三、函数
函数是指一段可以直接被另一段程序调用的程序或代码。
(一)字符串函数
(1)MySQL 字符串函数
| 函数名 | 功能描述 | 示例 | 结果 |
|---|---|---|---|
| LENGTH(str) | 返回字符串的字节长度(注意 UTF-8 中文是 3 字节) | SELECT LENGTH('abc'); |
3 |
| CHAR_LENGTH(str) / LENGTH(str)/CHAR_LENGTH(str) | 返回字符串的字符数(与字符集无关) | SELECT CHAR_LENGTH('你好'); |
2 |
| CONCAT(str1, str2, ...) | 拼接多个字符串 | SELECT CONCAT('My', 'SQL'); |
MySQL |
| CONCAT_WS(sep, str1, str2, ...) | 使用分隔符拼接字符串(WS = With Separator) | SELECT CONCAT_WS('-', '2025', '11', '13'); |
2025-11-13 |
| UPPER(str) / UCASE(str) | 转换为大写 | SELECT UPPER('mysql'); |
MYSQL |
| LOWER(str) / LCASE(str) | 转换为小写 | SELECT LOWER('MySQL'); |
mysql |
| LEFT(str, len) | 返回左边的 len 个字符 | SELECT LEFT('abcdef', 3); |
abc |
| RIGHT(str, len) | 返回右边的 len 个字符 | SELECT RIGHT('abcdef', 2); |
ef |
| SUBSTRING(str, pos, len) / MID(str, pos, len) | 从指定位置开始截取子串 | SELECT SUBSTRING('abcdef', 2, 3); |
bcd |
| LOCATE(substr, str) / POSITION(substr IN str) | 返回子串第一次出现的位置(找不到返回 0) | SELECT LOCATE('b', 'abcdb'); |
2 |
| INSTR(str, substr) | 与 LOCATE 类似,返回子串位置 | SELECT INSTR('abcdb', 'b'); |
2 |
| REPLACE(str, from_str, to_str) | 字符串替换 | SELECT REPLACE('abcabc', 'a', 'x'); |
xbcxbc |
| REVERSE(str) | 反转字符串 | SELECT REVERSE('abc'); |
cba |
| LPAD(str, len, padstr) | 在字符串左侧填充至指定长度 | SELECT LPAD('abc', 6, '*'); |
***abc |
| RPAD(str, len, padstr) | 在字符串右侧填充至指定长度 | SELECT RPAD('abc', 6, '*'); |
abc*** |
| LTRIM(str) | 去掉左边空格 | SELECT LTRIM(' abc'); |
abc |
| RTRIM(str) | 去掉右边空格 | SELECT RTRIM('abc '); |
abc |
| TRIM(str) | 去掉两端空格 | SELECT TRIM(' abc '); |
abc |
| TRIM(BOTH | LEADING | TRAILING remstr FROM str) | 去除字符串两端(BOTH)、左侧(LEADING)或右侧(TRAILING)的指定字符 | SELECT TRIM(BOTH 'x' FROM 'xxhelloxx'); | hello |
| REPEAT(str, count) | 重复字符串 | SELECT REPEAT('ab', 3); |
ababab |
| SPACE(n) | 返回 n 个空格 | SELECT CONCAT('A', SPACE(3), 'B'); |
A B |
| ELT(N, str1, str2, ...) | 返回第 N 个字符串 | SELECT ELT(2, 'A', 'B', 'C'); |
B |
| FIELD(str, str1, str2, ...) | 返回 str 在列表中位置(索引) | SELECT FIELD('B', 'A', 'B', 'C'); |
2 |
| FIND_IN_SET(str, strlist) | 查找字符串是否在以逗号分隔的列表中 | SELECT FIND_IN_SET('b', 'a,b,c'); |
2 |
| MAKE_SET(bits, str1, str2, ...) | 根据 bits 的二进制位返回字符串集合 | SELECT MAKE_SET(5, 'a', 'b', 'c'); |
a,c |
| INSERT(str, pos, len, newstr) | 在字符串中替换部分内容 | SELECT INSERT('abcdef', 2, 3, 'XYZ'); |
aXYZef |
| QUOTE(str) | 用单引号包裹字符串并转义特殊字符 | SELECT QUOTE('O\'Reilly'); |
'O'Reilly' |
(2)示例:
示例1:拼接学生姓名与班级
sql
SELECT id, CONCAT(name, ' - ', class_name) AS student_info
FROM student;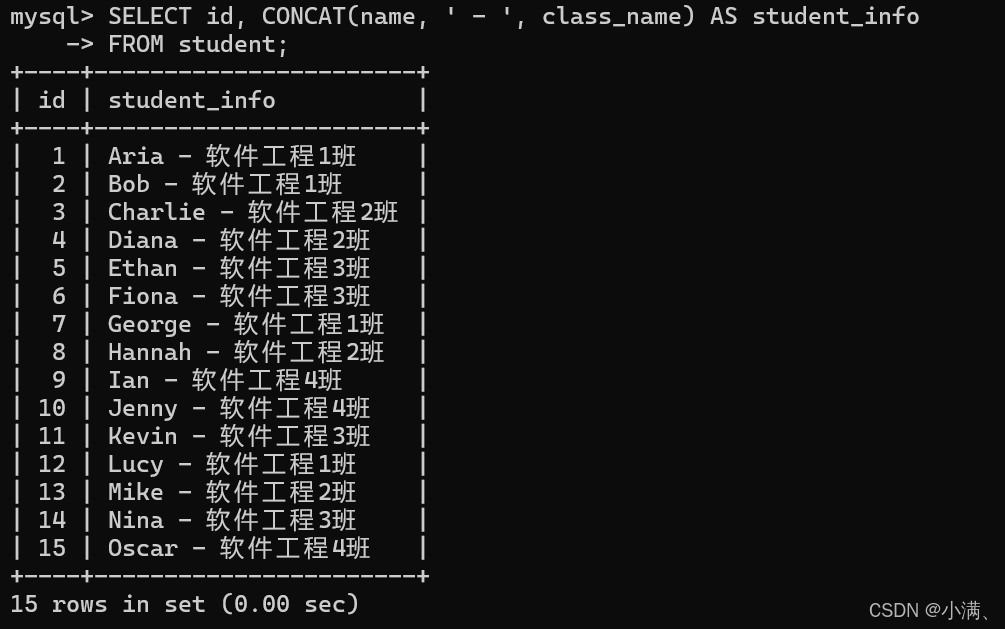
示例2:将英文姓名转为小写
sql
SELECT name, LOWER(name) AS name_lower
