目录
选题意义背景
随着互联网技术的迅猛发展,Web应用已成为人们日常生活和工作中不可或缺的重要组成部分。然而,伴随Web应用普及而来的是日益严峻的网络安全威胁,恶意请求是指含有攻击代码的HTTP请求,攻击者通过在请求报文中注入恶意代码,如SQL注入语句、跨站脚本(XSS)代码、命令注入等,对Web服务器进行攻击。这些攻击可能导致数据泄露、服务中断、系统宕机等严重后果。最新的网络安全报告显示,超过85%的Web应用漏洞可以通过恶意请求触发,因此如何快速、高效地检测Web恶意请求已成为网络安全领域的研究热点。

当前,基于机器学习的恶意请求检测方法面临的主要挑战包括:(1)特征提取维度单一,通常仅针对URL字段进行分析,导致模型泛化能力较弱;(2)过度依赖有标签数据,而在实际网络环境中,人工标注大量数据十分困难,导致模型训练不充分;(3)检测准确率和效率难以兼顾,无法满足大规模Web应用的实时检测需求,针对现有方法的不足,提出了两种创新的Web恶意请求检测方法:一种基于多维特征融合,另一种基于自监督对比判别。这些方法旨在提高恶意请求检测的准确性、泛化能力和适应性,为Web应用安全防护提供更加有效的技术手段。
数据集
数据集获取
在本研究中,我们主要使用了三个公开的Web恶意请求数据集进行模型训练和评估:CSIC 2010数据集、Label CND数据集以及自行构建的CND数据集。 Web请求样本主要分为两大类:
-
正常请求:符合HTTP协议规范、不包含恶意代码的请求。这类请求通常由正常用户通过浏览器或其他客户端工具发送,用于访问Web应用的正常功能。
-
恶意请求:包含攻击代码或试图利用Web应用漏洞的请求。根据攻击类型的不同,恶意请求又可以细分为以下几类:
- SQL注入攻击:通过在请求参数中插入SQL语句,试图操纵数据库或获取敏感信息
- 跨站脚本(XSS)攻击:通过注入恶意脚本,在用户浏览器中执行恶意操作
- 命令注入攻击:通过注入系统命令,试图控制服务器操作系统
- 文件包含攻击:通过操纵文件包含函数,读取服务器上的敏感文件
- WebShell攻击:上传包含恶意代码的脚本文件,获取服务器控制权
数据分割策略
为了确保模型训练的有效性和评估的公正性,我们采用了以下数据分割策略:
-
训练集、验证集和测试集的划分:
- 对于CSIC 2010数据集和Label CND数据集,我们采用7:1:2的比例进行划分,即70%的数据用于模型训练,10%用于模型验证,20%用于模型测试
- 对于CND数据集,由于大部分为无标签数据,我们将无标签数据全部用于自监督预训练,将有标签数据按8:2的比例划分为预训练模型的微调集和测试集
-
数据分割的随机性:
- 为避免数据分割带来的偏差,我们使用随机种子确保每次分割的可重复性
- 在分割过程中,我们保持各类别样本在训练集、验证集和测试集中的比例一致,避免类别不平衡问题
数据预处理
数据预处理是模型训练前的关键步骤,直接影响模型的性能。我们对原始数据进行了以下预处理操作:
-
数据清洗:
- 移除重复的请求样本,避免模型过拟合
- 过滤无效或格式错误的请求报文
- 移除请求报文中的噪声数据,如随机生成的会话ID、时间戳等
-
数据标准化:
- 将所有请求报文转换为统一的字符编码(UTF-8)
