文章目录
-
- 一、引言
- 二、时序数据的核心概念
-
- [1. 数据点(Data Point)](#1. 数据点(Data Point))
- [2. 测点(Measurement / Time Series)](#2. 测点(Measurement / Time Series))
- [3. 设备(Device)](#3. 设备(Device))
- [三、IoTDB 的两种时序数据模型详解](#三、IoTDB 的两种时序数据模型详解)
-
- [3.1 树模型(Tree Model)------面向监控的灵活路径体系](#3.1 树模型(Tree Model)——面向监控的灵活路径体系)
-
- [3.1.1 模型结构](#3.1.1 模型结构)
- [3.1.2 创建与写入示例(CLI 或 JDBC)](#3.1.2 创建与写入示例(CLI 或 JDBC))
- [3.1.3 优化技巧](#3.1.3 优化技巧)
- [3.1.4 适用场景](#3.1.4 适用场景)
- [3.2 表模型(Table Model)------面向分析的标准 SQL 体系](#3.2 表模型(Table Model)——面向分析的标准 SQL 体系)
-
- [3.2.1 模型结构](#3.2.1 模型结构)
- [3.2.2 创建与操作示例](#3.2.2 创建与操作示例)
- [3.2.3 优势](#3.2.3 优势)
- 四、大数据场景下的建模实战
- 五、总结与最佳实践
一、引言
随着物联网(IoT)、工业互联网、智能交通、智慧能源等领域的迅猛发展,全球每天产生数以亿计的传感器数据。这些数据具有典型的时间序列特征:高频率采集、强时间相关性、设备维度丰富、写多读少或读写并重。传统关系型数据库在处理此类数据时面临写入性能瓶颈、存储成本高、查询效率低下等问题。
Apache IoTDB 是一款专为时序数据设计的高性能数据库,由清华大学发起并成为 Apache 顶级项目。它针对工业和物联网场景优化了存储引擎、压缩算法和查询语言,在大规模时序数据管理中表现出色。尤其在大数据背景下,IoTDB 提供了树模型 与表模型两种互补的建模范式,支持从边缘设备接入到云端分析的全链路数据治理。
本文将系统阐述 IoTDB 的时序数据模型原理,并结合真实业务场景,通过具体代码示例,详细说明如何在大数据环境下进行高效、可扩展、易维护的时序数据建模。全文内容超过2000字,涵盖理论、实践与最佳实践建议。
官网下载

