Numpy
用来存储和处理大型矩阵
NumPy重要功能如下:
- 高性能科学计算和数据分析的基础包
- ndarray,多维数组,具有矢量运算能力,快速、节省空间
- 矩阵运算,无需循环,可完成类似Matlab中的矢量运算
- 用于读写磁盘数据的工具以及用于操作内存映射文件的工具
Numpy 属性
py
import numpy as np
# 生成15个数据
arr = np.arange(15)
print(arr) # [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]转换成 3 行 5 列
py
# 转换
reshape = arr.reshape(3, 5)
print(reshape)
# [[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]]
print(f'数组的维度(轴):{reshape.ndim}') # 几维数组。轴就是几
print(f'数组的形状:{reshape.shape}') # 几行几列 (行数,列数)
print(f'数组的元素类型:{reshape.dtype}')# 整型
print(f'数组中每个元素所占字节数:{reshape.itemsize}') #int32 4字节 int64 8字节
print(f'数组中元素的个数:{reshape.size}') # 长度
print(f'数组的类型:{type(reshape)}') # <class 'numpy.ndarray'>
# 数组的维度(轴):2
# 数组的形状:(3, 5)
# 数组的元素类型:int64
# 数组中每个元素所占字节数:8
# 数组中元素的个数:15
# 数组的类型:<class 'numpy.ndarray'>创建 ndarray
NumPy数组是一个多维的数组对象(矩阵),称为ndarray,具有矢量算术运算能力和复杂的广播能力,并具有执行速度快和节省空间的特点。
注意:ndarray的下标从0开始,且数组里的所有元素必须是相同类型。
array 函数
py
import numpy as np
# 将普通数组转换成 numpy
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])指定字节类型,注意如果是小数,用的是整型,会直接砍掉,并不是四舍五入
py
array = np.array([1, 2, 3, 4, 5], dtype=np.int32)
print(f'数组的元素类型:{array.dtype}') # 整型
print(f'数组中每个元素所占字节数:{array.itemsize}') #int32 4字节 int64 8字节
print(f'数组的类型:{type(array)}') # <class 'numpy.ndarray'>arange 函数
包左不包右
py
import numpy as np
# 创建一个数组,从2到10,步长为2
array = np.arange(2, 10, 2)
print(array) # [2 4 6 8]random 随机数
random.rand
py
import numpy as np
# 随机数, 0-1, 3 行 4 列
array = np.random.rand(3, 4)
print(array)
# [[0.31049238 0.75832324 0.37506145 0.32252616]
# [0.38807463 0.93432297 0.17881305 0.88305402]
# [0.41024363 0.28271881 0.86731565 0.53035414]]random.randint 整数
py
import numpy as np
# 随机数, -1-4, 3 行 4 列
array = np.random.randint(-1, 5, size=(3, 4))
print(array)
# [[ 3 2 1 1]
# [ 3 4 3 -1]
# [ 1 0 3 0]]random.uniform 包含小数
py
import numpy as np
# 随机数, -1-4, 3 行 4 列,包含小数
array = np.random.uniform(-1, 5, size=(3, 4))
print(array)
# [[ 4.67745816 4.20730726 2.1148062 1.7430438 ]
# [ 4.13875101 3.95117814 -0.91604952 0.31978374]
# [ 2.18948176 2.99218651 4.02325524 2.29999013]]randn
生成正态分布,的浮点数,3行5列。
py
import numpy as np
f = np.random.randn(3, 5)
print(f)创建等比数列
logspace(起始次幂,结束次幂,数字个数, base=基数) -> 生成等比数列,默认基数是10,即:10的起始次幂 ~ 10的结束次幂,包左包右
需求:创建长度为 5 的等比数列,起始次幂为1,结束次幂为3
过程:会自动计算,每生成一个数字,加多少幂合适。中间会变,开始和结尾不会变。
py
import numpy as np
n = np.logspace(1, 3, 5, base=10)
print(n)
# [ 10. 31.6227766 100. 316.22776602 1000. ]创建等差数列
np.linspace(起始值,结束值,元素个数, endpoint=True)
生成指定范围内的等差数列,默认包左包右。
- endpoint:设置为false,可以不包右
py
import numpy as np
# 创建一个等差数列,从1开始,到10结束,共10个数,包右
n = np.linspace(1, 10, 10, endpoint=True)
print(n)
# [ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]数据类型转换
1. 把元素类型为 np.float64 -> np.int32
- zeros 创建用 0 填充的数组
- astype 用于将调用者转换成指定类型,返回
py
import numpy as np
# 生成 3行4列用0填充的数组,类型是float
zeros = np.zeros((3, 4), dtype=np.float64)
print(zeros)
# [[0. 0. 0. 0.]
# [0. 0. 0. 0.]
# [0. 0. 0. 0.]]
#
# 将zeros数组转换成整型
astype = zeros.astype(np.int32)
print(astype)
# [[0 0 0 0]
# [0 0 0 0]
# [0 0 0 0]]Numpy 内置函数
py
f = [[-0.30398695 0.39242509 0.83707249 -0.5360649 ]
[-0.10631079 -0.69037792 -0.47947986 -1.06188956]
[-0.45553133 -0.49964343 1.3645323 0.26271202]]根据上面的 f 进行函数运算。
py
import numpy as np
# 天花板数,向上取整
print(np.ceil(f))
# [[-0. 1. 1. -0.]
# [-0. -0. -0. -1.]
# [-0. -0. 2. 1.]]
# 地板数,向下取整
print(np.floor(f))
# [[-1. 0. 0. -1.]
# [-1. -1. -1. -2.]
# [-1. -1. 1. 0.]]
# 四舍五入
print(np.rint(f))
# [[-0. 0. 1. -1.]
# [-0. -1. -0. -1.]
# [-0. -0. 1. 0.]]
# 判断是否为空
print(np.isnan(f))
# [[False False False False]
# [False False False False]
# [False False False False]]
# 矩阵乘法
# 矩阵乘法的意思是,np.multiply() 会对数组 x 和 y 的每个对应位置的元素执行乘法运算。
print(np.multiply(f, f))
# [[0.09240807 0.15399745 0.70069035 0.28736557]
# [0.01130198 0.47662167 0.22990094 1.12760944]
# [0.20750879 0.24964356 1.8619484 0.0690176 ]]
# 矩阵除法
# 意思是,会对数组 x 和 y 的每个对应位置的元素执行除法运算。
print(np.divide(f, f))