FROM student;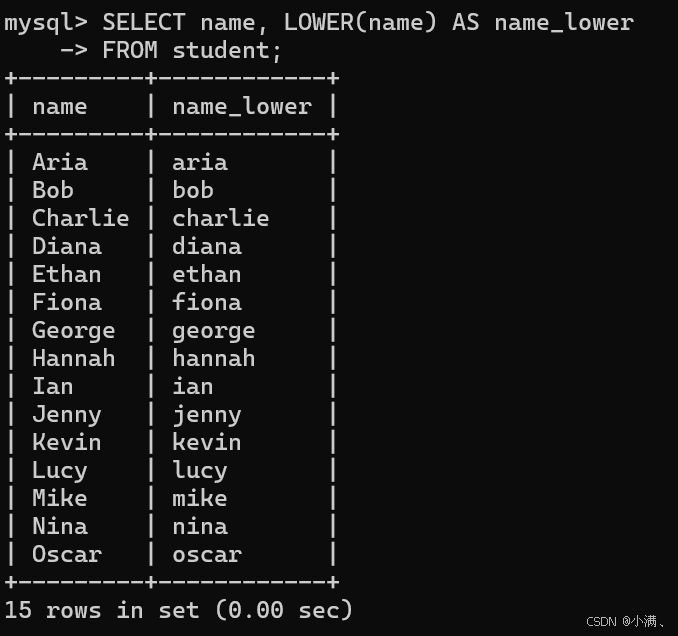
示例3:提取"班级名称"中的数字部分
sql
SELECT class_name,
SUBSTRING(class_name, 5, 1) AS class_number
FROM student
WHERE class_name IS NOT NULL;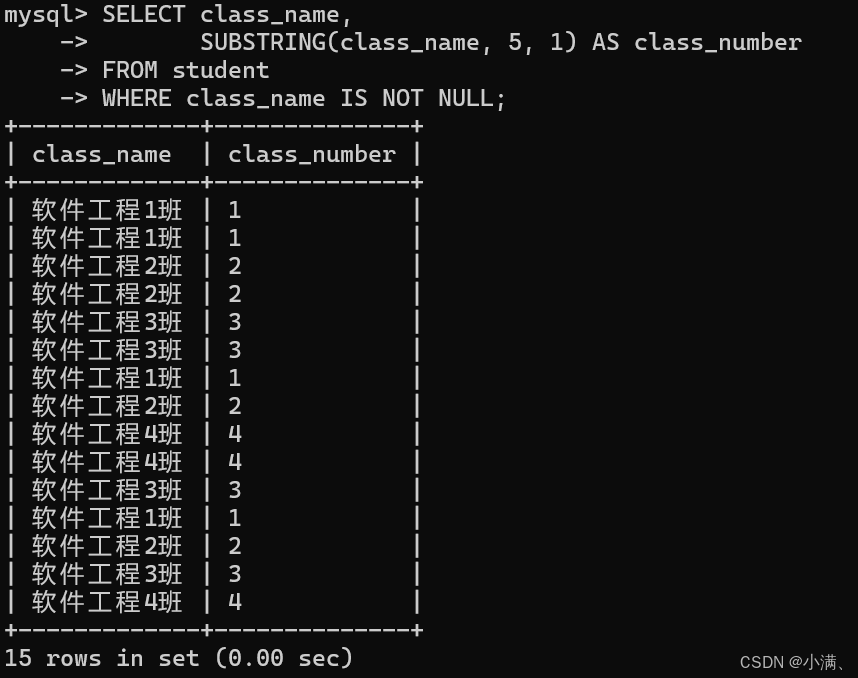
示例4:在 id 前补零
sql
SELECT id, LPAD(id, 4, '0') AS student_code, name
FROM student;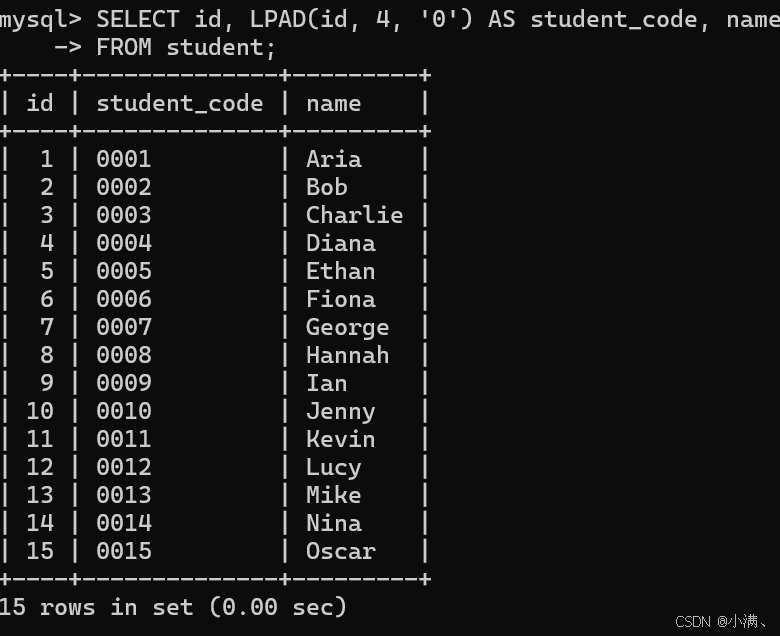
示例5:反转学生姓名
sql
SELECT name, REVERSE(name) AS reversed_name
FROM student;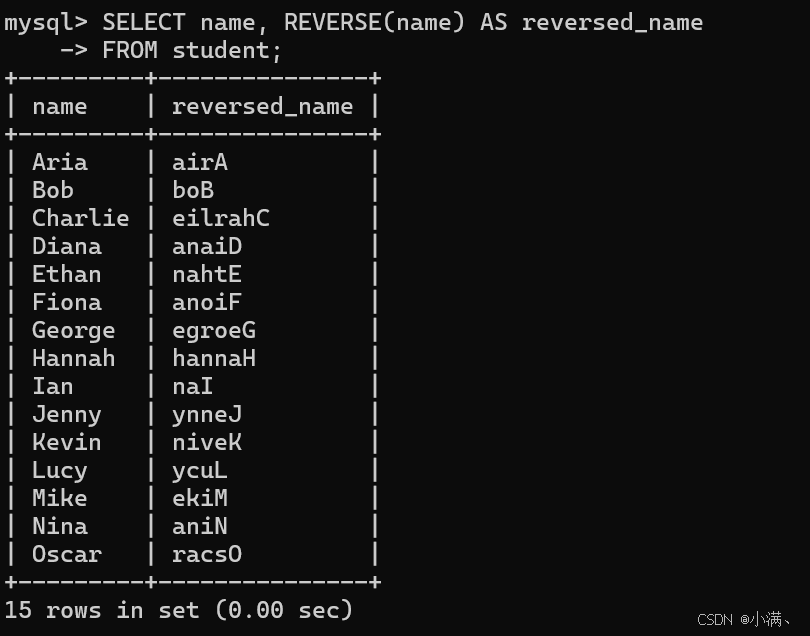
(二)数值函数
(2)MySQL常用数值函数
| 函数名 | 功能描述 | 示例 | 结果 |
|---|---|---|---|
| ABS(x) | 返回 x 的绝对值 | SELECT ABS(-10); |
10 |
| SIGN(x) | 返回 x 的符号(1 正数,0 零,-1 负数) | SELECT SIGN(-8); |
-1 |
| CEIL(x) 或 CEILING(x) | 向上取整(不小于 x 的最小整数) | SELECT CEIL(3.14); |
4 |
| FLOOR(x) | 向下取整(不大于 x 的最大整数) | SELECT FLOOR(3.14); |
3 |
| ROUND(x, d) | 四舍五入,保留 d 位小数(默认 0) | SELECT ROUND(3.14159, 2); |
3.14 |
| TRUNCATE(x, d) | 截断到 d 位小数,不四舍五入 | SELECT TRUNCATE(3.14159, 2); |
3.14 |
| MOD(x, y) 或 x % y | 返回 x 除以 y 的余数 | SELECT MOD(10, 3); |
1 |
| RAND() | 返回 [0,1) 的随机数 | SELECT RAND(); |
0.7324(示例) |
| POW(x, y) 或 POWER(x, y) | 计算 x 的 y 次幂 | SELECT POW(2, 3); |
8 |
| SQRT(x) | 返回平方根 | SELECT SQRT(16); |
4 |
| EXP(x) | 计算 e 的 x 次幂 | SELECT EXP(1); |
2.7182818 |
| LOG(x) | 返回自然对数 ln(x) | SELECT LOG(10); |
2.302585 |
| LOG10(x) | 返回以 10 为底的对数 | SELECT LOG10(100); |
2 |
| LOG2(x) | 返回以 2 为底的对数 | SELECT LOG2(8); |
3 |
| PI() | 返回圆周率 π | SELECT PI(); |
3.141593 |
| RADIANS(x) | 将角度转为弧度 | SELECT RADIANS(180); |
3.141593 |
| DEGREES(x) | 将弧度转为角度 | SELECT DEGREES(PI()); |
180 |
| SIN(x) | 返回正弦值(x 以弧度为单位) | SELECT SIN(PI()/2); |
1 |
| COS(x) | 返回余弦值 | SELECT COS(PI()); |
-1 |
| TAN(x) | 返回正切值 | SELECT TAN(PI()/4); |
1 |
| COT(x) | 返回余切值 | SELECT COT(PI()/4); |
1 |
| LEAST(x1, x2, ...) | 返回最小值 | SELECT LEAST(3,7,2,5); |
2 |
| GREATEST(x1, x2, ...) | 返回最大值 | SELECT GREATEST(3,7,2,5); |
7 |
示例1:计算每个学生与 22 岁的年龄差(绝对值)
sql
SELECT id, age, ABS(age - 22) AS age_diff
FROM student;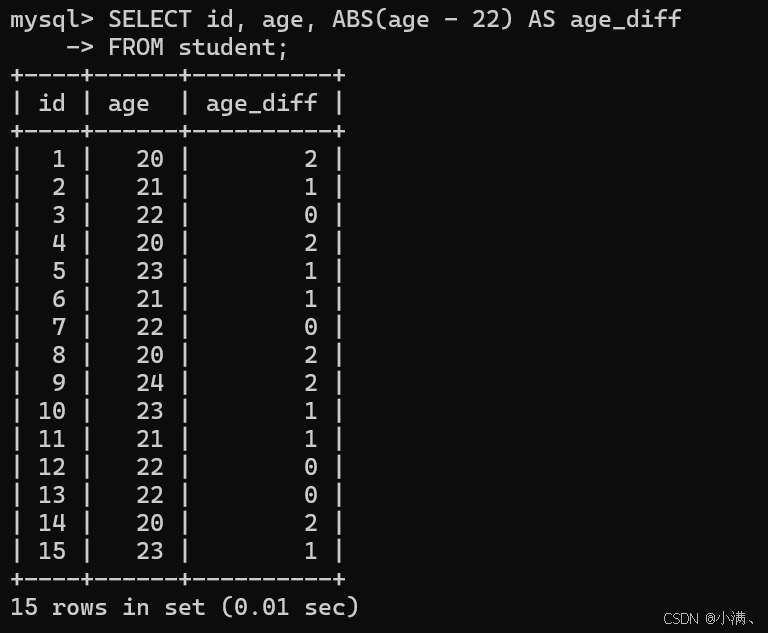
示例2:判断学生年龄是奇数还是偶数
sql
SELECT id, age, MOD(age, 2) AS age_mod_2
FROM student;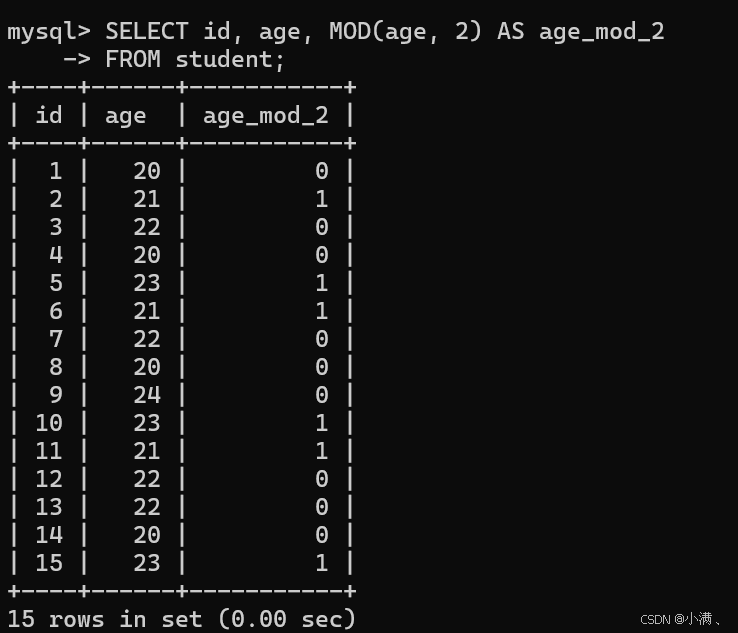
示例3:计算每个学生年龄的平方
sql
SELECT id, POW(age, 2) AS age_square
FROM student;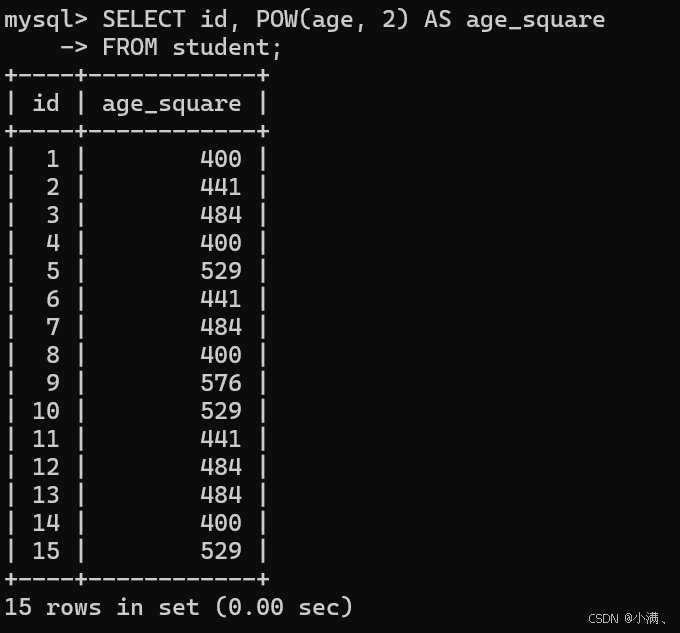
示例4:为每位学生随机生成一个 0~100 的"模拟成绩"
sql
SELECT id, name, ROUND(RAND() * 100) AS random_score
FROM student;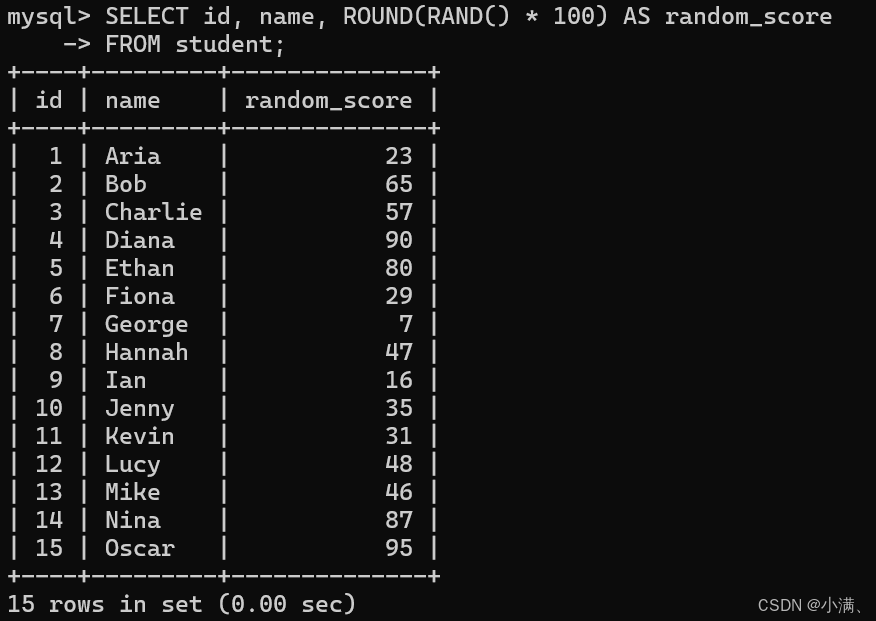
(三)日期函数
(1)MySQL 常用日期函数
| 函数名 | 功能说明 | 示例 | 结果说明 |
|---|---|---|---|
| NOW() | 返回当前日期和时间(精确到秒) | SELECT NOW(); |
2025-11-13 14:45:32 |
| CURDATE() | 返回当前日期(不含时间) | SELECT CURDATE(); |