二、时序数据的核心概念
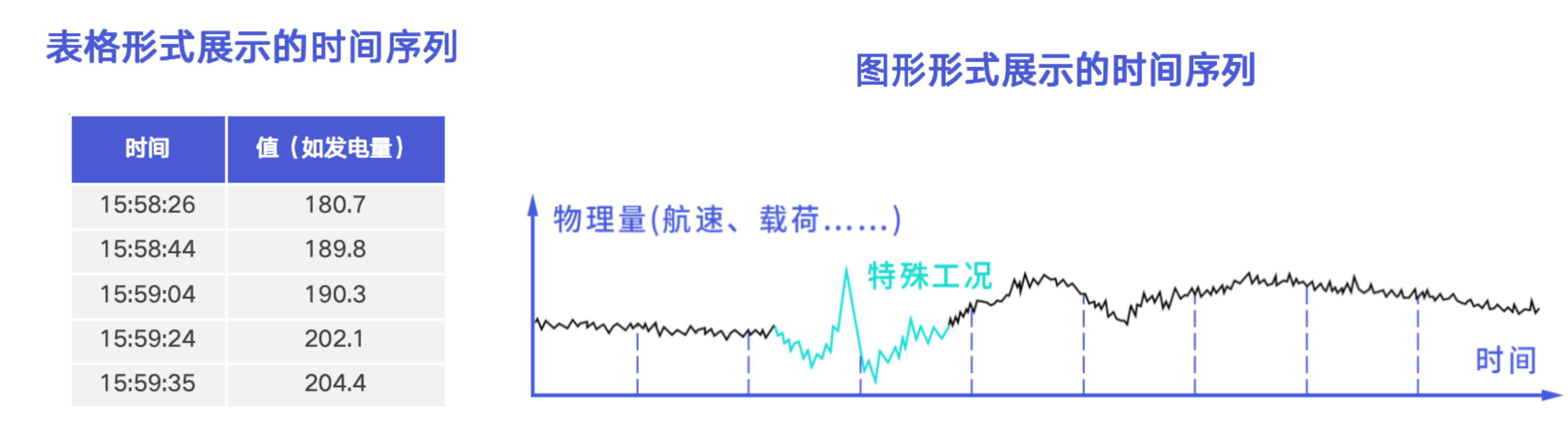
在 IoTDB 中,时序数据建模围绕三个核心层级展开:
1. 数据点(Data Point)
- 定义:一个时间戳(long 类型) + 一个数值(支持 BOOLEAN、INT32、FLOAT、DOUBLE、TEXT 等)。
- 示例 :
(1719283200000, 23.5)表示 2024-06-25 00:00:00 的温度为 23.5℃。
2. 测点(Measurement / Time Series)
- 定义:多个按时间递增排列的数据点构成一条时间序列。
- 别名:物理量、指标、信号量、时间线。
- 示例 :
voltage、rpm、gps_longitude。
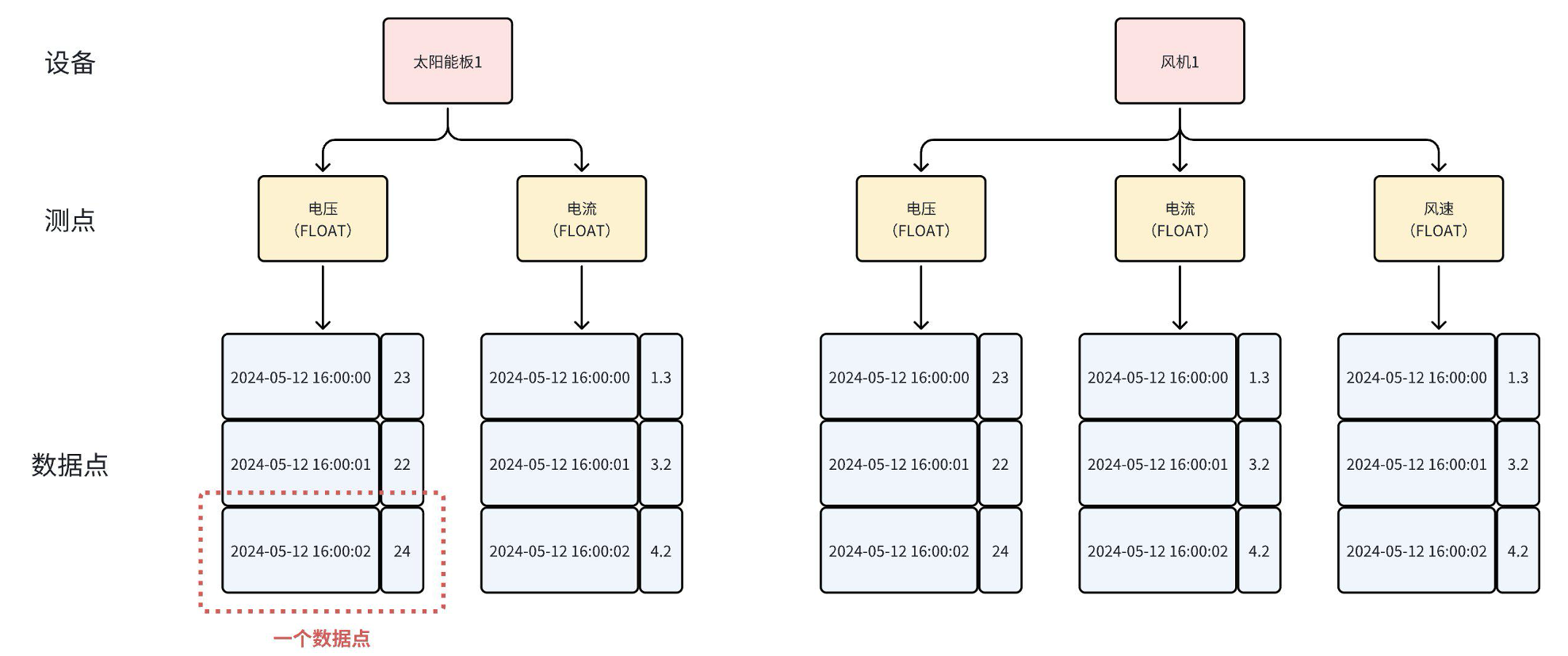
3. 设备(Device)
- 定义:现实世界中的物理实体,是测点的容器,通常由一组标签唯一标识。
- 示例 :
- 车辆:VIN = "VIN123456789"
- 风机:region="North", station="WindFarmA", turbine_id="T001"
这三层结构构成了 IoTDB 建模的逻辑基础,也是后续树模型与表模型设计的出发点。
三、IoTDB 的两种时序数据模型详解
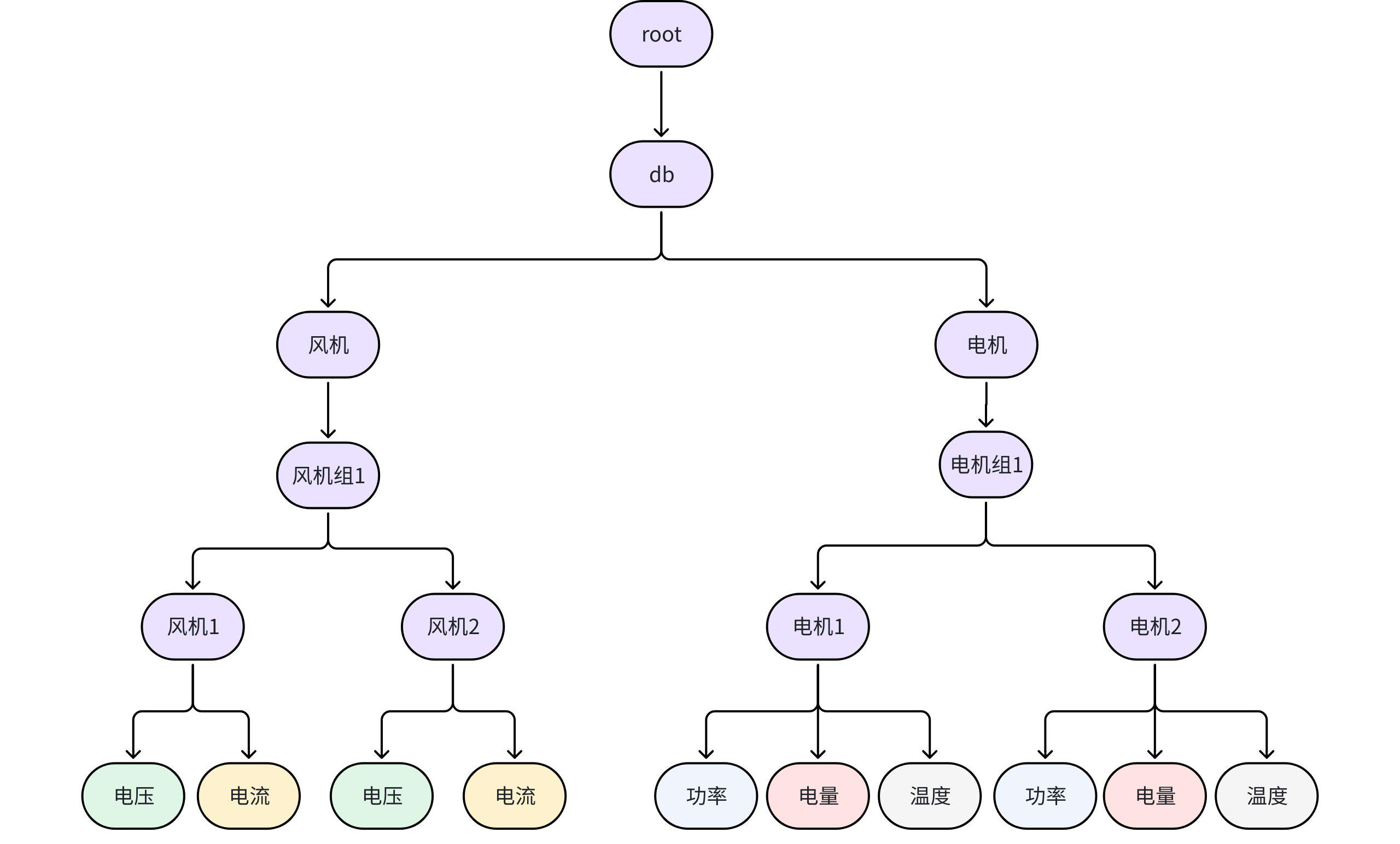
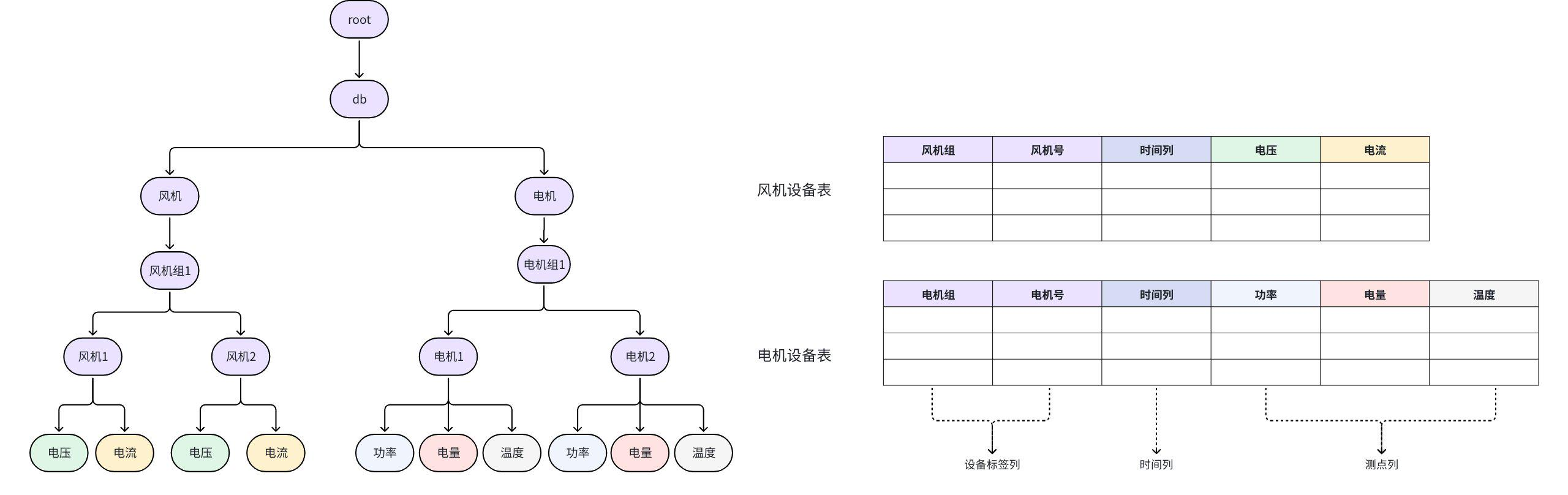
3.1 树模型(Tree Model)------面向监控的灵活路径体系
3.1.1 模型结构
树模型采用类似文件系统的路径结构,以 root. 为根节点,通过 . 分隔形成层级目录。例如:
text
root.factory.line1.robotA.joint1.temperature
root.factory.line1.robotA.camera.status
root.energy.region01.stationB.turbine002.power每条路径对应一个独立的时间序列,其倒数第二层默认视为"设备"。
3.1.2 创建与写入示例(CLI 或 JDBC)
sql
-- 创建数据库(可选,写入时自动创建)
SET STORAGE GROUP TO root.factory;
-- 写入数据(自动创建时间序列)