# [[1. 1. 1. 1.]
# [1. 1. 1. 1.]
# [1. 1. 1. 1.]]
# 条件运算
print(np.where(f > 0, 1, 0))
# [[0 1 1 0]
# [0 0 0 0]
# [0 0 1 1]]统计函数
数据展示
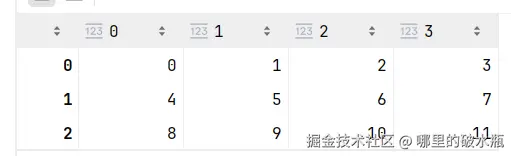
0 是列,1是行
py
# 创建3行4列数据
f = np.arange(12).reshape(3,4)
# 求所有的和
print(f.sum()) # 66
# 求每列的和
print(f.sum(axis=0)) # [12 15 18 21]
# 求每行的和
print(f.sum(axis=1)) # [ 6 22 38]
# 求累加和,会把数组转成一维数组,进行累加
print(f.cumsum()) # [ 0 1 3 6 10 15 21 28 36 45 55 66]
# 按列统计,第一列,0,4,8,结果就是,0+0,0+4,0+4+8
print(f.cumsum(axis=0))
# [[ 0 1 2 3]
# [ 4 6 8 10]
# [12 15 18 21]]
# 按行统计
print(f.cumsum(axis=1))
# [[ 0 1 3 6]
# [ 4 9 15 22]
# [ 8 17 27 38]]去重和排序
去重
我们创建了一个3行3列的数组,可以看到有很多重复的。通过unique执行了去重,发现变成一维数组了,并且不会影响arr的部分。
py
import numpy as np
arr = np.array([[1, 2, 1], [2, 3, 4], [3, 4, 5]])
# [[1 2 1]
# [2 3 4]
# [3 4 5]]
# 执行去重
print(np.unique(arr)) # [1 2 3 4 5]排序
不会影响原数组。
py
import numpy as np
arr = np.array([33, 11, 22, 66, 55])
print(arr) # [33 11 22 66 55]
print(np.sort(arr)) # [11 22 33 55 66]影响原数组
py
import numpy as np
arr = np.array([33, 11, 22, 66, 55])
arr.sort()
print(arr) # [11 22 33 55 66]矩阵运算
多维数组运算
相加,相减,相乘,相除
可以看到每一列相加了,必须是元素个数一一对应,如果A的数组是6个,B的数组必须是6个,如果不一致,会报错。多维也是一样的。
py
import numpy as np
arr = np.array([33, 11, 22, 66, 55])
print(arr)# [33 11 22 66 55]
a = np.arange(5)
print(a) # [0 1 2 3 4]
print(arr + a) # [33 12 24 69 59]矩阵乘法,矩阵A的行数 = 矩阵B的列数
将 A 的 1,2,3 这一行,去和 B 的 9,6,5 这一列,去逐个元素相乘,然后再逐个元素相加,等于 C 的第一个数字
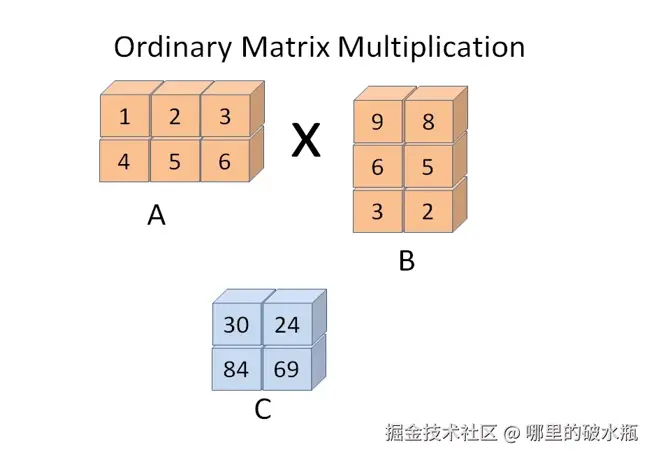

元素个数不一致也会报错。
py
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
print(arr)
# [[1 2 3]
# [4 5 6]]
a = np.array([[9, 8], [6, 5], [3, 2]])
print(a)
# [[9 8]
# [6 5]
# [3 2]]
print(arr.dot(a))
print(np.dot(arr, a)) # 结果和上面一样
# [[30 24]
# [84 69]]Pandas
Pandas 是 Python 的一个第三方包
Pandas在数据处理上具有独特的优势:
- 底层是基于Numpy构建的,所以运行速度特别的快
- 有专门的处理缺失数据的API
- 强大而灵活的分组、聚合、转换功能
适用场景:
- 数据量大到Excel严重卡顿,且又都是单机数据的时候,我们使用Pandas
- Pandas用于处理单机数据(小数据集(相对于大数据来说))
- 在大数据ETL数据仓库中,对数据进行清洗及处理的环节使用Pandas
不能处理 GB 以上的数据
读取 CSV 文件
配置一些参数
设置显示的最大行数和列数为None
pd.set_option('display.max_rows', None) pd.set_option('display.max_columns', None)
恢复显示的最大行数到默认值pd.reset_option('display.max_rows') # 恢复显示的最大列数到默认值 pd.reset_option('display.max_columns')
恢复所有选项到默认值 pd.reset_option('all')
开始
首先要确保工作路径,可以通过 os.getcwd() 获取工作目录,使用 os.chdir(r'E:\') 修改路径。因为每次都会默认到用户路径下。
如果编码是不正确的,会直接抛出异常,默认会打印所有。
py
# 导入
import pandas as pd
# 加载路径下的文件,并指定编码
csv = pd.read_csv('./1960-2019全球GDP数据.csv', encoding='gbk')
# print(csv)
head = csv.head() # 查看前 5 行
head = csv.head(10) # 查看前 10 行曲线生成 / 数据检索
需求:检索出中国,按照年份查看(并且将年份设置为行)
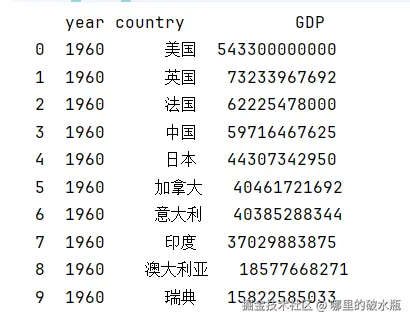
注意 Pandas 绘制图需要的是 matplotlib,pip install matplotlib
在设置索引的时候,inplace 表示的是否在原数据进行修改,默认false
GDP 是表中的字段,表示绘制那一列。
py
import pandas as pd
csv = pd.read_csv('./1960-2019全球GDP数据.csv', encoding='gbk')
# 获取中国数据
s = csv[csv.country == '中国']
# 设置行列
s.set_index('year', inplace=True)
# 绘制 GDP 折线图
s.GDP.plot()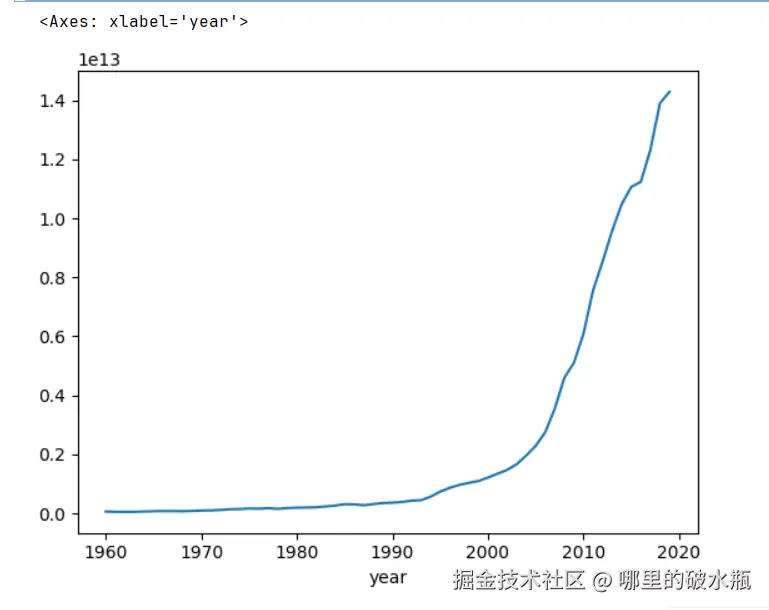
前面是一个图一个折现,如果是多个呢
注意:只能通过 s.GDP.plot() 这种方式去绘制,当多个字段一样时,自动合并
有个坑:inplace=True 表示 原地修改 DataFrame,这样就不能链式调用了。
那如果想修改颜色呢,和加上图例呢。注意,图例的名称默认是行名。比如GDP就是GDP,通过 color 和 legend,通过 label 属性呢,设置图例的名称。
显示出来了,但是我们发现,中文是乱码啊,这是因为 matplotlib 是 UTF-8的。
py
import pandas as pd
