Ai-Agent学习历程------ 阶段1------环境的选择、Pydantic基座、Jupyter Notebook的使用
- 概述
- 一、Conda
-
- [1.1 Conda的定义](#1.1 Conda的定义)
- [1.2 为什么Conda是AI领域的标准](#1.2 为什么Conda是AI领域的标准)
- [1.3 Conda和Pycharm什么关系](#1.3 Conda和Pycharm什么关系)
- [1.4 安装conda(重点)](#1.4 安装conda(重点))
- [1.5 使用Conda](#1.5 使用Conda)
- [二、Jupyter Notebook(按需选择)](#二、Jupyter Notebook(按需选择))
-
- [2.1 定义](#2.1 定义)
- [2.2 原生浏览器模式](#2.2 原生浏览器模式)
- [2.3 PyCharm 集成模式](#2.3 PyCharm 集成模式)
- [2.4 Jupyter的使用原理](#2.4 Jupyter的使用原理)
- [2.5 Jupyter的优势和劣势](#2.5 Jupyter的优势和劣势)
- 三、Pydantic(数据验证)
-
- [3.1 必备四大知识点](#3.1 必备四大知识点)
-
- [1. BaseModel(基类)](#1. BaseModel(基类))
- [2. Field (字段元数据)](#2. Field (字段元数据))
- [3. Type Hints (类型提示与嵌套)](#3. Type Hints (类型提示与嵌套))
- [4. @field_validator (自定义业务校验)](#4. @field_validator (自定义业务校验))
- [3.2 AI调用场景设计](#3.2 AI调用场景设计)
- [3.3 代码实践](#3.3 代码实践)
- 修正创建项目的配置(C盘会多一份Conda文件)
- 总结
概述
💡 基于Gemini 和 Bilibili 的辅助,我对阶段一已经有了一个完整的理解,现在我们将进入阶段一的学习,这一章还是为了准备,所谓完事开头难,当我们计划好之后,如何开始学习,从哪一个方向进行切入是重中之重,不然很可能会浪费时间。
📝 这一章围绕三个知识点:
- Conda :一个
管理系统 - Pydantic :基于 Python 类型提示的
数据验证与设置管理库,对标Java的Class中各种技术,比如类型校验、格式映射等。 - Jupyter Notebook :一个基于 Web 的
交互式计算环境
先不要着急,我们慢慢来解释这几个知识点,虽然我们可能有些用不着,但这是我们在学习过程中必须面对的几种技术,这是主流,只是我们目前的阶段使用的比较少或者在下一个阶段使用。
一、Conda
1.1 Conda的定义
💡 Conda是一个开源的软件包管理系统和环境管理工具。
📝 类比:Maven + Docker 的结合体,可以安装不同版本的Python,使用命令切换到某一个环境,然后安装指定的依赖(这一点也有些像Nvm),同时也可以部署多个容器,不同的容器跑不同的项目。
- 包管理器(Maven):下载和安装不同的库。
- 环境管理器 (Docker):同时创建多个
独立的容器,不同的容器安装不同版本的环境并运行项目。
1.2 为什么Conda是AI领域的标准
Python版本任意切换
⚠️ 正常的Python + venv 手段是基于同一个Python解释器的,也就是只能是一个版本,如果你想要运行另外版本的Python代码是不行的,它只起到同一个环境下不同项目的隔离。
💡 而Conda仓库直接包含了Python解释器本身,就像上面说的,创建一个容器,安装不同版本的Python直接运行,毫无压力,随意切换。
而且还有一点,有些Agent不是基于最新的Python版本,甚至有些是老的版本,如果要用你岂不是得重新安装一个Python,那之前的代码怎么办捏,又跑不了了。
解决依赖地狱
⚠️ AI领域的大量库(如 NumPy, PyTorch, Faiss, TensorFlow)底层是用 C/C++ 写的,不仅仅是 Python 代码。所以你要安装对应的依赖那可就多了,你的小机器可能扛不住,而且管理很麻烦。
💡 Conda仓库里面的包是预编译好的二进制文件,不需要进行二次编辑,直接运行,这就省得你搭建了,能大大节省你的环境搭建问题,这才是核心。
1.3 Conda和Pycharm什么关系
关于Conda的作用我们已经说清楚了,但实际上Conda怎么在我们的开发中使用呢?这和Pycharm开发工具的联系又是什么呢?
首先我们清楚一点,是一个工具系统,在Java开发中的等价关系为:
Conda = JDK + Tomcat + Maven
正常我们运行Java的时候是需要安装jdk进行编译,然后使用Maven下载依赖,然后利用Tomcat容器启动web项目,而Python是我们的编译环境,如果没有Conda,我们直接使用本地的Python环境启动项目即可,但是Conda给我们便利,一个独立的工作环境。
- 切记,不需要卸载原有的Python环境 ,我们直接安装Conda,在Conda中安装Python,代码还是在Pycharm中编写,只需要将
运行的环境从本地换到Conda环境即可。
1.4 安装conda(重点)
⚠️ 不建议跟着网上或者bilibili的教程走,我的安装思路稍有不同,但整体更适合正常开发。
首先conda分为两种:
- Miniconda :
