目录
[1. 聚合函数](#1. 聚合函数)
[&& 示例的数据准备](#&& 示例的数据准备)
[1.1 count函数](#1.1 count函数)
[1.2 sum函数](#1.2 sum函数)
[1.3 avg函数](#1.3 avg函数)
[1.4 max函数](#1.4 max函数)
[1.5 min函数](#1.5 min函数)
[2. group by 分组查询](#2. group by 分组查询)
[2.1 语法](#2.1 语法)
[2.2 示例的数据准备](#2.2 示例的数据准备)
[2.3 示例](#2.3 示例)
[3. having 分组结果筛选](#3. having 分组结果筛选)
[3.1 语法](#3.1 语法)
[3.2 示例](#3.2 示例)
[3.3 having与where的区别](#3.3 having与where的区别)
[3.4 严格模式下的隐式分组](#3.4 严格模式下的隐式分组)
[4. 内置函数](#4. 内置函数)
[4.1 日期函数](#4.1 日期函数)
[4.2 字符串处理函数](#4.2 字符串处理函数)
[4.3 数学函数](#4.3 数学函数)
[4.4 其他常用函数](#4.4 其他常用函数)
[5. 所有查询子句的执行时机问题](#5. 所有查询子句的执行时机问题)
[5.1 各子句的执行顺序](#5.1 各子句的执行顺序)
[5.2 哪些子句可以起别名](#5.2 哪些子句可以起别名)
[5.3 不同执行顺序的子句如何引用别名](#5.3 不同执行顺序的子句如何引用别名)
1. 聚合函数
&& 示例的数据准备
用于展示的示例表
drop table if exists exam;
CREATE TABLE exam (
id BIGINT primary key,
name VARCHAR(20) COMMENT '同学姓名',
chinese float COMMENT '语文成绩',
math float COMMENT '数学成绩',
english float COMMENT '英语成绩'
);
插入测试数据
INSERT INTO exam (id, name, chinese, math, english) VALUES
(1, '唐三藏', 67, 98, 56),
(2, '孙悟空', 87, 78, 77),
(3, '猪悟能', 88, 98, 90),
(4, '曹孟德', 82, 84, 67),
(5, '刘玄德', 55, 85, 45),
(6, '孙权', 70, 73, 78),
(7, '宋公明', 75, 65, 30),
(8, '张飞', 54, 128, NULL);
1.1 count函数
格式:count(distinct expr)
- 作用:返回查询到的数据的数量。
- expr包括列和表达式,函数在统计时会自动过滤掉 expr 中值为null的数据。
- 加上distinct关键字后,会对 expr 去重后再统计。
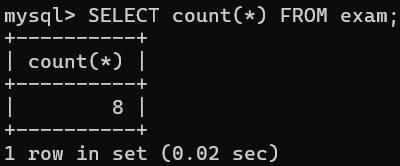
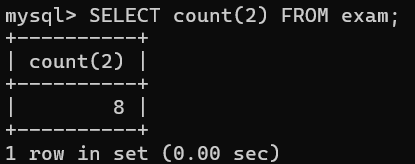
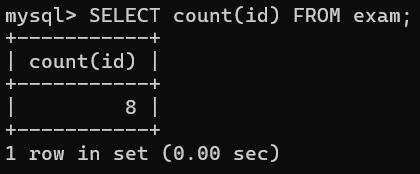
-- 1.查看exam表中的总记录数
对于查看某个表的总记录数,我们有3种传参方式。
- 传入通配符 * :这是SQL语言级别的标准,任何数据库软件都通用,比较推荐。
- 传入常量(常量表达式)
- 传入主键
下面是对以上3种方式的执行结果:
-- 2.统计有多少学生参加英语考试(自动排除null值)
sql
SELECT count(english) FROM exam; # 排除了张三的null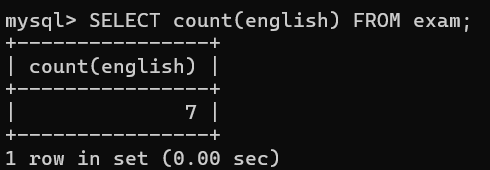
-- 3.统计英语成绩少于50分的学生个数
sql
SELECT count(*) FROM exam WHERE english < 50;
SELECT * FROM exam WHERE english < 50; # null值在排序时比任何值都小,但是在where条件中null也会被过滤掉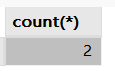
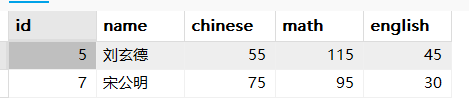
