Transformer实战(26)------通过领域适应提升Transformer模型性能
0. 前言
我们已经使用经典 Tansformer 模型解决了许多任务,但我们可以通过利用特定的技术来进一步提高模型性能。有多种方法可以提升 Transformer 模型的性能,在节中,我们将介绍如何通过领域适应技术将模型性能提升到超越普通训练流程的水平。领域适应是一种提高 Transformer 模型性能的方法,由于大语言模型是在通用和多样化的文本上进行训练的,因此在应用于特定领域时,可能会存在一定的差异,我们可能需要根据特定的应用领域调整这些语言模型,并考虑多种因素。
1. 模型适应特定领域
尽管 Transformer 架构的微调方法通常表现良好,但源数据和目标数据分布的差异可能会显著影响微调的效果。如果源数据集和目标数据集存在较大差异,微调可能会面临困难,难以有效地学习。
研究表明,预训练的 Transformer 是处理词汇分布变化的最稳定架构,相比其他架构具有更强的泛化能力,但仍然存在改进空间,可以通过使用更多的领域内数据来提升效果。通过将模型专门化到目标数据上,我们期望提升其在下游任务中的表现。具体来说,就是使用目标数据进一步训练预训练模型,并期望该数据分布更接近目标分布。最终,我们将得到另一个版本的预训练模型(如 adapted-bert),该模型仍然需要进行微调才能应用于下游任务。下图总结了领域适应微调框架:
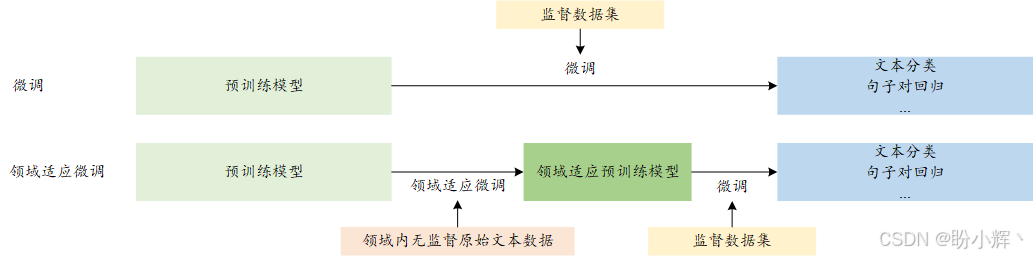
如上图所示,领域适应微调包括三个阶段,目标函数通常是掩码语言模型 (Masked Language Model, MLM)。在第一步,可以使用预训练的权重,这些预训练模型已经在大量数据上进行了训练,并且在其参数中编码了足够深的句法和语义知识,如 bert-base-uncased 和 roberta-large。因此,我们不需要从零开始预训练模型。
在第二阶段,预训练模型使用相同的源目标函数 MLM 进行训练,但使用目标(领域内)无监督数据集进行适应。需要注意的是,可以利用其他类型的辅助目标函数来改进适应效果。在此阶段,我们不会改变原始 BERT 模型架构的目标 (MLM),也不会增加任何额外的参数。经过这个过程后,我们将得到一个适应后的预训练权重,可以用于微调下游任务。
2. 领域适应实现
接下来,使用领域数据对 BERT 模型进行适应,然后进行微调,本节将使用 IMDB 数据集。
2.1 数据加载
(1) 首先定义 model_path 并加载分词器:
python
from transformers import BertTokenizerFast, BertForSequenceClassification
model_path= 'bert-base-uncased'
tokenizer = BertTokenizerFast.from_pretrained(model_path)(2) 加载包含 4000 训练集、1000 验证集和 1000 测试集的数据集,也可以将其扩展为整个数据集:
python
from datasets import load_dataset
imdb_train = load_dataset("imdb", split="train[:2000]+train[-2000:]")
imdb_test = load_dataset("imdb", split="test[:500]+test[-500:]")
imdb_val = load_dataset("imdb", split="test[500:1000]+test[-1000:-500]")
imdb_train.shape, imdb_test.shape, imdb_val.shape
# ((4000, 2), (1000, 2), (1000, 2))(3) 对数据集进行分词和编码,为训练做准备:
python
def tokenize_it(e):
return tokenizer(e["text"], padding=True, truncation=True)
enc_train = imdb_train.map(tokenize_it, batched=True, batch_size=1000)
enc_test = imdb_test.map(tokenize_it, batched=True, batch_size=1000)
enc_val = imdb_val.map(tokenize_it, batched=True, batch_size=1000)我们将使用所有可用训练数据集中的原始文本来适应 bert-base-uncased 模型,在此过程中不会使用监督方法。在此阶段,可以使用领域中的所有原始文本数据,仅使用 IMDB 训练数据集中的文本部分,而不使用标签。数据量对于良好的适应至关重要,因此,我们将使用所有训练数据进行适应。
2.2 领域适应训练
(1) 加载整个训练数据:
python
dataset_for_adaptation= load_dataset('imdb', split="train")
imdb_sentences=dataset_for_adaptation["text"]
train_sentences=imdb_sentences[:20000]
dev_sentences=imdb_sentences[20000:](2) 然后,加载模型:
python
from transformers import AutoModelForMaskedLM, AutoTokenizer
model = AutoModelForMaskedLM.from_pretrained(model_path)(3) 定义适应阶段的超参数:
python
batch_size = 16
num_train_epochs = 15
max_length = 100
mlm_prob = 0.25其中,将训练的 epoch 数设置得比正常的微调过程更大。另一方面,BERT 的原始 MLM 率值为 0.15,MLM 率是指输入词元中被掩码的百分比,研究证明该值如果在 15% 到 40% 之间会更高效。随着掩码词元数量的增加,模型能够提取出更强的表示,从而捕捉含义。在本节中,我们将 MLM 值设置为 0.25,可以根据 GPU 的容量增加最大长度值和批大小。
(4) 定义数据集类 TokenizedSentencesDataset():
python
class TokenizedSentencesDataset:
def __init__(self, sentences, tokenizer, max_length, cache_tokenization=False):
self.tokenizer = tokenizer
self.sentences = sentences
self.max_length = max_length
self.cache_tokenization = cache_tokenization
def __getitem__(self, item):
if not self.cache_tokenization:
return self.tokenizer(
self.sentences[item],
add_special_tokens=True,
truncation=True,
max_length=self.max_length,
return_special_tokens_mask=True,
)
if isinstance(self.sentences[item], str):
self.sentences[item] = self.tokenizer(
self.sentences[item],
add_special_tokens=True,
truncation=True,
max_length=self.max_length,
return_special_tokens_mask=True,
)
return self.sentences[item]
def __len__(self):
return len(self.sentences)(5) 对数据集进行分词:
python
train_dataset = TokenizedSentencesDataset(train_sentences, tokenizer, max_length)
dev_dataset = TokenizedSentencesDataset(dev_sentences, tokenizer, max_length)(6) 使用 Trainer 类来准备运行环境,将 mlm_prob = 0.25 传递给 DataCollator 对象:
python
from transformers import DataCollatorForLanguageModeling, TrainingArguments, Trainer
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=True, mlm_probability=mlm_prob
)
training_args = TrainingArguments(
output_dir='./model_file',
num_train_epochs=num_train_epochs,
evaluation_strategy="steps",
per_device_train_batch_size=batch_size,
prediction_loss_only=True,
fp16=True,
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=dev_dataset,
)(7) 进行领域适应训练:
python
trainer.train()训练过程输出如下:
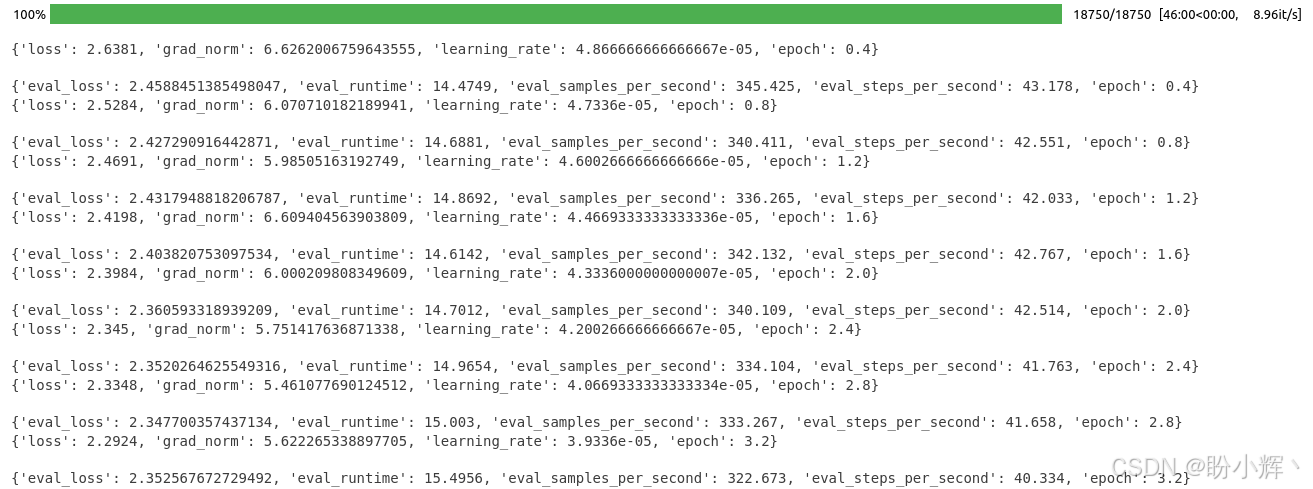
(8) 保存训练完成的领域适应模型,以便使用:
python
adapted_model_path="adapted-bert"
model.save_pretrained(adapted_model_path)
tokenizer.save_pretrained(adapted_model_path)2.3 微调领域适应预训练模型
现在,我们有两个预训练权重:
bert-base-uncased(原始BERT)adapted-bert(领域适应BERT)
(1) 接下来,注释掉原始 BERT,首先对领域适应 BERT 进行微调,然后通过交换注释的方式对原始 BERT 进行微调:
python
