一、项目简介
本项目基于 Rust 语言开发,目标是爬取豆瓣电影 Top250 榜单的核心信息,包括电影名称、评分、导演、主演、上映年份、剧情简介等关键数据,并将结果以 JSON 格式持久化存储,便于后续数据分析或二次开发。相较于其他语言,Rust 的内存安全性和高效性能让爬虫在处理页面解析与数据处理时更稳定,同时通过异步编程实现高效请求,避免网络等待导致的性能浪费。
二、技术栈
本项目选取 Rust 生态中成熟稳定的第三方库,兼顾功能完整性与学习成本,具体技术栈如下:
- HTTP 客户端 :
reqwest(Rust 异步 HTTP 客户端的事实标准,支持 TLS 加密、请求头配置,能模拟浏览器请求规避反爬,同时支持连接复用提升效率) - HTML 解析 :
scraper(基于 W3C 选择器标准,支持 CSS 选择器定位元素,轻量高效,能精准提取页面中的电影数据) - JSON 序列化 :
serde+serde_json(Rust 生态的序列化标杆库,通过派生宏简化数据结构与 JSON 的转换,支持格式化输出提升可读性) - 异步运行时 :
tokio(高性能异步运行时,负责调度 HTTP 请求与解析任务,实现非阻塞 IO 操作,提升爬虫整体效率) - 错误处理 :
anyhow(简化错误传递流程,支持为错误添加上下文信息,无需手动定义复杂错误类型,便于调试) - 日志输出 :
log+env_logger(轻量级日志方案,可通过环境变量控制日志级别,输出请求状态、解析进度等关键信息)
三、项目结构
项目采用简洁清晰的结构,核心逻辑集中在 main.rs 中,同时预留扩展模块的空间,便于后续功能迭代。具体结构如下:
bash
douban-movie-top250-crawler/
├── Cargo.toml # 项目配置与依赖管理
├── src/
│ └── main.rs # 核心逻辑(请求、解析、存储全流程)
└── douban_top250.json # 输出结果文件(运行后自动生成)各文件职责说明:
Cargo.toml:声明项目名称、版本、edition 等基础信息,配置所有依赖库及其版本和特性,确保编译环境一致src/main.rs:包含数据结构定义、HTTP 请求发送、HTML 解析、数据提取、JSON 存储等核心逻辑,是程序执行的入口douban_top250.json:爬虫运行成功后生成的结果文件,存储格式化的电影数据,便于后续查看和使用
四、项目开发
4.1 环境准备
首先确保本地已安装 Rust 开发环境(通过 rustup 安装),验证环境:
bash
rustc --version # 输出 Rust 版本(建议 ≥1.63.0)
cargo --version # 输出 Cargo 版本4.2 初始化项目
通过 Cargo 命令创建项目并进入目录:
bash
cargo new douban-movie-top250-crawler
cd douban-movie-top250-crawler4.3 配置依赖(Cargo.toml)
编辑 Cargo.toml 文件,添加项目所需依赖,指定版本和必要特性(版本可通过 crates.io 查询最新稳定版):
toml
[package]
name = "douban-top250-scraper"
version = "0.1.0"
edition = "2021"
[dependencies]
reqwest = { version = "0.11", features = ["json", "gzip", "brotli", "stream", "rustls-tls"] }
scraper = "0.17"
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
tokio = { version = "1", features = ["full"] }
regex = "1.10"
