j结合Paimon与StarRocks构建流式湖仓-实时计算 Flink版-阿里云
参考:https://blog.csdn.net/MDZ_1122333322/article/details/145651839
FLINK1.20 + FLINK CDC + MINIO3 + PAIMON1.2 + StarRocks3.5.7 + JDK11 + streampark2.1
Mysql SQL FLINK CDC 同步到 PAIMON (基于 minio)
在streampark上 创建 dwd到dws层的Flink任务
通过starrocks查询PAIMON的数据,并构建异步物化视图
在mysql中创建名称为order_dw的数据库
create database order_dw;
建表并写入数据
CREATE TABLE `orders` (
order_id bigint not null primary key,
user_id varchar(50) not null,
shop_id bigint not null,
product_id bigint not null,
buy_fee bigint not null,
create_time timestamp not null,
update_time timestamp not null default now(),
state int not null
);
CREATE TABLE `orders_pay` (
pay_id bigint not null primary key,
order_id bigint not null,
pay_platform int not null,
create_time timestamp not null
);
CREATE TABLE `product_catalog` (
product_id bigint not null primary key,
catalog_name varchar(50) not null
);
-- 准备数据
INSERT INTO product_catalog VALUES(1, 'phone_aaa'),(2, 'phone_bbb'),(3, 'phone_ccc'),(4, 'phone_ddd'),(5, 'phone_eee');
INSERT INTO orders VALUES
(100001, 'user_001', 12345, 1, 5000, '2023-02-15 16:40:56', '2023-02-15 18:42:56', 1),
