文章目录
- 基础IO
-
- 理解"文件"
- 文件系统调用接口
- 文件描述符(fd)
-
- open函数的返回值
- [特殊的fd:0, 1, 2](#特殊的fd:0, 1, 2)
- 文件描述符(fd)的本质
- fd的分配原则
- 通过dup2实现重定向
- 理解一切皆文件
- 缓冲区
-
- [read 和 write 与内核级缓冲区的关系](#read 和 write 与内核级缓冲区的关系)
- [C 语言 FILE 封装用户级级缓冲区](#C 语言 FILE 封装用户级级缓冲区)
- [C 语言级用户缓冲区的刷新策略](#C 语言级用户缓冲区的刷新策略)
- 关于缓冲区的三个现象
- 简单设计一下libc库
基础IO
理解"文件"
文件的构成:内容与属性
创建一个空文件时,它依然会占据一定的存储空间 -- 这里的 "空",仅指代文件 内容为空 ,而非文件本身没有任何存储开销.因为文件的构成包含两部分核心:
文件 = 文件内容 + 文件属性 文件 = 文件内容+文件属性 文件=文件内容+文件属性
文件属性是描述文件的元数据,比如文件名,创建时间,修改时间,权限等,这些信息无论文件内容是否存在,都需要占用存储空间来记录.
相应地,对文件的操作也自然分为两类:一类是对文件内容的操作 ,比如向文件中写入数据,从文件中读取数据等;另一类是对文件属性的操作,比如修改文件名,调整文件权限等.
而无论要执行哪一类操作,其首要前提都是要先"访问文件" -- 即通过文件路径定位到文件,由 OS 验证权限后,获取用于操作的标识(如文件描述符,文件指针),只有这样才能通过该标识间接对文件的内容或属性进行操作.
访问文件的核心逻辑:进程与文件的交互
下面通过一段简单的 C 语言代码和运行结果,来拆解 "程序操作文件"的核心逻辑 -- 其本质是 进程与文件的交互,而"访问文件"的第一步,必然是通过路径定位文件,再由进程发起"打开"请求.
c
#include <stdio.h>
int main()
{
FILE* fp = fopen("hello.txt", "w"); // 以写方式打开,文件不存在就创建
if (fp == NULL)
perror("fopen");
char* str = "hello";
for (int i = 0; i < 5; i ++)
{
fprintf(fp, "%s : %d\n", str, i);
}
fclose(fp);
return 0;
}
shell
# ls
makefile operfile operfile.c
# ./operfile
# ls
hello.txt makefile operfile operfile.c
# cat hello.txt
hello : 0
hello : 1
hello : 2
hello : 3
hello : 4运行前,当前目录下只有 makefile,operfile,operfile.c;运行程序后,目录中新增了 hello.txt,且文件内容为 5 行"hello : 数字"-- 这说明程序成功创建并写入了文件.
访问文件:必须通过"路径"定位,无路径则默认使用进程的 cwd
代码中没写路径,但是也能找到路径,其实不是不需要路径,而是使用了默认路径:进程当前的工作目录(Current Working Directory,cwd)
通过 ls查看进程文件夹,可以看到其 cwd,这正是创建"hello.txt"的目录
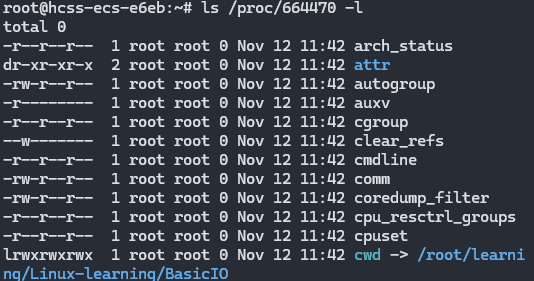
在上述代码 fopen前添加 chdir("../"),修改了进程的 cwd,更改工作目录后,会发现"hello.txt"出现在了上一层目录中.
shell
# ls ../
BasicIO myshell Process test_01 笔记
# ./operfile
# ls ../
BasicIO hello.txt myshell Process test_01 笔记程序是"静态的代码集合",只有被加载到内存中运行,才会成为"进程" -- 静态程序无法操作任何文件,只有运行起来的进程,才能通过路径定位文件,向 OS 申请资源,通过文件指针/文件操作符操作文件.
Linux下文件分类及组织
Linux 中的文件按"是否被加载到内存" 可分为两类:
①未被进程打开的文件,以持久化形式存储在磁盘上,称为 磁盘文件 .
②被进程打开后,从磁盘加载到内存中的文件,称为 内存文件.
由于CPU不能直接访问磁盘,只能直接访问内存,所以进程打开文件,本质是将磁盘文件的内容和属性加载到内存,转换为内存文件后,随后进行文件相关操作.
由于系统中可能同时存在大量被不同进程打开的内存文件,为了高效管理这些内存文件,Linux 设计了专门的 文件结构体 (如 struct file),每个内存文件都对应一个这样的结构体实例.系统会将所有文件结构体用链表的形式串联起来,如此一来,对内存文件的管理,本质上就是对这个链表的增删查改操作.
C打开文件的模式
C 语言标准库提供了一套完整的文件操作接口,这些接口基于"文件指针(
FILE*)" 实现对文件的访问,核心可分为打开/ 关闭文件 和操作文件(读 /写 / 定位等) 两大类.这些接口封装了底层系统调用,自带用户态缓冲区,简化了文件操作的复杂度.
具体操作详见C语言:文件操作,下面简单复习一下
C语言中,由 fopen的文件操作符(mode)参数来指定,常用的模式包括:
| 模式 | 核心权限 | 文件不存在时 | 写操作行为 | 读写位置起点 | 适用场景 |
|---|---|---|---|---|---|
r |
只读 | 报错(NULL) |
不允许写 | 文件开头 | 读取已存在的文件(如读配置文件) |
w |
只写 | 创建文件 | 清空原有内容(覆盖) | 文件开头 | 新建文件并写(如之前创建 hello.txt) |
a |
只写(追加) | 创建文件 | 数据追加到文件末尾 | 文件末尾 | 日志写入(不覆盖历史内容) |
r+ |
读写 | 报错(NULL) |
不清空原有内容 | 文件开头 | 读 + 修改已存在文件(不新建) |
w+ |
读写 | 创建文件 | 清空原有内容(覆盖) | 文件开头 | 新建文件并读写(如先写后读) |
a+ |
读写(追加) | 创建文件 | 写数据追加到末尾 | 读:文件开头;写:末尾 | 读历史内容 + 追加新内容(如日志读写) |
重点讲一下 a,a是 appending的缩写,代表"追加模式",是文件写入操作中用于保留原有内容的核心模式.其核心特性是:以 a模式打开文件时,所有写入操作都会自动追加到文件末尾,无论文件原有内容如何,都不会被覆盖.
c
#include <stdio.h>
int main()
{
FILE* fp = fopen("hello.txt", "a");
if (fp == NULL) perror("fopen");
fputs("hello : appending\n", fp);
fclose(fp);
return 0;
}运行前 hello.txt已有内容:
shell
# cat hello.txt
hello运行程序后,新内容被追加到文件末尾,原有内容完整保留:
shell
# ./operfile
# cat hello.txt
hello
hello : appending # 新内容追加在末尾输出重定向 >,本质是对 w模式的封装:以 w模式打开文件时,会先清空文件原有内容,再从文件开头开始写入 ,这与 >的 "覆盖" 行为完全一致.
