在今年云栖大会上,EMR Serverless Stella 1.0正式发布,这是一款面向企业级场景深度优化的高性能数据分析引擎。阿里云开源大数据平台OLAP引擎负责人周康系统性地分享了 Stella 在存算分离架构、Lakehouse 场景以及全文检索等三大核心场景下的深度优化经验,为业界提供了大规模 OLAP 系统工程化实践的宝贵参考。Stella引擎的发布将为企业级用户提供更加专业、高效的OLAP解决方案。
站在巨人肩膀上:与 StarRocks 开源社区的深度合作
阿里云与StarRocks开源社区的合作可以追溯到2021年,从开源第一天起就建立了深度合作关系。在过去四年中,双方在源码共创、产品发布和技术优化方面积累了丰富的经验。
合作历程回顾:
- 2021年:开启源码共创,重点推动数据湖分析相关框架和性能优化
- 2022年3月:推出EMR半托管StarRocks形态
- 2023年:响应市场需求,推出全托管产品形态
- 2024年:正式商业化存算分离版本
随着产品的成熟,阿里云EMR已积累数百家B端企业客户。"我们始终站在巨人的肩膀上,"阿里云开源大数据平台OLAP引擎负责人周康表示,"Stella 所有功能和优化都会逐步回馈给社区,同时确保API层面与开源版本完全兼容。" 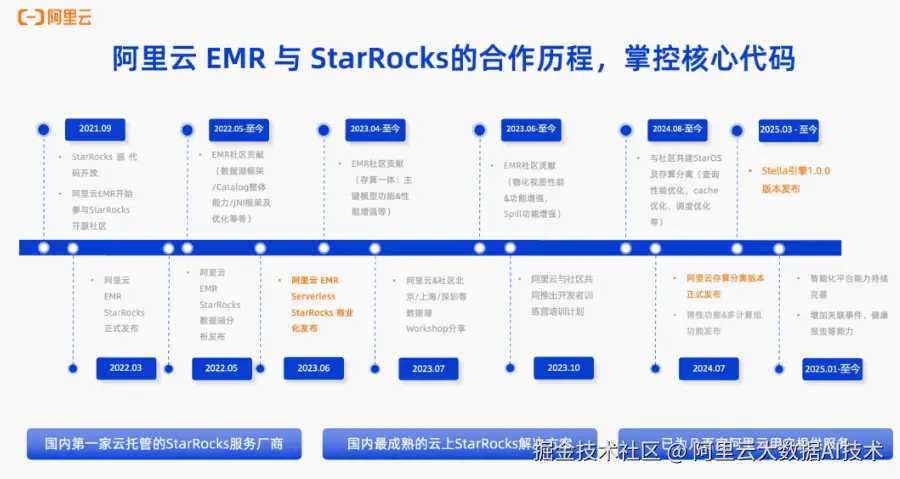
Lakehouse 成为业界共识:Stella 应运而生
2024年,阿里云正式发布 OpenLake 方案,标志着 Lakehouse 架构在数据基础设施领域的全面落地:  2024云栖大会重磅发布OpenLake解決方案,StarRocks 为 OLAP场景核心组件
2024云栖大会重磅发布OpenLake解決方案,StarRocks 为 OLAP场景核心组件
