
「【新智元导读】就在 OpenAI 刚刚教会 GPT-5.1 人情世故的同一天,一款 2.4 万亿的国产大模型证明了,AI 不仅能懂人情,还能更好地理解世界。」
2.4 万亿参数,原生全模态模型今天杀到了!
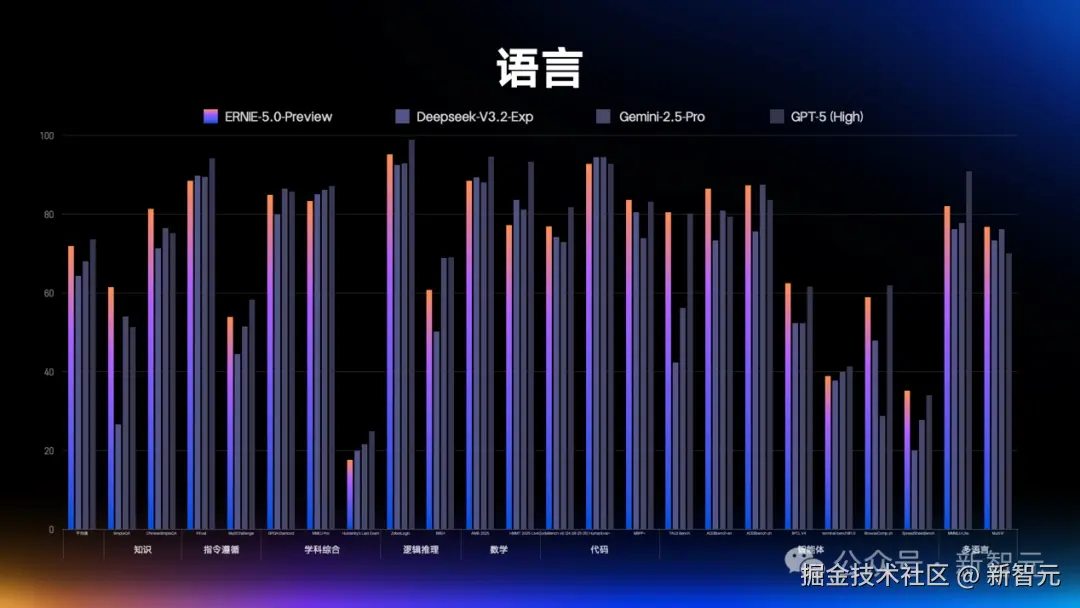
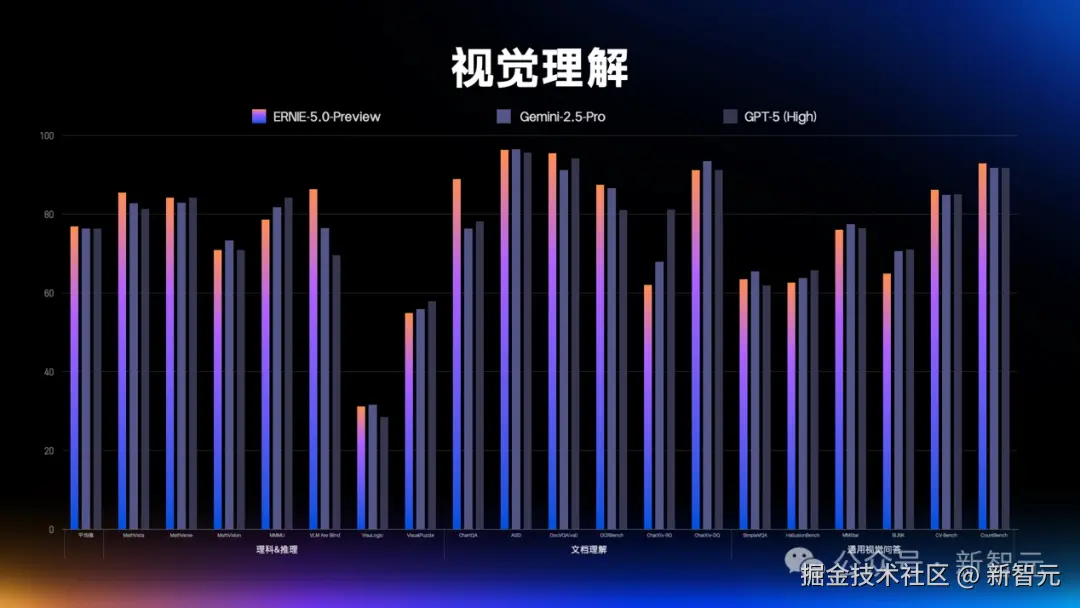
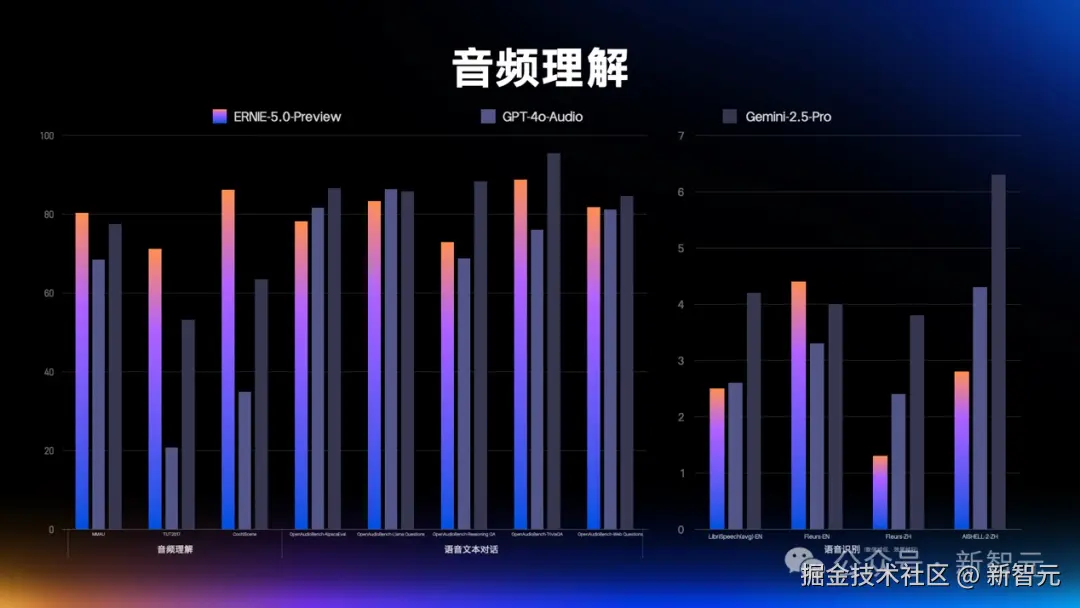