csv = pd.read_csv('./1960-2019全球GDP数据.csv', encoding='gbk')
# 获取中国数据
s = csv[csv.country == '中国'].set_index('year')
# 获取日本数据
j = csv[csv.country == '日本'].set_index('year')
# 获取美国数据
u = csv[csv.country == '美国'].set_index('year')
s.GDP.plot(color='red', legend=True, label='中国')
j.GDP.plot(color='gray', legend=True, label='日本')
u.GDP.plot(color='blue', legend=True, label='美国')修复乱码
py
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False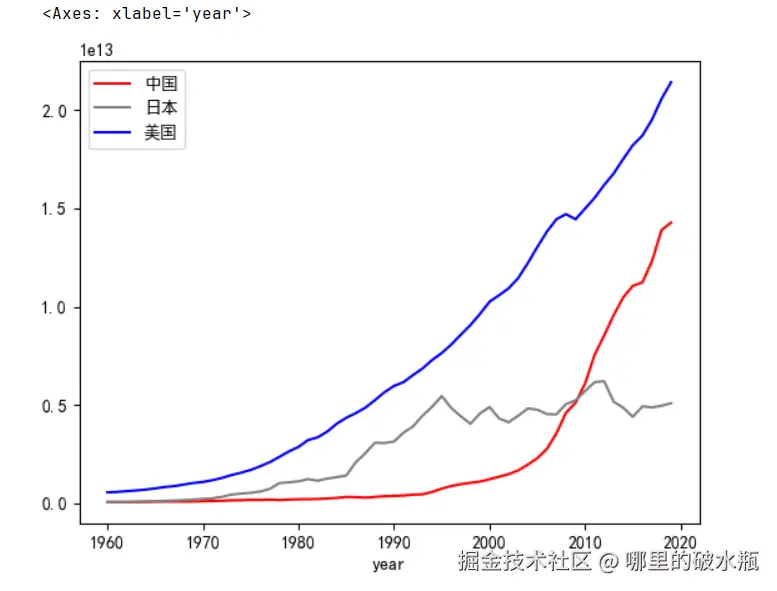
Pandas 数据结构
在 pandas 中没有行的概念。
看图中,其中,0,1,2,3,4,5~这一列是索引列
索引列的左侧还隐藏了一列,叫行索引列,看不到,但是有,无法修改。
year,country,GDP,这一行叫列名。
每一列都是一个 Series 对象
还隐藏了一个列的编号,下方图中,year的编号是0,country 是1,GDP 是2。
这一整个图,叫做DataFrame对象 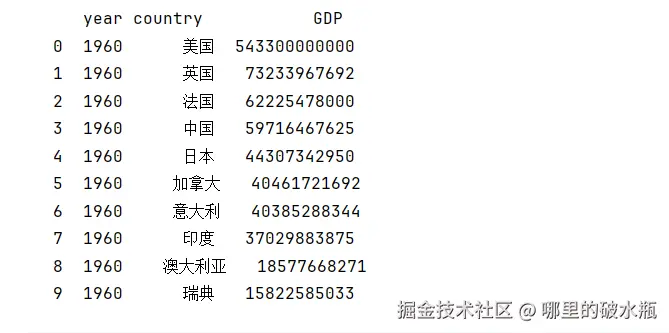
Series 对象的创建
Series也是Pandas中的最基本的数据结构对象,是 DataFrame 的列对象,series 本身也具有索引。
Series 是一种类似于一维数组的对象,由下面两个部分组成:
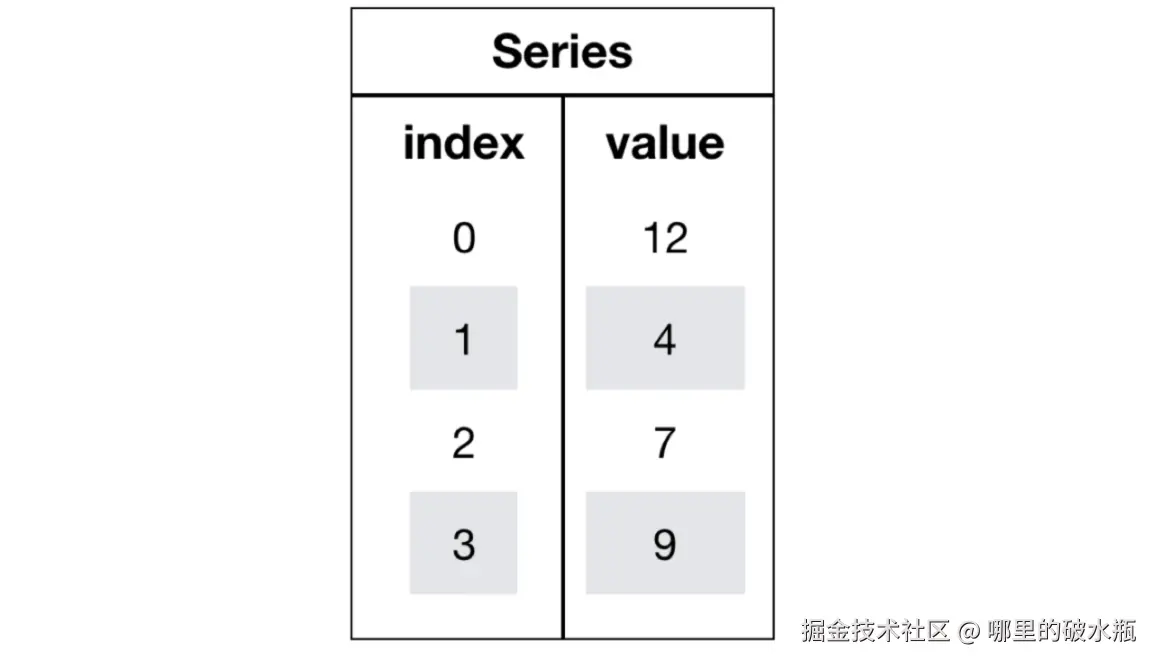
- 通过列表创建 series,使用 index 设置索引
py
import pandas as pd
series = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
print(series)
# a 1
# b 2
# c 3
# dtype: int64- 通过元组创建 series
py
import pandas as pd
s3 = pd.Series(('张三', '男', 23), index=['name', 'sex', 'age'])
print(s3)
# name 张三
# sex 男
# age 23
# dtype: object- 通过字典生成,默认key是索引,value是数据
py
import pandas as pd
s3 = pd.Series({'name': '张三', 'age': 18, 'sex': '男'})
print(s3)
# name 张三
# age 18
# sex 男
# dtype: object- 将 numpy 的 ndarray 对象转换成 series
py
import pandas as pd
import numpy as np
arange = np.arange(5)
s3 = pd.Series(arange)
print(s3)Series 的常用属性
- 我希望获取索引列
- 我希望获取数值列
- 我希望根据索引获取数据
py
import pandas as pd
s1 = pd.Series(data=[i for i in range(6)], index=[i for i in 'ABCDEF'])
print(s1)
# A 0
# B 1
# C 2
# D 3
# E 4
# F 5
# dtype: int64
# 索引列
print(s1.index)
# 数据列
print(s1.values)
# 根据索引D找值
print(s1['D'])DataFrame 对象
DataFrame是一个类似于二维数组或表格(如excel)的对象,既有行索引,又有列索引
- 行索引,表明不同行,横向索引,叫index,0轴,axis=0
- 列索引,表明不同列,纵向索引,叫columns,1轴,axis=1
除了之前用 csv文件读取获取 DataFrame 还有很多方式
- 创建 DataFrame 对象,字典 + 列表的方式
py
import pandas as pd
data_dict = {
'日期': ['2025-11-08', '2025-11-09', '2025-11-10'],
'温度': [5, 3, 4],
'湿度': [60, 70, 60]
}
# 把上面的数据字典转换成DataFrame
s1 = pd.DataFrame(data=data_dict, index=['A', 'B', 'C'])
print(s1)
# 日期 温度 湿度
# A 2025-11-08 5 60
# B 2025-11-09 3 70
# C 2025-11-10 4 60- 创建 DataFrame 对象,列表加元组的方式,不一定是元组,列表+列表也是可以的。
通过 columns 设置列名,通过index设置索引
py
import pandas as pd
data_dc = [
('2025-11-08', 5, 60),
('2025-11-09', 3, 70),
('2025-11-10', 4, 60)
]
s2 = pd.DataFrame(data=data_dc, columns=['日期', '温度', '湿度'], index=['A', 'B', 'C'])
print(s2)
# 日期 温度 湿度
# A 2025-11-08 5 60
# B 2025-11-09 3 70
# C 2025-11-10 4 60- 通过 numpy 创建
py
import pandas as pd
import numpy as np
s3 = pd.DataFrame(np.arange(9).reshape(3, 3))
print(s3)
# 0 1 2
# 0 0 1 2
# 1 3 4 5
# 2 6 7 8DataFrame 常用属性
py
import pandas as pd
import numpy as np
score = np.random.randint(40, 101, size=(10, 5))
score_df = pd.DataFrame(score)
# 赋值
score_df.columns = ['语文', '数学', '英语', '物理', '化学']
score_df.index = ['同学' + str(i) for i in range(10)]已有数据是
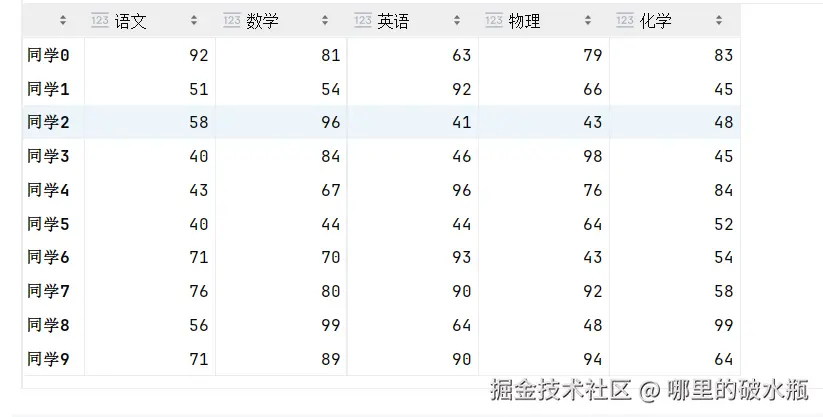
注意,打印的 dtype 虽然是 object,但是表示的意思是字符串,等于 str
py
# 获取形状
print(score_df.shape) # (10, 5)
# 获取索引
print(score_df.index) # Index(['同学0',....], dtype='object')
# 获取数据
print(score_df.values)