2025-11-13 |
| CURTIME() | 返回当前时间(不含日期) | SELECT CURTIME(); |
14:45:32 |
| SYSDATE() | 返回执行 SQL 时的系统日期时间 | SELECT SYSDATE(); |
与 NOW() 类似,但在多次调用中不同步 |
| YEAR(date) | 返回年份 | SELECT YEAR(NOW()); |
2025 |
| MONTH(date) | 返回月份 | SELECT MONTH('2025-11-13'); |
11 |
| DAY(date) / DAYOFMONTH(date) | 返回月份中的"日" | SELECT DAY('2025-11-13'); |
13 |
| HOUR(time) | 返回小时 | SELECT HOUR(NOW()); |
14 |
| MINUTE(time) | 返回分钟 | SELECT MINUTE(NOW()); |
45 |
| SECOND(time) | 返回秒 | SELECT SECOND(NOW()); |
32 |
| WEEK(date) | 返回一年中的第几周 | SELECT WEEK('2025-11-13'); |
45 |
| DAYNAME(date) | 返回星期名称 | SELECT DAYNAME('2025-11-13'); |
Thursday |
| MONTHNAME(date) | 返回月份英文名 | SELECT MONTHNAME('2025-11-13'); |
November |
| DATE_FORMAT(date, format) | 格式化日期输出 | SELECT DATE_FORMAT(NOW(), '%Y年%m月%d日 %H:%i:%s'); |
2025年11月13日 14:45:32 |
| STR_TO_DATE(str, format) | 将字符串解析为日期 | SELECT STR_TO_DATE('2025-11-13 14:30:00', '%Y-%m-%d %H:%i:%s'); |
2025-11-13 14:30:00 |
| DATE_ADD(date, INTERVAL n unit) | 日期加法 | SELECT DATE_ADD('2025-11-13', INTERVAL 5 DAY); |
2025-11-18 |
| DATE_SUB(date, INTERVAL n unit) | 日期减法 | SELECT DATE_SUB('2025-11-13', INTERVAL 2 MONTH); |
2025-09-13 |
| DATEDIFF(date1, date2) | 返回两个日期之间的天数差 | SELECT DATEDIFF('2025-11-13', '2025-11-01'); |
12 |
| TIMESTAMPDIFF(unit, datetime1, datetime2) | 返回时间差(指定单位) | SELECT TIMESTAMPDIFF(DAY, '2025-11-01', '2025-11-13'); |
12 |
| LAST_DAY(date) | 返回该月的最后一天 | SELECT LAST_DAY('2025-11-13'); |
2025-11-30 |
| FROM_DAYS(n) | 将天数(整数)转为日期 | SELECT FROM_DAYS(739000); |
2025-03-26 |
| TO_DAYS(date) | 将日期转为天数(整数) | SELECT TO_DAYS('2025-11-13'); |
739232 |
(四)流程函数
(1)MySQL 常用流程控制函数
| 函数 | 功能说明 | 示例 | 结果说明 |
|---|---|---|---|
| IF(expr, true_value, false_value) | 如果 expr 为真返回 true_value,否则返回 false_value |
SELECT name, IF(gender='女','女学生','男学生') AS gender_desc FROM student; |
将性别转换为"男学生/女学生" |
| IFNULL(expr, alt_value) | 如果 expr 为 NULL 返回 alt_value,否则返回 expr |
SELECT name, IFNULL(age, 18) AS age FROM student; |
将年龄为 NULL 的学生设为 18 |
| NULLIF(expr1, expr2) | 如果 expr1 = expr2 返回 NULL,否则返回 expr1 |
SELECT id, NULLIF(age, 22) AS age_check FROM student; |
年龄为 22 的返回 NULL,其余返回原值 |
| COALESCE(expr1, expr2, ..., exprN) | 返回第一个非 NULL 的值 | SELECT name, COALESCE(age, 20, 18) AS age_value FROM student; |
如果 age 为 NULL 返回 20,否则返回 age |
| CASE WHEN ... THEN ... ELSE ... END | 多条件判断,相当于 if/else if/else | sql SELECT name, age, CASE WHEN age<21 THEN '年轻' WHEN age<=23 THEN '中年' ELSE '成熟' END AS age_level FROM student; |
根据年龄返回"年轻/中年/成熟" |
| GREATEST(expr1, expr2, ...) | 返回最大值 | SELECT name, GREATEST(age, 20) AS max_age FROM student; |
