AI时代,不知道你是否和我有同样的经历:搜索了大量号称"小白也能看懂"的AI科普文章,结果点进去,仍有90%的内容让人一头雾水。
这篇文章,是我在阅读众多资料后,整理出的一份更易懂的总结。它不强求全面,但力求逻辑清晰、层层递进------从基础概念逐步引出更复杂的内容,而不是一上来就抛出"神经网络""深度学习"或"ChatGPT预测模型"这样的术语。
我相信,只要你具备初中知识水平,就能轻松理解。让我们开始吧!
一、人工智能的起源
1956年,一群科学家在达特茅斯会议上首次提出"人工智能"这一概念。他们讨论的核心问题是:如何制造出能够学习并模拟人类智能的机器。
从此,人工智能作为一个独立的研究领域正式诞生。
但问题在于,机器处理信息的方式与人类截然不同。机器接收的所有数据最终都会转化为数字(包括文字)。
简单解释为什么文字在计算机内部也是数字表示的,就涉及到编码的知识,例如 ASCII 编码,字母 a 在计算机内部表示 97。而 97 最终会被解释而 2 进制,因为计算机本身就是 2 进制的。它只能认识 0 和 1。然后我们将数字和文字做个映射,例如
01100001表示字母 a ,而01100001的 10 进制就是 97.
我们抽象一下计算机的思考方式,简单来说就是:
f(x)=y
-
我们向计算机输入参数 x
-
计算机将参数转为数字(这就是为什么很多文章说什么向量这个概念,向量可以简单理解为数字组成的多维数组,也就是说例如 "苹果" 这个词,最终要转化为数字,计算机才能理解),然后通过函数 f 处理并计算
-
最终输出结果 y
但这显然不是人类思考问题的方式。那么,如何让机器具备类似人类的判断与学习能力,成为真正的"智能机器"呢?
科学家们提出了不同的思路。
二、符号主义:用规则模拟智能
在人工智能的早期阶段,符号主义(Symbolism)是一种主流思路。它认为,可以通过数学逻辑来模拟人类的推理过程。
举个例子,我们设计一个判断是否下雨的机器:
-
参数 aa:是否为阴天
-
参数 bb:湿度是否大于70%
只有当 a 和 b 同时为"真"时,机器才输出"要下雨",否则输出"不下雨"。
这种思路本质上就是编程中的 if...else... 逻辑。
别小看符号主义,它的成功应用之一就是"专家系统"。比如在医疗诊断中:
-
从 头疼 + 发热 + 咳嗽 的症状 → 能推测出得了流感
-
从 腹痛 + 尿血 → 能推测出得了 肾结石
通过一系列规则组合,专家系统能够模拟人类专家的决策过程,并在特定领域取得了显著成果。
但它也有明显的局限:
-
规则难以统一:比如面对同一张股票走势图,不同专家可能做出完全相反的判断。
-
无法自主学习:系统本身不具备学习能力,依赖人工更新规则。
随着研究的深入,另一种思路逐渐兴起:与其预设所有规则,不如让机器自己从数据中学习。这就是"联结主义"(Connectionism)。
三、联结主义:让机器自己学习
这种模式有点像训狗,你说坐下,它坐下你就奖励零食,如果错了,就跟它一飞腿,这样你就能训练出一个会听坐下指令的狗了。
