一.YARN 架构
1.YARN 是什么?
YARN 是 Apache Hadoop 生态系统中的核心资源管理和调度平台。它的诞生是为了解决 Hadoop 1.0 中 MapReduce 框架的两个主要问题:
-
可扩展性差:在 Hadoop 1.0 中,JobTracker 同时负责资源管理和作业调度/监控,随着集群节点和作业数量的增加,它成为了系统瓶颈。
-
不支持多种计算模型:Hadoop 1.0 只能运行 MapReduce 任务,无法有效支持像 Spark、Flink、Tez 这样的其他计算框架。
YARN 的基本思想是:将资源管理和作业调度/监控的功能分离开来。它提供了一个通用的、跨框架的资源管理平台,允许各种计算框架(如 MapReduce, Spark, Flink, Hive on Tez 等)在一个集群上共享资源,协同工作。
2. YARN 的核心组件与架构
YARN 采用了经典的 Master/Slave 架构,主要由以下几个核心组件构成:
1. ResourceManager (RM) - 主节点(Master)
ResourceManager 是整个 YARN 集群的资源总管 ,负责整个系统的资源管理和分配。RM 将
各个资源部分(计算、内存等)安排给基础 NodeManager(NM)。
RM 与 ApplicationMaster(AM) 一起分配资源,RM与NM 一起启动和监视它们的基础应用程序。AM 承担了以前的 TaskTracker 的一些角色,RM 承担了JobTracker 的角色。
它主要由两个组件构成:
-
调度器(Scheduler) :纯调度器,它根据容量、队列等限制条件,将系统资源(如 CPU、内存)分配给各个正在运行的应用程序。它不负责监控或跟踪应用程序的状态,而是将这些工作交由应用程序相关的AM完成
-
应用程序管理器(ApplicationsManager):应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动AM、监控AM运行状态并在失败时重新启动它。
2. NodeManager (NM) - 从节点(Slave)
NodeManager 是每个工作节点上的代理,负责:
-
管理单个节点上的资源。
-
向 ResourceManager 汇报本节点的资源使用情况(CPU,内存等)。
-
接收并处理来自 ResourceManager 和
ApplicationMaster的命令,例如启动或停止容器(Container)。 -
