本篇是 Perfetto 系列文章的第七篇,主要介绍 Android App 中的 MainThread 和 RenderThread,也就是大家熟悉的主线程 和渲染线程。文章会从 Perfetto 的角度来看 MainThread 和 RenderThread 的工作流程,涉及卡顿、软件渲染、掉帧计算等相关知识。
随着 Google 正式推出 Perfetto 工具替代 Systrace,Perfetto 在性能分析领域已经成为主流选择。本文将结合 Perfetto 的具体 trace 信息,帮助读者理解 MainThread 和 RenderThread 的完整工作流程,让你在使用 Perfetto 分析性能问题时能够:
- 准确识别关键 trace tag:知道 UI Thread、RenderThread 等关键线程的作用
- 理解帧渲染的完整流程:从 Vsync 信号到屏幕显示的每个步骤
- 定位性能瓶颈:通过 trace 信息快速找到卡顿和性能问题的根因
本文目录
- 系列文章目录
- [基于 Perfetto 的渲染流程分析](#基于 Perfetto 的渲染流程分析 "#render-flow")
- 双线程渲染架构的演进
- 主线程的创建过程
- [ActivityThread 的功能](#ActivityThread 的功能 "#activitythread")
- 渲染线程的创建和发展
- 性能
- [Perfetto 独有的 FrameTimeline 功能](#Perfetto 独有的 FrameTimeline 功能 "#frametimeline")
- [Perfetto 中 Vsync 信号](#Perfetto 中 Vsync 信号 "#vsync")
- 参考
- 附件
- [关于我 && 博客](#关于我 && 博客 "#about")
系列文章目录
- Android Perfetto 系列目录
- Android Perfetto 系列 1:Perfetto 工具简介
- Android Perfetto 系列 2:Perfetto Trace 抓取
- Android Perfetto 系列 3:熟悉 Perfetto View
- Android Perfetto 系列 4:使用命令行在本地打开超大 Trace
- Android Perfetto 系列 5:Android App 基于 Choreographer 的渲染流程
- Android Perfetto 系列 6:为什么是 120Hz?高刷新率的优势与挑战
- Android Perfetto 系列 7 - MainThread 和 RenderThread 解读
- Android Perfetto 系列 8:深入理解 Vsync 机制与性能分析
- Android Perfetto 系列 9 - CPU 信息解读
- 视频(B站) - Android Perfetto 基础和案例分享
如果大家还没看过 Systrace 系列,下面是传送门:
- Systrace 系列目录 : 系统介绍了 Perfetto 的前身 Systrace 的使用,并通过 Systrace 来学习和了解 Android 性能优化和 Android 系统运行的基本规则。
- 个人博客 :个人博客,主要是 Android 相关的内容,也放了一些生活和工作相关的内容。
欢迎大家在 关于我 页面加入微信群或者星球,讨论你的问题、你最想看到的关于 Perfetto 的部分,以及跟各位群友讨论所有 Android 开发相关的内容.
本文使用到的 Trace 文件我上传到了 Github :github.com/Gracker/Sys... ,需要的可以自取。
注:本文内容基于 Android 16 的最新渲染架构
基于 Perfetto 的渲染流程分析
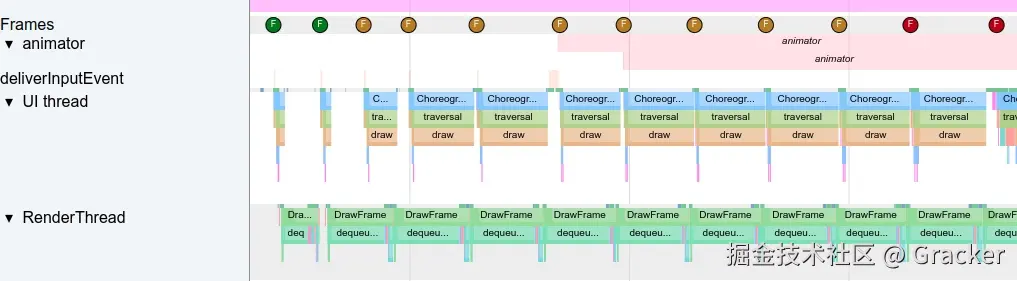
这里以滑动列表为例,我们通过 Perfetto 截取主线程和渲染线程一帧的工作流程(每一帧都会遵循这个流程,不过有的帧需要处理的事情多,有的帧需要处理的事情少)。在 Perfetto UI 中,重点观察 "UI Thread" 和 "RenderThread" 这两个线程的活动。
帧的概念和基本参数
在分析 Perfetto trace 之前,需要先了解帧(Frame)的基本概念。Android 系统按照固定的时间间隔刷新屏幕内容:
- 60Hz 设备:每 16.67ms 刷新一次,每秒 60 帧
- 90Hz 设备:每 11.11ms 刷新一次,每秒 90 帧
- 120Hz 设备:每 8.33ms 刷新一次,每秒 120 帧
在 Perfetto 中分析渲染性能时,需要重点关注以下两个线程:
- UI Thread:应用主线程,处理用户输入、业务逻辑、布局计算
- RenderThread:渲染线程,执行 GPU 渲染命令,与 SurfaceFlinger 交互
主线程和渲染线程的工作流程

通过上面的 Perfetto 截图,可以看到一帧完整的渲染流程。我们可以将 Perfetto 图想象成一条河流:主线程在上游处理逻辑,渲染线程在下游执行绘制。河流从左到右流动,每段代表一个步骤。
重要说明:并非每一帧都会执行所有步骤。Input、Animation、Insets Animation 这些回调是基于前一帧的状态决定当前帧是否执行,而 Traversal(measure、layout、draw)是每帧的核心流程。
通过以下描述,试着在脑中"播放"这个完整流程:
1. 主线程等待 Vsync 信号
- Perfetto trace: 主线程处于 Sleep 状态(显示为空闲块)
- 流程说明: 主线程等待垂直同步信号(Vsync)到来,这确保渲染与屏幕刷新率同步,避免画面撕裂
2. Vsync-app 信号传递过程
- Perfetto trace :
vsync-app相关事件,SurfaceFlinger app 线程活动 - 流程说明: 当硬件产生 Vsync 信号时,首先传递给 SurfaceFlinger。SurfaceFlinger 的 app 线程被唤醒,负责管理和分发 Vsync 信号给需要渲染的应用程序。这个中间层设计允许系统级的 Vsync 调度和优化
重要说明:
- Vsync-app 是按需申请的:只有 App 主动请求时才会收到 vsync-app 信号,不申请就没有
- 多 App 共享机制:同时可能有多个 App 申请 vsync-app 信号
- 信号归属问题:SurfaceFlinger 中的 vsync-app 信号可能是其他 App 申请的,当前分析的 App 如果没有申请,就不会有帧输出,这是正常现象
3. SurfaceFlinger 唤醒 App 主线程
- Perfetto trace :
FrameDisplayEventReceiver.onVsync - 流程说明: SurfaceFlinger 通过 FrameDisplayEventReceiver 机制将 Vsync 信号发送给已注册的 App。App 的 Choreographer 接收到信号后开始启动一帧绘制流程
4. 处理输入事件(Input)
-
Perfetto trace :
Input块 -
流程说明: 仅在有输入事件时才执行,主要处理触摸、滑动等用户交互
-
触发条件:
- 有 Input 回调:手指按压屏幕并滑动时(如列表滑动、页面拖拽)
- 无 Input 回调:手指抬起后的惯性滑动阶段、静止状态
-
注意: Input 回调是由前一帧的用户交互行为决定是否在当前帧执行
5. 处理动画(Animation)
-
Perfetto trace :
Animation块 -
流程说明: 仅在有动画需要更新时才执行,更新动画状态和当前帧的动画值
-
触发条件:
- 有 Animation 回调:惯性滑动阶段、属性动画运行时、列表 item 创建和内容变化、页面转场动画等
- 无 Animation 回调:界面静止状态、纯 Input 交互阶段(无动画效果时)
-
注意: Animation 回调同样由前一帧 post 的回调决定当前帧是否执行
6. 处理 Insets 动画
-
Perfetto trace :
Insets Animation块 -