我们把狗换成机器,也可以用同样的方式训练,让它在某个任务下完成任务。例如说现在要训练一个能识别苹果图片的智能。
举例:识别苹果
那么机器肯定要识别苹果的特征,才能区别别的图片,假设我们设置了如下维度
-
直径: 苹果直径大约10cm
-
颜色: 苹果是红色
-
形状: 苹果是球形
例如在某些条件下,直径,颜色,形状都符合苹果特性的条件下,才是苹果,但是我们之前说了,计算机只认识数字,只能通过计算来判断,所以我们需要结合一些数学公式来把 直径,颜色,形状,映射为数字,通过数字的计算映射它们在现实生活的是否对应。
既然文字也可以通过数字映射,例如 97 代表数字 a,那么其它属性也可以,例如(我乱说的,就是表达一种意思),我们把形状,颜色,和直径,都理解为权重。什么意思呢?我们举个例子:
假设我们给每个特征分配一个权重(weight),代表这个特征对"是否是苹果"的重要程度:
-
直径:苹果直径约 10cm 权重 = +0.6(越接近 10cm 越可能是苹果)
-
颜色:红色程度(0 不是红,1 是红) 权重 = +0.3(红色对判断有贡献)
-
形状:球形程度(0 不是球形,1 是球形) 权重 = +0.4(球形对判断有贡献)
然后,我们设计一个简单的"苹果得分"公式:
苹果得分=(直径得分)×0.6+(颜色得分)×0.3+(形状得分)×0.4
然后得出来的值,如果大于 1 就是苹果,如果小于 1 就不是苹果。
计算例子
例1:一个红苹果(直径 10cm,红色,球形)
- 直径得分 = 1
- 颜色得分 = 1
- 形状得分 = 1
苹果得分 = 1×0.6+1×0.3+1×0.4=1.3
例2:一个橙子(直径 8cm,橙色,球形)
- 直径得分 = 0.8(假设 8cm 离 10cm 差 2cm,得分 0.8)
- 颜色得分 = 0(不是红色)
- 形状得分 = 1
苹果得分 = 0.8×0.6+0×0.3+1×0.4=0.48+0.4=0.88
大家应该明白上面的意思了吧。我们再次抽象为数学公式,也就是变为 1 次函数。将得分用 x 表示,将权重用 w 表示,如下:
z = (w 1 × x 1) + (w 2 × x 2) + (w 3 × x 3) + b
其中:
-
w1,w2,w3 是各特征的权重(重要性)
-
b 是偏置项(可理解为判断门槛)
所以
-
如果 z≥0,判定为苹果
-
如果 z<0,判定为非苹果
因为有 w1,w2,w3 3个参数,不利于我们后面的讲解,我们再次简化公式,来帮助我们理解后面的概念。
z = (w 1 × x 1) + (w 2 × x 2) + b
变为只有两个参数来决定是否是苹果,其实这是这是初中数学中的 线性方程,它的图像是一条直线。如下:
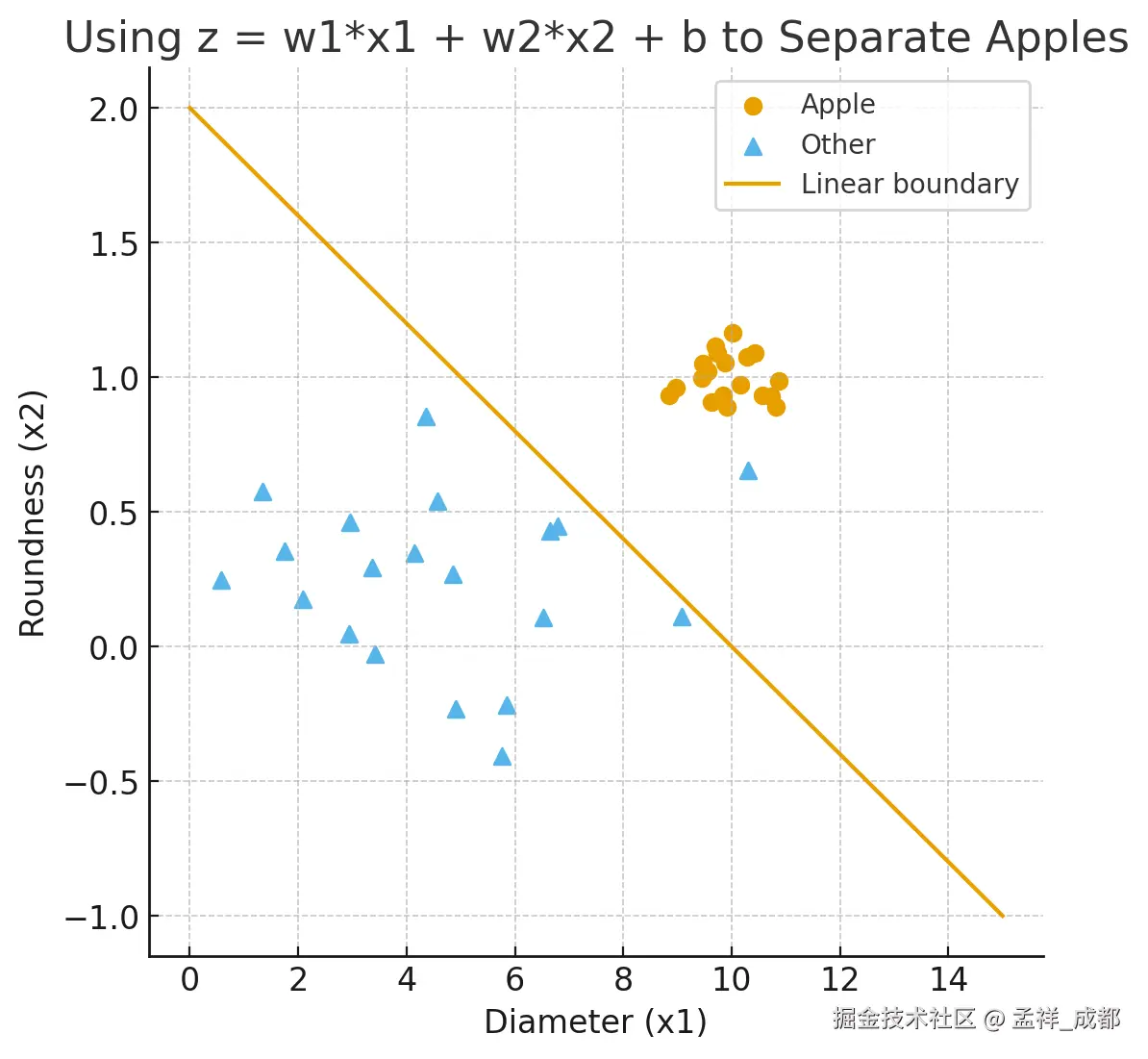
这条直线下方的就是就是非苹果,上方的就是苹果。
接下来有人会问,你说形状,直径这些特征的值,是怎么来的呢?