(100002, 'user_002', 12346, 2, 4000, '2023-02-15 15:40:56', '2023-02-15 18:42:56', 1),
(100003, 'user_003', 12347, 3, 3000, '2023-02-15 14:40:56', '2023-02-15 18:42:56', 1),
(100004, 'user_001', 12347, 4, 2000, '2023-02-15 13:40:56', '2023-02-15 18:42:56', 1),
(100005, 'user_002', 12348, 5, 1000, '2023-02-15 12:40:56', '2023-02-15 18:42:56', 1),
(100006, 'user_001', 12348, 1, 1000, '2023-02-15 11:40:56', '2023-02-15 18:42:56', 1),
(100007, 'user_003', 12347, 4, 2000, '2023-02-15 10:40:56', '2023-02-15 18:42:56', 1);
INSERT INTO orders_pay VALUES
(2001, 100001, 1, '2023-02-15 17:40:56'),
(2002, 100002, 1, '2023-02-15 17:40:56'),
(2003, 100003, 0, '2023-02-15 17:40:56'),
(2004, 100004, 0, '2023-02-15 17:40:56'),
(2005, 100005, 0, '2023-02-15 18:40:56'),
(2006, 100006, 0, '2023-02-15 18:40:56'),
(2007, 100007, 0, '2023-02-15 18:40:56');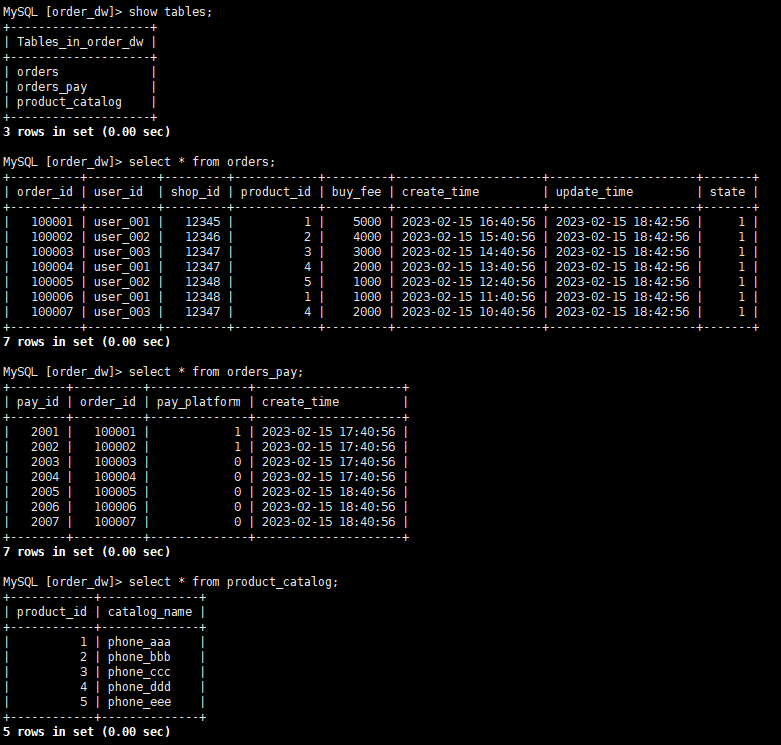
下载:
Central Repository: org/apache/paimon/paimon-flink-action/1.2.0
下载 flink-sql-connector-mysql-cdc-3.1.x.jar
Maven Repository: org.apache.flink >> flink-sql-connector-mysql-cdc >> 3.1.1
增加的主要依赖包如下:

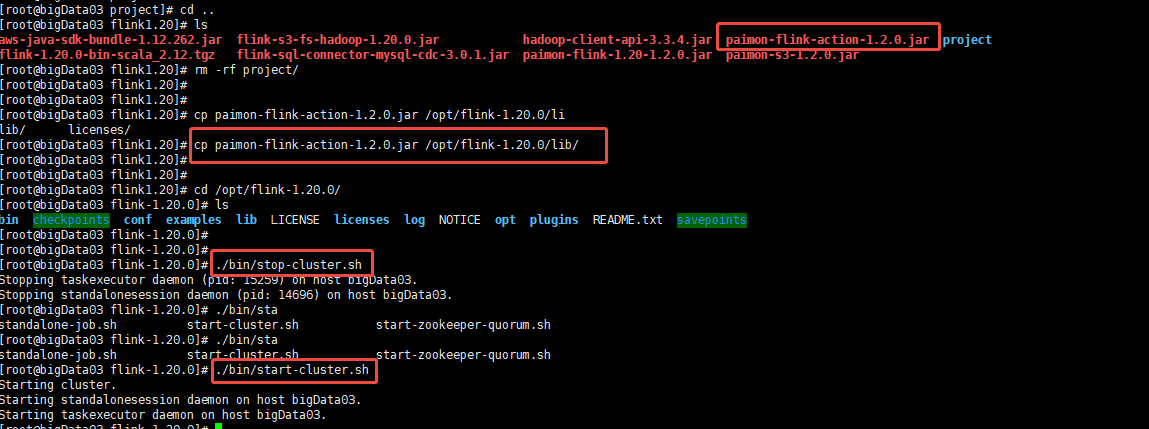
copy到flink/lib下 重启flink集群