thiserror = "1.0"
rand = "0.8"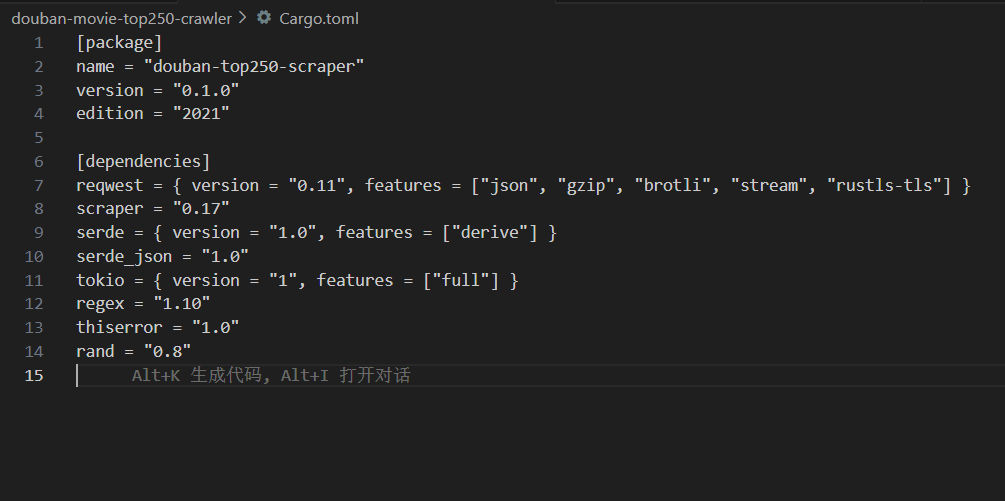
4.4 核心逻辑实现(src/main.rs)
1. 数据结构定义(Movie 结构体)
rust
#[derive(Debug, Serialize, Deserialize, Clone)]
struct Movie {
rank: u32, // 电影排名(1-250)
title: String, // 电影名称
director: String, // 导演
rating: String, // 豆瓣评分
year: String, // 上映年份
}- 派生宏说明:
Debug:支持调试打印(如println!("{:?}", movie));Serialize/Deserialize:支持与 JSON 格式互转;Clone:支持结构体深拷贝(实际场景中可根据需求移除)。
- 字段设计:均使用
String类型存储文本数据,避免类型转换错误,兼容"未知信息"等默认值场景。
2. 自定义错误类型(ScraperError)
rust
#[derive(thiserror::Error, Debug)]
pub enum ScraperError {
#[error("网络请求错误: {0}")]
RequestError(#[from] reqwest::Error), // 网络请求相关错误
#[error("解析错误: {0}")]
ParseError(String), // HTML 解析相关错误
}- 基于
thiserror实现,错误信息语义化,便于调试; - 支持从
reqwest::Error自动转换(#[from]宏),简化错误处理流程。
3. 主函数(程序入口)
rust
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
// 1. 爬取所有电影数据
let movies = scrape_douban_top250().await?;
// 2. 控制台打印结果
for movie in &movies {
println!(
"排名: {}\n片名: {}\n导演: {}\n评分: {}\n年份: {}\n----------",
movie.rank, movie.title, movie.director, movie.rating, movie.year
);
}
// 3. 序列化并保存为 JSON 文件
let json = serde_json::to_string_pretty(&movies)?;
tokio::fs::write("douban_top250.json", json).await?;
println!("已保存 {} 部电影信息到 douban_top250.json", movies.len());
Ok(())
}- 入口注解
#[tokio::main]:启用 Tokio 异步运行时,支撑后续异步函数调用; - 核心流程:爬取数据 → 控制台输出 → JSON 持久化;
- 异步文件写入
tokio::fs::write:与 Tokio 运行时兼容,避免阻塞线程。
4. 核心爬取逻辑(scrape_douban_top250)
rust
async fn scrape_douban_top250() -> Result<Vec<Movie>, ScraperError> {
// 1. 创建 HTTP 客户端(带请求头配置)
let client = create_http_client()?;
let mut all_movies = Vec::new();
// 2. 遍历 10 页榜单(豆瓣 Top250 每页 25 条)
for page in 0..10 {
let start = page * 25; // 分页偏移量(0、25、50...)