例如命令 > hello.txt,实际是对"hello.txt"清空,下面的代码可以模拟 shell 执行该命令的行为:
c
#include <stdio.h>
int main()
{ // 仅按w打开,不进行任何写入
FILE* fp = fopen("hello.txt", "w");
if (fp == NULL) perror("fopen");
fclose(fp);
return 0;
}运行前hello.txt的内容:
shell
# cat hello.txt
hello
hello : appending运行程序后,文件内容被清空,与 > hello.txt命令效果一致:
shell
# ./operfile
# cat hello.txt
# (文件内容为空)同样的,追加重定向 >>,本质是对 a模式的直接映射:以 >>重定向时,新内容会追加到文件末尾,原有内容不会被覆盖 ,与 a模式的行为完全一致.
文件系统调用接口
OS 的核心设计原则之一是隔离与保护 :用户程序(运行在用户态)不能直接访问硬件资源(如磁盘,内存等),必须通过内核(运行在内核态)提供的系统调用间接操作.
当用户要写入文件时(例如调用库函数 fprintf),本质要对磁盘上的文件进行修改,而磁盘是硬件,用户程序不可以直接进行操作,其必定封装了OS 提供的系统调用,系统调用让内核统一管理硬件资源.
系统调用虽然解决了"安全访问硬件"的问题,但是它是底层,粗糙,易用性低 的接口.C语言对此封装了底层系统调用,提供库函数(如 fprintf等),以此简化编程,提升效率,增强跨平台性.
系统文件IO,核心通过文件描述符(fd) 标识打开文件,主要涉及 open/close/read/write/lseek等系统调用.
文件打开:open()
文件打开,C语言是 fopen,系统调用是 open
c
#include <fcntl.h>
int open(const char* pathname, int flags);
int open(const char* pathname, int flags, mode_t mode);open的原型并非严格定义为两个,底层是可变参数 ,这里后面再解释,先重点关注 open的三个参数及返回值.
pathname:文件路径flags:文件打开模式(整数宏,通过|组合,核心分两类)- 访问权限 (必选,三选一):
O_RDONLY(只读),O_WRONLY(只写),O_RDWR(读写) - 行为控制 (可选):
O_CREAT(文件不存在则创建),O_TRUNC(文件存在则清空内容),O_APPEND(写操作追加到末尾),O_EXCL(与O_CREAT配合,文件存在则报错)等
- 访问权限 (必选,三选一):
mode:文件权限(仅O_CREAT时有效,如0644对应rw-r--r--,需与进程的 umask 配合)- 返回值:类型为
int, 成功返回fd(非负整数),失败返回-1(并设置errno)
flags参数控制文件打开方式
open函数的flags参数是控制文件打开方式的 "核心开关",由一系列预定义的整数宏(定义在<fcntl.h>中)组成,通过按位或(|) 操作组合使用.它决定了文件的访问权限(读 / 写),打开行为(创建/ 清空 /追加等),甚至是 IO 模式(阻塞 / 非阻塞).
flags是标志位,为 int类型,本质是位图,这样才能通过 |操作组合使用.
下面自己设计一个接口,按照传递标志位的方式,来理解 flags的使用.
首先用 #define定义 ONE,TWO等标志位,本质是每个标志占据一个独立的二进制位:
c
// 定义标志位
#define ONE (1<<0) // 0000 0001
#define TWO (1<<1) // 0000 0010
#define THREE (1<<2) // 0000 0100
#define FOUR (1<<3) // 0000 1000
// 打印函数,通过传递不同标志位组合让其打印不同数据
void Print(int flags) // 传递标志位
{
if (flags & ONE) printf("ONE\n");
if (flags & TWO) printf("TWO\n");
if (flags & THREE) printf("THREE\n");
if (flags & FOUR) printf("FOUR\n");
}
int main()
{
// 想打印谁,传对应标志位即可
printf("---print_ONE---\n");
Print(ONE);
printf("---print_TWO---\n");
Print(TWO);
printf("---print_ONE and print_THREE---\n");
Print(ONE|THREE);
printf("---print_ONE and print_TWO and print_THREE and print_FOUR---\n");
Print(ONE|TWO|THREE|FOUR);
return 0;
}用 #define定义 ONE,TWO等标志位,本质是每个标志占据一个独立的二进制位 .这样可以保证每个标志在二进制中只有1位1,其余位为0,确保多个标志组合时不会冲突.
需要同时启用多个选项时,通过 |操作将标志组合成一个整数.例如 Print(ONE | THREE),ONE(0001) | THREE(0100) -> 0101(十进制为5).这种组合方式,可以用一个整数来传递多个选项 ,无需为每个选项单独设计参数(比如写成 Print(int one, int two, int three, int four)),极大简化了函数接口.
标志位解析:用 & 检查选项是否可用.以 flags = ONE | THREE为例:
flags & ONE -> 0101 & 0001 = 0001(非0) -> 打印 ONE
flags & TWO -> 0101 & 0010 = 0000(0) -> 不打印 TWO
flags & THREE -> 0101 & 0100 = 0100(非0) -> 打印 THREE
flags & FOUR -> 0101 & 1000 = 0000(0) -> 不打印 FOUR
运行结果如下:
shell
# ./operfile
---print_ONE---
ONE
---print_TWO---
TWO
---print_ONE and print_THREE---
ONE
THREE
---print_ONE and print_TWO and print_THREE and print_FOUR---
ONE
TWO
THREE
FOURopen的参数 flags也是如此逻辑,flags参数可分为 必选的 "访问权限标志"和可选的 "行为控制标志" 两大类,前者决定"能对文件做什么",后者决定"如何做".
- 必选:访问权限标志(三选一,互斥)
这三个标志指定文件的基本访问权限,且 只能选一个(不能同时使用,否则会报错).
| 标志 | 含义 | 说明 |
|---|---|---|
O_REONLY |
Read Only(只读) | 打开文件后只能读取内容,无法写入(对应 C 库 fopen的 "r"模式) |
O_WRONLY |
Write Only(只写) | 打开文件后只能写入内容,无法读取(对应 "w"/"a"模式的写权限) |
O_RDWR |
Read and Write(读写) | 打开文件后既能读也能写(对应 "r+"/"w+"/"a+"模式的读写权限) |
- 可选:行为控制标志(可组合)
这类标志用于控制文件打开/操作的具体行为,可与访问权限标志通过|组合使用,核心常用标志如下.
| 标志 | 含义 | 说明 |
|---|---|---|
O_RDONLY |
Read Only(只读) | 打开文件后只能读取内容,无法写入(对应 C 库 fopen的 "r"模式) |
O_WRONLY |
Write Only(只写) | 打开文件后只能写入内容,无法读取(对应 "w"/"a"模式的写权限) |
O_TRUNC |
若文件已存在且可写(O_WRONLY/O_RDWR),则清空文件原有内容 |
对应 fopen("w")(覆盖写)、Shell 的 >重定向(清空后写入) |
O_APPEND |
写操作时,强制将数据追加到文件末尾(无论当前读写位置如何) | 对应 fopen("a")(追加写)、Shell 的 >>重定向(追加写入) |
open接口使用
下面用 open()打开 log.txt,没有就创建,同时打印 fd的值
c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
int fd = open("log.txt", O_WRONLY | O_CREAT);
if (fd < 0) perror("open");
printf("fd:%d\n", fd);
return 0;
}设置 flags为 O_WRONLY | O_CREAT,表示文件只写,若没有相应文件则创建.
返回值用 fd接收,进程对文件的操作都是通过 fd来进行的.
