在上一篇文章中,我们快速了解了 LiteLLM 的核心特性和基本用法。我们知道 LiteLLM 通过统一的 API 接口支持调用 100+ 个 LLM 服务商的模型,而 Proxy Server 可以作为一个企业级的 LLM 网关来统一管理和路由请求。
但是,当我们真正去部署和使用 LiteLLM Proxy 时,会面临一个非常实际的问题:如何有效地管理这些模型?
是否能够快速添加新模型而不需要重启服务?能否让用户清楚地了解有哪些模型可用?在使用过程中,如何追踪模型的定价和成本?怎样安全地存储和管理各个服务商的 API 凭据?这些都是模型管理需要解决的问题。
这一篇文章,我们就来深入学习 LiteLLM 的模型管理功能,看看它是如何帮助我们解决这些实际问题的。
基础配置
在前面的快速入门篇,我们已经接触过简单的模型配置,可以通过 config.yaml 文件定义模型:
yaml
model_list:
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_API_KEY
- model_name: claude
litellm_params:
model: anthropic/claude-sonnet-4-20250514
api_key: os.environ/ANTHROPIC_API_KEY这里的配置很直观:
model_name是用户在调用 API 时使用的名称litellm_params包含了 LiteLLM 在调用该模型时需要的所有参数,包括实际的模型名称、API 密钥、URL 地址等model:遵循provider/model_id的格式,LiteLLM 通过这个来识别实际的模型和服务商api_key:支持os.environ/KEY_NAME的格式来从环境变量中读取,避免将密钥硬编码在配置文件中
但在实际应用中,我们往往需要更多的信息。比如,某个模型的最大 Token 数是多少?调用这个模型的成本是多少?这个模型有什么特殊的功能限制吗?这就需要用到 model_info 字段,我们可以通过 /model/info 接口了解每个模型的详细信息:
bash
