1、准备数据
上一篇,使用AnyLabeling对图片进行了标注,当标注完成后,在图片所在的文件夹内会生成与每个图片同名的json文件,当再次使用AnyLabeling导入图片文件夹时,json文件会一同被导入,方便再次编辑和导出。这些json文件内包含了每个同名图片的标注数据。
这篇,将学习如果获取用于YOLO实例分割的数据集。
- 目录结构
预期的YOLO项目下训练文件的目录结构是这样的:
python
ultralytics-main
├──datasets
├── images/
│ ├── train/
│ ├── var/
│ ├── test/
├── labels/
│ ├── train/
│ ├── valr/
│ ├── test/
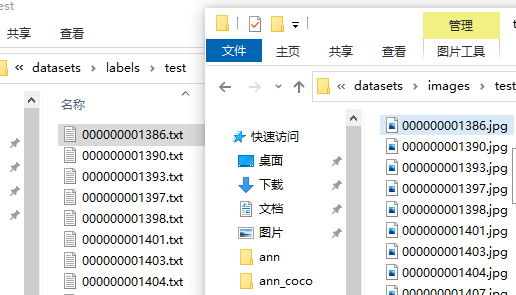
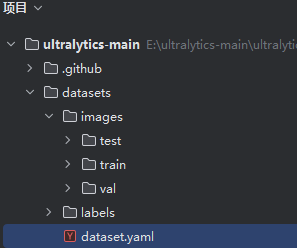
├── dataset.yamlimags目录下保存图片,按照用途的不同又分为train(训练集)、var(验证集)和test(测试集),labels目录下保存与images目录下图片文件的同名txt文件,dataset.yaml是训练配置文件。如图:
- 标注文件格式
YOLO对实例分割的标注文件格式要求如下:
https://blog.csdn.net/xulibo5828/article/details/145657008
每行的内容:
class x1 y1 x2 y2... xn yn
其中 class 是类别索引,后面跟着目标轮廓上一系列点的归一化坐标(x 和 y 交替出现)。
之前用AnyLabeling对图片标注完成后,在图片所在的文件夹内生成的与图片同名的json文件,其内容格式如下:
python
{
"version": "0.4.30",
"flags": {},
"shapes": [
{
"label": "人",
"text": "",
"points": [
[
303.0,
146.0
],
[
295.0,
152.0
],
],
"group_id": null,
"shape_type": "polygon",
"flags": {}
},
{
"label": "钟表",
"text": "",
"points": [
[
0.0,
0.0
],
[
0.0,
34.0
],
[
9.0,
34.0
],
[
10.0,
33.0
]
],
"group_id": null,
"shape_type": "polygon",
"flags": {}
}
],
"imagePath": "000000000294.jpg",
"imageData": null,
"imageHeight": 427,
"imageWidth": 640
}其中的"label"是标签名称,"points"是轮廓点位。我需要做的就是将这两个内容提取出来,写入每一个与图片同名的txt文件。
生成数据,复制文件
创建以下脚本在项目根目录下,并运行:
python
import json
import os
import shutil
from pathlib import Path
import yaml
def convert_AnyLabeling_to_YOLO(source_path, target_path, copy_image=False, divide_train_val=True):
# 创建目标文件夹
os.makedirs(os.path.join(target_path, 'labels', 'train'), exist_ok=True)
os.makedirs(os.path.join(target_path, 'labels', 'val'), exist_ok=True)
os.makedirs(os.path.join(target_path, 'labels', 'test'), exist_ok=True)
os.makedirs(os.path.join(target_path, 'images', 'train'), exist_ok=True)
os.makedirs(os.path.join(target_path, 'images', 'val'), exist_ok=True)
os.makedirs(os.path.join(target_path, 'images', 'test'), exist_ok=True)
file_idx = 0 # 当前处理文件的索引(用来区分训练集和验证集)
classes_file = os.path.join(source_path, 'classes.txt') # 类别文件,所有分类标签
yaml_file = os.path.join(target_path, 'dataset.yaml') # 设置文件