流程说明: 仅在有窗口插入变化时才执行,处理窗口边界动画
-
触发条件:
- 有 Insets Animation 回调:键盘弹出/收起、状态栏显示/隐藏、导航栏变化等
- 无 Insets Animation 回调:窗口边界稳定状态,大部分普通交互场景
7. Traversal(测量、布局、绘制准备)
- Perfetto trace :
performTraversals,measure,layout,draw - 流程说明: Android UI 渲染的三大核心流程,每一帧都会执行这个完整的流程:
7.1 Measure(测量阶段)
-
作用: 确定每个 View 的尺寸大小
-
过程: 从根 View 开始,递归测量所有子 View 的宽高
-
关键概念:
MeasureSpec:封装了父容器对子 View 的尺寸要求(EXACTLY、AT_MOST、UNSPECIFIED)onMeasure():每个 View 重写此方法来实现自己的测量逻辑
-
Perfetto 中的表现 :
measure事件,耗时取决于 View 层级复杂度
7.2 Layout(布局阶段)
-
作用: 确定每个 View 在父容器中的位置坐标
-
过程: 基于 Measure 阶段的结果,为每个 View 分配实际的显示位置
-
关键概念:
layout(left, top, right, bottom):设置 View 的四个边界坐标onLayout():ViewGroup 重写此方法来确定子 View 的位置
-
Perfetto 中的表现 :
layout事件,通常比 measure 更快
7.3 Draw(绘制阶段)
-
作用: 将 View 的内容绘制到画布上
-
现代实现: 不直接绘制像素,而是构建 DisplayList(绘制指令列表)
-
关键流程:
draw(Canvas):绘制 View 自身内容onDraw(Canvas):子类重写实现具体绘制逻辑dispatchDraw(Canvas):ViewGroup 用来绘制子 View
-
Perfetto 中的表现 :
draw事件,在硬件加速下主要是构建 DisplayList
ViewRootImpl.performTraversals 核心代码
scss
// frameworks/base/core/java/android/view/ViewRootImpl.java
private void performTraversals() {
// ... 其他代码
// 1. Measure 阶段
if (mFirst || windowShouldResize || viewVisibilityChanged || params != null) {
performMeasure(childWidthMeasureSpec, childHeightMeasureSpec);
}
// 2. Layout 阶段
final boolean didLayout = layoutRequested && (!mStopped || mReportNextDraw);
if (didLayout) {
performLayout(lp, mWidth, mHeight);
}
// 3. Draw 阶段
if (!performRequestedAction(mAttachInfo, mFirst)) {
if (mFirst || viewVisibilityChanged) {
performDraw();
}
}
}注:实际 AOSP 源码中
performTraversals的条件判断更为复杂,会涉及mFirst、mAdded、mWindowShouldResize以及各种dirty状态标记,但以上代码清晰地展示了其核心的 Measure、Layout、Draw 三阶段流程。
三阶段的执行条件:
- Measure: 当窗口大小变化、首次创建或者视图可见性变化时执行
- Layout: 当布局被请求且应用未停止时执行
- Draw: 当有绘制请求或者是首次绘制、视图可见性变化时执行
8. 同步 DisplayList 到渲染线程
- Perfetto trace: syncAndDrawFrame,可见 "sync" 或 "syncAndDrawFrame" 事件(通常显示为主线程向渲染线程的数据传递点)
- 流程说明: 主线程通过 syncAndDrawFrame 将构建好的 DisplayList(包含 RenderNode 树、视图属性如变换矩阵、透明度和裁剪区域,以及共享资源如纹理)传递给渲染线程。这个同步过程是硬件加速的核心,确保渲染线程获得完整的绘制指令。同步完成后,主线程立即释放资源(可继续处理其他消息、IdleHandler 或进入 Sleep 等待下一个 Vsync),而渲染线程独立接管后续的 GPU 渲染工作。
9. 渲染线程获取 Buffer
- Perfetto trace :
dequeueBuffer块 - 流程说明: 渲染线程从 BlastBufferQueue(App 端管理的缓冲队列)通过 dequeueBuffer 获取一个可用缓冲区,作为渲染目标(framebuffer)。BlastBufferQueue 采用生产者-消费者模型,预先管理缓冲池以减少等待时间;如果无可用 Buffer,可能短暂等待或触发新 Buffer 创建。
10. 处理渲染指令并 flush 到 GPU
Perfetto trace : drawing 相关块
- 流程说明: RenderThread(运行在 CPU 上)通过 HardwareRenderer 和 CanvasContext 处理从 UI thread 同步过来的 DisplayList,调用 OpenGL ES 或 Vulkan API 来准备绘制命令序列(如渲染视图的几何形状、纹理、着色效果)。这些命令被构建成命令缓冲区(command buffer),然后通过 flush 操作(例如 mRenderPipeline->flush())提交到 GPU 驱动,同时生成 present fence 用于后续同步。GPU 异步执行这些指令,实际生成图像内容。
11. 提交 Buffer(可能 unsignaled)
- Perfetto trace: queueBuffer(可观察 acquireFence 状态)
- 流程说明: RenderThread 通过 queueBuffer 将渲染完成的 Buffer 提交回 BlastBufferQueue,此时 Buffer 可能携带 unsignaled 的 acquire fence(即 GPU 渲染命令尚未完全执行完毕)。这种异步提交机制有助于减少整体渲染延迟。
12. 触发 Transaction 到 SurfaceFlinger
- Perfetto trace: TransactionQueue 或 BLAST transaction 事件 ,一般在 queueBuffer 之后,有些 Trace 没有这个 Tag
- 流程说明: 在 queueBuffer 完成后,RenderThread 通过 applyPendingTransactions 将积累的 Transaction(包括 Buffer 更新、层属性变化等)批量发送给 SurfaceFlinger。SurfaceFlinger 处理这些 Transaction,根据 LatchUnsignaledConfig 策略(例如 AutoSingleLayer 配置)检查并可能 latch unsignaled buffer 以进一步优化延迟;如果配置禁用 unsignaled latch,则等待 fence signaled 确保 Buffer 就绪。随后,SurfaceFlinger 执行层合成(composite)并将最终图像显示到屏幕。
在 Perfetto 中识别不同的渲染模式:
- 手指滑动时 :每帧都有
Input→Traversal→RenderThread的完整链路 - 惯性滑动时 :每帧都有
Animation→Traversal→RenderThread,没有Input - 静止状态时 :偶尔出现
Animation→Traversal→RenderThread,没有Input