# [[92 81 63 79 83]
# ...
# [71 89 90 94 64]]
# 转换成 numpy
print(score_df.to_numpy())
# 行列,数据转换,之前是行的转成列,之前是列的转成行
print(score_df.T)
# 同学0 同学1 同学2 同学3 同学4 同学5 同学6 同学7 同学8 同学9
# 语文 92 51 58 40 43 40 71 76 56 71
# 数学 81 54 96 84 67 44 70 80 99 89
# 英语 63 92 41 46 96 44 93 90 64 90
# 物理 79 66 43 98 76 64 43 92 48 94
# 化学 83 45 48 45 84 52 54 58 99 64
# size 大小,统计的元素个数。只包含数据
print(score_df.size) # 50
# 获取数据类型
print(score_df.dtypes)
# 语文 int32
# 数学 int32
# 英语 int32
# 物理 int32
# 化学 int32
# dtype: object常用方法
已知数据 score_df
py
# 查看前5行
score_df.head()
# 查看前10行
score_df.head(10)
# 查看后5行
score_df.tail()
# 查看后10行
score_df.tail(10)获取方法的描述信息统计信息等
py
score_df.describe()| 行名 | 含义 | 示例解释(以"语文"为例) |
|---|---|---|
| count | 非空(有效)样本数 | 一共有 10 个学生的语文成绩 |
| mean | 平均值(算术平均数) | 平均语文成绩是 67 分 |
| std | 标准差(standard deviation) | 成绩的波动程度是 19.9,说明分数差距较大 |
| min | 最小值 | 语文最低分 41 |
| 25% | 第 1 四分位数(Q1) | 有 25% 的学生语文 ≤ 50.5 |
| 50% | 中位数(Q2) | 一半学生语文 ≤ 64,另一半 ≥ 64 |
| 75% | 第 3 四分位数(Q3) | 有 75% 的学生语文 ≤ 82.75 |
| max | 最大值 | 语文最高分 98 |
py
# 获取数据的描述性,详细信息
score_df.info()
# <class 'pandas.core.frame.DataFrame'>
# Index: 10 entries, 同学0 to 同学9
# Data columns (total 5 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 语文 10 non-null int32
# 1 数学 10 non-null int32
# 2 英语 10 non-null int32
# 3 物理 10 non-null int32
# 4 化学 10 non-null int32
# dtypes: int32(5)
# memory usage: 280.0+ bytes索引操作
已知数据是
新增一列,列名是 同学0,值全部是 stu
py
score_df['同学0'] = 'stu'
# 删除列,axis = 1 是列
score_df.drop('同学0', axis=1, inplace=True)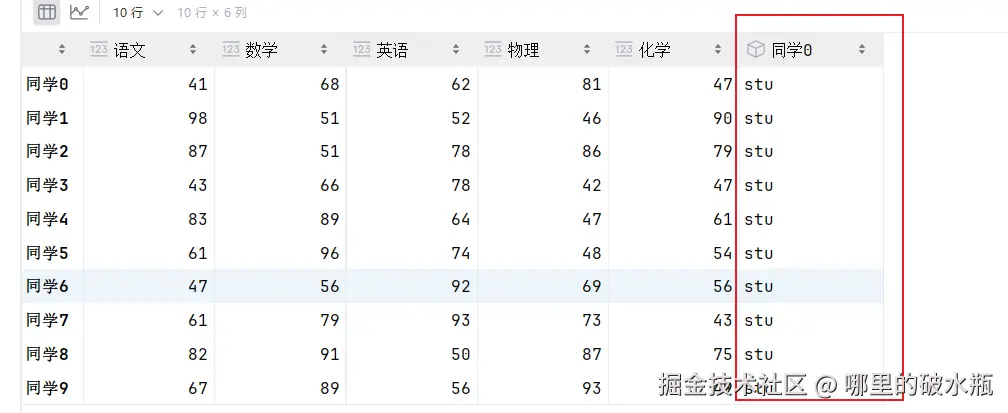
设置索引列
reset_index,可以被执行多次,但是执行多次有上限,会将 index 和 level0置顶过去。
py
# 设置
score_df.reset_index('month', drop=False, inplace=True)
# 取消设置索引列
score_df.reset_index(inplace=True)
# 设置多列索引
score_df.reset_index(['month', 'year'], drop=False, inplace=True)数据类型
| Pandas数据类型 | 说明 | 对应的Python类型 |
|---|---|---|
| Object | 字符串类型 | string |
| int | 整数类型 | int |
| float | 浮点数类型 | float |
| datetime | 日期时间类型 | datetime包中的datetime类型 |
| timedelta | 时间差类型 | datetime包中的timedelta类型 |
| category | 分类类型 | 无原生类型,可以自定义 |
| bool | 布尔类型 | bool(True,False) |
| nan | 空值类型 | None |
py
import pandas as pd
pd.to_datetime('2025-11-10')
# <class 'pandas._libs.tslibs.timestamps.Timestamp'>
pd.to_datetime(['2025-11-10', '2025-11-11', '2025-11-12'])
# DatetimeIndex(['2025-11-10', '2025-11-11', '2025-11-12'], dtype='datetime64[ns]', freq=None)计算时间间隔
py
import pandas as pd
start = pd.to_datetime('2025-11-10')
end = pd.to_datetime('2025-11-13')
result = end - start
print(result) # 3 days 00:00:00
print(type(result)) # <class 'pandas._libs.tslibs.timedeltas.Timedelta'>category 类型
此时有重复的数据。
打印结果为:
0 apple
1 pear
2 orange
3 apple
4 pear
dtype: object
加上 dtype = category,数据一样,但是打印的值类型是3个,减少了内存消耗,只存储唯一值。
0 apple
1 pear
2 orange
3 apple
4 pear