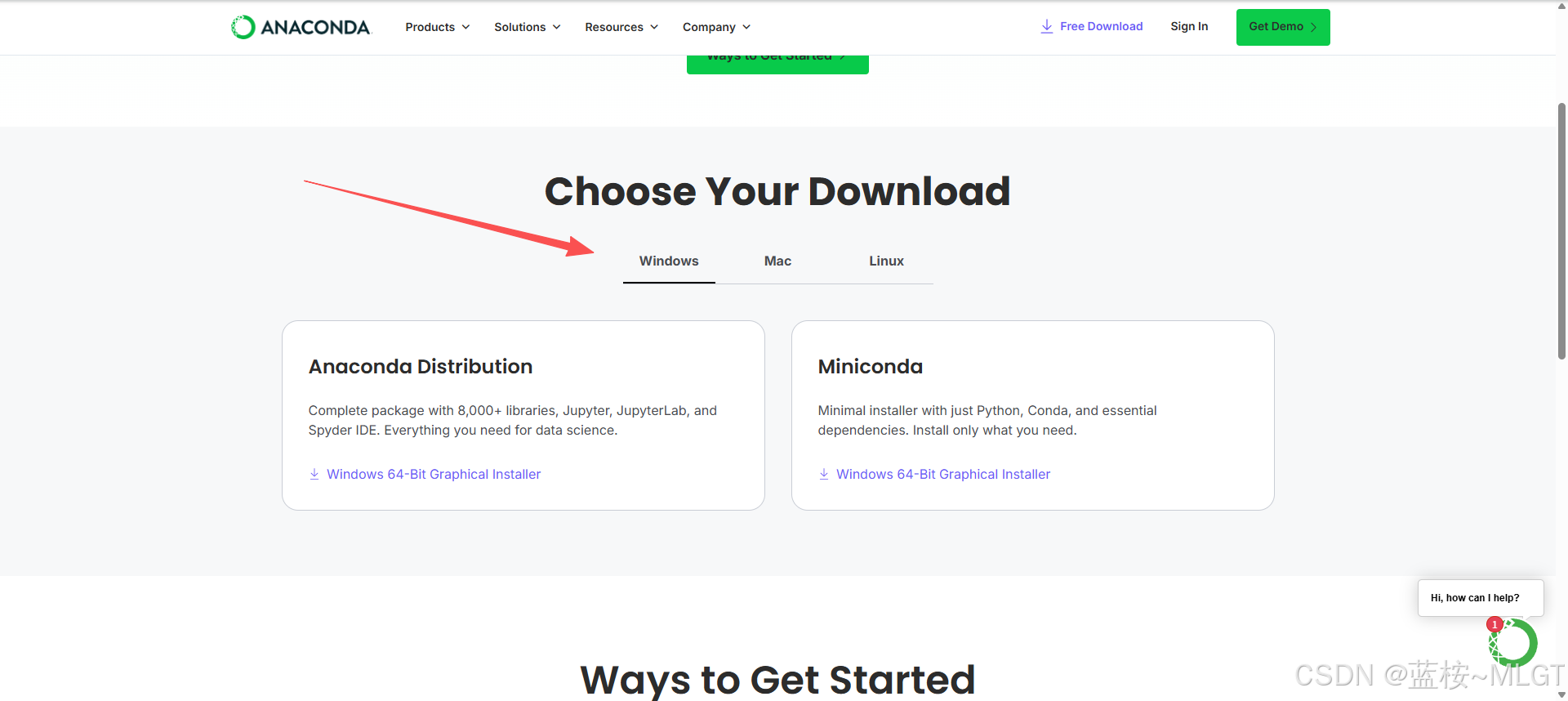
精简版,只包含conda核心和Python,后面按需下载即可,占用内存不到1G,推荐! - Anaconda :
标准版,预装了Anaconda Navigator和几百个数据包等,占用内存大(3-5G),一般预下载的就够用了,但不推荐,很臃肿(虽然我不小心下载了哈哈哈)。
如何下载Miniconda
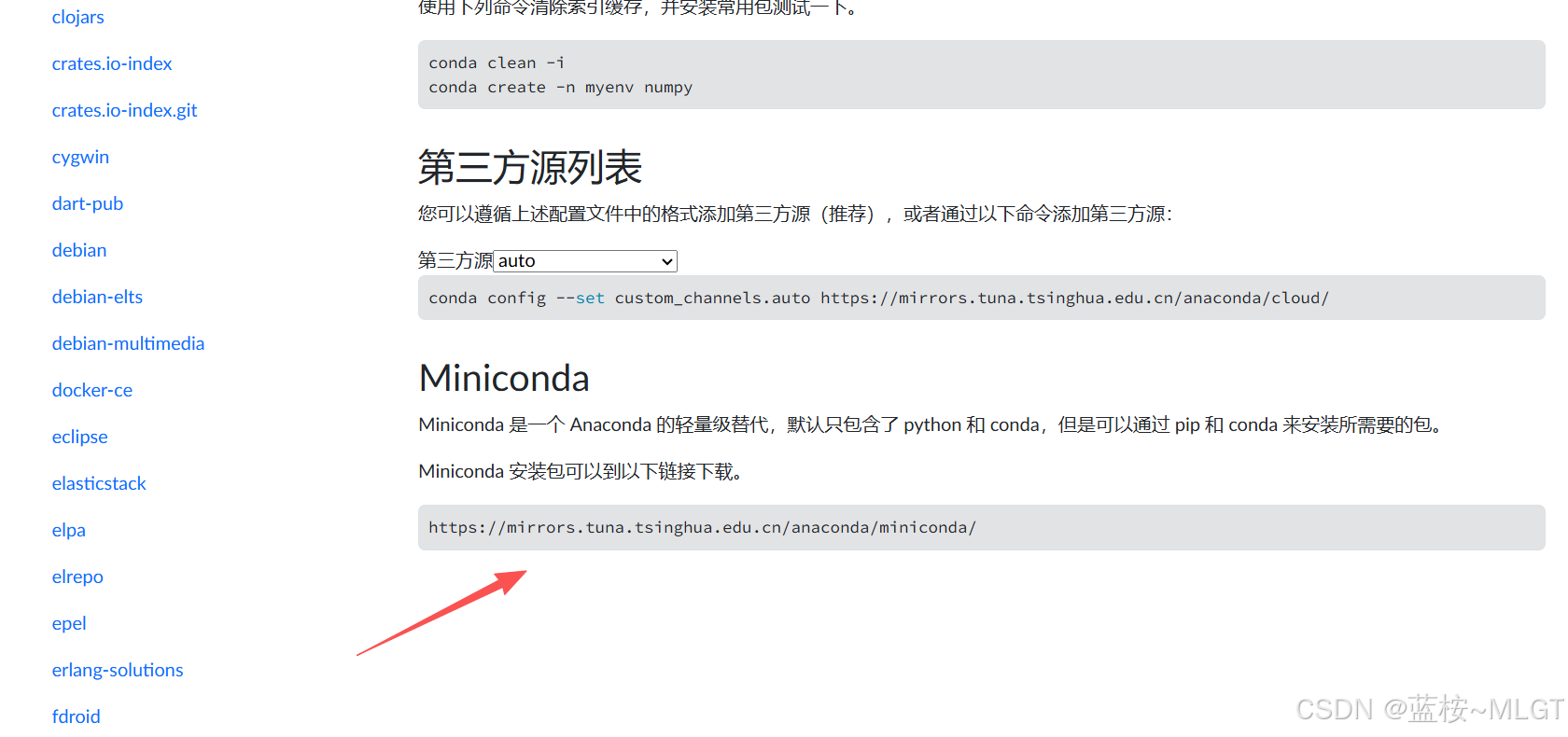
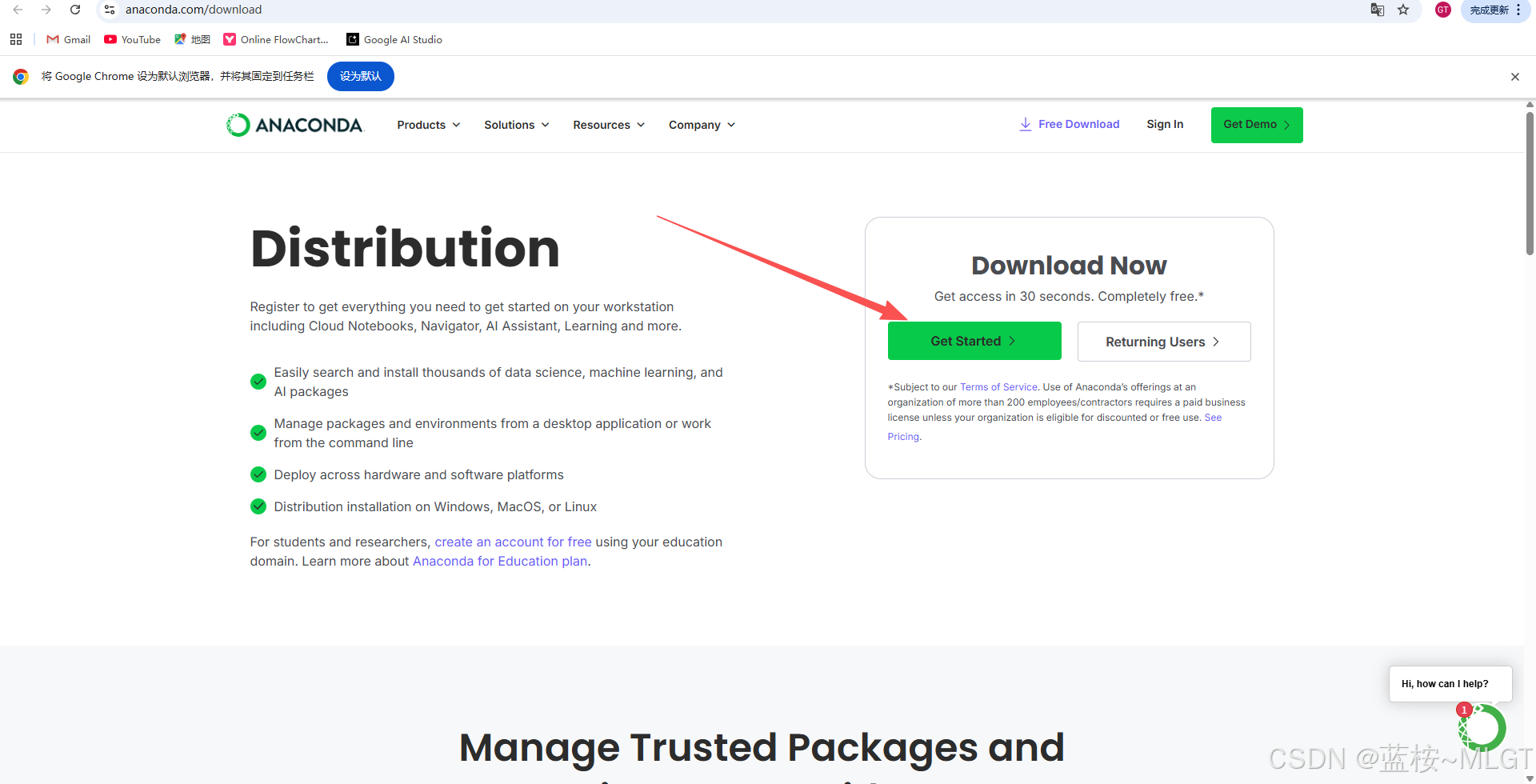
- Conda官网 :官网需要VPN访问 ,下载需要登录账号 ,一般使用Google账号登录。Conda官网
安装注意事项:
- Create start menu shortcuts (默认勾选) -> 保持勾选。
- Add Miniconda3 to my PATH environment variable (默认不勾选) ->
强烈建议不要勾选! - Register Miniconda3 as my default Python 3.11",建议勾选
📝 我们按照流程选择安装位置,勾选即可,但非常不建议勾选自动添加环境变量,很可能会把系统的DLL搞乱,尤其是你的系统中安装了大量其它开发环境的时候比如Java、Node、Maven以及原生的Python等等,更别说Python用爬虫的时候还需要安装Proxifier等等工具了。

安装好之后点击window按钮会出现这些,注意,我们如果直接在com中使用conda --version命令是不会生效的,因为我们没有配置环境变量,也不需要,所以直接打开Anaconda Prompt命令窗口,这是Conda自带的命令行工具。
这里我们就安装好了,同时安装完成之后会自动运行Anaconda Navigator,关闭即可,我们不需要使用这个可视化页面,一个是非常吃内存,一个是操作复杂,命令行完全可以满足我们的需求。
1.5 使用Conda
首先查看我当前安装的Python版本(这是cmd窗口,Conda使用自带的Conda窗口)
使用Conda创建一个测试空间(打开Conda自带窗口)
📝 创建命令:conda create -n hello_test python=3.10 -y(-y 表示自动确认)

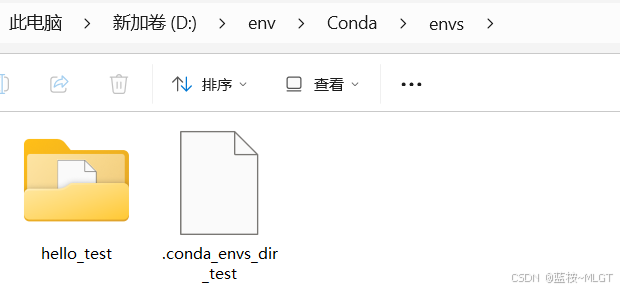
💡 创建成功后我们可以在对应安装的目录中发现我们创建的独立空间。
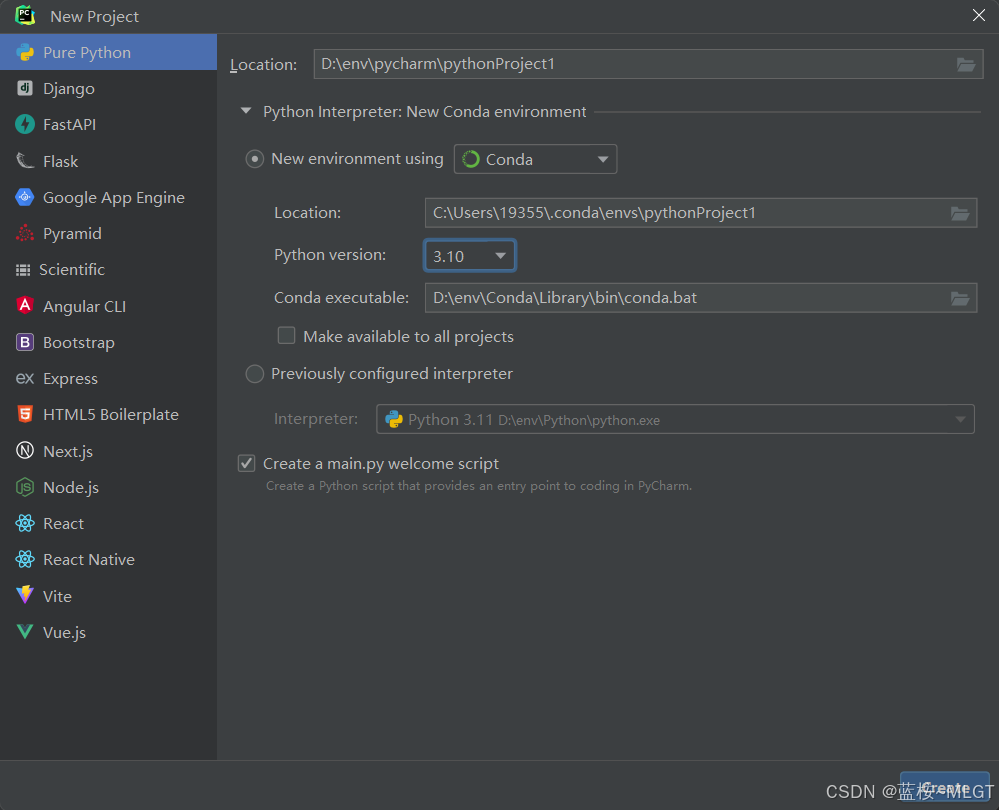
接下来直接使用Pycharm创建新的项目,将环境指向Conda即可,Pycharm会自动选择对应的项目和启动脚本位置,如果没有就重启一下或者手动选择。
python
def print_hi(name):
import sys
# 1. 打印 Hello World
print("Hello World! ")
# 2. 打印分隔线
print("-" * 50)
# 3. 验证当前使用的 Python 环境路径
# 这相当于 Java 中的 System.getProperty("java.home")
print(f"当前 Python 解释器路径: {sys.executable}")
# 4. 验证 Python 版本
print(f"当前 Python 版本: {sys.version}")
if __name__ == '__main__':
print_hi('PyCharm')验证一下第一个Hello World程序,我的Python自带版本是3.11,使用Conda安装3.10

二、Jupyter Notebook(按需选择)
2.1 定义
💡 它是一个 B/S 架构 的 Web 应用。
- Server 端 (Kernel): 负责运行 Python 代码(类似 JVM)。
- Browser 端 (UI): 让你在一个网页里编写代码、写文档(Markdown)、查看图表。
💡 文件格式 : .ipynb (Interactive Python Notebook),它本质上是一个巨大的 JSON 文件。它把你的代码、Markdown 文本、甚至运行结果(包括图片)都编码成 JSON 存在里面
简单点来说就是将代码的编写和运行进行了拆解,之前的代码运行时如果修改就需要重启服务,在AI的调试过程中,我们是不需要频繁的创建连接的,而且代码中会存在不断的检查机制(比如模型是否可用),这种不需要多次进行,比较浪费Token。所以Jupyter Notebook就会将代码切割,一些不必要的变量会存入内存,不需要再次初始化。
2.2 原生浏览器模式
⚠️ 如果你是通过清华镜像安装的Conda不会自带Jupyter,你需要手动安装,这个自行安装一下。

第一步:打开Jupyter,会出现一个黑色的cmd,不能关闭,等会儿会自动打开浏览器8888端口,相当于运行dubbo一样,会出现一个可视化操作页面。
不好意思没有第二步了哈哈哈,因为这种方式我们几乎不会使用,只是了解一下,主要战场还是在Pycharm中,想研究的可以在这里面创建项目和运行项目。
2.3 PyCharm 集成模式
步骤1:创建Jupyter文件。
步骤2:编写代码并运行。(运行前Pycharm得安装Jupyter包,一般会自动提示)

2.4 Jupyter的使用原理
📝 正常的操作步骤我们已经说明了,这里需要理解一下它的使用原理是什么,这里一个Cell标记一个代码块,可以单独运行某一个代码块,然后它的变量就会存储在内存中,只要不停止可以一直在。之后我们继续添加Cell,编写代码,然后运行就可以得到我们想要的结果。