软件绘制 vs 硬件加速
虽然现在基本都使用硬件加速渲染,但了解两种渲染模式的区别仍然有助于理解 Perfetto trace:
| 方面 | 软件绘制 | 硬件加速 |
|---|---|---|
| 绘制线程 | 主线程 | RenderThread |
| 绘制引擎 | Skia (CPU) | OpenGL/Vulkan (GPU) |
| Perfetto 特征 | 主线程有大块 draw 事件 |
主线程快速完成,RenderThread 处理绘制 |
| 性能影响 | 可能阻塞主线程 | 异步渲染,性能更好 |
上面介绍的是基本的渲染流程,更详细的 Choreographer 原理可以参考 Android Perfetto 系列 5:Android App 基于 Choreographer 的渲染流程。
接下来我们重点讲解主线程和渲染线程的深入内容:
- 主线程的发展
- 主线程的创建
- 渲染线程的创建
- 主线程和渲染线程的分工
双线程渲染架构的演进
Android 的渲染系统经历了从单线程到双线程的重要演进过程。
单线程时代(Android 4.4 之前)
在早期的 Android 版本中,所有的 UI 相关工作都在主线程中执行:
- 处理用户输入事件
- 执行 measure、layout、draw
- 调用 OpenGL 进行实际绘制
- 与 SurfaceFlinger 交互
这种设计的问题:
- 响应性差:主线程负载过重,容易出现 ANR
- 性能瓶颈:CPU 和 GPU 无法并行工作
- 帧率不稳定:复杂界面容易导致掉帧
双线程时代(Android 5.0 Lollipop 开始)
Android 5.0 引入了 RenderThread,实现渲染工作的分离:
主线程职责:
- 处理用户输入和业务逻辑
- 执行 View 的 measure、layout、draw
- 构建 DisplayList(绘制指令列表)
- 与渲染线程同步数据
渲染线程职责:
- 接收并处理 DisplayList
- 执行 OpenGL/Vulkan 渲染命令
- 管理纹理和渲染资源
- 与 SurfaceFlinger 交互
这种架构带来的优势:
- 并行处理:主线程可以在渲染线程工作时处理下一帧
- 响应性提升:主线程不再被渲染阻塞
- 性能优化:GPU 资源得到更好利用
主线程的创建过程
Android App 的进程是基于 Linux 的,其管理也是基于 Linux 的进程管理机制,所以其创建也是调用了 fork 函数
frameworks/base/core/jni/com_android_internal_os_Zygote.cpp
ini
pid_t pid = fork();Fork 出来的进程,我们这里可以把他看做主线程,但是这个线程还没有和 Android 进行连接,所以无法处理 Android App 的 Message ;由于 Android App 线程运行基于消息机制 ,那么这个 Fork 出来的主线程需要和 Android 的 Message 消息绑定,才能处理 Android App 的各种 Message
这里就引入了 ActivityThread ,确切的说,ActivityThread 应该起名叫 ProcessThread 更贴切一些。ActivityThread 连接了 Fork 出来的进程和 App 的 Message ,他们的通力配合组成了我们熟知的 Android App 主线程。所以说 ActivityThread 其实并不是一个 Thread,而是他初始化了 Message 机制所需要的 MessageQueue、Looper、Handler ,而且其 Handler 负责处理大部分 Message 消息,所以我们习惯上觉得 ActivityThread 是主线程,其实他只是主线程的一个逻辑处理单元。
ActivityThread 的创建
App 进程 fork 出来之后,回到 App 进程,查找 ActivityThread 的 Main函数
com/android/internal/os/ZygoteInit.java
java
// Android 16 最新的 Zygote 初始化实现
static final Runnable childZygoteInit(
int targetSdkVersion, String[] argv, ClassLoader classLoader) {
RuntimeInit.Arguments args = new RuntimeInit.Arguments(argv);
// 设置线程优先级
if (args.niceName != null) {
Process.setArgV0(args.niceName);
}
// 设置应用程序的调试模式
if (args.invokeWith != null) {
WrapperInit.execApplication(args.invokeWith,
args.niceName, args.targetSdkVersion,
VMRuntime.getCurrentInstructionSet(),
null, args.remainingArgs);
// Should not get here.
throw new IllegalStateException("WrapperInit.execApplication unexpectedly returned");
} else {
ZygoteInit.zygoteInit(args.targetSdkVersion, args.disabledCompatChanges,
args.remainingArgs, classLoader);
}
return RuntimeInit.findStaticMain(args.startClass, args.startArgs, classLoader);
}这里的 startClass 就是 ActivityThread,找到之后调用,逻辑就到了 ActivityThread的main函数
android/app/ActivityThread.java
ini
public static void main(String[] args) {
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, "ActivityThreadMain");
// 1. 初始化 Looper、MessageQueue
Looper.prepareMainLooper();
// 2. 初始化 ActivityThread
long startSeq = 0;
if (args != null) {
for (int i = args.length - 1; i >= 0; --i) {
if (args[i] != null && args[i].startsWith(PROC_START_SEQ_IDENT)) {
startSeq = Long.parseLong(
args[i].substring(PROC_START_SEQ_IDENT.length()));
}
}
}
ActivityThread thread = new ActivityThread();
// 3. 主要是调用 AMS.attachApplicationLocked,同步进程信息,做一些初始化工作
thread.attach(false, startSeq);
// 4. 获取主线程的 Handler,这里是 H ,基本上 App 的 Message 都会在这个 Handler 里面进行处理
if (sMainThreadHandler == null) {
sMainThreadHandler = thread.getHandler();
}
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
// 5. 初始化完成,Looper 开始工作
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
}注释里面都很清楚,这里就不详细说了,main 函数处理完成之后,主线程就算是正式上线开始工作.
