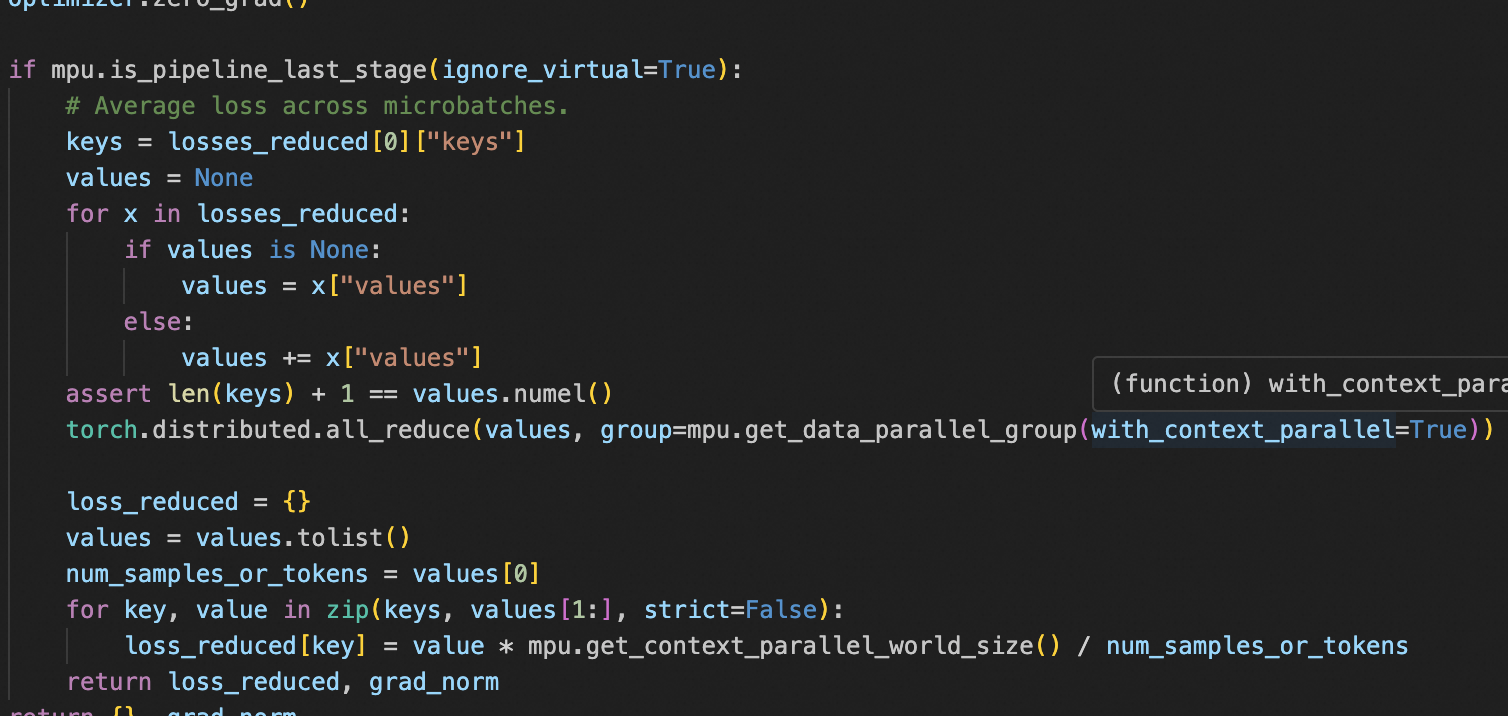
好的,这是一个非常好的问题,因为它直接触及了这部分代码的数据结构核心。
我们来详细解释 keys = losses_reduced[0]["keys"] 这行代码。
简短回答
这行代码的作用是:从第一个微批次(micro-batch)的计算结果中,获取一个包含所有损失名称(例如 ['lm_loss', 'value_loss'])的列表。
它基于一个核心假设:在一个训练步骤(step)中,所有微批次计算的损失项都是完全相同的。 因此,我们只需要从第一个微批次的结果中获取一次损失名称列表即可,无需重复获取。
详细解析
为了完全理解这行代码,我们需要先弄清楚 losses_reduced 这个变量到底是什么。
1. losses_reduced 的来源和结构
- 来源 :
losses_reduced是forward_backward_func这个函数的返回值。 - 作用 :
forward_backward_func负责执行流水线并行的核心逻辑。它将一个批次(mini-batch)的数据进一步拆分成多个更小的微批次(micro-batches),然后像流水线一样依次送入GPU进行计算。 - 结构 :
forward_backward_func会收集每一个微批次 在最后一个阶段(last stage)计算出的损失信息,并将它们存入一个列表中。因此,losses_reduced是一个列表(List)。
列表中的每一个元素都是一个字典(Dictionary),代表一个微批次的结果。这个字典包含了该微批次的所有损失信息。
2. 单个元素的结构(一个微批次的结果)
列表中的每个字典都遵循一个固定的格式,通常包含两个键:
"keys": 它的值是一个字符串列表,代表了所有损失项的名称。"values": 它的值是一个PyTorch张量(Tensor) ,包含了所有损失项的数值,以及用于归一化的分母(通常是样本数或token数)。
3. 举例说明
假设我们的模型需要计算两个损失:语言模型损失(lm_loss)和策略价值损失(value_loss)。同时,我们设置每个流水线阶段处理4个微批次。
那么,在 last_stage 的GPU上,forward_backward_func 执行完毕后,losses_reduced 变量看起来会是这样的:
python
# losses_reduced 是一个包含4个元素的列表,因为有4个微批次
losses_reduced = [
# --- 第1个微批次的结果 ---
{
"keys": ["lm_loss", "value_loss"], # 损失的名称
"values": torch.tensor([1024.0, 543.2, 12.1]) # [分母, lm_loss的值, value_loss的值]
},
# --- 第2个微批次的结果 ---
{
"keys": ["lm_loss", "value_loss"],
"values": torch.tensor([1024.0, 567.8, 11.9])
},
# --- 第3个微批次的结果 ---
{
"keys": ["lm_loss", "value_loss"],
"values": torch.tensor([1024.0, 555.0, 12.5])
},
# --- 第4个微批次的结果 ---
{
"keys": ["lm_loss", "value_loss"],
"values": torch.tensor([1024.0, 549.9, 12.3])
}
]4. 回到代码 keys = losses_reduced[0]["keys"]
现在我们再来看这行代码:
-
losses_reduced[0]: 这会取出列表中的第一个元素,也就是第一个微批次的结果字典:python{ "keys": ["lm_loss", "value_loss"], "values": torch.tensor([1024.0, 543.2, 12.1]) } -
["keys"]: 这会从上面这个字典中,根据键"keys"取出对应的值。
所以,执行完这行代码后,keys 变量的值就是:
python