将年龄和 20 比较,返回较大值 |
| LEAST(expr1, expr2, ...) | 返回最小值 | SELECT name, LEAST(age, 22) AS min_age FROM student; |
将年龄和 22 比较,返回较小值 |
四、约束
1. 概述
(1)概念
约束是作用于数据库表中字段或表的规则,用于限制数据的输入和修改,以保证数据的准确性和完整性。
(2)目的
保证数据正确性:避免无效或错误的数据存入表中
保证数据有效性:确保数据符合业务规则
保证数据完整性:维护表与表之间的关系一致性
(3)分类
| 约束类型 | 描述 | 对应关键字 |
|---|---|---|
| 主键约束 | 唯一标识表中的每一行记录,不能为 NULL | PRIMARY KEY |
| 唯一约束 | 保证列的值在表中唯一,可以为空(NULL 可以重复) | UNIQUE |
| 非空约束 | 列值不能为空 | NOT NULL |
| 外键约束 | 保证表与表之间的引用完整性,限制列的值必须在关联表中存在 | FOREIGN KEY |
| 检查约束 | 限制列值必须满足指定条件 | CHECK |
| 默认值约束 | 当插入数据时,如果没有指定列值,则使用默认值 | DEFAULT |
2. 约束演示
(1)示例表:stu
sql
CREATE TABLE stu (
id INT PRIMARY KEY, -- 主键约束
name VARCHAR(50) NOT NULL, -- 非空约束
email VARCHAR(50) UNIQUE, -- 唯一约束
age INT CHECK (age >= 0), -- 检查约束
gender ENUM('男', '女') DEFAULT '男' -- 默认值约束
);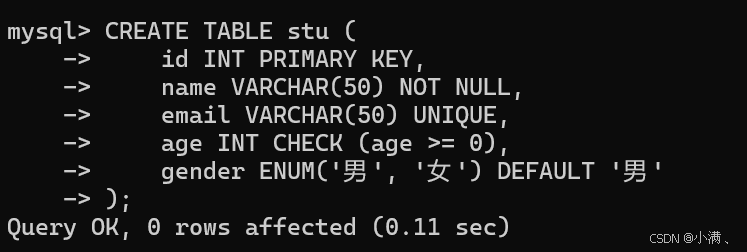
说明:
id:主键约束,唯一且不能为 NULL
name:非空约束,不能为空
email:唯一约束,每个邮箱唯一
age:检查约束,限制年龄必须 >= 0
gender:默认值约束,如果插入时未指定,则默认为 '男'
(2)测试插入数据
sql
INSERT INTO stu (id, name, email, age) VALUES (1, 'Aria', 'aria@example.com', 20);
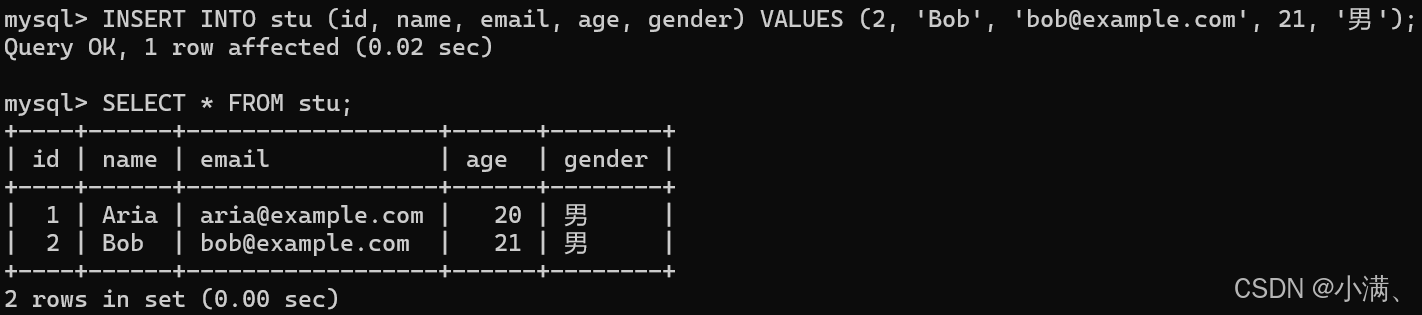
INSERT INTO stu (id, name, email, age, gender) VALUES (2, 'Bob', 'bob@example.com', 21, '男');
-- INSERT INTO stu (id, name, email, age) VALUES (1, 'Charlie', 'charlie@example.com', 22); -- 会报错,id 主键重复
-- INSERT INTO stu (id, name, email, age) VALUES (3, NULL, 'david@example.com', 23); -- 会报错,name 非空
-- INSERT INTO stu (id, name, email, age) VALUES (4, 'Eve', 'aria@example.com', 19); -- 会报错,email 唯一
-- INSERT INTO stu(id, name, email, age) VALUES (5, 'Frank', 'frank@example.com', -1); -- 会报错,age 检查约束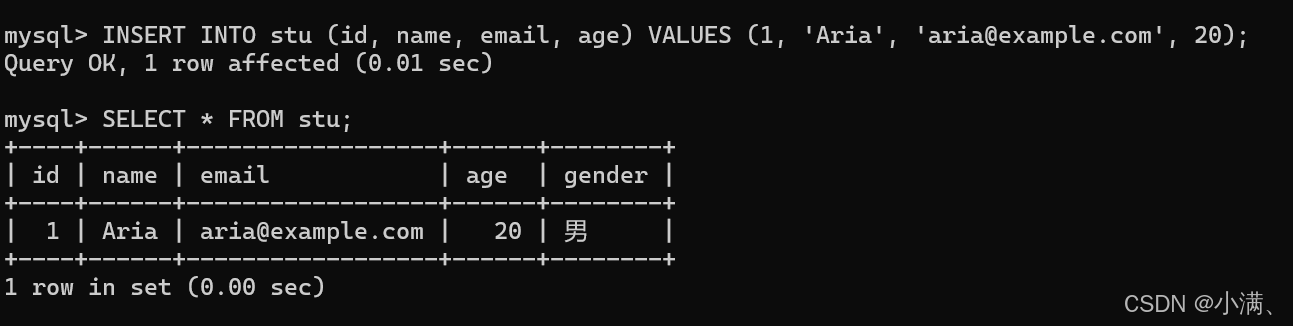




3. 外键约束
(1)概念
外键用于在两张表之间建立联系,确保数据的一致性和完整性。
外键列的值必须在引用表的主键或唯一列中存在
可以防止子表中出现不存在于主表的值
(2)语法
创建表时添加外键
sql
CREATE TABLE 主表 (
主键列 数据类型 PRIMARY KEY,
其他列 ...
);
CREATE TABLE 子表 (
子表主键列 数据类型 PRIMARY KEY,
外键列 数据类型,
其他列 ...
[CONSTRAINT 外键名称] FOREIGN KEY (外键列) REFERENCES 主表(主键列)
);已存在表中添加外键
sql
ALTER TABLE 子表
ADD CONSTRAINT 外键名称 FOREIGN KEY (外键列) REFERENCES 主表(主键列);删除外键
sql
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;示例:部门与学生
sql
-- 创建部门表(主表)
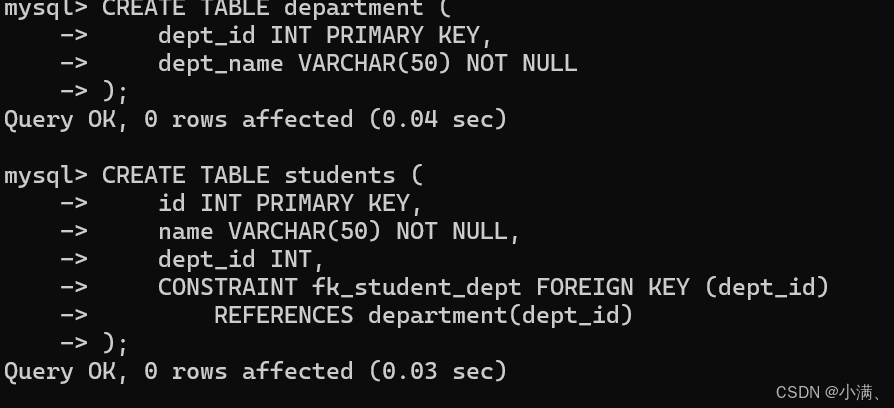
CREATE TABLE department (
dept_id INT PRIMARY KEY,
dept_name VARCHAR(50) NOT NULL
);
-- 创建学生表(子表),带外键约束
CREATE TABLE students (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
dept_id INT,
CONSTRAINT fk_student_dept FOREIGN KEY (dept_id)
REFERENCES department(dept_id)
);
测试数据
sql
-- 插入部门
INSERT INTO department (dept_id, dept_name) VALUES (1, '软件工程'), (2, '网络工程');