运行结果如下:
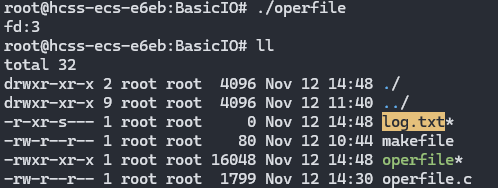
可以看到, log.txt 的权限是乱码,这是由于没有指定 mode参数,导致 mode参数接收到了一个随机值.
当创建一个文件,该文件是要受到 Linux 权限的约束的,需要告诉 OS 指定的权限是什么.
这时就要用到第三个参数 mode, 该参数仅 O_CREAT时有效,修改代码,将文件指定权限 0666即所有用户都可读可写:
c
int fd = open("log.txt", O_WRONLY | O_CREAT, 0666);运行后,查看 log.txt 的权限
shell
# ll log.txt
-rw-r--r-- 1 root root 0 Nov 12 14:59 log.txt # 权限为644?但是其权限不是指定的 666,而是 664.
这是由于 OS 有默认的权限掩码 umask
shell
# umask
0022指定 666时,因为 umask为 0022,需要 0666 - 0022 = 0644,所以最终给 log.txt 的权限为 644
umask实际上也是一个系统调用,可以让调用进程设置文件权限掩码
c
#include <sys/types.h>
#include <sys/stat.h>
mode_t umask(mode_t mask);就想要 log.txt 的权限为自己指定的 666, 就可以调用 umask(0)(设置默认文件权限掩码为 0000)
c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
umask(0); // 指定默认文件权限掩码
int fd = open("log.txt", O_WRONLY | O_CREAT, 0666);
if (fd < 0) perror("open");
printf("fd:%d\n", fd);
return 0;
}
shell
# ./operfile
fd:3
# ll log.txt
-rw-rw-rw- 1 root root 0 Nov 12 15:07 log.txtumask设置服从就近原则,若进程指定则使用指定的 umask,否则使用系统默认的 umask
文件关闭:close()
C 语言中文件关闭为 fclose,系统调用为 close
c
#include <unistd.h>
// 成功返回0,失败返回-1(设置errno)
int close(int fd);close关闭 fd,释放内核资源(文件描述符表项、文件对象等),必须调用(否则可能导致资源泄露).
c
// 操作完成后关闭fd
if (close(fd) == -1) {
perror("close failed");
return 1;
}文件写入:write()
C 语言中用的是 fprintf,fputs, fwrite 等接口,而在系统调用为 write.
c
#include <unistd.h>
// 成功返回实际写入的字节数,失败返回-1(设置errno)
ssize_t write(int fd, const void* buf, size_t count);fd:文件描述符(open返回的 fd)buf:待写入的内存缓冲区(如字符串,数组)count:期望写入的字节数(buf的长度)
下面向文件读入5行信息
c
const char* msg = "hello\n";
ssize_t sum_n = 0;
for (int i = 0; i < 5; i ++)
{
ssize_t n = write(fd, msg, strlen(msg));
sum_n += n;
}
printf("写入%ld字节\n", sum_n);
shell
# ./operfile
写入30字节
# cat log.txt
hello
hello
hello
hello
hello需要注意的是,write第三个参数不需要 strlen(buf)+1,不需要把 \0也写入.
\0是 C 语言的规定,字符串末尾为 \0,仅需把字符串本身写入,若把 \0写入打开文件会有乱码.
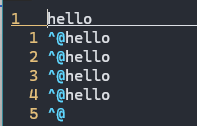
C 语言在 w 模式打开文件时,文件内容是会被清空的,但是 O_WRONLY并非如此
当前 log.txt 有如下数据
shell
# cat log.txt
abcdefg随后打开文件向其写入 aaa, flags仅设计为 O_WRONLY | O_CREAT
c
int main()
{
int fd = open("log.txt", O_WRONLY | O_CREAT, 0666);
if (fd < 0) perror("open"), exit(1);
const char* msg = "aaa";
write(fd, msg, strlen(msg)); // 写入aaa
close(fd);
return 0;
}
shell
# cat log.txt
abcdefg # 写入前 log.txt 的内容
# ./operfile # 写入 aaa
# cat log.txt
aaadefg # 写入后 log.txt 的内容可以看到,log.txt 并没有被清空后才写入,只有 O_WRONLY和 O_CREAT,是远远不够的.
若想达到 w的效果,需要添加 O_TRUNC
c
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
shell
# cat log.txt
aaadefg
# ./operfile
# cat log.txt
aaa同样,若想要达到 a的效果,需要添加 O_APPEND
c
int fd = open("log.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);# cat log.txt
aaa
# ./operfile
# cat log.txt
aaa
aaa文件读取:read()
C 语言中用的是 fscanf,fgets, fread,系统调用为 read
c
#include <unistd.h>
// 成功返回实际读取的字节数(0表示文件结束),失败返回-1(设置errno)
ssize_t read(int fd, void *buf, size_t count);read从 fd 对应的文件中读取数据到内存缓冲区,同样无用户态缓冲.
fd:文件描述符buf:接收数据的内存缓冲区(需预先分配空间)count:期望读取的最大字节数(buf的容量)
下面来读取 log.txt 的内容
c
int main()
{
int fd = open("log.txt", O_RDONLY); // 只读模式打开
if (fd < 0) perror("open"), exit(1);
char buf[1024] = {0, }; // 缓冲区
ssize_t n = read(fd, buf, sizeof(buf)-1); // 留1字节存'\0'
if (n == -1) {perror("read failed"); close(fd); return 1;}
printf("读取到%ld字节:%s\n", n, buf);
return 0;
}
shell
# ./operfile
读取到38字节:hello,i am the content of this file!!文件描述符(fd)
文件描述符(File Descriptor,简称
fd)是 Linux 系统中 标识 "打开文件" 的非负整数 ,是进程与内核之间交互文件(包括普通文件、设备、管道、网络套接字等)的 "唯一手柄"。所有系统级文件操作(如read/write/close)都通过fd完成,理解fd是掌握 Linux 文件 IO 的核心。
open函数的返回值
c
int fd = open("log.txt", O_RDONLY);open函数是打开/创建文件的系统调用,其返回值有明确的含义:
- 成功时,返回一个非负整数(如3, 4, 5...)
- 失败时,返回
-1(并设置errno标识错误原因)
这个"非负整数"就是文件描述符(fd) .
示例:创建多个文件,获取文件的 b
c
int main()
{
int fd1 = open("log1.txt", O_WRONLY | O_CREAT, 0666);
int fd2 = open("log2.txt", O_WRONLY | O_CREAT, 0666);
int fd3 = open("log3.txt", O_WRONLY | O_CREAT, 0666);
int fd4 = open("log4.txt", O_WRONLY | O_CREAT, 0666);
int fd5 = open("log5.txt", O_WRONLY | O_CREAT, 0666);
printf("fd1: %d\n", fd1);
printf("fd2: %d\n", fd2);
printf("fd3: %d\n", fd3);
printf("fd4: %d\n", fd4);
printf("fd5: %d\n", fd5);
close(fd1);
close(fd2);
close(fd3);
close(fd4);
close(fd5);
return 0;
}
shell
# ./operfile
fd1: 3
fd2: 4
fd3: 5
fd4: 6
fd5: 7发现 open的 5 个文件的 fd 分别是 3, 4, 5, 6, 7, 那么0, 1, 2去哪里了?