let url = format!("https://movie.douban.com/top250?start={}&filter=", start);
println!("正在爬取第 {} 页...", page + 1);
// 3. 爬取当前页数据
match scrape_page(&client, &url, start).await {
Ok(mut movies) => {
println!("第 {} 页成功爬取到 {} 部电影", page + 1, movies.len());
all_movies.append(&mut movies);
}
Err(e) => {
eprintln!(" 爬取页面失败 {}: {}", url, e);
}
}
// 4. 反爬优化:随机延迟 2~5 秒
let delay_secs = rand::thread_rng().gen_range(2..=5);
println!(" 等待 {} 秒后继续...", delay_secs);
sleep(Duration::from_secs(delay_secs)).await;
}
Ok(all_movies)
}- 分页逻辑:通过
start参数控制分页(start=0为第 1 页,start=25为第 2 页,以此类推); - 错误处理:使用
match捕获单页爬取错误,仅打印警告不中断整体爬取; - 反爬设计:随机延迟 2~5 秒,模拟人工浏览行为,避免高频请求被豆瓣封禁 IP。
5. HTTP 客户端配置(create_http_client)
rust
fn create_http_client() -> Result<reqwest::Client, ScraperError> {
let mut headers = HeaderMap::new();
// 模拟浏览器请求头,规避基础反爬
headers.insert(USER_AGENT, HeaderValue::from_static("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"));
headers.insert(ACCEPT, HeaderValue::from_static("text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8"));
headers.insert(ACCEPT_LANGUAGE, HeaderValue::from_static("zh-CN,zh;q=0.9,en;q=0.8"));
let client = reqwest::Client::builder()
.default_headers(headers) // 设置默认请求头
.timeout(Duration::from_secs(30))
.build()?;
Ok(client)
}- 核心作用:配置请求头模拟浏览器行为,避免被豆瓣识别为爬虫;
- 关键配置:
USER_AGENT:标识客户端类型,使用主流 Chrome 浏览器 UA;ACCEPT:声明可接收的响应格式,符合 HTTP 规范;ACCEPT_LANGUAGE:指定语言偏好,适配豆瓣中文页面;timeout:设置 30 秒超时,防止因网络问题导致程序卡死。