INSERT INTO root.factory.line1.robotA.joint1 (time, temperature) VALUES (1719283200000, 23.5);
INSERT INTO root.factory.line1.robotA.joint1 (time, temperature) VALUES (1719283260000, 24.1);
-- 查询
SELECT temperature FROM root.factory.line1.robotA.joint1 WHERE time >= 1719283200000;3.1.3 优化技巧
-
设备层扩充 :若设备少但测点多,添加
.value层:textroot.db.device01.metric001.value -
特殊字符处理 :使用反引号包裹含空格或符号的节点:
sqlINSERT INTO root.db.`device name`(time, `temp °C`) VALUES (1719283200000, 25.0);
3.1.4 适用场景
- 工业 SCADA/DCS 系统
- 边缘设备动态上报
- 设备结构异构、无法统一 schema
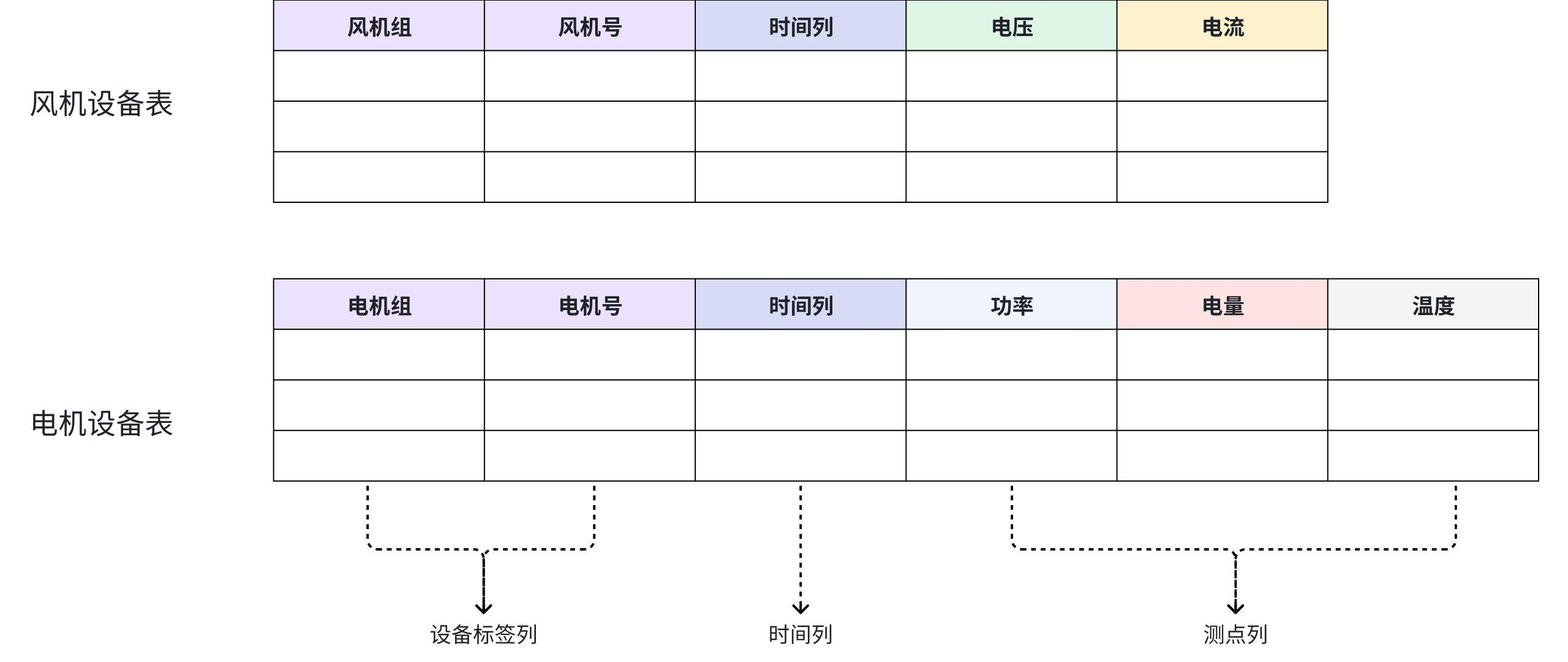
3.2 表模型(Table Model)------面向分析的标准 SQL 体系
3.2.1 模型结构
表模型以"时序表"为核心,每张表代表一类设备,包含四类列:
| 列类型 | 说明 | 是否可变 |
|---|---|---|
| TIME | 时间戳,必须为 time 列 |
固定 |
| TAG | 设备标识(联合主键),如 VIN、区域 | 不可修改 |
| ATTRIBUTE | 静态属性,如厂商、安装日期 | 可新增/更新 |
| FIELD | 动态测点,如温度、电压 | 随时间变化 |
3.2.2 创建与操作示例
sql
-- 创建时序表
CREATE TIMESERIES TABLE vehicle_data (
time TIMESTAMP,
vin STRING TAG,
city STRING TAG,
model STRING TAG,
manufacturer STRING ATTRIBUTE,
battery_type STRING ATTRIBUTE,
speed FLOAT FIELD,
soc FLOAT FIELD, -- State of Charge
mileage INT32 FIELD,