- 对URL和请求参数进行解码处理,还原被编码的恶意代码
- 将请求报文按字段(URL、Cookie、User-Agent等)进行拆分,便于后续特征提取
-
数据增强:
- 对于有标签数据,我们采用了多种数据增强技术,如同义词替换、字符插入等,扩充训练数据规模
- 对于用于自监督预训练的数据,我们采用了随机掩码、随机删除等技术,增强模型的鲁棒性
-
特征预处理:
- 对统计特征进行标准化处理,使其取值范围归一化到0,1区间
- 对文本特征进行分词处理,将请求报文转换为模型可处理的序列形式
- 构建字符级别的词汇表,用于词嵌入表示
通过以上预处理步骤,我们得到了高质量的训练数据,为后续的模型训练奠定了坚实基础。
功能模块介绍
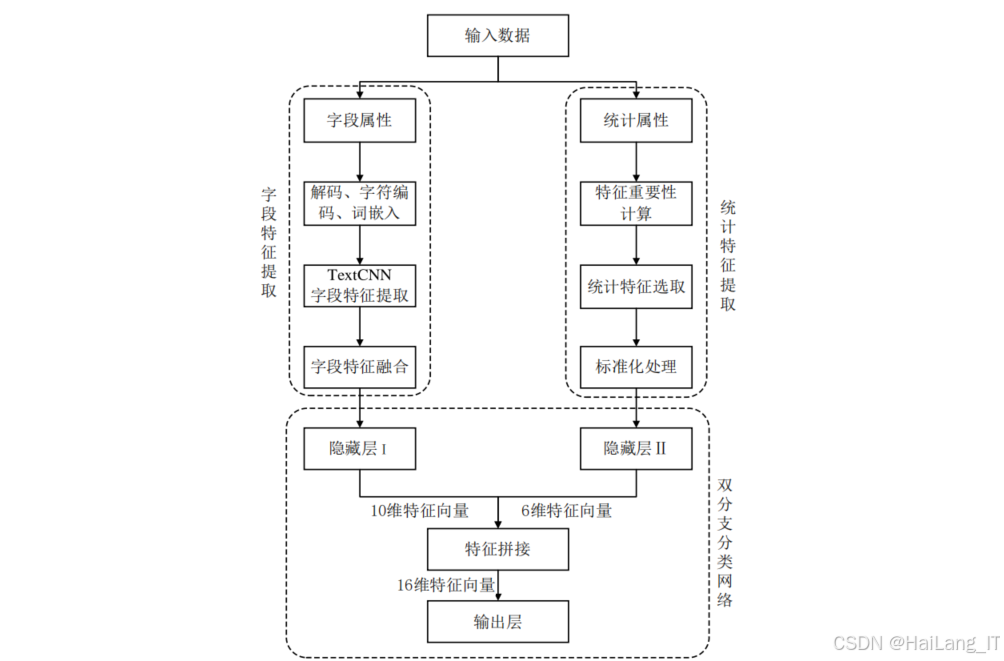
多维特征融合的恶意请求检测模块
该模块的核心思想是从多个维度对HTTP请求报文进行特征提取,并通过特征融合技术提高检测模型的性能。该模块主要包含以下几个子模块:
字段属性分析与特征提取负责对HTTP请求报文中的关键字段进行分析和特征提取。主要步骤包括:
-
字段识别与提取 :首先从HTTP请求报文中提取出关键字段,包括传输参数、Cookie、User-Agent、Referer和X-Forwarded-For等。这些字段是恶意代码注入的主要目标,包含了丰富的攻击特征信息。

-
解码处理 :对提取出的字段进行解码处理,还原被编码的恶意代码。常见的编码方式包括Base64编码、URL编码和Hex编码等。解码过程需要智能识别字段的编码类型,并选择相应的解码算法。

-
字符编码 :将解码后的字段文本按字符分割,并使用独热编码 将每个字符转换为数字化向量。这种方法能够最大程度地保留字段文本中的语义信息,便于后续模型处理。
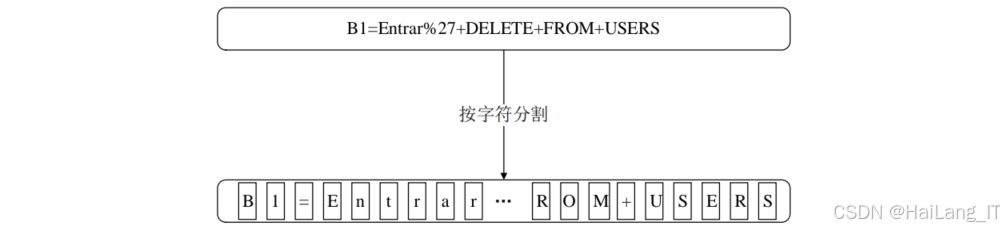
-
词嵌入表示:通过训练Embedding层,将字符的独热编码转换为低维、稠密的字符特征向量。词嵌入能够有效表示字符之间的语义关联性,相关性高的字符在特征空间中距离较近。
-
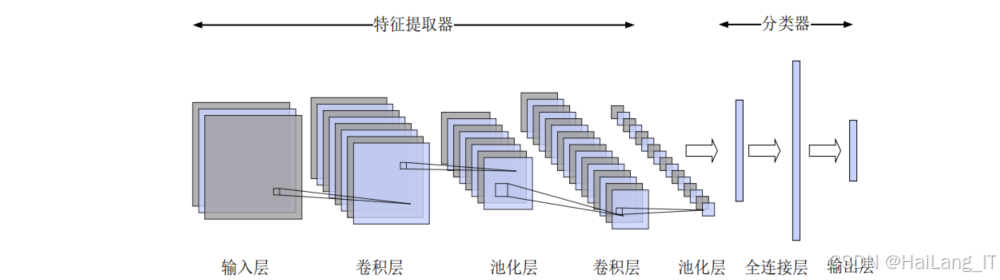
特征提取 :使用TextCNN模型对词嵌入后的字符序列进行特征提取。TextCNN通过多个不同尺寸的卷积核,能够捕获不同长度的字符组合特征,有效识别恶意请求中的攻击模式。
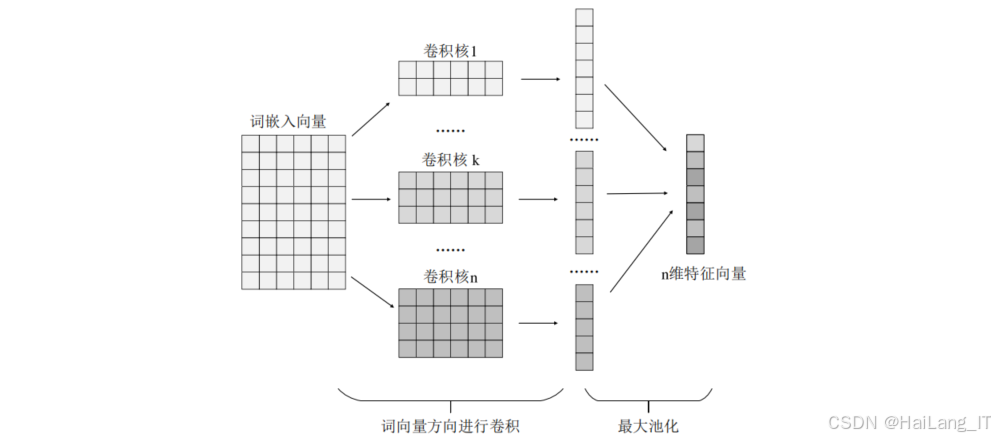
统计特征分析与提取模块负责从统计角度对HTTP请求报文进行特征提取,主要包括:
-
长度统计特征提取 :计算HTTP请求报文及其各字段的长度特征,如请求总长度、URL长度、Cookie长度等。恶意请求由于包含大量攻击代码,通常具有较长的长度特征。
-
数量统计特征提取:统计HTTP请求报文中的参数数量、特殊字符数量等特征。攻击代码通常通过多个参数或特殊字符注入,因此这些特征能够有效区分正常请求和恶意请求。
-
信息熵与重合指数计算:计算请求报文的信息熵和重合指数。恶意请求为了混淆视听,通常包含大量随机字符,表现出较高的信息熵和较低的重合指数。
-
特征重要性评估:基于基尼系数和随机森林算法,对提取出的统计特征进行重要性评估,筛选出对恶意请求检测贡献较大的特征。这一步骤能够减少特征冗余,提高模型训练效率。