ActivityThread 的功能
另外我们经常说的,Android 四大组件都是运行在主线程上的,其实这里也很好理解,看一下 ActivityThread 的 Handler 的 Message 就知道了
java
class H extends Handler { // 摘抄了部分,基于 Android 16 最新实现
public static final int BIND_APPLICATION = 110; // 应用启动
public static final int CREATE_SERVICE = 114; // 创建Service
public static final int BIND_SERVICE = 121; // 绑定Service
public static final int RECEIVER = 113; // 广播接收
// ... 还有其他四大组件相关的消息类型
}可以看到,进程创建、Activity 启动、Service 的管理、Receiver 的管理、Provider 的管理这些都会在这里处理,然后进到具体的 handleXXX
渲染线程的创建和发展
主线程讲完了我们来讲渲染线程,渲染线程也就是 RenderThread ,最初的 Android 版本里面是没有渲染线程的,渲染工作都是在主线程完成,使用的也都是 CPU ,调用的是 libSkia 这个库,RenderThread 是在 Android Lollipop 中新加入的组件,负责承担一部分之前主线程的渲染工作,减轻主线程的负担
软件绘制
我们一般提到的硬件加速,指的就是 GPU 加速,这里可以理解为用 RenderThread 调用 GPU 来进行渲染加速 。 硬件加速在目前的 Android 中是默认开启的, 所以如果我们什么都不设置,那么我们的进程默认都会有主线程和渲染线程(有可见的内容)。我们如果在 App 的 AndroidManifest 里面,在 Application 标签里面加一个
ini
android:hardwareAccelerated="false"我们就可以关闭硬件加速,系统检测到你这个 App 关闭了硬件加速,就不会初始化 RenderThread ,直接 cpu 调用 libSkia 来进行渲染。其 Trace 跟踪表现如下 (资源比较老,用 Systrace 图示)
与这篇文章开头开启硬件加速的 Perfetto 图对比,可以看到主线程由于要进行渲染工作,所以执行的时间变长了,也更容易出现卡顿,同时帧与帧之间的空闲间隔也变短了,使得其他 Message 的执行时间被压缩。在 Perfetto 中,这种差异通过线程活动的时间长度和密集程度可以清晰地观察到。
硬件加速绘制
正常情况下,硬件加速是开启的,主线程的 draw 函数并没有真正的执行 drawCall ,而是把要 draw 的内容记录到 DisplayList 里面,通过 syncAndDrawFrame 将 DisplayList 同步到 RenderThread 中,一旦同步完成,主线程就可以被释放出来做其他的事情,RenderThread 则继续进行渲染工作。
渲染线程初始化
渲染线程初始化在真正需要 draw 内容的时候,一般我们启动一个 Activity ,在第一个 draw 执行的时候,会去检测渲染线程是否初始化,如果没有则去进行初始化
android/view/ViewRootImpl.java
ini
// 渲染线程初始化
mAttachInfo.mThreadedRenderer.initializeIfNeeded(
mWidth, mHeight, mAttachInfo, mSurface, surfaceInsets);
// 初始化 BlastBufferQueue - App 端缓冲区管理器
if (mBlastBufferQueue == null) {
mBlastBufferQueue = new BLASTBufferQueue(mTag, mSurfaceControl,
mSurfaceSize.x, mSurfaceSize.y,
mWindowAttributes.format);
mBlastBufferQueue.update(mSurfaceControl,
mSurfaceSize.x, mSurfaceSize.y, mWindowAttributes.format);
}这里创建的 BlastBufferQueue 将在后续的渲染过程中发挥关键作用:
- 为 RenderThread 提供高效的 Buffer 管理
- 支持批量 Transaction 提交,减少与 SurfaceFlinger 的交互开销
- 在 Perfetto 中可观察到 QueuedBuffer 指标的变化
后续直接调用 draw
android/graphics/HardwareRenderer.java
scss
mAttachInfo.mThreadedRenderer.draw(mView, mAttachInfo, this);
void draw(View view, AttachInfo attachInfo, DrawCallbacks callbacks) {
final Choreographer choreographer = attachInfo.mViewRootImpl.mChoreographer;
choreographer.mFrameInfo.markDrawStart();
// 更新 RootDisplayList,构建 RenderNode 树
updateRootDisplayList(view, callbacks);
// 处理动画 RenderNode
if (attachInfo.mPendingAnimatingRenderNodes != null) {