dtype: category
Categories (3, object): 'apple', 'orange', 'pear'
py
import pandas as pd
# f = pd.Series(['apple', 'pear', 'orange', 'apple', 'pear'])
f = pd.Series(['apple', 'pear', 'orange', 'apple', 'pear'], dtype='category')操作 pandas 数据
使用语法和 loc 获取
已知 sd 数据为
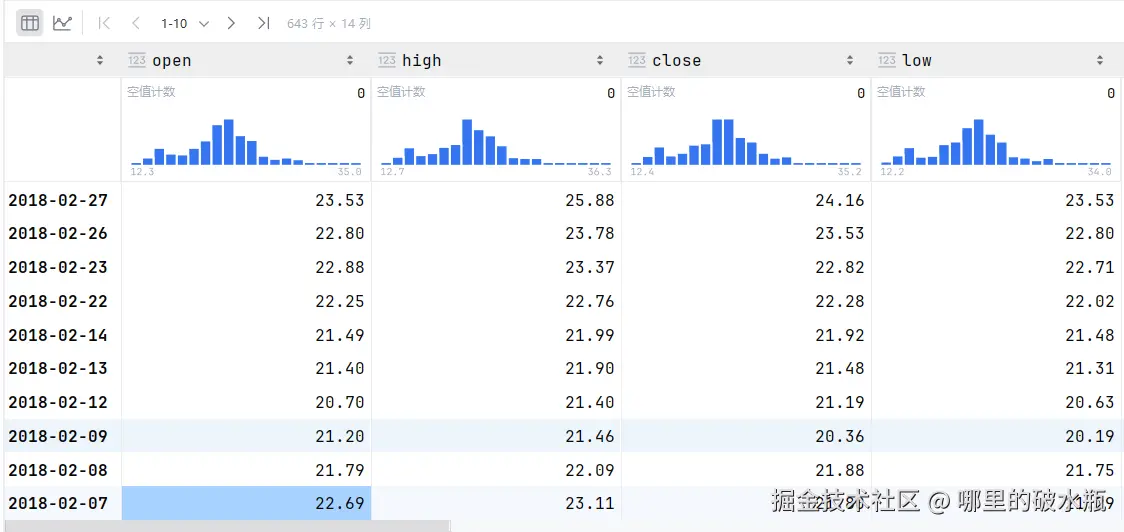
因为时间设置了索引,所以是按照时间排的,注意:必须是先列后行
py
# 获取 open 列
sd['open']
# 必须是5个,因为是5行,控制是否查看这一行。
sd.head(5)[[True, True, True, False, True]]
py
# 获取到具体的数据,语法:sd[列][行]
sd['open']['2018-02-23'] # 22.88
# 这也是获取的,只不过是先行后列,语法:sd.loc[行, 列]
sd.loc['2018-02-23', 'open']获取区间的数据,语法:loc开始:结束, 列名,不指定列,是所有列
py
sd.loc['2018-02-27':'2018-02-22', 'open']
# 获取多列
sd.loc['2018-02-27':'2018-02-22', ['open', 'high']]
# 写一个 : 号也是所有列
sd.loc['2018-02-27':'2018-02-22', :]
# 都不写,所有时间,所有列
sd.loc[:, :]使用 iloc 获取
iloc 是操作索引的
获取第指定行所有列
py
# 获取第 0 行所有
print(sd.iloc[0])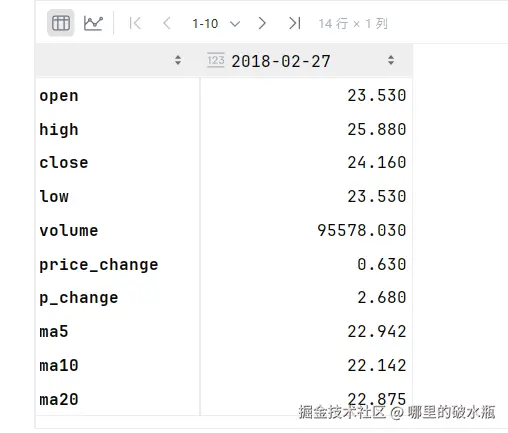
获取指定行的指定列
py
sd.iloc[0,0]区间查找
获取前四行数据,只要第0列。
py
sd.iloc[:4, 0]获取前四行,并且要第0~4列
py
sd.iloc[:4, 0:4]
# 获取前四行,所有列
sd.iloc[:4, :]
# 获取所有行所有列
sd.iloc[:, :]加上步长
py
# 从第1行到第5行,步长为2,获取2~5列
sd.iloc[1:5:2, 2:5]
py
# 查看第 0 行和第2行
sd.iloc[[0, 2]]删除、添加、修改
py
# 删除 axis = 1 的列,列名是ma20和ma10
sd.drop(['ma20', 'ma10'], axis=1)在进行修改的时候,可以直接使用列名进行赋值,如果存在则修改,不存在则添加
py
# 将open列的值设置为1
sd['open'] = 1
# 因为ai列没有,此时是新增
sd['ai'] = '333'
# 这样新增的时候,会每行进行计算,而不是每一列都是一个数据
sd['diff'] = sd['high'] - sd['low']细节:方括号里写列名和.列名,都是一样的,只是特殊内容,直接写出来,并不合规
排序
已知 sd 数据如下图
- ascending:等于 false 是降序排序
- 注意axis 只能是 0
py
# 默认是升序排序,指定列名
sd.sort_values('列名', ascending=False)
# 多列名排序
sd.sort_values(['列名', '列名'])
# 多列名排序,并单独指定排序规则
sd.sort_values(['列名', '列名'], ascending=[True, False])
# 根据索引排序,默认是True,升序
sd.sort_index(ascending=True)
# 这样也可以
sd.列名.sort_values()pandas 基础运算
已知 open 数据如下
基础运算符 +-*/ 都一样
py
# 临时数据,此时 s 的结果是open这一列 + 1的数据
s = open + 1
# 此时返回的 s 也是加 1 的
s = open.add(1)
# 修改原数据 + 1
open += 1
py
# 加法是 open,减法是 sub
open.sub(1)可以进行两个字段相计算。空用Nan填充
实现对整个DataFrame表加 1
已知整个表的数据为 sd
py
sd + 1pandas 逻辑运算
已知 sd 数据为
py
# 筛选出 open 的值大于 23 的
sd[sd.open > 23]
# 多条件判断方式一
sd[(sd.open >= 23) & (sd.open <= 24)]
sd[(sd['open'] >= 23) & (sd['open'] <= 24)]逻辑运算函数方式
- query:可以直接写表达式
- isin:等于比较
py
# 查询出来 open 的值在 23 和 24 之间
sd.query('open >= 23 & open <= 24')
# 查询出来 open 等于 23.8或者等于22.8
sd[(sd.open == 23.8) | (sd.open == 22.8)]
# query 方式
sd.query('open in [22.8, 23.8]')
# isin 方式
sd[sd.open.isin([22.8, 23.8])]统计函数
已知数据是
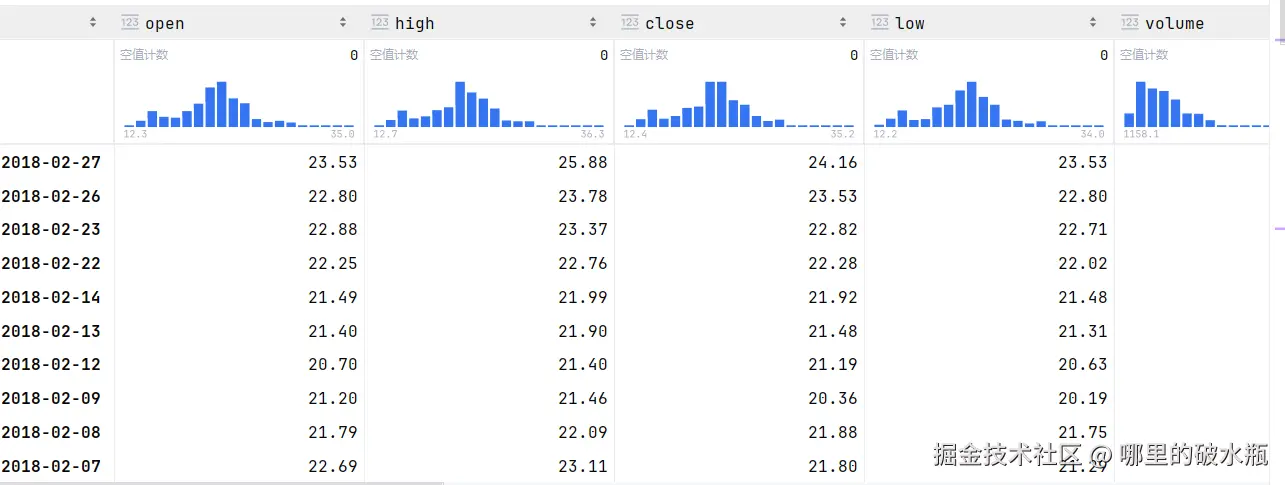
py
# 统计每列数据的总条数
sd.count()
sd.count(axis=0)
# 统计每行有多少列
sd.count(axis='columns')
# 统计每列有多少行
sd.count(axis='rows')
# 查看每列最大值
sd.max()
sd.max(0)
# 按行索引统计最大值
sd.max(1)
# 最小值 min
# 查看平均值
sd.mean()方差怎么算呢,每个值和平均值的差值。
每个值和 平均值的差的一个平方和的平均值。
标准差等于 方差开根号。
py
# 查看每列的标准差(std),方差(var)
sd.std()
sd.var()求中位数,将数据从小到大排序,取中间的那个数字,如果是偶数,取中间两个数字的平均值。
py
df = pd.DataFrame({