6. 单页数据解析(scrape_page)
这是最核心的解析模块,负责从 HTML 中提取单页电影数据:
rust
async fn scrape_page(client: &reqwest::Client, url: &str, start_offset: usize) -> Result<Vec<Movie>, ScraperError> {
// 1. 发送 HTTP 请求并检查响应状态
let response = client.get(url).send().await?;
let status = response.status();
if !status.is_success() {
eprintln!("HTTP请求失败,状态码: {}", status);
return Err(ScraperError::RequestError(reqwest::Error::from(
response.error_for_status().unwrap_err(),
)));
}
// 2. 解析 HTML 文档
let body = response.text().await?;
let document = Html::parse_document(&body);
let item_selector = Selector::parse("div.item").unwrap(); // 电影项容器选择器
let mut movies = Vec::new();
// 3. 遍历所有电影项,提取字段
for (index, element) in document.select(&item_selector).enumerate() {
// 排名 = 分页偏移量 + 页内索引 + 1
let rank = (start_offset + index + 1) as u32;
// 提取片名(CSS 选择器:span.title)
let title = element
.select(&Selector::parse("span.title").unwrap())
.next()
.map(|e| e.text().collect::<String>())
.unwrap_or_else(|| "未知片名".to_string()); // 缺失时使用默认值
// 提取评分(CSS 选择器:span.rating_num)
let rating = element
.select(&Selector::parse("span.rating_num").unwrap())
.next()
.map(|e| e.text().collect::<String>())
.unwrap_or_else(|| "暂无评分".to_string());
// 提取导演和年份(复杂文本处理,使用正则)
let mut director = "未知导演".to_string();
let mut year = "未知年份".to_string();
// 找到包含导演、年份的容器(CSS 选择器:div.bd p)