特殊的fd:0, 1, 2
每个进程启动时,无需手动 open,内核会自动打开 3 个文件,分配固定的 fd:
fd = 0:标准输入(stdin), 默认对应键盘fd = 1:标准输出(stdout),默认对应屏幕fd = 2:标准输出(stderr),默认对应屏幕
验证:fd=1时标准输出
c
int main()
{
// 向fd=1写入数据(默认输出到屏幕)
const char *msg = "fd=1 是标准输出\n";
write(1, msg, strlen(msg));
return 0;
}
shell
# ./operfile
fd=1 是标准输出在 C 语言中, write(1, msg, strlen(msg)) 相当于 fputs(msg, stdout), C 语言中的库函数封装了底层调用.
封装的不只是函数,C 语言也封装了 fd.在 C 语言中,文件操作都要使用 FILE*类型的文件指针, stdin, stdout, stderr就是 FILE*类型的,被默认打开.
c
#include <stdio.h>
extern FILE* stdin;
extern FILE* stdout;
extern FILE* stderr;FILE结构体的实现中,必然包含一个 fd成员 --- 它是 FILE*与底层文件的 "连接纽带".
那么,stdin封装 0,stdout封装 1,stderr封装 2,C 语言库函数底层调用文件系统调用接口,就会用到其文件指针封装的 fd.
验证:stdin,stdout,stderr封装 0, 1, 2
c
int main()
{
printf("stdin->fd: %d\n", stdin->_fileno);
printf("stdout->fd: %d\n", stdout->_fileno);
printf("stderr->fd: %d\n", stderr->_fileno);
return 0;
}
shell
# ./operfile
stdin->fd: 0
stdout->fd: 1
stderr->fd: 2fd的值为 0,1,2,3,4...,这很像数组下标,下面谈谈文件描述符的本质.
stdout和 stderr都是向显示器输出, stderr的存在可以分离错误信息.
c
int main()
{
fprintf(stdout, "正确输出1\n");
fprintf(stdout, "正确输出2\n");
fprintf(stdout, "正确输出3\n");
fprintf(stderr, "错误输出1\n");
fprintf(stderr, "错误输出2\n");
fprintf(stderr, "错误输出3\n");
return 0;
}上述代码利用重定向,可以分离错误信息
shell
# ./operfile 1>normal.txt 2>err.txt
# cat err.txt
错误输出1
错误输出2
错误输出3
# cat normal.txt
正确输出1
正确输出2
正确输出3文件描述符(fd)的本质
进程与被打开的文件(内存文件)之间,存在明确的 1:n 对应关系 --- 一个进程可以同时打开多个文件,这些被打开的文件会被加载到内存中成为"内存文件".
当系统运行时,会有大量进程同时工作,每个进程又可能打开多个文件,这意味着内核中会存在大量的"内存文件".如何高效管理这些分散的内存文件?操作系统的解决方案的核心逻辑依然是:先描述,再组织.
先描述:用 struct file刻画"打开的文件"
当一个文件被进程打开后,绝不仅仅是"把磁盘文件内容加载到内存"这么简单 --- 内核会为这个"打开的文件"创建一个专属的内核数据结构 struct file,用它来描述这个内存文件所有的关键信息.
可以把 struct file理解为内存文件的"身份证+状态报告",其简化结构如下:
c
struct file {
// 1. 文件的核心属性(从磁盘inode加载而来)
mode_t f_mode; // 打开模式(如O_RDONLY、O_APPEND)
loff_t f_pos; // 当前读写位置(类似数组下标,整数偏移量)
unsigned int f_flags;// 打开时的flags参数(如O_CREAT、O_NONBLOCK)
struct inode *f_inode; // 指向文件的inode(关联磁盘文件的静态属性)
// 2. 链表节点:用于参与"组织"逻辑
struct file *f_next; // 指向链表中的下一个struct file
struct file *f_prev; // 指向链表中的上一个struct file
};这个结构的核心作用是"描述":整合内存文件的动态状态 (读写位置,打开模式)和静态属性(关联的inode),让内核能够通过这个结构"看清"这个内存文件的所有细节.
再组织:用链表串联所有的 struct file
内核中会存在大量的 struct file(每个打开的文件对应一个),操作系统会用 struct file中的 f_next和 f_prev指针,将所有的 struct file 串联.
对内存文件加载删除等操作,本质是对该链表的增删查改.
目前先不用关注磁盘文件是如何加载到内存成为内存文件的,只用先明白:磁盘文件的属性和内容会分别被加载到 struct file的成员和该结构指向一个缓冲区内.

每个进程可以打开多个文件,那么怎么建立进程和内存文件的关系呢?
在进程的PCB(task_struct)中,包含了一个 struct files_struct *files的结构体指针,用于记录该进程打开的所有文件的信息.
c
/* open file information */
struct files_struct *files;同时,struct files_struct中,包含一个 struct file*类型的数组 fd_array[],该数组记录进程打开的内存文件结构体对象的地址,fd就是被打开文件在 fd_array[]的下标.
c
struct file * fd_array[NR_OPEN_DEFAULT];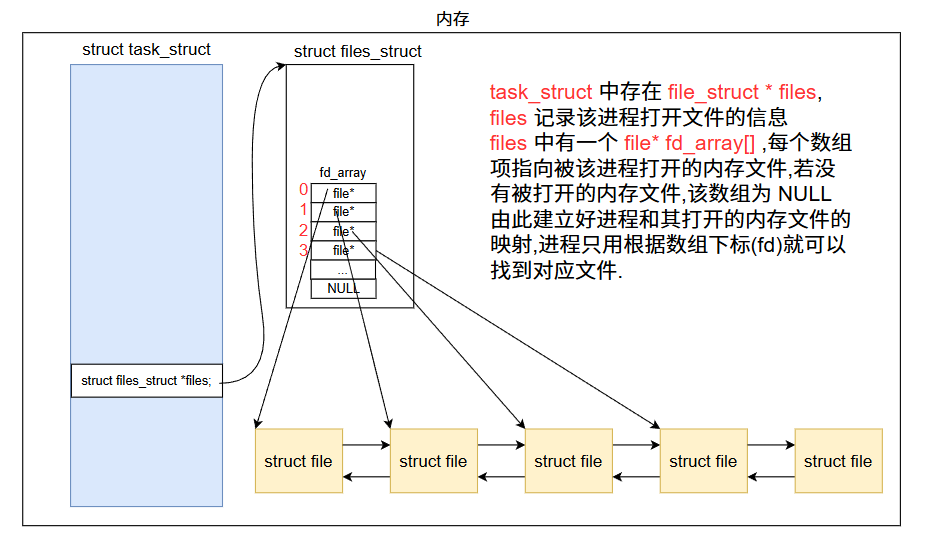
进程想访问其打开的文件,只需要知道该文件在这张映射表中的数组下标即可.这个下标 0,1,2,3,4 就是对应的文件描述符 fd .
fd的分配原则
示例:close(0)即关闭键盘文件后,再打开一个新文件,观察新文件 fd
c
int main()
{
close(0); // 关闭键盘文件
int fd = open("log.txt", O_WRONLY | O_CREAT, 0666); // 打开一个文件
if (fd < 0) perror("open"), exit(1);
printf("fd: %d\n", fd);
close(fd);
return 0;
}
shell
# ./operfile
fd: 0可以看到,分配给新文件的 fd为 0.
文件描述符分配的核心规则:最小未使用整数原则
当打开一个新文件时,会找到 fd_array[]最小未被使用的下标,下标未使用即为 fd_array[fd] == NULL,随后将该下标分配给新文件的 fd.