它们当然不是天然存在的,而是需要我们人为设计和提取的。这个过程在传统机器学习中被称为 "特征工程"。我们又要举一个粗糙的例子了,我们拿颜色得分来举例:
-
思路: 苹果通常是红色、绿色或黄色。我们需要量化"红色程度"。
-
设计方法:
-
如果是从图片中提取: 计算机可以分析图片的所有像素点。
- 将图片从RGB颜色空间转换到 HSV 颜色空间(H代表色调,能更好地表示颜色本身)。
- 统计所有像素中,色调(H)在红色范围内(比如0-10度和350-360度)的像素比例。比例越高,
x2越接近1。
-
如果是从文字描述提取: 如果我们的数据是文字"深红色",我们可以建立一个颜色词典:
-
"深红色" ->
x2 = 0.9 -
"浅红色" ->
x2 = 0.7 -
"绿色" ->
x2 = 0.3(因为青苹果也存在) -
"蓝色" ->
x2 = 0
-
-
好了,特征得分我们解决了,然后就是训练,调整 w1 和 w2 参数,从而找出一个分界线,在分界线范围内的就是苹果,范围外的就是其它。当然这个分界线不一定是直线,也可以是很复杂的曲线范围,我们只是为了引出核心概念,就是:
"机器学习"!
虽然没有直接说出"机器学习"四个字,但已经完整地描绘了它的核心思想:通过数据(苹果的特征)和反馈(得分是否大于阈值),让机器自动调整内部参数(权重 w 和偏置 b),从而学会一项任务(识别苹果)。
我们接着聊,刚才我们举得例子非常粗糙,但可以很容易的理解大概的意思。
上面这种机器学习的思路,称为联结主义,可这种思路在最初曾一度被整个世界称为骗子思路!
为什么是骗子?
刚才我们举了一个非常简单的例子,让机器根据 直径、颜色 来判断是不是苹果。
我们最终把它抽象成一个数学公式:
z = (w 1 × x 1) + (w 2 × x 2) + b
本质上,它就是一个一次函数(二维下是一条直线,三维下是一张平面)。
在很多任务中,这种模型真的能工作。
比如"苹果 vs 不是苹果",
如果苹果的数据大多集中在同一块区域,那么一条直线(或平面)确实能把它们区分开来。
如果有一个任务,根本无法用一条直线分开呢?
科学家们很快就发现:
并不是所有问题都像识别苹果一样简单。
其中最典型的例子就是 异或 ( XOR )问题。
先看什么是异或:
| 输入 A | 输入 B | 输出 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
也就是输入是一样的情况,例如都是 0 或者都是 1 ,得到的结果是 0,否则得到的结果是 1。
如下图,我们是无法找到一条直线,分割红色点和蓝色点的
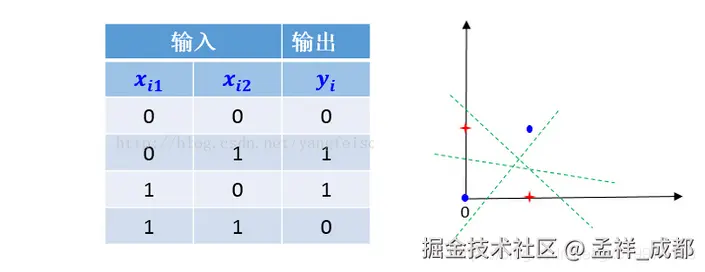
这就意味着,简单的线性模型,有些情况是无法模拟的!