if let Some(bd_element) = element.select(&Selector::parse("div.bd p").unwrap()).next() {
let bd_text: String = bd_element.text().collect::<String>();
// 清洗文本:去除换行、非-breaking 空格,修剪首尾空白
let clean_text = bd_text.replace("\n", " ").replace("\u{00a0}", " ").trim().to_string();
// 正则提取导演(匹配 "导演: XXX" 格式)
let re_director = regex::Regex::new(r"导演:\s*([^主演]+)").unwrap();
if let Some(cap) = re_director.captures(&clean_text) {
director = cap[1].trim().to_string();
}
// 正则提取年份(匹配 4 位数字)
let re_year = regex::Regex::new(r"(\d{4})").unwrap();
if let Some(caps) = re_director.captures(&clean_text) {
year = caps[1].to_string();
}
}
// 4. 构建 Movie 对象并添加到列表
movies.push(Movie {
rank,
title,
director,
rating,
year,
});
}
Ok(movies)
}- 解析流程:
- 请求响应处理:检查 HTTP 状态码,非 2xx 则返回错误;
- HTML 解析初始化 :将响应文本转为
Html文档对象,定义电影项容器选择器div.item; - 字段提取逻辑 :
- 简单字段(片名、评分):直接通过 CSS 选择器提取,缺失时使用默认值(如"未知片名");
- 复杂字段(导演、年份):先清洗文本(去除无效字符),再通过正则表达式提取(应对非结构化文本);
- 排名计算:基于分页偏移量 + 页内索引,确保排名连续(1-250)。
五、运行说明
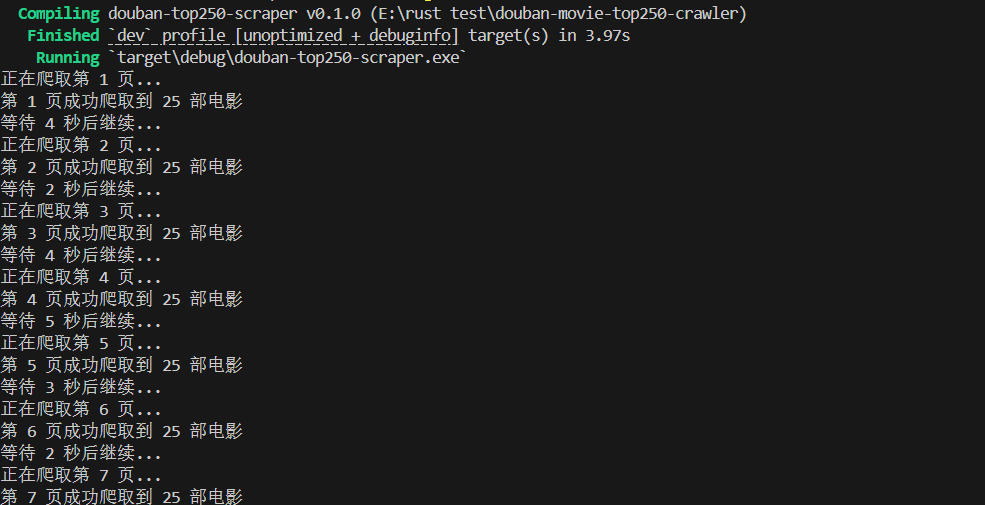
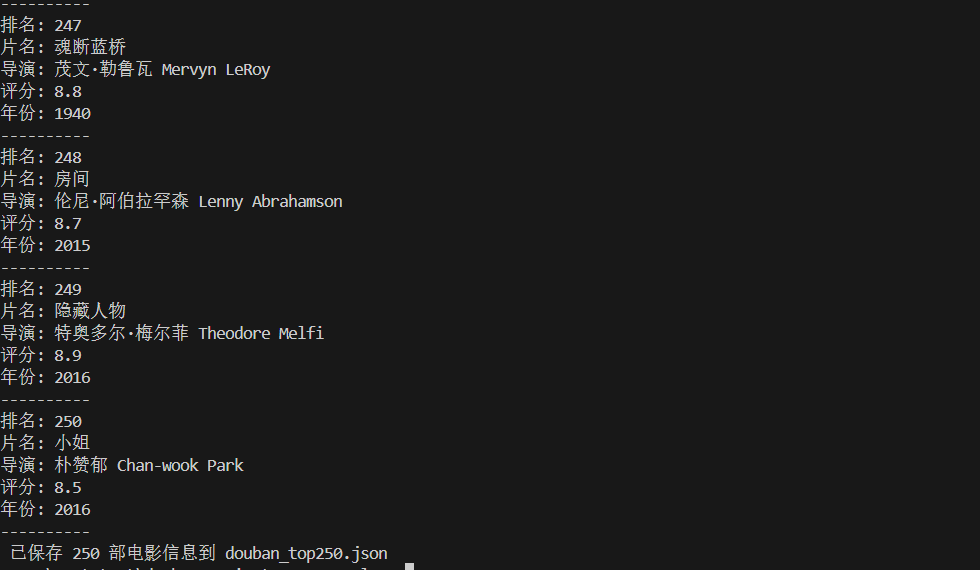
运行命令
bash
cargo run输出结果
- 控制台打印每部电影的排名、片名、导演、评分、年份;
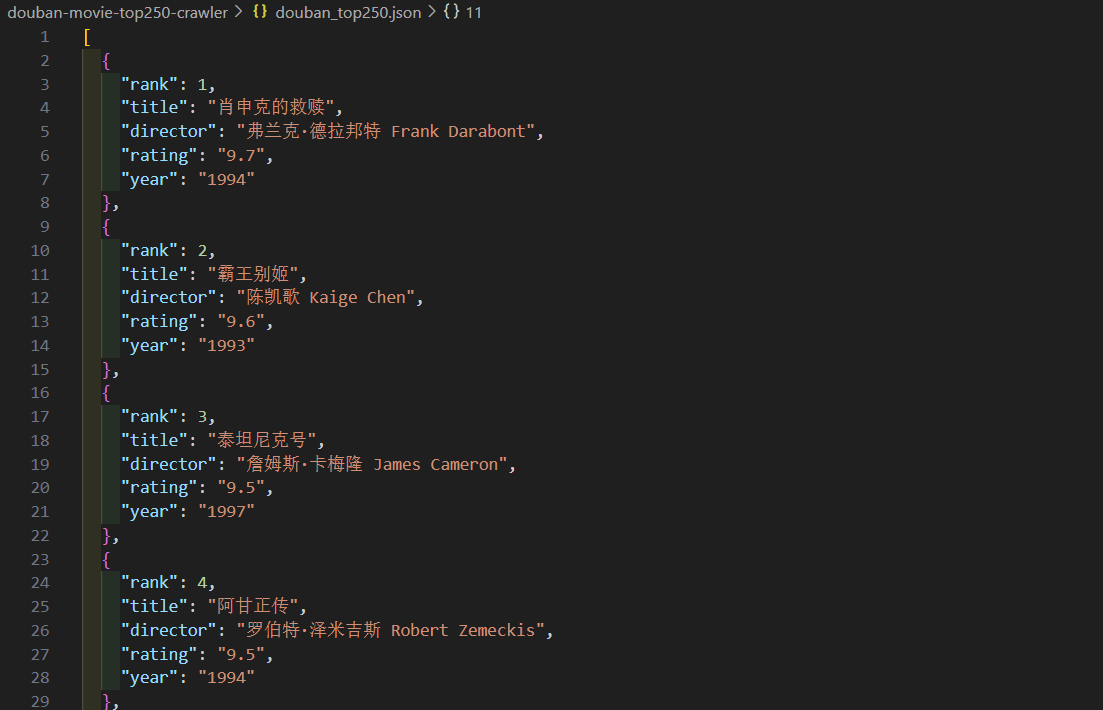
- 项目根目录生成
douban_top250.json文件,包含所有电影的 JSON 格式数据。
六、项目总结
本项目通过实践验证了Rust在爬虫开发中的优势---类型安全保障了数据处理的准确性,异步运行时提升了网络请求效率,内存高效的特性使程序在长时间运行中仍保持稳定。同时,项目也凸显了"合规爬取"的重要性,后续开发中需持续遵守豆瓣robots协议,进一步优化请求策略,在获取数据价值的同时尊重目标网站的服务规则。
想了解更多关于Rust语言的知识及应用,可前往华为开放原子旋武开源社区(https://xuanwu.openatom.cn/),了解更多资讯~