# 读取json文件
jsons = list(Path(source_path).resolve().glob("*.json")) # 获取json文件列表
jsons_count = len(list(jsons)) # json文件数量
# 标签类别文件的处理
if not os.path.exists(classes_file): # 如果不存在标签类别文件,则创建一个空文件
with open(classes_file, 'w', encoding='utf-8') as cf:
cf.write('')
with open(classes_file, 'r+', encoding='utf-8') as cf:
classes = cf.read().splitlines() # 读取标签类别文件中的所有标签,并存储在列表中
# 从json文件中读取标签类别并写入标签类别文件
for file in jsons:
with open(file, 'r', encoding='utf-8') as jf:
data = json.load(jf)
for d in data['shapes']:
if d['label'] not in classes:
classes.append(d['label'])
cf.write(f"{d['label']}\n")
if divide_train_val and jsons_count < 10:
print(f"{source_path} 文件夹中json文件数量小于10,不进行转换")
return
# 开始转换json文件
for json_file in jsons:
# 读取json文件并获取数据
file_name = json_file.stem # 文件名(不带后缀)
with open(json_file, encoding="utf-8") as f:
data = json.load(f) # json数据
# 数据集的划分
if file_idx < jsons_count * 0.7:
purpose = 'train'
elif file_idx < jsons_count * 0.9:
purpose = 'val'
else:
purpose = 'test'
if not divide_train_val: # 如果不划分训练集和验证集,则全部写入训练集
purpose = 'train'
h, w = data['imageHeight'], data['imageWidth'] # 图片的宽度和高度
# 写入标注文件
with open(os.path.join(target_path, 'labels', purpose, file_name + '.txt'), 'w') as f:
for d in data['shapes']:
label_idx = str(classes.index(d['label'])) # 类别在类别表中的索引顺序
points = d['points']
line = label_idx # 写入类别索引(每一行的第一个数字)
# 写入坐标点
for point in points:
x = point[0] / w
y = point[1] / h
x = max(0, min(1, x))
y = max(0, min(1, y))
x = round(x, 6)
y = round(y, 6)
line += ' ' + str(x) + ' ' + str(y)
line += '\n' # 写入换行符
f.write(line)
# 如果需要复制图片到images文件夹中,则复制图片到images文件夹中
if copy_image:
jpg_file = os.path.join(source_path, file_name + '.jpg')
png_file = os.path.join(source_path, file_name + '.png')
if os.path.exists(jpg_file):
shutil.copy(jpg_file, os.path.join(target_path, 'images', purpose, file_name + '.jpg'))
if os.path.exists(png_file):
shutil.copy(png_file, os.path.join(target_path, 'images', purpose, file_name + '.png'))
file_idx += 1
# 设置文件的处理
if not os.path.exists(yaml_file): # 如果不存在yaml文件,则创建一个空文件
with open(yaml_file, 'w', encoding='utf-8') as f:
f.write('')
with open(yaml_file, 'r+', encoding='utf-8') as f:
data = yaml.safe_load(f) or {}