也就是说 ❌ 再怎么调整 w1、w2、b,这个模型也永远无法学会异或。
这导致了人工智能历史上第一次寒冬(AI Winter)。
四、突破:引入非线性!------ 神经网络的诞生
后来科学家们发现:
如果在两个线性模型中间,再加上一层"非线性函数",就能解开异或。
你可以把思想理解成:
-
一条直线不能分的
-
两条直线可以
-
让模型像搭积木一样把"多条直线"组合起来 → 就能拼出复杂的边界
什么意思呢,我们可以简单用下入理解:
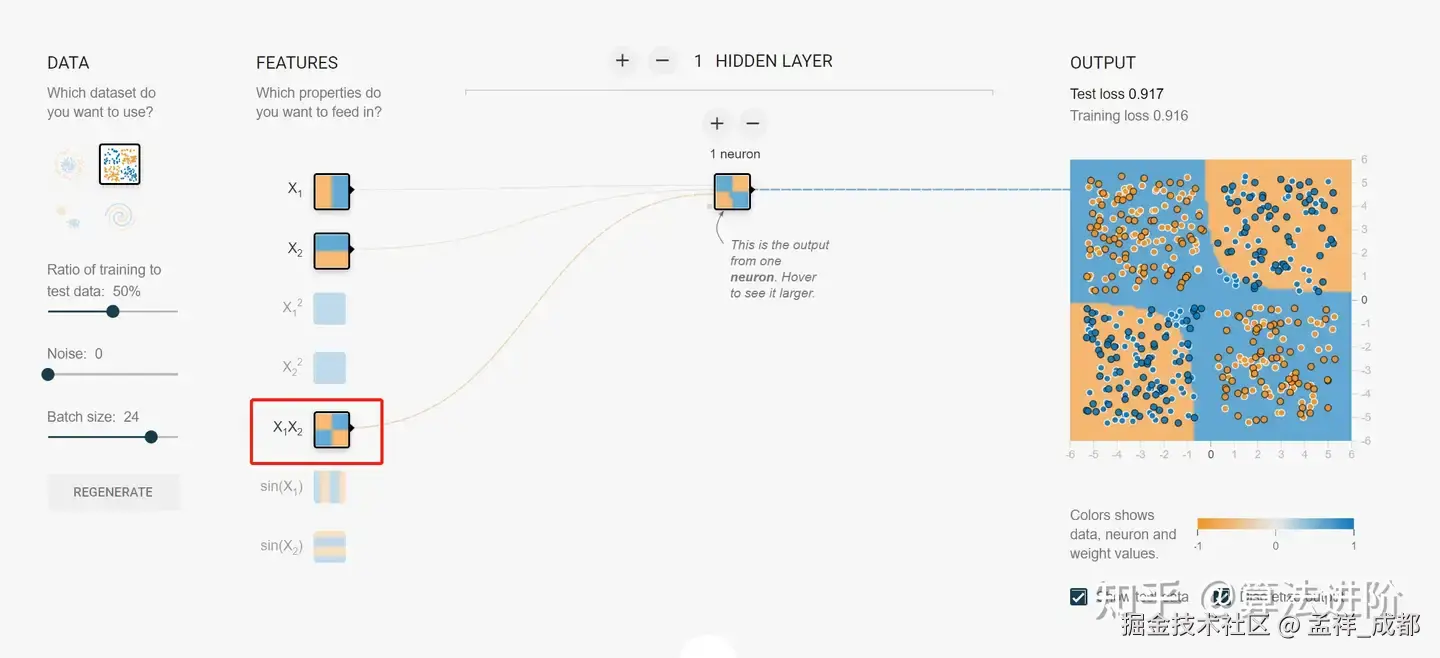
如上图右边,是不是边界变成了不是一条直线,而是两个曲线去分割呢,借助这这种思路就解决了异或问题。
这就是**神经网络(Neural Network)**最核心的思想:
多个简单模型叠在一起,中间加上激活函数(非线性), 就能表达更复杂的决策边界。
我们从开始的线性模型,也就是单层结构是:
输入 → 权重加权 → 激活函数 → 输出
简单来说就是输入 x1, x2 的得分 ---> 跟 w1,w2 权重计算 -> 跟阈值对比,例如大于 1 就是苹果 -> 输出是否是苹果
然后再看看新的多层结构:
输入 → [权重加权 + 激活函数] → [权重加权 + 激活函数] → 输出
好了至此,我们就明白了神经网络的概念,神经网络也是联结主义的一部分。此时再次解释以下联结主义的主张:
"智能来自大量简单单元(神经元)的连接和学习,而不是手写规则。"
我们再来一个小小结,就是从符号主义,这种依靠人自身写规则到联结主义,到神经网络,我们逐渐步入了新的人工智能时代。
五、从神经网络到深度学习:当网络变得"深不可测"
好了,现在我们明白了神经网络------它通过多层连接,巧妙地解决了简单模型无法处理的复杂问题(如异或问题)。那么,深度学习又是什么呢?