为应用启用调度器,以分配给应用的Container
-
保证已经启用的Container不会使用超过分配的资源量
-
为task构建Container环境,包括二进制可执行文件.jars等
-
为所在节点提供一个管理本地存储资源的简单服务
3. ApplicationMaster (AM) - 应用程序主管(每个应用一个)
它是一个应用程序级别的守护进程,每个应用程序(例如一个 MapReduce 作业,一个 Spark 作业)都有一个自己的 AM。
-
负责与 ResourceManager 的调度器协商资源。
-
从 NodeManager 上启动和监控具体的任务(如 Map Task, Reduce Task)。
-
跟踪任务状态和进度,并向 ResourceManager 汇报。
-
在任务失败时,向 ResourceManager 申请新的资源来重启任务。
4.ResourceRequest和Container
-
一个应用程序可以通过AM请求特定的资源需求来满足它的资源需要。调度器会分配一个Container来响应资源需求,用于满足由AM在ResourceManager中提出的需求。ResourceRequest具有以下形式:< 资源名称,优先级,资源需求,Container数 >。
-
本质上Container是一种资源分配形式,是ResourceManager为ResourceRequest成功分配资源的结果。Container为应用程序授予在特定主机上使用资源(如内存,CPU等)的权利。
-
ApplicationMaster必须取走Container,并交给NodeManager,NodeManager会利用相应的资源来启动Container的任务进程。出于安全考虑,Container的分配要以一种安全的方式进行验证,来保证ApplicationMaster不能伪造集群中的应用。
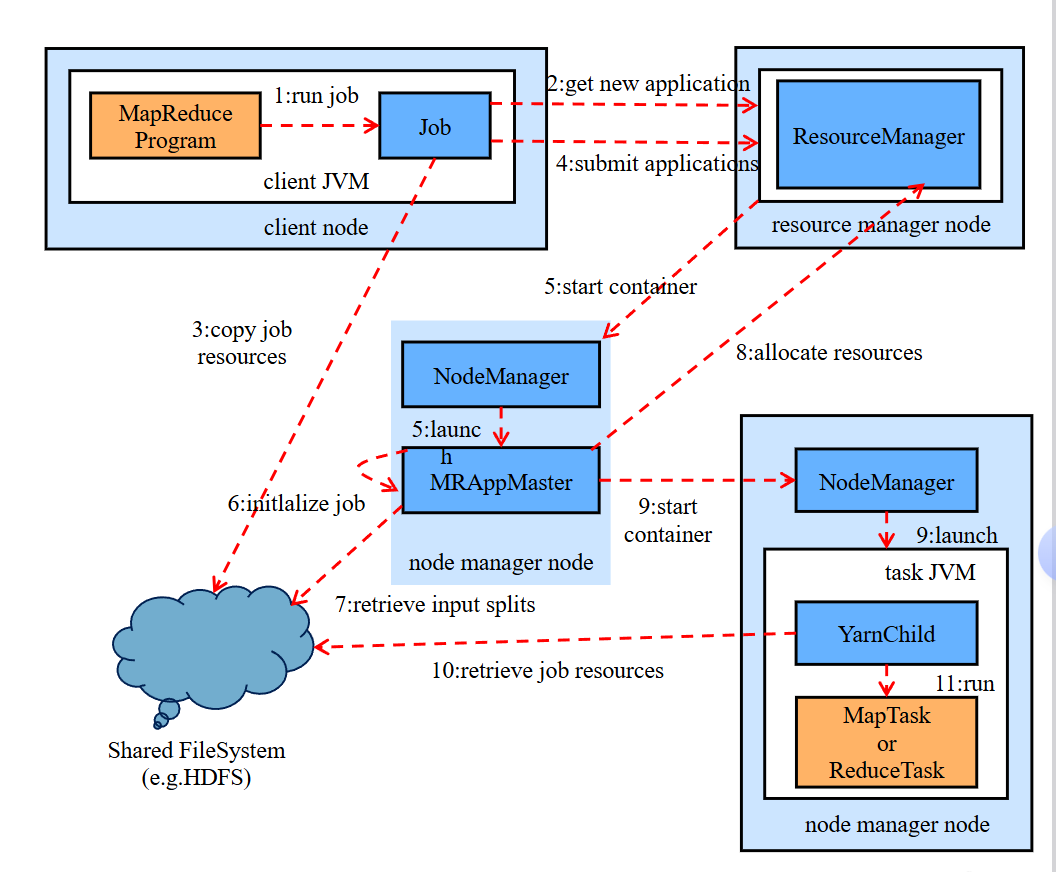
3.基于YARN的运行机制解析
二.Shuffle和排序
Shuffle 是一个过程,它将 Map 阶段(数据读取和初步处理)的输出,按照 Key 重新分发到 Reduce 阶段所在节点上的过程。你可以把它想象成打扑克时的洗牌,将分散在不同人手中的牌(Map 的输出)收集起来,然后重新发牌,确保相同点数的牌(相同的 Key)都发到同一个人(同一个 Reduce 任务)手里。
1.为什么需要 Shuffle?