伴随这一趋势,Lakehouse(数据湖仓一体)已成为国内外头部公司的业界共识: 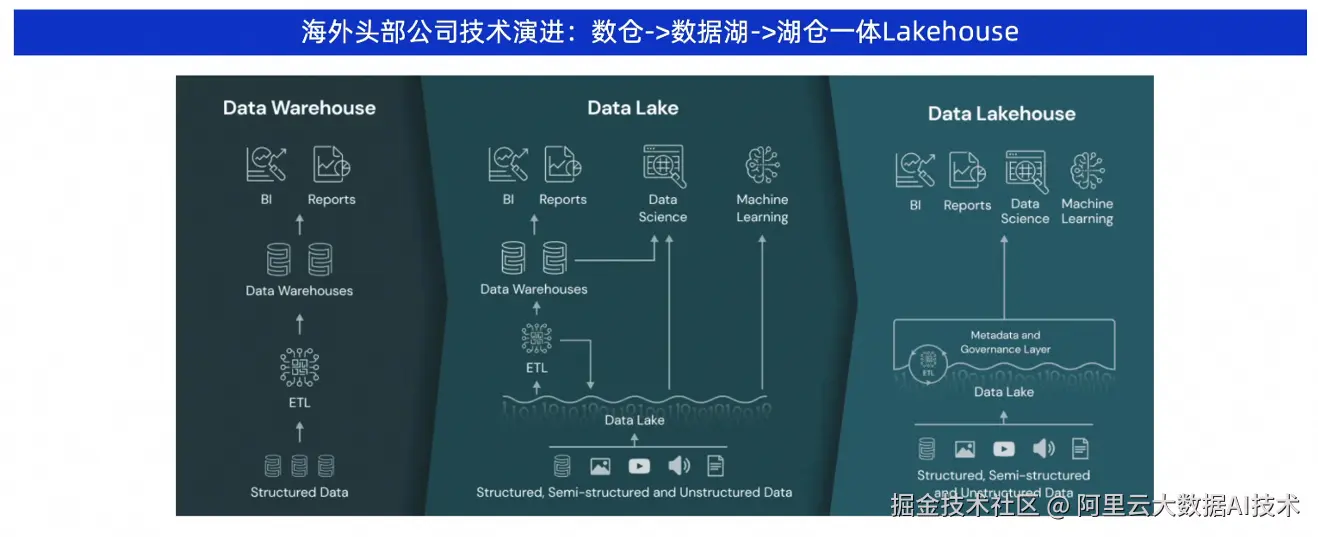
海外Lakehouse发展趋势 Snowflake/Databricks/BigQuery + Iceberg/Delta/Hudi
阿里云推出了 OpenLake 一体化湖仓解决方案,StarRocks 在其中担任核心 OLAP 引擎角色。然而,在大规模生产环境中,StarRocks 在存算分离架构和湖表查询方面仍有优化空间。Stella 项目正是为了应对这些挑战而生。通过在调度、查询优化、执行引擎和存储引擎四个层面的全面改进,Stella 1.0 针对几十 TB 甚至 PB 级数据场景,解决了事务机制、Compaction 效率、查询性能、元数据管理等一系列生产环境痛点。
Stella 1.0 三大核心场景突破
EMR Serverless Stella 1.0版本于今年5月正式发布,主要聚焦三大核心技术能力的重大突破:
一、存算分离:性能和稳定性大幅提升
Stella 1.0 在存算分离架构下实现了三大突破:
1. 冷查性能大幅提升
- 实现 IO 合并,减少对象存储访问次数
- 优化 Compaction 调度器,大幅减少小文件数量
- 针对轻量级 ETL 场景优化负载调度
2. 写入性能保障
- 开发 Batch Publish 能力,解决串行化导入瓶颈
- 推出 Collocated PK Index,避免缓存盘和索引盘互相影响
- 优化 FE 侧 Tablet 创建删除效率
3. 缓存利用率优化
- 引入 Index Cache 和 Meta Data Cache,提升元数据访问速度
- 实现自适应 IO Stream,智能选择本地缓存或远端访问
- 针对 ETL 场景优化空间利用