自监督对比判别的恶意请求检测模块
针对有标签数据不足的场景,通过自监督学习方法提高恶意请求检测的效果。该模块主要包含以下几个子模块:
预训练模块是自监督学习的核心,负责从大规模无标签数据中学习通用的特征表示。该模块包括:
-
数据准备与增强 :对无标签的请求报文数据进行预处理,并通过多种数据增强技术生成多样化的训练样本。数据增强技术包括随机删除、同义词替换、Dropout等,能够有效扩充训练数据规模。
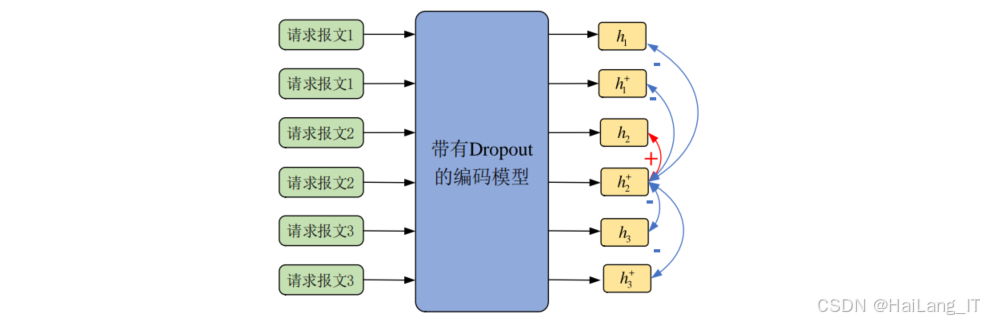
-
基于对比学习的预训练:设计对比学习任务,将同一请求报文的不同增强样本作为正样本对,不同请求报文的增强样本作为负样本对。通过优化对比损失函数,使模型学习到请求报文的语义表示,将相似的请求报文在特征空间中聚集。
-
基于掩码判别的预训练:设计掩码判别任务,随机掩盖请求报文中的部分字符,让模型预测被掩盖的字符。通过这种方式,模型能够学习到请求报文的上下文信息和字符间的依赖关系,提高特征表示的质量。
-
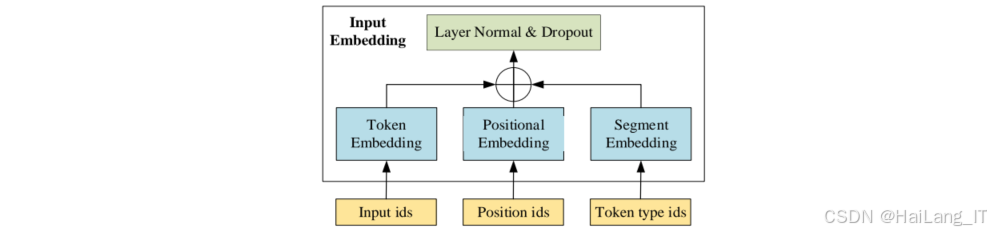
Bert模型优化:基于预训练任务的损失函数,对Bert模型的参数进行优化,特别是词嵌入矩阵和注意力权重。优化后的Bert模型能够更有效地表示请求报文的语义信息,为后续的分类任务提供高质量的特征输入。
分类检测模块基于预训练后的Bert模型,对请求报文进行分类检测。该模块包括:
-
词向量表征:使用预训练后的Bert模型对请求报文进行词向量表征,得到包含丰富语义信息的特征向量。
-
BiLSTM特征提取:使用双向长短期记忆网络(BiLSTM)对词向量序列进行特征提取。BiLSTM能够有效捕捉请求报文的时序特征,同时考虑上下文信息,提高特征提取的效果。
-
多头目标注意力机制 :设计多头目标注意力机制,从不同的注意力头空间对BiLSTM的输出进行特征提取。这种方法能够从多个角度关注请求报文的关键特征,有效缓解BiLSTM模型的长距离依赖问题。
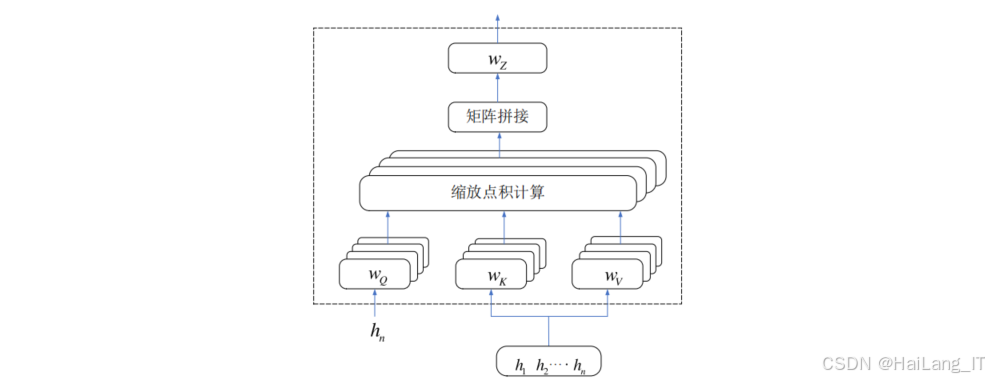
-
分类器设计:使用全连接神经网络作为分类器,对提取出的特征进行分类,判断请求报文是否为恶意请求。分类器的输出层使用softmax激活函数,输出请求报文属于各类别的概率。
算法理论
多维特征融合算法
多维特征融合算法是本研究提出的第一种恶意请求检测方法的核心,其理论基础包括字段特征提取、统计特征分析和特征融合三个方面。字段特征提取是从HTTP请求报文的各字段中提取攻击特征的过程。该过程基于以下理论:
-
字符级表示理论:将HTTP请求报文字段视为字符序列,通过字符级表示能够保留字段中的所有信息,包括特殊字符和攻击代码。与词级表示相比,字符级表示在处理未知词汇和特殊字符时具有明显优势。
-
卷积神经网络理论 :TextCNN模型基于卷积神经网络理论,通过多个卷积核提取不同长度的字符组合特征。卷积操作能够有效捕获局部特征模式,对于识别恶意请求中的攻击代码片段具有重要作用。
-
词嵌入理论 :词嵌入将离散的字符映射到连续的向量空间,能够有效表示字符之间的语义关联性。在恶意请求检测中,相似的攻击模式在嵌入空间中距离较近,便于模型学习和识别。
