在 GPT-4 展现出惊人的多模态能力后,其技术细节的保密特性激发了科研界的探索热情。MiniGPT-4 作为一款开源的视觉 - 语言模型,通过极简的架构设计实现了与 GPT-4 相似的核心能力,为我们揭示了高级大语言模型(LLM)在多模态领域的巨大潜力。
原文链接:https://arxiv.org/pdf/2304.10592
代码链接:https://minigpt-4.github.io/
一、研究背景与核心动机
1. 多模态模型的发展现状
近年来,大语言模型(LLMs)在自然语言处理领域取得了革命性进展,从 GPT-3、ChatGPT 到 Vicuna 等开源模型,展现出强大的零样本学习、逻辑推理和自然语言生成能力。与此同时,视觉 - 语言模型(VLMs)也在快速发展,但传统模型如 BLIP-2、Kosmos-1 等受限于所采用的语言模型能力不足,难以实现复杂的多模态交互。
GPT-4 的发布改变了这一格局,它能够直接从手写文本生成网站、识别图像中的幽默元素等,但 OpenAI 并未公开其技术细节。研究团队推测,GPT-4 的强大多模态能力源于先进 LLM 与视觉特征的有效对齐,这成为 MiniGPT-4 的核心研究起点。
2. 核心研究问题
- 如何通过极简架构实现视觉特征与高级 LLM 的有效对齐?
- 仅通过少量训练数据和简单训练流程,能否复现 GPT-4 的核心多模态能力?
- 如何解决视觉 - 语言对齐过程中语言生成不自然、碎片化的问题?
3. 研究贡献
- 提出极简架构:仅通过一个投影层连接冻结的视觉编码器和冻结的高级 LLM(Vicuna),验证了 "强 LLM + 视觉对齐" 的有效性。
- 设计两阶段训练策略:解决了简单对齐导致的语言生成质量问题,大幅提升模型可用性。
- 展现丰富 emergent 能力:除了 GPT-4 演示的能力外,还实现了图像灵感创作、食谱生成、植物病害诊断等新功能。
- 开源生态:公开代码、预训练模型和数据集,为多模态研究提供重要基准。
二、模型架构:极简设计的力量
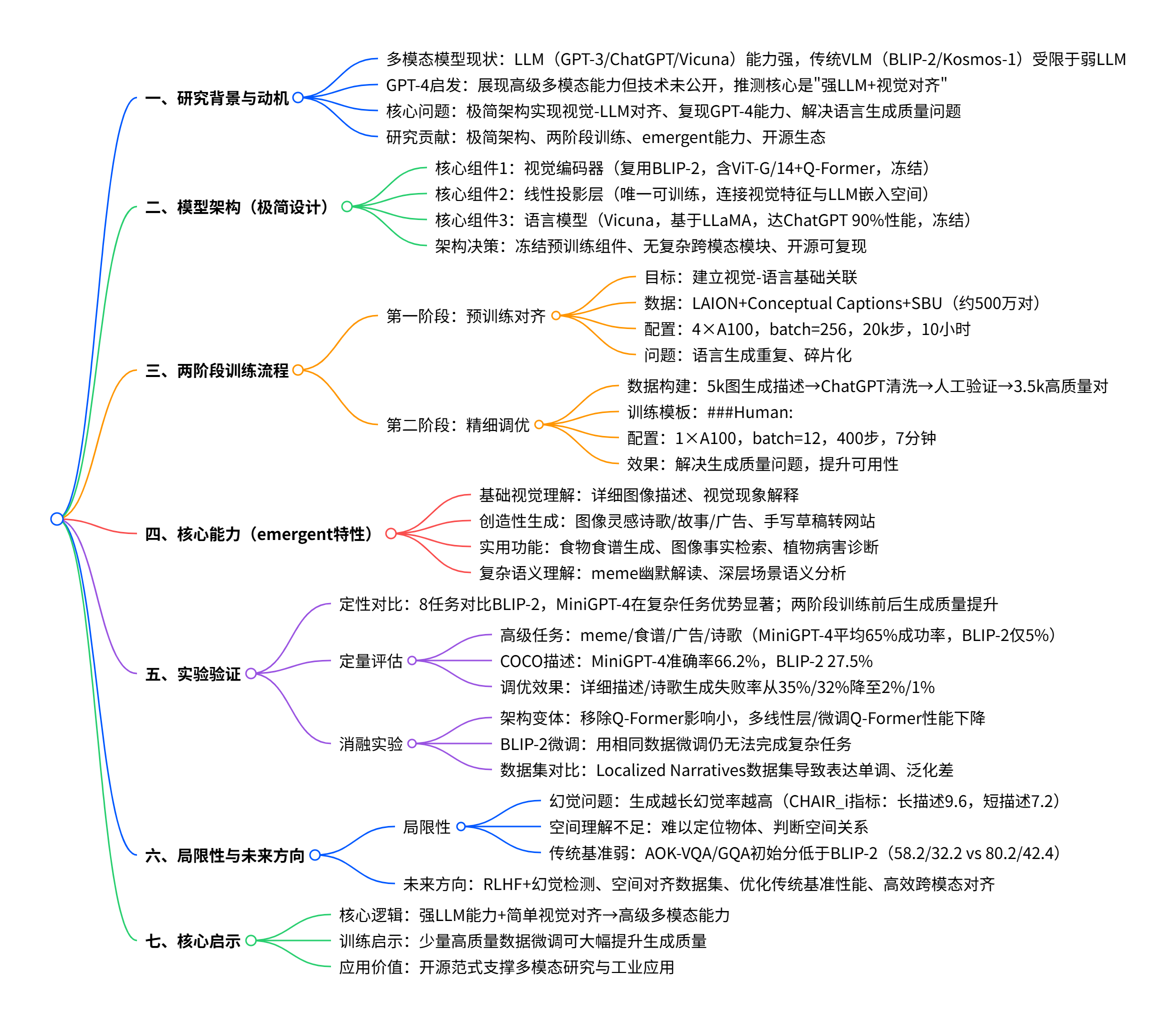
MiniGPT-4 的架构设计遵循 "极简高效" 原则,核心思路是复用现有成熟模型的能力,仅通过少量可训练参数实现视觉与语言的跨模态对齐。其整体架构如图 1 所示:
1. 三大核心组件
- 视觉编码器:直接采用 BLIP-2 的预训练视觉组件,包含 EVA-CLIP 的 ViT-G/14 骨干网络和 Q-Former。ViT-G/14 负责提取图像的视觉特征,Q-Former 则将高维视觉特征压缩为固定长度的特征向量,为后续与语言模型对齐做准备。
- 线性投影层:模型中唯一可训练的组件,起到 "桥梁" 作用。其核心功能是将 Q-Former 输出的视觉特征向量映射到 Vicuna 语言模型的嵌入空间,实现视觉与语言特征的维度匹配和语义对齐。
- 语言模型:选用 Vicuna 作为语言解码器,该模型基于 LLaMA 构建,在人类评估中达到 ChatGPT 90% 的性能。Vicuna 的强大语言理解和生成能力是 MiniGPT-4 实现复杂多模态任务的基础。
2. 架构设计的关键决策
- 冻结预训练组件:视觉编码器和语言模型均保持冻结状态,仅训练投影层。这一设计大幅降低了训练成本,同时避免了预训练模型能力的退化。