2.5 Jupyter的优势和劣势
| 维度 | 优势 (Pros) | 劣势 (Cons) |
|---|---|---|
| 开发体验 | 即时反馈 (REPL)。写一行跑一行,特别适合调试 API 和数据处理。 | 容易写出面条代码。因为随意跳转执行顺序,逻辑容易混乱。 |
| 可视化 | 图表内嵌。matplotlib 画的折线图直接显示在代码下面,不用弹窗。 | 版本控制噩梦。.ipynb 是 JSON,且包含图片 Base64,Git Diff 根本看不懂变更了啥。 |
| 文档性 | 代码即文档。非常适合写教程、做实验记录、展示 Demo。 | 难以复用。你很难在其他项目里 import 一个 .ipynb 文件。 |
| 工程化 | 0 分。不适合写复杂的业务逻辑或微服务。 | 不适合生产部署。上线时必须重构为 .py 文件。 |
从目前来看,这种写法有它的优势,只不过正常我觉得我们是不会习惯的,但是知道一下总没有坏处,说不定之后再开发中我们会需要这种写法,真的,这种写法和拼积木一样。
虽然说这对调试Prompt很有效,但说实话还不如重启呢,毕竟在学习,也不差那点儿Token,根据个人喜好自己切换吧。
三、Pydantic(数据验证)
💡 在Agent开发中,Pydantic扮演的角色是 DTO(数据传输对象)和 Validation(校验器),过程中我们必须要用到的几个知识点如下:
如果对这部分不熟悉的可以直接看我的另一篇博客 Python面向对象,里面包含了所有的相关知识,还有很多扩展。
3.1 必备四大知识点
1. BaseModel(基类)
- 定义:所有数据模型的父类
- 作用 :不仅仅只是存放数据的对象,还会在构造时主动尝试转换数据类型
- 例子:
python
from pydantic import BaseModel
class User(BaseModel):
id: int
name: str
# 传入字符串 "123",它会自动转为 int 123
u = User(id="123", name="JavaDev")
print(u.id) # 输出 123 (int类型)2. Field (字段元数据)
- 定义: 用于给字段添加"
额外信息"和"基础约束"。 - 作用: LLM返回的结果会根据 Field 的
description属性修正结果。 - 例子:
python
from pydantic import Field
class Product(BaseModel):
# description 会直接变成 Prompt 的一部分
price: float = Field(description="商品的最终售价,保留两位小数", gt=0)3. Type Hints (类型提示与嵌套)
- 定义: Python 的
泛型表达, 和TypeScript类似,对字段进行类型限制。 - 作用: 支持复杂的嵌套结构,将AI返回的复杂JSON进行整理。
- 例子:
python
from typing import List, Optional
class Order(BaseModel):
# 嵌套结构,List[Product] 会强制要求列表里每个元素都符合 Product 定义
items: List[Product]
# Optional 表示允许为 None (即 null)
notes: Optional[str] = None4. @field_validator (自定义业务校验)
- 定义: 在类型正确的前提下,数据要
符合业务场景,我们一般会内置一些逻辑来保证数据的正确,比如花费多少天来写作业,天数不可能为负数。 - 作用: 在数据实例化的一瞬间进行清洗或拦截
- 例子:
python
from pydantic import field_validator
class User(BaseModel):
role: str
@field_validator('role')
@classmethod
def check_role(cls, v: str):
if v not in ['admin', 'user']:
raise ValueError('角色只能是 admin 或 user')
return v.lower() # 顺便还能做数据清洗,转小写3.2 AI调用场景设计
💡 首先我们要清楚一个现象,一般我们直接调用AI模型的时候大多数都是询问问题,AI会给你返回你想要的答案,但实际上AI可以将数据按照指定格式返回比如JSON、markdown、csv等等格式,同时也能对我们的数据进行整理。
场景:
你是一个电商运营的后端,需要根据用户的描述提取出核心的信息,并在数据库中进行查找是否有对应的产品。用户的输入一般是没有格式的文本内容,且不固定。
例如:给我推荐一款运动鞋,要白色的,42码左右,男士,价位在500左右,我要购买20双
基于上面的问题,如果让AI用JSON返回,极有可能出现以下的问题:
- Markdown 包裹: 前后有 ```````json```` 符号,直接
json.loads()会报错。 - 废话: 结尾可能带有一句"这是为您生成的 JSON"。
- 类型不确定: 价格可能是
"500"(String) 而不是500(Int)。
为了解决上面的几个通用问题,我们使用Pydantic来进行数据清洗。
3.3 代码实践