统计特征分析基于请求报文的统计属性进行恶意请求识别,其理论基础包括:
-
特征重要性评估理论:基于基尼系数的特征重要性评估方法,通过计算特征划分前后样本集纯度的变化,评估特征对分类任务的贡献程度。基尼系数越低,说明样本集纯度越高,特征的分类效果越好。
-
随机森林理论:随机森林算法通过集成多个决策树,降低了模型的方差,提高了分类的准确性。在特征选取过程中,随机森林能够有效评估各特征的重要性,筛选出最优的特征子集。
-
信息论理论:信息熵和重合指数基于信息论理论,用于衡量请求报文的不确定性和字符分布特征。恶意请求由于包含随机生成的攻击代码,通常具有较高的信息熵和较低的重合指数。
特征融合是将不同维度的特征进行有效结合的过程,其理论基础包括:
-
注意力机制理论:注意力机制能够自动学习各特征的重要性权重,为不同的特征分配不同的权重,实现自适应的特征融合。在恶意请求检测中,不同字段特征的重要性可能随攻击类型的不同而变化,注意力机制能够动态调整各字段的权重。
-
多分支网络理论:双分支网络结构能够并行处理不同类型的特征,充分发挥各类特征的优势。字段特征和统计特征在表征恶意请求时具有互补性,双分支网络能够有效融合这两类特征的信息。
自监督对比判别算法
自监督对比判别算法是本研究提出的第二种恶意请求检测方法的核心,其理论基础包括对比学习、掩码学习和注意力机制三个方面。
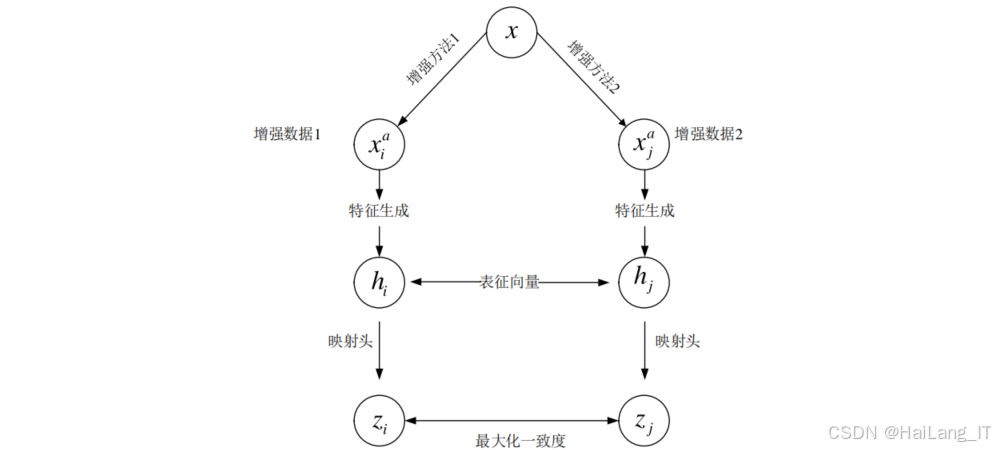
对比学习是一种无监督学习方法,通过学习样本间的相似性和差异性,实现数据的有效表征。其理论基础包括:
-
对比损失函数理论:对比损失函数通过最大化正样本对的相似度,最小化负样本对的相似度,使模型学习到数据的语义表示。在恶意请求检测中,对比学习能够使相似的请求报文在特征空间中聚集,不同的请求报文相互分离。
-
数据增强理论:数据增强是对比学习的重要组成部分,通过生成样本的不同变体,扩充训练数据规模。在请求报文数据增强中,需要保持样本的语义信息不变,同时引入合理的扰动,使模型学习到更鲁棒的特征表示。
-
表征学习理论:对比学习的目标是学习到数据的有效表征,使表征向量能够保留数据的语义信息。在恶意请求检测中,有效的表征能够帮助模型更好地区分正常请求和恶意请求。
掩码学习是另一种自监督学习方法,通过预测被掩盖的部分,使模型学习到数据的上下文信息。其理论基础包括:
-
掩码语言模型理论:掩码语言模型通过随机掩盖输入文本的部分字符,让模型预测被掩盖的字符。在恶意请求检测中,这种方法能够使模型学习到请求报文的字符间依赖关系和语义结构。
-
Bert模型理论:Bert模型基于Transformer架构,通过多层自注意力机制,能够有效捕捉文本的全局依赖关系。在预训练过程中,Bert模型通过掩码学习任务,学习到通用的语言表示能力。
多头目标注意力机制是对传统注意力机制的改进,能够从多个角度关注输入数据的关键特征。 注意力机制通过计算查询向量与键向量的相似度,为值向量分配不同的权重,实现对重要信息的关注。在恶意请求检测中,注意力机制能够帮助模型关注请求报文中的攻击代码部分。 多头注意力通过多个注意力头并行计算,从不同的子空间对输入数据进行特征提取。不同的注意力头能够学习到不同的特征模式,提高模型的表达能力。 目标引导注意力机制将分类目标信息融入注意力计算过程,使模型更关注与分类任务相关的特征。在恶意请求检测中,这种方法能够使模型更有效地识别与攻击相关的特征模式。