final int count = attachInfo.mPendingAnimatingRenderNodes.size();
for (int i = 0; i < count; i++) {
registerAnimatingRenderNode(
attachInfo.mPendingAnimatingRenderNodes.get(i));
}
attachInfo.mPendingAnimatingRenderNodes.clear();
attachInfo.mPendingAnimatingRenderNodes = null;
}
// 同步并绘制帧,这里会触发 RenderThread 工作
int syncResult = syncAndDrawFrame(choreographer.mFrameInfo);
// 处理各种结果状态
if ((syncResult & SYNC_LOST_SURFACE_REWARD_IF_FOUND) != 0) {
setEnabled(false);
attachInfo.mViewRootImpl.mSurface.release();
attachInfo.mViewRootImpl.invalidate();
}
if ((syncResult & SYNC_REDRAW_REQUESTED) != 0) {
attachInfo.mViewRootImpl.invalidate();
}
}上面的 draw 只是更新 DisplayList ,更新结束后,调用 syncAndDrawFrame ,通知渲染线程开始工作,主线程释放。在 syncAndDrawFrame 中完成了关键的 UI Thread 到 RenderThread 的数据同步过程。
UI Thread 与 RenderThread 的 DisplayList 同步机制
在 syncAndDrawFrame 这个关键函数中,发生了以下重要的同步操作:
arduino
// frameworks/base/libs/hwui/renderthread/RenderProxy.cpp
int RenderProxy::syncAndDrawFrame() {
// 1. 将 UI Thread 的 DisplayList 同步到 RenderThread
// 这里会把主线程构建的 RenderNode 树传递给渲染线程
return mDrawFrameTask.drawFrame();
}syncAndDrawFrame 的调用并非一个阻塞的同步过程,而是 UI 线程创建并派发一个 DrawFrameTask 到 RenderThread 的任务队列。这个 Task 封装了渲染这一帧所需的所有信息(主要是 RenderNode 树)。派发后,UI 线程就可以从渲染工作中解脱出来,处理其他事务。RenderThread 在自己的 Looper 中取出这个 Task 并执行,从而实现了两个线程的并行工作。
具体的同步过程包括:
- RenderNode 树的传递:主线程在 draw 过程中构建的 RenderNode 树(包含 DisplayList)会被传递给 RenderThread
- 属性同步:View 的变换矩阵、透明度、裁剪区域等属性会一并同步
- 资源共享:纹理、Path、Paint 等绘制资源在两个线程之间建立共享机制
- 渲染状态传递:当前帧需要的渲染状态信息传递给 RenderThread
这个同步过程是 Android 硬件加速渲染的核心,它实现了 UI Thread 专注于逻辑处理,RenderThread 专注于渲染的分工模式。
渲染线程的核心实现在 libhwui 库里面,其代码位于 frameworks/base/libs/hwui
RenderThread 与 BlastBufferQueue 的交互流程
RenderThread 接收到同步的 DisplayList 后,开始真正的渲染工作,这个过程中会与 BlastBufferQueue 进行密切的交互:
scss
// frameworks/base/libs/hwui/renderthread/CanvasContext.cpp
// Android 16 最新的 RenderThread 渲染流程
void CanvasContext::draw() {
SkRect dirty;
mDamageAccumulator.finish(&dirty);
// 1. 从 BlastBufferQueue 获取可用的 Buffer
ANativeWindowBuffer* buffer;
int fenceFd;
status_t result = mNativeSurface->dequeueBuffer(&buffer, &fenceFd);
if (result != OK) {
ALOGW("Failed to dequeue buffer: %s (%d)", strerror(-result), result);
return;
}
// 2. 设置渲染目标并绑定 Buffer
mRenderPipeline->onDequeueBuffer(buffer);
// 3. 执行 GPU 渲染命令,包括所有 RenderNode 的绘制
bool drew = mRenderPipeline->draw(frame, windowDirty, dirty, mLightGeometry,
&mLayerUpdateQueue, mContentDrawBounds, mOpaque,
mLightInfo, mRenderNodes, &(profiler()));
// 4. 完成渲染后,提交 Buffer(可能 unsignaled)
if (drew) {
// GPU 异步渲染,获取 presentFence(可能未 signal)