FLINK CDC 整体 同到 PAIMON,采用 paimon-flink-action-1.2.0.jar
方式一 在flink-1.20.0所在服务期 直接提供 flink 命令
# 提交 Flink 作业
/opt/flink-1.20.0/bin/flink run \
-Dexecution.checkpointing.interval=10s \
-Dstate.checkpoints.dir=file:///tmp/flink-checkpoints \
/opt/flink-1.20.0/lib/paimon-flink-action-1.2.0.jar \
mysql_sync_database \
--warehouse s3://warehouse/wh \
--database order_dw \
--mysql_conf hostname=192.168.1.247 \
--mysql_conf port=3306 \
--mysql_conf username=root \
--mysql_conf password=123456 \
--mysql_conf database-name=order_dw \
--catalog_conf s3.endpoint=http://192.168.1.243:9000 \
--catalog_conf s3.access-key=minio \
--catalog_conf s3.secret-key=minio@123 \
--catalog_conf s3.region=us-east-1 \
--catalog_conf s3.path.style.access=true \
--table_conf bucket=1 \
--table_conf changelog-producer=input \
--table_conf sink.parallelism=1

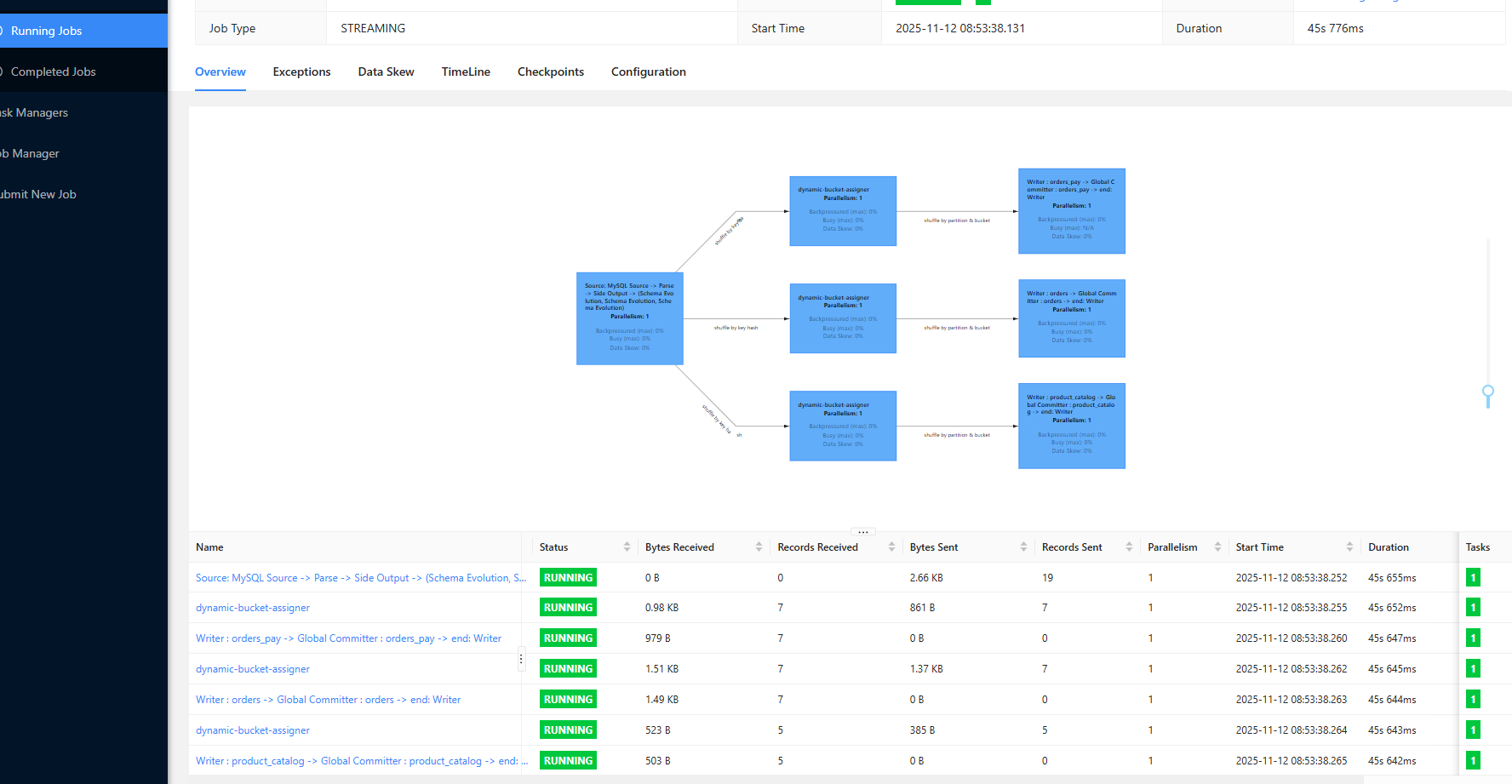
方式二 :在streampark上提交任务
参考:在streampark运行paimon-flink-action-1.20.0.jar-CSDN博客
1、上传相关jar包到streampark所在服务的 /opt/flink-1.20.0/lib

rm -rf flink-sql-connector-mysql-cdc-3.0.1.jar (要用3.1)
2、在streampark上配置任务
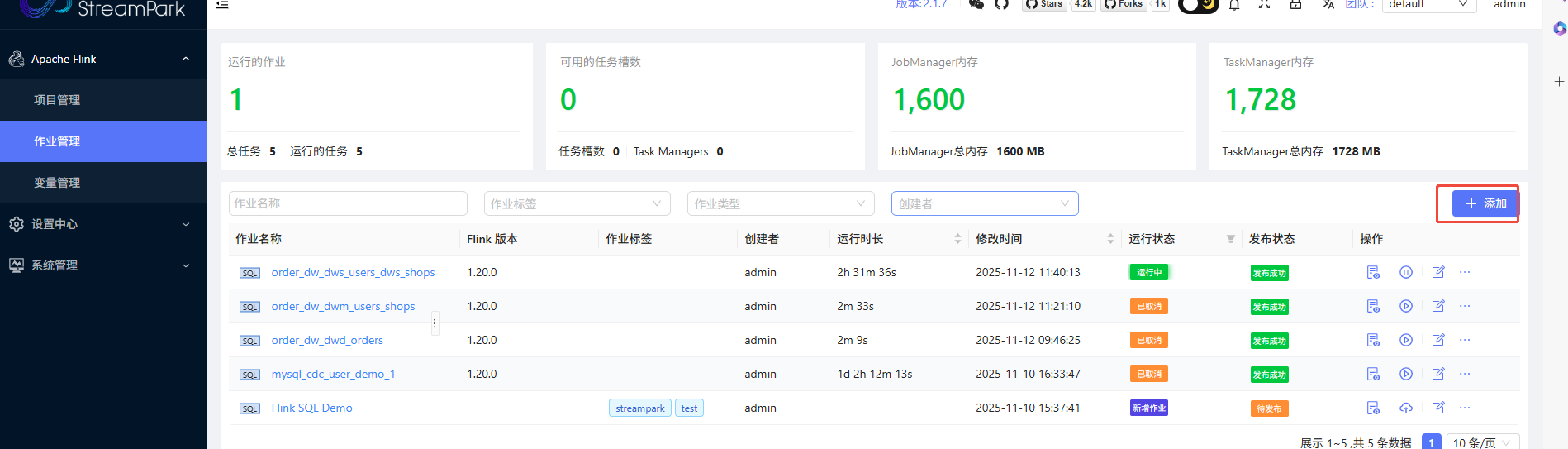
上传