核心代码介绍
多维特征融合模型实现
基于TextCNN的字段特征提取器。首先,通过嵌入层将字符索引转换为低维向量表示;然后,使用多个不同尺寸的卷积核提取不同长度的字符组合特征;最后,通过最大池化和特征拼接,得到字段的特征向量。该模块能够有效捕获HTTP请求报文字段中的局部特征模式,为后续的恶意请求检测提供重要的特征支持。以下是多维特征融合模型的核心代码实现,主要包括特征提取和双分支分类网络:
python
# 字段特征提取模块
class FieldFeatureExtractor(nn.Module):
def __init__(self, vocab_size, embedding_dim, kernel_sizes, num_filters):
super(FieldFeatureExtractor, self).__init__()
# 字符嵌入层
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# TextCNN卷积层
self.convs = nn.ModuleList([
nn.Conv2d(1, num_filters, (k, embedding_dim)) for k in kernel_sizes
])
# Dropout层防止过拟合
self.dropout = nn.Dropout(0.5)
def forward(self, x):
# x shape: [batch_size, seq_len]
embedded = self.embedding(x) # [batch_size, seq_len, embedding_dim]
embedded = embedded.unsqueeze(1) # [batch_size, 1, seq_len, embedding_dim]
# 多尺寸卷积提取特征
conved = [F.relu(conv(embedded)).squeeze(3) for conv in self.convs]
pooled = [F.max_pool1d(conv, conv.size(2)).squeeze(2) for conv in conved]
# 特征拼接
cat = self.dropout(torch.cat(pooled, dim=1))
return cat注意力机制的特征融合实现
基于注意力机制的特征融合模块。该模块首先计算每个字段特征的注意力权重,权重的大小反映了该字段对恶意请求检测的重要程度;然后,根据注意力权重对各字段特征进行加权求和,得到融合后的特征向量。通过这种方式,模型能够自动学习各字段特征的重要性,实现自适应的特征融合,提高恶意请求检测的准确性。以下是基于注意力机制的特征融合模块的核心代码实现:
python
# 基于注意力机制的特征融合模块
class AttentionFusion(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(AttentionFusion, self).__init__()