$ curl -X GET http://127.0.0.1:4000/model/info \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json'返回结果类似下图:

对于一些比较常见的模型,LiteLLM 会定期维护基本信息,不过用户也可以在配置文件中进行修改,这样会覆盖默认值,用户还可以添加自定义的字段:
yaml
model_list:
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_API_KEY
model_info:
description: "这里是用户自定义字段"
max_tokens: 4096
supports_vision: true
supports_function_calling: true这个 /model/info 接口非常有用,可以用来在应用的 UI 中展示可用的模型列表和详细信息,帮助用户选择最合适的模型,进行成本估算和预算规划。
动态管理
通过配置文件管理模型固然简单,但是每次修改都需要重启 Proxy Server,这在生产环境下是不可接受的。LiteLLM 支持将模型信息保存到 Postgres 数据库中,从而实现动态管理功能。首先修改 config.yaml 文件,加上数据库配置并开启模型保存功能:
yaml
general_settings:
master_key: sk-1234 # 管理员密钥
database_url: "postgresql://postgres:password@127.0.0.1:5432/litellm"
store_model_in_db: true # 是否将模型保存到数据库然后重启 Proxy Server,现在我们就可以通过 API 接口的方式动态管理模型了,具体又可以分为 通过 API 管理 、通过命令行管理 、通过 Web UI 管理 几种方式。
通过 API 管理
通过 /model/new 接口添加模型:
bash
$ curl -X POST "http://127.0.0.1:4000/model/new" \
-H 'Authorization: Bearer sk-1234' \
