PriorSignalModelEstimator在WebRTC噪声抑制系统中承担先验模型参数估计的核心角色。该类通过分析LRT、频谱平坦度和频谱差异三个特征的统计直方图,动态估计噪声检测的关键阈值。采用峰值检测、波动性分析和自适应权重分配算法,它能智能区分语音与噪声状态。基于直方图统计学习,自动调整各特征的检测阈值和贡献权重,确保噪声抑制系统在不同音频环境下都能保持最佳性能。这种自适应性显著提升了WebRTC在复杂场景中的语音增强效果和系统鲁棒性。
1. 核心功能
PriorSignalModelEstimator类负责估计先验信号模型参数,用于噪声抑制中的语音/噪声概率估计。它通过分析音频特征的统计直方图,动态调整噪声检测的阈值参数。
2. 核心算法原理
2.1 LRT特征更新算法
// LRT特征更新算法数学原理:
// 平均值计算:μ = Σ(hist[i] * bin_mid) / count
// 平方平均值:E[x²] = Σ(hist[i] * bin_mid²) / window_size
// 波动性判断:E[x²] - μ * E[x] < 0.05
void UpdateLrt(rtc::ArrayView<const int, kHistogramSize> lrt_histogram,
float* prior_model_lrt, bool* low_lrt_fluctuations) {
// 计算前10个bin的平均值(主要关注低LRT区域)
for (int i = 0; i < 10; ++i) {
float bin_mid = (i + 0.5f) * kBinSizeLrt;
average += lrt_histogram[i] * bin_mid; // 加权平均
count += lrt_histogram[i];
}
// 计算整个直方图的统计量
for (int i = 0; i < kHistogramSize; ++i) {
float bin_mid = (i + 0.5f) * kBinSizeLrt;
average_squared += lrt_histogram[i] * bin_mid * bin_mid; // 平方平均
average_compl += lrt_histogram[i] * bin_mid; // 完整平均
}
// 判断LRT波动性:方差较小表示稳定噪声状态
*low_lrt_fluctuations = average_squared - average * average_compl < 0.05f;
// 根据波动性设置LRT阈值
if (*low_lrt_fluctuations) {
*prior_model_lrt = kMaxLrt; // 低波动→很可能是噪声→高LRT阈值
} else {
*prior_model_lrt = std::min(kMaxLrt, std::max(kMinLrt, 1.2f * average));