# 注意力计算层
self.attention = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.Tanh(),
nn.Linear(hidden_dim, 1)
)
def forward(self, field_features):
# field_features: [num_fields, batch_size, feature_dim]
num_fields = len(field_features)
batch_size = field_features[0].size(0)
feature_dim = field_features[0].size(1)
# 计算每个字段的注意力权重
weights = []
for i in range(num_fields):
weight = self.attention(field_features[i]) # [batch_size, 1]
weights.append(weight)
# 权重归一化
weights = torch.cat(weights, dim=1) # [batch_size, num_fields]
weights = F.softmax(weights, dim=1).unsqueeze(2) # [batch_size, num_fields, 1]
# 特征融合
field_features = torch.stack(field_features, dim=1) # [batch_size, num_fields, feature_dim]
fused_feature = torch.sum(weights * field_features, dim=1) # [batch_size, feature_dim]
return fused_feature自监督预训练模型实现
自监督预训练模型的核心结构。该模型基于Bert架构,包含两个主要的预训练任务:对比学习和掩码预测。对比学习通过投影头将Bert的输出映射到低维特征空间,用于计算样本间的相似度;掩码预测则通过预测头预测被掩盖的字符,使模型学习到请求报文的上下文信息。通过这两个预训练任务,模型能够从大规模无标签数据中学习到通用的特征表示,为后续的恶意请求检测任务提供高质量的特征输入。以下是基于对比学习和掩码判别的自监督预训练模型的核心代码实现:
python
# 自监督预训练模型
class SelfSupervisedPreTrainer(nn.Module):
def __init__(self, bert_model):
super(SelfSupervisedPreTrainer, self).__init__()
self.bert = bert_model
# 对比学习投影头
self.projector = nn.Sequential(
nn.Linear(768, 512),
nn.ReLU(),
nn.Linear(512, 256)
)
# 掩码预测头
self.mask_predictor = nn.Linear(768, bert_model.config.vocab_size)