步骤一:创建新的环境,使用Python3.11版本,之前3.10只是为了测试,高版本对于ai支持较好
conda create -n test_product python=3.11 -y
步骤二: 打开新的项目,指向新创建的环境。

⚠️ 注意:这里可能不会及时刷新出新创建的环境,不能指向之前的那个环境,这里可以选择重启Pycharm或者在上面的位置手动选择。
步骤三: 创建核心代码文件
- 品牌枚举类:category.py
python
from enum import Enum
class CategoryEnum(str, Enum):
"""定义系统支持的商品分类"""
# --- 国际品牌 ---
NIKE = "耐克"
ADIDAS = "阿迪达斯"
# --- 中国本土品牌 ---
LI_NING = "李宁"
ANTA = "安踏"
XTEP = "特步"
ERKE = "鸿星尔克"
PEAK = "匹克"
WARRIOR = "回力"
FEIYUE = "飞跃"
# 注意:变量名不能以数字开头,所以 361度 通常需要特殊处理
DEGREE_361 = "361度"- 产品类:product.py
python
from typing import List
from pydantic import BaseModel, Field, field_validator
from category import CategoryEnum
class ProductInfo(BaseModel):
"""
商品信息实体类
注意:这里的 description 会作为 Prompt 发送给 AI
"""
name: str = Field(description="商品的简短名称,不超过20个字")
# 自动转换:AI 如果返回 "599.9" (str),这里会自动转为 float
price: float = Field(description="商品建议售价", gt=0)
size: int = Field(description="鞋的尺码", ge=0)
target_gender: str = Field(description="鞋子受众群体,分男和女两种,没有默认男")
# 强制枚举:AI 必须从上面定义的 Enum 中选一个,否则报错
category: CategoryEnum = Field(description="运动鞋的品牌")
color: str = Field(description="鞋子的颜色,用英文表示")
buy_num: int = Field(description="购买数量", ge=0)
tags: List[str] = Field(description="商品的特征标签列表,最多3个", default=[])
# --- 业务校验逻辑 ---
@field_validator('name')
@classmethod
def clean_name(cls, v: str):
# 业务规则:如果 AI 生成的名字带了品牌前缀,去掉它 (模拟数据清洗)
return v.strip().replace("【新品】", "")
@field_validator('tags')
@classmethod
def limit_tags(cls, v: List[str]):
# 业务规则:只取前3个标签
return v[:3]- 密钥配置类:config.py
python
# Gemini API 配置文件
GEMINI_API_KEY = "AIxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxTs"- 核心ai调用类:ai_service.py
python
import json
import re
from concurrent.futures import ThreadPoolExecutor, TimeoutError as FutureTimeoutError
from typing import Optional
from google import genai
from google.genai.errors import ClientError
from pydantic import ValidationError
from product import ProductInfo
class AIService:
def __init__(self, api_key: str):
self.client = genai.Client(api_key=api_key)
self.model_name = 'gemini-2.5-flash'
def _clean_json_string(self, raw_string: str) -> str:
"""
[清洗层]:处理 AI 返回的 Markdown 格式和废话
"""
print(f"--- [DEBUG] AI 原始返回:\n{raw_string}\n---")
# 1. 使用正则去除 ```json ... ```包裹
match = re.search(r"```(?:json)?\s*(.*)\s*```", raw_string, re.DOTALL)
if match:
json_str = match.group(1)
else:
json_str = raw_string
# 2. 简单的去首尾空格
return json_str.strip()