'col1': [2, 3, 4, 5, 4, 2], # 排序后:2,2,3,4,4,5
'col2': [0, 1, 2, 3, 4, 2] # 排序后:0,1,2,2,3,4
})
df.median()
# col1 3.5,3和4之间就是3.5
# col2 2.0 # 两个一样就是 2
# dtype: float64如果不是偶数,是奇数,直接取中间的数字
py
df = pd.DataFrame({
'col1': [2, 3, 4, 5, 4, 2, 10], # 排序后:2,2,3,4,4,5,10
'col2': [0, 1, 2, 3, 4, 2, 10] # 排序后:0,1,2,2,3,4,10
})
# 求中位数
df.median()
# col1 4.0
# col2 2.0
# dtype: float64
# 求最大值位置,找出行 索引
df.idxmax()
# df.idxmax(1) # 如果是1没有意义,求出来的是列名
# col1 6
# col2 6
# dtype: int64累加和函数
已知 sd 数据为
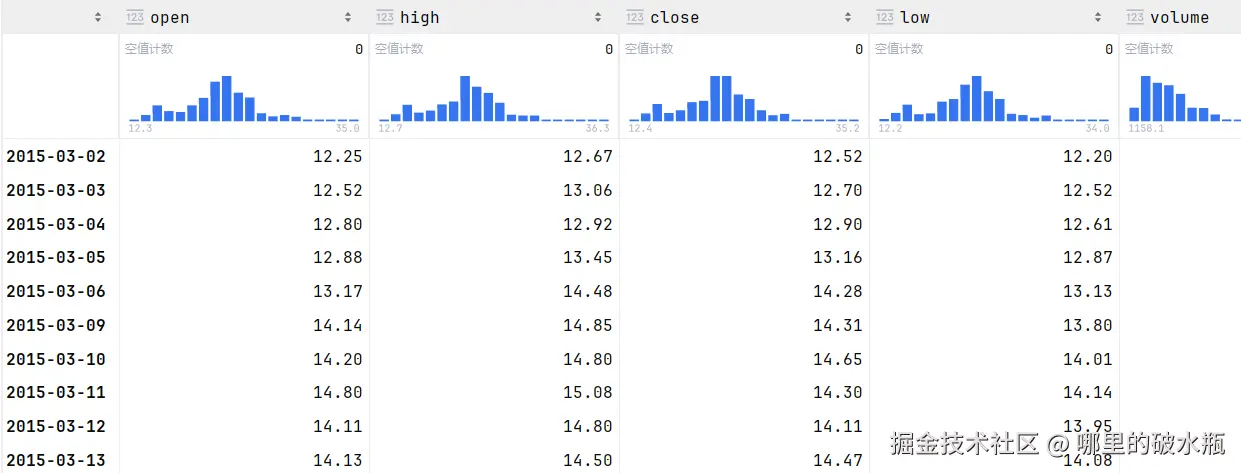
计算每列的累加和
py
# 求每列累加和
sd.cumsum()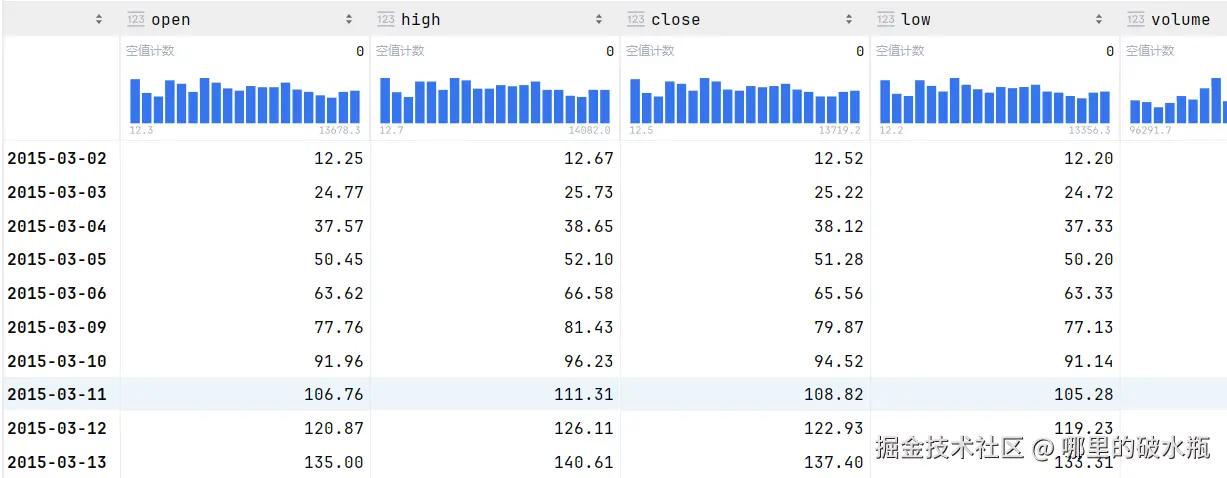
py
# 计算 open 列
sd.open.cumsum()
# 绘制所有列的可视化图
sd.cumsum().plot()apply 函数执行自定义函数
apply(函数对象,axis=0)
执行自定义函数,按行 1 或者 按列 0 传入数据。
py
# 求每行的最大值
sd.apply(lambda col: col.max(), axis=0)
# 求每行的最小值
sd.apply(lambda col: col.max(), axis=0)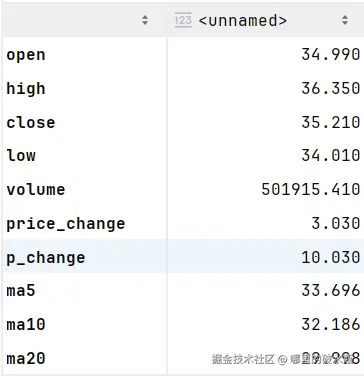
以行的方式传入
py
sd.apply(lambda row: row.max(), axis=1)读写文件
csv 是以逗号分隔,tsv 是以 Tab 分割。
读取 CSV
- index_col:设置索引列
py
# 读取所有列
sd = pd.read_csv('./stock_day.csv')
# 加载指定列
sd = pd.read_csv('./stock_day.csv', usecols=['high', 'low'])写入 csv
- index:是否将索引写入,默认True
- header:是否将表头写入,默认True
py
sd.to_csv('./testHead10.csv', index=True, header=True)读取 TSV
- columns:指定写出的列
- sep:按 \t 分割
- mode='a':表示追加
py
sd.to_csv('./testHead10.tsv', sep='\t', columns=['low'])读写 SQL
创建引擎对象
- mysql+pymysql:要操作的数据库,具体用的包
- root:123456:要操作的数据库的账号和密码
- localhost:3306:数据库的IP和端口
- my_project:数据库表
- charset:码表
py
# 导包
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/my_project?charset=utf8')
# Engine(mysql+pymysql://root:***@localhost:3306/my_project?charset=utf8)写入
- 参数一:导入的sql表名
- 参数二:连接对象
- 参数三:是否包含索引
- 参数四:导入模式(如果表名存在),fail/报错, replace/覆盖,append/追加
py
sd = pd.read_csv('./csv示例文件.csv', encoding='GBK', index_col=0)
sd.to_sql('person_info', engine, index=False, if_exists='replace')读入
- 参数一:sql语句
- 参数二:引擎对象
py
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/my_project?charset=utf8')
pd.read_sql('select * from person_info', engine)数据转JSON
- ensure_ascii:是否将中文转换为 ASCII 码
py
import json
# 创建一个字典
dict_data = {'name': '乔峰', 'age': 38, 'sex': '男'}
# 将字典转为JSON
json2 = json.dumps(dict_data, ensure_ascii=False)
# 将 JSON 转换为 字典
newDict = json.loads(json2)读取JSON文件
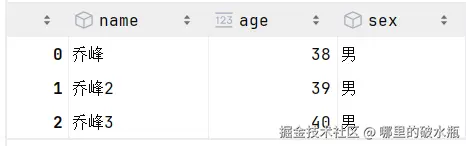
首先 json 文件是如下
json
{"name": "乔峰", "age": 38, "sex": "男"}
{"name": "乔峰2", "age": 39, "sex": "男"}
{"name": "乔峰3", "age": 40, "sex": "男"}- 参数一:是路径
- 参数二:是读取方式,表示每个对象是一行
- records:每个对象一行
- columns:以列为主
- index:以索引为主
- 参数三:是一行一行的读取
py
import pandas as pd
pd.read_json('./my.json', orient='records', lines=True)写入 JSON 文件
已知数据是
py
import pandas as pd
df.to_json('./my_to.json')
# 效果同上
df.to_json('./my_to.json', orient='columns')转换后是 
希望是按行读取,返回列表 orient='records'
py
import pandas as pd
df.to_json('./my_to.json', orient='records')