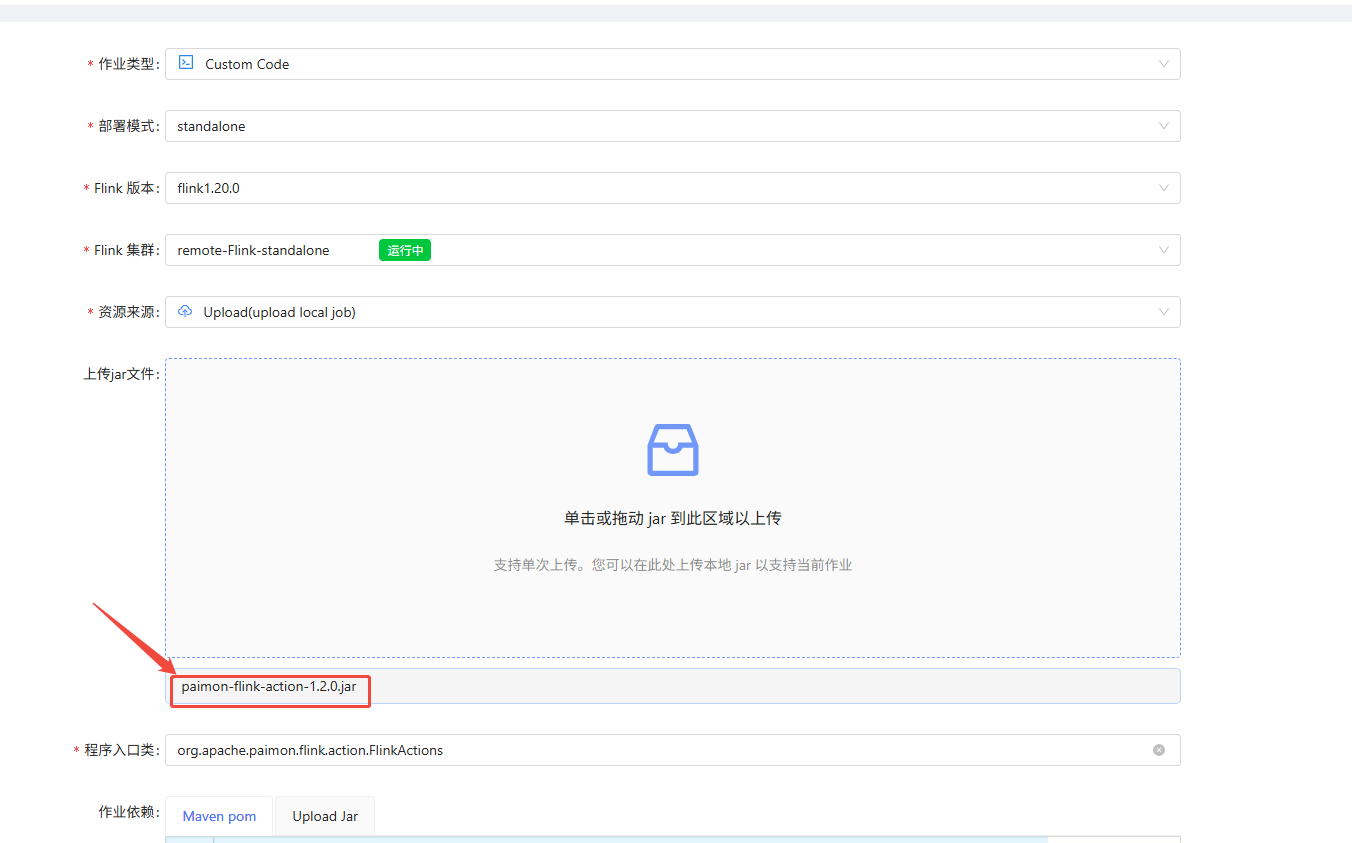

添加程序参数
mysql_sync_database
--warehouse s3://warehouse/wh
--database order_dw
--mysql_conf hostname=192.168.1.247
--mysql_conf port=3306
--mysql_conf username=root
--mysql_conf password=123456
--mysql_conf database-name=order_dw
--catalog_conf s3.endpoint=http://192.168.1.243:9000
--catalog_conf s3.access-key=minio
--catalog_conf s3.secret-key=minio@123
--catalog_conf s3.region=us-east-1
--catalog_conf s3.path.style.access=true
--table_conf bucket=1
--table_conf changelog-producer=input
--table_conf sink.parallelism=1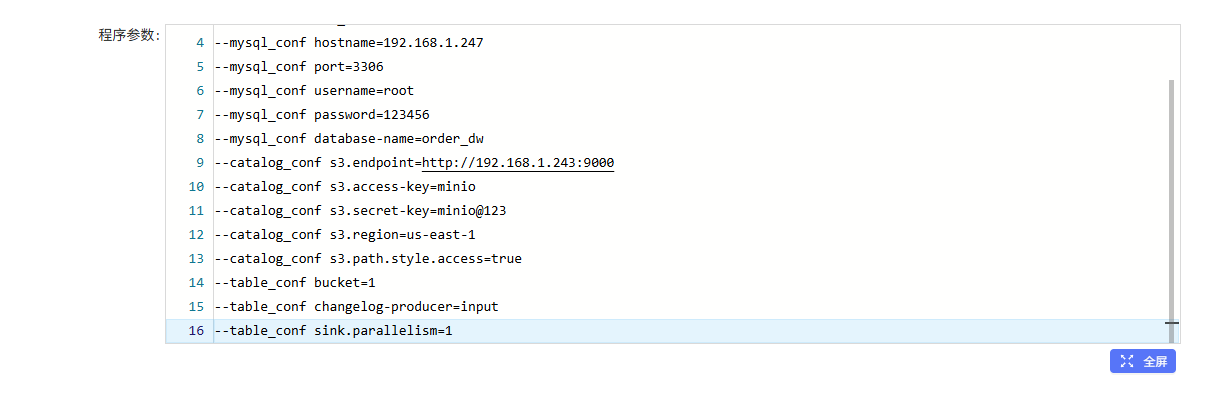
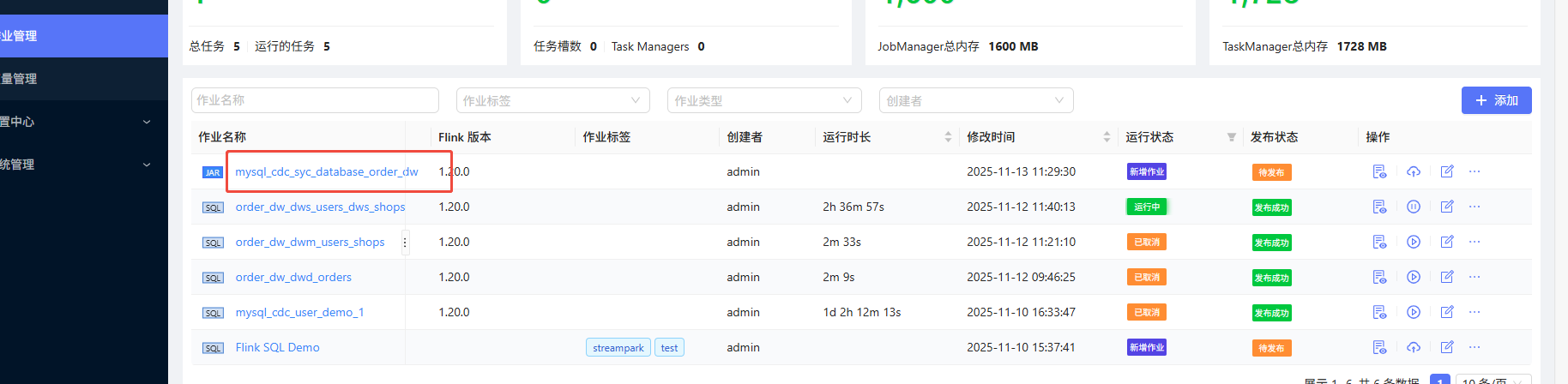
运行成功:

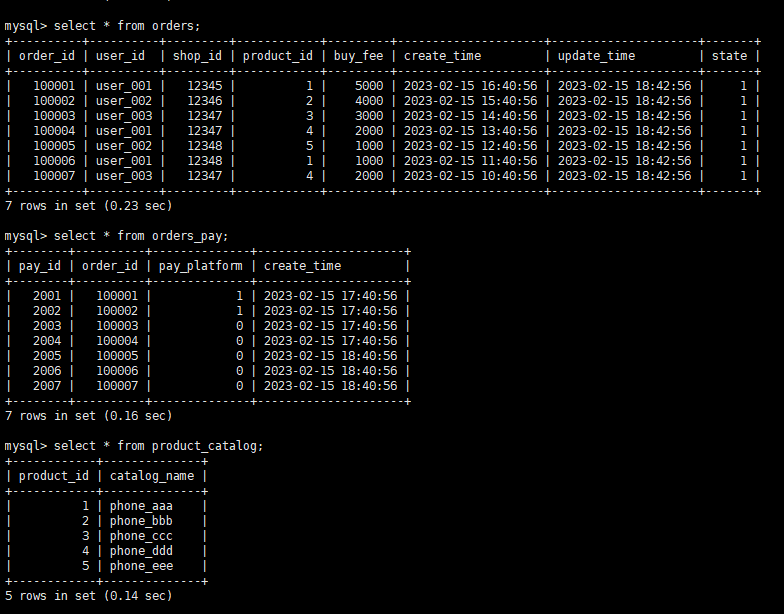
验证数据:
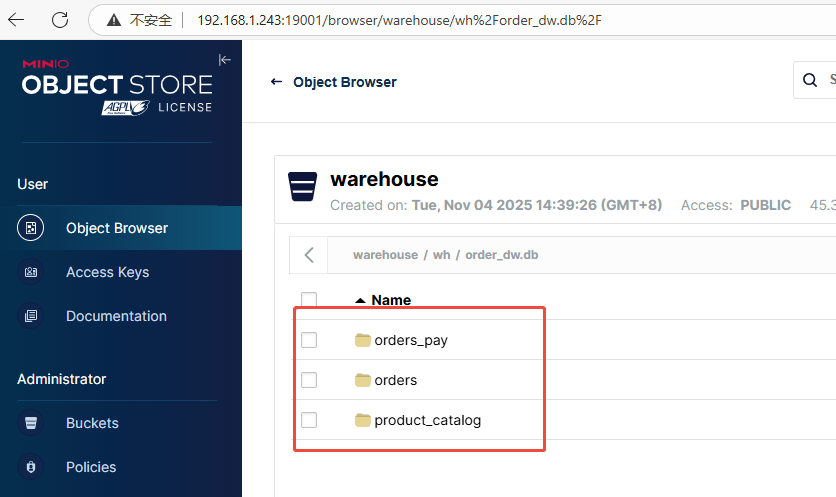
数据已经同步过来了
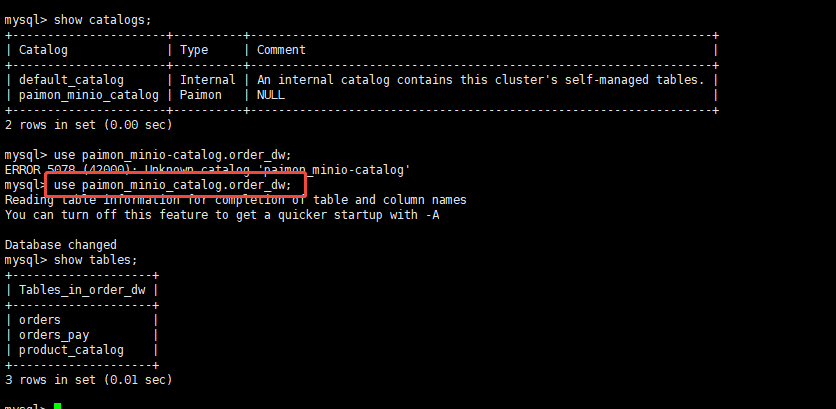
starrocks表已经有了
构建 DWD :dwd_orders
-- Step 2: ?? Paimon Catalog
CREATE CATALOG paimon_minio WITH (
'type' = 'paimon',
'warehouse' = 's3://warehouse/wh',
's3.endpoint' = 'http://192.168.1.243:9000',
's3.access-key' = 'minio',
's3.secret-key' = 'minio@123',
's3.region' = 'us-east-1',
's3.path.style.access' = 'true'
);
-- ? ??? Paimon Catalog?????