因为"物以类聚"。例如,我们要统计一篇文章中每个单词出现的次数(WordCount)。
-
Map 阶段 :每台机器处理文章的一部分,输出类似
(apple, 1), (banana, 1), (apple, 1)的键值对。 -
Shuffle 阶段 :我们需要把所有
apple的记录发送到同一台 负责统计apple的机器上,把所有banana的记录发送到另一台负责统计banana的机器上。 -
Reduce 阶段 :每台机器收到所有分配给自己的键值对后,进行聚合计算(例如,把所有的
(apple, 1)加起来)。
没有 Shuffle,Reduce 任务就无法对全局所有相同 Key 的数据进行聚合。
**2.**Shuffle 的详细过程(以 MapReduce 为例)
-
Map 端:
-
分区(Partitioning):Map 任务在处理完数据后,会为每个输出键值对计算一个分区号,决定这个键值对属于哪个 Reduce 任务。
-
溢写(Spill) :Map 任务将输出先写入内存的一个环形缓冲区。当缓冲区达到一定阈值(如80%),会启动一个后台线程,将缓冲区中的数据排序后溢写到本地磁盘,生成一个小的临时文件。
-
合并(Merge) :当 Map 任务结束时,它会将磁盘上所有的小的临时文件合并成一个大的、已分区且已排序的输出文件。
-
-
拷贝(Copy):
- Reduce 任务启动后,会通过 HTTP 请求从各个已完成 Map 任务的节点上拉取(Fetch) 属于自己的那部分数据。
-
Reduce 端:
- 合并(Merge) :Reduce 任务从多个 Map 节点拉取数据,这些数据可能也是多个小文件。Reduce 任务会将这些文件在内存或磁盘上进行多路归并,最终形成一个整体上有序的数据文件,作为 Reduce 任务的输入。
3.Sort排序:在MapReduce计算框架中主要用到了两种排序算法:快速排序和归并排序
(1)三次排序过程详解
第一次排序:Map 端内存缓冲区排序
-
时机:Map 任务输出,内存环形缓冲区达到溢出阈值(如 80%)时。
-
位置:内存。
-
操作 :在数据溢出到磁盘之前,后台线程会对缓冲区每个分区内的数据按照 Key 进行排序。
-
算法 :快速排序。
- 原因:快速排序是一种高效的内部排序算法,平均时间复杂度为 O(n log n),且是原地排序,非常适合在内存中对大量数据进行排序。
-
结果 :生成一个在磁盘上的溢写文件 ,这个文件内部是分区的,且每个分区内的数据是按键有序的。
第二次排序:Map 端溢写文件合并排序
-
时机:Map 任务结束时,所有溢写文件需要被合并成一个最终的 Map 输出文件。
-
位置:磁盘。
-
操作 :将多个已经内部有序的溢写文件(可能还包括内存中未溢出的数据)合并成一个文件。
-
算法 :归并排序。
- 原因:当有多个有序的子文件时,归并排序是最高效的将它们合并成一个整体有序文件的方法。其时间复杂度为 O(n log k),其中 k 是子文件的数量。它只需要一次顺序扫描,非常适合磁盘 I/O 的特性。
-
结果 :生成一个最终的、整体有序的 Map 输出文件。这个文件仍然是分区的,但现在是每个分区内全局有序(对于这个 Map 任务而言)。
第三次排序:Reduce 端文件合并排序
-
时机:Reduce 任务从所有 Map 任务节点拉取到属于自己的数据分片后,在开始执行 Reduce 函数之前。
-
位置:磁盘(或内存与磁盘结合)。
-
操作 :Reduce 任务会从多个 Map 节点拉取数据,这些数据都是每个 Map 任务最终输出的、已经排好序的文件片段。Reduce 任务需要将这些来自不同 Map 任务但属于同一分区的有序文件合并成一个整体有序的文件,作为 Reduce 函数的输入。
-
算法 :归并排序。
- 原因:与第二次排序完全相同。面对多个有序的输入流,归并排序是最佳选择。在 Hadoop 中,这个阶段通常是一个多路归并。
-
结果 :生成一个提供给 Reduce 函数的、全局有序的输入数据流。这样,Reduce 函数可以顺序处理所有相同 Key 的数据,并在遇到下一个 Key 时知道前一个 Key 的所有值都已处理完毕。
三.wordcount实例代码
1.mapper类
java
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* Map函数,处理每一行数据
* @param key: 行的起始偏移量
* @param value: 一行的内容
* @param context: 上下文对象,用于输出Mapper的结果