int presentFence = mRenderPipeline->flush();
// 5. 直接提交 Buffer 到队列(无需等待 GPU 完成),并将 presentFence 传递给消费者
// presentFence 是一个同步锁,由 GPU 在完成渲染时解开。根据系统配置(latch_unsignaled),SurfaceFlinger 可能会等待这个 fence,也可能在 fence 未 signaled 时就提前开始合成工作。
result = mNativeSurface->queueBuffer(buffer, presentFence);
// 6. 触发 transaction,批量提交到 SurfaceFlinger
// SurfaceFlinger 将根据 latch_unsignaled 策略决定是否接受
if (mBlastBufferQueue != nullptr) {
mBlastBufferQueue->flushTransaction();
}
} else {
// 如果没有绘制内容,直接取消 Buffer
mNativeSurface->cancelBuffer(buffer, fenceFd);
}
}BlastBufferQueue 的关键特性:
- App 端管理:不同于传统的 BufferQueue 由 SurfaceFlinger 创建,BlastBufferQueue 是由 App 端创建和管理
- 减少同步等待:通过生产者-消费者模型,减少了 RenderThread 在 dequeueBuffer 时的等待时间
- 高效的缓冲区轮转:支持更智能的缓冲区管理策略,特别适配高刷新率显示器
- 异步提交:通过 transaction 机制异步地将完成的帧提交给 SurfaceFlinger
- 支持 unsignaled buffer :配合 SurfaceFlinger 的
latch_unsignaled策略,允许提交 GPU 尚未完成的 Buffer,进一步减少渲染延迟
关于 Latching Unsignaled Buffers 的深入探讨
现代 Android 系统对 presentFence 的处理有精细的控制,并非总是等待。这个机制被称为 "Latching Unsignaled Buffers" (捕获未就绪的缓冲区)。
- 传统模式 : SurfaceFlinger 必须等待 App 的
presentFence被 GPU signal 后,才能 "latch" (捕获) 这个 Buffer 进行合成。这保证了安全性,但增加了延迟。 - Latch Unsignaled 模式 : 在此模式下,SurfaceFlinger 可以立即 latch 一个 GPU 尚未完成渲染的 Buffer(即 fence 未 signaled),并提前开始部分合成工作。当它需要真正使用这个 Buffer 的内容时,它才会在内部等待
presentFence。这通过流水线化进一步隐藏了 GPU 渲染的延迟,对降低游戏、视频等全屏应用的输入延迟至关重要。
控制开关与策略 (Android 13+) :
这个行为可以通过系统属性 debug.sf.latch_unsignaled 进行全局调试,但更重要的是,它由一个名为 LatchUnsignaledConfig 的分层策略控制。一个典型的策略是 AutoSingleLayer:
- 当屏幕上只有单个图层更新时(如全屏游戏或视频),系统会自动启用 Latch Unsignaled 模式,因为此时没有复杂的图层依赖,风险最低,收益最大。
- 当有多个图层更新时,系统会回退到更安全的传统等待模式,以避免潜在的视觉错误。
因此,SurfaceFlinger 并非总是盲目等待 presentFence,而是根据精密的策略来决定是否"抢跑",以在稳定性和极致性能之间取得平衡。
主线程和渲染线程的分工
主线程负责处理进程 Message、处理 Input 事件、处理 Animation 逻辑、处理 Measure、Layout、Draw ,更新 DisplayList ,但是不涉及与 SurfaceFlinger 直接打交道;渲染线程负责渲染相关的工作,包括与 BlastBufferQueue 的交互、GPU 渲染命令的执行,以及与 SurfaceFlinger 的最终交互。
当启动硬件加速后,在 Measure、Layout、Draw 的 Draw 这个环节,Android 使用 DisplayList 进行绘制而非直接使用 CPU 绘制每一帧。DisplayList 是一系列绘制操作的记录,抽象为 RenderNode 类,这样间接的进行绘制操作的优点如下
- DisplayList 可以按需多次绘制而无须同业务逻辑交互
- 特定的绘制操作(如 translation、scale 等)可以作用于整个 DisplayList 而无须重新分发绘制操作
- 当知晓了所有绘制操作后,可以针对其进行优化:例如,所有的文本可以一起进行绘制一次
- 可以将对 DisplayList 的处理转移至另一个线程(也就是 RenderThread)
- 主线程在 sync 结束后可以处理其他的 Message,而不用等待 RenderThread 结束
- 通过 BlastBufferQueue 实现更高效的缓冲区管理,减少渲染延迟和主线程阻塞
BlastBufferQueue 的工作原理
BlastBufferQueue 是现代 Android 渲染架构中的关键组件,它改变了传统的缓冲区管理方式:
传统 BufferQueue vs BlastBufferQueue:
-
创建主体不同:
- 传统 BufferQueue:由 SurfaceFlinger 创建和管理
- BlastBufferQueue:由 App 端(ViewRootImpl)创建和管理