def parse_product_from_text(self, user_input: str) -> Optional[ProductInfo]:
"""
核心方法:用户输入 -> AI -> 清洗 -> Pydantic校验 -> 对象
"""
# 1. 构造 Prompt
# 关键点:我们将 Pydantic 的 Schema 直接喂给 AI,让它知道格式
schema_instruction = ProductInfo.model_json_schema()
prompt = f"""
你是一个电商数据助理。请根据用户描述,提取商品信息并输出 JSON。
用户描述:"{user_input}"
请严格按照以下 JSON Schema 格式输出,不要包含任何额外解释:
{json.dumps(schema_instruction, ensure_ascii=False)}
"""
try:
def call_ai():
response = self.client.models.generate_content(
model=self.model_name,
contents=prompt
)
# 新 API 返回的 response 结构可能不同,需要提取文本
if hasattr(response, 'text'):
return response.text
elif hasattr(response, 'candidates') and len(response.candidates) > 0:
# 如果返回的是 candidates 格式
candidate = response.candidates[0]
if hasattr(candidate, 'content') and hasattr(candidate.content, 'parts'):
return candidate.content.parts[0].text
elif hasattr(candidate, 'text'):
return candidate.text
# 尝试直接转换为字符串
return str(response)
# 使用线程池执行,设置 30 秒超时
with ThreadPoolExecutor(max_workers=1) as executor:
future = executor.submit(call_ai)
try:
raw_text = future.result(timeout=30)
except FutureTimeoutError as e:
print(e)
return None
# 3. 字符串清洗 (ETL)
cleaned_json_str = self._clean_json_string(raw_text)
# 4. JSON 转换 (String -> Dict)
data_dict = json.loads(cleaned_json_str)
# 5. Pydantic 校验与转换 (Dict -> Object)
# 这一步会自动执行类型转换、Enum 匹配、Validator 清洗
product = ProductInfo.model_validate(data_dict)
return product
except json.JSONDecodeError:
print("❌ JSON 解析失败,AI 返回的不是合法 JSON")
return None
except ValidationError as e:
print("❌ Pydantic 校验失败 (业务规则不符):")
print(e.json(indent=2)) # 打印详细报错给开发者看
return None
except ClientError as e:
print(e)
return None
except Exception as e:
print(f"错误类型: {type(e).__name__}")
return None- main主类:main.py
python
import sys
from ai_service import AIService
from config import GEMINI_API_KEY
def main():
"""
主函数:调用AI服务处理用户提示词,并打印清洗后的结果
"""
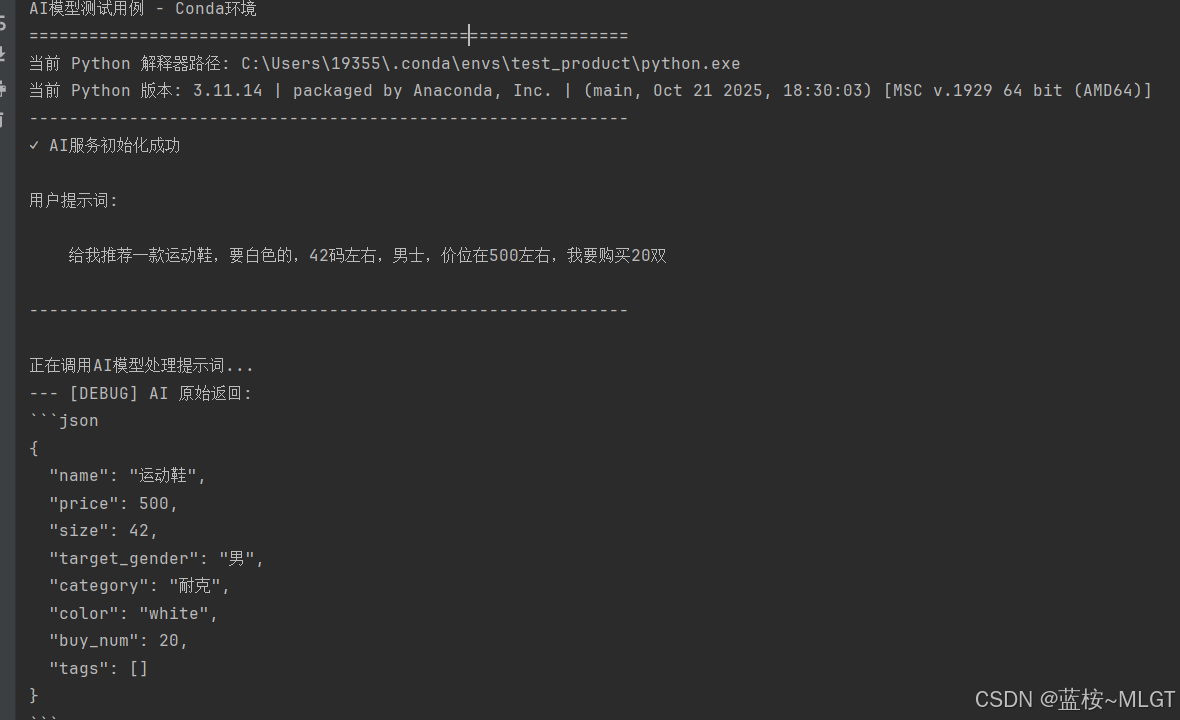
# 1. 打印环境信息
print("=" * 60)
print("AI模型测试用例 - Conda环境")
print("=" * 60)
print(f"当前 Python 解释器路径: {sys.executable}")
print(f"当前 Python 版本: {sys.version}")
print("-" * 60)
# 2. 初始化AI服务
try:
ai_service = AIService(api_key=GEMINI_API_KEY)
print("✓ AI服务初始化成功")
except Exception as e:
print(f"❌ AI服务初始化失败: {e}")
return
# 3. 用户提示词(预留,待用户完善)
user_prompt = """
给我推荐一款运动鞋,要白色的,42码左右,男士,价位在500左右,我要购买20双
"""
print("\n用户提示词:")
print(user_prompt)
print("-" * 60)
# 4. 调用AI服务处理提示词
print("\n正在调用AI模型处理提示词...")