}
}2.2 双峰检测与合并算法
// 双峰检测算法:寻找直方图中最大的两个峰值
// 如果两峰距离小于2*bin_size且权重相近,则合并
void FindFirstOfTwoLargestPeaks(
float bin_size, rtc::ArrayView<const int, kHistogramSize> spectral_flatness,
float* peak_position, int* peak_weight) {
// 遍历直方图,寻找两个最大峰值
for (int i = 0; i < kHistogramSize; ++i) {
const float bin_mid = (i + 0.5f) * bin_size;
if (spectral_flatness[i] > peak_value) {
// 发现新的主峰,将原主峰降级为次峰
secondary_peak_value = peak_value;
secondary_peak_weight = *peak_weight;
secondary_peak_position = *peak_position;
// 更新主峰信息
peak_value = spectral_flatness[i];
*peak_weight = spectral_flatness[i];
*peak_position = bin_mid;
} else if (spectral_flatness[i] > secondary_peak_value) {
// 发现新的次峰
secondary_peak_value = spectral_flatness[i];
secondary_peak_weight = spectral_flatness[i];
secondary_peak_position = bin_mid;
}
}
// 峰值合并条件:距离近且权重相当
if ((fabs(secondary_peak_position - *peak_position) < 2 * bin_size) &&
(secondary_peak_weight > 0.5f * (*peak_weight))) {
*peak_weight += secondary_peak_weight; // 权重相加
*peak_position = 0.5f * (*peak_position + secondary_peak_position); // 位置平均
}
}3. 关键数据结构
3.1 PriorSignalModel(先验信号模型)
// 存储噪声检测的关键阈值参数和权重
struct PriorSignalModel {
float lrt; // 似然比检验阈值
float flatness_threshold; // 频谱平坦度阈值
float template_diff_threshold;// 频谱差异阈值