1.2 sum函数
格式**:sum(distinct expr)**
- 作用:计算数值列的总和。
- expr 包括列和表达式,该方法仅对数值类型的expr有效,对其他类型(如字符串类型、日期类型)使用该函数会报错。
- 计算总和时会自动过滤 null 值。
- 加上distinct关键字后,会对 expr 去重后再求合。(很少用)
-- 1.统计所有学生的数学总成绩和英语总成绩【自动过滤null值】
sql
SELECT SUM(math) AS '数学总分', SUM(english) AS '英语总分' FROM exam;
-- 2.对非数值类型无法使用
sql
SELECT SUM(`name`) FROM exam; # 发出警告
SHOW WARNINGS;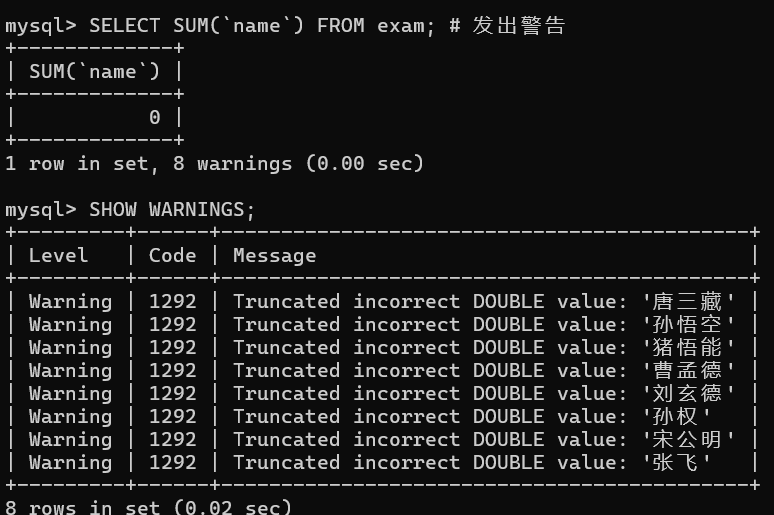
1.3 avg函数
格式**:avg(distinct expr)**
- 作用:计算数值列的平均值。
- expr 包括列和表达式,该方法仅对数值类型的expr有效,对其他类型(如字符串类型、日期类型)使用该函数会报错。
- 计算时会自动过滤 null ,把null值排除的同时**(分子)** ,也过滤了含null值的行**(分母)**。
- 加上distinct关键字后,会对 expr 去重后再求平均值。(很少用)
-- 1.统计英语成绩的平均分
sql
SELECT AVG(english), SUM(english), COUNT(english) FROM exam;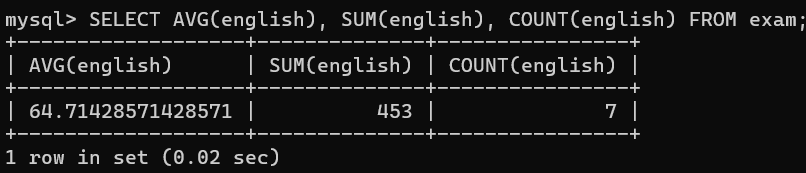
可以看到,张三的整行数据被过滤掉了。
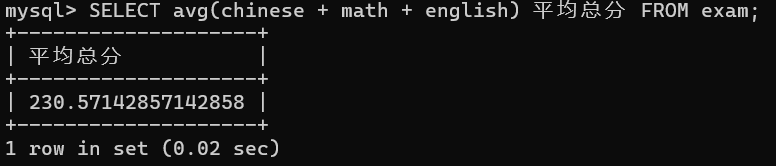
-- 2.统计平均总分
sql
SELECT avg(chinese + math + english) 平均总分 FROM exam; 张飞的所有数据都没算上【任何值加上null都等于null】
1.4 max函数
格式**:max(distinct expr)**
- 作用:找出列中的最大值。
- expr 包括列和表达式,该方法仅对数值类型的expr有效,对其他类型(如字符串类型、日期类型)使用该函数会报错。
- 查找最大值时会自动过滤 null 。
- 加上distinct关键字后,会对 expr 去重后再找最大值。(没必要, 最大值本身具有唯一性)
-- 1.查询英语最高分
sql
SELECT MAX(english) FROM exam;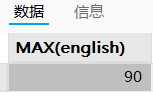
1.5 min函数
格式**:max(distinct expr)**
- 作用:找出列中的最小值。
- expr 包括列和表达式,该方法仅对数值类型的expr有效,对其他类型(如字符串类型、日期类型)使用该函数会报错。
- 查找最小值时会自动过滤 null 。
- 加上distinct关键字后,会对 expr 去重后找最小值。(没必要, 最小值本身具有唯一性)
-- 1.查询>70分以上的数学最低分
sql
SELECT MIN(math) FROM exam WHERE math > 70;
-- 2.查询数据成绩的最高分与英语成绩的最低分
sql
SELECT max(math), min(english) FROM exam;
2. group by 分组查询
GROUP BY 的主要作用是将数据按照指定的列或表达式进行分组 ,然后对每个组应用聚合函数进行统计计算。
2.1 语法
SELECT 查询列表 FROM 表名 WHERE子句 GROUP BY { 列 | 表达式 }, ...;
在分组查询中,select子句受到group by子句的限制,查询列表中只能包括:
GROUP BY 中使用的列
聚合函数
常量(常量表达式)
2.2 示例的数据准备
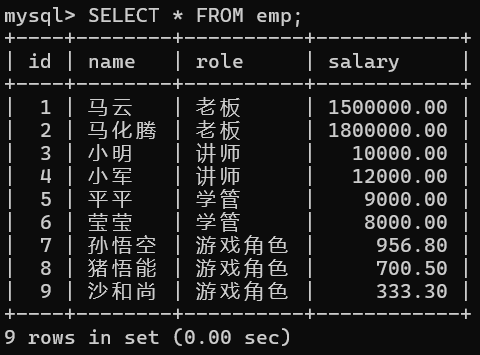
准备测试表及数据职员表emp,列分别为:id(编号),name(姓名),role(角色),salary(薪水)
drop table if exists emp;
create table emp (
id bigint primary key auto_increment,
name varchar(20) not null,