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable,Text,Text,IntWritable>.Context context)
throws IOException, InterruptedException {
// 将一行文本转换为String
String line = value.toString();
String [] words = line.split("\\s+");
// 遍历所有单词,将每一个单词与数值1拼接成键值对写出
for(String word :words){
context.write(new Text(word),new IntWritable(1));
}
}
}注意public void map()这个函数的四个参数分别是
1. KEYIN - 输入键的类型
-
默认类型 :
LongWritable -
含义 :表示每行文本在文件中的起始字节偏移量(这一行第一个字符,是这个块的第几个字符,起始从0 开始计算)
-
示例 :
0,6,13等位置
2. VALUEIN - 输入值的类型
-
默认类型 :
Text -
含义 :表示一行的文本内容
-
示例 :
"Hello","Hadoop","HHA"
3. KEYOUT - 输出键的类型
-
自定义类型:根据业务需求定义
-
含义:Mapper处理后的中间结果的键
-
WordCount示例 :
Text(单词)
4. VALUEOUT - 输出值的类型
-
自定义类型:根据业务需求定义
-
含义:Mapper处理后的中间结果的值
-
WordCount示例 :
IntWritable(词频,通常为1)
2.reducer类
java
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* KEYIN: Reducer输入Key的类型,对应Mapper的KEYOUT (Text)
* VALUEIN: Reducer输入Value的类型,对应Mapper的VALUEOUT (IntWritable)
* KEYOUT: Reducer输出Key的类型,这里是单词 (Text)
* VALUEOUT: Reducer输出Value的类型,这里是总词频 (IntWritable)
*/
public class WordCountReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
int times = 0;
// 遍历该单词对应的所有计数值(1)
for (IntWritable value : values) {
// 累加求和
times += value.get();
}
// 输出最终结果:<单词, 总词频>
context.write(key, new IntWritable(times));
}
}1. KEYIN - 输入键的类型
-
对应Mapper的KEYOUT
-
含义:Mapper输出的中间结果的键
-
WordCount示例 :
Text(单词)
2. VALUEIN - 输入值的类型
-
对应Mapper的VALUEOUT
-
含义:Mapper输出的中间结果的值列表
-
WordCount示例 :
IntWritable(词频计数的列表)
3. KEYOUT - 输出键的类型
-
自定义类型:根据最终输出需求定义
-
含义:Reducer处理后的最终结果的键
-
WordCount示例 :
Text(单词)
4. VALUEOUT - 输出值的类型
-
自定义类型:根据最终输出需求定义
-
含义:Reducer处理后的最终结果的值
-
WordCount示例 :
IntWritable(总词频)
3.driver类
java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 1.获取配置信息
// 加载默认的配置,即core-default.xml、hdfs-default.xml、mapped-default.xml和yarn-default.xml中的配置信息
// 然后读取项目中的core-site.xml、hdfs-site.xml、mapped-site.xml和yarn-site.xml中配置的信息,更新某些属性的值
Configuration conf = new Configuration();
// 2.如果需要继续更新某些属性的值,可以在代码中更新