-- 插入学生
INSERT INTO students (id, name, dept_id) VALUES (1, 'Aria', 1), (2, 'Bob', 2);
-- 尝试插入不存在的部门
-- INSERT INTO students (id, name, dept_id) VALUES (3, 'Charlie', 3); -- 会报错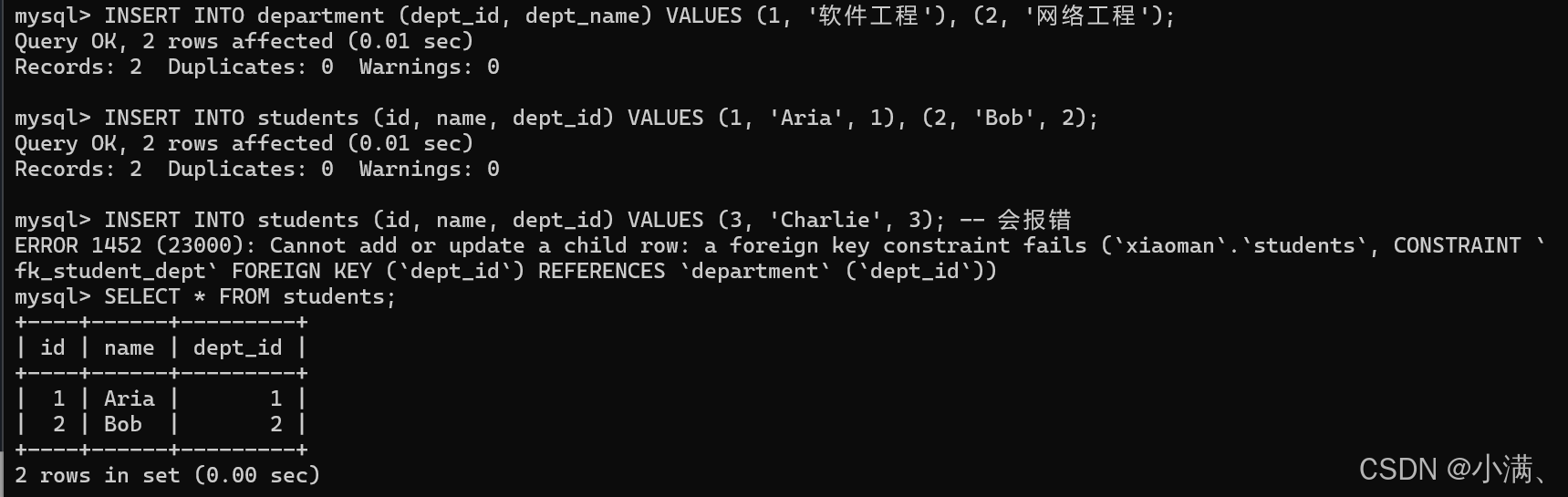
sql
--删除外键
ALTER TABLE students DROP FOREIGN KEY fk_student_dept;
(3)删除/更新行为
在数据库中,外键约束不仅保证了表与表之间的数据一致性,还可以指定当主表记录被删除或更新时 ,子表应该如何处理。这部分行为通常通过 ON DELETE 和 ON UPDATE来控制。
行为分类
| 行为类型 | 描述 | 关键字 |
|---|---|---|
| 删除主表记录 | 当主表中被引用的记录被删除时,子表的对应外键列的处理方式 | ON DELETE |
| 更新主表记录 | 当主表中被引用的记录被更新时,子表的对应外键列的处理方式 | ON UPDATE |
可选操作及说明
| 操作关键字 | 描述 |
|---|---|
CASCADE |
级联操作:主表删除或更新时,子表对应记录也会被删除或更新 |
SET NULL |
设置空值:删除或更新主表记录时,子表外键列被置为 NULL(前提列允许 NULL) |
RESTRICT |
限制操作:禁止删除或更新主表中被引用的记录(默认行为) |
NO ACTION |
与 RESTRICT 类似,禁止操作,在 MySQL 中效果相同 |
SET DEFAULT |
设置默认值:删除或更新主表记录时,子表外键列被设置为默认值(列必须有默认值) |
现在我们重新为 students 添加外键约束,并设置 ON DELETE / ON UPDATE 行为。
示例:
删除部门时,学生的部门ID变为 NULL;
更新部门ID时,学生表的对应外键自动同步更新。
sql
ALTER TABLE students
ADD CONSTRAINT fk_student_dept
FOREIGN KEY (dept_id)
REFERENCES department(dept_id)
ON DELETE SET NULL
ON UPDATE CASCADE;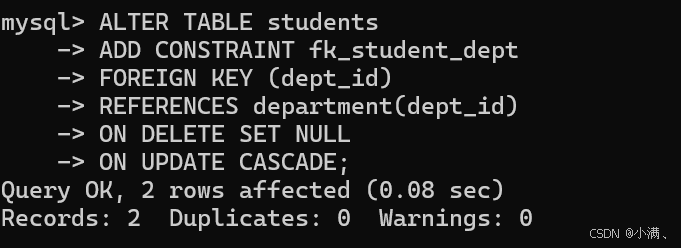
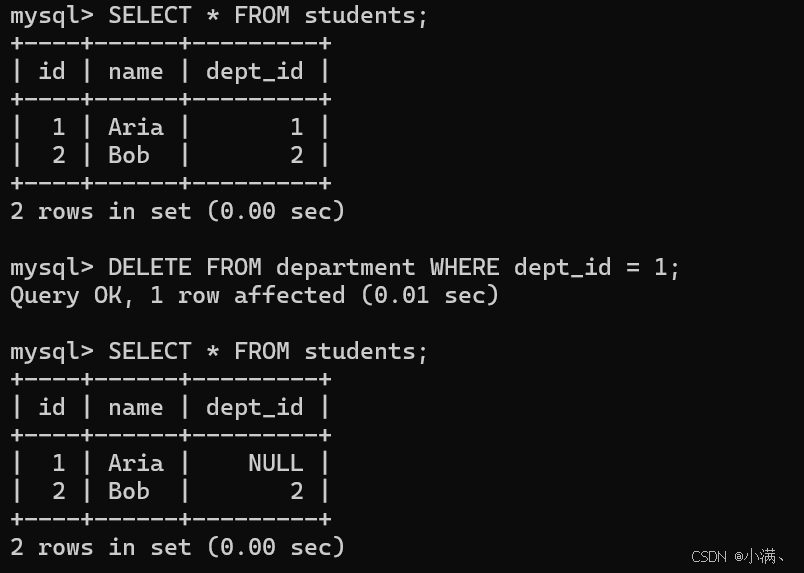
测试删除行为:
sql
DELETE FROM department WHERE dept_id = 1;学生表中所有 dept_id = 1 的行会自动变为 NULL(因为 ON DELETE SET NULL)。
测试更新行为:
sql
UPDATE department SET dept_id = 3 WHERE dept_id = 2;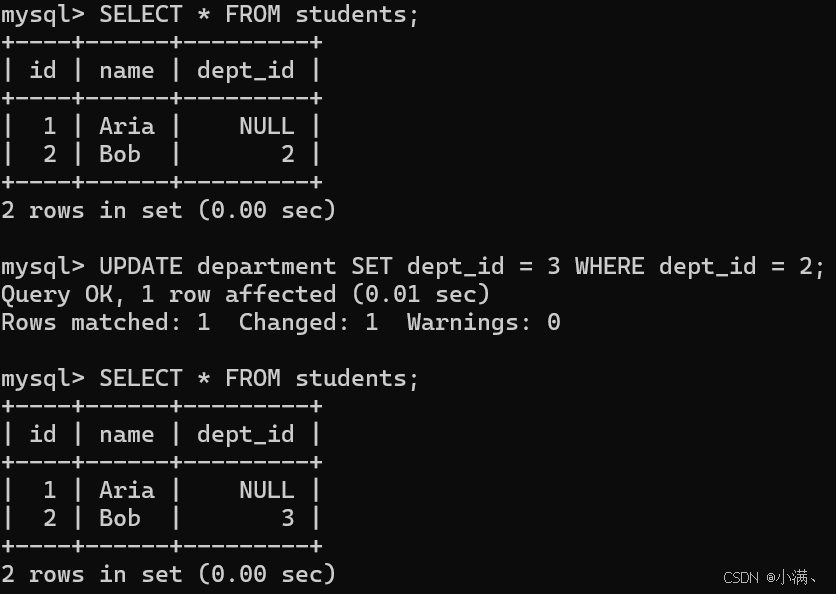
学生表中原本 dept_id = 2 的学生会自动更新为 dept_id = 3(因为 ON UPDATE CASCADE)。
五、多表查询
在项目开发中,数据库表通常不是孤立存在的。随着业务模块之间的关联加强,各表之间也会形成不同的关系,从而产生多表查询的需求。
(一)多表关系
1. 概述
在数据库表结构设计中,会根据业务实体之间的关联关系设计不同类型的表关系,常见的有三种:
(1)一对多(多对一)
例如:一个客户可以有多个订单。
(2)多对多
例如:一个订单可以包含多个商品,一个商品也可以出现在多个订单中(通过中间表实现)。
(3)一对一
例如:用户表与用户详情表,一条记录对应一条扩展记录。
这些关系是多表查询的基础。
(二)多表查询概述
多表查询指在一条 SQL 中同时从两张或多张表中查询数据。
示例表
sql
-- 客户表
CREATE TABLE customer (
id INT PRIMARY KEY,
name VARCHAR(50),
level VARCHAR(20)
);
-- 订单表
CREATE TABLE orders (
id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
amount DECIMAL(10,2)
);
-- 商品表
CREATE TABLE product (
id INT PRIMARY KEY,
product_name VARCHAR(50),
category VARCHAR(50),
price DECIMAL(10,2)
);
-- 订单明细
CREATE TABLE order_item (
id INT PRIMARY KEY,
order_id INT,
product_id INT,
quantity INT
);
INSERT INTO customer VALUES
(1, '张三', 'VIP'),
(2, '李四', '普通'),
(3, '王五', 'VIP'),
(4, '赵六', '普通');
INSERT INTO orders VALUES
(101, 1, '2024-01-10', 300),
(102, 1, '2024-02-05', 800),
(103, 2, '2024-02-20', 150),
(104, 3, '2024-03-15', 600);
INSERT INTO product VALUES
(1, '键盘', '外设', 150),
(2, '鼠标', '外设', 80),
(3, '显示器', '主机设备', 899),
(4, '显卡', '主机设备', 2500);
INSERT INTO order_item VALUES