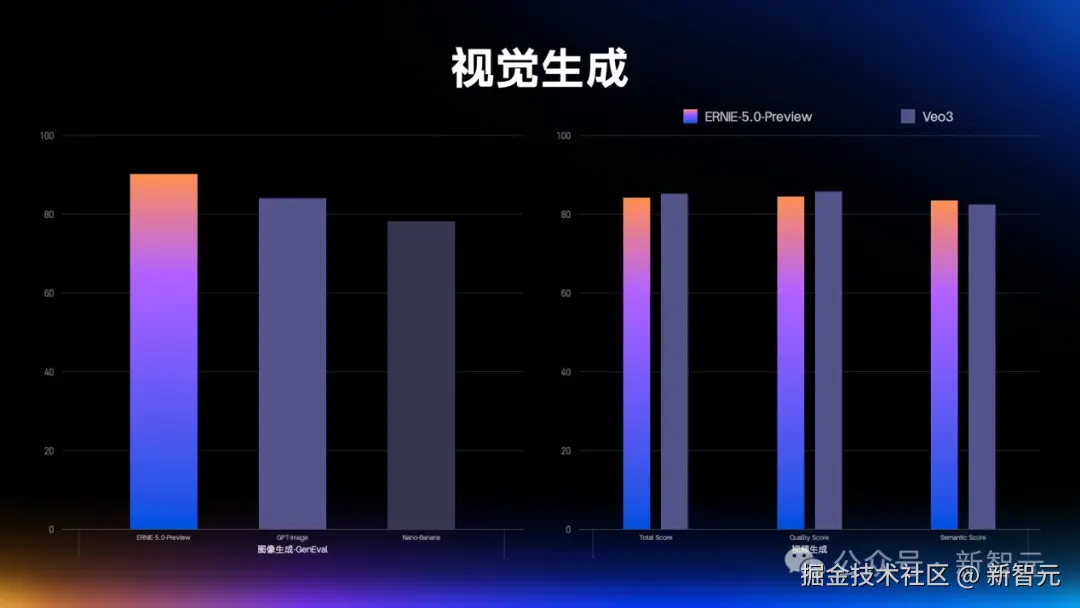
一经发布,这款模型的预览版就在多模态理解、指令遵循、创意写作、智能体规划等 40 + 核心赛道表现惊艳。
这一次,出手的还是中国 AI。
左右滑动查看
2025 百度世界大会上,文心新一代模型------文心 5.0 重磅发布。
作为「原生全模态」模型,它从底层架构上实现了一次深刻的变革。

