本文介绍了 Zalando 如何通过引入路由服务器(RouteSRV)帮助 Skipper Ingress 应对高速增长的流量,以更有效管理控制平面并确保集群稳定运行的实践。原文:Scaling Beyond Limits: Harnessing Route Server for a Stable Cluster
简介
在 Zalando,我们正面临严峻挑战:入口控制器有可能使 Kubernetes 集群不堪重负。我们需要能够应对不断增长的流量并实现高效扩展的解决方案,本文将介绍我们如何实现路由服务器以更有效管理控制平面流量并确保集群稳定运行的实践。
Skipper:Ingress 控制器
我们用 Skipper(HTTP 反向代理)来实现 ubernetes Ingress 和 RouteGroups 的控制平面和数据平面。创建 Ingress 或 RouteGroup 将会产生带有 TLS 终止功能的 AWS LB,该 LB 会通过 kube-ingress-aws-controller 与 Skipper 进行通信,同时在 Skipper 上设置 HTTP 路由,并通过 external-dns 将 DNS 域名指向该 LB。
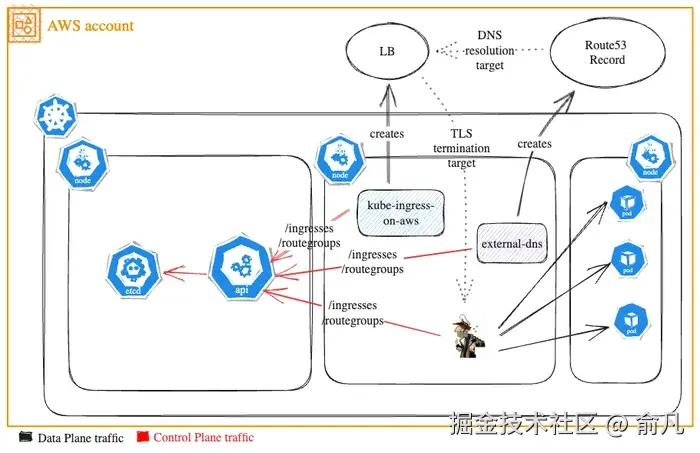
为了理解部署环境,以下是我们的实际运行规模:
- 15,000 个 Ingress 和 5,000 个 RouteGroup。
- 每秒处理高达 2,000,000 次请求的流量。
- 80% - 90% 的流量是经过认证的服务间调用,服务集群每天调用次数在 500,000 到 1,000,000 次。
- 共有 200 个 Kubernetes 集群。
挑战
扩容的痛点
Skipper 实例从 Kubernetes API 获取 Ingress 和 RouteGroups 信息,起初这种方式运行良好。但 Skipper 实例数量迅速增加,达到每个集群约 180 个,开始超出 etcd 基础设施的承载能力。
这种负载过重导致了严重的 Kubernetes API CPU 限流问题,引发了关键的控制平面稳定性风险。主要表现为两种情况:集群失去了有效调度新 Pod 的能力,而现有 Pod 的管理操作也开始出现故障。这些问题威胁到了 Kubernetes 基础设施的整体稳定性和可靠性。
实施路由服务器
在引入路由服务器之前,Skipper 的职责包括:
- 从 Kubernetes API 获取 Ingress 和 RouteGroups 信息。
- 解析并处理这些资源以转换为 Eskip 格式。
- 验证生成的 Eskip 格式。
- 更新路由表。
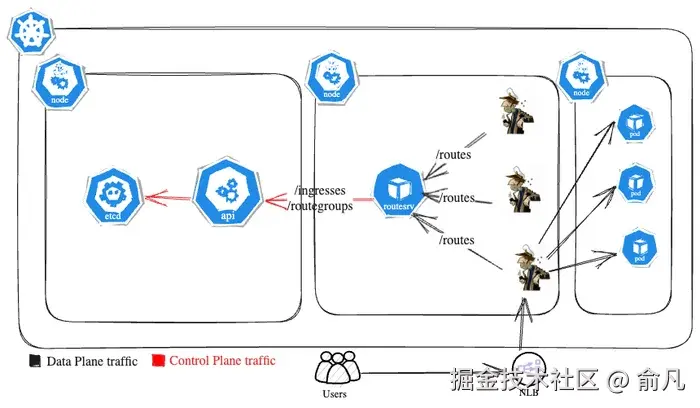
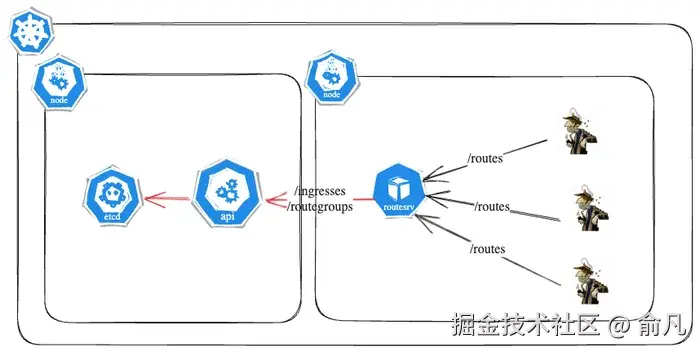