role varchar(20) not null,
salary decimal(10, 2) not null
);
INSERT INTO emp VALUES(1, '马云', '老板', 1500000.00);
INSERT INTO emp VALUES(2, '马化腾', '老板', 1800000.00);
INSERT INTO emp VALUES(3, '小明', '讲师', 10000.00);
INSERT INTO emp VALUES(4, '小军', '讲师', 12000.00);
INSERT INTO emp VALUES(5, '平平', '学管', 9000.00);
INSERT INTO emp VALUES(6, '莹莹', '学管', 8000.00);
INSERT INTO emp VALUES(7, '孙悟空', '游戏角色', 956.8);
INSERT INTO emp VALUES(8, '猪悟能', '游戏角色', 700.5);
INSERT INTO emp VALUES(9, '沙和尚', '游戏角色', 333.3);
SELECT * FROM emp;
2.3 示例
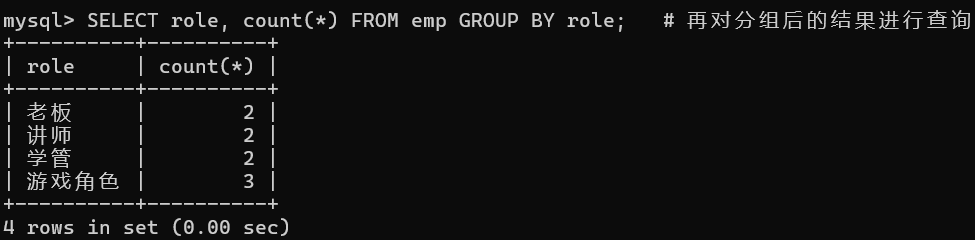
-- 1. 统计每个角色的人数
sql
SELECT role FROM emp GROUP BY role; # 先分组
SELECT role, count(*) FROM emp GROUP BY role; # 再对分组后的结果进行查询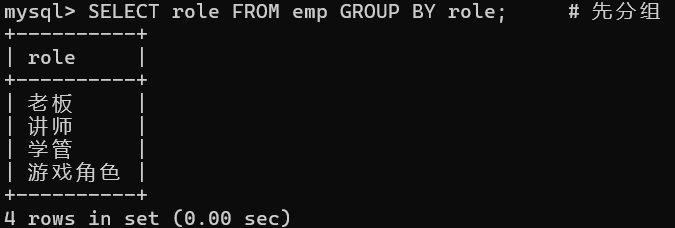
-- 2. 统计每个角色的平均工资,最高工资,最低工资
sql
SELECT role, avg(salary), max(salary), min(salary) FROM emp GROUP BY role;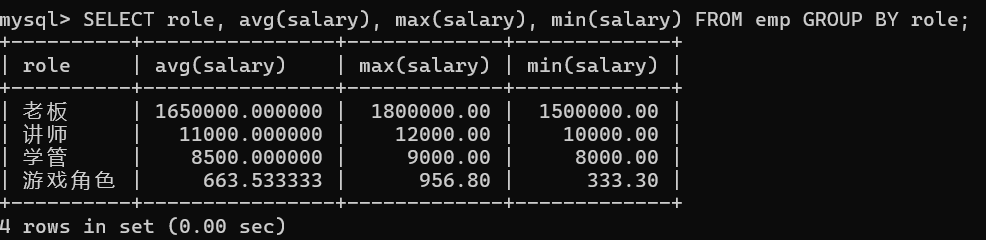
3. having 分组结果筛选
使用having子句可以对分组后的虚拟表进行筛选。
3.1 语法
SELECT 查询列表 FROM 表名 WHERE 行级过滤条件 GROUP BY子句 HAVING 组级过滤条件;
组级过滤条件的使用也是有要求的,其允许的条件类型:
- 聚合函数
- 用于group by分组的列
3.2 示例
tips:以下示例的数据准备用的是2.2的数据
-- 1. 显示平均工资低于1500的角色和它的平均工资
sql
# 先根据角色进行分组
SELECT role, avg(salary) FROM emp GROUP BY role;
# 再对分组结果使用聚合函数进行条件过滤
SELECT role, avg(salary) FROM emp GROUP BY role HAVING avg(salary) < 1500; 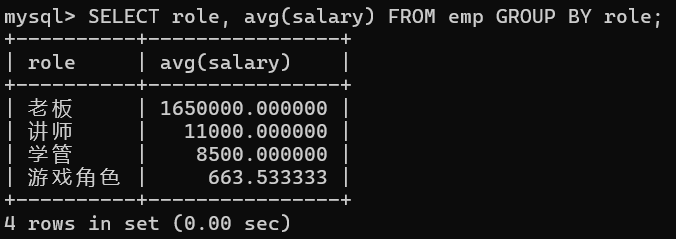

3.3 having与where的区别
|----------|------------|-------------|
| 特性 | WHERE | HAVING |
| 执行时机 | 在分组前执行 | 在分组后执行 |
| 作用对象 | 原始数据行 | 分组后的结果集 |
| 聚合函数 | 不能使用 | 可以直接使用 |
反例:where子句中不能使用聚合函数
SELECT name, salary FROM emp where avg(salary) < 1500;

3.4 严格模式下的隐式分组
sql
-- 查看当前 SQL 模式
SELECT @@sql_mode;
默认的SQL模式下都会使用 ONLY_FULL_GROUP_BY 模式,也就是严格分组模式。在该模式下的group by分组,其select查询列表只能包含group by子句中的列、聚合函数 和 常量。
如果使用的是非严格模式,那么select查询列表中可以使用不用于分组的列,但是这种列的结果是随机选值来填充。
在严格模式下,如果在没有使用group by子句情况下使用了 聚合函数 或 having子句,那么会触发触发隐式分组。
在严格模式触发隐式分组后,使用的查询列表(select)会有以下限制:
- 使用聚合函数时的隐式分组:
- 如果不是在having中使用聚合函数,而是仅在select中使用聚合函数,那么此时查询列表中只能包含该聚合函数和常量表达式。【常用】
- 使用 HAVING 子句时的隐式分组:
- select 查询列表中只能使用 having 子句中用于条件过滤的列。(如果select中存在having中没有的列,那么mysql会无法识别该列;当双方都存在同一个列时,mysql才会识别出来)【很少用,完全可以用where子句代替】
显式分组时明确指定了哪些是分组列,select不能使用非分组列。而隐式分组时虽然没有指定分组列,这不代表着select不能使用任何列,而是select中出现的列也必须在having中出现。
-- 1. 使用聚合函数时的隐式分组
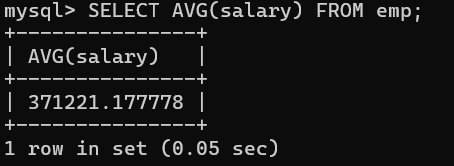
SELECT AVG(salary) FROM emp;
-- ✅ 允许:只有聚合函数
【其实这里能验证隐式分组是无条件分组,而不是分组列是所有列,否则(emp表)有多少行数据就会有多少组,而现在打印出来的只有一组,所以隐式分组是把整个表看成是一组】
SELECT name, AVG(salary) FROM emp;
-- ❌ 错误:name 是非聚合列,在隐式分组中无法确定显示哪个值
-- 2. 使用 HAVING 子句时的隐式分组
SELECT name FROM emp HAVING id > 0;
-- ❌ 错误:name 是非聚合列,在隐式分组中无法确定显示哪个值
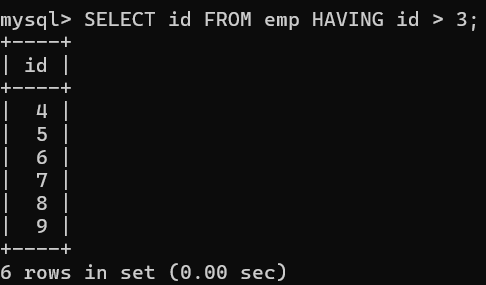
SELECT id FROM emp HAVING id > 3;
-- ✅ 允许:SELECT 和 HAVING 使用同一列,MySQL 可以确定值
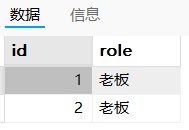
SELECT id, role FROM emp having id > 0 and role = '老板';
-- ✅ 允许:在 SELECT 和 HAVING 使用过 id列 和 role列,MySQL 可以确定值
4. 内置函数
在默认字符编码集和默认的排序规则下,函数名也是不区分大小写的。对于函数结果的打印都使用select子句。
4.1 日期函数
|---------------------------------------|-------------------------------------------------------------------------|
| 函数 | 说明 |
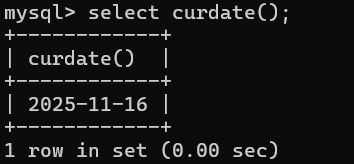
| CURDATE() | 返回当前日期,格式**"年-月-日"。 有同义词:current_date、current_date() |
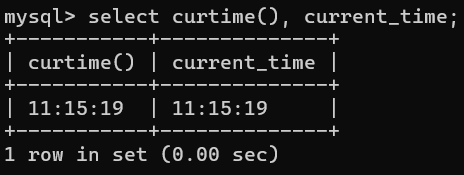
| CURTIME() | 返回当前时间,格式"时:分:秒"。 同义词 CURRENT_TIME , CURRENT_TIME(fsp) |
| NOW() | 返回当前⽇期和时间,格式"年-月-日 时:分:秒"。 同义语 CURRENT_TIMESTAMP ,CURRENT_TIMESTAMP |
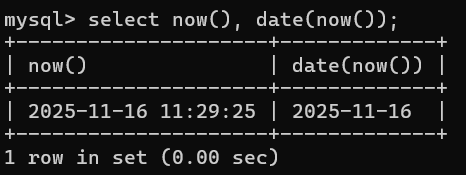
| DATE( datetime ) | 提取date或datetime表达式的日期部分**,没有则返回null |
| ADDDATE(date, INTERVAL expr unit) | 向⽇期值添加时间值(间隔),同义词 DATE_ADD() |
| SUBDATE(date, INTERVAL expr unit) | 向⽇期值减去时间值(间隔),同义词 DATE_SUB() |
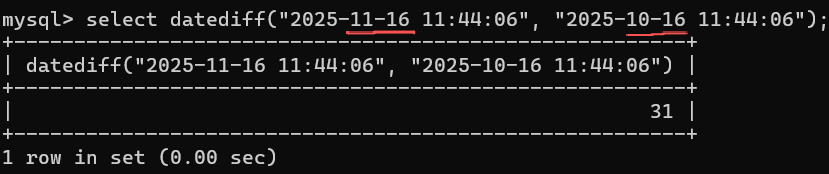
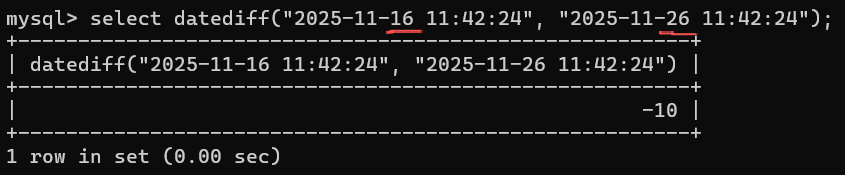
| DATEDIFF(expr1,expr2) | 两个⽇期的差,以天为单位,expr1-expr2。仅计算日期部分,时间部分完全忽略 |
-- 1.返回当前日期
-- 2.返回当前时间
-- 3.返回当前日期和时间
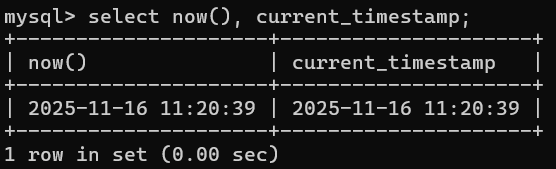