gps_lat DOUBLE FIELD,
gps_lon DOUBLE FIELD
);
-- 插入数据
INSERT INTO vehicle_data(time, vin, city, model, manufacturer, battery_type, speed, soc, mileage, gps_lat, gps_lon)
VALUES
(1719283200000, 'VIN123', 'Beijing', 'ModelX', 'Tesla', 'LFP', 65.2, 82.3, 12500, 39.9042, 116.4074),
(1719283260000, 'VIN123', 'Beijing', 'ModelX', 'Tesla', 'LFP', 68.0, 82.1, 12501, 39.9050, 116.4080);
-- 查询:北京地区平均电量
SELECT avg(soc) FROM vehicle_data WHERE city = 'Beijing' AND time >= 1719283200000;
-- 按车型分组统计最大速度
SELECT model, max(speed) FROM vehicle_data GROUP BY model;⚠️ 注意:使用表模型需在连接时指定
sql_dialect=table:
javaProperties props = new Properties(); props.setProperty("sql_dialect", "table"); Connection conn = DriverManager.getConnection("jdbc:iotdb://127.0.0.1:6667/", props);
3.2.3 优势
- 支持标准 SQL,兼容 BI 工具(如 Grafana、Superset)
- 标签列自动建立索引,筛选效率高
- 便于数据治理与权限控制
四、大数据场景下的建模实战
场景一:百万级风机监控(树模型)
需求:某风电集团管理 10 万台风机,每台含 200+ 测点,需实时监控异常。
建模路径设计:
text
root.wind.region{1..10}.farm{A..Z}.turbine{00001..10000}.{metric}例如:
text
root.wind.region3.farmK.turbine05678.rpm