product_info = ai_service.parse_product_from_text(user_prompt.strip())
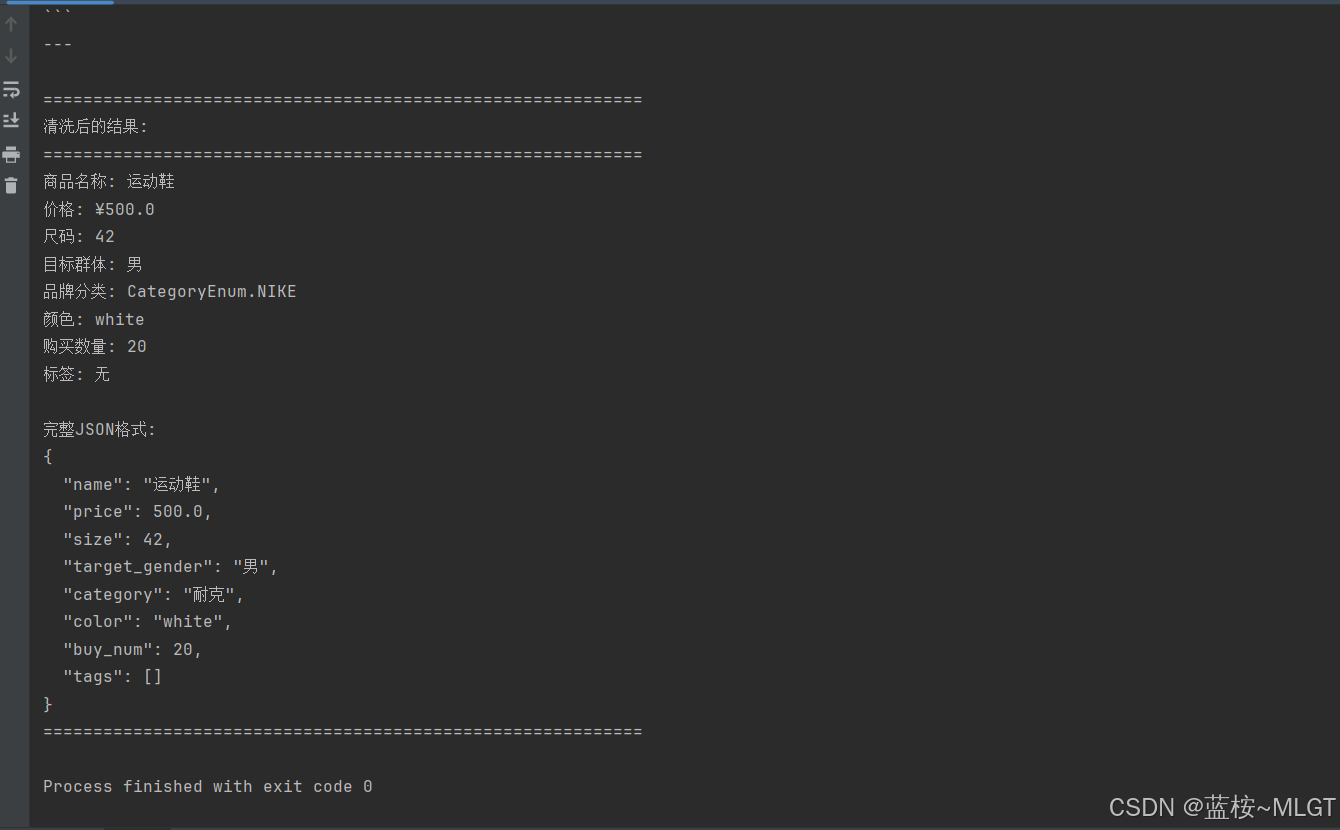
# 5. 打印清洗后的结果
print("\n" + "=" * 60)
print("清洗后的结果:")
print("=" * 60)
if product_info:
# 使用 Pydantic 的 model_dump 方法获取字典格式,便于打印
result_dict = product_info.model_dump()
print(f"商品名称: {result_dict['name']}")
print(f"价格: ¥{result_dict['price']}")
print(f"尺码: {result_dict['size']}")
print(f"目标群体: {result_dict['target_gender']}")
print(f"品牌分类: {result_dict['category']}")
print(f"颜色: {result_dict['color']}")
print(f"购买数量: {result_dict['buy_num']}")
print(f"标签: {', '.join(result_dict['tags']) if result_dict['tags'] else '无'}")
print("\n完整JSON格式:")
print(product_info.model_dump_json(indent=2, ensure_ascii=False))
else:
print("❌ 未能成功解析商品信息,请检查提示词或AI返回结果")
print("=" * 60)
if __name__ == '__main__':
main()- 依赖文件:requirements.txt
python
pydantic~=2.12.4
google-genai>=1.52.0运行的时候安装好依赖(注意因为是Conda环境的原因,Pycharm可能一时间识别不到依赖已经安装了,还会提示你安装,这时候直接运行即可,没事),运行后我们可以得到以下结果
修正创建项目的配置(C盘会多一份Conda文件)
⚠️ 一定要注意!!!