-- 4.提取时间类型的值的日期部分

-- 5.添加时间和减去时间
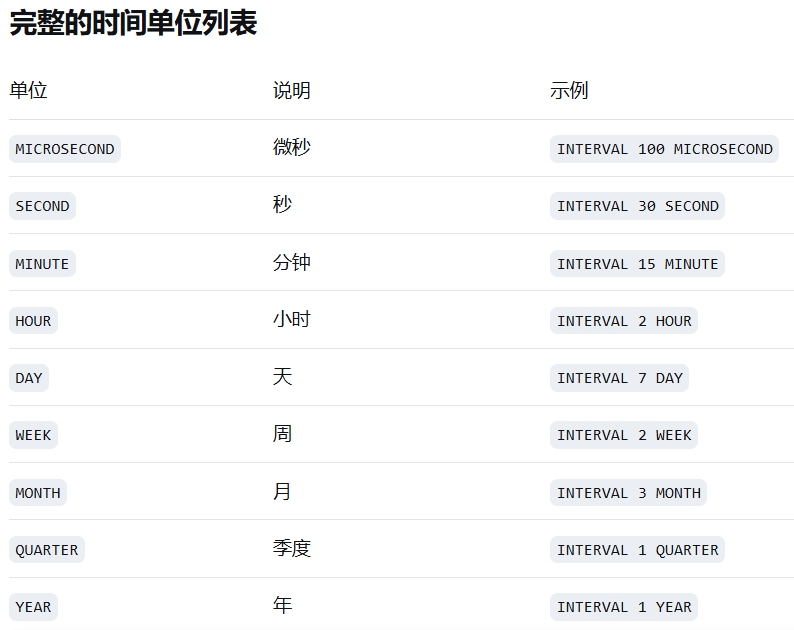
interval是时间间隔关键字,也是时间间隔表达式的开头。
语法:INTERVAL 数值 时间单位
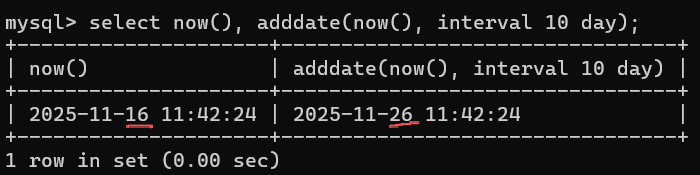
例1:在当前时间上加上10天
例2:在当前时间上减去5个月
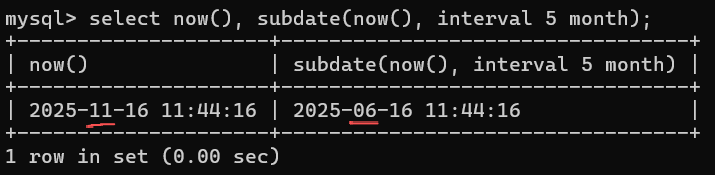
-- 6.两个日期的差
4.2 字符串处理函数
| 分类 | 函数名 | 语法 | 功能描述 | 示例 |
|---|---|---|---|---|
| 连接函数 | CONCAT | CONCAT(str1, str2, ...) |
连接多个字符串 | CONCAT('My', 'SQL') → 'MySQL' |
| CONCAT_WS | CONCAT_WS(sep, str1, str2, ...) |
使用分隔符连接字符串 | CONCAT_WS(',', 'A', 'B') → 'A,B' |
|
| GROUP_CONCAT | GROUP_CONCAT(column) |
分组连接多个值 | 将分组内的多个值连接成单个字符串 | |
| 长度函数 | LENGTH | LENGTH(str) |
返回字符串的字节长度 | LENGTH('中文') → 6 (UTF-8) |
| CHAR_LENGTH | CHAR_LENGTH(str) |
返回字符串的字符个数 | CHAR_LENGTH('中文') → 2 |
|
| 位置函数 | LOCATE | LOCATE(substr, str) |
返回子串在字符串中的位置 | LOCATE('SQL', 'MySQL') → 3 |
| POSITION | POSITION(substr IN str) |
返回子串在字符串中的位置 | POSITION('SQL' IN 'MySQL') → 3 |
|
| INSTR | INSTR(str, substr) |
返回子串在字符串中的位置 | INSTR('MySQL', 'SQL') → 3 |
|
| 截取函数 | LEFT | LEFT(str, len) |
从左截取指定长度的字符串 | LEFT('MySQL', 2) → 'My' |
| RIGHT | RIGHT(str, len) |
从右截取指定长度的字符串 | RIGHT('MySQL', 3) → 'SQL' |
|
| SUBSTRING | SUBSTRING(str, pos, len) |
从指定位置截取字符串 | SUBSTRING('MySQL', 3, 2) → 'SQ' |
|
| SUBSTRING_INDEX | SUBSTRING_INDEX(str, delim, count) |
按分隔符截取字符串 | SUBSTRING_INDEX('a.b.c', '.', 2) → 'a.b' |
|
| 替换函数 | REPLACE | REPLACE(str, from_str, to_str) |
替换字符串中的子串 | REPLACE('ABC', 'B', 'X') → 'AXC' |
| INSERT | INSERT(str, pos, len, newstr) |
在指定位置插入字符串 | INSERT('Hello', 3, 0, 'xxx') → 'Hexxxllo' |
|
| REPEAT | REPEAT(str, count) |
重复字符串指定次数 | REPEAT('Hi', 3) → 'HiHiHi' |
|
| 大小写函数 | LOWER | LOWER(str) |
将字符串转换为小写 | LOWER('MySQL') → 'mysql' |
| UPPER | UPPER(str) |
将字符串转换为大写 | UPPER('mysql') → 'MYSQL' |
|
| LCASE | LCASE(str) |
将字符串转换为小写 | LCASE('MySQL') → 'mysql' |
|
| UCASE | UCASE(str) |
将字符串转换为大写 | UCASE('mysql') → 'MYSQL' |
|
| 空格处理 | TRIM | TRIM([BOTH] str) |