- 无额外跨模态模块:不同于 Flamingo 的门控交叉注意力机制,MiniGPT-4 放弃了复杂的跨模态交互设计,证明了简单线性投影在强 LLM 加持下的有效性。
- 组件开源可复现:所有核心组件均基于开源模型构建,确保了研究的可重复性,为后续改进提供了便利。
三、两阶段训练流程:从对齐到优化
MiniGPT-4 采用两阶段训练策略,既解决了视觉 - 语言的基础对齐问题,又通过精细调优提升了语言生成的自然度和任务适应性。
1. 第一阶段:预训练对齐
- 训练目标:建立视觉特征与语言模型的基础关联,让模型学会从图像特征生成对应的文本描述。
- 训练数据:融合 LAION、Conceptual Captions、SBU 三大图像 - 文本数据集,共包含约 500 万对样本,覆盖广泛的场景和语义。
- 训练配置:使用 4 张 A100 GPU,批量大小 256,训练 20,000 步,总训练时间约 10 小时。
- 存在问题:仅通过短文本描述对齐会导致语言生成不自然,出现重复、碎片化、内容无关等问题,类似 GPT-3 未经过指令微调前的状态。
2. 第二阶段:精细调优
为解决第一阶段的缺陷,研究团队设计了针对性的精细调优流程,核心是构建高质量的视觉 - 语言对齐数据集并采用对话式模板训练。
(1)高质量数据集构建
- 初始生成:使用第一阶段训练后的模型,对 Conceptual Captions 数据集中随机选择的 5,000 张图像生成详细描述。通过设计提示词("详细描述图像,尽可能提供多的细节")并补充 "继续" 指令(确保输出长度超过 80 词),获取初始图像 - 文本对。
- 数据清洗:利用 ChatGPT 修正生成文本中的错误,包括重复内容、碎片化句子、无意义字符等。
- 人工验证:手动过滤残留错误(如道歉类语句)并精炼文本,最终得到 3,500 对高质量图像 - 详细描述样本。
(2)调优训练细节
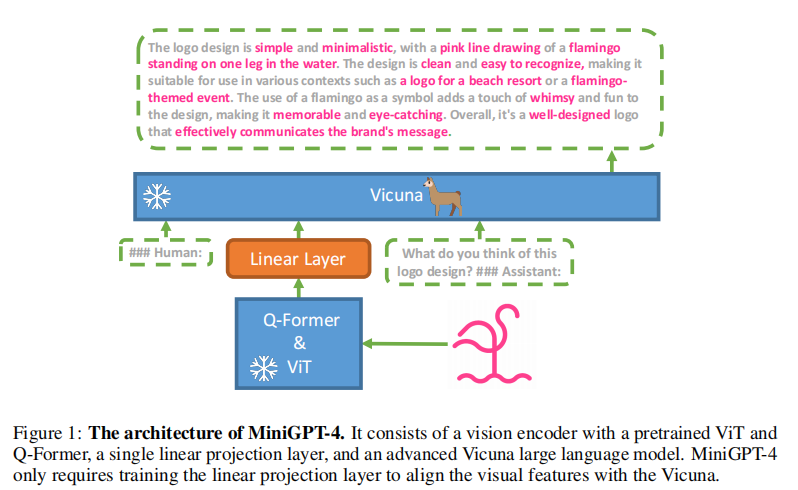
- 训练模板:采用对话式模板
 其中 Instruction 包含多种表述形式(如 "详细描述这张图像"、"能为我介绍图像内容吗"),提升模型的指令适应性。
其中 Instruction 包含多种表述形式(如 "详细描述这张图像"、"能为我介绍图像内容吗"),提升模型的指令适应性。 - 训练配置:使用 1 张 A100 GPU,批量大小 12,仅训练 400 步,总训练时间约 7 分钟,效率极高。
- 训练目标:不计算文本 - 图像提示的回归损失,重点优化语言生成的自然度和任务相关性。
3. 训练流程的核心洞察
两阶段训练的本质是 "先对齐,后优化":第一阶段解决视觉与语言的语义关联问题,第二阶段修复语言生成的质量缺陷。这种设计既保证了模型的基础能力,又通过少量高质量数据实现了性能的大幅提升,为资源有限的研究提供了高效范式。
四、核心能力:超越传统 VLM 的 emergent 特性
MiniGPT-4 通过视觉特征与高级 LLM 的有效对齐,展现出一系列传统视觉 - 语言模型不具备的 emergent 能力(涌现能力),这些能力可分为以下几类:
1. 基础视觉理解能力
- 详细图像描述:能够捕捉图像中的细枝末节,包括物体、场景、纹理、空间关系等。如图 2 所示,相比 BLIP-2 仅能描述 "城市街道、行人、摩托车" 等核心元素,MiniGPT-4 还能识别出钟楼、鹅卵石路面、装饰性建筑立面、街灯等细节,生成的描述更丰富、更精准。