float lrt_weighting; // LRT特征权重
float flatness_weighting; // 平坦度特征权重
float difference_weighting; // 差异特征权重
};3.2 Histograms(特征直方图)
// 存储音频特征的统计直方图
class Histograms {
const std::array<int, kHistogramSize>& get_lrt() const; // LRT直方图
const std::array<int, kHistogramSize>& get_spectral_flatness() const; // 频谱平坦度直方图
const std::array<int, kHistogramSize>& get_spectral_diff() const; // 频谱差异直方图
};4. 核心方法详解
4.1 Update方法 - 模型参数更新入口
void PriorSignalModelEstimator::Update(const Histograms& histograms) {
// 步骤1:更新LRT特征阈值
bool low_lrt_fluctuations;
UpdateLrt(histograms.get_lrt(), &prior_model_.lrt, &low_lrt_fluctuations);
// 步骤2:检测频谱平坦度和频谱差异的峰值
float spectral_flatness_peak_position;
int spectral_flatness_peak_weight;
FindFirstOfTwoLargestPeaks(kBinSizeSpecFlat, histograms.get_spectral_flatness(),
&spectral_flatness_peak_position, &spectral_flatness_peak_weight);
float spectral_diff_peak_position;
int spectral_diff_peak_weight;
FindFirstOfTwoLargestPeaks(kBinSizeSpecDiff, histograms.get_spectral_diff(),
&spectral_diff_peak_position, &spectral_diff_peak_weight);
// 步骤3:特征有效性判断
const int use_spec_flat = spectral_flatness_peak_weight < 0.3f * 500 ||
spectral_flatness_peak_position < 0.6f ? 0 : 1;
const int use_spec_diff = spectral_diff_peak_weight < 0.3f * 500 ||