希望每个对象一行一行,而不是一个列表,lines = True
py
import pandas as pd
df.to_json('./my_to.json', orient='records', lines=True)
DateFrame 列操作
已知 sd 数据为
这些都会修改原始数据
增加 col1 列,值全是 2
py
sd['col1'] = 2增加col2 列,每列指定数据,这种方式,假设该 DataFrame,有五列,就只能指定 5 个,否则会报错
py
sd['col2'] = [1, 2, 3, 4, 5]还可以使用其他列计算
py
sd['col3'] = sd.year * 2不会修改原始数据的
py
# 添加一列 cole = 1
sd.assign(cole = 1)
sd.assign(cole = [1,2,3,4,5])
sd.assign(cole = sd.year * 2)使用 series 对象传入,如果行数对不齐,使用 NAN 填充
py
import pandas as pd
series = pd.Series(['段延庆', '王伟', '叶二娘', '王小虎'])
sd.assign(col = series)使用函数
py
def fun1(df):
# 返回索引
return df.index.values
sd.assign(col = fun1)一次添加多个列
py
sd.assign(
col=2, # 列1
col1=[1, 2, 3, 4, 5] # 列2
)删除
删除行
py
# 删除第 0 行,不会修改数据,这是根据索引
sd.drop([0])
# 效果同上
sd.drop([0], axis = 0)
# 删除多行
sd.drop([0, 1, 4])删除列
py
# 删除列
sd.drop(['year', 'col', 'col1'], axis=1)修改原数据,删除列
py
del sd['year']去重
dataframe 的去重
已知数据 sd 数据是 9930 行
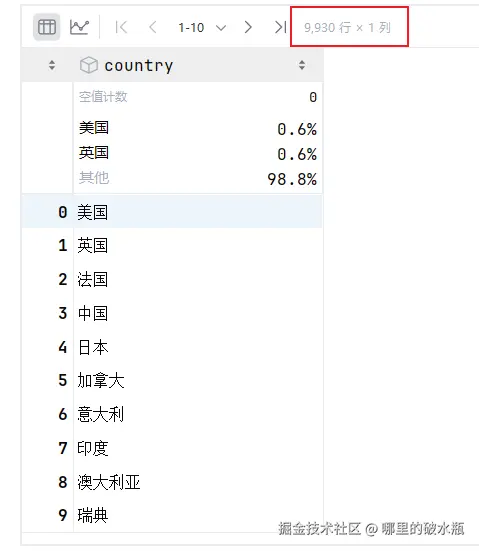
py
# 执行去重
sd.drop_duplicates()serires 的去重
假设有个 s 变量是series类型
py
# 去重
s.unique()
# 去重
s.drop_duplicates()修改
py
# 修改df5,的GDP列为 66,临时修改
df5.assign(GDP=66)
# 同上
df5['GDP'] = [5, 4, 3, 2, 1]replace 替换
py
# 将 sd2 的 year 字段的 1960 修改为 2025
sd2.year.replace(1960, 2025)
# 替换多个值,方式一
sd2.replace([1960, '日本', '中国'], [2025, '鬼子', '龙国'])
# 多个值,方式二
sd2.replace({1960: 2025, '日本': '鬼子', '中国': '龙国'})查询dataFrame中的数据
py
# 默认取前5行数据
df.head()
df.head(10) # 取前10行
# 默认取后5行数据
df.tail()
df.tail(15) # 倒数15行获取一列或多列数据
py
df['country']
df.country
df[['country', 'GDP']] # 返回新的df索引下标切片取行
格式:df[start:stop:step]
py
df[:3] # 取前3行
df[:5:2] # 取前5行,步长为2
df[1::3] # 取第2行到最后所有行,步长为3查找数据
py
df.query('country=="帕劳"')
df[df['country']=='帕劳']多条件查询
py
df.query('country=="中国" or country=="日本" or country=="美国"').query('year in ["2015", "2016", "2017", "2018", "2019"]')
df.query('(country=="中国" or country=="日本" or country=="美国") and year in ["2015", "2016", "2017", "2018", "2019"]')排序函数
已知 sd 数据为
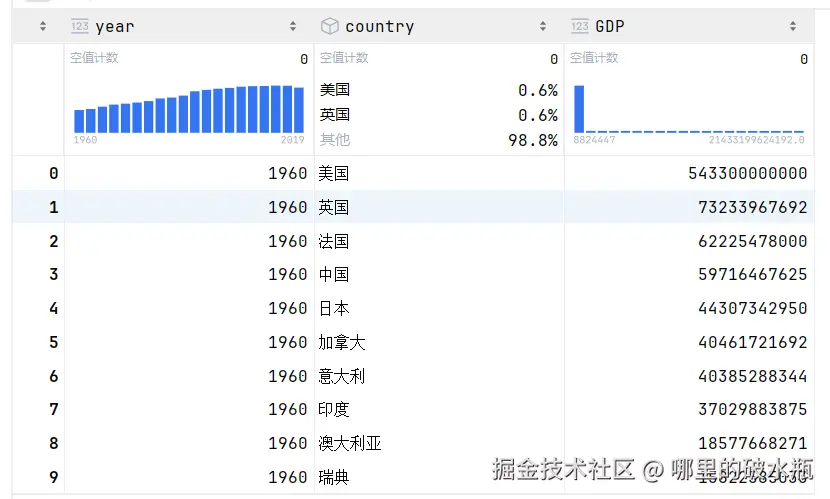
py
# 根据索引排序,默认升序, ascending 设置为false ,降序
sd.sort_index(ascending=False)
# 按照字段排序,默认升序,ascending 设置 False,降序
sd.sort_values('GDP', ascending=False)
# 如果year一样,按照GDP排序,降序排序
sd.sort_values(['year', 'GDP'], ascending=False)
# 如果year一样,按照GDP排序,year 是降序排序,GDP 是升序排序
sd.sort_values(['year', 'GDP'], ascending=[False, True])排名函数,rank
定义数据
py
df = pd.DataFrame({
'姓名': ['小明', '小美', '小强', '小兰'],
'成绩': [100, 90, 90, 80]
})
py
# 按照排名,降序排序,评分一致,取平均值
df.rank(ascending=False)
df.rank(ascending=False, method='average')
# 评分一致,取最小值
df.rank(ascending=False, method='min')
# 评分一致,取最大值
df.rank(ascending=False, method='max')
# 评分一致,数值相同,完全等价于SQL中的dense_rank(),完全等于 min函数
df.rank(ascending=False, method='dense')缺失值处理
已知 sd 数据为
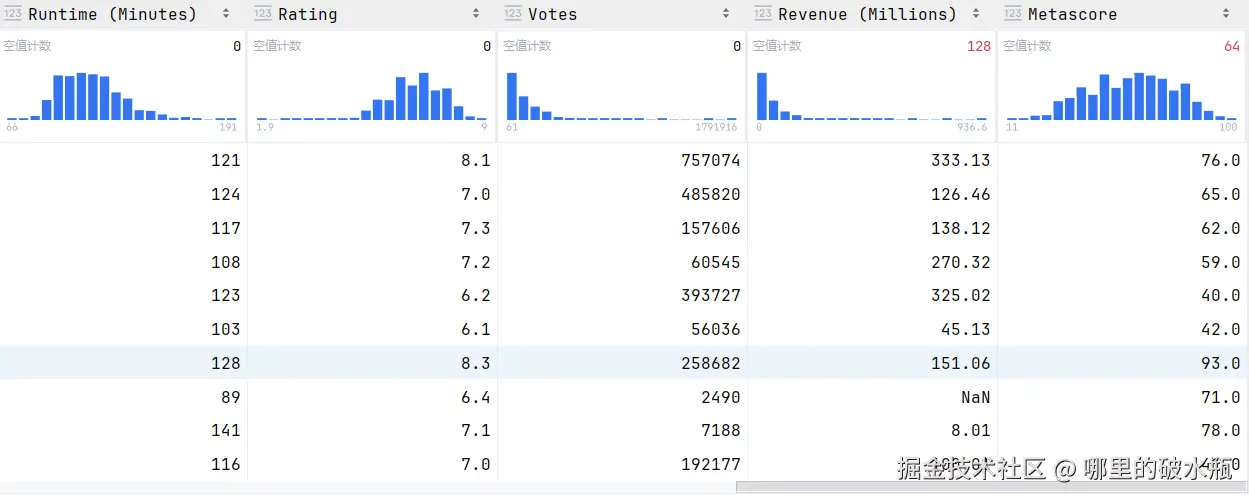
查看信息
py