-
缓冲区获取机制:
- 传统方式:RenderThread 需要通过 Binder 调用向 SurfaceFlinger 请求 Buffer,可能会因为没有可用 Buffer 而阻塞
- BlastBufferQueue:App 端预先管理缓冲区池,RenderThread 可以更高效地获取 Buffer
-
提交机制:
- 传统方式:通过 queueBuffer 直接提交给 SurfaceFlinger
- BlastBufferQueue:通过 transaction 机制批量提交,减少 Binder 调用开销
在 Perfetto 中观察 BlastBufferQueue:
在 Perfetto 跟踪中,BlastBufferQueue 的状态通过以下关键指标显示:
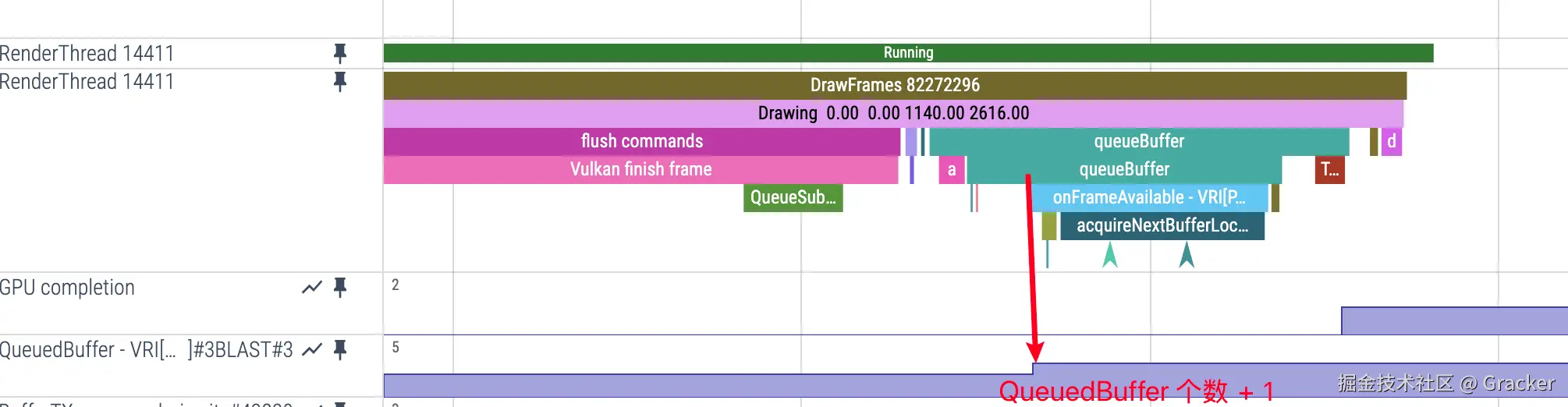
App 端的 QueuedBuffer 指标
- Perfetto 显示 :
QueuedBuffer数值轨道 - 计算规则:App 生产的 Buffer 总数 = QueuedBuffer - 1
- 基准值说明:QueuedBuffer 的最小值为 1,0 表示没有 Buffer 在队列中
- 数值含义:QueuedBuffer 为 2 表示有 1 个 Buffer 在队列中,QueuedBuffer 为 3 表示有 2 个 Buffer 在队列中,以此类推

QueuedBuffer 数值变化时机
QueuedBuffer +1 的时机:
- 触发条件 :RenderThread 执行
queueBuffer操作 - Perfetto 表现 :
queueBuffer事件执行时,QueuedBuffer 计数增加 - 含义:RenderThread 将渲染完成的 Buffer 提交到 App 端的 BlastBufferQueue 中等待发送给 SurfaceFlinger
QueuedBuffer -1 的时机:
- 触发条件 :收到 SurfaceFlinger 的
releaseBufferCallback - Perfetto 表现 :可观察到
releaseBuffer相关事件 - 含义:SurfaceFlinger 已使用完某个 Buffer,将其释放回 App 端 BlastBufferQueue,该 Buffer 可重新用于渲染
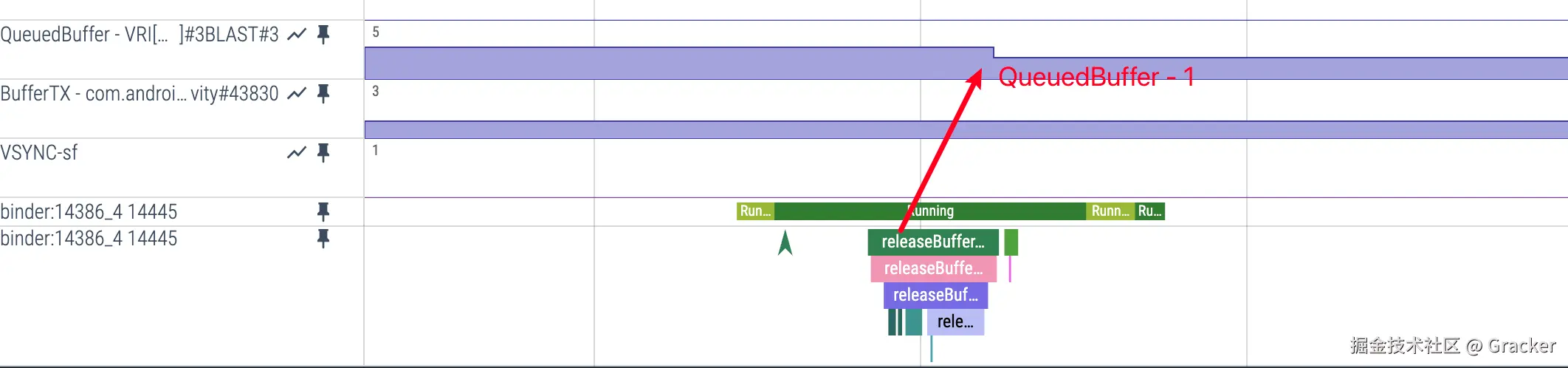
SurfaceFlinger 端的 BufferTX 指标
- Perfetto 显示 :SurfaceFlinger 进程中的
BufferTX数值轨道 - 变化时机:SurfaceFlinger 接收到 Transaction 后 BufferTX +1
- 触发条件 :App 端通过
flushTransaction将 Buffer 真正发送给 SurfaceFlinger - 最大值限制:BufferTX 最高为 3
- 原因说明 :这个最大值为 3 的限制,实际上就是我们熟知的三缓冲(Triple Buffering) 机制在合成侧的体现:一个正在被显示器读取(Front Buffer),一个准备在下一个 Vsync 周期被合成(Back Buffer),还有一个作为备用(Third Buffer)。这确保了即使在轻微的渲染抖动下,SurfaceFlinger 依然有帧可合成,从而提升流畅度。
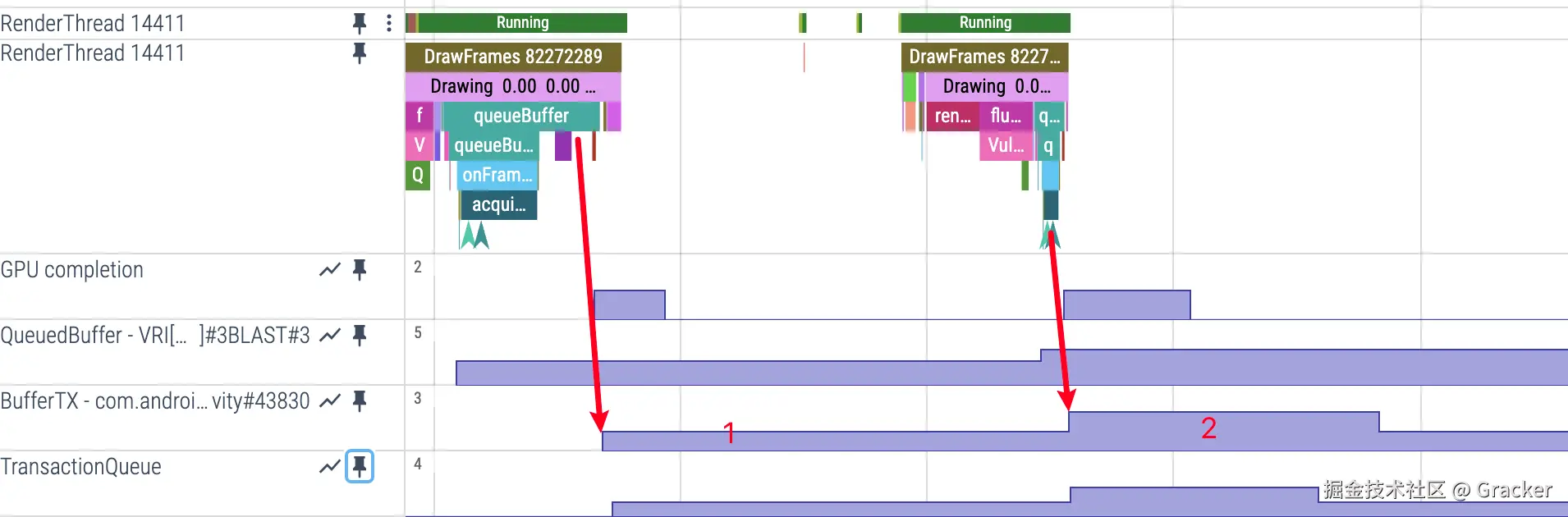
App 端和 SF 端的协作流程
- App 端 :RenderThread
queueBuffer→ App 端 QueuedBuffer +1(Buffer 进入 App 端队列) - App 端 :
flushTransaction→ 将队列中的 Buffer 批量发送给 SurfaceFlinger - SF 端:接收 Transaction → SF 端 BufferTX +1(Buffer 进入 SF 端处理)
- SF 端 :处理完成后发送
releaseBufferCallback→ App 端 QueuedBuffer -1(Buffer 释放回 App)
关键性能观察点
在分析性能时,重点关注:
- App 端 QueuedBuffer 数值:反映渲染生产速度,如果 App 生产过慢,QueuedBuffer 个数就可以反应出来 (always 是 1 ,说明没有 Buffer 生产出来)。重点关注需要连续出帧的场景(比如滑动过程),QueuedBuffer 的值为 1 超过 1 个 Vsync 的地方,看对应的 App 主线程和渲染线程是否有性能问题。
- SurfaceFlinger 端 BufferTX:反映系统合成处理能力 ,如果 SurfaceFlinger 消费 Buffer 过慢,也会有性能问题。重点关注需要连续出帧的场景(比如滑动过程) ,对应的 BufferTX 为 0 的情况 或者 BufferTX 没有被消费的情况,前一种情况是 App 的问题,后一种情况是 SurfaceFlinger 的问题。
性能
如果主线程需要处理所有任务,则执行耗时较长的操作(例如,网络访问或数据库查询)将会阻塞整个界面线程。一旦被阻塞,线程将无法分派任何事件,包括绘图事件。主线程执行超时通常会带来两个问题
- 卡顿:如果主线程 + 渲染线程每一帧的执行都超过 8.33ms(120fps 的情况下),那么就可能会出现掉帧(说可能是因为有的情况下其实不会掉帧,因为有 app duration 、buffer 堆积等情况)。
- 卡死 :如果界面线程被阻塞超过几秒钟时间(根据组件不同 , 这里的阈值也不同),用户会看到 "应用无响应" (ANR) 对话框(部分厂商屏蔽了这个弹框,会直接 Crash 到桌面)