其实答案出乎意料的简单:
深度学习 = 特别"深"的神经网络。
这里的"深",指的不是哲学的深邃,而是字面意思上的层数非常多。
我们可以做一个直观的对比:
-
传统的神经网络:可能只有几层(比如一个输入层、一个隐藏层、一个输出层)。就像一个简单的三明治。
-
深度学习模型:则拥有十几层、上百层甚至上千层。这就像一个巨无霸汉堡,拥有无数层馅料和面包。
为什么层数多了就厉害?
还记得我们之前手动设计"特征"的麻烦吗?(比如要自己写规则计算"颜色得分"、"形状得分")深度学习的强大之处在于,它能够自动完成这件事,而且做得比我们好得多。
我们拿一个识别狗的例子举例:
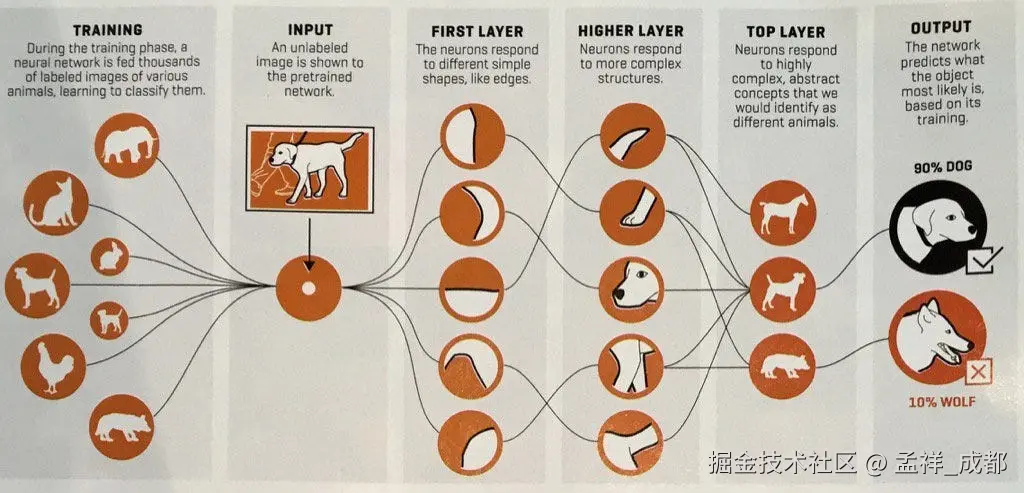
我们可以把一个深度网络理解成一个分工极其精细的流水线工厂,用来识别一张"狗"的图片:
- 第一层(最基础的工人):只负责检测图像中最简单的边缘和色块。比如这里是横线,那里是竖线,那片是黑色。
- 中间几层(初级组装工):接收下一层的"边缘和色块",把它们组合成更复杂的局部特征。比如,"两个圆圈"可能是眼睛,"一个三角形"可能是耳朵。
- 最后层(最终决策者):基于前面所有层传递过来的、已经高度抽象化的信息(比如"这是一个有胡须、尖耳朵、竖瞳的动物面部"),最终做出判断:"这是狗。"
这个过程,就是一个"逐层抽象,不断精炼"的过程。 每一层都在前一层的基础上,学习并提取更复杂、更核心的特征。网络越深,能学到的特征就越抽象,解决问题的能力也就越强。
到此我相信大部分应该明白了几个很基础的概念,就是机器学习,神经网络,深度学习的概念。我是一名前端开发技术专家,目前除了开始接触 ai 部分的知识,前端部分正在写关于 headless 组件库教程 这是网站首页,欢迎大家给个赞哦,感谢!同时也在写酷炫的动画教程,有兴趣的同学可以看这篇文章
下一章我将简单介绍一下 chatgpt 的基本原理,也是面相纯小白,也绝对包票你能看懂。