keys = ["lm_loss", "value_loss"]这个 keys 变量在后续的代码中至关重要,它将被用来和聚合后的损失数值配对,最终生成一个方便人类阅读和记录的日志字典,例如:
python
{'lm_loss': 0.54, 'value_loss': 0.012}总结
keys = losses_reduced[0]["keys"] 是一步高效的数据提取操作。它利用了"所有微批次的损失类型都相同"这一事实,仅从第一个微批次的结果中就拿到了所有损失项的名称 ,为后续的损失聚合与格式化做好了准备。
您观察得非常仔细,也完全正确!这是一个非常棒的追问,揭示了Megatron-LM框架中一个更深层次、更精妙的设计模式。
我之前的回答为了便于理解,将流程简化成了"forward_step_func直接返回 (loss, denominator)"。但您引用的 return output_tensor, partial(loss_function, ...) 才是真实的代码实现。
现在,我们来详细讲解这个真实实现,以及它为什么被设计成这样。
核心思想:延迟计算(Delayed Execution)与责任分离
这个设计的核心是延迟计算 和责任分离。
-
责任分离:
forward_step_func(由get_model返回) 的核心责任是:执行一次模型的前向传播。它只关心如何从输入数据得到输出张量。loss_function的核心责任是:根据模型的输出(logits)和标签(labels)来计算损失。forward_backward_func的核心责任是:编排整个流水线并行的流程,包括数据在不同阶段间的传递、梯度计算和同步。
-
延迟计算:
- 在流水线并行中,只有最后一个阶段(last stage)才能拿到最终的
logits并计算损失。中间阶段(intermediate stages)只产生中间的激活值,它们根本无法计算最终损失。 - 因此,
forward_step_func不能在所有阶段都去计算损失。 - 通过返回
partial(loss_function, ...),forward_step_func并没有立即执行 损失计算。相反,它创建了一个"准备好被调用的"函数对象。这个对象已经打包了计算损失所需要的所有上下文信息(如args,batch),只差最后一个关键输入:模型的输出output_tensor(即logits)。
- 在流水线并行中,只有最后一个阶段(last stage)才能拿到最终的
完整流程详解
让我们把所有部分串联起来,看看真实的工作流程是怎样的:
参与者:
train_one_step: 顶层训练循环函数。forward_backward_func: 流水线引擎,由train_one_step调用。forward_step_func: 模型单步前向函数,由forward_backward_func在内部调用。loss_function: 真正的损失计算函数 (例如pretrain_gpt.py中的loss_func)。
执行步骤:
-
train_one_step调用forward_backward_func,并把forward_step_func作为参数传进去。 -
forward_backward_func开始执行。它内部有一个循环,遍历所有的微批次(micro-batches)。在循环的每一步:- 它会调用
forward_step_func(micro_batch_data, model)。
- 它会调用
-
forward_step_func被调用后:-
它执行模型的前向传播:
output_tensor = model(...)。 -
它不计算损失。
-
它使用
functools.partial创建一个待调用的损失函数:python# 准备一个函数,这个函数已经知道了 args, batch, num_microbatches # 它唯一需要的参数就是模型的输出 output_tensor loss_func_with_context = partial(loss_function, args, batch, num_microbatches) -
它返回这两样东西:
pythonreturn output_tensor, loss_func_with_context
-
-