对于用户来说,这两个情况都是用户不愿意看到的,所以对于 App 开发者来说,两个问题是发版本之前必须要解决的,ANR 这个由于有详细的调用栈,所以相对来说比较好定位;但是间歇性卡顿这个,可能就需要使用工具来进行分析了:Perfetto + Trace View (Android Studio 已经集成) ,所以理解主线程和渲染线程的关系和他们的工作原理是非常重要的,这也是本系列的一个初衷。
Perfetto 独有的 FrameTimeline 功能
Perfetto 相比 Systrace 的一个重要优势是提供了 FrameTimeline 功能,可以一眼就可以看到卡顿的地方。
注意: FrameTimeline 需要 Android 12(S) 或更高版本支持
FrameTimeline 的核心概念
根据 Perfetto 官方文档,当帧在屏幕上的实际呈现时间与调度器预期的呈现时间不匹配时,就会产生卡顿。FrameTimeline 为每个有帧在屏幕上显示的应用添加了两个新的轨道:

1. Expected Timeline(预期时间线)
- 作用: 显示系统分配给应用的渲染时间窗口
- 开始时间: Choreographer 回调被调度运行的时间
- 含义: 为了避免系统卡顿,应用需要在这个时间范围内完成工作
2. Actual Timeline(实际时间线)
- 作用: 显示应用完成帧的实际时间(包括 GPU 工作)
- 开始时间 :
Choreographer#doFrame或AChoreographer_vsyncCallback开始运行的时间 - 结束时间 :
max(GPU 时间, Post 时间),其中 Post 时间是帧被提交到 SurfaceFlinger 的时间
当你点击 Actual Timeline 上的一个 追踪的时候,会显示这一帧具体的被消费的时间(可以看延时)。
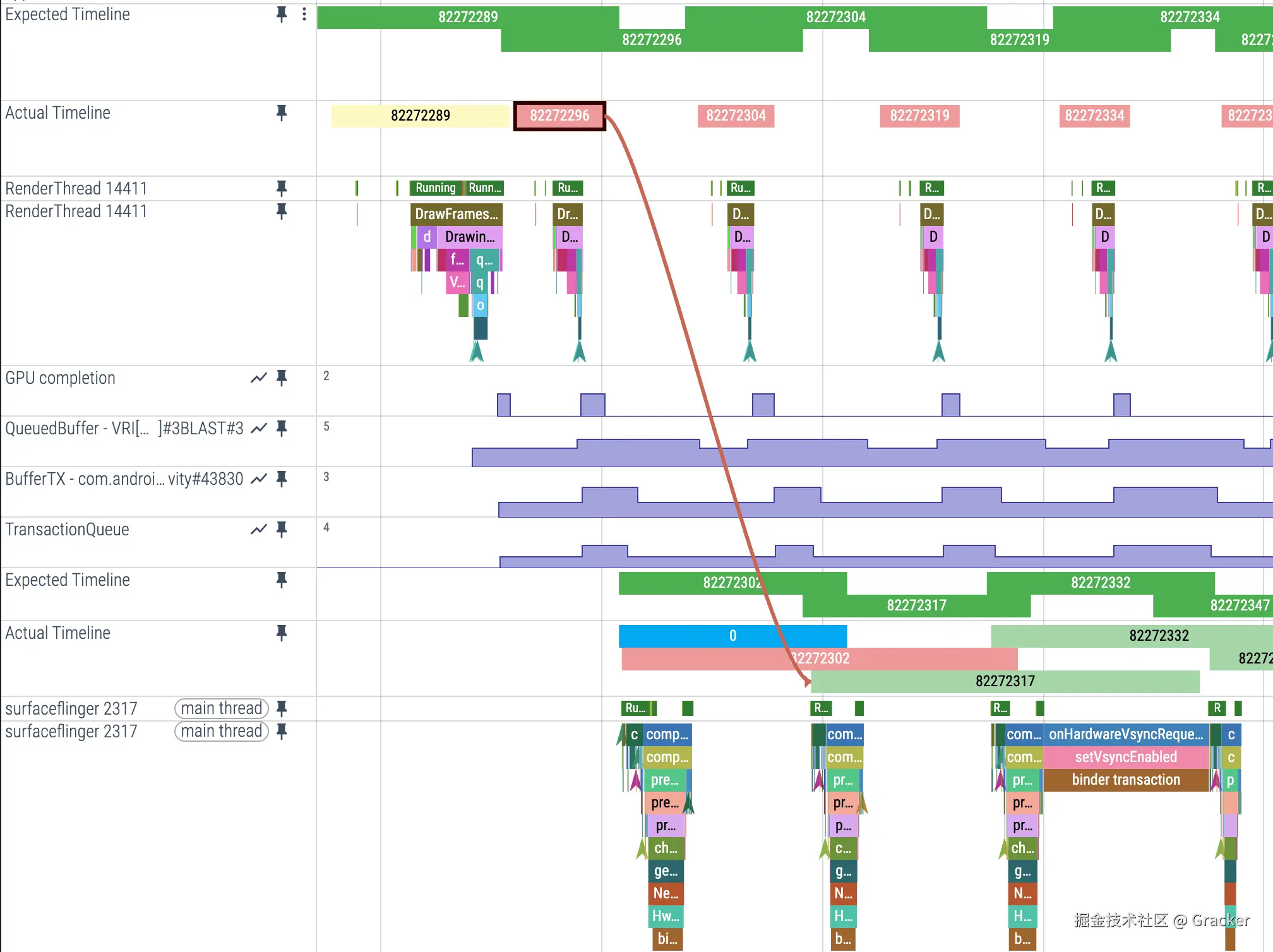
颜色编码系统
FrameTimeline 使用直观的颜色来标识不同的帧状态:
| 颜色 | 含义 | 说明 |
|---|---|---|
| 绿色 | 正常帧 | 没有观察到卡顿,理想状态 |
| 浅绿色 | 高延迟状态 | 帧率稳定但帧呈现延迟,导致输入延迟增加 |
| 红色 | 卡顿帧 | 当前进程导致的卡顿 |
| 黄色 | 应用无责任卡顿 | 帧出现卡顿但应用不是原因,SurfaceFlinger 导致的卡顿 |
| 蓝色 | 丢帧 | SurfaceFlinger 丢弃了该帧,选择了更新的帧 |
点击不同颜色的 ActualTimeline 可以在信息栏看到下面的描述,告诉你卡顿的原因:

卡顿类型分析
FrameTimeline 可以识别多种卡顿类型:
应用端卡顿:
- AppDeadlineMissed: 应用运行时间超过预期
- BufferStuffing: 应用在前一帧呈现前就发送新帧,导致 Buffer 队列堆积
SurfaceFlinger 卡顿:
- SurfaceFlingerCpuDeadlineMissed: SurfaceFlinger 主线程超时
- SurfaceFlingerGpuDeadlineMissed: GPU 合成时间超时
- DisplayHAL: HAL 层呈现延迟
- PredictionError: 调度器预测偏差
配置 FrameTimeline
在 Perfetto 配置中启用 FrameTimeline:
arduino
data_sources {
config {
name: "android.surfaceflinger.frametimeline"
}
}Perfetto 中 Vsync 信号
在 Perfetto 中,Vsync 信号使用 Counter 类型来显示,这与很多人的直觉认知不同:
- 0 → 1 的变化:表示一个 Vsync 信号
- 1 → 0 的变化:同样表示一个 Vsync 信号
- 错误理解:很多人误以为只有变成 1 才是 Vsync 信号
正确的 Vsync 信号识别
下图中 1 、2、3、4 的时间点都是 Vsync 信号到达

关键要点:
- 每次数值变化都是一个 Vsync:无论是 0→1 还是 1→0
- 信号频率:120Hz 设备上约每 8.33ms 会有一次变化(实际可能因系统调度略有差异,这里指的是连续出帧场景)
- 多 App 场景:Counter 可能因为其他 App 的申请而保持活跃状态
分析技巧
判断 App 是否接收到 Vsync:
- 正确方法 :查看 App 进程中是否有对应的
FrameDisplayEventReceiver.onVsync事件 - 错误方法 :仅凭 SurfaceFlinger 中的
vsync-appcounter 变化来判断
参考
- juejin.im/post/5a9e01...
- www.cocoachina.com/articles/35...
- juejin.im/post/5b7767...
- gityuan.com/2019/06/15/...
- developer.android.google.cn/guide/compo...
附件
本文涉及到的 Perfetto 跟踪文件也上传了,各位下载后可以在 Perfetto UI (ui.perfetto.dev/) 中打开分析
关于我 && 博客
下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
- 博主个人介绍 :里面有个人的微信和微信群链接。
- 本博客内容导航 :个人博客内容的一个导航。
- 个人整理和搜集的优秀博客文章 - Android 性能优化必知必会 :欢迎大家自荐和推荐 (微信私聊即可)
- Android性能优化知识星球 : 欢迎加入,多谢支持~
一个人可以走的更快 , 一群人可以走的更远