(1, 101, 1, 1),
(2, 101, 2, 2),
(3, 102, 3, 1),
(4, 103, 2, 1),
(5, 104, 4, 1);
1. 笛卡儿积(需要避免)
笛卡尔乘积表示两个集合的所有组合情况。
例如:A 表 3 行 × B 表 4 行 → 12 组合。
多表查询时,若未加入连接条件,会产生无效笛卡尔积,因此必须使用连接条件过滤。
2. 多表查询分类:
1. 连接查询(JOIN)
内连接(INNER JOIN)
返回两表交集数据。
外连接(LEFT / RIGHT JOIN)
左外连接:保留左表全部 + 两表交集
右外连接:保留右表全部 + 两表交集
自连接(SELF JOIN)
同一张表自我连接,必须使用别名。
2. 子查询(Subquery)
SQL 中嵌套 SELECT,即为子查询。可用于:
SELECT
WHERE
FROM
INSERT/UPDATE/DELETE 条件中
(三)内连接
内连接返回两张表中满足连接条件的记录(可理解为"匹配的数据部分")。
1. 内连接查询语法
隐式内连接(旧写法)
sql
SELECT 字段列表
FROM 表1, 表2
WHERE 连接条件;显示内连接
sql
SELECT 字段列表
FROM 表1
INNER JOIN 表2 ON 连接条件;2. 内连接示例
查询客户及其订单信息
sql
SELECT c.name, o.id AS order_id, o.amount
FROM customer c
INNER JOIN orders o ON c.id = o.customer_id;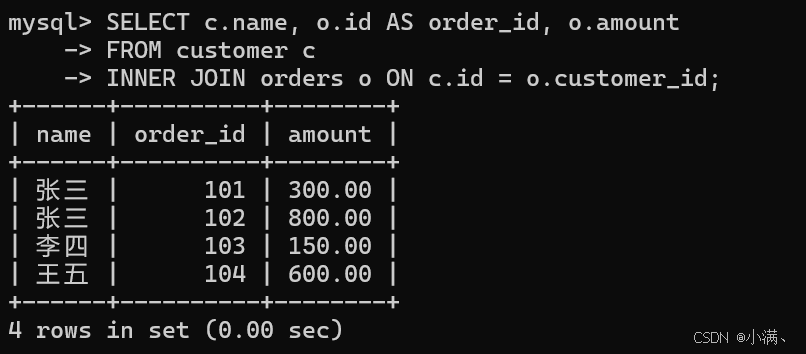
(四)外连接(LEFT / RIGHT JOIN)
1. 左外连接(LEFT JOIN)
语法:
sql
SELECT 字段列表
FROM 表1
LEFT JOIN 表2 ON 条件;含义:返回表1全部 + 两表匹配部分
示例:查询所有客户(包括没下过订单的客户)
sql
SELECT c.name, o.id AS order_id, o.amount
FROM customer c
LEFT JOIN orders o ON c.id = o.customer_id;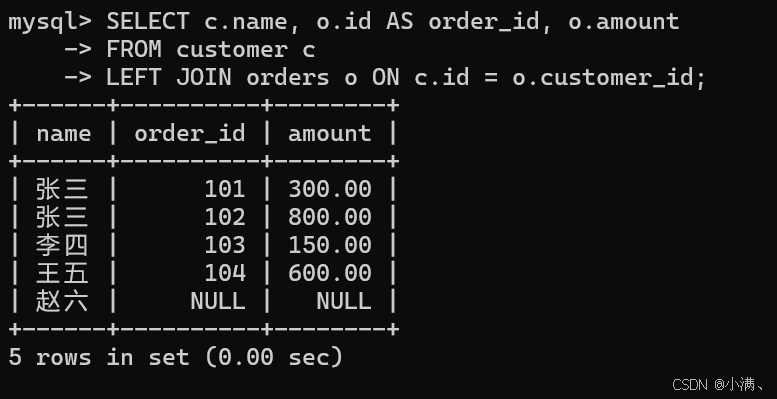
2. 右外连接(RIGHT JOIN)
语法:
sql
SELECT 字段列表
FROM 表1
RIGHT JOIN 表2 ON 条件;含义:返回表2全部 + 两表匹配部分
示例:查询所有订单及客户信息
sql
SELECT c.name, o.id AS order_id, o.amount
FROM customer c
RIGHT JOIN orders o ON c.id = o.customer_id;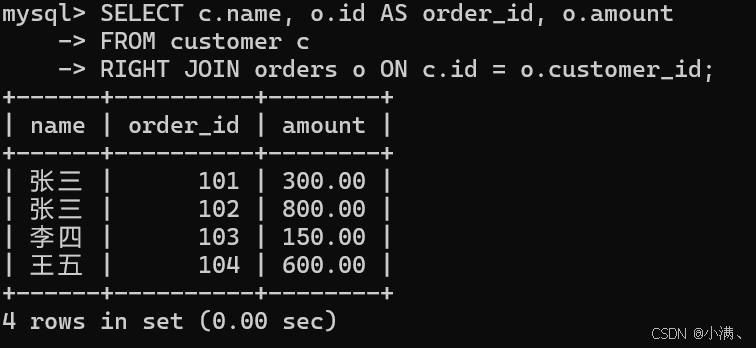
(五)自连接(SELF JOIN)
自连接指同一张表的不同别名相互连接。
语法:
sql
SELECT 字段列表
FROM 表A AS a
JOIN 表A AS b ON 连接条件;示例:员工与上级(父子级结构)
示例表
sql
CREATE TABLE employee (
id INT PRIMARY KEY,
name VARCHAR(50),
leader_id INT
);
INSERT INTO employee VALUES
(1, '张三', NULL),
(2, '李四', 1),
(3, '王五', 1),
(4, '赵六', 2);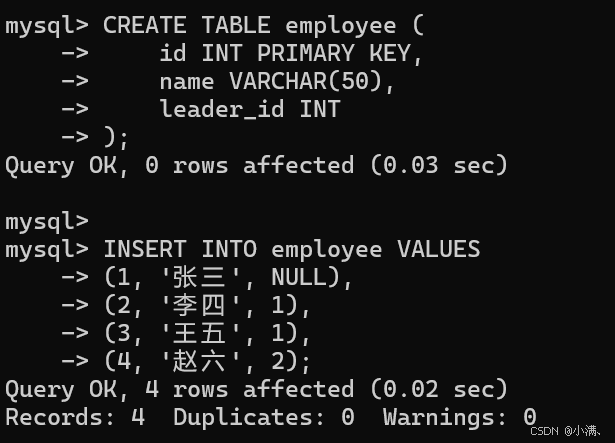
查询每个员工的上级
sql
SELECT e1.name AS 员工, e2.name AS 上级
FROM employee e1
LEFT JOIN employee e2 ON e1.leader_id = e2.id;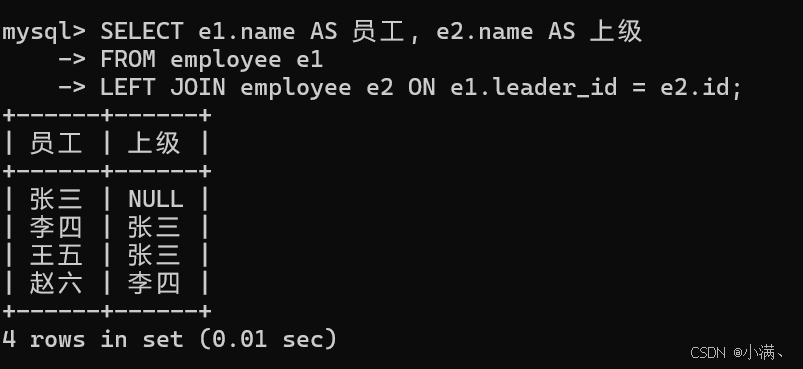
(六)联合查询(UNION / UNION ALL)
用于合并多次查询的结果,要求:
列数一致
数据类型兼容
语法:
sql
SELECT 字段列表 FROM 表A...
UNION[ALL]
SELECT 字段列表 FROM 表B...;区别:
UNION:合并并去重
UNION ALL:合并但不去重(性能更好)
示例:客户姓名 + 商品名称合并结果
sql
SELECT name FROM customer
UNION ALL
SELECT product_name FROM product;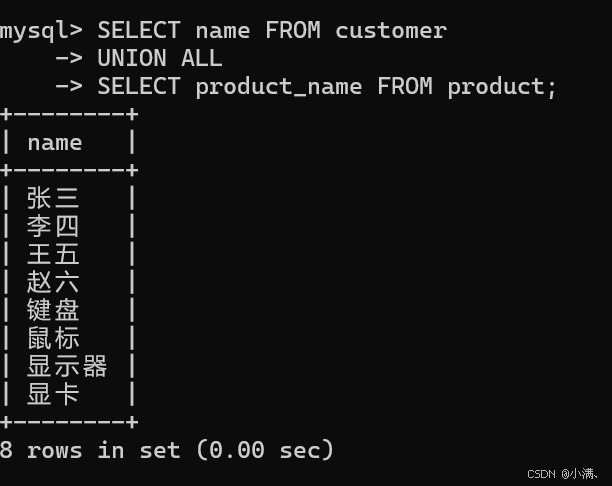
(七)子查询(Subquery)
子查询是指在一个 SQL 语句中嵌套另一个 SELECT 查询语句,子查询可以作为外部查询的条件或数据来源。根据返回结果的形态,子查询可以分为四类:
标量子查询(Scalar Subquery):返回单个值(数字、字符串、日期等),常用于比较操作。
列子查询(Column Subquery):返回一列多行,用于 IN、ANY、ALL 等条件判断。
行子查询(Row Subquery):返回一行多列,用于多列比较或匹配。
表子查询(Table Subquery):返回多行多列,可以作为临时表在外部查询中使用。
子查询可以出现在 WHERE、FROM、SELECT,甚至 INSERT、UPDATE、DELETE 的条件中。
1. 标量子查询(返回单个值)
标量子查询返回单个值,通常用于比较或赋值场景。常用操作符包括 =、<>、>、>=、<、<=。
示例:查询金额最高的订单
sql
SELECT *
FROM orders
WHERE amount = (
SELECT MAX(amount) FROM orders