conf.set("fs.defaultFS", "hdfs://192.168.215.130:9820");
// 3.创建Job对象
Job job = Job.getInstance(conf); // 修正:应该是conf,不是config
// 4.设置Mapper类型
job.setMapperClass(WordCountMapper.class);
// 5.设置Reducer类型
job.setReducerClass(WordCountReducer.class);
// 6.设置驱动类型
job.setJarByClass(WordCountDriver.class);
// 7.设置Map阶段输出的键值对类型
// 如果Map阶段输出的键值对类型与Reduce阶段输出的键值对类型相同,则可以省略这个设置。
// 例如:现在的Map阶段输出是<Text, IntWritable>类型的,与Reduce阶段的数据类型相同,因此可以省略不写。
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(IntWritable.class);
// 8.设置Reduce阶段输出的键值对类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 9.设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(args[0])); // 修正:添加分号
FileOutputFormat.setOutputPath(job, new Path(args[1])); // 修正:添加分号
// 10.提交Job
System.exit(job.waitForCompletion(true) ? 0 : -1);
}
}4.实例分析:
对于任何一个实例,大概需要四步,定义一个新的自定义类,写出mapper,reducer,driver类
其中新的自定义类,需要根据题目自行分析出来,mapper,reducer,driver类中参数等都是相同的模板,只有void mapper/reducer()这个函数内部具体代码是根据实例来的。
相同之处还有 具体代码的最后都是:
// 输出最终结果:<单词, 总词频>
context.write(key, new IntWritable(。。。));
四.分区器设置:
**1.**概述
在MapReduce的程序中,最终⽣成多少个⽂件是由ReduceTask的数量来决定 的。
在上述的案例中,我们最终⽣成了⼀个⽂件,这是因为只有⼀个ReduceTask。那么如果需要⽣成 两个结果⽂件,可以将ReduceTask的数量设置为2。
在MapReduce程序中,⼀个MapTask会处理⼀个分⽚的数据,⽽⼀个ReduceTask 是⽤来处理⼀个分区的数据。因此如果我们需要明确某个单词的统计结果,到底该存放在哪个⽂件 中,只需要设置好分区即可。⽽Partitioner就是⼀个分区器组件,来实现数据的分区操作。默认的 分区器是HashPartitioner,如果我们需要实现⾃⼰的分区逻辑,就需要⾃定义分区器了。
HashPartitioner的逻辑为:
● 分区器计算每个Key的HashCode;
● 将计算后的HashCode % ReduceTask的数量,得到⼀个分区的编号。
二.实例代码
1.自己设立的Partitioner
java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class WordCountPartitioner extends Partitioner<Text, IntWritable> {
/**
* 计算每⼀个键值对所对应的分区号,分区号从0开始
* @param text 键
* @param intWritable 值
* @param i 总的ReduceTask的数量
* @return 该键值对对应的分区
*/
@Override
public int getPartition(Text text, IntWritable intWritable, int i) {
// 将键值对按照⾸字⺟分为三个分区: a-i, j-q, 其他
// 1.获取⾸字⺟
char firstLetter = text.toString().charAt(0);
// 2.判断范围,分别返回不同的数值
if (firstLetter >= 'a' && firstLetter <= 'i') {
return 0;
