DataX 本身不直接支持增量导入,但可以通过以下方案实现增量同步:
datax只有一种方案:使用where语句
id name dtime
1 zhangsan 2024-09-05 12:38:56
2 lisi 2024-09-05 08:38:12
想提取这个表中的 9 月 5 号的数据
select * from a where dtime >='2024-09-05 00:00:00' and dtime <='2024-09-05 23:59:59'
还有一种方案:
select * from a where substr(dtime,1,10) ='2024-09-05'
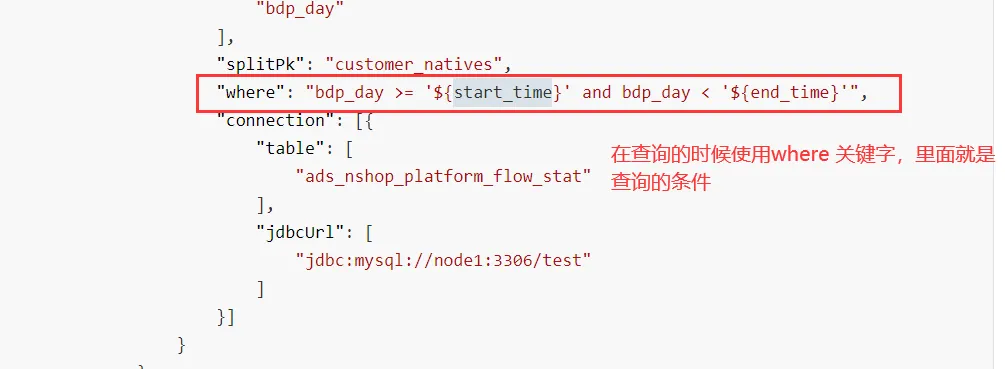
如果json中有变量,需要传递值,在运行的时候,使用-D 传递即可
datax.py job/append.json -p "-Dstart_time=2021-01-01 -Dend_time=2021-01-03"
实现方案
-
基于时间戳的增量同步
在源数据表中添加更新时间字段(如
update_time),每次同步时记录上次同步的最大时间戳:SELECT * FROM table WHERE update_time > '${last_max_time}' -
配置 DataX Job
{ "job": { "content": [{ "reader": { "name": "mysqlreader", "parameter": { "connection": [{ "querySql": "SELECT * FROM table WHERE update_time > '${last_max_time}'" }] } }, "writer": {...} }] } } -
记录同步状态
每次同步后,将本次的最大时间戳存储到外部文件或数据库:
# 示例:记录时间戳到文件 echo "2023-10-01 12:00:00" > last_time.txt
注意事项
- 时区一致性:确保源数据库与应用服务器的时区一致。
- 索引优化:为时间戳字段建立索引以提高查询效率。
- 数据去重 :目标端需处理可能重复的增量数据(如
REPLACE INTO或唯一键约束)。
扩展方案
对于无时间戳的场景,可通过以下方式替代:
-
自增 ID 分段 :
SELECT * FROM table WHERE id > ${last_max_id} -
数据库日志解析:如 MySQL Binlog + Canal 同步增量数据。
通过合理设计同步策略,DataX 可实现高效的增量数据迁移。