示例:那么如果关闭1呢?
c
int main()
{
close(1);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) perror("open"), exit(1);
printf("fd: %d\n", fd);
close(fd);
return 0;
}
shell
# ./operfile
#显示器没有打印显示 ,似乎 printf没有执行.可以预想到 fd=1 , 由于 printf默认输出到 stdout中,我们通过系统调用关闭了 1 ,但是 stdout 是 C 语言实现的,FILE结构体没有改变 ,stdout->_fileno仍为 1,所以最终应该会把内容写到 log.txt?
但是结果没有打印出来, log.txt 里面也什么都没有:
shell
# cat log.txt
# 在代码中加入 fflush(stdout),查看结果:
c
printf("fd: %d\n", fd); // stdout有错误状态,可能不进缓冲
fflush(stdout); // 尝试刷新缓冲
printf("fflush返回\n"); // 打印fflush返回
shell
# cat log.txt
fd: 1将显示器应该打印的内容输出到文件中,这本身就是输出重定向,使用 fflush(stdout)似乎刷新缓冲区成功了,但其实这样的重定向是有问题的,可以看到第二个 printf并没有重定向到 log.txt 中,必须还得手动刷新缓冲.
通过dup2实现重定向
在 C 语言中实现重定向的核心是利用 系统调用 dup2 修改文件描述符(fd)的指向,从而改变标准输入( stdin,fd=0),标准输出(stdout,fd=1)或标准错误( stderr,fd=2)的流向.
dup2是 Linux 系统中的核心系统调用,用于 复制文件描述符 ,让新的文件描述符(newfd)指向旧的文件描述符(oldfd)对应的文件对象,是实现 IO 重定向、共享文件访问等功能的关键工具。
c
#include <unistd.h>
int dup2(int oldfd, int newfd);-
参数 :
oldfd:要复制的"源文件描述符"(需是有效的,已打开的fd).newfd:目标文件描述符(若已打开,dup2会先关闭它,再让其指向oldfd的文件).
-
返回值 :
- 成功:返回
newfd - 失败:返回
-1,并设置errno(如oldfd无效时errno=EBADF)
- 成功:返回
通过 dup2系统调用,不需要手动 close,进行重定向仅仅修改 fd是不够的,还会有其他操作,通过系统调用可以完备地进行.
dup2的本质是:修改文件描述符表的映射关系 .
要注意 dup2的参数,调用 dup(oldfd, newfd),会让 fd_array[oldfd]和 fd_array[newfd]全都指向 oldfd对应的文件.所以若要进行输出重定向,dup2(fd,1)是正确的,这里 fd指向需要重定向输出的文件.
示例:使用 dup2进行输出重定向
c
int main()
{
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) perror("open"), exit(1);
dup2(fd, 1); // fd <- 1
fprintf(stdout, "fd: %d\n", fd);
close(fd);
return 0;
}
shell
# ./operfile
# cat log.txt
fd: 3理解一切皆文件
在谈 fd 的时候, 0, 1, 2 ->stdin ,stdout,stderr,对应的键盘,显示器等硬件;打开新文件 log.txt,分配其 fd=3.可以看到,在 Linux 中,硬件和普通文件是一样的,都是文件,遵循"一切皆文件"的设计.
硬件也由内核的 struct file 结构体来标识和管理.硬件设备被抽象为设备文件 ,设备文件和普通文件在内核中共享同一套管理机制(包括 struct file).
这样做最明显的好处是,开发者仅需要使⽤⼀套API和开发⼯具,即可调取Linux系统中绝⼤部分的资源 .举个简单的例⼦, Linux 中⼏乎所有读(读⽂件,读系统状态,读PIPE)的操作都可以⽤read函数来进⾏;⼏乎所有更改(更改⽂件,更改系统参数,写PIPE)的操作都可以⽤write函数来进⾏.
拿设备来说,键盘有其专属的的读(read_keyboard)和写(write_keyboard,若设备不支持则可置为空);显示器也有自己的读(read_screen)和写(write_screen);不同设备硬件都有自己不同的方法 ,而我们开发者面对的是统一的 struct file 结构体 , 那么,这种通过通用文件读写(如 read,write系统调用)到具体设备操作的映射,究竟是如何实现的呢?
在 struct file结构体中,有一个成员
c
const struct file_operations *f_op;它指向了一个结构体对象 file_operations,该结构体在 fs.h下有定义
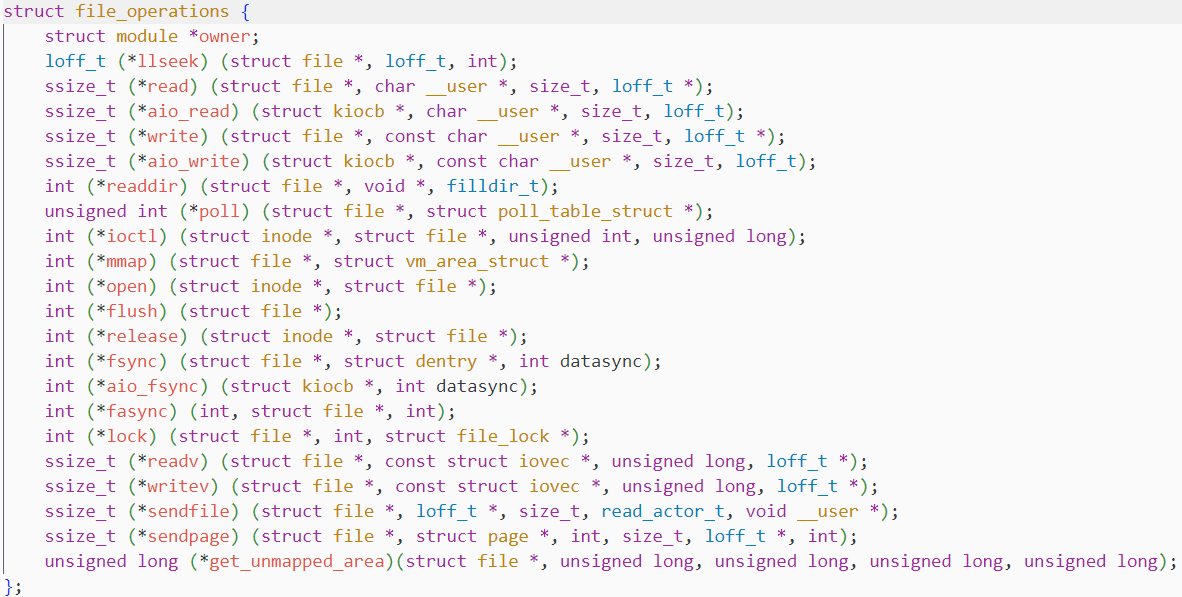
file_operation中,除了 owner,其他全是函数指针,该结构体构建了一层"接口适配层" --- 它像一个"函数指针对照表",将通用的文件操作(如"读","写")与设备特有的硬件逻辑(如 read_keyboard,write_screen)精准绑定.
设备既然也是文件,那么也分为被打开的文件和未被打开的文件.在磁盘中的设备文件会关联其特有的硬件操作逻辑(键盘读,显示器写等),这些具体操作被存放在 file_operations结构体中,并根据不同的设备进行不同的实例化出结构体对象.
当进程打开设备时,内核会为打开的设备创建一个 struct file,并将 struct file的 f_op指向该设备对应的 file_operations实例.此时 struct file就像是一个"中间代理",通过 f_op与设备的具体操作方法建立了隐形关联(面向对象思想中的"多态" 在 kernel 中的实现).