} else if (firstLetter >= 'j' && firstLetter <= 'q') {
return 1;
}
return 2;
}
} 2.Driver
java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 1.获取配置信息
// 加载默认的配置,即core-default.xml、hdfs-default.xml、mapped-default.xml和yarn-default.xml中的配置信息
// 然后读取项目中的core-site.xml、hdfs-site.xml、mapped-site.xml和yarn-site.xml中配置的信息,更新某些属性的值
//conf:Hadoop 配置对象(通常是 Configuration 类实例)
Configuration conf = new Configuration();
// 2."fs.defaultFS": Hadoop 的核心配置参数,指定默认文件系统
//"hdfs://192.168.215.130:9820": HDFS 服务的地址和端口
conf.set("fs.defaultFS", "hdfs://192.168.215.130:9820");
// 3.创建Job对象
Job job = Job.getInstance(conf);
// 4.设置Mapper类型
job.setMapperClass(WordCountMapper.class);
// 5.设置Reducer类型
job.setReducerClass(WordCountReducer.class);
// 6.设置驱动类型
job.setJarByClass(WordCountDriver.class);
// 7.设置Map阶段输出的键值对类型
// 如果Map阶段输出的键值对类型与Reduce阶段输出的键值对类型相同,则可以省略这个设置。
// 例如:现在的Map阶段输出是<Text, IntWritable>类型的,与Reduce阶段的数据类型相同,因此可以省略不写。
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(IntWritable.class);
// 8.设置Reduce阶段输出的键值对类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 9.设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 10.设置分区器
job.setPartitionerClass(WordCountPartitioner.class);
// 11.设置ReduceTask的数量
// ReduceTask的数量最好和分区的数量保持⼀致:
// 如果ReduceTask的数量多于分区的数量: 会出现多余的ReduceTask空占资源,不去处理任何的数据,浪费资源,且⽣成空的结果⽂件
// 如果ReduceTask的数量少于分区的数量: 会出现某个分区的数据暂时⽆法处理,
//需要等待某ReduceTask任务处理结束后再处理这个分区的数据,⽆法⾼效并发
job.setNumReduceTasks(3);
// 12.提交Job
System.exit(job.waitForCompletion(true) ? 0 : -1);
}
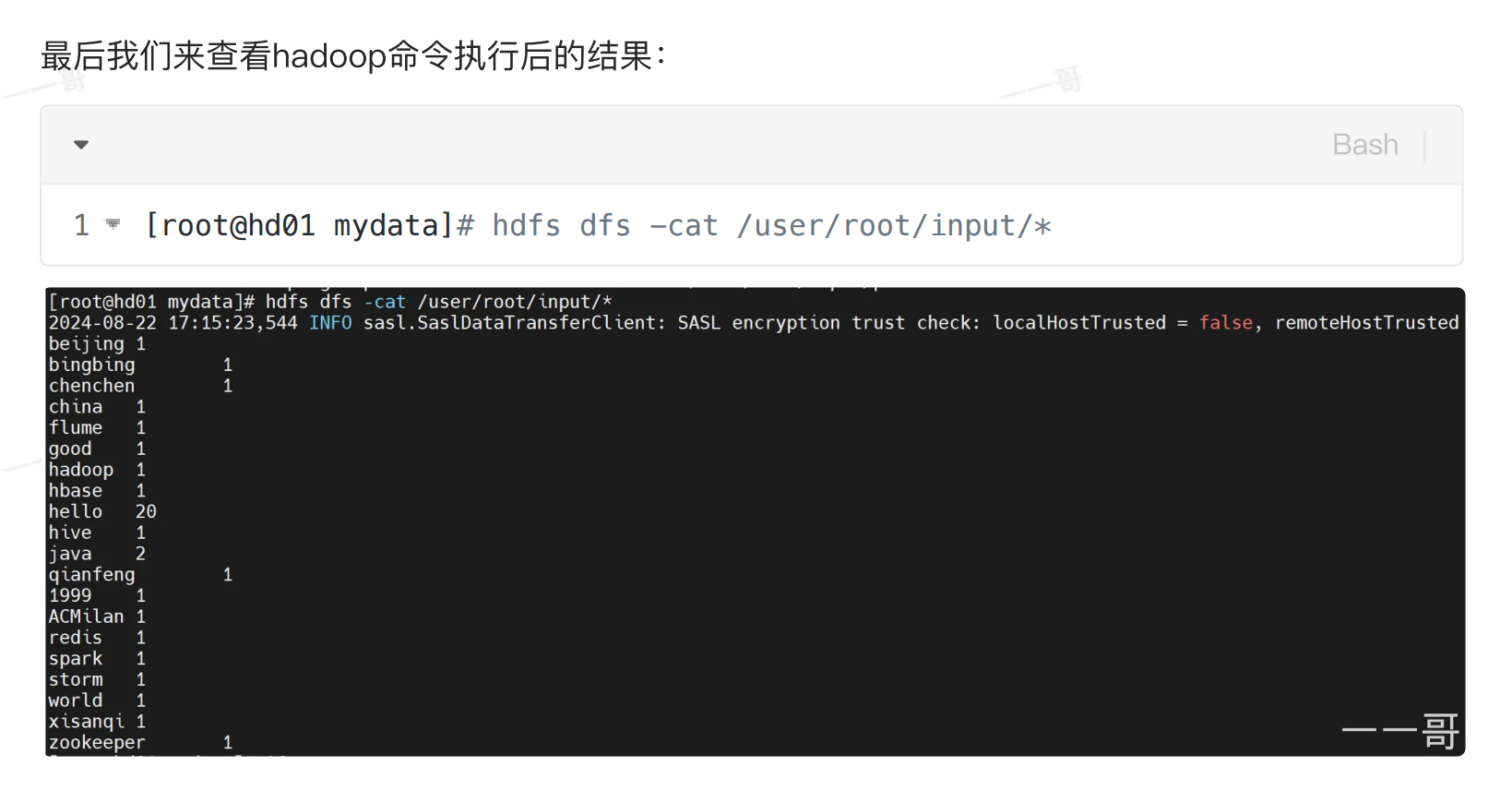
}3.命令后的效果
五.序列化机制
**1.**概述
在讲解为什么要序列化之前,我们要先来了解下什么是序列化和反序列化。
●序列化:序列化是指将具有结构化的内存对象,转为0和1组成的字节序列,以便进⾏⽹络传
输或持久存储到设备的过程。
● 反序列化: 反序列化指的是将字节序列,转为内存中具有结构化的对象的过程。
在基于类的编程语⾔中,数据都会被封装成对象,在内存中进⾏管理。但有些时候,如果⼀个对象
要直接存储到磁盘,或者要进⾏⽹络传输,那么该怎么做呢?这就需要将对象序列化成0和1组成的
字节序列,字节序列就可以存储到磁盘中,或者进⾏⽹络传输了。当我们需要对象时,当读取磁盘
上的字节序列,或者接收⽹络传输过来的字节序列,反序列化成我们需要的对象就可以了。
2.常⽤类型简介
| Java 数据类型 | Hadoop 序列化数据类型 | 释义 |
|---|---|---|
byte |
ByteWritable |
字节型 |
short |
ShortWritable |
短整型 |
