。
2.2 支持source/sink配置项中的占位符替换,通过sourceId动态获取数据源信息。
-
插件方式支持metalake并集成Apache Gravitino
定义metalake接口,支持根据唯一ID查询数据源配置信息,并实现Apache Gravitino数据源信息转换为 SeaTunnel配置项占位符的功能。
3.1 定义metalake实现接口,提供数据源查询功能。
3.2 支持Apache Gravitino集成,参考Gravitino REST API文档。
3.3 支持扩展性,通过实现接口可支持其他数据目录,如UnityCatalog或DataHub。
3.4 确保向后兼容,不影响存量任务的正常运行。
二、方案描述
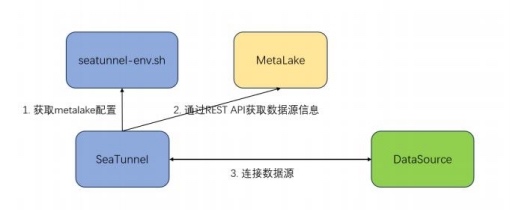
-
完成metalake配置信息适配
1.1 任务启动时读取
seatunnel-env中配置项
-
实现目标:在任务启动时,从
seatunnel-env.sh或者任务配置文件中读取metalake相关的配置。 -
实现方法:在
seatunnel-env.sh文件中定义metalake配置项,例如:METALAKE_ENABLED=true
METALAKE_TYPE=gravitino
METALAKE_URL=http://localhost:8090/api/metalakes/metalake_name/catalogs /
...
或者在任务配置文件中的env中配置
env{
metalake_enabled = true
metalake_type = "gravitino"
metalake_url =
"http://localhost:8090/api/metalakes/metalake_name/catalogs/" }1.2 将配置集成到env中
- 实现目标:将读取的metalake配置集成到任务的env中。
- 实现方法:
- 若用户在任务配置文件中配置env,那么自然无需集成。
- 若在seatunnel-env.sh脚本中配置,也可通过System.getEnv()获得,无需集成到env中
-
完成source和sink的数据源配置信息改造
2.1 source/sink增加sourceId配置项
- 实现目标:为source和sink添加sourceId字段,用于标识metalake中的数据源。
- 实现方法:
-
在任务脚本中指定sourceId即可。
-
任务脚本示例:
source {
type = "mysql"
sourceId = "mysql_datasource_001"
url = "jdbc:mysql://localhost:3306/db"
...
}
-
2.2 支持source/sink的配置项占位符替换
- 实现目标:通过metalake动态获取数据源信息,并替换配置中的占位符。
- 实现方法:
- 在配置解析阶段,检查sourceId和metalakeEnabled。
- 如果启用metalake且sourceId存在,则用户可将username和password等字段并设为占位符,然 后通过metalake接口查询数据源信息并占位符替换。
- 步骤:
*- 定义占位符格式,例如${key}。
-
- 通过REST API查询数据源信息。

- 通过REST API查询数据源信息。
-
- 替换配置中的占位符。
- 代码示例:

-
插件方式支持metalake并支持Apache Gravitino集成
3.1 定义metalake实现接口
- 实现目标:定义一个通用接口,用于与metalake交互。
- 实现方法:
- 定义
MetalakeClient接口,包含查询数据源信息的方法。 - 接口定义:

- 定义
3.2 支持Apache Gravitino集成
-
实现目标:实现与Apache Gravitino的集成,通过REST API获取数据源信息。
-
实现方法:
- 创建
GravitinoClient类,实现MetalakeClient接口。 - 使用HTTP客户端发送请求到Gravitino API,并解析响应。
- 代码示例:

3.3 支持可扩展
- 创建
-
实现目标:通过插件化设计,支持其他metalake实现。
-
实现方法:
- 使用工厂方法,根据metalakeType选择合适的client。
- 代码示例:

3.4 不影响存量任务,向后兼容
-
实现目标:确保新功能不破坏现有任务。
-
实现方法:
- 将metalakeEnabled设为可选配置,默认值为false。
- 仅在metalakeEnabled=true且sourceId存在时触发metalake逻辑。
- 代码示例:

三、时间规划
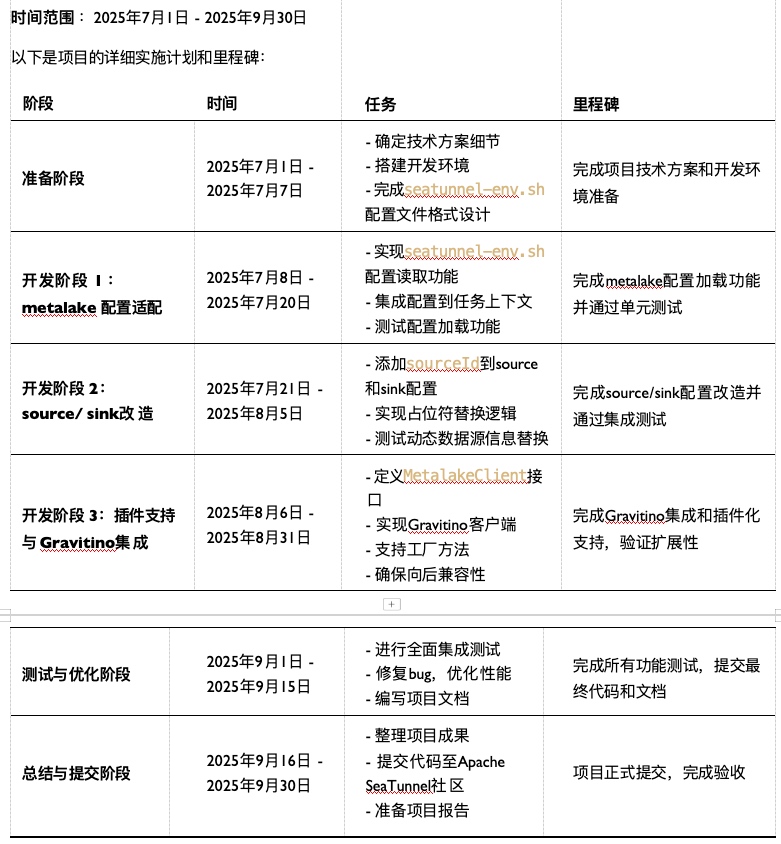
四、项目进度
已完成工作
已完成项目所需功能的开发与测试,并经过修改后,已经合并了PR。
遇到的问题与解决方案
在编写代码时,我遇到的问题不多,并且要感谢liugddx老师的指导,在老师的指导下,我遇到的问题基本迎刃 而解。
还有一个问题就是该项目的test case较多,测试时间较长,并且合并PR前要通过所有的test case。然后由于网 络等原因,这些test case不是很稳定,有时需要多次重试才能通过,这很考验我的耐心。
测试用例
设计了一个简单的任务配置脚本,并在source中使用了metalake。
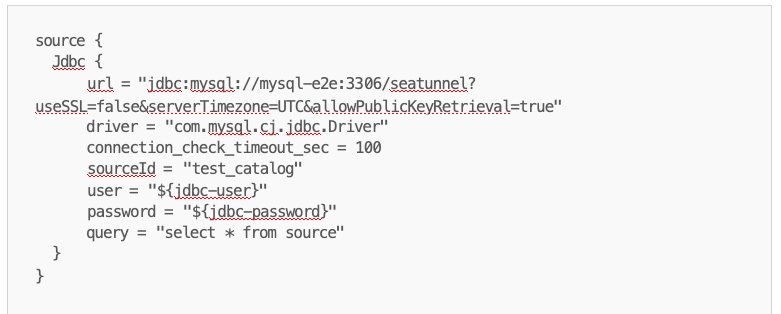
并为此测试用例构建了相应的MySQL数据库和Gravitino。在sink中使用了Assert connector,保证得到正确的结 果。该集成测试的test case代码也已上传github,并且通过了测试。
后续工作安排
后续可以考虑集成更多的metalake类型,使得该功能不局限于Gravitino。