为何这么说?
与业内主流的多模态 AI 不同,文心 5.0 从训练之初融合了语言、图像、视频、音频等多模态数据。
而且,它还支持文、图、视、音的联合输入与输出,实现「原生」的统一理解和生成。
由此,文心 5.0 具备了强大的多模态理解和推理能力。

大会现场,文心 5.0 以「武林外传」佟湘玉的口吻二创「甄嬛传」。「AI 甄嬛」妙语连珠,出人意料的演绎瞬间点燃全场。

「告别「拼接」,原生全模态登场」
原生全模态,不是多模态的「加法」。
一提到多模态 AI,人们可能想到的是,将语言、图像、视频、音频等不同数据「拼接」起来的模型。
当前,业界大多都采用了这种「后期融合」方式的多模态模型。
但文心 5.0 不同,它从根源上构建了一个统一的架构,即新一代「原生全模态大模型」。

自训练伊始,文心 5.0 融合了语言、图像、视频、音频等多模态数据,实现了文、图、视、音的联合输入与输出。
这样一来,文心 5.0 就能真正做到原生的全模态理解与生成。
不过在此之前,百度团队克服了业内普遍面临的难题:
原生多模态架构的「理解与生成一体化」
一般来说,传统方法往往先是处理单一模态,再将所有模态数据融合。这种方法看似优雅,实则会带来很多致命的问题。
后期融合只在输出层进行,也就是说,每个模态的特征在融合之前,就已独立决策完成。
这样的 AI 根本学不到模态之间的「深层语义交互」,比如视频中,人物表情和语音语调高度相关,进而造成信息丢失。
文心 5.0 通过精细建模多模语义特征,让理解和生成相互增强。
同时,它还采用了「自回归统一结构」,对不同模态的训练目标进行离散化建模,确保了多模态特征在统一框架下充分融合并协同优化,由此提升了全模态统一建模的能力。
在参数规模上,文心 5.0 总参数超过 2.4 万亿,业界公开参数的模型之最。
更关键的是,它引入了超稀疏混合专家架构,进行庞大的全模态训练。
其激活参数比例低于 3%,在保持强大能力的同时,显著降低计算和推理成本。
「 」
」
「训推双引擎,成本骤降」
要让万亿级全模态 MoE 真正跑得动、跑得快,团队在训练与推理上同时开刀,构建了一套高效的训推体系。
「1. 高效全模态超稀疏混合专家分布式训练」
在训练阶段,依托飞桨框架,他们研发了多模态编码器分离异步训练架构、动态自适应显存卸载技术,以及细粒度通信计算重叠编排专家并行技术。
同时,结合 FP8 混合精度训练,实现了对万亿级参数全模态超稀疏混合专家模型的高效训练。
结果,文心 5.0 预训练性能较基准提速 230%。
「2. 多级分离架构的全模态统一高性能推理」
在推理阶段,文心 5.0 采用了「多模编码器 - 预填充 - 解码 - 多模生成器」的多级分离推理部署框架。
此外,团队还研发了面向超稀疏混合专家、数据负载和注意力计算的均衡算法,以及动态自适应多步投机解码和效果无损低比特键值缓存量化技术。