# model_path = "adapted-bert" # 1) Adapted model
model_path= "bert-base-uncased" # 2)vanilla bert
model = BertForSequenceClassification.from_pretrained(
model_path, id2label={0: "NEG", 1: "POS"}, label2id={"NEG": 0, "POS": 1}
)(2) 创建TrainingArguments和Trainer对象,并进行微调:
python
import pandas as pd
from sklearn.metrics import (accuracy_score, precision_recall_fscore_support)
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels,preds, average='macro')
acc = accuracy_score(labels, preds)
return {
'Accuracy': acc,
'F1': f1,
'Precision': precision,
'Recall': recall
}
training_args = TrainingArguments(output_dir='./bert-base-uncased',
do_train=True,
do_eval=True,
num_train_epochs=3,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
fp16=True,
load_best_model_at_end=True,
save_strategy='epoch',
eval_strategy='epoch')
trainer = Trainer(
model=model,
args=training_args,
train_dataset=enc_train,
eval_dataset=enc_val,
compute_metrics= compute_metrics)
trainer.train()
q=[trainer.evaluate(eval_dataset=data) for data in [enc_train, enc_val, enc_test]]
pd.DataFrame(q, index=["train","val","test"]).iloc[:,:5](3) 接下来,比较原始 BERT 和领域适应 BERT 微调的表现。原始 bert 微调的训练输出如下:

领域适应 bert 模型的训练输出如下:

如上图所示,领域适应后的模型在所有指标上都略优于原始 BERT 模型。我们以一种直接的方式解决了领域适应问题,除此之外,还有很多方法可以增强领域适应过程。常用的关于领域适应学习的技巧包括:
- 灾难性遗忘,灾难性遗忘可能导致训练模型的权重中大量信息的丢失。因此,如果遇到这种情况,需要保持较低的学习率值,并仔细监控验证损失值。如果忽视这些因素,可能会阻碍模型的改进
- 顺序训练策略,迁移学习策略具有顺序特性。因此,我们可以根据需要将这个训练步骤多次加入到训练流程中
- 领域适应与任务适应,我们已经通过使用领域特定的文本进行无监督的领域适应训练,然后使用特定任务目标进行了任务适应训练。我们可以在最后的微调之前,增加一些与当前任务相似的任务。例如,假设我们想解决医疗领域特定问答 (
Question Answering,QA) 任务。我们有常见的数据集,如PudMed文本、类似斯坦福问答数据集 (SQuAD) 的医患对话以及我们自己的医学QA任务。我们首先使用PudMed数据集对模型进行无监督的适应,然后使用医患数据集进行有监督的训练,最后训练我们的QA任务。这种顺序训练(领域适应和任务适应)可以提高模型性能 - 序列标注任务,假设我们要解决一个序列标注任务,比如在文本中检测敏感信息(如身份证、银行信息等)。由于命名实体识别 (Named Entity Recognition, NER) 任务任务是常见的序列标注任务,因此已经有许多为
NER任务训练的预训练权重。我们可以直接使用这些已经训练好的NER预训练权重,而不是使用bert-base,这也是顺序迁移学习方法的一个重要优势
小结
本节探讨了通过领域适应技术提升 Transformer 模型在特定任务中性能的方法。实验表明,在 IMDB 数据集上,经过领域适应的 BERT 模型相比原始 BERT 在情感分析任务中取得了全面提升。领域适应通过缩小预训练与目标领域的数据分布差异,显著提升了模型泛化能力。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类
Transformer实战(20)------微调Transformer语言模型进行问答任务
Transformer实战(21)------文本表示(Text Representation)
Transformer实战(22)------使用FLAIR进行语义相似性评估
Transformer实战(23)------使用SBERT进行文本聚类与语义搜索
Transformer实战(24)------通过数据增强提升Transformer模型性能
Transformer实战(25)------自动超参数优化提升Transformer模型性能