去除字符串两端空格/字符 | TRIM(' MySQL ') → 'MySQL' |
| LTRIM | LTRIM(str) |
去除字符串左侧空格 | LTRIM(' MySQL') → 'MySQL' |
|
| RTRIM | RTRIM(str) |
去除字符串右侧空格 | RTRIM('MySQL ') → 'MySQL' |
|
| 填充函数 | LPAD | LPAD(str, len, padstr) |
左侧填充字符串至指定长度 | LPAD('Hi', 5, '*') → '***Hi' |
| RPAD | RPAD(str, len, padstr) |
右侧填充字符串至指定长度 | RPAD('Hi', 5, '*') → 'Hi***' |
|
| SPACE | SPACE(n) |
返回指定数量的空格 | SPACE(3) → ' ' |
|
| 比较函数 | STRCMP | STRCMP(str1, str2) |
比较两个字符串 | STRCMP('a', 'b') → -1 |
| LIKE | str LIKE pattern |
模式匹配 | 'MySQL' LIKE 'My%' → 1 |
|
| REGEXP | str REGEXP pattern |
正则表达式匹配 | 'MySQL' REGEXP '^M' → 1 |
|
| 格式化函数 | REVERSE | REVERSE(str) |
反转字符串 | REVERSE('MySQL') → 'LQSyM' |
| FORMAT | FORMAT(num, decimals) |
数字格式化 | FORMAT(1234.567, 2) → '1,234.57' |
|
| QUOTE | QUOTE(str) |
添加引号并转义特殊字符 | QUOTE("Don't") → "'Don't'" |
|
| 编码函数 | HEX | HEX(str) |
转换为十六进制 | HEX('abc') → '616263' |
| UNHEX | UNHEX(hex_str) |
十六进制转字符串 | UNHEX('616263') → 'abc' |
|
| CONVERT | CONVERT(str USING charset) |
转换字符集 | CONVERT('中文' USING utf8mb4) |
|
| 其他函数 | ELT | ELT(n, str1, str2, ...) |
返回第n个字符串 | ELT(2, 'a', 'b', 'c') → 'b' |
| FIELD | FIELD(str, str1, str2, ...) |
返回字符串在列表中的位置 | FIELD('b', 'a', 'b', 'c') → 2 |
|
| SOUNDEX | SOUNDEX(str) |
返回字符串的语音表示 | SOUNDEX('smith') → 'S530' |

对于字符串的处理一般会在后端或者前端就做好了,++通常不会在数据库阶段进行处理++。
所以这里仅做两个常用字符串函数的示例:
-- 1. 获取字符串的长度
sql
SELECT length('123456');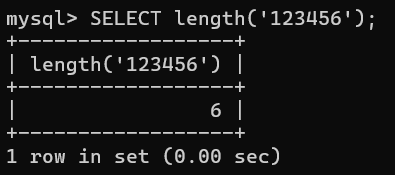
-- 2. 显示学生的考试成绩,格式为"XXX的语文成绩:XXX分,数学成绩:XXX分,英语成绩:XXX分"
这里展示表使用的是exam表,我给大家看一下它所包含的列和数据:
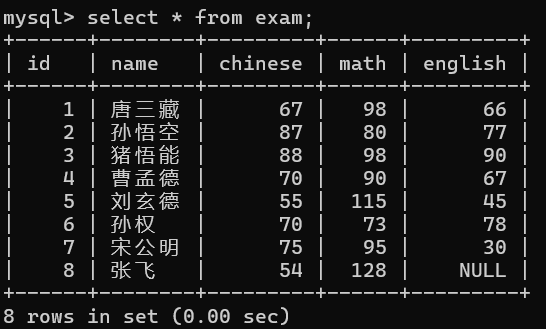
注意,null与字符串拼接的结果也为null。
sql
SELECT
concat(name, '的语文成绩: ', chinese
, '分, 数学成绩:', math
, '分,英语成绩:', english
, '分') AS 分数
FROM exam; 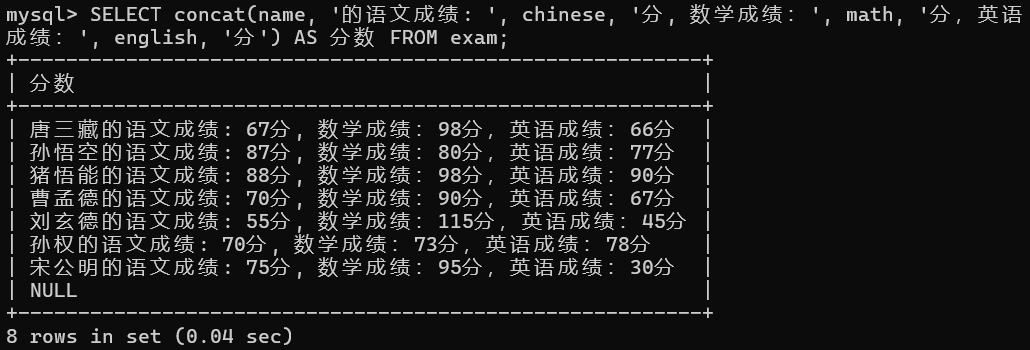
4.3 数学函数
| 分类 | 函数名 | 语法 | 功能描述 | 示例 |
|---|---|---|---|---|
| 基本运算 | + | a + b |
加法运算 | SELECT 5 + 3; → 8 |
| - | a - b |
减法运算 | SELECT 5 - 3; → 2 |
|
| * | a * b |
乘法运算 | SELECT 5 * 3; → 15 |