当开发者调用 read(fd, buf, n)时,内核会沿着 fd ->struct file->file_operations->设备特有函数的路径,自动完成由通用接口到硬件操作的转换.
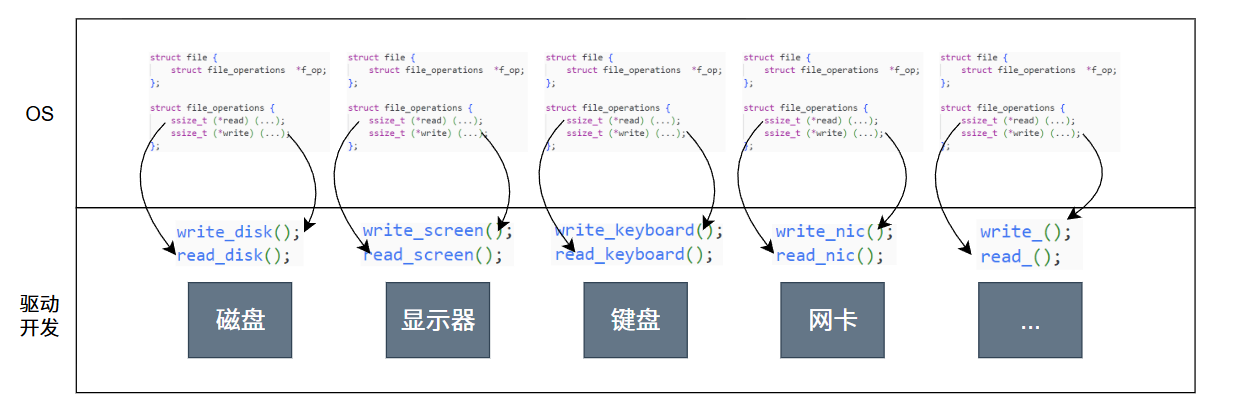
在 C 语言中,Linux 内核正是通过 struct file和 struct file_operations的组合, 模拟了面向对象中的"多态"特性 --- struct file 相当于"基类",struct file_operations 中的 read/write 等函数指针则相当于"虚函数",而不同设备的 file_operations 实例则是"派生类"对虚函数的具体实现.
缓冲区
缓冲区的核心作用是 减少低速 IO(如磁盘、键盘、网络)的直接操作次数 ------ 因为内存操作速度远快于硬件 IO,通过先在内存中暂存数据,达到一定量后再批量写入 / 读出硬件,能大幅提升系统效率。Linux 系统中,缓冲区分为两层: 用户态的 C 语言级缓冲区 (库层)和 内核态的内核级缓冲区 (内核层),二者协同完成 IO 操作。
read 和 write 与内核级缓冲区的关系
当打开一个文件时,操作系统会预先将文件的部分(或全部)内容从磁盘加载到内核级缓冲区,这一过程涉及硬件IO,必须由操作系统参与并通过系统调用完成,目的是将低速磁盘数据暂存到高速内存中,为后续访问提速.
这一涉及直接影响了 read和 write系统调用的行为,它们本质都是内存间的拷贝操作,而非直接与硬件进行交互.
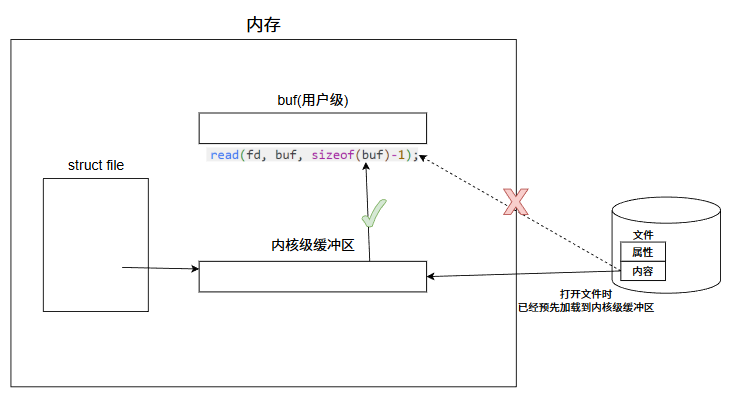
以 read为例:
c
char buf[1024]; // 用户级缓冲区
read(fd, buf, sizeof(buf)-1);read会将内核级缓冲区(已缓存的文件数据,位于内核态内存)的内容,拷贝 到用户态的 buf.整个过程 read并不直接访问磁盘,而是读取内存中的内核级缓冲区.
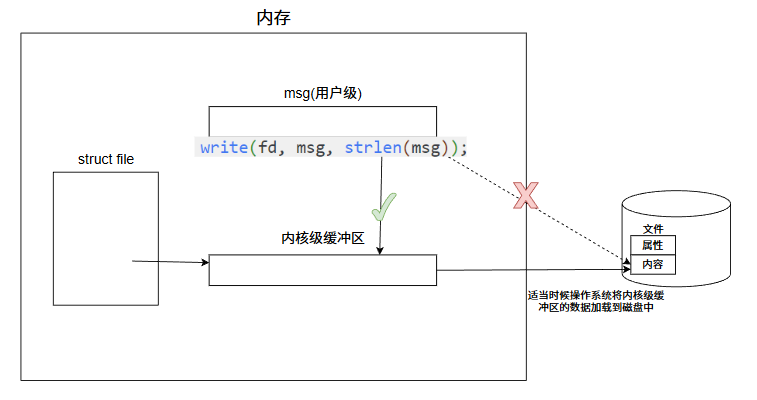
write操作的逻辑类似,同样是拷贝:
c
char *msg = "hello"; // 用户级缓冲区
write(fd, msg, strlen(msg);write并不会将数据直接写入磁盘,而是将用户态 msg的内容复制到内核级缓冲区.数据会暂时存放在内核缓冲区中,直到内核缓冲区满,调用 fsync或系统调度时,操作系统才会批量将内核级缓冲区的数据写入磁盘.
为什么要设置缓冲区?直接和磁盘进行IO不好吗?
若不设置缓冲区,那么每次对文件进行一次读写操作时,都需要读写系统调用来处理此操作,执行一次系统调用将涉及 CPU 状态的切换,即从用户态转换为内核态,同时实现进程上下文的切换,这将损耗一定的 CPU 时间,频繁的磁盘访问对程序的执行效率造成很大的影响.
为了减少使用系统调用的次数,提高效率,就可以采用缓冲机制.这样就可以减少系统调用次数,再加上计算机对缓冲区的操作大大快于 IO 操作,故应用缓冲区可以大大提高计算机的运行速度.
C 语言 FILE 封装用户级级缓冲区
调用系统调用(比如 read,write)是有成本的 --- 每次调用都要经历"用户态->内核态"的切换,还要执行内核的权限检查,上下文保存等操作,频繁调用会显著消耗性能.
内核级缓冲区的引入,确实减少了与硬件(如磁盘)的直接 IO 次数,但是我们通过 read,write系统调用与内核级缓冲区交互时,每调用一次就会产生一次系统调用开销 .如果程序需要频繁读写少量数据(比如循环打印单个字符),频繁的 read/write系统调用会成为性能瓶颈.
为了解决这个问题, C 语言的标准库在 FILE指针中做了一层关键封装:它不仅包裹了与内核交互的 fd(文件描述符,用来关联内核级缓冲区和文件), 还额外封装了一块 语言级缓冲区(位于用户态内存的一块临时存储区域) --- 核心目的就是 "攒够数据再批量发起系统调用",从而最大化减少系统调用的次数.