data['path'] = target_path
data['train'] = os.path.join('..', 'images', 'train')
data['val'] = os.path.join('..','images', 'val')
data['test'] = os.path.join('..','images', 'test')
data['nc'] = len(classes)
data['names'] = classes
yaml.dump(data, f, allow_unicode=True, default_flow_style=False, sort_keys=False)
print(f"{source_path} 文件夹中的json文件转换完成")
if __name__ == '__main__':
convert_AnyLabeling_to_YOLO(r'E:\images', r'datasets', copy_image=True)执行完成后,会在AnyLabeling图片文件夹内生成一个classes.txt文件:
classes.txt文件内容是该目录下所有的图片标注时用过的标签:

并且会在项目中生成图片文件夹和标注文件夹:
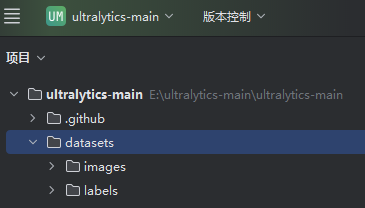
以及复制训练图片和生成标注文件
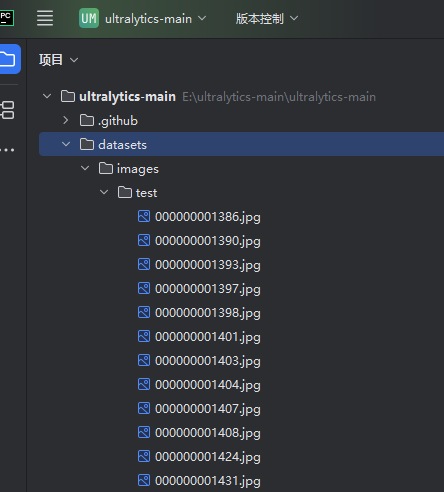
和生成配置文件dataset.yaml。
另外需要知道的是,AnyLabeling导出的YOLO格式数据是用于目标检测和分类检测的,不能用于实例分割。需要用AnyLabeling导出coco格式后再用ultralytics自带的工具来转换成YOLO数据集(ultralytics.data.converter.convert_coco),才能用于实例分割。由于AnyLabeling对中文的支持不好,导出coco格式时生成的json文件中文是字节形式,需要再编写代码转换成汉字。
如图,AnyLabeling生成的json文件中,中文是以字节方式保存的:
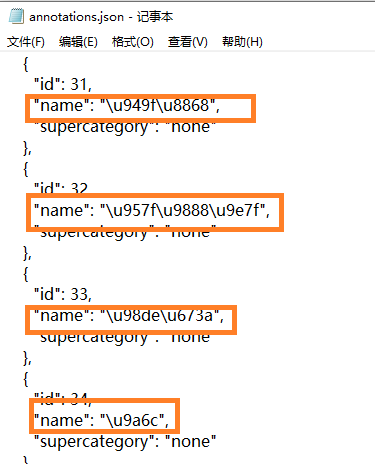
AnyLabeling导出coco格式还有个问题,就是图片比较多,分多次标注和导出时,它的分类标签的顺序可能是不固定的,某一个分类,比如"长颈鹿",第一次导出时在annotations.json中的序号可能是2,下一次可能就是3,这就给后面的训练带来了隐患,有可能使模型认错种类。所以,我才编写了上面的脚本,在图片目录中创建classes.txt文件,把标签顺序固定下来,即使多次标注和导出,和新增了种类标签,原先的标签种类和顺序也不会改变。
2、训练
windows下需要打开anaconda prompt命令行窗口,Ubuntu直接打开命令行窗口即可,激活安装ultralytics时创建的虚拟环境,然后用cd指令切换到本地ultralytics下的datasets\目录下,输入命令:
python
yolo task=segment mode=train model=yolo11s-seg.yaml data=dataset.yaml epochs=10 imgsz=640 batch=4 device=0 workers=1命令解释:
- task=segment:任务类型为实例分割
- mode=train:模式为训练
- model=yolo11s-seg.yaml:使用的基础模型是 YOLOv11 的 small 版本(yolo11s),但是不用它的预训练权重(从头训练),如果使用预训练权重,将该段指令改为:model=yolo11s-seg.pt
- model=yolo11s-seg.pt:使用的基础模型是 YOLOv11 的 small 版本(yolo11s)的预训练分割模型
- data=dataset.yaml:指定数据集配置文件,包含训练集 / 验证集路径、类别信息等
- epochs=10:训练总轮次为 10 轮
- imgsz=640:输入图像的尺寸统一调整为 640x640 像素
- batch=4:每批处理 4 张图像
- device=0:指定使用第 0 号 GPU 进行训练(若为 cpu 则使用 CPU)
- workers=1:使用1个并行进程训练,提高效率
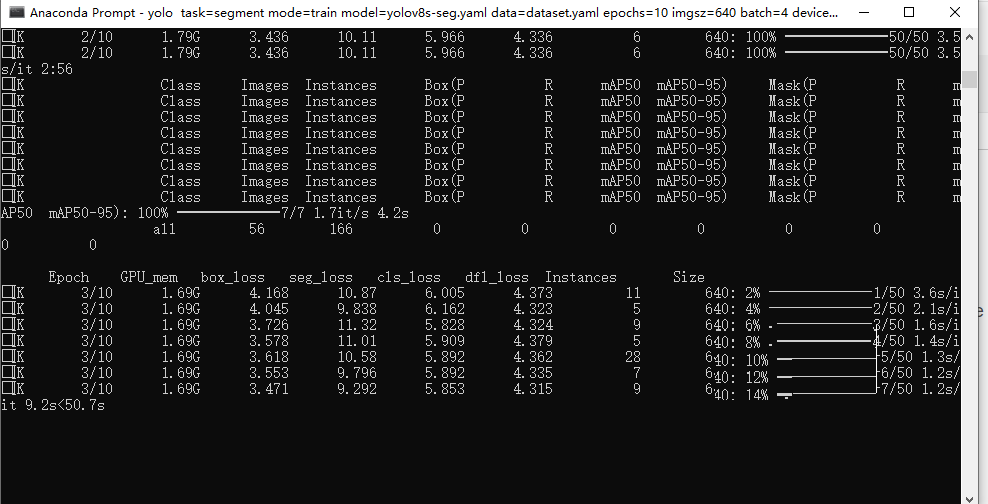
开始训练:
由于使用了中文标签,需要进行设置,使matplot支持中文字体输出,方法见:
https://blog.csdn.net/xulibo5828/article/details/154879460
训练完成后,会得到模型以及各种过程曲线:
本例只是演示了训练模型的方法,使用了较少数量的图片(35类,约300张图片)和10个epochs。如果想得到更好的训练效果,就需要更多的训练图片和更多轮的训练。