sd.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 1000 entries, 0 to 999 # 有 0 ~ 999 行数据
# Data columns (total 12 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 Rank 1000 non-null int64
# 1 Title 1000 non-null object
# 2 Genre 1000 non-null object
# 3 Description 1000 non-null object
# 4 Director 1000 non-null object
# 5 Actors 1000 non-null object
# 6 Year 1000 non-null int64
# 7 Runtime (Minutes) 1000 non-null int64
# 8 Rating 1000 non-null float64
# 9 Votes 1000 non-null int64
# 10 Revenue (Millions) 872 non-null float64 # 872行非空
# 11 Metascore 936 non-null float64 # 936行非空
# dtypes: float64(3), int64(4), object(5)
# memory usage: 93.9+ KB判断缺失值
py
import pandas as pd
import numpy as np
# 打印的列表有 true 的就是空值
sd.isnull()
# 打印的列表有 true 的是非空值
sd.notnull()
# 打印缺失值的个数
sd.isnull().sum()
# 打印非缺失值的个数
sd.notnull().sum()
# 使用 numpy 的all方法,判断是否全部不为空,有一个就 false
np.all(sd.notnull())删除缺失值
比如,A 字段 和 B 字段,B字段为空,那么即使A字段不为空,也会删除。
但是索引会留下,比如删除了 8 行,那么 9 索引不会往前靠。
py
# 删除行
sd.dropna()
# 删除列
sd.dropna(axis=1)填充缺失值
根据平均值,填充所有列。
py
# 计算平均值
avg = sd['Revenue (Millions)'].mean()
# 执行填充
sd.fillna(avg, inplace=True)循环遍历,是否存在缺失值,用每列的平均值填充每列
py
for col_name in sd:
# 判断是否存在缺失值
if sd[col_name].isnull().sum() > 0:
# 计算每列平均值
mean_value = sd[col_name].mean()
# 填充给每列
sd[col_name] = sd[col_name].fillna(mean_value)如果表示空的不是NaN呢,那该怎么处理
已知数据集中使用的是 ? 号作为空值,处理逻辑是:先进行更换成 nan,再进行删除
py
# 加载数据
wis = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data")
# 将问号替换为空
wis.replace('?', np.nan, inplace=True)
# 进行删除
wis.dropna(inplace=True)数据合并
concat 可以合并多个 DataFrame 对象,可以行也可以列合并
已知数据如下
py
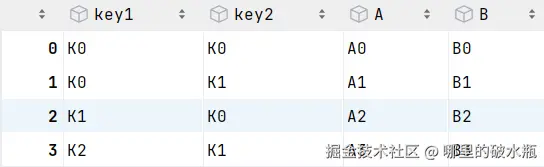
import pandas as pd
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
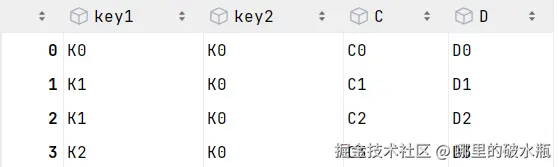
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})left
right
合并结果
- 列名一样,列合并
- 列名不一样,行合并
- 默认是纵向合并
py
import pandas as pd
pd.concat([left, right])
# 同上
# pd.concat([left, right], axis=0)上述会发现,索引居然出现了重复,去除索引重复,忽略索引
py
pd.concat([left, right], axis=0, ignore_index=True)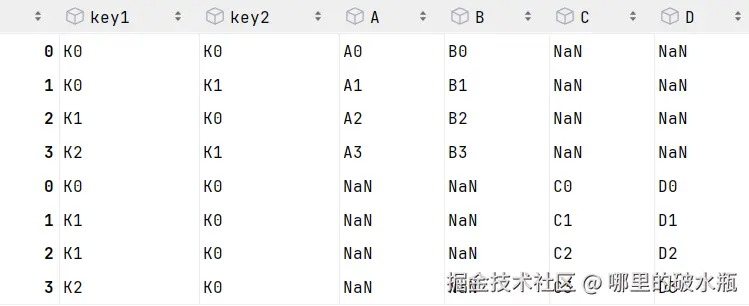
列合并呢,直接往后面堆叠就可以,但是会参考行索引
py
import pandas as pd
pd.concat([left, right], axis=1)
行索引不一致演示,会使用空填充
py
import pandas as pd
pd.concat([left, right], axis=1)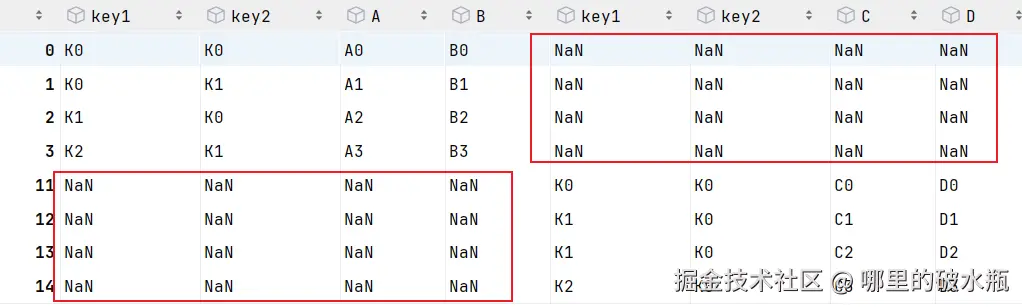
merge
只能两个两个合并
- 参数1:第一个df对象
- 参数2:第二个df对象
- 参数3:how 连接方式
- left 左外连接,
- right 右外连接
- inner 内连接
- outer 全连接,满外连接
- 参数4:on 关联字段,表示参考谁合并
左外连接
py
import pandas as pd
pd.merge(left, right, how='left', on=['key1'])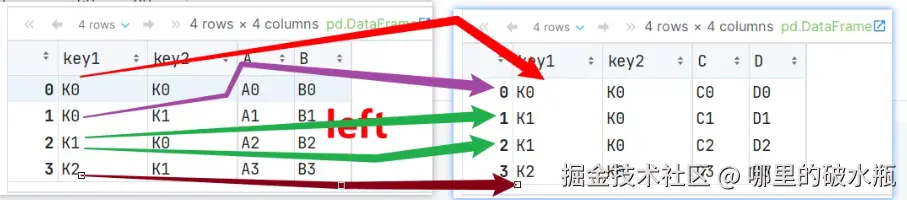
结果
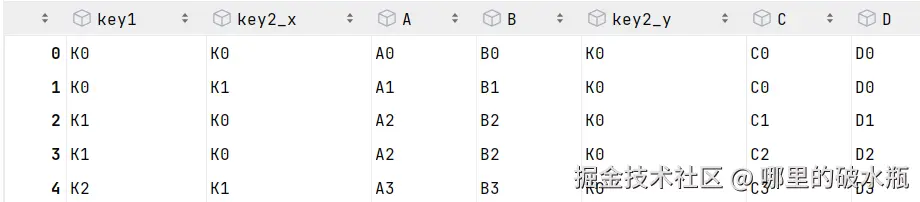
右连接
也是按照右表,去一一的找,找不到就丢弃左表的。
py
import pandas as pd
pd.merge(left, right, how='right', on=['key1', 'key2'])内连接,基于左右表全有
py
pd.merge(left, right, how='inner', on=['key1', 'key2'])全连接
会基于左表的全部和右表的全部
py
pd.merge(left, right, how='outer', on=['key1', 'key2'])