USE CATALOG paimon_minio;
CREATE TABLE IF NOT EXISTS paimon_minio.order_dw.dwd_orders (
order_id BIGINT,
order_user_id STRING,
order_shop_id BIGINT,
order_product_id BIGINT,
order_product_catalog_name STRING,
order_fee BIGINT,
order_create_time TIMESTAMP,
order_update_time TIMESTAMP,
order_state INT,
pay_id BIGINT,
pay_platform INT COMMENT 'platform 0: phone, 1: pc',
pay_create_time TIMESTAMP,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'merge-engine' = 'partial-update',
-- ????????????????
'partial-update.romove-record-on-delete' = 'true',
-- ????
'changelog-producer' = 'lookup' -- ??lookup??????????????????
);
SET
'execution.checkpointing.max-concurrent-checkpoints' = '3';
SET
'table.exec.sink.upsert-materialize' = 'NONE';
SET
'execution.checkpointing.interval' = '10s';
SET
'execution.checkpointing.min-pause' = '10s';
-- Paimon?????????????????INSERT???????????????UNION ALL?
INSERT INTO
paimon_minio.order_dw.dwd_orders
SELECT
o.order_id,
o.user_id,
o.shop_id,
o.product_id,
dim.catalog_name,
o.buy_fee,
o.create_time,
o.update_time,
o.state,
CAST(NULL AS BIGINT) AS pay_id,
CAST(NULL AS INT) AS pay_platform,
CAST(NULL AS TIMESTAMP) AS pay_create_time
FROM
(
SELECT
*,
PROCTIME() AS proctime
from
paimon_minio.order_dw.orders
) o
LEFT JOIN paimon_minio.order_dw.product_catalog FOR SYSTEM_TIME AS OF o.proctime AS dim ON o.product_id = dim.product_id
UNION ALL
SELECT
order_id,
CAST(NULL AS STRING) AS user_id,
CAST(NULL AS BIGINT) AS shop_id,
CAST(NULL AS BIGINT) AS product_id,
CAST(NULL AS STRING) AS order_product_catalog_name,
CAST(NULL AS BIGINT) AS order_fee,
CAST(NULL AS TIMESTAMP) AS order_create_time,
CAST(NULL AS TIMESTAMP) AS order_update_time,
CAST(NULL AS INT) AS order_state,
pay_id,