在推理成本上,文心 5.0 得到大幅压缩,真正实现了效率与能力的平衡,让其更接近实用。
此外,衡量一个模型能否从实验室走向实际应用,长程任务的指标是最重要的衡量因素之一。
为了提升文心 5.0 长程任务的能力,团队基于大规模工具环境,合成了长程任务轨迹数据。
然后,在预训练和后训练阶段,基于思维链和行动链对文心 5.0 进行「端到端」多轮强化学习训练。
由此可见,文心 5.0 的智能体和工具调用能力,得到了显著的提升。
「文心又回来了!」
过去两年,多模态模型已迅速崛起,成为驱动 AI 时代发展的核心引擎。
与传统大语言模型不同,它突破了单一文本的限制,通过无缝融合图像、音频、视频等多源信息,实现了更接近人类的综合理解与生成能力。
放眼全球,在这场 AI 大战中,OpenAI、谷歌等硅谷巨头早已在多模态赛道上抢先布局。
OpenAI 发布 GPT-4o 时,便向世界生动展示了多模态 AI 应有的交互形态------
一个统一的神经网络,无缝处理文本、音频、视觉等多种模态的输入与输出。


而谷歌的 Gemini 系列,更是从诞生之初便被烙上了「原生多模态」的印记。
他们在技术报告中,多次强调了原生多模态与非原生的差异。


CEO Demis Hassabis 也曾明确表示,Gemini 的目标就是要让一个模型能原生地理解图像、音频和视频。
最终,实现与物理世界的真实交互。

视线转回国内,阿里、字节等头部大厂同样在多模态赛道上重兵布局。而在众多路径中,百度选择了一条更效率导向的道路------「「原生全模态」」。

原生全模态,意味着模型从训练的第一天起,就如人类一般,活在视觉、听觉与文字交融的统一感知中。
和婴儿一样,它学习世界的方式是通过所有感官的同步输入来形成认知。毕竟,人类的思考从来都不是「先看再听再想」的线性接力,而是所有信息洪流的同步融合。
这之中的核心,便是将每一帧画面、每一段声音、乃至每一个词语,都转化为一套统一的离散符号流,并置于同一个自回归框架下建模。
也就是说,当你输入一段街头艺人表演的视频,探寻「背后的故事」时,AI 不再是割裂地解析画面、分析音频,最后拼凑答案。它能在一个统一的语义空间中,同步完成感知、推理与叙事,像人类一样,给予一个完整而深刻的回应。
正是凭借这种全模态的内在优势,文心 5.0 得以突破复杂场景的束缚,为 AI 的未来应用开启无限想象。
更值得一提的是,文心的实力,早已超越了实验室的范畴,在真实应用中形成了技术落地的闭环。
发布会现场,与百度连线的「AI 老罗」便是最好的证明。他不仅能轻松做出「点赞、比心、比耶」的互动三连,更在问答环节中,将罗永浩本人「犀利吐槽」的语言风格模仿得惟妙惟肖。

技术基于慧播星高说服力数字人
如今,当理解与生成走向统一,当技术与应用协同共生,人机智能的边界也正悄然消融。
在这场全球大模型的激烈角逐中,文心正以全新姿态,强势回归!