我们引入路由服务器作为自定义代理层,以更高效处理控制平面流量,并在 Skipper 与 Kubernetes API 服务器之间充当带有 HTTP ETag 缓存层的代理。
现在,路由服务器负责执行轮询和解析操作,减少了 Skipper 的计算负担,同时实现了清晰的职责划分。
缓存层
路由服务器每隔 3 秒向 Kubernetes API 发送一次请求,以获取最新的 Ingress 和 RouteGroup。然后生成路由表以及相应的 ETag 值。当 Skipper 向路由服务器请求更新时,会包含自己当前的 ETag。如果这个 ETag 与路由服务器当前的 ETag 相匹配,表示没有变化,路由服务器会以 HTTP 304 (Not Modified) 状态码进行响应。然而,如果 ETag 不同,路由服务器会将更新后的路由表发送给 Skipper,然后 Skipper 会更新其本地配置以及 ETag。
路由服务器不可用
尽管路由服务器极大提高了系统效率,但也必须考虑到可能出现的故障情况。当路由服务器不可用时,有以下两种可能的情况:
- Skipper 没有初始路由表。
- Skipper 有初始路由表,但路由服务器无法更新。
在第一种情况下,如果启用了 -wait-first-route-load 标志,那么 Skipper 容器将无法启动。在第二种情况下,Skipper 将继续使用最后已知的路由表。这是在可用性和一致性之间做出的权衡。
在这两种情况下,我们都会收到告警,并且需要决定是修复路由服务器,还是将其禁用,然后让 Skipper 在没有路由服务器的情况下继续运行。目前,我们还没有自动切回旧方法的机制。
集成路由服务器后的最终流程如下:
部署策略
部署路由服务器并非易事,哪怕出现一个错误,也可能导致 Kubernetes API 与 Skipper 的连接中断,从而可能影响销售业绩和商品交易总额(GMV)。我们必须极其谨慎,并遵循完善的部署策略。
我们计划以可控的方式逐步部署路由服务器,先从测试集群开始,生产集群则被分为不同的层级,路由服务器逐层部署,每部署完一层都会进行监控,然后再进行下一层部署。
为了实现这一目标,我们为部署路由服务器制定了不同的设置模式:
- 模式:False - 禁用模式
- 模式:Pre - 预处理模式
- 模式:Exec - 执行模式
这些模式通过配置项进行控制。
默认模式为 false,意味着路由服务器已被禁用,此时就用常规的控制平面流量。
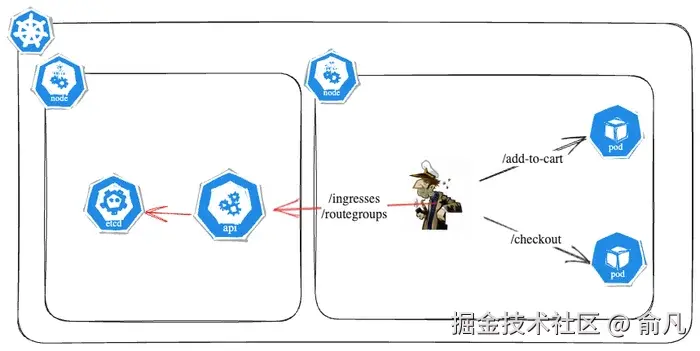
预处理模式
在该模式下,路由服务器与 Skipper 协同工作,从 Kubernetes API 获取 Ingress 和 RouteGroup,并对其进行预处理。此模式适用于测试和调试,也是我们推出策略的关键因素。