借助 C 标准库 FILE的封装,当用户调用 fopen函数打开文件时,C 库会自动在用户态内存中创建一块用户级缓冲区,这块缓冲区完全由 C 标准库管理,无需手动分配或维护.
当需要向文件写入数据时(例如调用 fprintf, fwrite等函数),数据并不会直接进入内核或磁盘 --- 而是先被拷贝 至这块用户级缓冲区暂存,等满足特定条件时, C 库才会触发一次 write系统调用,将用户级缓冲区的数据批量拷贝至内核级缓冲区.这里的"适当时候"包括:用户级缓冲区被写满,主动调用 fflush强制刷新,调用 fclose关闭文件,或是行缓冲模式下遇到 \n换行符.
随后就是上述讲解内核级缓冲区被写入物理磁盘中文件的流程.
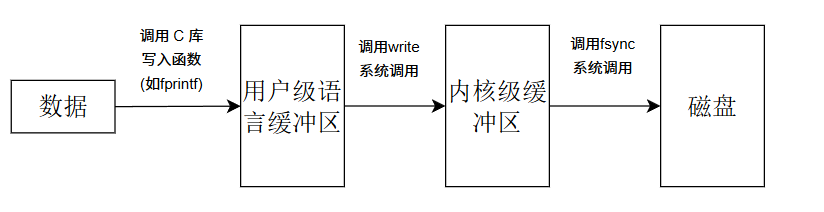
除去手动调用 C 库函数,剩余系统调用都会根据缓冲区的缓冲类型自动进行调用,若需要立刻刷新缓冲区来调用系统调用,也有库函数 fflush和系统调用 fsync 分别用于刷新用户级缓冲区和内核级缓冲区.
C 语言级用户缓冲区的刷新策略
用户级缓冲区由 C 标准库管理,刷新策略和缓冲模式强绑定(全缓冲,行缓冲,无缓冲).
| 缓冲模式 | 适用场景 | 核心刷新条件 |
|---|---|---|
| 行缓冲 | stdout(显示器输出) |
① 遇到 \n 换行符;② 缓冲区被写满;③ 主动调用 fflush(fp);④ 切换读写方向(如先写后读) |
| 全缓冲 | 普通文件(如 test.txt) |
① 缓冲区被写满(默认通常 4KB);② 主动调用 fflush(fp);③ 调用 fclose(fp) 关闭文件 |
| 无缓冲 | stderr(标准错误) |
无缓冲,数据写入时直接调用 write 同步到内核,不暂存(保证错误信息即时输出) |
无论哪种缓冲模式,以下情况都会触发用户级缓冲区刷新:
- 主动强制刷新 :调用
fflush(fp)(刷新指定FILE缓冲区),fflush(NULL)(刷新所有打开的FILE缓冲区) - 文件关闭时 :调用
fclose(fp)--- 关闭前会自动刷新缓冲区为同步的数据(防止数据丢失) - 程序正常退出时 :
main函数返回,调用exit(0)--- C 库会自动刷新所有已打开FILE的缓冲区 - 异常情况 :程序被信号终止(如
SIGINT中断) --- 仅行缓冲/全缓冲的未刷新数据可能丢失(无缓冲不受影响)
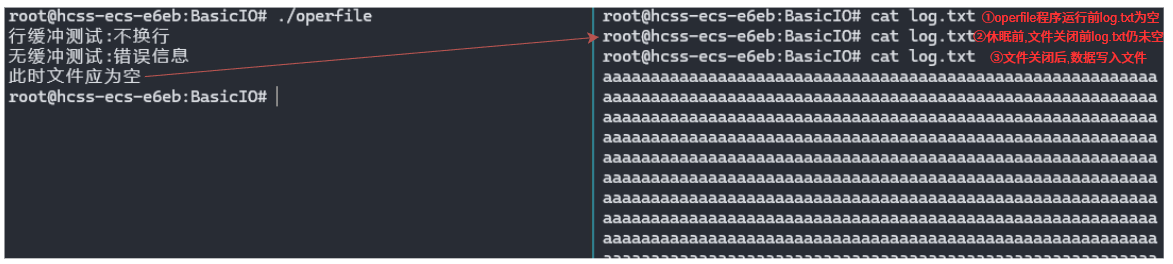
示例:直观感受刷新策略
c
int main()
{
// stdout: 行缓冲,遇\n刷新
printf("行缓冲测试:不换行"); // 未遇\n, 暂存用户级缓冲区不输出
sleep(2); // 休眠期间无输出
printf("\n"); // 遇\n, 刷新用户级缓冲区,终端显示内容
// stderr: 无缓冲,即时输出
fprintf(stderr, "无缓冲测试:错误信息"); // 直接同步到内核,终端显示内容
sleep(2);
// 普通文件: 全缓冲,满了才刷新
FILE* fp = fopen("log.txt", "w");
if (!fp) return 1;
for (int i = 0; i < 4000; i ++)
{
fputc('a', fp); // 4000个'a'不会将缓冲区占满,暂存用户级缓冲区
}
printf("\n此时文件应为空\n");
sleep(2); // 观察文件内容为空
fclose(fp); // 关闭文件,刷新用户级缓冲区,同步到内核级缓冲区,进程结束后会载入磁盘文件
return 0;
}-
stdout是行缓冲,遇到\n才会刷新缓冲区,等待2s后显示器才显示内容.shell# ./operfile 行缓冲测试:不换行 # 等待了2s遇到\n才显示 -
stderr是无缓冲,直接打印到显示器.shell无缓冲测试:错误信息 # 直接显示 -
普通文件是全缓冲,用户级缓冲区为 4 KB,写入了不到 4KB 的数据,用户级缓冲区未满,文件再休眠2s前为空,随后关闭文件触发用户级缓冲区刷新,数据写入文件.