在TPC-H 10T基准测试中,存算分离版本的Stella相比上一版本性能提升超过120% ,充分展现了云原生架构的技术优势。 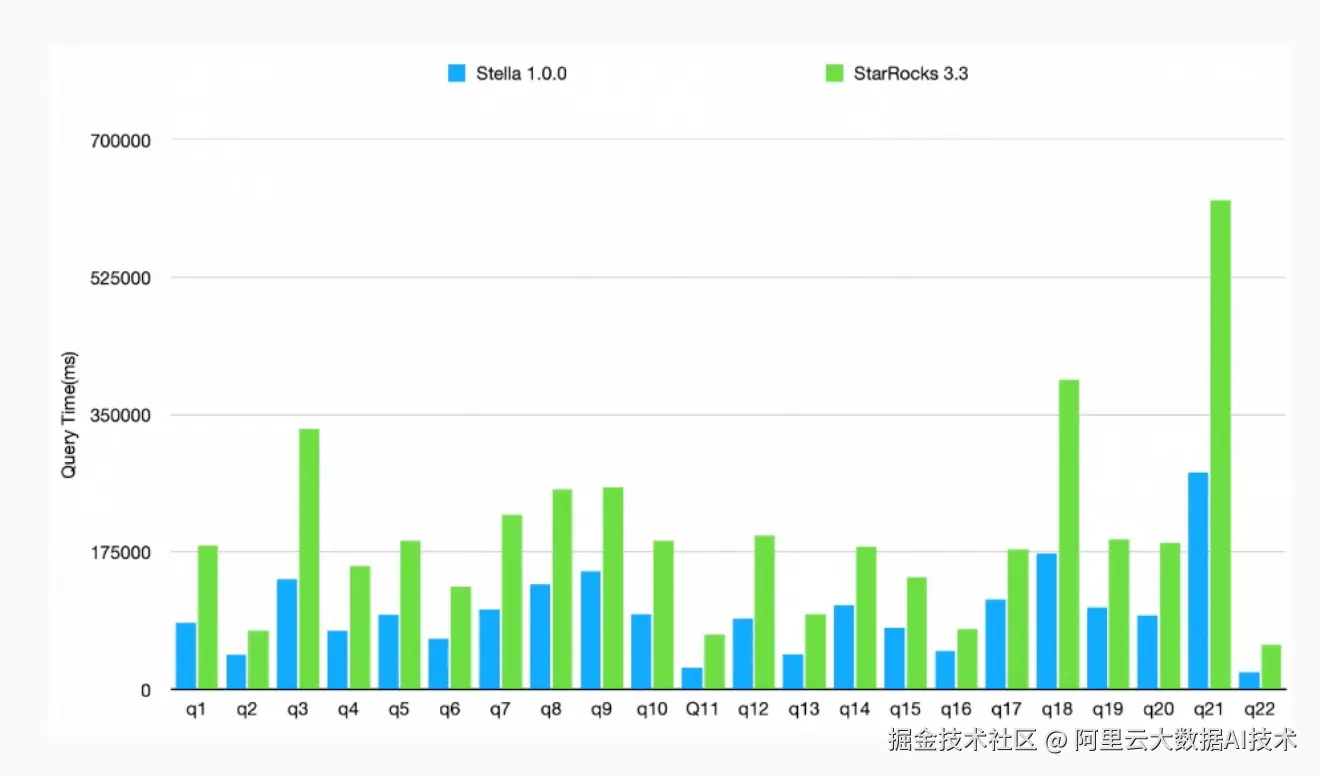
二、Paimon 湖表查询:Co-design 驱动性能飞跃
Stella 1.0在Paimon表分析方面,重点聚焦在三个方向的提升:
1. 数据读写效率提升
- 实现自适应 Batch Size 优化
- 支持Native Paimon Writer,性能大幅提升
2. 元数据访问优化
- 针对 Manifest 数量众多场景,实现分布式解析能力
- 适配异步 Splits 调度框架
- 优化 Manifest Cache 策略
3. 深度集成阿里云 DLF 2.x
- 与 Data Lake Formation 产品深度整合
- 借助 DLF 能力提升 Paimon 查询和写入的性能与稳定性
- 针对DV表实现Native读取优化
Stella在Lakehouse场景下查询Paimon下性能的提升非常明显: 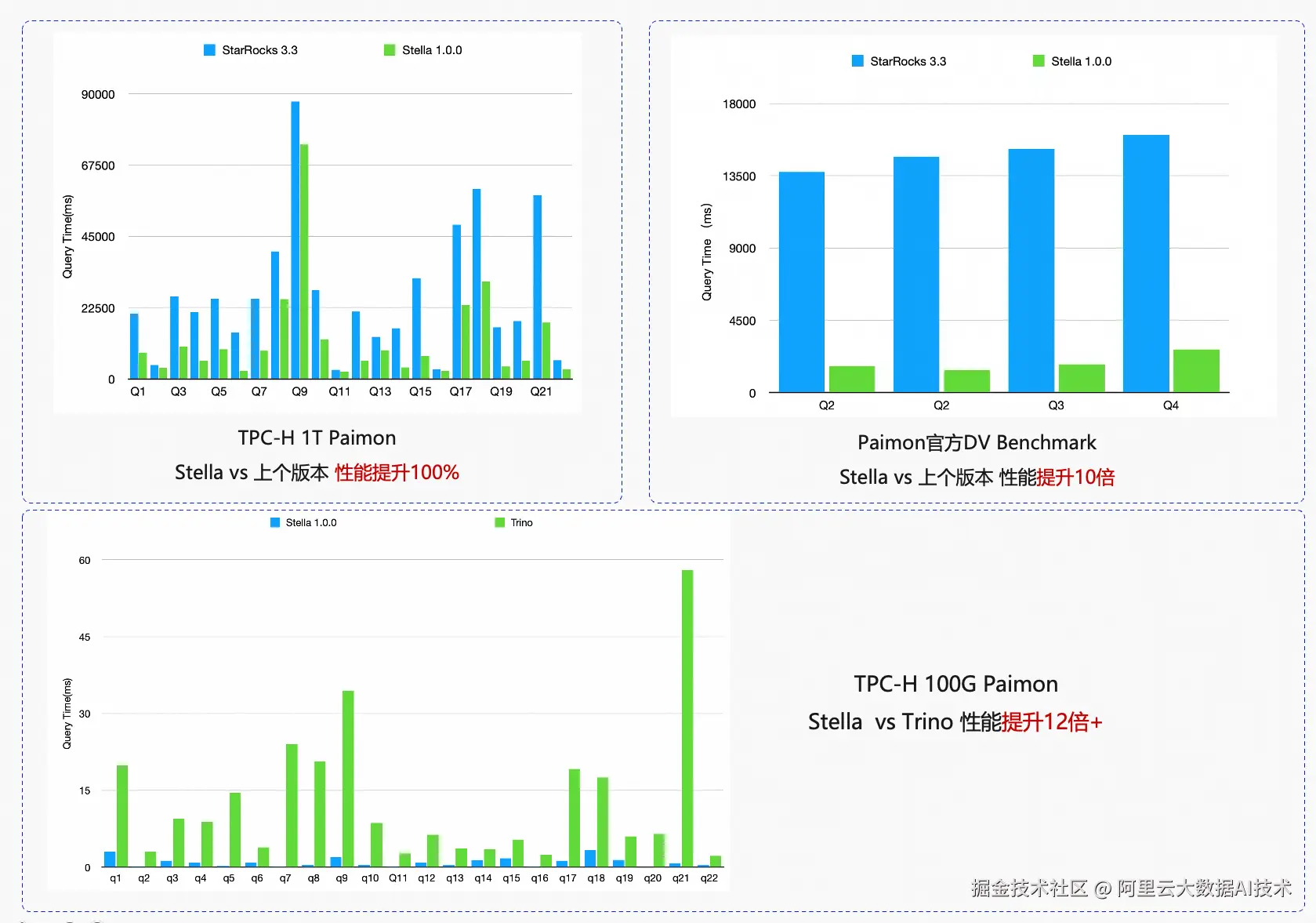
虽然 Flink + Paimon 已成为成熟的实时入湖方案,但计算引擎与 Paimon 存储的查询优化结合仍有巨大提升空间。Stella 与 Paimon 将在多个方便持续进行Co-Design,更多优化成果将在后续版本中发布。
三、全文检索:打造高性能、高可用的文本分析能力
Stella 1.0 正式推出全文检索能力,支持高效、精准的文本查询。
- 架构重构:对 Inverted Index(倒排索引) 整体解决方案进行架构优化
- 存算分离主键表支持:新增主键表全文检索能力,实现高效精准的查询能力