通过成功获取 Skipper 和路由服务器的路由表,并将其与原表进行对比,以确保路由服务器运行正常。要知道,如果路由表因为某种原因出现故障,就会导致服务中断。这就是为什么必须格外谨慎,检查所有集群中路由表的任何细微差异。
perl
# 用非常大的 limit 获取所有 Skipper 路由
➜ curl -i http://127.0.0.1:9911/routes\?limit\=10000000000000\&nopretty > skipper_routes.eskip
# 获取路由服务器的所有路由,我们决定不使用分页来减少请求数量,Skipper 是目前唯一的消费者
➜ curl -i http://127.0.0.1:9090/routes > routesrv_routes.eskip
➜ git diff --no-index -- skipper_routes.eskip routesrv_routes.eskip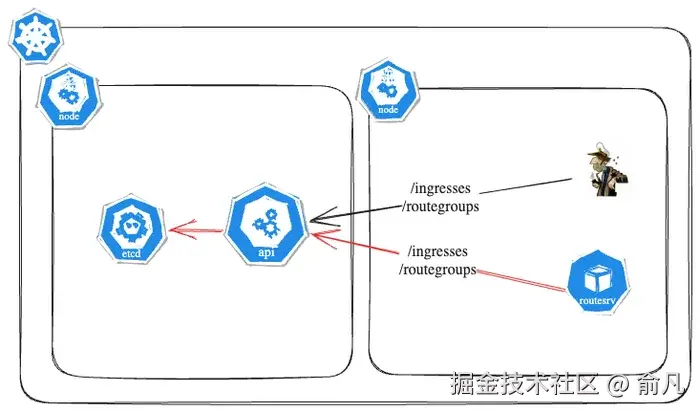
执行模式
在该模式下,路由服务器充当 Skipper 与 Kubernetes API 之间的代理。Skipper 向路由服务器发送请求,然后路由服务器再将这些请求转发至 Kubernetes API。路由服务器会缓存响应并将其返回给 Skipper。此模式是用于生产环境的最终设置。
产品上线
经过全面的负载测试后,我们以可控的方式将路由服务器投入生产使用:
- 已分发至所有测试集群,并进行了为期两周的监测。
- 逐层部署到生产集群,每部署一层都会对其进行监测,然后继续进行下一层部署。
替代方案
我们曾考虑使用 Kubernetes Informer 来监视 Kubernetes API 的变化。然而,这种方法仍需要 Kubernetes API 向所有 Skipper 实例发送信息,可能会导致遇到的同样的问题。因为问题的本质是流量突然增加,而 HPA 无法跟上并扩展 Kubernetes API 和 etcd。
未来改进措施
- 自动回退机制:建立回退机制,以确保在路由服务器不可用的情况下,Skipper 仍能继续运行。
总结
- 在上线过程中实现了零停机时间且未出现商品交易总额(GMV)损失的情况。
- 将 Skipper HPA 扩展至 300 个 Pod。
- 单个路由服务器能够处理高达 100 个每秒请求数(RPS),相当于约 300 个 Skipper Pod,且没有任何问题。
- 路由服务器现已成为平台核心组件。
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。为了方便大家以后能第一时间看到文章,请朋友们关注公众号"DeepNoMind",并设个星标吧,如果能一键三连(转发、点赞、在看),则能给我带来更多的支持和动力,激励我持续写下去,和大家共同成长进步!