- 视觉现象解释:能够理解图像中不寻常的视觉场景并给出合理解释,例如识别图像中的光学错觉、特殊天气现象等。
2. 创造性生成能力
- 基于图像的创作:能够根据图像灵感创作诗歌、故事、广告文案等。如图 3 所示,针对巨嘴鸟台灯图像,MiniGPT-4 生成了包含产品卖点、使用场景、情感价值的专业广告,而 BLIP-2 仅能简单描述物体本身。

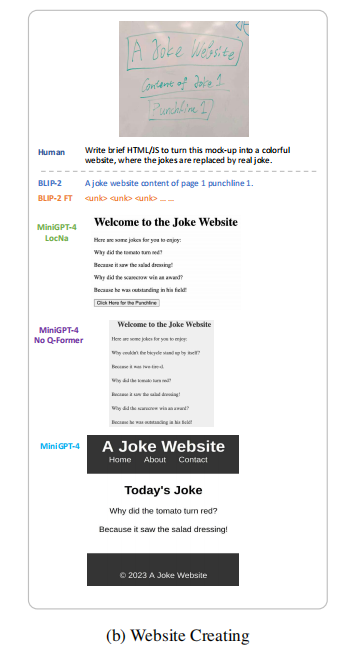
- 手写草稿转网站:能够将手写的网站草稿转换为可运行的 HTML/JS 代码。如图 4 (b) 所示,即使是潦草的手写内容,MiniGPT-4 也能准确理解布局和功能需求,生成结构完整、可交互的网站代码。
3. 实用功能能力
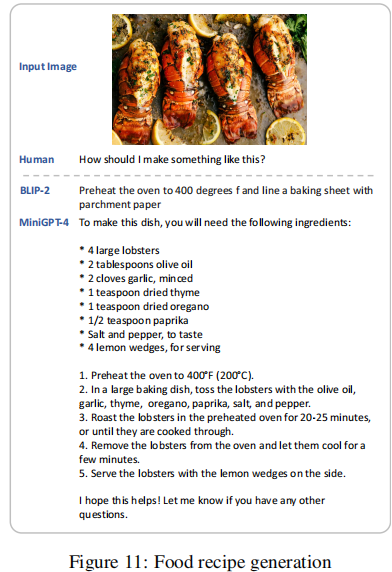
- 食谱生成:根据食物图像直接生成详细的烹饪步骤和食材清单。如图 11 所示,针对龙虾图像,MiniGPT-4 列出了具体食材、预处理步骤、烘烤温度和时间,以及食用建议,实用性远超 BLIP-2 的简单提示。
- 事实检索:从图像中识别人物、电影、艺术品等,并检索相关背景信息。如图 8 所示,针对《教父》电影海报,MiniGPT-4 准确介绍了导演、上映时间、剧情梗概、演员阵容和文化地位,而 BLIP-2 出现了导演信息错误。