- 小文件合并 :解决存算分离架构下的"性能杀手"问题(单个 Segment 产生十几个小文件)

文本过滤性能benchmark: Stella vs EMR StarRocks 3.3
目前,全文检索功能已在阿里集团内部和云上客户中投入使用,所有优化代码已通过 PR 提交至 StarRocks 开源社区。
技术创新路线图持续演进
面向未来,Stella引擎制定了清晰的技术发展路线图,在四个关键领域持续深耕:
- 迈向Stella 2.0时代:轻量 ETL Production Ready
全面强化轻量级 ETL 能力,打通从数据接入、转换到分析的端到端链路,使用户无需依赖外部调度系统即可高效完成日常数据加工任务,真正实现"开箱即用、生产就绪"。 - Lake Optimizer:湖表性能全面对齐甚至超越内表
推出专为开放数据湖设计的 Lake Optimizer,显著提升 Apache Paimon 等湖表格式的查询性能,让湖表在复杂分析场景中媲美甚至超越传统内表体验。 - 智能化 Background Job Service:彻底释放用户运维负担
针对企业用户长期面临的内表运维复杂、资源争抢等问题,Stella 将推出智能化后台作业服务,自动处理 compaction、索引构建、统计信息收集等任务,实现高智能化的自治运维,大幅提升系统稳定性与资源效率。 - 全文检索与向量检索能力持续提升
在已有的高性能 OLAP 基础上,进一步融合全文检索与向量检索能力,支持非结构化与多模态数据的统一分析,为 AI 原生应用、智能搜索等新兴场景提供底层引擎支撑。
这四大方向不仅体现了 Stella 对 Lakehouse 架构的深度适配,更彰显了其从"高性能分析引擎"向"智能数据平台核心引擎"演进的战略决心。随着这些能力的逐步落地,Stella 将为企业用户提供更开放、更智能、更易用的下一代实时分析体验。