-H "Content-Type: application/json" \
-d '{
"model_name": "deepseek",
"litellm_params": {
"model": "deepseek/deepseek-chat",
"api_key": "sk-xxx"
}
}'通过命令行管理
LiteLLM 还提供了一个命令行工具 litellm-proxy,方便从命令行管理模型,这个工具在安装 Proxy Server 时会一起安装好:
bash
$ pip install 'litellm[proxy]'首先通过环境变量配置认证信息:
bash
export LITELLM_PROXY_URL=http://localhost:4000
export LITELLM_PROXY_API_KEY=sk-1234也可以使用
litellm-proxy login登录,这会打开浏览器进行身份认证,认证后的凭据会保存在本地。
列出所有模型:
bash
$ litellm-proxy models list添加新模型:
bash
$ litellm-proxy models add deepseek \
--param model=deepseek/deepseek-chat \
--param api_key=sk-xxxx删除模型:
bash
$ litellm-proxy models delete <model-id>通过 Web UI 管理
如果你不习惯使用命令行,LiteLLM Proxy 的 Web UI 也提供了可视化的模型管理界面,登录到管理后台后,点击 "Models + Endpoints" 菜单:
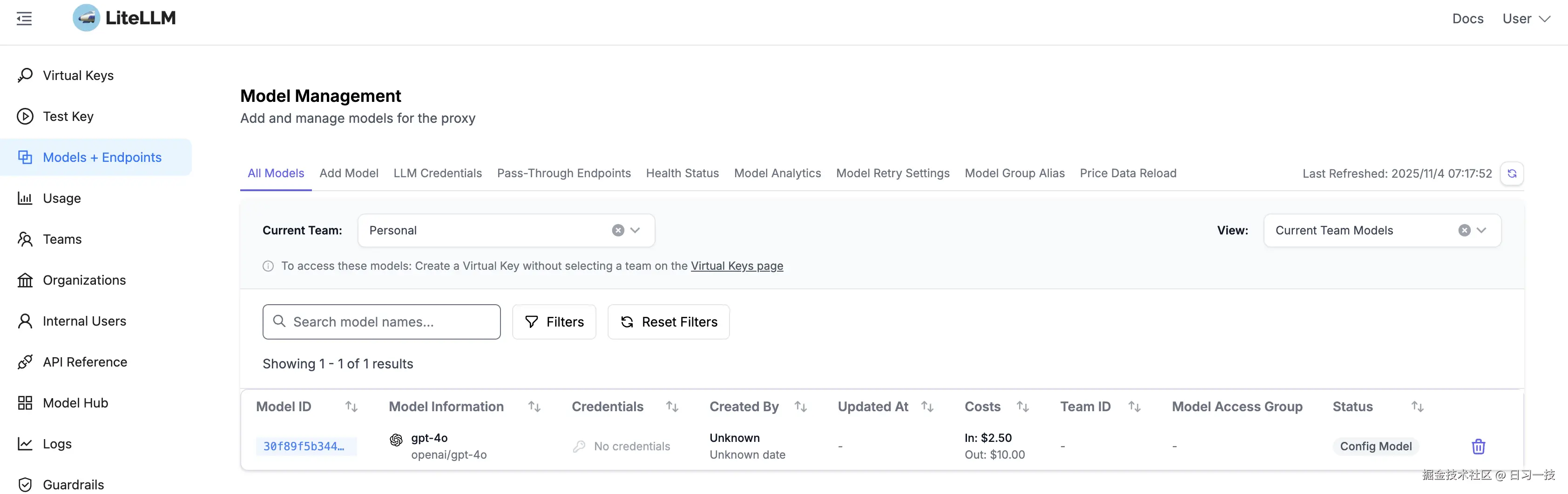
这里列出了当前系统的所有模型,包括配置文件中的和数据库中的。点击 "Add Model" 标签添加新模型:
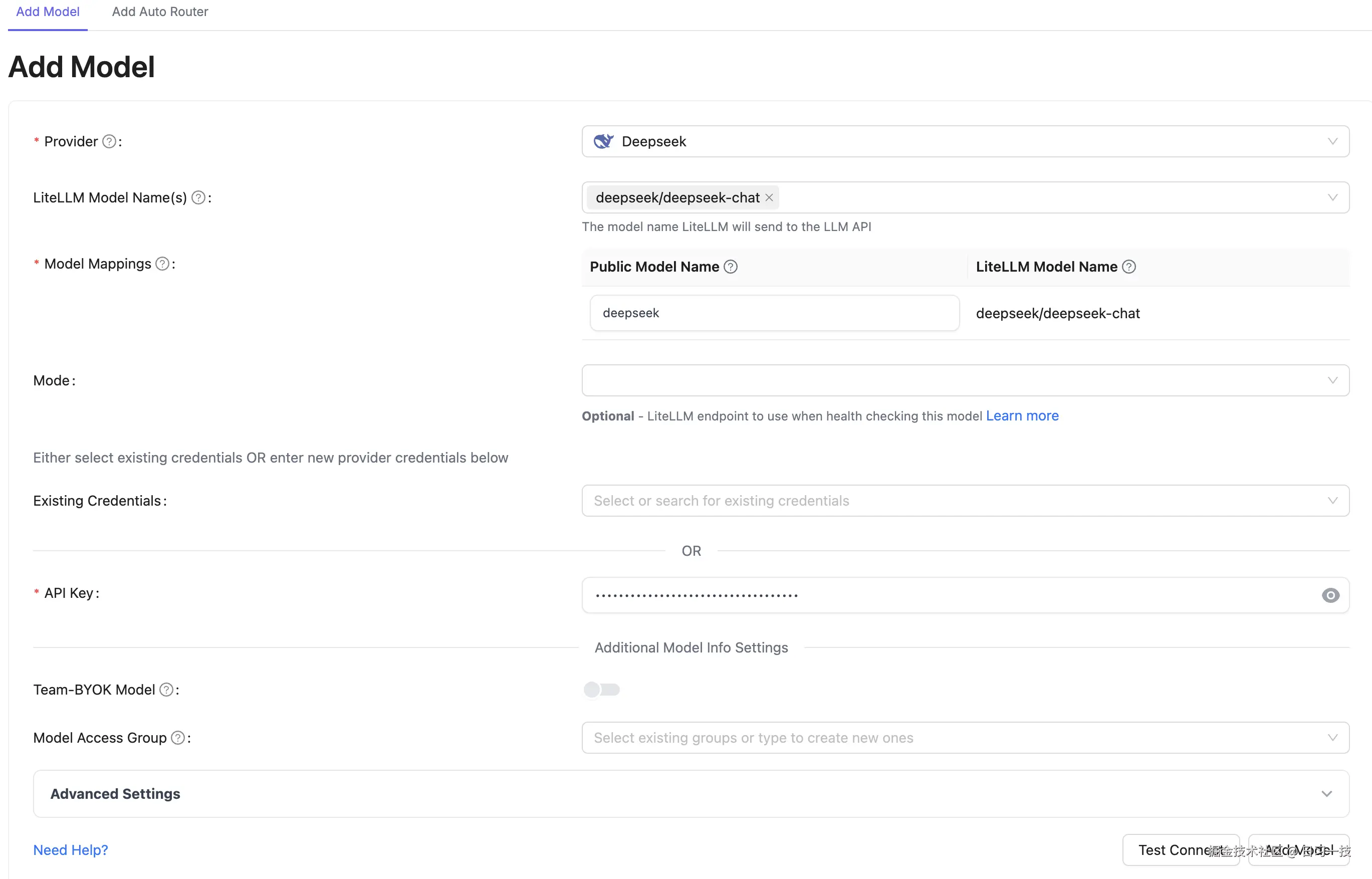
填写 Provider、Model Names、Model Mappings、API Key 等参数,点击确认即可。