|
| / | a / b |
除法运算 | SELECT 6 / 2; → 3.0000 |
|
| DIV | a DIV b |
整数除法 | SELECT 7 DIV 2; → 3 |
|
| % | a % b |
取模运算 | SELECT 7 % 2; → 1 |
|
| MOD | MOD(a, b) |
取模运算 | MOD(7, 2) → 1 |
|
| 绝对值函数 | ABS | ABS(x) |
返回绝对值 | ABS(-10) → 10 |
| 取整函数 | CEIL | CEIL(x) |
向上取整 | CEIL(10.1) → 11 |
| CEILING | CEILING(x) |
向上取整 | CEILING(10.1) → 11 |
|
| FLOOR | FLOOR(x) |
向下取整 | FLOOR(10.9) → 10 |
|
| ROUND | ROUND(x, d) |
四舍五入 | ROUND(10.567, 2) → 10.57 |
|
| TRUNCATE | TRUNCATE(x, d) |
截断小数位 | TRUNCATE(10.567, 1) → 10.5 |
|
| 符号函数 | SIGN | SIGN(x) |
返回数值符号 | SIGN(-5) → -1, SIGN(0) → 0, SIGN(5) → 1 |
| 幂运算 | POW | POW(x, y) |
返回x的y次方 | POW(2, 3) → 8 |
| POWER | POWER(x, y) |
返回x的y次方 | POWER(2, 3) → 8 |
|
| SQRT | SQRT(x) |
返回平方根 | SQRT(16) → 4 |
|
| 指数对数 | EXP | EXP(x) |
返回e的x次方 | EXP(1) → 2.718281828459045 |
| LN | LN(x) |
返回自然对数 | LN(EXP(1)) → 1 |
|
| LOG | LOG(x) 或 LOG(b, x) |
返回对数 | LOG(10) → 1, LOG(2, 8) → 3 |
|
| LOG10 | LOG10(x) |
返回以10为底的对数 | LOG10(100) → 2 |
|
| LOG2 | LOG2(x) |
返回以2为底的对数 | LOG2(8) → 3 |
|
| 三角函数 | SIN | SIN(x) |
返回正弦值 | SIN(PI()/2) → 1 |
| COS | COS(x) |
返回余弦值 | COS(0) → 1 |
|
| TAN | TAN(x) |
返回正切值 | TAN(PI()/4) → 1 |
|
| ASIN | ASIN(x) |
返回反正弦值 | ASIN(1) → 1.5707963267948966 |
|
| ACOS | ACOS(x) |
返回反余弦值 | ACOS(1) → 0 |
|
| ATAN | ATAN(x) |
返回反正切值 | ATAN(1) → 0.7853981633974483 |
|
| ATAN2 | ATAN2(y, x) |
返回两个参数的反正切 | ATAN2(1, 1) → 0.7853981633974483 |
|
| COT | COT(x) |
返回余切值 | COT(PI()/4) → 1 |
|
| 角度弧度 | DEGREES | DEGREES(x) |
弧度转角度 | DEGREES(PI()) → 180 |
| RADIANS | RADIANS(x) |
角度转弧度 | RADIANS(180) → 3.141592653589793 |
|
| 圆周率 | PI | PI() |
返回圆周率π | PI() → 3.141593 |
| 随机数 | RAND | RAND() 或 RAND(seed) |
返回0-1的随机数 | RAND() → 0.123456789 |
| 进制转换 | BIN | BIN(n) |
十进制转二进制 | BIN(10) → '1010' |
| OCT | OCT(n) |
十进制转八进制 | OCT(10) → '12' |
|
| HEX | HEX(n) |
十进制转十六进制 | HEX(255) → 'FF' |
|
| CONV | CONV(n, from_base, to_base) |