root.wind.region3.farmK.turbine05678.power_active批量写入代码(Java SDK 示例):
java
Session session = new Session("127.0.0.1", 6667);
session.open();
List<String> paths = Arrays.asList(
"root.wind.region3.farmK.turbine05678.rpm",
"root.wind.region3.farmK.turbine05678.power_active"
);
List<Long> times = Arrays.asList(System.currentTimeMillis());
List<List<String>> values = Arrays.asList(
Arrays.asList("1250", "2300.5")
);
List<TSDataType> types = Arrays.asList(TSDataType.INT32, TSDataType.FLOAT);
session.insertRecordsOfOneDevice("root.wind.region3.farmK.turbine05678", times, paths, types, values);
session.close();优势:路径天然表达设备归属,查询某场站所有风机功率只需:
sql
SELECT power_active FROM root.wind.region3.farmK.**场景二:车联网数据分析(表模型)
需求:分析不同城市电动车的能耗与续航表现。
建模与分析:
sql
-- 创建表
CREATE TIMESERIES TABLE ev_telemetry (
time TIMESTAMP,
vin STRING TAG,
city STRING TAG,
brand STRING TAG,
battery_capacity_kwh FLOAT ATTRIBUTE,
soc FLOAT FIELD,
speed FLOAT FIELD,
odometer INT32 FIELD
);
-- 计算百公里电耗(kWh/100km)
SELECT
city,
brand,
(max(odometer) - min(odometer)) / 1000.0 AS distance_km,