- 问题诊断与解决方案:能够识别图像中展示的问题并提供专业建议。如图 12 所示,针对带有褐斑的植物叶片,MiniGPT-4 判断可能是真菌感染,并给出了识别方法、杀菌剂使用、日常养护等完整解决方案。

4. 复杂语义理解能力
- ** meme 幽默解读 **:能够理解图像中的幽默元素并解释笑点。如图 4 (a) 所示,针对 "周一的狗"meme,MiniGPT-4 准确捕捉到 "狗的慵懒状态与人类周一的疲惫感" 这一核心笑点,而 BLIP-2 仅能描述图像内容,无法理解深层语义。

这些 emergent 能力的核心来源是:高级 LLM 本身具备的语言生成、逻辑推理、知识储备能力,通过视觉 - 语言对齐被迁移到多模态场景中,形成了 "视觉理解 + 语言能力" 的组合优势。
五、实验验证:量化与定性双重证明
研究团队通过定性案例分析和定量实验,全面验证了 MiniGPT-4 的性能优势,主要分为以下几个部分:
1. 定性对比实验
选取 8 个不同任务场景,将 MiniGPT-4 与当前领先的视觉 - 语言模型 BLIP-2 进行对比。结果显示:
- BLIP-2 仅能完成简单的图像描述任务,在 meme 解读、网站生成、诗歌创作等复杂任务中表现极差,甚至无法生成有效输出。
- MiniGPT-4 在所有任务中均能生成高质量结果,尤其在需要深层语义理解和创造性生成的任务中优势显著。
如图 5 所示,对比了 MiniGPT-4 在第二阶段调优前后的表现:调优前生成的描述碎片化、不完整;调优后能够生成逻辑连贯、细节丰富的完整描述。

2. 定量评估实验
(1)高级视觉 - 语言任务评估
构建包含 4 个任务的评估数据集(每个任务 25 张图像):meme 解读、食谱生成、广告创作、诗歌创作。邀请人类 evaluator 判断模型输出是否满足任务要求,结果如下表所示:

数据显示,MiniGPT-4 在高级任务中的平均成功率达到 65%,远超 BLIP-2 的 5%。其中诗歌创作任务表现最佳(80% 成功率),meme 解读任务因需要更强的文化语境理解,成功率相对较低但仍远优于 BLIP-2。
(2)COCO 图像描述评估
采用 ChatGPT 作为评估工具,判断模型生成的描述是否覆盖了真实标签中的所有物体和视觉关系。结果如下表所示:
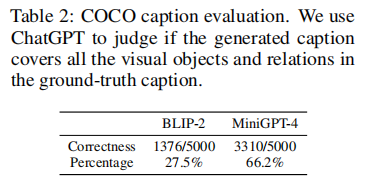
MiniGPT-4 的准确率达到 66.2%,是 BLIP-2(27.5%)的 2.4 倍,证明其在视觉信息捕捉的完整性和准确性上具有显著优势。
(3)调优效果量化
对比第二阶段调优前后,模型在详细描述和诗歌生成任务中的失败率:

调优后模型的失败率大幅下降至 2% 以下,证明第二阶段的高质量数据微调对提升生成可靠性至关重要。
3. 消融实验
为验证架构设计和训练策略的有效性,研究团队进行了三组消融实验:
(1)架构变体实验
对比不同架构设计在 AOK-VQA 和 GQA 数据集上的表现:

结果表明:
- 移除 Q-Former 后性能变化不大,说明 Q-Former 在高级 LLM 加持下并非必需组件。
- 增加线性层数量会导致性能下降,证明单投影层已足够完成视觉 - 语言对齐。
- 微调 Q-Former 会损害性能,因为预训练的 Q-Former 已适配视觉特征提取,额外微调会破坏其原有能力。
(2)BLIP-2 微调实验
使用 MiniGPT-4 的第二阶段数据集微调 BLIP-2(记为 BLIP-2 FT),结果显示 BLIP-2 FT 仍无法完成复杂任务,仅能生成简短输出。这证明高级 LLM 是实现复杂视觉 - 语言能力的核心,而非微调数据。
(3)不同数据集对比实验
用 Localized Narratives 数据集替换自构建数据集进行第二阶段调优(记为 MiniGPT-4 LocNa),结果显示:
- MiniGPT-4 LocNa 能生成长篇描述,但表达单调重复。
- 在 meme 解读等复杂任务中泛化能力差,证明数据集的质量和多样性对模型性能至关重要。
六、局限性与未来方向
1. 主要局限性
(1)幻觉问题
MiniGPT-4 继承了 LLM 的幻觉特性,会生成图像中不存在的内容。如图 6 所示,模型错误地声称餐厅场景中有 "白色桌布",且无法正确定位窗户位置。

通过 CHAIR_i 指标量化幻觉率:
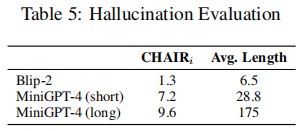
结果表明,生成文本越长,幻觉率越高,这为需要精准描述的场景带来挑战。
(2)空间信息理解不足
模型在处理空间关系、物体定位等任务时表现薄弱,难以准确回答 "窗户在照片左侧吗" 这类空间查询。这主要是因为训练数据中缺乏专门针对空间信息的对齐样本。
(3)传统基准任务表现一般
在 AOK-VQA 和 GQA 等传统视觉问答基准上,MiniGPT-4 的原始性能低于 BLIP-2:

这是因为 MiniGPT-4 的设计目标是复现 GPT-4 的高级能力,而非优化传统基准任务。研究团队通过解冻 LLM 并增加训练数据,将 AOK-VQA 分数提升至 67.2,GQA 提升至 43.5,证明其性能有较大优化空间。
2. 未来研究方向
- 引入 AI 反馈强化学习(RLHF)和幻觉检测模块,降低生成幻觉率。
- 增加空间信息对齐数据集(如 RefCOCO、Visual Genome),提升空间理解能力。
- 优化训练策略,平衡高级能力与传统基准任务性能。
- 探索更高效的跨模态对齐方式,进一步提升模型的交互性和实时性。
七、总结与启示
MiniGPT-4 以极简的架构设计和高效的训练流程,验证了 "强 LLM + 视觉对齐" 的多模态模型发展路径。其核心启示在于:高级 LLM 本身具备的强大语言能力和推理能力,通过简单的视觉 - 语言对齐即可迁移到多模态领域,产生丰富的 emergent 能力。
模型的成功并非依赖复杂的跨模态模块,而是源于对现有成熟模型能力的充分复用和精准对齐。两阶段训练策略则为解决 "对齐质量" 与 "生成自然度" 的矛盾提供了有效方案,少量高质量数据的微调就能带来显著的性能提升。
作为开源模型,MiniGPT-4 不仅为科研人员提供了研究多模态能力的重要工具,也为工业界开发多模态应用提供了高效范式。尽管模型仍存在幻觉、空间理解不足等问题,但它为我们指明了多模态模型的核心发展方向 ------ 未来的视觉 - 语言模型将更加依赖于 LLM 的能力提升,而跨模态对齐则会趋向于更简洁、更高效的设计。