任意进制转换 | CONV('A', 16, 10) → '10' |
|
| 位运算 | & | a & b |
按位与 | SELECT 5 & 3; → 1 |
| | | `a | b` | 按位或 | |
| ^ | a ^ b |
按位异或 | SELECT 5 ^ 3; → 6 |
|
| << | a << b |
左移位 | SELECT 1 << 3; → 8 |
|
| >> | a >> b |
右移位 | SELECT 8 >> 2; → 2 |
|
| ~ | ~a |
按位取反 | SELECT ~1; → 18446744073709551614 |
|
| 比较函数 | GREATEST | GREATEST(a, b, c, ...) |
返回最大值 | GREATEST(1, 5, 3) → 5 |
| LEAST | LEAST(a, b, c, ...) |
返回最小值 | LEAST(1, 5, 3) → 1 |
|
| 其他函数 | CRC32 | CRC32(expr) |
计算循环冗余校验值 | CRC32('MySQL') → 3259397556 |
| FORMAT | FORMAT(x, d) |
格式化数字显示 | FORMAT(1234.567, 2) → '1,234.57' |
同样的,对于字符串的处理一般会在后端或者前端就做好了,++通常不会在数据库阶段进行处理++。
这里仅演示一个常用的函数:
-- 限定两位小数
sql
SELECT round(3.1415936, 2); #round(原始数值,限定位数)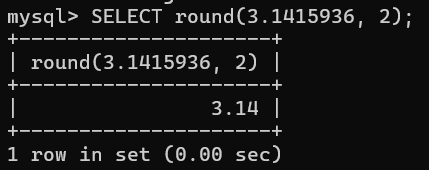
4.4 其他常用函数
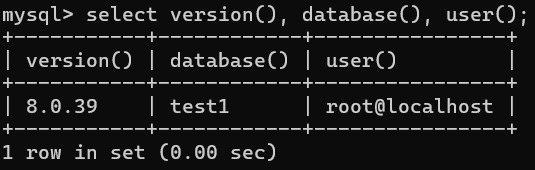
|------------------------|-----------------------------|
| 函数 | 说明 |
| version() | 显示当前数据库版本 |
| database() | 显示当前正在使⽤的数据库 |
| user() | 显示当前用户 |
| md5(str) | 对⼀个字符串进⾏md5摘要,摘要后得到⼀个32位字符串 |
| ifnull(val1, val2) | 如果val1为NULL,返回val2,否则返回val1 |
-- 示例

5. 所有查询子句的执行时机问题
5.1 各子句的执行顺序
SQL查询的实际执行顺序与书写顺序不同
-- 书写顺序
select distinct 查询列表 from 表名 where 条件 group by 分组列表 having 条件 order by 排序规则 limit 行数;
-- 实际执行顺序
1. FROM 子句 2. WHERE 子句 3. GROUP BY 子句 4. HAVING 子句 5. SELECT 子句 6. DISTINCT 子句 7. ORDER BY 子句 8. LIMIT 子句
在select之前执行的操作(from、where、group by、having)都是在真实表上操作,在select之后执行的操作(distinct、order by、limit)都是在虚拟表上操作。
数据准备阶段:处理基础表数据。
结果构建阶段(SELECT):构建包含计算列和别名的结果集(虚拟表)。
结果处理阶段:对最终结果集进行排序和限制。
5.2 哪些子句可以起别名
这么多种子句,只有select子句和from子句可以起别名。
SELECT子句**:** 定义列别名。
FROM子句**:** 定义表别名。
5.3 不同执行顺序的子句如何引用别名
规则:
- 一般来说,后执行的子句能够引用前执行子句的别名,前执行的子句不能引用后执行子句的别名。
- 由于MySQL的功能拓展,group by子句 和having子句都可以使用select子句定义的列别名。【注意:其他数据库不支持,这样的写法只有MySQL数据库支持,不具有可移植性】
- limit子句不存在别名的使用。
-- 显示平均工资高于10000的角色和它的平均工资:having子句使用列别名
sql
SELECT role 角色, avg(salary) 平均工资 FROM emp GROUP BY 角色 HAVING 平均工资 > 10000;
本期分享完毕,感谢大家的支持Thanks♪(・ω・)ノ