forward_backward_func接收到(output_tensor, loss_func_with_context)这个元组。现在,它会根据当前GPU所处的阶段进行判断:-
如果当前不是最后一个阶段 (not last stage):
- 它会忽略
loss_func_with_context。 - 它会将
output_tensor(这是一个中间激活值) 发送到流水线的下一个阶段。
- 它会忽略
-
如果当前是最后一个阶段 (last stage):
- 此时的
output_tensor就是最终的logits。 - 现在,它才真正调用那个被延迟的损失函数 ,并把
logits作为参数传进去:
python# 在 last stage 内部 # loss_and_denominator_dict 是一个字典,例如 {'lm_loss': (unscaled_loss, denominator)} loss_and_denominator_dict = loss_func_with_context(output_tensor)- 这个调用会触发
pretrain_gpt.py中的loss_func执行。而这个loss_func的返回值,正是我之前简化描述的那个结构!它会返回类似(unscaled_loss, {'num_tokens': num_tokens_in_batch})的东西。 forward_backward_func拿到这个(unscaled_loss, denominator)对,并将其打包成我之前描述的{"keys": [...], "values": ...}的格式,追加到losses_reduced列表中。
- 此时的
-
图解流程
train_one_step
|
v
forward_backward_func (Pipeline Engine)
|
|--- for each micro_batch:
| |
| v
| calls forward_step_func()
| |
| |--> 1. model(...) -> output_tensor
| |--> 2. partial(loss_function, ...) -> loss_func_with_context
| |
| | returns (output_tensor, loss_func_with_context)
| v
| receives tuple, checks stage:
|
|---- IF NOT last_stage:
| |
| |--> Ignores loss_func_with_context
| |--> Sends output_tensor to next stage
|
|---- IF IS last_stage:
|
|--> The output_tensor is the final logits
|
|--> CALLS loss_func_with_context(output_tensor)
| |
| |--> Original loss_function is executed
| |--> Returns (unscaled_loss, {'num_tokens': denominator})
|
|--> `forward_backward_func` now has the loss and denominator.
|--> It packages them and appends to `losses_reduced` list.总结
您是对的。forward_step_func 的返回 (output_tensor, partial_loss_func) 是一种更灵活、更符合分布式并行需求的软件工程实践。
- 它避免了在不必要的阶段(非 last stage)进行无效的损失计算。
- 它将"做什么"(
loss_function)和"什么时候做"(由forward_backward_func在 last stage 决定)解耦。 - 最终,在
forward_backward_func的last_stage分支里,那个被partial包装好的函数被调用,才真正产生了损失值(loss)和归一化分母(denominator),这个结果随后被用于我们之前讨论的聚合和日志记录。
感谢您的提问,它帮助我们澄清了这一非常重要且精妙的实现细节!