);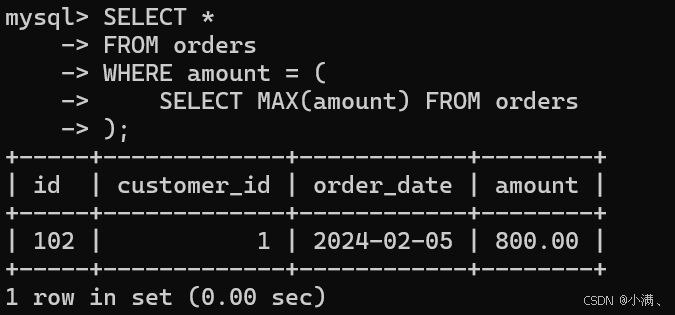
说明:子查询返回订单表中的最大金额,然后外部查询获取对应订单信息。
2. 列子查询(返回一列多行)
列子查询返回一列多行,用于判断字段是否在指定集合内,常配合 IN、NOT IN、ANY、ALL 使用。
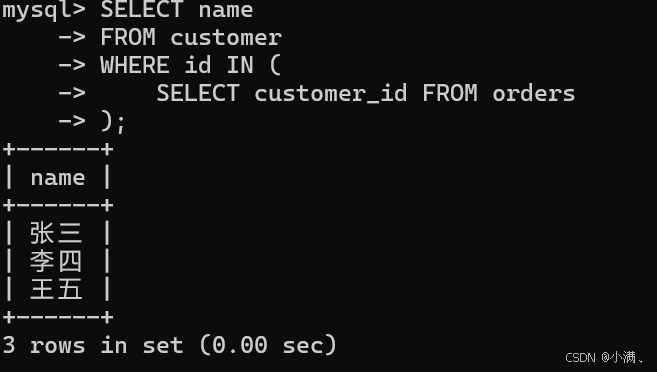
示例:查询下过订单的客户
sql
SELECT name
FROM customer
WHERE id IN (
SELECT customer_id FROM orders
);
使用 ALL 示例:查询价格高于"外设"类所有商品价格的商品
sql
SELECT product_name
FROM product
WHERE price > ALL (
SELECT price FROM product WHERE category = '外设'
);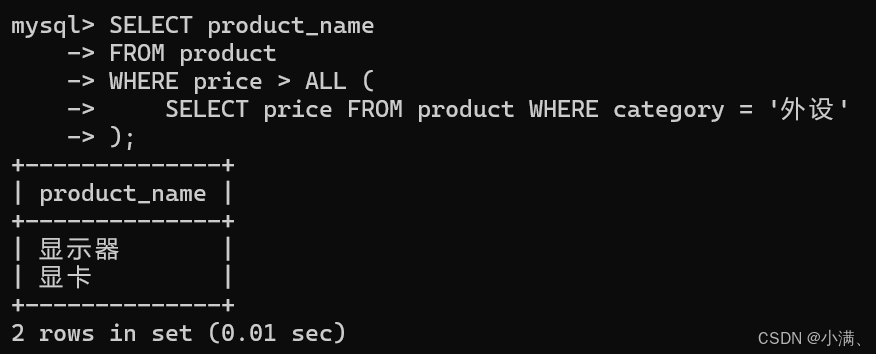
说明:列子查询可以将外部字段与子查询返回的多行数据进行集合比较,灵活实现过滤逻辑。
3. 行子查询(返回一行多列)
行子查询返回一行多列,常用于多列组合比较或匹配场景。
示例:查询与订单 101 商品结构完全相同的明细
sql
SELECT *
FROM order_item
WHERE (product_id, quantity) IN (
SELECT product_id, quantity
FROM order_item
WHERE order_id = 101
);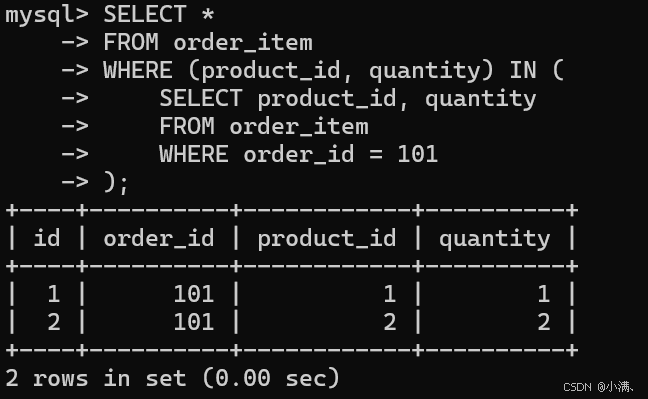
说明:通过行子查询可以同时比较多个字段,常用于订单明细、配置信息等多列匹配。
4. 表子查询(返回多行多列)
表子查询返回多行多列,常作为临时表在外部查询中使用,可用于聚合统计或复杂数据计算。
示例:查询每个订单的总金额
sql
SELECT t.order_id, t.total_amount
FROM (
SELECT oi.order_id, SUM(p.price * oi.quantity) AS total_amount
FROM order_item oi
JOIN product p ON oi.product_id = p.id
GROUP BY oi.order_id
) t;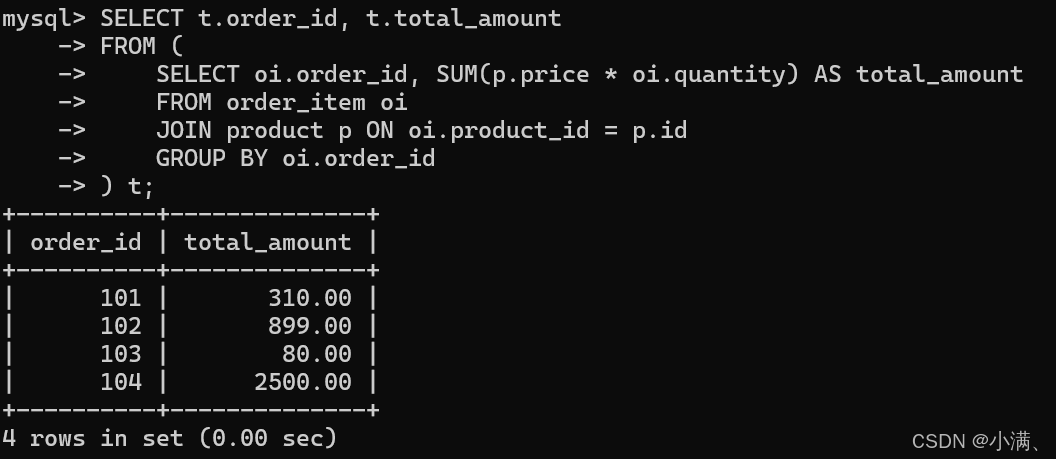
说明:子查询生成了一个临时表 t ,外部查询直接使用聚合结果,避免了重复计算。
六、事务
(一)事务简介
事务(Transaction)是数据库中的一个逻辑执行单元,由一组操作构成,这些操作要么全部成功、要么全部失败,是不可分割的整体。
例如,银行转账属于典型事务场景:
A 给 B 转 100 元
操作包含:A 账户扣 100、B 账户加 100
两步必须要么都成功,要么都失败,否则会造成资金丢失
MySQL 默认自动提交(autocommit)
MySQL 默认开启 autocommit = 1:
每执行一条 DML(INSERT/UPDATE/DELETE)语句,MySQL 自动提交一个事务。
sql
SELECT @@autocommit;如果想把一个事务中的操作"打包提交",必须关闭自动提交:
sql
SET @@autocommit = 0;(二)事务操作
方式一:使用 autocommit 控制事务
1. 查看 / 设置事务的提交方式
sql
SELECT @@autocommit; -- 查看当前事务提交方式
SET @@autocommit = 0; -- 设置为手动提交2. 手动提交事务
sql
COMMIT;3. 手动回滚事务
sql
ROLLBACK;方式二:显式开启事务
当你想手动控制事务时:
sql
START TRANSACTION;
-- 或
BEGIN;执行操作后:
sql
COMMIT; -- 提交
ROLLBACK; -- 回滚(三)事务四大特性(ACID)
原子性(Atomicity): 事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
一致性(Consistency): 事务完成时,必须使所有的数据都保持一致状态。
隔离性(Isolation):不同事务之间相互隔离,并发执行不互相影响。
持久性(Durability):事务一旦提交,结果永久保存,即使宕机也不会丢失。
(四)并发事务问题
多事务同时执行,会产生如下典型问题:
| 问题 | 描述 |
|---|---|
| 脏读(Dirty Read) | 读到了另一个事务未提交的数据 |
| 不可重复读(Non-repeatable Read) | 同一事务,多次读取 同一记录,结果不一致 |
| 幻读(Phantom Read) | 同一事务内多次执行 范围查询,数据行数不一致 |
(五)事务隔离级别
| 隔离级别(从低到高) | 脏读(Dirty Read) | 不可重复读(Non-repeatable Read) | 幻读(Phantom Read) | 说明 |
|---|---|---|---|---|
| Read Uncommitted | ✔(会出现) | ✔(会出现) | ✔(会出现) | 几乎没有隔离,问题最多 |
| Read Committed | ✖(不会出现) | ✔(可能出现) | ✔(可能出现) | Oracle 默认级别 |
| Repeatable Read(MySQL 默认) | ✖ | ✖ | ✔(理论上可能) | MySQL 通过间隙锁减少幻读 |
| Serializable | ✖ | ✖ | ✖ | 完全串行执行,无并发问题 |
隔离级别越高,数据越安全
并发性能越差
查看当前隔离级别
sql
SELECT @@TRANSACTION_ISOLATION;修改隔离级别