在之前我创建项目的过程中,虽然创建了一个盒子在D盘,但实际上我并没有使用它,而一直适用的是New environment这个选项,也就是下面的图片:
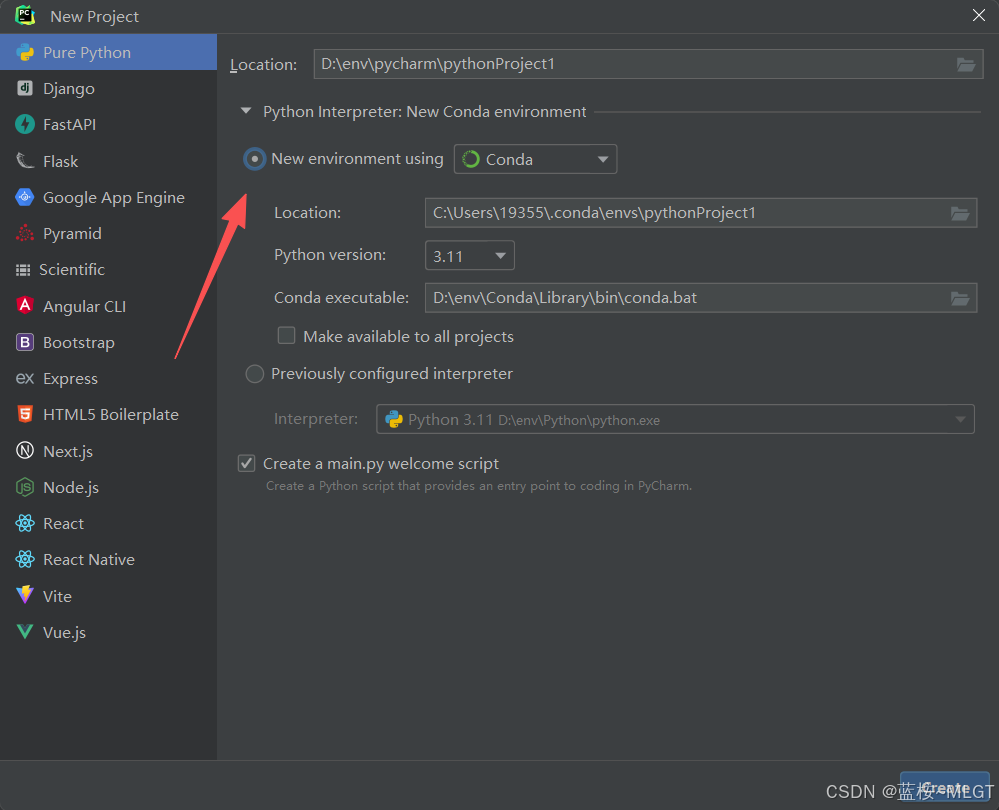
这是非常致命的,这就相当于你又在C盘创建了一份新的环境,只不过是Pycharm自动帮你创建的,而之前那个D盘的盒子是空的,你没有使用,这相当的致命。
但是!!!
No 怪我现在才说,因为这也是我最后才发现的,如果你能读到这里说明你正确的跟着我的步伐走了一遭,这样的经历也能增强你的感知和错误解决能力,现在我将演示正确的做法和一些基本的问题。
正确的创建项目方法
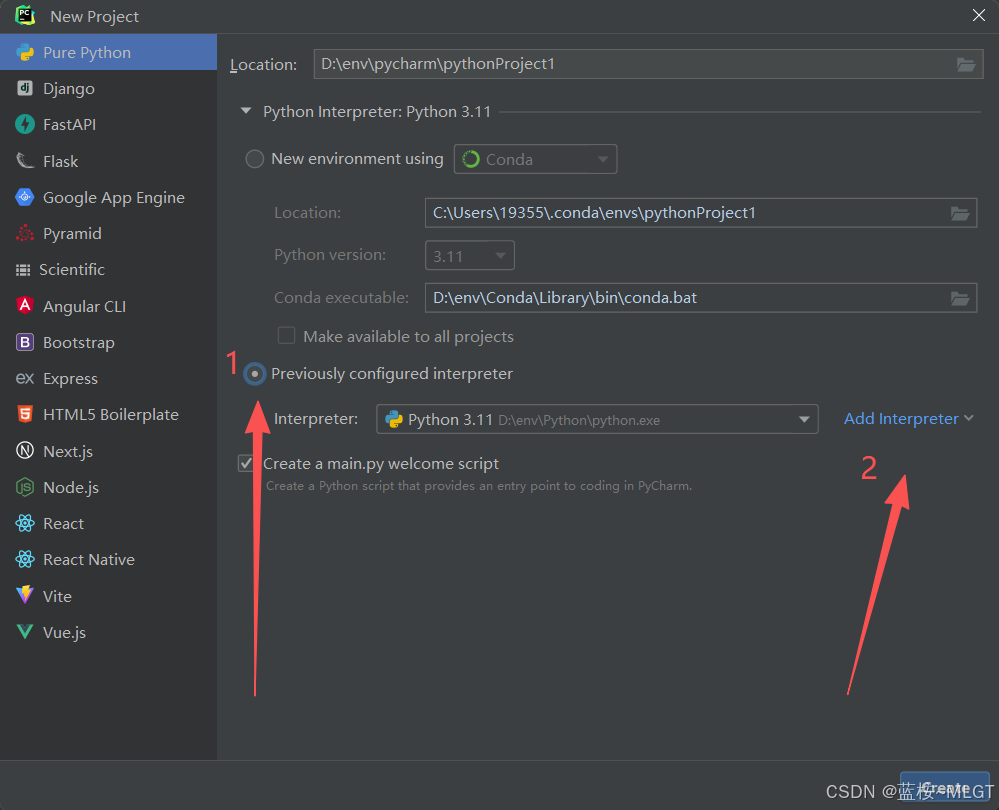
注意看,这个选项是选择已有的解释器,但是目前只有本机自带的解释器,所以我们需要将新安装的盒子的Python解释器添加进来。
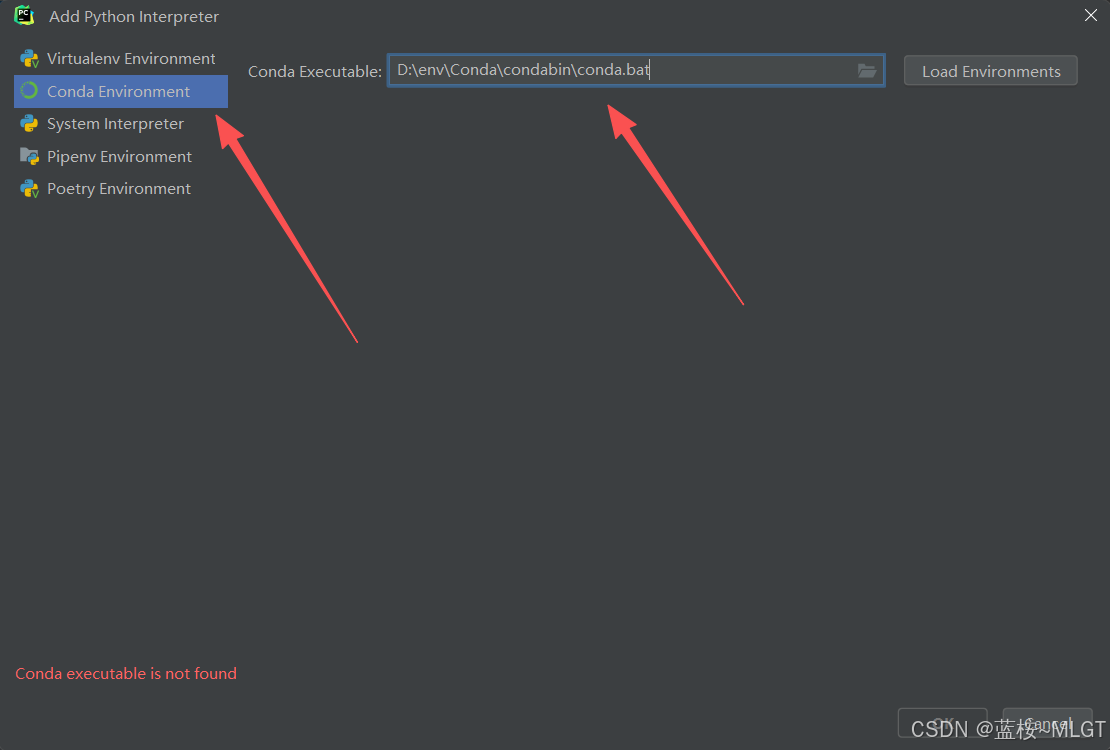
正常我们使用这一个步骤应该是能添加成功的,但是因为Pycharm对Conda的兼容性问题,一般会出现下面的报错:
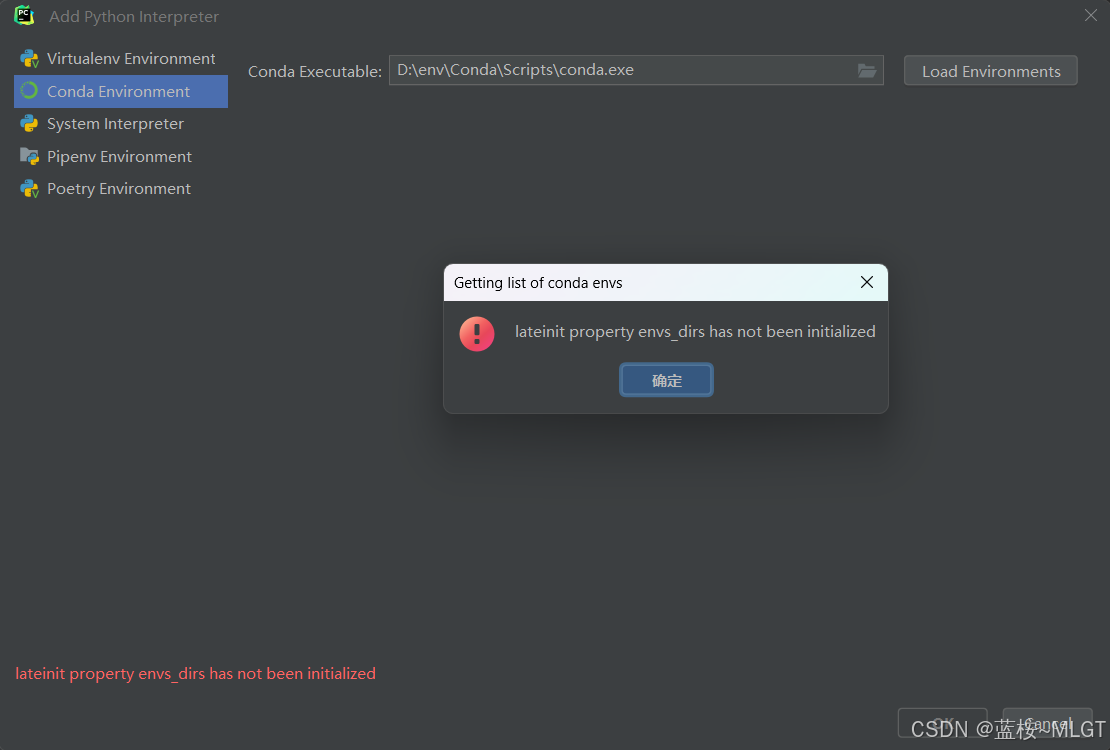
这里不管使用bat还是exe都是比较容易出错的,所以使用终极方案。
终极方案

直接使用系统的配置选择解释器,位置就是你新创建的盒子中的Python.exe位置,这样创建的项目才是最正确的,完美。
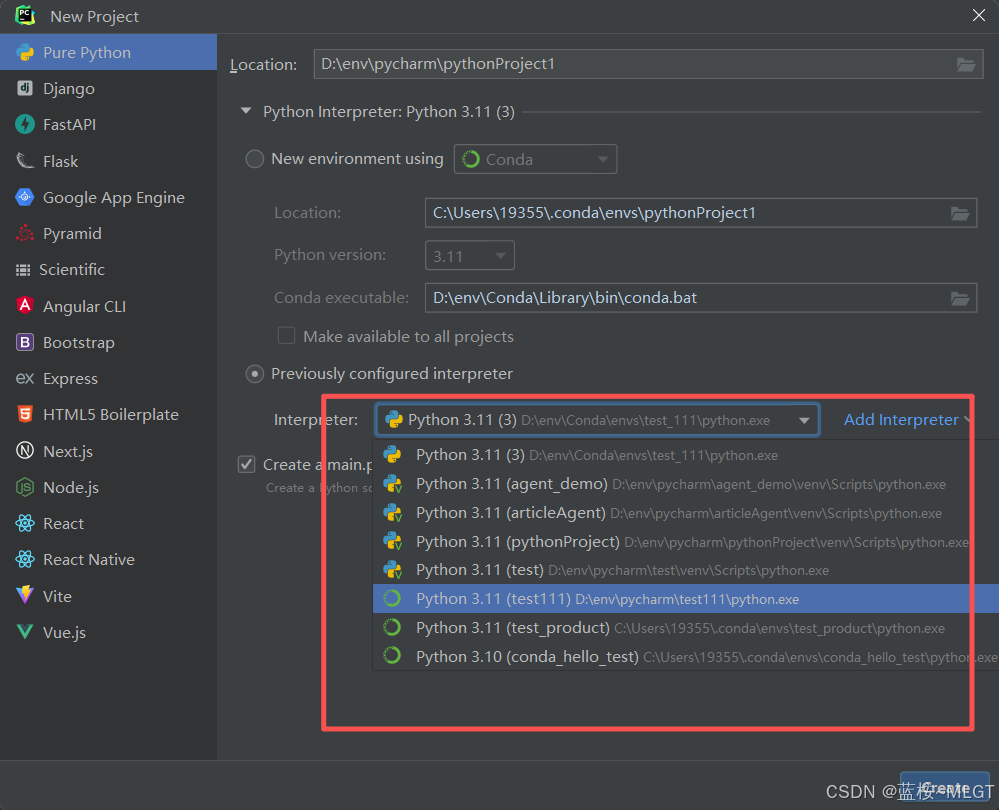
这个时候我们就能看到一堆解释器了,选择自己的就完事儿了,加油!!!
总结
理论固然重要,但是实践才是唯一真理!!!