int |
IntWritable |
整型 |
long |
LongWritable |
长整型 |
float |
FloatWritable |
单精度浮点型 |
double |
DoubleWritable |
双精度浮点型 |
boolean |
BooleanWritable |
布尔型 |
String |
Text |
使用 UTF-8 编码的字符串 |
array[] |
ArrayWritable |
数组 |
Map<K, V> |
MapWritable |
键值对集合 |
null |
NullWritable |
空类型,常用于占位或作为 Key/Value 为空的情况 |
3.序列化接⼝Writable
3.1 Writable接⼝
模板:
java
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}例子:
java
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @ClassName: StudentWriter
* @Author: 壹壹哥
* @Date: 2024-08-22 17:47
*/
public class StudentWriter implements Writable {
private String name;
private int age;
public StudentWriter(String name,int age){
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(name);
out.writeInt(age);
}
@Override
public void readFields(DataInput in) throws IOException {
name = in.readUTF();
age = in.readInt();
}
}3.2 WritableComparable接⼝
java
public interface WritableComparable<T> extends Writable, Comparable<T> {
}3.3自定义序列化接口
如果想要把⼀个⾃定义的数据类型作为K2V2或者K3V3来使⽤,那么就必须要实现序列化的接⼝Writable。
如果这个⾃定义的数据类型是⼀个Key的数据类型,则还需要在满⾜⽐较的条件,也就是再额外实现⼀个Comparable的接⼝
或者可以直接实现WritableComparable接⼝。
java
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.Objects;
public class TextPair implements WritableComparable {
/*一些java自定义函数.... */
//* 序列化⽅法,将属性序列化成字节序列
public void write(DataOutput out) throws IOException {
//将属性写到输出流程
name.write(out);
info.write(out);
//如果不是hadoop类型,⽐如是java类型
// out.writeUTF(name);
// out.writeUTF(info);
}
//* 反序列化⽅法,从流中读取字节序列进⾏反序列化。
public void readFields(DataInput in) throws IOException {
//要按照序列化的顺序进⾏反序列化
name.readFields(in);
info.readFields(in);
}
public int compareTo(Object o) {
return 0;
}
}3.4**.**实现Serializable接⼝
java.io.Serializable 是一个标记接口。它内部没有任何需要实现的方法。
它的唯一作用是在编译时和运行时向 Java 虚拟机(JVM)声明:
"这个类的对象可以被序列化。"
如果一个类没有实现 Serializable 接口,尝试对其对象进行序列化操作(例如,使用 ObjectOutputStream)将会抛出 NotSerializableException。
代码如下:
java
import java.io.Serializable;
public class StudentSerializer implements Serializable {
}