(first_value(soc) - last_value(soc)) * avg(battery_capacity_kwh) / 100.0 AS consumption_kwh_per_100km
FROM ev_telemetry
WHERE time >= now() - 7d
GROUP BY city, brand;场景三:双模型融合------智能制造工厂
架构设计:
- 写入层:边缘网关使用树模型上报原始数据;
- 分析层:构建表视图进行 OEE(设备综合效率)计算。
步骤:
-
树模型写入:
sqlINSERT INTO root.plant.a.line1.machine01 (time, status, cycle_time) VALUES (1719283200000, 'RUNNING', 12.5); -
创建表视图(IoTDB 1.3+ 支持):
sqlCREATE VIEW machine_oee AS SELECT time, 'line1' AS line TAG, 'machine01' AS machine_id TAG, status FIELD, cycle_time FIELD FROM root.plant.a.line1.machine01; -
分析查询:
sqlSELECT machine_id, count_if(status = 'RUNNING') * 1.0 / count(*) AS availability FROM machine_oee WHERE time >= now() - 1d GROUP BY machine_id;
优势:一份数据,两种视角,兼顾灵活性与分析力。
五、总结与最佳实践
| 维度 | 树模型 | 表模型 | 双模型 |
|---|---|---|---|
| 写入性能 | 极高(无 schema 约束) | 高(需预定义) | 高 |
| 查询灵活性 | 路径通配符强大 | SQL 标准丰富 | 两者兼得 |
| 数据治理 | 弱(需人工规范) | 强(schema 管控) | 中 |
| 适用规模 | 百万+ 时间序列 | 十万+ 设备 | 大型复杂系统 |
推荐策略:
- 边缘/现场层:用树模型,快速接入异构设备;
- 平台/分析层:用表模型,构建数据仓库;
- 混合架构:通过视图或 ETL 实现模型转换。
IoTDB 的双模型设计,使其在大数据时代既能应对海量设备的高并发写入,又能支撑复杂的业务分析需求,是工业数字化转型的理想时序数据底座。