一、序 言
在分布式系统中,网络请求的可靠性直接决定了服务质量。想象一下,当你的支付系统因第三方API超时导致订单状态不一致,或因瞬时网络抖动造成用户操作失败,这些问题往往源于HTTP客户端缺乏完善的超时控制和重试策略。Golang标准库虽然提供了基础的HTTP客户端实现,但在高并发、高可用场景下,我们需要更精细化的策略来应对复杂的网络环境。
二、超时控制的风险与必要性
2024年Cloudflare的网络报告显示,78%的服务中断事件与不合理的超时配置直接相关 。当一个HTTP请求因目标服务无响应而长时间阻塞时,不仅会占用宝贵的系统资源,更可能引发级联故障------大量堆积的阻塞请求会耗尽连接池资源,导致新请求无法建立,最终演变为服务雪崩。超时控制本质上是一种资源保护机制,通过设定合理的时间边界,确保单个请求的异常不会扩散到整个系统。
超时配置不当的两大典型风险:
- DoS攻击放大效应:缺乏连接超时限制的客户端,在遭遇恶意慢响应攻击时,会维持大量半开连接,迅速耗尽服务器文件描述符。
- 资源利用率倒挂 :当ReadTimeout设置过长(如默认的0表示无限制),慢请求会长期占用连接池资源。Netflix的性能数据显示,将超时时间从30秒优化到5秒后,连接池利用率提升了400% ,服务吞吐量增长2.3倍。
三、超时参数示例
永远不要依赖默认的http.DefaultClient,其Timeout为0(无超时)。生产环境必须显式配置所有超时参数,形成防御性编程习惯。
以下代码展示如何通过net.Dialer配置连接超时和keep-alive策略:
go
transport := &http.Transport{
DialContext: (&net.Dialer{
Timeout: 3 * time.Second, // TCP连接建立超时
KeepAlive: 30 * time.Second, // 连接保活时间
DualStack: true, // 支持IPv4/IPv6双栈
}).DialContext,
ResponseHeaderTimeout: 5 * time.Second, // 等待响应头超时
MaxIdleConnsPerHost: 100, // 每个主机的最大空闲连接
}
client := &http.Client{
Transport: transport,
Timeout: 10 * time.Second, // 整个请求的超时时间
}四、基于context的超时实现
context.Context为请求超时提供了更灵活的控制机制,特别是在分布式追踪和请求取消场景中。与http.Client的超时参数不同,context超时可以实现请求级别的超时传递,例如在微服务调用链中传递超时剩余时间。
4.1 上下文超时传递
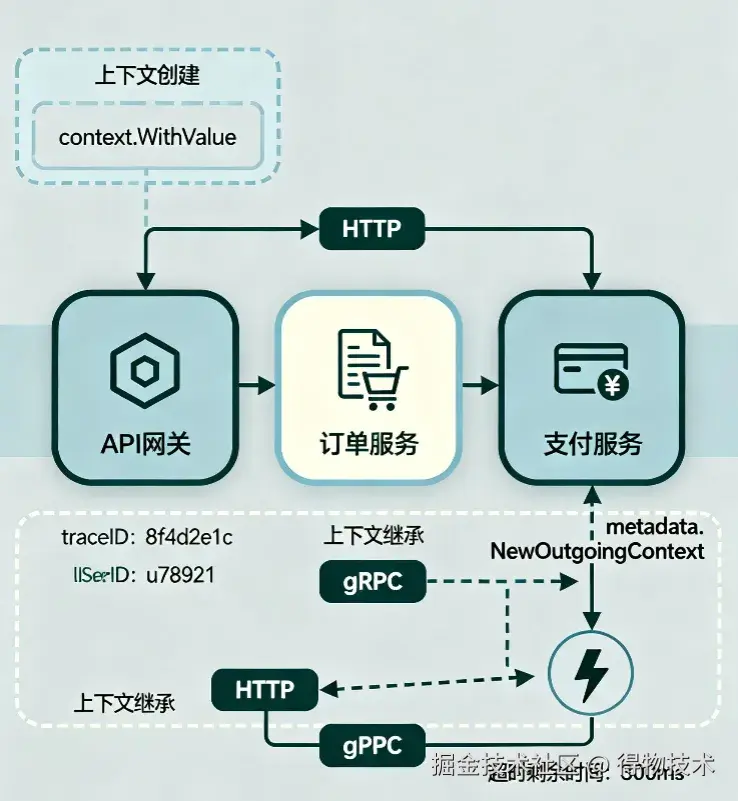
如图所示,context通过WithTimeout或WithDeadline创建超时上下文,在请求过程中逐级传递。当父context被取消时,子context会立即终止请求,避免资源泄漏。
4.2 带追踪的超时控制
go
func requestWithTracing(ctx context.Context) (*http.Response, error) {
// 从父上下文派生5秒超时的子上下文
ctx, cancel := context.WithTimeout(ctx, 5*time.Second)
defer cancel() // 确保无论成功失败都取消上下文
req, err := http.NewRequestWithContext(ctx, "GET", "https://api.example.com/data", nil)
if err != nil {
return nil, fmt.Errorf("创建请求失败: %v", err)
}
// 添加分布式追踪信息
req.Header.Set("X-Request-ID", ctx.Value("request-id").(string))
client := &http.Client{
Transport: &http.Transport{
DialContext: (&net.Dialer{
Timeout: 2 * time.Second,
}).DialContext,
},
// 注意: 此处不设置Timeout,完全由context控制
}
resp, err := client.Do(req)
if err != nil {
// 区分上下文取消和其他错误
if ctx.Err() == context.DeadlineExceeded {
return nil, fmt.Errorf("请求超时: %w", ctx.Err())
}
return nil, fmt.Errorf("请求失败: %v", err)
}
return resp, nil
}关键区别:context.WithTimeout与http.Client.Timeout是叠加关系而非替代关系。当同时设置时,取两者中较小的值。
五、重试策略
网络请求失败不可避免,但盲目重试可能加剧服务负载,甚至引发惊群效应。一个健壮的重试机制需要结合错误类型判断、退避算法和幂等性保证,在可靠性和服务保护间取得平衡。
5.1 指数退避与抖动
指数退避通过逐渐增加重试间隔,避免对故障服务造成二次冲击。Golang实现中需加入随机抖动,防止多个客户端同时重试导致的波峰效应。
以下是简单的重试实现示例:
go
type RetryPolicy struct {
MaxRetries int