low_lrt_fluctuations ? 0 : 1;
// 步骤4:更新模型参数
prior_model_.template_diff_threshold = 1.2f * spectral_diff_peak_position;
prior_model_.template_diff_threshold = std::min(1.f, std::max(0.16f, prior_model_.template_diff_threshold));
// 步骤5:计算特征权重(归一化)
float one_by_feature_sum = 1.f / (1.f + use_spec_flat + use_spec_diff);
prior_model_.lrt_weighting = one_by_feature_sum;
if (use_spec_flat == 1) {
prior_model_.flatness_threshold = 0.9f * spectral_flatness_peak_position;
prior_model_.flatness_threshold = std::min(.95f, std::max(0.1f, prior_model_.flatness_threshold));
prior_model_.flatness_weighting = one_by_feature_sum;
} else {
prior_model_.flatness_weighting = 0.f; // 无效特征权重为0
}
if (use_spec_diff == 1) {
prior_model_.difference_weighting = one_by_feature_sum;
} else {
prior_model_.difference_weighting = 0.f;
}
}5. 设计亮点
-
自适应阈值调整:根据实时统计特征动态调整噪声检测阈值
-
多特征融合:结合LRT、频谱平坦度、频谱差异三个特征,提高鲁棒性
-
峰值检测与合并:智能处理直方图中的多峰情况
-
特征有效性验证:通过权重机制自动屏蔽不可靠特征
-
边界保护:所有阈值参数都限制在合理范围内
6. 典型工作流程
6.1 时序图
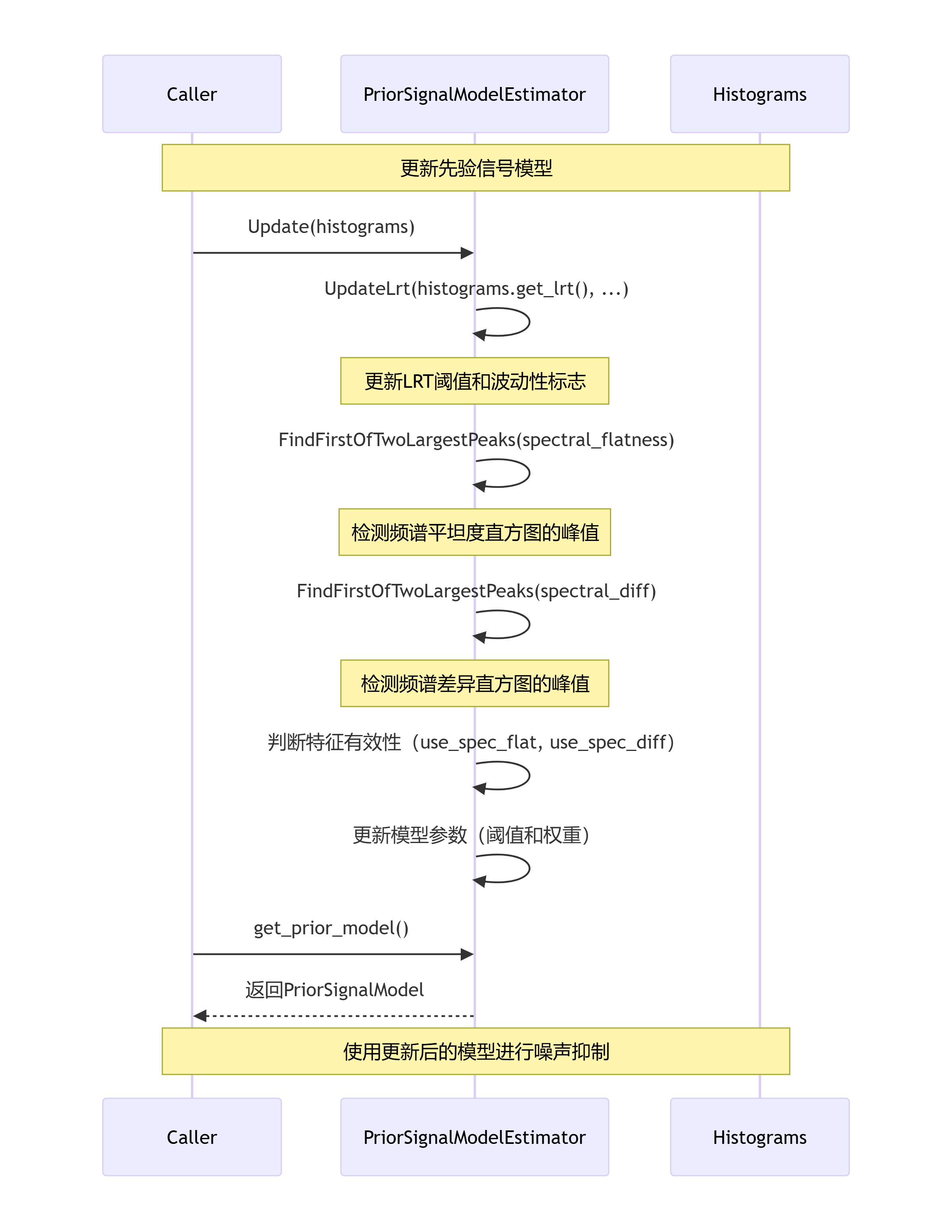
6.2 流程图
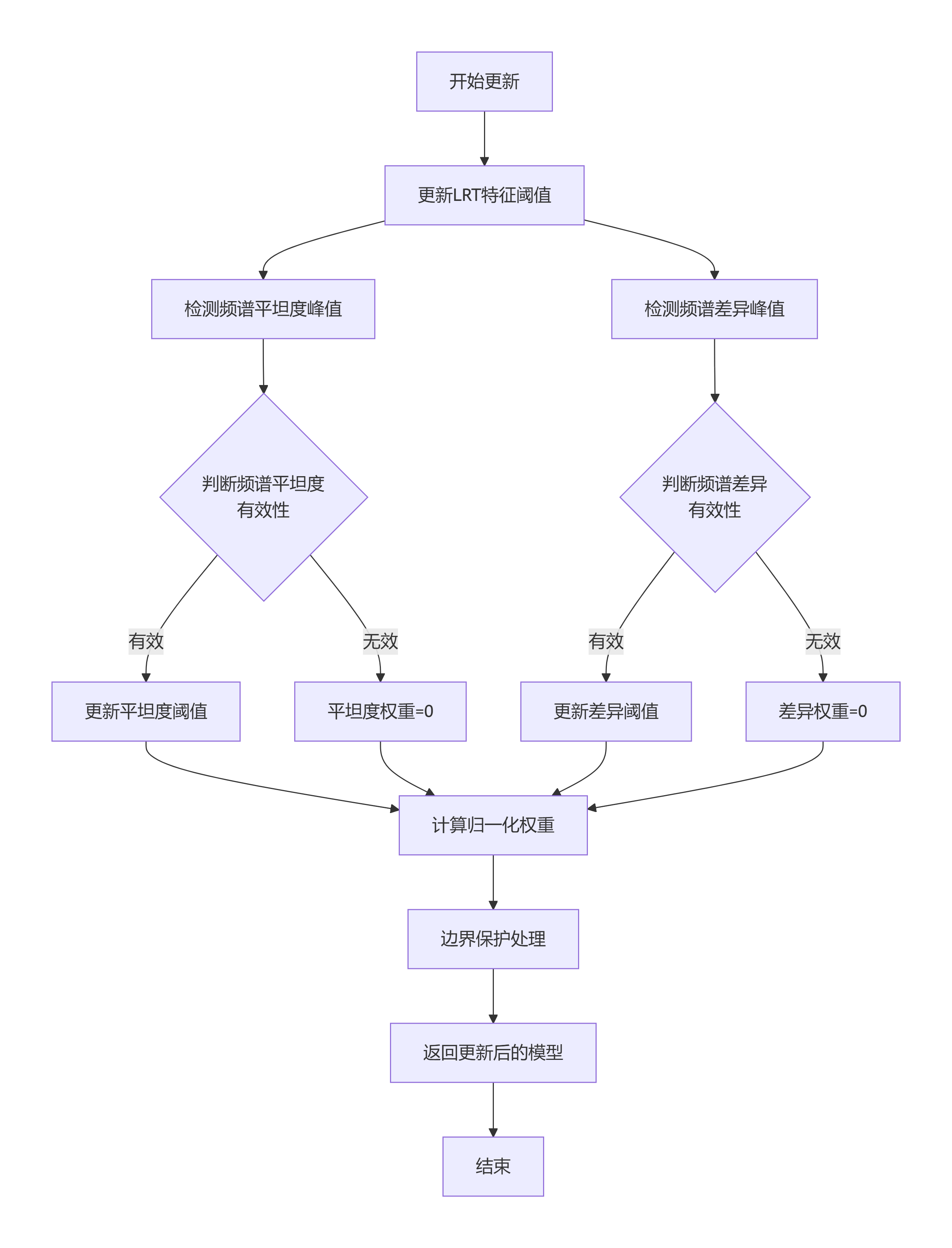
关键流程说明:
-
LRT更新:分析LRT直方图波动性,判断是否为稳定噪声状态
-
峰值检测:在频谱特征直方图中寻找主要分布模式
-
有效性验证:基于峰值权重和位置判断特征可靠性
-
权重分配:动态调整各特征在决策中的贡献度
-
边界保护:确保所有参数在合理范围内,避免极端值
这个类通过统计学习的方式,使噪声抑制系统能够自适应不同环境和音频特性,显著提高了语音增强的效果和鲁棒性。