sql
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;级别可选:
READ UNCOMMITTED
READ COMMITTED
REPEATABLE READ
SERIALIZABLE
(六)事务隔离级别演示
为了更直观地理解事务隔离级别对数据库并发行为的影响,我们可以使用两个独立的 CMD 窗口分别启动两个 MySQL 客户端实例,通过模拟两个并发事务,观察四种典型并发问题的实际发生过程。
1. 准备测试环境
执行以下 SQL,创建并初始化测试库:
sql
CREATE DATABASE test_tx;
USE test_tx;
-- 账户表(用于脏读与不可重复读演示)
CREATE TABLE account (
id INT PRIMARY KEY,
balance INT
);
INSERT INTO account VALUES (1, 1000);
-- 订单表(用于幻读演示)
CREATE TABLE orders (
id INT AUTO_INCREMENT PRIMARY KEY,
amount INT
);
INSERT INTO orders(amount) VALUES (200), (300), (150);
2. 脏读(Dirty Read)演示
脏读指的是一个事务读取到了另一个事务 尚未提交 的数据,只会在 READ UNCOMMITTED 隔离级别下出现。
(1)两个窗口均设置隔离级别
sql
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;(2)模拟过程
CMD1(修改但不提交)
sql
START TRANSACTION;
UPDATE account SET balance = 500 WHERE id = 1;
-- 不提交事务CMD2(读取未提交数据)
sql
SELECT balance FROM account WHERE id = 1;CMD2 会读取到 500,即 CMD1 尚未提交的数据,这就是典型的脏读。
CMD1 回滚:
sql
ROLLBACK;
3. 不可重复读(Non-repeatable Read)演示
不可重复读是指同一个事务内的两次查询结果不一致,通常在 READ COMMITTED 下发生。
(1)设置隔离级别
sql
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;(2) 模拟过程
CMD1:开启事务并读取数据
sql
START TRANSACTION;
SELECT balance FROM account WHERE id = 1; -- 结果:1000CMD2:修改并提交
sql
UPDATE account SET balance = 800 WHERE id = 1;
COMMIT;CMD1:再次读取
sql
SELECT balance FROM account WHERE id = 1; -- 结果:800,与第一次不同这就是"不可重复读":同一个事务中,两次读取同一行数据却得到了不同结果。
CMD1 结束事务
sql
COMMIT;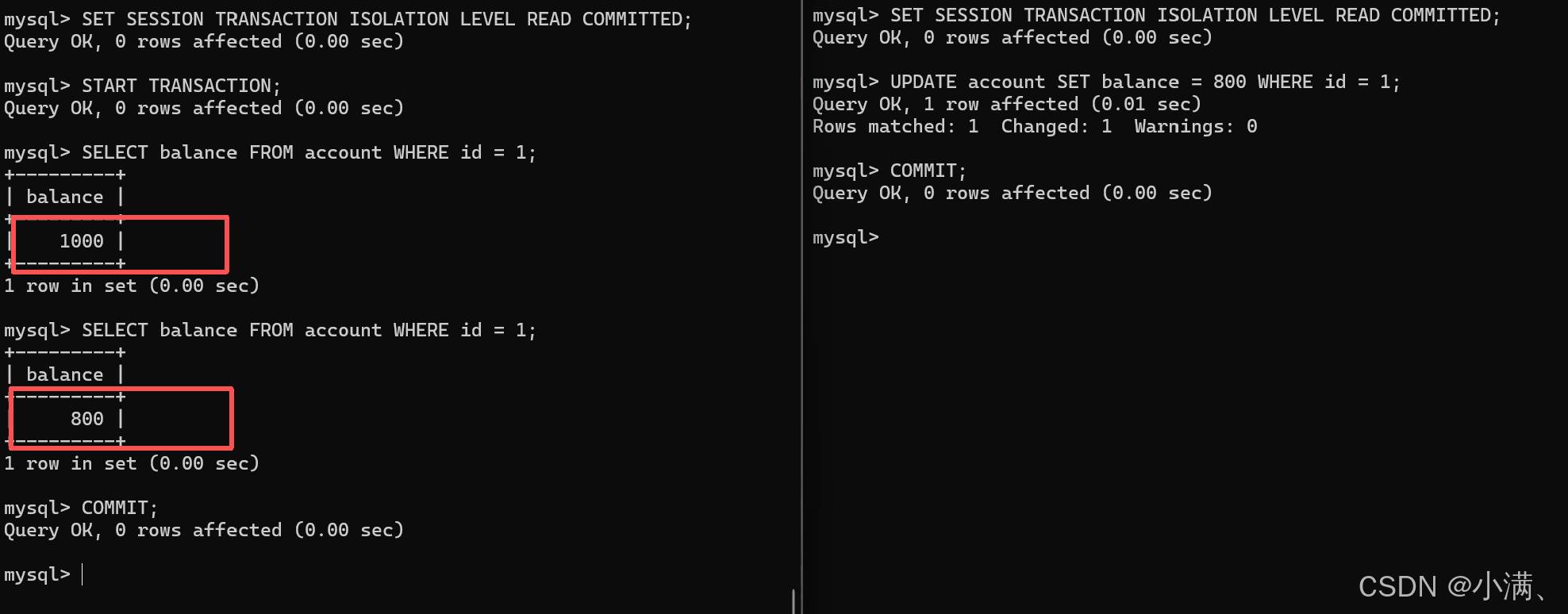
4.幻读(Phantom Read)演示
幻读是指事务在按某个范围条件查询时,发现后续的查询结果出现了"凭空多出的记录"。在 READ COMMITTED 和 Repeatable Read(MySQL 默认) 下理论上都可能发生幻读。
为简化演示,我们使用 READ COMMITTED
(1)设置隔离级别
sql
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;(2)模拟操作
CMD1:第一次查询
sql
START TRANSACTION;
SELECT * FROM orders WHERE amount > 100;
-- 结果:3 行CMD2:插入满足条件的新数据
sql
INSERT INTO orders(amount) VALUES (500);
COMMIT;CMD1:再次查询
sql
SELECT * FROM orders WHERE amount > 100;
-- 结果:4 行,比第一次多一行这条"凭空出现"的记录就是幻读(Phantom Row)。
CMD1 提交事务
sql
COMMIT;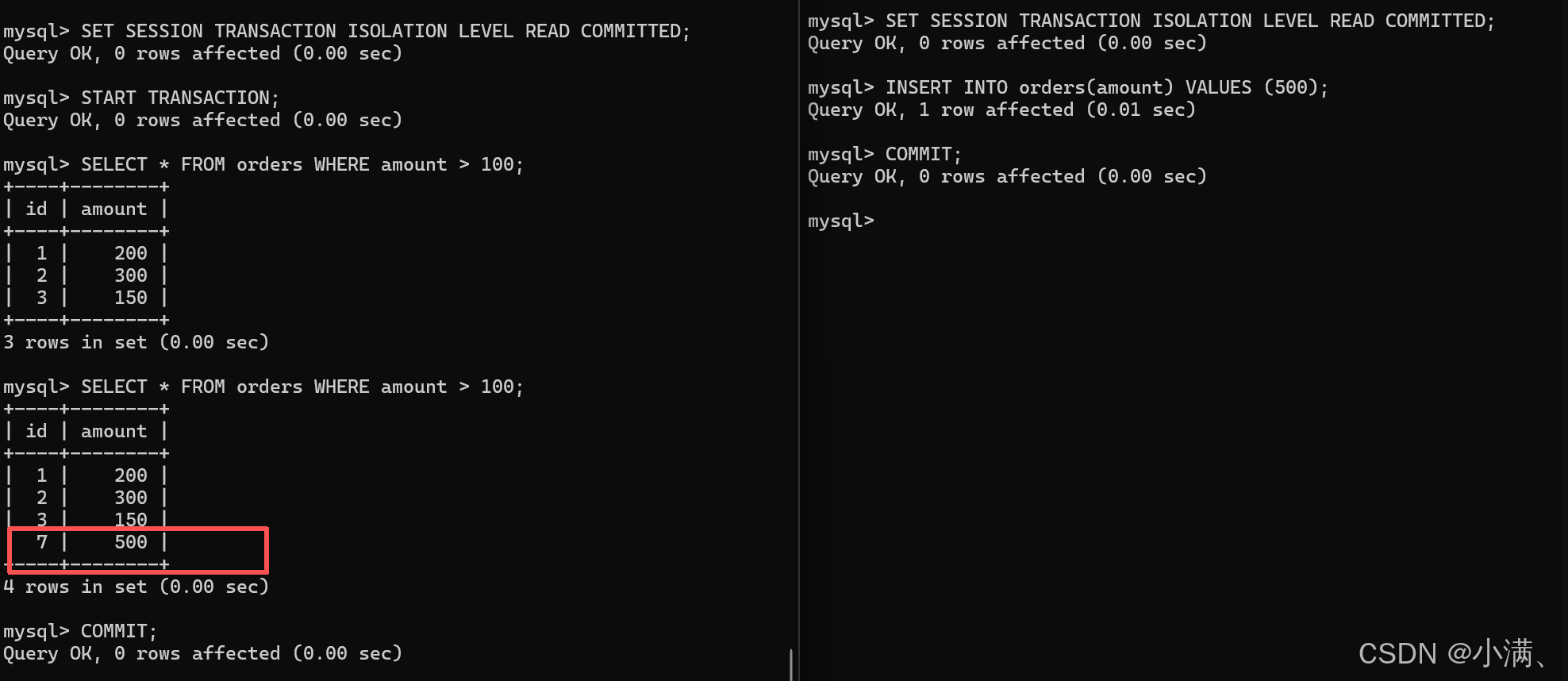
5. 验证最高隔离级别 Serializable
Serializable 是最严格的隔离级别,会强制所有读取操作加锁,使并发行为表现为串行执行,从而完全避免幻读。
(1)设置隔离级别
sql
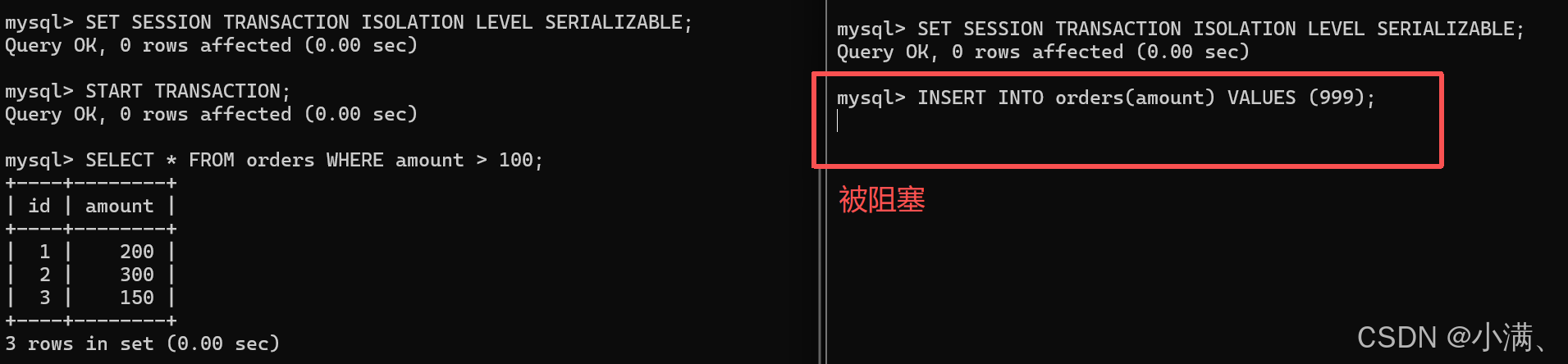
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;(2)模拟过程
CMD1:
sql
START TRANSACTION;
SELECT * FROM orders WHERE amount > 100;CMD2(尝试插入新数据):
sql
INSERT INTO orders(amount) VALUES (999);此时 CMD2 会被阻塞,直到 CMD1 完成提交,因为 Serializable 会对读范围加锁,从根源上消除幻读。
在演示 MySQL 的事务隔离级别(如脏读、不可重复读、幻读等)时,将两个 CMD 窗口都设置为相同的隔离级别是完全可行的,也是教学和实验中最常用的做法。
严格来说,实际上只有涉及读取数据的窗口需要设置隔离级别即可,但为了保证实验环境的一致性、避免干扰和减少理解难度,建议在实际演示时,两侧窗口都显式地设置隔离级别。