InitialBackoff time.Duration
MaxBackoff time.Duration
JitterFactor float64 // 抖动系数,建议0.1-0.5
}
// 带抖动的指数退避
func (rp *RetryPolicy) Backoff(attempt int) time.Duration {
if attempt <= 0 {
return rp.InitialBackoff
}
// 指数增长: InitialBackoff * 2^(attempt-1)
backoff := rp.InitialBackoff * (1 << (attempt - 1))
if backoff > rp.MaxBackoff {
backoff = rp.MaxBackoff
}
// 添加抖动: [backoff*(1-jitter), backoff*(1+jitter)]
jitter := time.Duration(rand.Float64() * float64(backoff) * rp.JitterFactor)
return backoff - jitter + 2*jitter // 均匀分布在抖动范围内
}
// 通用重试执行器
func Retry(ctx context.Context, policy RetryPolicy, fn func() error) error {
var err error
for attempt := 0; attempt <= policy.MaxRetries; attempt++ {
if attempt > 0 {
// 检查上下文是否已取消
select {
case <-ctx.Done():
return fmt.Errorf("重试被取消: %w", ctx.Err())
default:
}
backoff := policy.Backoff(attempt)
timer := time.NewTimer(backoff)
select {
case <-timer.C:
case <-ctx.Done():
timer.Stop()
return fmt.Errorf("重试被取消: %w", ctx.Err())
}
}
err = fn()
if err == nil {
return nil
}
// 判断是否应该重试
if !shouldRetry(err) {
return err
}
}
return fmt.Errorf("达到最大重试次数 %d: %w", policy.MaxRetries, err)
}5.2 错误类型判断
盲目重试所有错误不仅无效,还可能导致数据不一致。shouldRetry函数需要精确区分可重试错误类型:
go
func shouldRetry(err error) bool {
// 网络层面错误
var netErr net.Error
if errors.As(err, &netErr) {
// 超时错误和临时网络错误可重试
return netErr.Timeout() || netErr.Temporary()
}
// HTTP状态码判断
var respErr *url.Error
if errors.As(err, &respErr) {
if resp, ok := respErr.Response.(*http.Response); ok {
switch resp.StatusCode {
case 429, 500, 502, 503, 504:
return true // 限流和服务器错误可重试
case 408:
return true // 请求超时可重试
}
}
}
// 应用层自定义错误
if errors.Is(err, ErrRateLimited) || errors.Is(err, ErrServiceUnavailable) {
return true
}
return false
}行业最佳实践:Netflix的重试策略建议:对5xx错误最多重试3次,对429错误使用Retry-After头指定的间隔,对网络错误使用指数退避(初始100ms,最大5秒)。
六、幂等性保证
重试机制的前提是请求必须是幂等的,否则重试可能导致数据不一致(如重复扣款)。实现幂等性的核心是确保多次相同请求产生相同的副作用,常见方案包括请求ID机制和乐观锁。
6.1 请求ID+Redis实现
基于UUID请求ID和Redis的幂等性检查机制,可确保重复请求仅被处理一次:
go
type IdempotentClient struct {
redisClient *redis.Client
prefix string // Redis键前缀
ttl time.Duration // 幂等键过期时间
}
// 生成唯一请求ID
func (ic *IdempotentClient) NewRequestID() string {
return uuid.New().String()
}
// 执行幂等请求
func (ic *IdempotentClient) Do(req *http.Request, requestID string) (*http.Response, error) {
// 检查请求是否已处理
key := fmt.Sprintf("%s:%s", ic.prefix, requestID)
exists, err := ic.redisClient.Exists(req.Context(), key).Result()
if err != nil {
return nil, fmt.Errorf("幂等检查失败: %v", err)