def forward(self, input_ids, attention_mask, token_type_ids, mask_labels=None):
# Bert编码
outputs = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids
)
sequence_output = outputs[0]
pooled_output = outputs[1]
# 对比学习特征
contrastive_features = self.projector(pooled_output)
# 掩码预测
mask_logits = None
if mask_labels is not None:
mask_logits = self.mask_predictor(sequence_output)
return contrastive_features, mask_logits重难点和创新点
研究难点分析
在Web恶意请求检测研究中,我们面临以下几个主要难点:
-
特征提取的全面性挑战:传统的恶意请求检测方法通常仅针对URL字段进行特征提取,忽略了其他字段(如Cookie、User-Agent等)中蕴含的攻击特征。如何全面、有效地提取HTTP请求报文的多维度特征,是本研究的首要难点。
-
特征融合的有效性挑战:不同维度的特征(如字段特征和统计特征)在表征恶意请求时具有不同的特点和优势,如何将这些特征进行有效融合,充分发挥各类特征的作用,是本研究的另一个重要难点。
-
有标签数据不足的挑战:在实际网络环境中,人工标注大量的恶意请求数据十分困难,导致有标签数据严重不足。如何在有限的有标签数据条件下,训练出高性能的检测模型,是本研究面临的第三个主要难点。
主要创新点
针对上述研究难点,本研究提出了以下创新点:
-
多维特征提取策略:提出了一种从字段属性和统计属性两个维度对HTTP请求报文进行特征提取的策略。在字段属性方面,提取了传输参数、Cookie、User-Agent等多个关键字段的特征;在统计属性方面,提取了长度特征、数量特征、信息熵等多种统计特征。这种多维特征提取策略能够更全面地捕获恶意请求的攻击特征,提高检测的准确性。
-
基于注意力机制的特征融合方法:提出了一种基于注意力机制的特征融合方法,能够自动学习各字段特征和统计特征的重要性权重,实现自适应的特征融合。该方法通过动态调整各特征的权重,充分发挥不同特征在不同攻击场景下的优势,提高了特征融合的有效性。
-
双分支分类网络结构:设计了一种双分支结构的分类网络,分别处理字段融合特征和统计特征。两个分支通过全连接层进行特征映射,然后在输出层进行特征联合,实现对恶意请求的分类。这种网络结构能够有效平衡各类特征在分类过程中的贡献,提高模型的分类性能。
总结
本研究针对Web应用面临的恶意请求威胁,深入探讨了基于机器学习的恶意请求检测方法,主要工作和成果如下:
-
研究了Web恶意请求的特征表示方法:通过对HTTP请求报文结构和常见攻击手段的分析,提出了从字段属性和统计属性两个维度进行特征提取的策略。在字段属性方面,提取了传输参数、Cookie等多个关键字段的特征;在统计属性方面,提取了长度特征、数量特征等多种统计特征。这些特征能够全面、有效地表征恶意请求的攻击特征,为后续的检测任务奠定了基础。