关于缓冲区的三个现象
-
用户级缓冲区内容未刷新到内核级缓冲区,就关闭文件描述符,数据丢失
cint main() { close(1); int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666); // fd 为 1 printf("fd: %d\n", fd); // stdout->1 指向普通文件,普通文件为全缓冲,暂存至用户级缓冲区 close(fd); // 直接关闭文件 return 0; }shell# cat log.txt # 程序运行前文件为空 # ./operfile # cat log.txt # 程序运行后文件仍未空①:
close(1),关闭stdout的文件描述符,fd=1变为"未使用"状态②:
open("log.txt",...):新打开的文件分配fd=1,原本stdout的位置③:
printf(...):该函数默认向stdout输出,此时fd=1为新打开的文件,普通文件的 C 语言用户级缓冲区是全缓冲模式 ,数据会先暂存用户态的缓冲区中(FILE结构体的buf),缓冲区未满,不会立刻调用write写入内核级缓冲区④:
close(fd):系统调用关闭内核中的文件描述符,不会处理 C 语言用户级缓冲区的刷新 ,更不会写入磁盘.⑤:程序退出时,C 库通常会自动刷新所有的
FILE缓冲区,但前提是FILE结构体与fd的关联正常.由于已经close(fd),stdout对应的FILE结构体可能已处于"无效状态",导致程序退出时也未触发刷新.解决方法可以在
printf(...)后手动fflush(stdout),再close(fd),用户级缓冲区会被刷新到内核级缓冲区,剩下的交给操作系统处理.shell# ./operfile # cat log.txt fd: 1 -
库函数
exit刷新用户级缓冲区,而系统调用_exit不会处理用户级缓冲区cint main() { printf("hello"); exit(0); }exit会刷新用户级缓冲区shell# ./operfile helloroot#cint main() { printf("hello"); _exit(0); }_exit则不会c# ./operfile # -
C 语言用户级缓冲区的缓冲模式差异 与
fork()对子进程内存的复制行为cint main() { // C库函数 printf("hello printf\n"); fprintf(stdout, "hello fprintf\n"); const char* s = "hello fputs\n"; fputs(s, stdout); // 系统调用 const char *ss = "hello write\n"; write(1, ss, strlen(ss)); fork(); // 注意,这里创建子进程 return 0; }打印至显示器时,还是正常 4 行打印信息, 但是如果重定向至文件中,则会有 7 行信息
shell# ./operfile hello printf hello fprintf hello fputs hello write # ./operfile > log.txt # cat log.txt hello write hello printf hello fprintf hello fputs hello printf hello fprintf hello fputs分场景解析输出差异
-
直接显示到显示器(4行正常输出)
代码中的 3 个库函数(
printf/fprintf/fputs)的输出都带\n, 且输出目标是显示器(行缓冲):- 父进程执行 C 库函数时 :由于
\n触发行缓冲刷新,"hello printf\n","hello fprintf\n","hello fputs\n"会立即从用户级缓冲区刷新到内核,最终输出到显示器.此时用户级缓冲区已空. - 执行
fork()创建子进程:子进程复制父进程的用户态内存,但此时父进程的 C 库缓冲区已空,所以子进程的用户级缓冲区也是空的. - 父进程和子进程退出 :两者都调用
exit,但由于缓冲区为空,没有额外数据刷新. - 系统调用
write:直接写入内核,不经过用户级缓冲区,只执行一次(在fork()之前)
最终总输出:3 行 C 库函数输出 + 1 行
write输出 = 4 行(父进程执行,子进程无额外输出) - 父进程执行 C 库函数时 :由于
-
重定向到文件(7行输出)
重定向到文件时,
stdout变为全缓冲,\n不再触发刷新, C 库函数的输出会暂存到用户级缓冲区中:- 父进程执行 C 库函数时 :
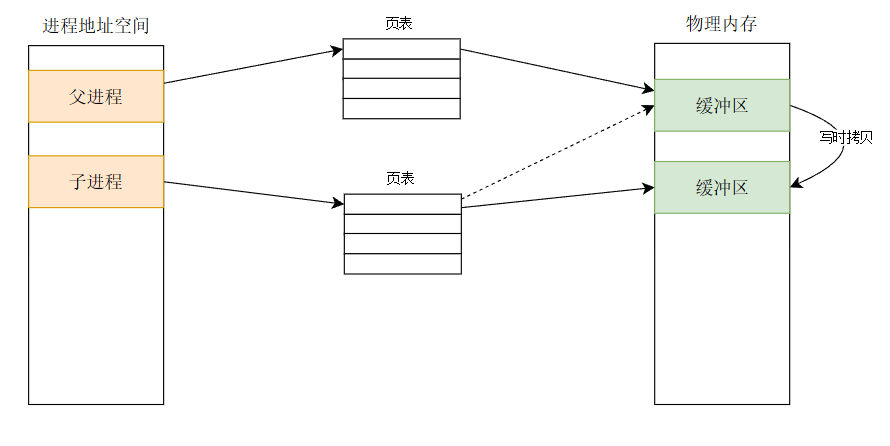
"hello printf\n","hello fprintf\n","hello fputs\n"被存入用户级缓冲区(未刷新,因为全缓冲未慢且未退出) - 执行
fork()创建子进程:子进程完整复制父进程的用户态内存,包括缓冲区中 3 行未刷新的数据,当其中一个退出需要刷新缓冲区触发写时拷贝成为两份(父子各有一份) - 父进程和子进程退出 :两者都调用
exit,触发用户级缓冲区刷新和写时拷贝.父进程和子进程分别对自己的用户级缓冲区进行刷新. - 系统调用
write:在fork()前执行,直接写入内核,只输出一次(fork()不影响已经写入内核的数据)
最终总输出: 3 (父 C 库) + 3 (子 C 库) + 1 (
write) = 7 行
- 父进程执行 C 库函数时 :
-
简单设计一下libc库
-
mystdio.hc#pragma once #include <stdio.h> #define SIZE 1024 #define MODE 0666 typedef struct _myFILE{ int _fd; int _flags; int _flush_mode; char _buffer[SIZE]; int _pos; int _cap; }myFILE; myFILE *myfopen(const char *filename, const char *mode); int myfputs(const char *str, myFILE *fp); void myfflush(myFILE *fp); void myfclose(myFILE *fp); -
mystdio.cc#include "mystdio.h" #include <string.h> #include <stdlib.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <unistd.h> #define NON_BUFFER 1 #define LINE_BUFFER 1<<1 #define FULL_BUFFER 1<<2 #define TRY_FLUSH 1 #define MUST_FLUSH 2 static void myfflushcore(myFILE *fp, int flag) { if (fp->_pos == 0) return; if (fp->_flush_mode == LINE_BUFFER || flag == MUST_FLUSH) { if (fp->_buffer[fp->_pos-1] == '\n' || flag == MUST_FLUSH) { // 写入内核级缓冲区 "12345\n" -- pos=6 write(fp->_fd, fp->_buffer, fp->_pos); fp->_pos = 0; // 清空缓冲区 } } else if (fp->_flush_mode == FULL_BUFFER || flag == MUST_FLUSH) { if (fp->_pos >= SIZE || flag == MUST_FLUSH) { write(fp->_fd, fp->_buffer, fp->_pos); fp->_pos = 0; } } else if (fp->_flush_mode == NON_BUFFER) { write(fp->_fd, fp->_buffer, fp->_pos); fp->_pos = 0; } else { // bug? } } myFILE *myfopen(const char *filename, const char *mode) { int fd = -1; int flags = 0; if(strcmp(mode, "w") == 0) { // 只写 flags = O_WRONLY | O_CREAT | O_TRUNC; fd = open(filename, flags, MODE); } else if (strcmp(mode, "r") == 0) { // 只读 flags = O_RDONLY; fd = open(filename, flags); } else if (strcmp(mode, "a") == 0) { // 追加 flags = O_WRONLY | O_CREAT | O_APPEND; fd = open(filename, flags, MODE); } else { // TODO } if (fd < 0) return NULL; myFILE *fp = (myFILE*)malloc(sizeof(myFILE)); fp->_fd = fd; fp->_flags = flags; fp->_flush_mode = LINE_BUFFER; fp->_pos = 0; fp->_cap = SIZE; } int myfputs(const char *str, myFILE *fp) { if (strlen(str) == 0) return 0; int len = strlen(str); int remain = fp->_cap - fp->_pos; if (len > remain) // 如果缓冲区剩余空间不足 { // 先拷贝剩余空间,刷新缓冲区,再处理剩余部分 memcpy(fp->_buffer+fp->_pos, str, remain); fp->_pos = fp->_cap; myfflushcore(fp, MUST_FLUSH); // 处理剩余字符串 myfputs(str+remain, fp); return len; } // 如果缓冲区剩余空间充足 memcpy(fp->_buffer+fp->_pos, str, strlen(str)); fp->_pos += strlen(str); // 更新pos // 如果条件允许,可以自己刷新 myfflushcore(fp, TRY_FLUSH); return len; } void myfflush(myFILE *fp) { myfflushcore(fp, MUST_FLUSH); } void myfclose(myFILE *fp) { myfflush(fp); // 强制刷新 fsync(fp->_fd); // 强制刷新到磁盘(不是必选) close(fp->_fd); // 关闭文件标识符 free(fp);// 归还空间 }