技术探索与社区协作深度融合
Stella引擎在技术架构探索方面持续深化与开源社区的合作:
Lakehouse架构能力的持续拓展体现了Stella引擎的前瞻性设计理念。在现有Lakehouse架构基础上,系统将支持更多检索功能,为企业的多元化分析需求提供全面支持。向量搜索技术是与Apache Paimon深度集成的创新探索,在AI和大数据时代,向量搜索能力将成为差异化的技术优势。
开源社区贡献亮点
- JSON等半结构化数据处理能力持续增强,推动整个生态发展
- 大规模场景技术实践经验分享,为社区贡献宝贵技术智慧
- 与Apache Paimon团队深度技术合作,确保生态整合持续优化
- 所有优化方案回馈开源社区,推动开源生态系统发展进步
开源社区的深度贡献体现了Stella团队的技术责任感和开放合作精神。JSON等半结构化数据处理能力的持续增强将推动整个生态的发展,为企业在数字化转型过程中处理多样化数据提供更强支持。大规模场景下的技术实践经验分享不仅展示技术实力,更为社区贡献了宝贵的技术智慧。
"我们不仅要在云上提供增值服务,更要推动整个开源生态的发展,"周康强调,"通过深度参与开源社区,确保所有用户都能从技术进步中受益。"
技术意义与未来规划
EMR Serverless Stella 1.0的发布标志着阿里云在湖仓一体技术领域达到新的里程碑,为用户提供从数仓加速、湖仓查询到全文检索的全方位OLAP能力支持。该版本不仅解决了企业在实际生产环境中遇到的关键技术挑战,更通过持续的技术创新和社区贡献,推动了整个StarRocks生态系统的发展。
未来,Stella将继续围绕Lakehouse架构演进,在缓存调度、查询优化、存储引擎和写入能力等核心领域持续创新,为企业数字化转型提供更加强劲的技术引擎。