pay_platform,
create_time
FROM
paimon_minio.order_dw.orders_pay;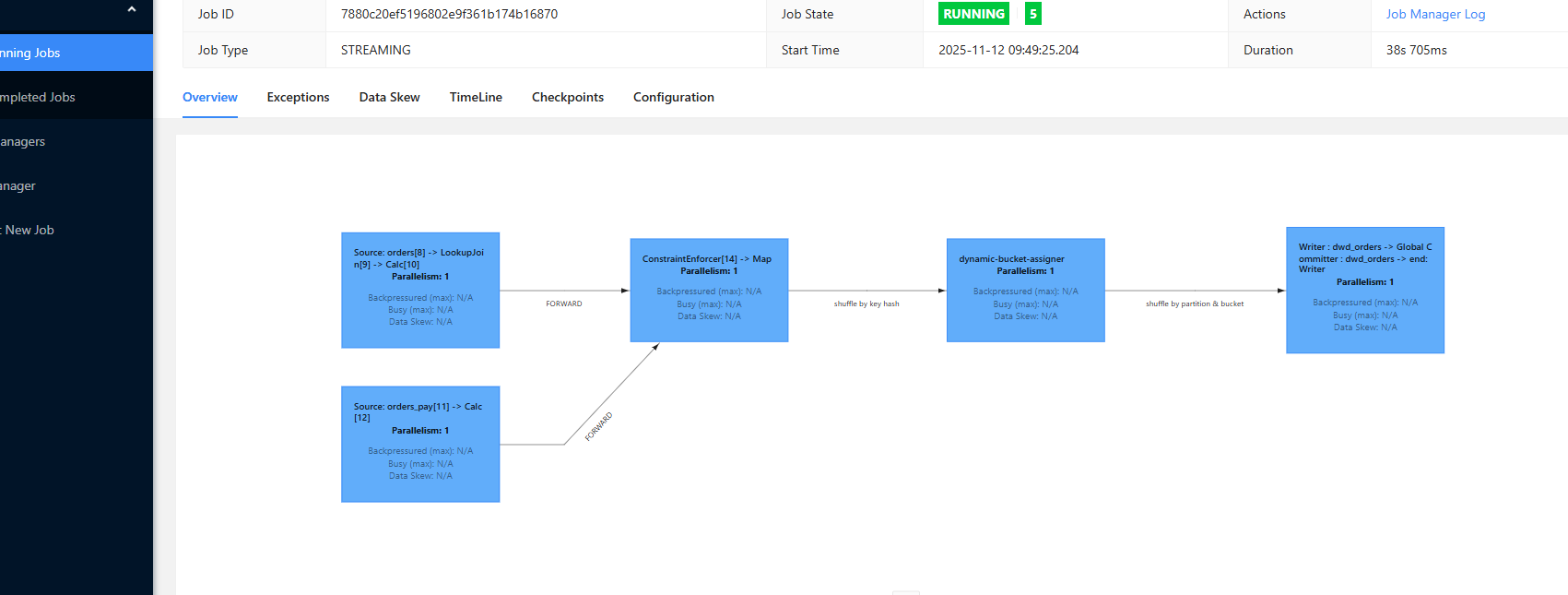
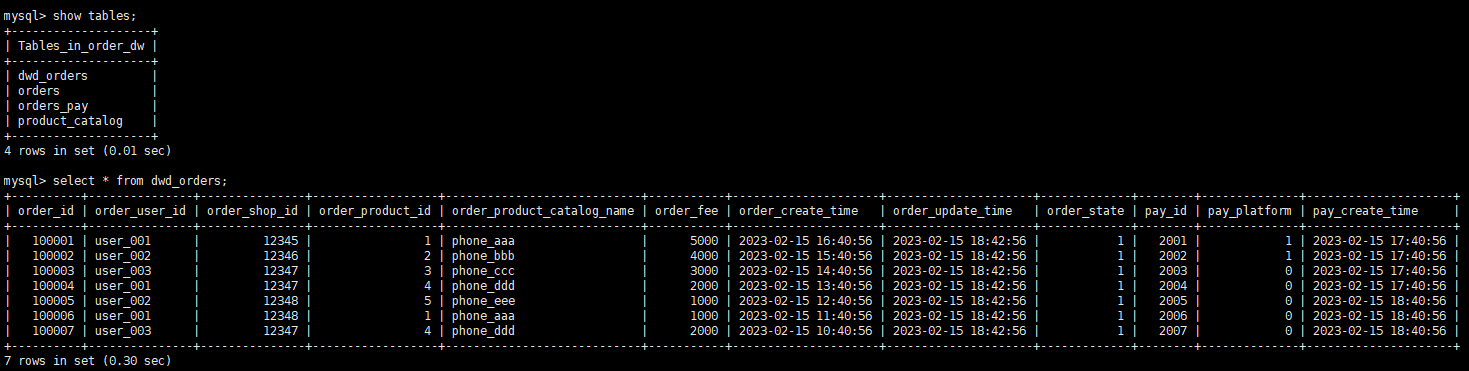
DWS
CREATE CATALOG paimon_minio WITH (
'type' = 'paimon',
'warehouse' = 's3://warehouse/wh',
's3.endpoint' = 'http://192.168.1.243:9000',
's3.access-key' = 'minio',
's3.secret-key' = 'minio@123',
's3.region' = 'us-east-1',
's3.path.style.access' = 'true'
);
USE CATALOG paimon_minio;
SET 'execution.checkpointing.max-concurrent-checkpoints' = '3';
SET 'table.exec.sink.upsert-materialize' = 'NONE';
SET 'execution.checkpointing.interval' = '10s';
SET 'execution.checkpointing.min-pause' = '10s';
-- 为了同时计算用户视角的聚合表以及商户视角的聚合表,另外创建一个以用户 + 商户为主键的中间表。
CREATE TABLE IF NOT EXISTS paimon_minio.order_dw.dwm_users_shops (
user_id STRING,
shop_id BIGINT,
ds STRING,
payed_buy_fee_sum BIGINT COMMENT '当日用户在商户完成支付的总金额',
pv BIGINT COMMENT '当日用户在商户购买的次数',
PRIMARY KEY (user_id, shop_id, ds) NOT ENFORCED
) WITH (
'merge-engine' = 'aggregation', -- 使用预聚合数据合并机制产生聚合表
'fields.payed_buy_fee_sum.aggregate-function' = 'sum', -- 对 payed_buy_fee_sum 的数据求和产生聚合结果
'fields.pv.aggregate-function' = 'sum', -- 对 pv 的数据求和产生聚合结果
'changelog-producer' = 'lookup', -- 使用lookup增量数据产生机制以低延时产出变更数据
-- dwm层的中间表一般不直接提供上层应用查询,因此可以针对写入性能进行优化。
'file.format' = 'avro', -- 使用avro行存格式的写入性能更加高效。
'metadata.stats-mode' = 'none' -- 放弃统计信息会增加OLAP查询代价(对持续的流处理无影响),但会让写入性能更加高效。
);
INSERT INTO paimon_minio.order_dw.dwm_users_shops
SELECT
order_user_id,
order_shop_id,
DATE_FORMAT (pay_create_time, 'yyyyMMdd') as ds,
order_fee,
1 -- 一条输入记录代表一次消费
FROM paimon_minio.order_dw.dwd_orders
WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL;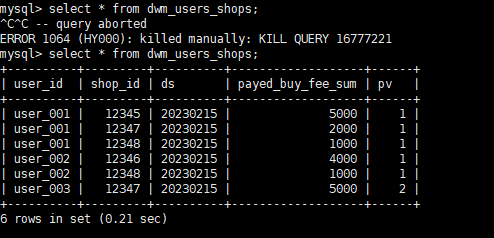
创建 dws_users 和 dws_shops
-- Step 2: ?? Paimon Catalog