注意,Model Mappings 中的 Public Model Name 就对应配置文件中的 model_name 参数,LiteLLM Model Name 对应 litellm_params.model 参数。
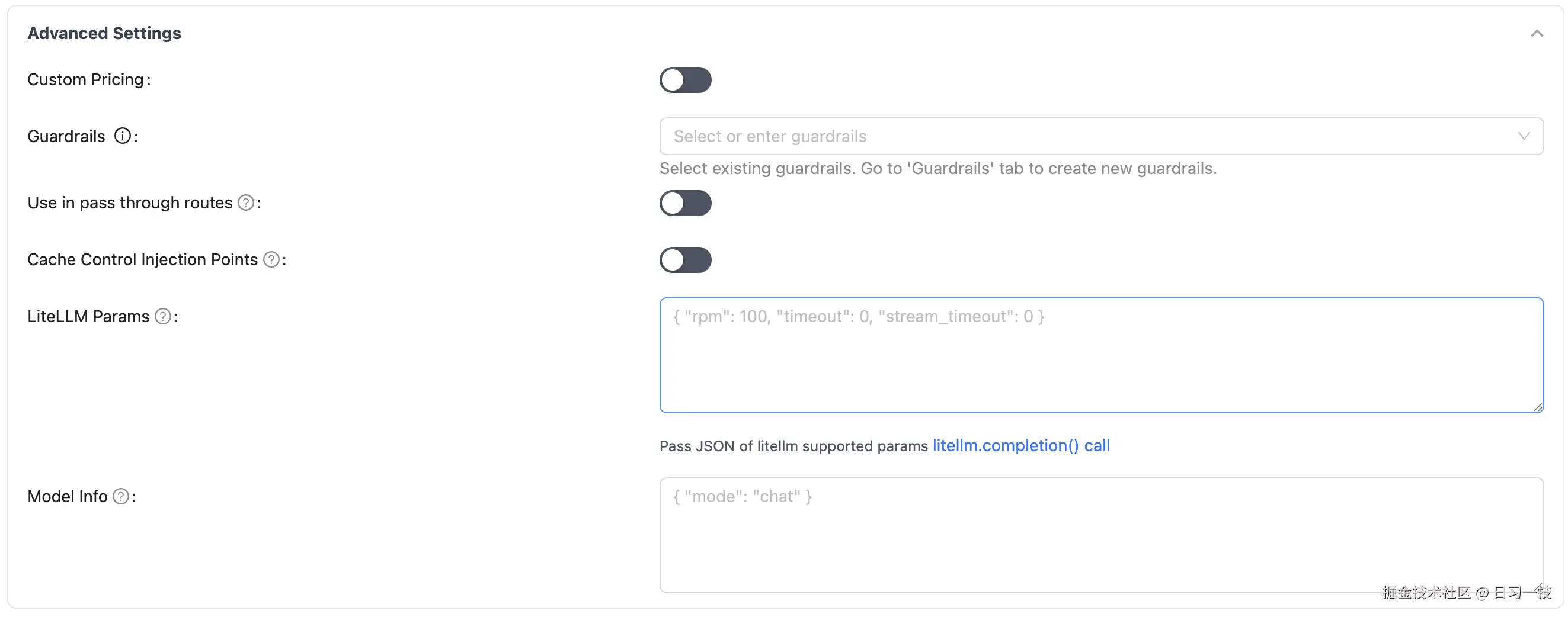
如果有一些额外参数,可以展开 "Advanced Settings" 进行配置:
模型发现
手动维护模型列表可能会很繁琐,特别是对于那些有大量模型的服务商,比如 OpenAI、Anthropic 等,每次他们发布新模型时我们都要手动更新配置。为此,LiteLLM 推出了 模型发现(Model Discovery) 功能,通过 Wildcard 模型 LiteLLM 可以自动从服务商处获取最新的模型列表,无需手动更新。
其配置非常简单,只需要在 config.yaml 中使用 /* 后缀来表示 Wildcard 模型:
yaml
model_list:
- model_name: anthropic/*
litellm_params:
model: anthropic/*
api_key: os.environ/ANTHROPIC_API_KEY
litellm_settings:
check_provider_endpoint: true # 启用模型发现功能注意 litellm_settings.check_provider_endpoint 必须设为 true,表示启用模型发现功能。
配置完成后,调用 /v1/models 接口就可以看到所有自动发现的模型:
bash
$ curl -X GET http://127.0.0.1:4000/v1/models \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json'这里我使用的是 Anthropic 服务商,因此返回的结果包含了 Anthropic 的所有可用模型:
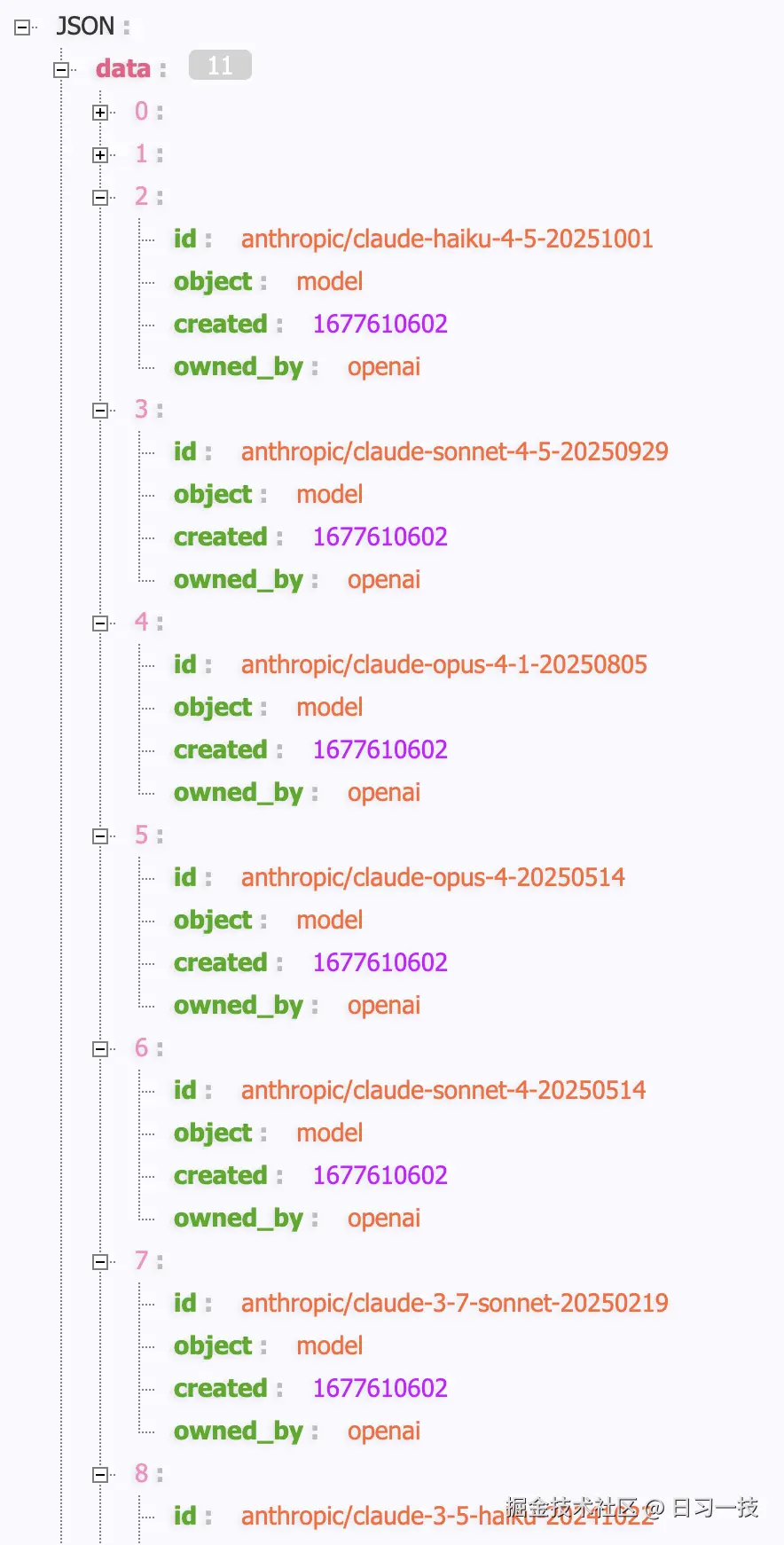
目前 LiteLLM 的模型发现功能支持以下服务商:
- Fireworks AI
- OpenAI
- Gemini
- LiteLLM Proxy(是的,可以级联!)