}
if exists == 1 {
// 返回缓存的响应或标记为重复请求
return nil, fmt.Errorf("请求已处理: %s", requestID)
}
// 使用SET NX确保只有一个请求能通过检查
set, err := ic.redisClient.SetNX(
req.Context(),
key,
"processing",
ic.ttl,
).Result()
if err != nil {
return nil, fmt.Errorf("幂等锁失败: %v", err)
}
if !set {
return nil, fmt.Errorf("并发请求冲突: %s", requestID)
}
// 执行请求
client := &http.Client{/* 配置 */}
resp, err := client.Do(req)
if err != nil {
// 请求失败时删除幂等标记
ic.redisClient.Del(req.Context(), key)
return nil, err
}
// 请求成功,更新幂等标记状态
ic.redisClient.Set(req.Context(), key, "completed", ic.ttl)
return resp, nil
}关键设计:幂等键的TTL应大于最大重试周期+业务处理时间。例如,若最大重试间隔为30秒,处理耗时5秒,建议TTL设置为60秒,避免重试过程中键过期导致的重复处理。
6.2 业务层幂等策略
对于写操作,还需在业务层实现幂等逻辑:
- 更新操作:使用乐观锁(如UPDATE ... WHERE version = ?)
- 创建操作:使用唯一索引(如订单号、外部交易号)
- 删除操作:采用"标记删除"而非物理删除
七、性能优化
高并发场景下,HTTP客户端的性能瓶颈通常不在于网络延迟,而在于连接管理和内存分配。通过合理配置连接池和复用资源,可显著提升吞吐量。
7.1 连接池配置
http.Transport的连接池参数优化对性能影响巨大,以下是经过生产验证的配置:
yaml
func NewOptimizedTransport() *http.Transport {
return &http.Transport{
// 连接池配置
MaxIdleConns: 1000, // 全局最大空闲连接
MaxIdleConnsPerHost: 100, // 每个主机的最大空闲连接
IdleConnTimeout: 90 * time.Second, // 空闲连接超时时间
// TCP配置
DialContext: (&net.Dialer{
Timeout: 2 * time.Second,
KeepAlive: 30 * time.Second,
}).DialContext,
// TLS配置
TLSHandshakeTimeout: 5 * time.Second,
TLSClientConfig: &tls.Config{
InsecureSkipVerify: false,
MinVersion: tls.VersionTLS12,
},
// 其他优化
ExpectContinueTimeout: 1 * time.Second,
DisableCompression: false, // 启用压缩
}
}Uber的性能测试显示,将MaxIdleConnsPerHost从默认的2提升到100后,针对同一API的并发请求延迟从85ms降至12ms,吞吐量提升6倍。
7.2 sync.Pool内存复用
频繁创建http.Request和http.Response会导致大量内存分配和GC压力。使用sync.Pool复用这些对象可减少90%的内存分配:
go
var requestPool = sync.Pool{
New: func() interface{} {
return &http.Request{
Header: make(http.Header),
}
},
}
// 从池获取请求对象
func AcquireRequest() *http.Request {
req := requestPool.Get().(*http.Request)
// 重置必要字段
req.Method = ""
req.URL = nil
req.Body = nil
req.ContentLength = 0
req.Header.Reset()
return req
}
// 释放请求对象到池
func ReleaseRequest(req *http.Request) {
requestPool.Put(req)
}八、总结
HTTP请求看似简单,但它连接着整个系统的"血管"。忽视超时和重试,就像在血管上留了个缺口------平时没事,压力一来就大出血。构建高可靠的网络请求需要在超时控制、重试策略、幂等性保证和性能优化之间取得平衡。
记住,在分布式系统中,超时和重试不是可选功能,而是生存必需。
扩展资源:
- Golang官方HTTP客户端文档(pkg.go.dev/net/http)
- Netflix Hystrix超时设计模式(github.com/Netflix/Hys...
往期回顾
-
RN与hawk碰撞的火花之C++异常捕获|得物技术
-
得物TiDB升级实践
-
得物管理类目配置线上化:从业务痛点到技术实现
-
大模型如何革新搜索相关性?智能升级让搜索更"懂你"|得物技术
-
RAG---Chunking策略实战|得物技术
文 /梧
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。