CREATE CATALOG paimon_minio WITH (
'type' = 'paimon',
'warehouse' = 's3://warehouse/wh',
's3.endpoint' = 'http://192.168.1.243:9000',
's3.access-key' = 'minio',
's3.secret-key' = 'minio@123',
's3.region' = 'us-east-1',
's3.path.style.access' = 'true'
);
USE CATALOG paimon_minio;
-- 用户维度聚合指标表。
CREATE TABLE IF NOT EXISTS paimon_minio.order_dw.dws_users (
user_id STRING,
ds STRING,
payed_buy_fee_sum BIGINT COMMENT '当日完成支付的总金额',
PRIMARY KEY (user_id, ds) NOT ENFORCED
) WITH (
'merge-engine' = 'aggregation',
-- 使用预聚合数据合并机制产生聚合表
'fields.payed_buy_fee_sum.aggregate-function' = 'sum' -- 对 payed_buy_fee_sum 的数据求和产生聚合结果
-- 由于dws_users表不再被下游流式消费,因此无需指定增量数据产生机制
);
-- 商户维度聚合指标表。
CREATE TABLE IF NOT EXISTS paimon_minio.order_dw.dws_shops (
shop_id BIGINT,
ds STRING,
payed_buy_fee_sum BIGINT COMMENT '当日完成支付总金额',
uv BIGINT COMMENT '当日不同购买用户总人数',
pv BIGINT COMMENT '当日购买用户总人次',
PRIMARY KEY (shop_id, ds) NOT ENFORCED
) WITH (
'merge-engine' = 'aggregation',
-- 使用预聚合数据合并机制产生聚合表
'fields.payed_buy_fee_sum.aggregate-function' = 'sum',
-- 对 payed_buy_fee_sum 的数据求和产生聚合结果
'fields.uv.aggregate-function' = 'sum',
-- 对 uv 的数据求和产生聚合结果
'fields.pv.aggregate-function' = 'sum' -- 对 pv 的数据求和产生聚合结果
-- 由于dws_shops表不再被下游流式消费,因此无需指定增量数据产生机制
);
SET
'execution.checkpointing.max-concurrent-checkpoints' = '3';
SET
'table.exec.sink.upsert-materialize' = 'NONE';
SET
'execution.checkpointing.interval' = '10s';
SET
'execution.checkpointing.min-pause' = '10s';
INSERT INTO
paimon_minio.order_dw.dws_users
SELECT
user_id,
ds,
payed_buy_fee_sum
FROM
paimon_minio.order_dw.dwm_users_shops;
-- 以商户为主键,部分热门商户的数据量可能远高于其他商户。
-- 因此使用local merge在写入Paimon之前先在内存中进行预聚合,缓解数据倾斜问题。
INSERT INTO
paimon_minio.order_dw.dws_shops