- Topaz
- Anthropic
- xAI
- vLLM
- Vertex AI
使用 Model Hub 公开模型
在团队或企业环境中,你可能希望让用户知道哪些模型是可用的,LiteLLM 提供了一个 Model Hub 功能,可以公开展示模型列表。使用 Model Hub 有以下几点优势:
- 自服务探索:用户可以自己浏览可用的模型,无需询问管理员
- 信息透明:每个模型都展示详细的信息,包括描述、能力、局限等
- 降低门槛:新用户可以快速了解系统中有什么,如何使用
- 公开演示:可以用来向客户或合作伙伴展示你的模型能力
首先,我们需要在 Web UI 中选择要公开的模型。进入 Model Hub 页面后,点击 "Make Public" 按钮,选择要公开的模型:
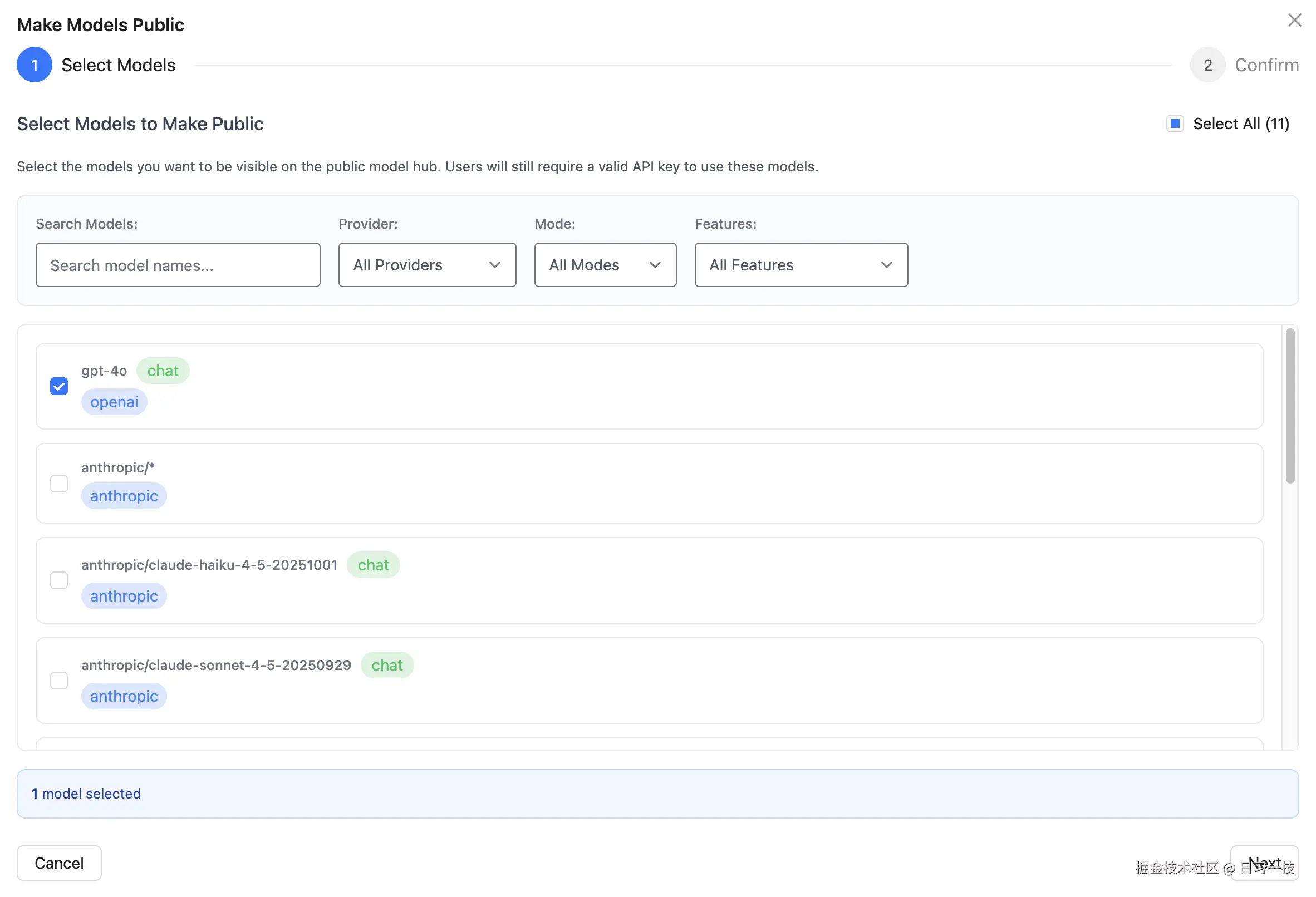
确认后,这些模型就会出现在公开的 Model Hub 页面上,访问下面这个 URL 进行查看:
arduino
http://127.0.0.1:4000/ui/model_hub_table这个页面是公开的,所有人都能访问,就像一个应用商店一样:
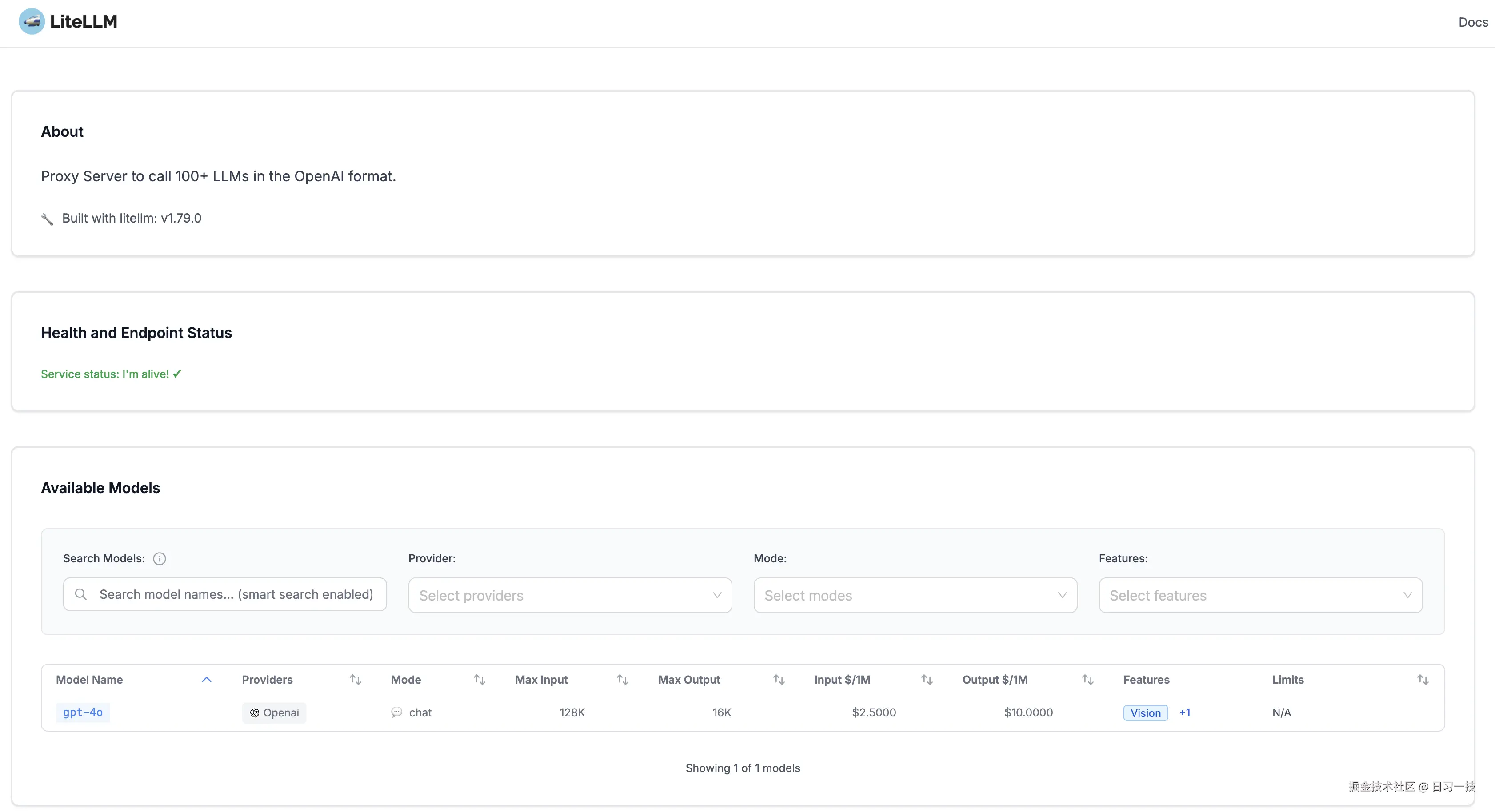
用户可以在这里查看每个模型的详细信息以及使用文档。
模型价格同步
在上面的学习中我们了解到,可以通过 /model/info 接口查询模型的详细信息,包括模型的上下文限制以及输入输出价格等,这些信息有助于企业进行准确的成本追踪和预算控制。
LiteLLM 在 GitHub 上维护了一个完整的模型成本映射表,包含了 100+ 个模型的详细信息:
bash
https://github.com/BerriAI/litellm/blob/main/model_prices_and_context_window.json随着新模型的发布和价格的变化,这个映射表会定期更新。为了保持你的 Proxy Server 中的成本数据最新,LiteLLM 提供了 手动同步 和 自动同步 的功能,可以从 GitHub 获取最新的价格信息,确保成本追踪的准确性。
如果你想立即同步最新的价格信息,可以使用以下命令:
bash
$ curl -X POST "http://127.0.0.1:4000/reload/model_cost_map" \
-H "Authorization: Bearer sk-1234" \
-H "Content-Type: application/json"对于生产环境,更推荐设置自动定期同步,比如每 6 小时同步一次:
bash
$ curl -X POST "http://127.0.0.1:4000/schedule/model_cost_map_reload?hours=6" \
-H "Authorization: Bearer sk-1234" \
-H "Content-Type: application/json"查看同步状态:
bash
$ curl -X GET "http://127.0.0.1:4000/schedule/model_cost_map_reload/status" \
-H "Authorization: Bearer sk-1234"取消定时同步:
bash
$ curl -X DELETE "http://127.0.0.1:4000/schedule/model_cost_map_reload" \
-H "Authorization: Bearer sk-1234"默认情况下,LiteLLM 从 GitHub 的官方仓库获取模型成本表。如果你有一些定制模型,想使用自定义的模型成本表,可以设置环境变量:
bash
export LITELLM_MODEL_COST_MAP_URL="https://your-server.com/your-cost-map.json"或者使用本地文件:
bash
export LITELLM_LOCAL_MODEL_COST_MAP=True此时 LiteLLM 会读取 litellm 目录下的 model_prices_and_context_window_backup.json 文件,不会访问网络。
凭据管理
关于模型管理的另一个话题是 凭据管理,我们知道,LiteLLM 支持 100 多个不同的模型服务商,每个服务商都有自己的 API Key 或认证方式,如何安全的管理这些服务商的凭据呢?
在前面的 config.yaml 文件中,我们配置 api_key 时使用了 os.environ/KEY_NAME 格式从环境变量中读取,这是最简单的一种凭据管理的方式,避免将密钥硬编码在配置文件中,虽然很方便,但是这种方式难以管理,而且也不够安全,在某些情况下,你可能希望在 LiteLLM 的数据库中直接存储和管理这些凭证。
LiteLLM 提供了一个专门的凭证管理界面,进入 Models -> LLM Credentials -> Add Credential,可以添加新的凭证:
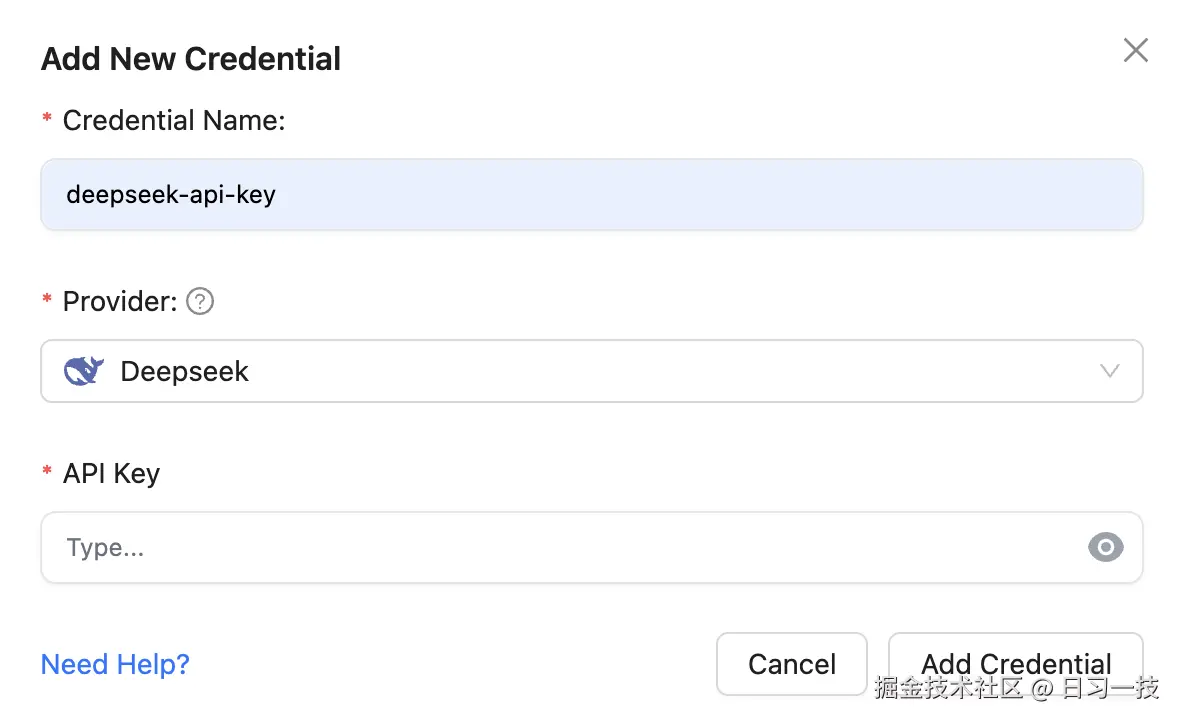
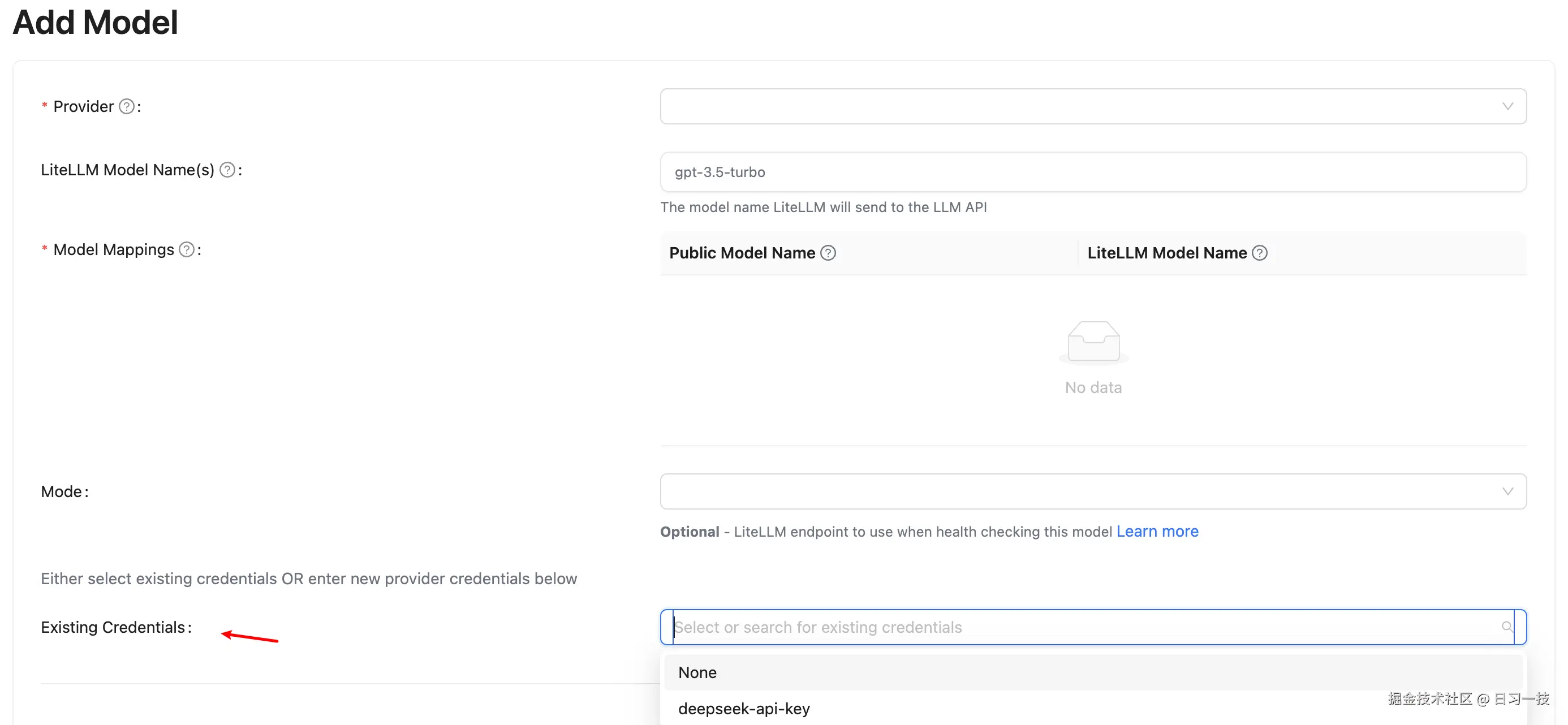
选择你的 LLM 服务商后,输入 API Key 和其他必要信息(根据不同的服务商,界面会显示相应的字段),点击确认即可。添加凭证后,在创建新模型时就可以从下拉列表中选择已有的凭证,避免重复输入敏感信息:
凭证在数据库中是加密存储的。LiteLLM 使用以下方式进行加密:
- 优先使用
LITELLM_SALT_KEY进行加密 - 如果未设置
LITELLM_SALT_KEY,则使用LITELLM_MASTER_KEY进行加密
这两个密钥都应该被妥善保管,不要泄露。
企业级凭据管理
对于企业级应用,对于凭据管理可能有着更高的安全要求,LiteLLM 支持与主流的 密钥管理服务(Secrets Manager) 集成,允许你将凭据存储在企业级的密钥管理服务中,而不是 LiteLLM 的数据库中。支持的 Secrets Manager 包括:
- AWS Secrets Manager
- AWS Key Management Service
- Azure Key Vault
- Google Secret Manager
- Google Key Management Service
- HashiCorp Vault
除了传统的 API Key,LiteLLM 还支持 OpenID Connect (OIDC) 身份认证,这是一种更现代、更安全的认证方式。支持的 OIDC 提供商包括:
- Google Cloud Run
- GitHub Actions
- Azure AD
- CircleCI
- Azure Kubernetes Service 等
这两个功能特别适合大型企业环境,可以显著提高安全性和合规性。详细的企业特性配置,请参考 LiteLLM 官方文档。
小结
通过这篇文章,我们详细学习了 LiteLLM Proxy 的模型管理功能。主要内容包括:
- 基础配置 :对于相对稳定的模型配置,应该在
config.yaml中定义,这样可以版本控制,便于回滚;充分利用model_info字段来添加模型描述、能力说明、使用建议等,这会让用户更容易选择合适的模型; - 动态管理 :通过
/model/new接口在运行时动态添加模型,支持 API、命令行、Web UI 三种方式对模型进行管理,无需重启服务; - 模型发现:通过通配符自动获取整个服务商的模型列表;
- Model Hub:公开展示可用的模型信息,提升用户体验;
- 模型价格同步:手动或自动从 GitHub 同步最新的模型成本数据,支持自定义模型成本表;
- 凭据管理:集中管理 API Key 和凭据信息,降低凭据泄露的风险;对于高安全要求场景,考虑使用企业特性(Secret Manager 或 OIDC),实现零密钥存储或临时凭据;
LiteLLM 的模型管理系统设计得相当完善,既支持初期的简单配置,也支持后期的复杂运维场景。从 config.yaml 的声明式配置,到运行时的动态管理,再到企业级的高安全凭据存储,LiteLLM 为不同规模的应用提供了灵活的解决方案。
欢迎关注
如果这篇文章对您有所帮助,欢迎关注我的同名公众号:日习一技,每天学一点新技术。
我会每天花一个小时,记录下我学习的点点滴滴。内容包括但不限于:
- 某个产品的使用小窍门
- 开源项目的实践和心得
- 技术点的简单解读
目标是让大家用5分钟读完就能有所收获,不需要太费劲,但却可以轻松获取一些干货。不管你是技术新手还是老鸟,欢迎给我提建议,如果有想学习的技术,也欢迎交流!