-
提出了基于多维特征融合的恶意请求检测方法:设计了一种基于注意力机制的特征融合方法,能够自动学习各字段特征和统计特征的重要性权重,实现自适应的特征融合。同时,提出了一种双分支结构的分类网络,分别处理字段融合特征和统计特征,有效平衡了各类特征在分类过程中的贡献。
-
提出了基于自监督对比判别的恶意请求检测方法:针对有标签数据不足的场景,提出了一种基于对比学习和掩码判别的自监督预训练方法,能够从大规模无标签数据中学习通用的特征表示。同时,设计了一种基于BiLSTM和多头目标注意力机制的分类检测网络,能够有效提取请求报文的时序特征和关键信息。
本研究的成果对于提高Web应用的安全性具有重要意义。提出的多维特征融合方法和自监督对比判别方法,不仅能够有效检测已知类型的恶意请求,还具有较强的泛化能力,能够识别未知类型的恶意请求。这些方法可以应用于Web应用防火墙、入侵检测系统等安全产品中,为Web应用提供更加可靠的安全防护。
未来的研究工作可以从以下几个方面展开:一是进一步优化特征提取和融合方法,提高特征表示的有效性;二是探索更先进的深度学习模型,如Transformer等,用于恶意请求检测;三是研究模型的实时性优化方法,使其能够满足大规模Web应用的实时检测需求;四是将研究成果与实际应用场景相结合,开发实用的安全防护产品。
参考文献
1 JIN X, ZHANG Y, WANG L, et al. A novel web attack detection method based on recurrent neural networkJ. IEEE Access, 2023, 11: 45621-45632.
2 WANG Y, LIU X, ZHAO H. Web attack detection using convolutional neural network with attention mechanismJ. Computer Networks, 2022, 218: 109321.
3 YU Z, SUN L, ZHOU W, et al. A hybrid approach for web attack detection combining TextCNN and SVMJ. Journal of Network and Computer Applications, 2021, 185: 103021.
4 TANG K, LIU J, CHEN H, et al. Long short-term memory for SQL injection attack detectionJ. Neural Computing and Applications, 2020, 32: 13849-13858.
5 LI D, ZHANG Q, WANG S, et al. A hybrid detection model based on LightGBM and CatBoost for web attacksJ. Information Sciences, 2022, 589: 710-725.