/*+ OPTIONS('local-merge-buffer-size' = '64mb') */
SELECT
shop_id,
ds,
payed_buy_fee_sum,
1,
-- 一条输入记录代表一名用户在该商户的所有消费
pv
FROM
paimon_minio.order_dw.dwm_users_shops;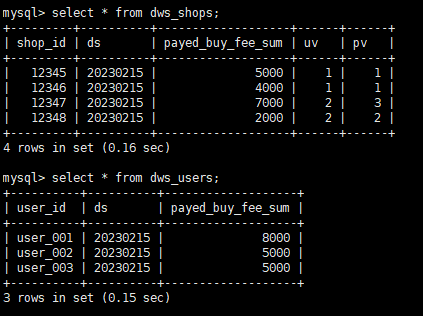
ADS层 构建物化视图
starrocks 切换会 默认的catalog;
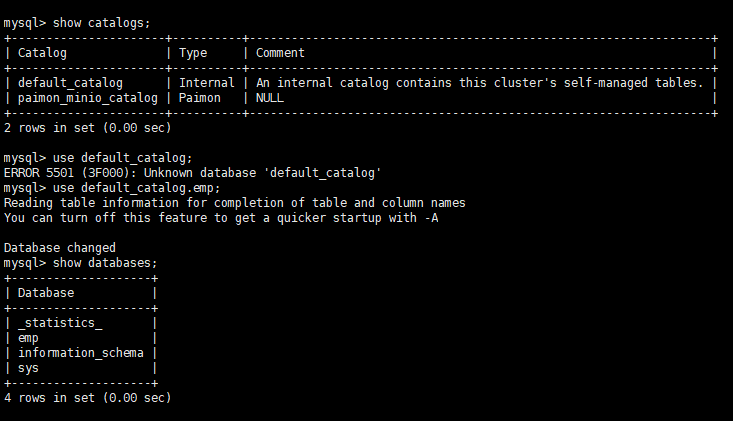
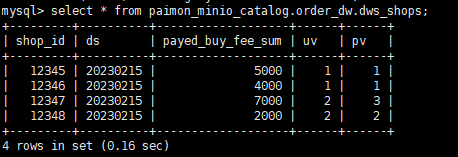
构建基于PAIMON的异步物化视图
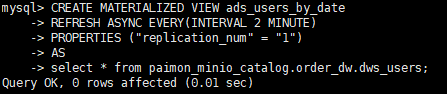
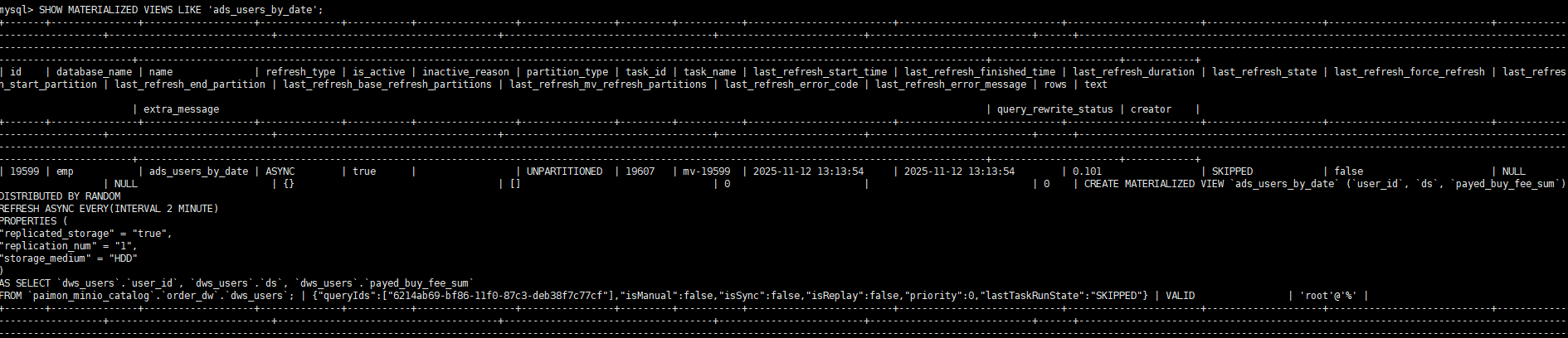
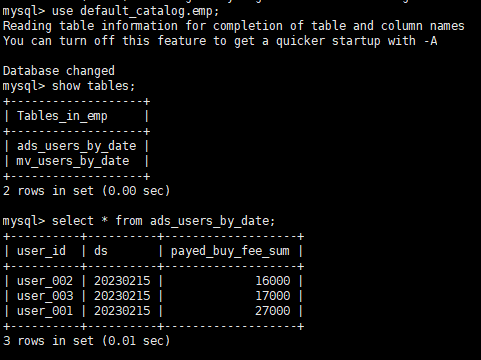
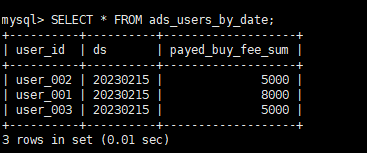
查询结果:
相关语句如下:
CREATE MATERIALIZED VIEW ads_users_by_date
REFRESH ASYNC EVERY(INTERVAL 2 MINUTE)
PROPERTIES ("replication_num" = "1")
AS
select * from paimon_minio_catalog.order_dw.dws_users;
-------------------------------------
-- 查看 MV 状态
SHOW MATERIALIZED VIEWS LIKE 'ads_users_by_date';
-- 手动刷新(可选)
REFRESH MATERIALIZED VIEW ads_users_by_date;
-- 查询结果
SELECT * FROM ads_users_by_date;1、同步任务 为 在命令行中提交的flink任务
2、分层建设任务 为在streampark上提供的3个任务
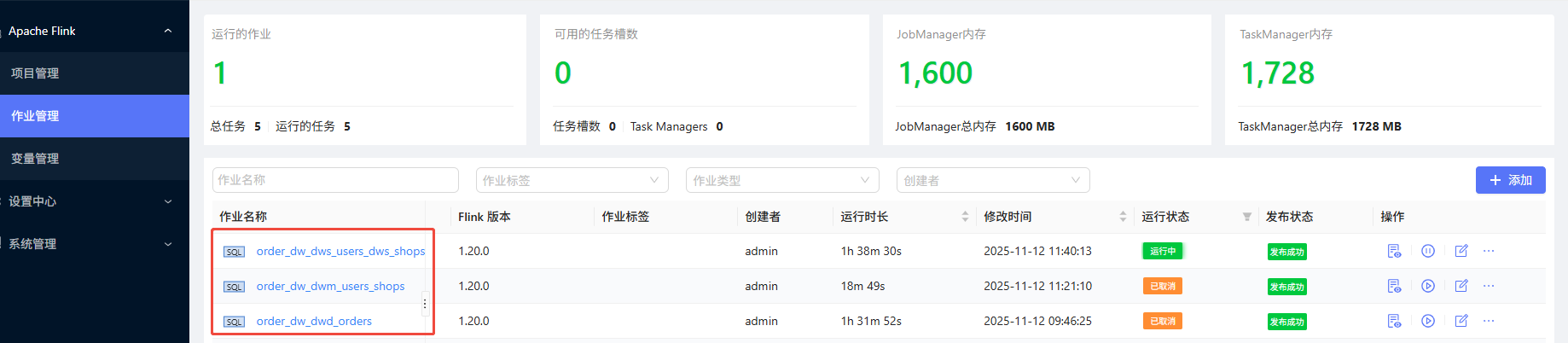
验证新数据的录入情况
捕捉业务数据库的变化
前面已完成了流式湖仓的构建,下面将测试流式湖仓捕捉业务数据库变化的能力。
PAIMON 中已有数据:

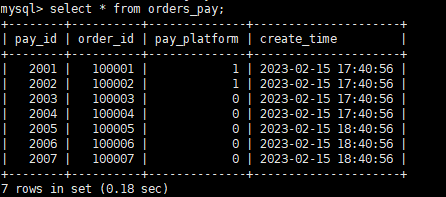

同步任务已启动。
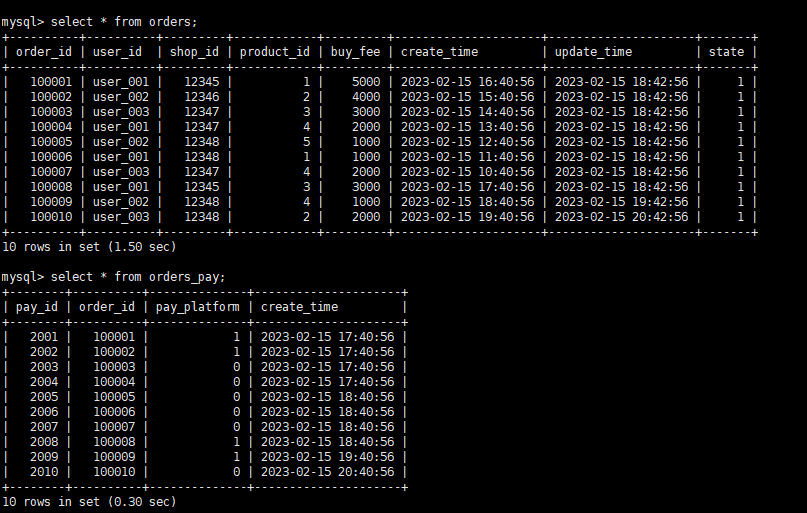
在mysql中添加数据:
INSERT INTO orders VALUES
(100008, 'user_001', 12345, 3, 3000, '2023-02-15 17:40:56', '2023-02-15 18:42:56', 1),
(100009, 'user_002', 12348, 4, 1000, '2023-02-15 18:40:56', '2023-02-15 19:42:56', 1),
(100010, 'user_003', 12348, 2, 2000, '2023-02-15 19:40:56', '2023-02-15 20:42:56', 1);
INSERT INTO orders_pay VALUES
(2008, 100008, 1, '2023-02-15 18:40:56'),
(2009, 100009, 1, '2023-02-15 19:40:56'),
(2010, 100010, 0, '2023-02-15 20:40:56');产看PAIMON中的数据
查看 dwd_orders, 数据已同步:

查看 dwm_users_shops, 数据已有变化:
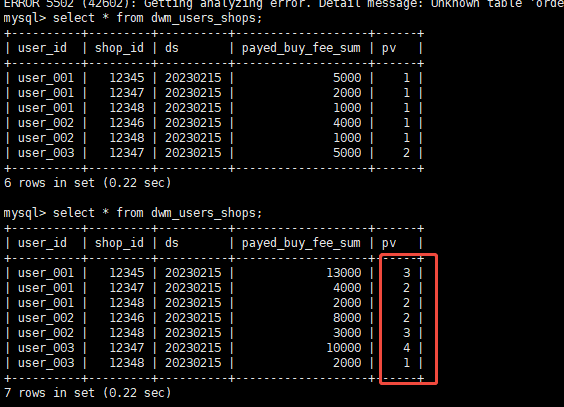
返回 查看starrocks 内部表
原有数据:
数据已更新为: