TL;DR
- 场景:3 节点(h121/122/123)资源吃紧环境,部署 Apache Kylin 3.1.1(HBase1.x 版)。
- 结论:通过环境变量与软链补齐、修正 HADOOP_CONF_DIR、按序启动组件,成功启动并登录 Kylin(7070)。
- 产出:完整命令序列、版本矩阵(已验证)、错误速查卡(常见症状→定位→修复)。

版本矩阵
| 组件/包名 | 版本 | 已验证 | 说明 |
|---|---|---|---|
| Apache Kylin | 3.1.1 (apache-kylin-3.1.1-bin-hbase1x) | 是 | 来自 archive.apache.org,运行于 h122,Web 端口 7070,默认 ADMIN/KYLIN(大写)。 |
| Hadoop | 2.9.2 | 是 | HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop;先启 HDFS,再启 YARN;HADOOP_CLASSPATH=hadoop classpath。 |
| Hive | 2.3.9 | 是 | 独立启动 Metastore(9083),日志 /tmp/metastore.log。 |
| HBase | 1.3.1 | 是 | hbase.zookeeper.quorum 仅填主机名;三节点协同启动。 |
| Spark | 2.4.5 (without-hadoop, Scala 2.12) | 是 | 作为依赖配置软链;未跑计算作业。 |
| ZooKeeper | 版本未记录(三节点) | 是 | 各节点 zkServer.sh start。 |

依赖环境
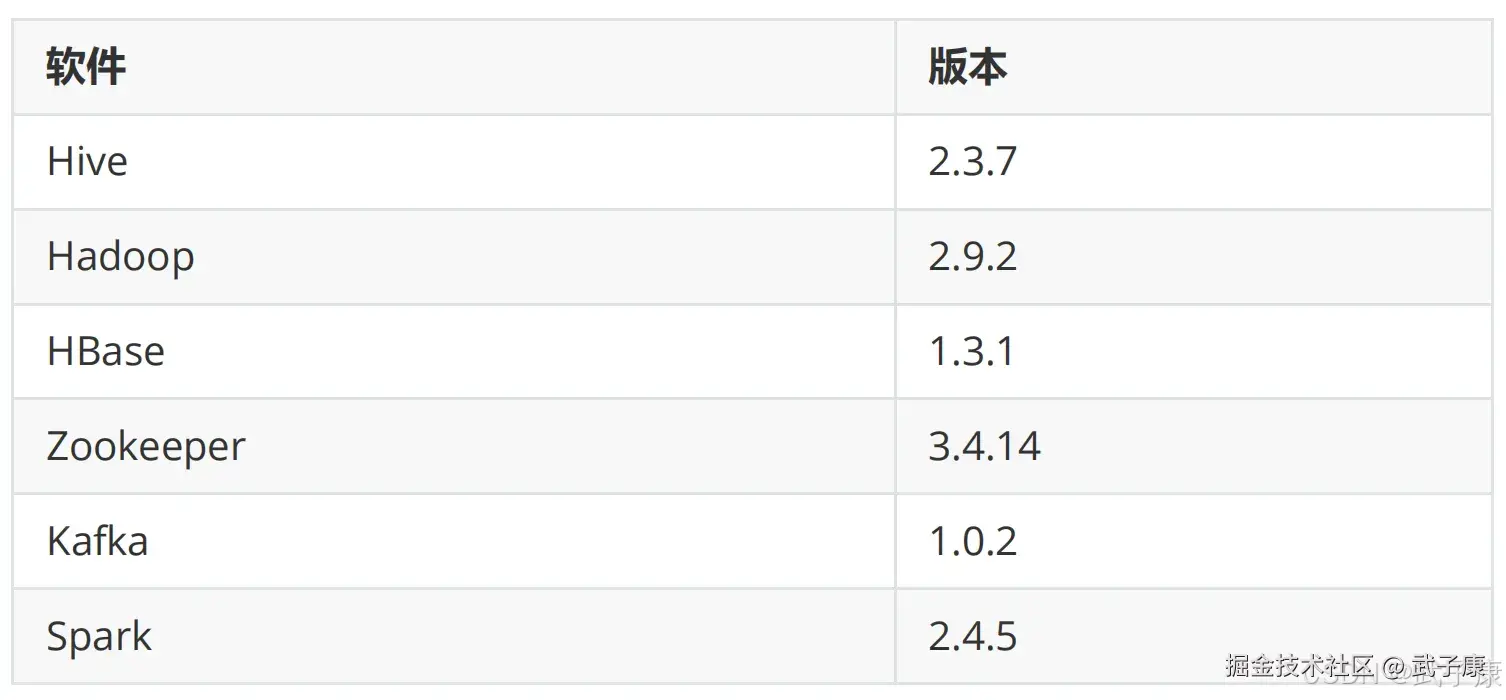
集群规划
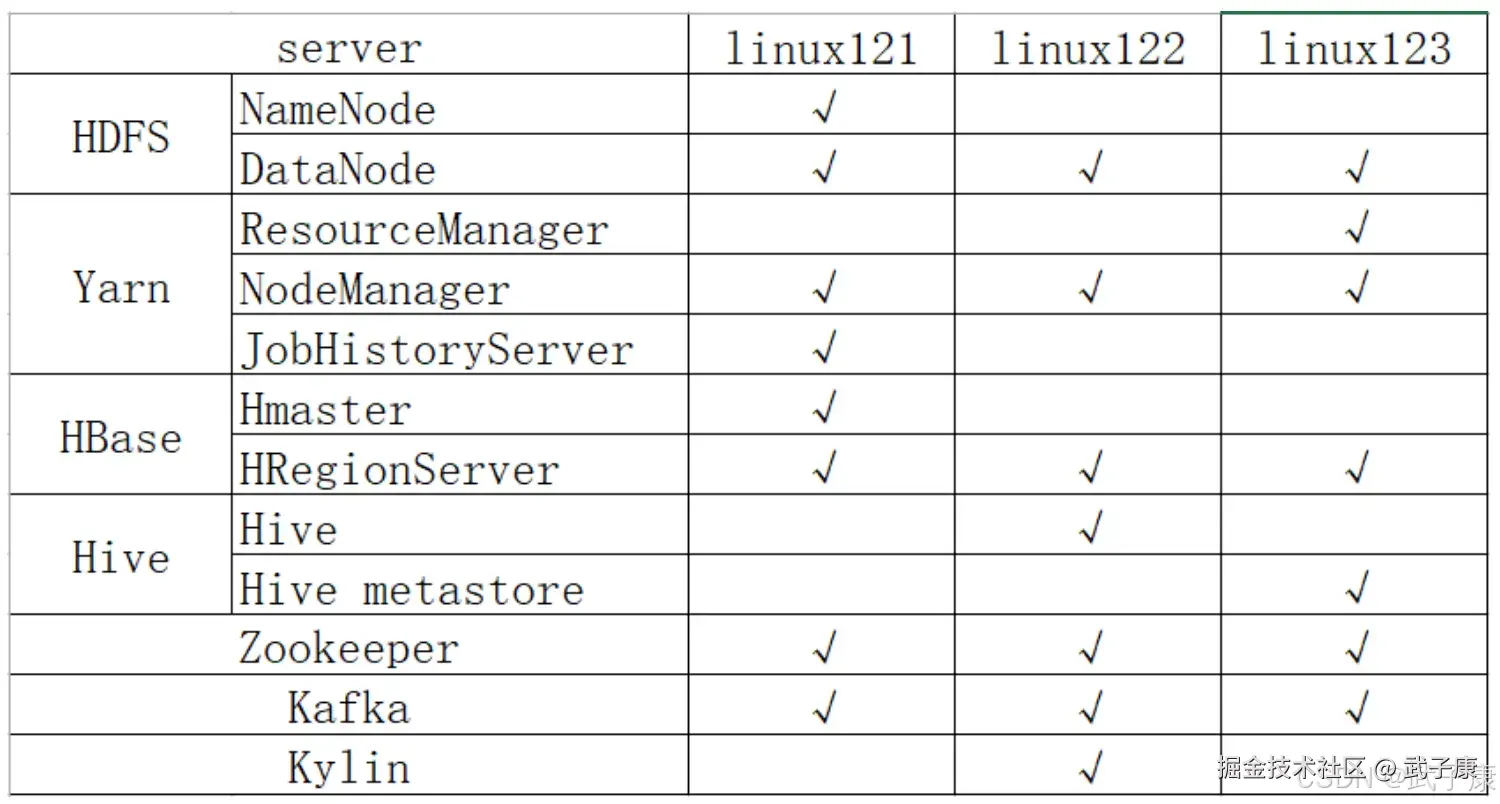 我这里就不根据上图来做了,因为我的服务器资源比较紧张,我就自由安排了。 需要注意:要求HBase的hbase.zookeeper.quorum值必须只能是 host1、host2这种,不允许host1:2181、host2:2181这种。
我这里就不根据上图来做了,因为我的服务器资源比较紧张,我就自由安排了。 需要注意:要求HBase的hbase.zookeeper.quorum值必须只能是 host1、host2这种,不允许host1:2181、host2:2181这种。
shell
cd /opt/servers/hbase-1.3.1/conf
vim hbase-site.xml(之前HBase实验已经做过了,配置就是这样的)
保险起见,放一个截图: 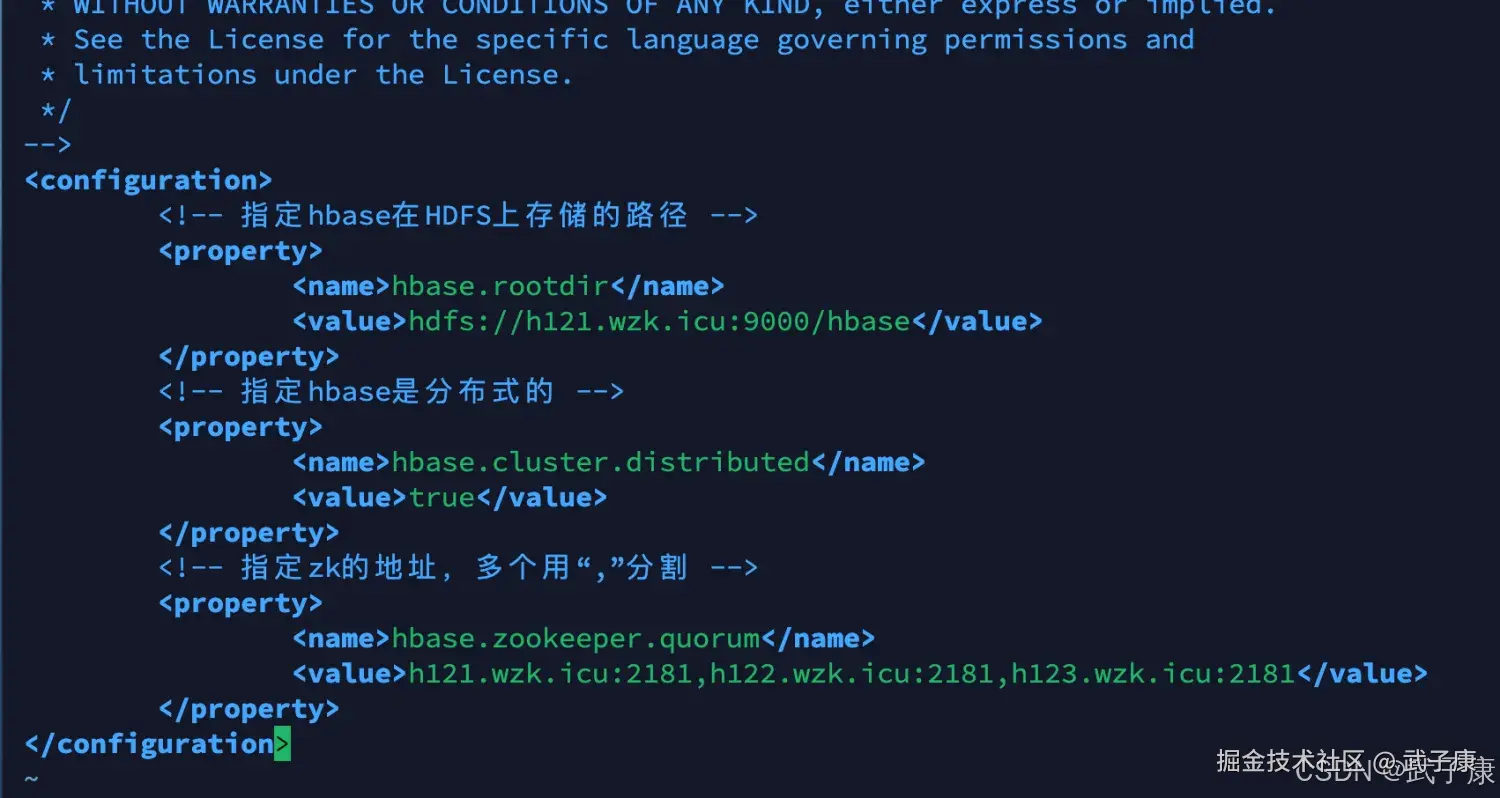
项目下载
下载地址如下:
shell
https://archive.apache.org/dist/kylin/这里使用的是:
shell
https://archive.apache.org/dist/kylin/apache-kylin-3.1.1/apache-kylin-3.1.1-bin-hbase1x.tar.gz你可以通过wegt或者本地下载完传到服务器上,按照需求,我这里是上传到 h122 节点上
shell
cd /opt/software
wget https://archive.apache.org/dist/kylin/apache-kylin-3.1.1/apache-kylin-3.1.1-bin-hbase1x.tar.gz等待下载完毕 
解压移动
shell
cd /opt/software
tar -zxvf apache-kylin-3.1.1-bin-hbase1x.tar.gz运行结果如下图所示: 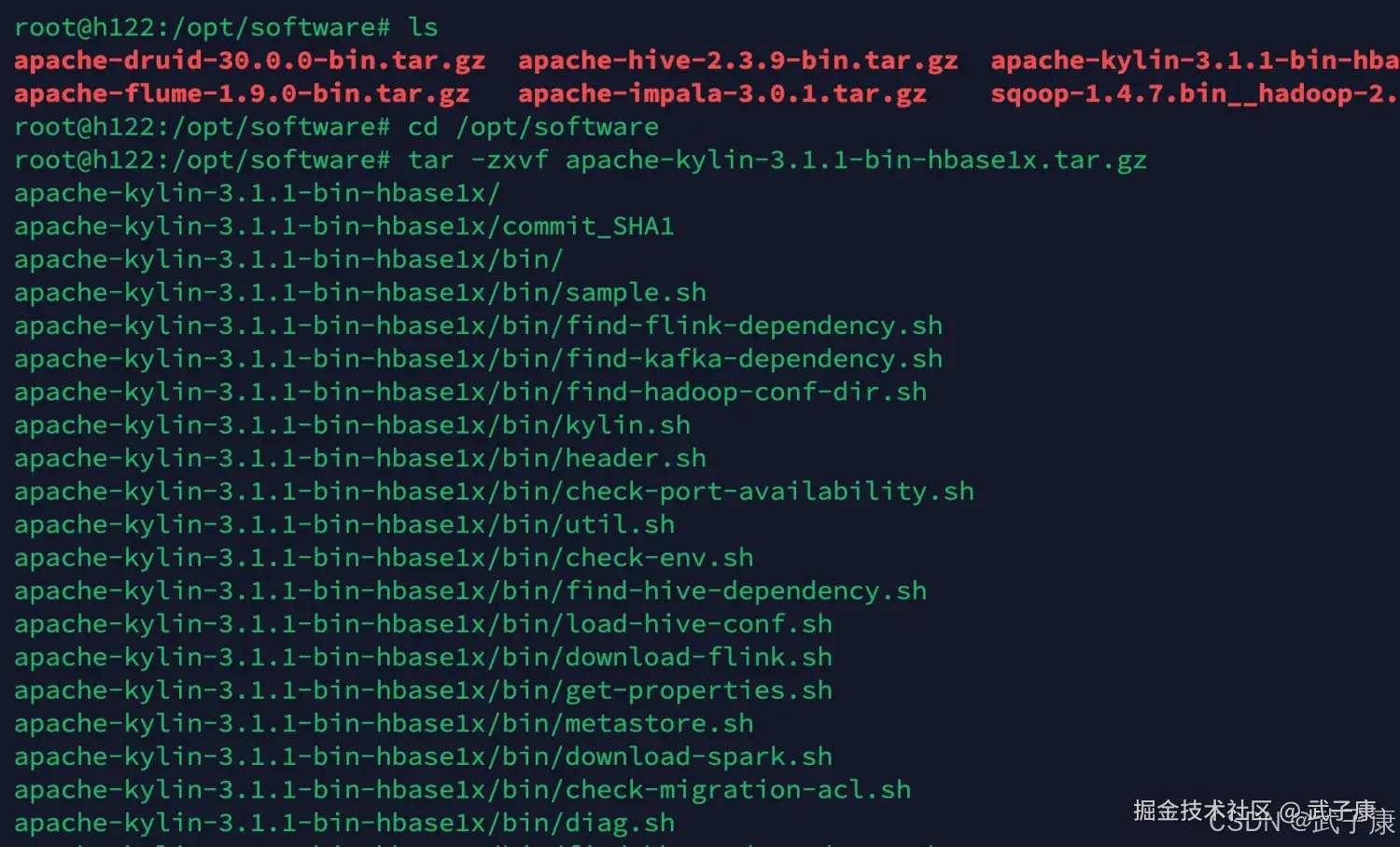
接着将其移动到servers目录,方便后续的管理: 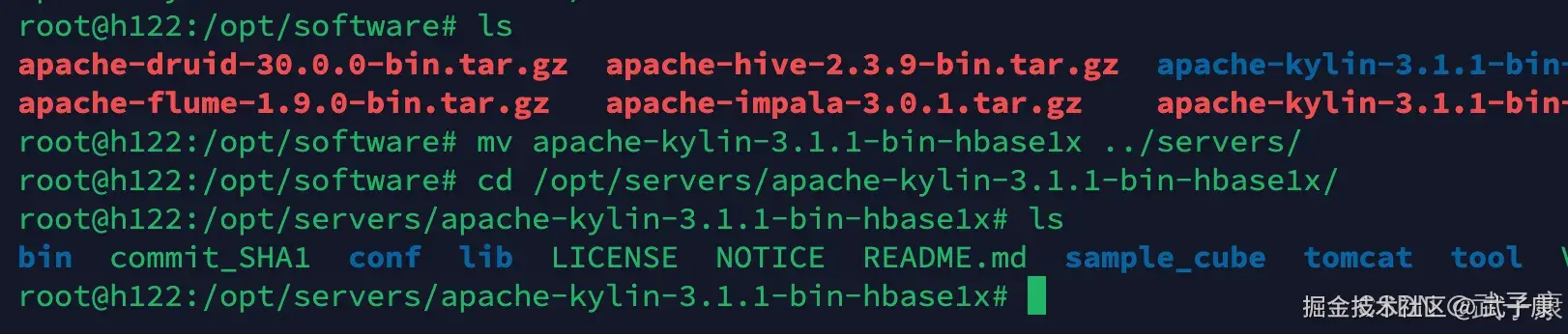
环境变量
shell
vim /etc/profile我们需要加入Kylin的环境变量:(记得刷新环境变量)
shell
export KYLIN_HOME=/opt/servers/apache-kylin-3.1.1-bin-hbase1x
export PATH=$PATH:$KYLIN_HOME/bin配置环境变量如下图所示: 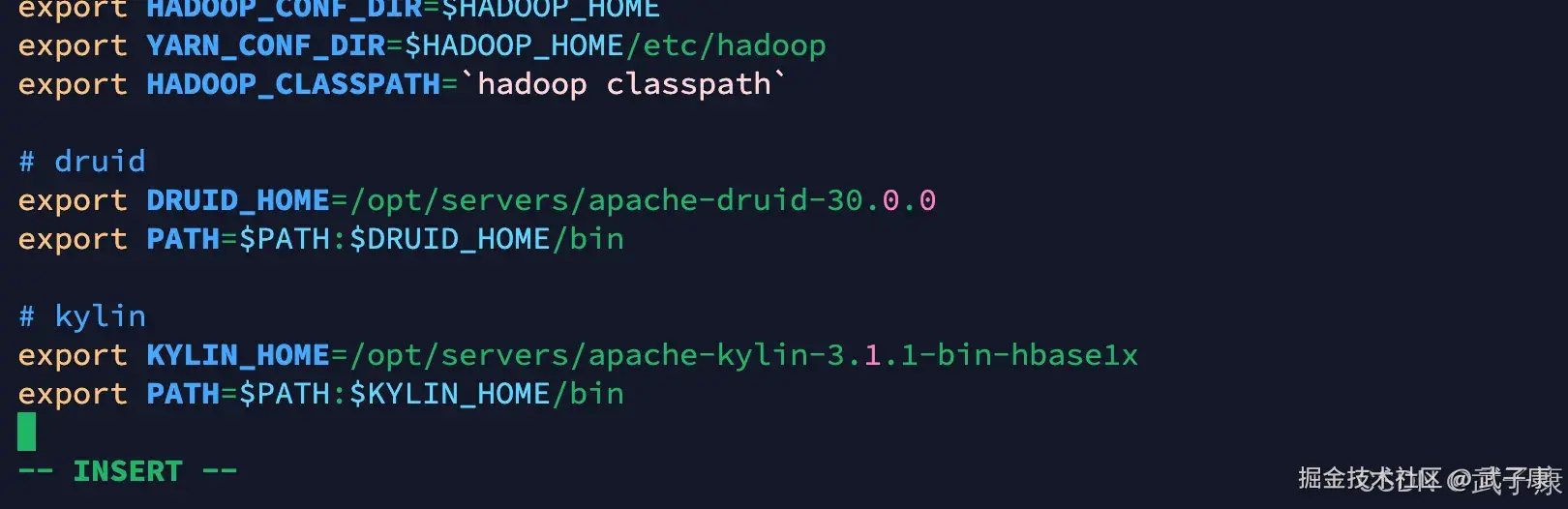
依赖组件
shell
cd $KYLIN_HOME/conf
ln -s $HADOOP_HOME/etc/hadoop/hdfs-site.xml hdfs-site.xml
ln -s $HADOOP_HOME/etc/hadoop/core-site.xml core-site.xml
ln -s $HBASE_HOME/conf/hbase-site.xml hbase-site.xml
ln -s $HIVE_HOME/conf/hive-site.xml hive-site.xml
ln -s $SPARK_HOME/conf/spark-defaults.conf spark-defaults.conf执行的结果如下图所示: 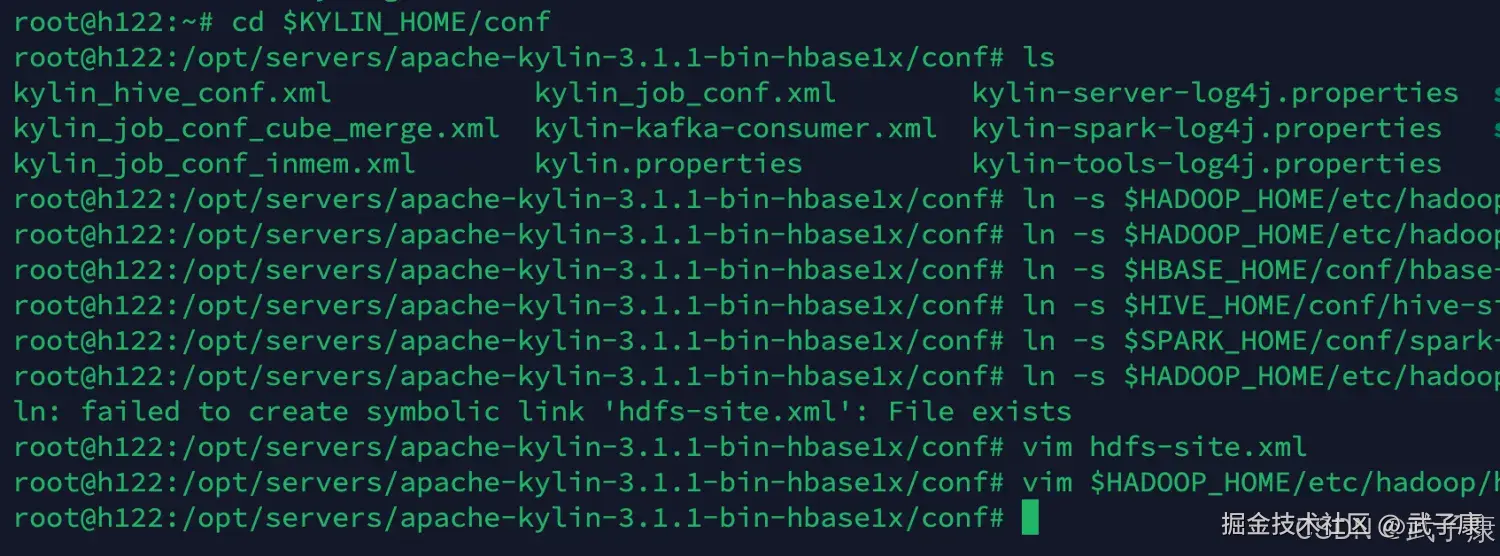
配置环境
我们需要修改 kylin.sh
shell
cd $KYLIN_HOME/bin
vim kylin.sh
# 需要写入这些依赖 防止后续报错
export HADOOP_HOME=/opt/servers/hadoop-2.9.2
export HIVE_HOME=/opt/servers/apache-hive-2.3.9-bin
export HBASE_HOME=/opt/servers/hbase-1.3.1
export SPARK_HOME=/opt/servers/spark-2.4.5-bin-without-hadoop-scala-2.12配置结果如下图所示: 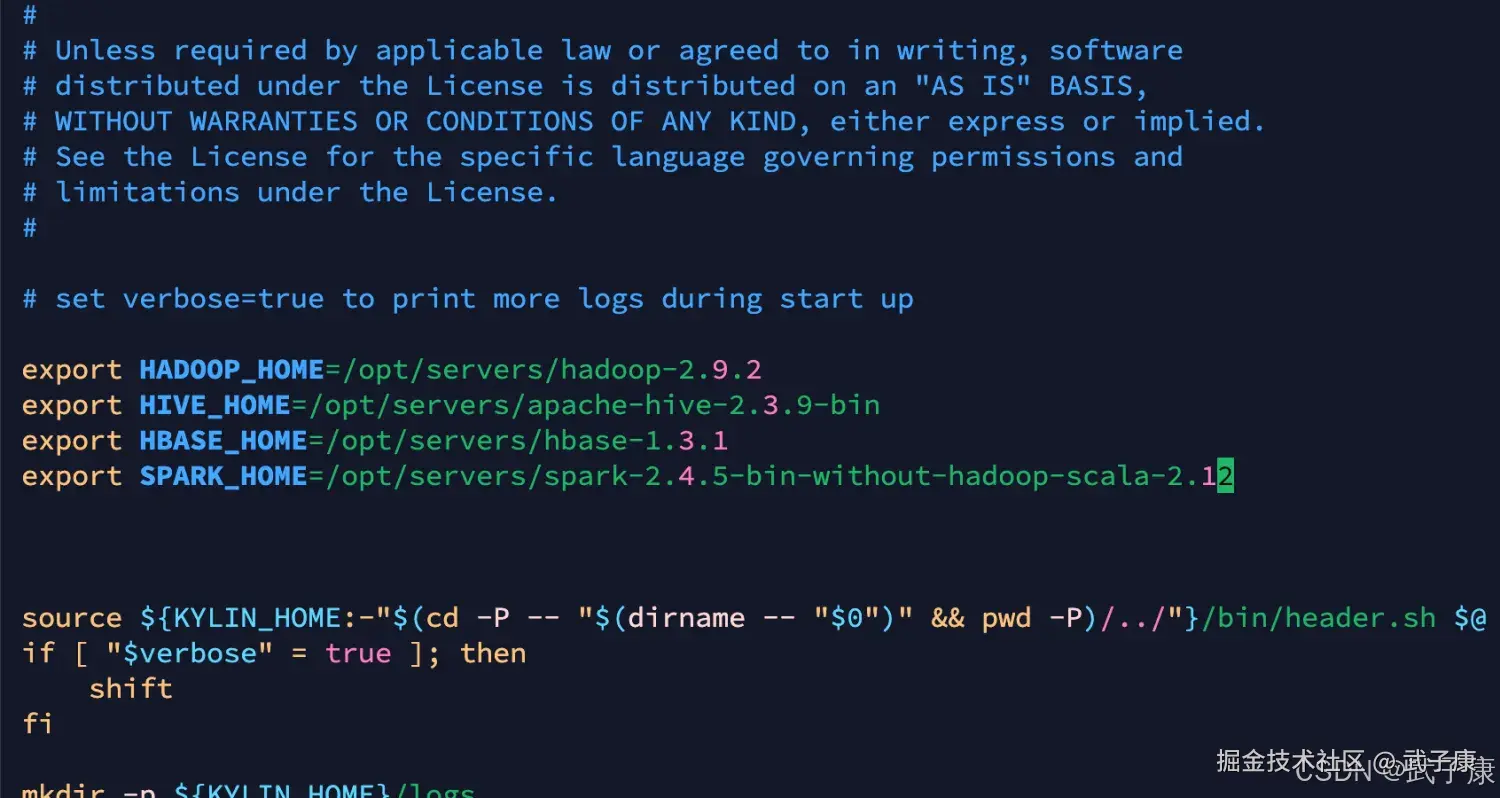
检查依赖
shell
$KYLIN_HOME/bin/check-env.sh我这里报错了,可能是之前的环境变量有问题: 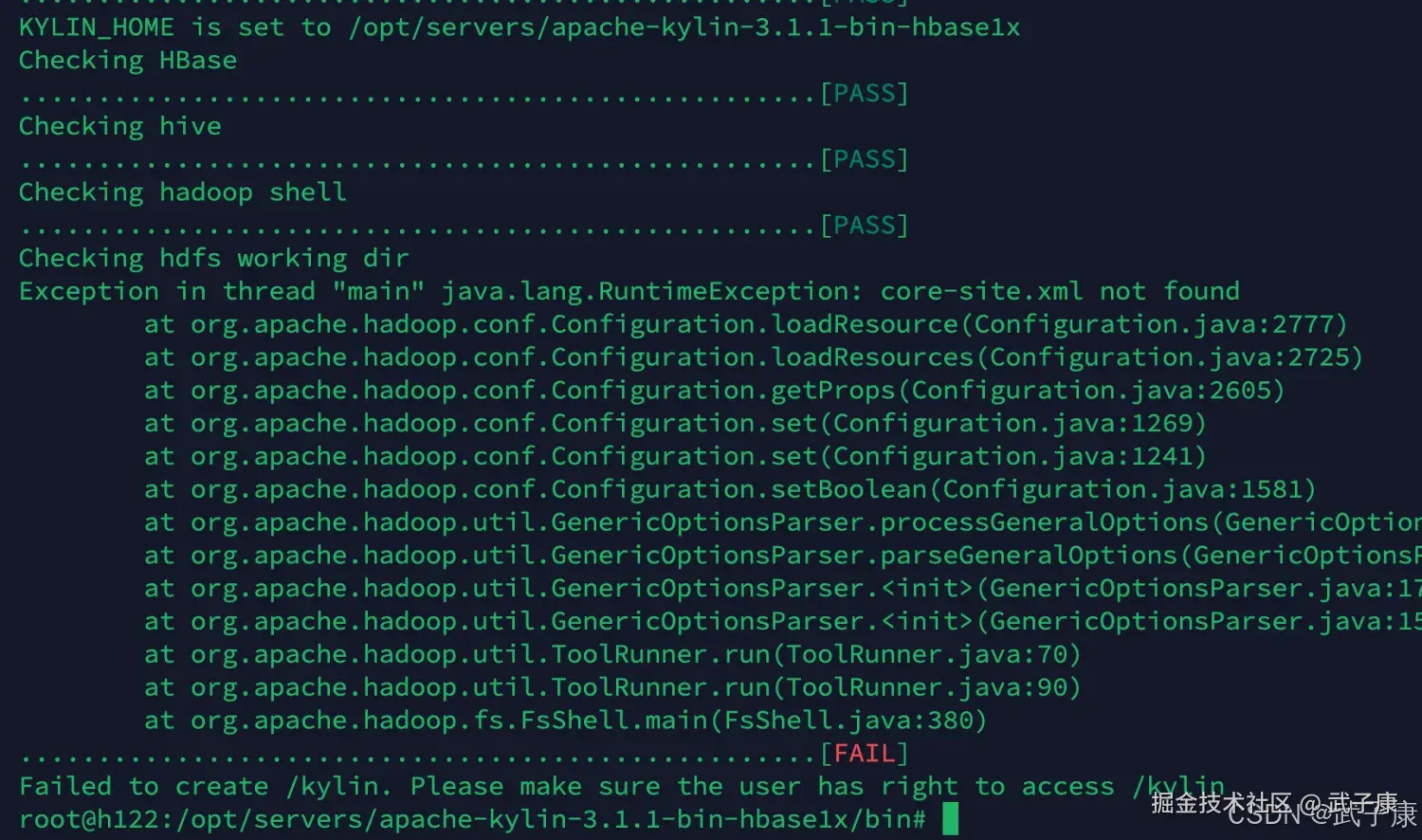 我找了一圈,看到 Flink YARN 这里HADOOP_CONF_DIR可能配置错了:
我找了一圈,看到 Flink YARN 这里HADOOP_CONF_DIR可能配置错了:
shell
# Flink YRAN
# export HADOOP_CONF_DIR=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`修改完的结果为如下:(这里我暂时注释了,防止我的FlinkYRAN以后不能用了) 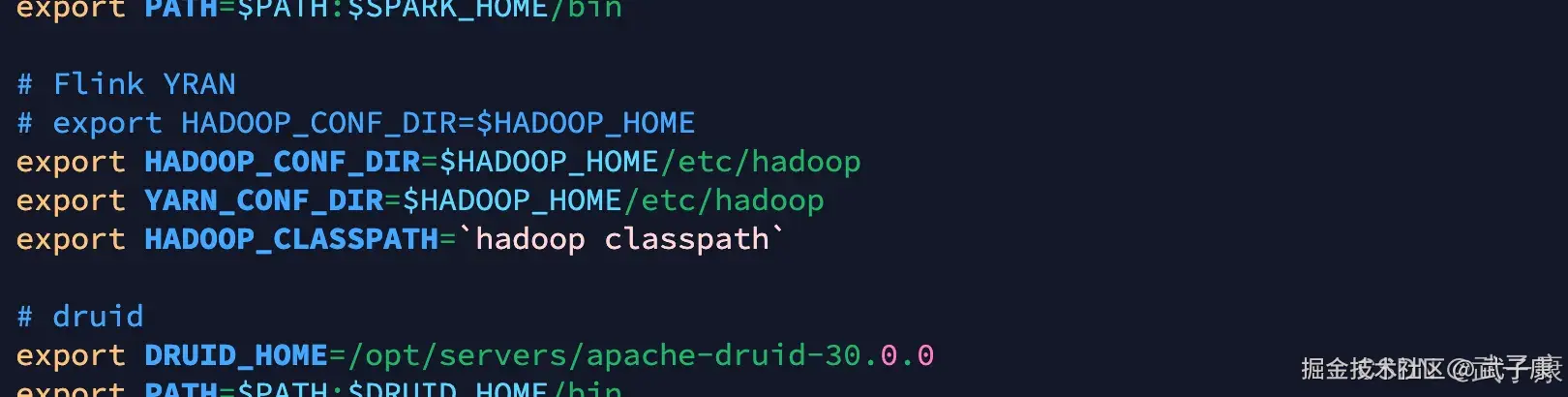 重新进行测试环境,检查顺利通过,看里边还有一些和Flink、Kafka的配置等,你需要的话可以加入:
重新进行测试环境,检查顺利通过,看里边还有一些和Flink、Kafka的配置等,你需要的话可以加入: 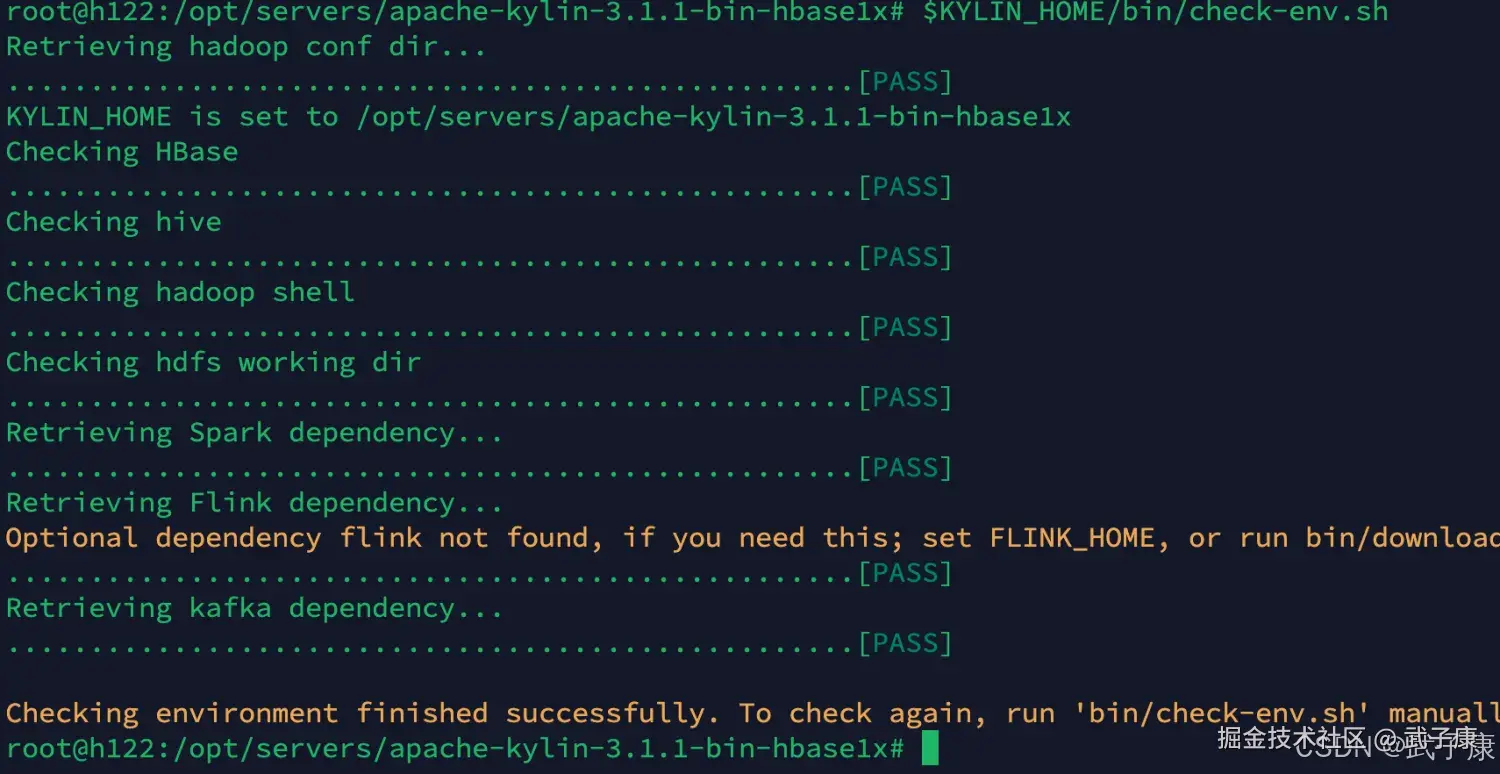
启动集群
ZooKeeper
启动 h121 h122 h123集群模式 需要每个节点都运行
shell
zkServer.sh startHDFS
启动 h121 h122 h123 h121运行即可,但是要检查确认
shell
start-dfs.shYRAN
启动 h121 h122 h123 h121运行即可,但是要检查确认
shell
start-yarn.shHBase
启动 h121 h122 h123 h121运行即可,但是要检查确认
shell
start-hbase.shMetastore
启动 h121 即可
shell
nohup hive --service metastore > /tmp/metastore.log 2>&1 &运行结果如下图: 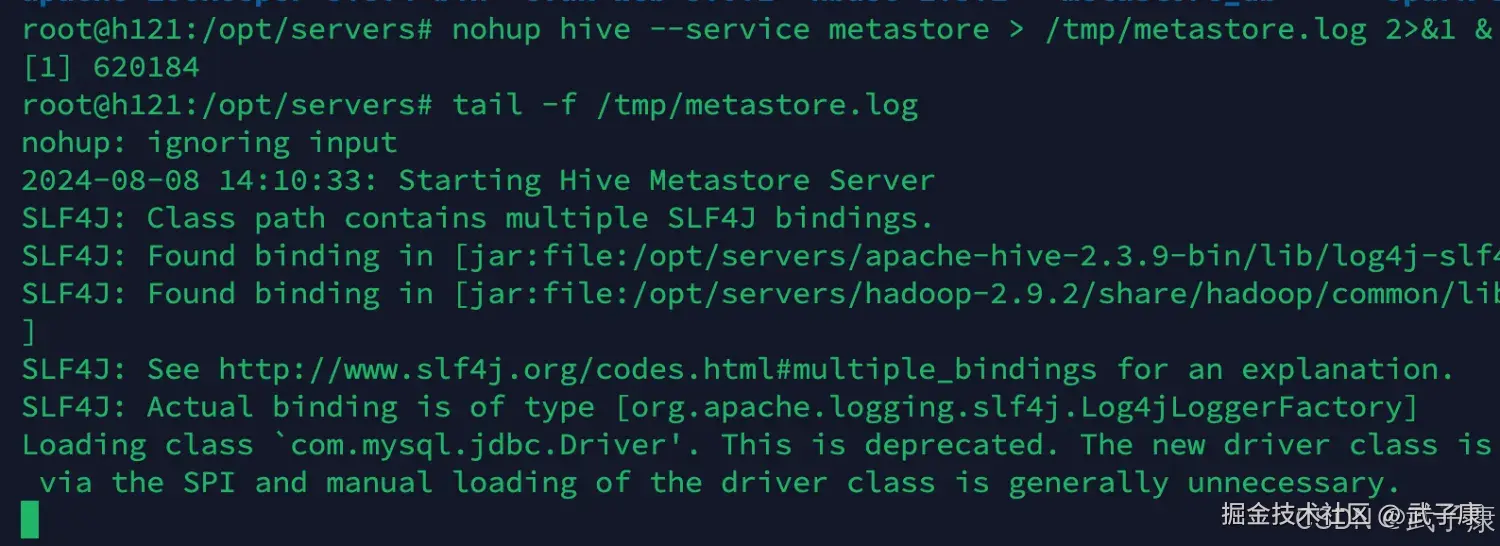
history server
启动 h121 即可
shell
mr-jobhistory-daemon.sh start historyserverKylin
启动 h122
shell
kylin.sh start运行过程如下图所示: 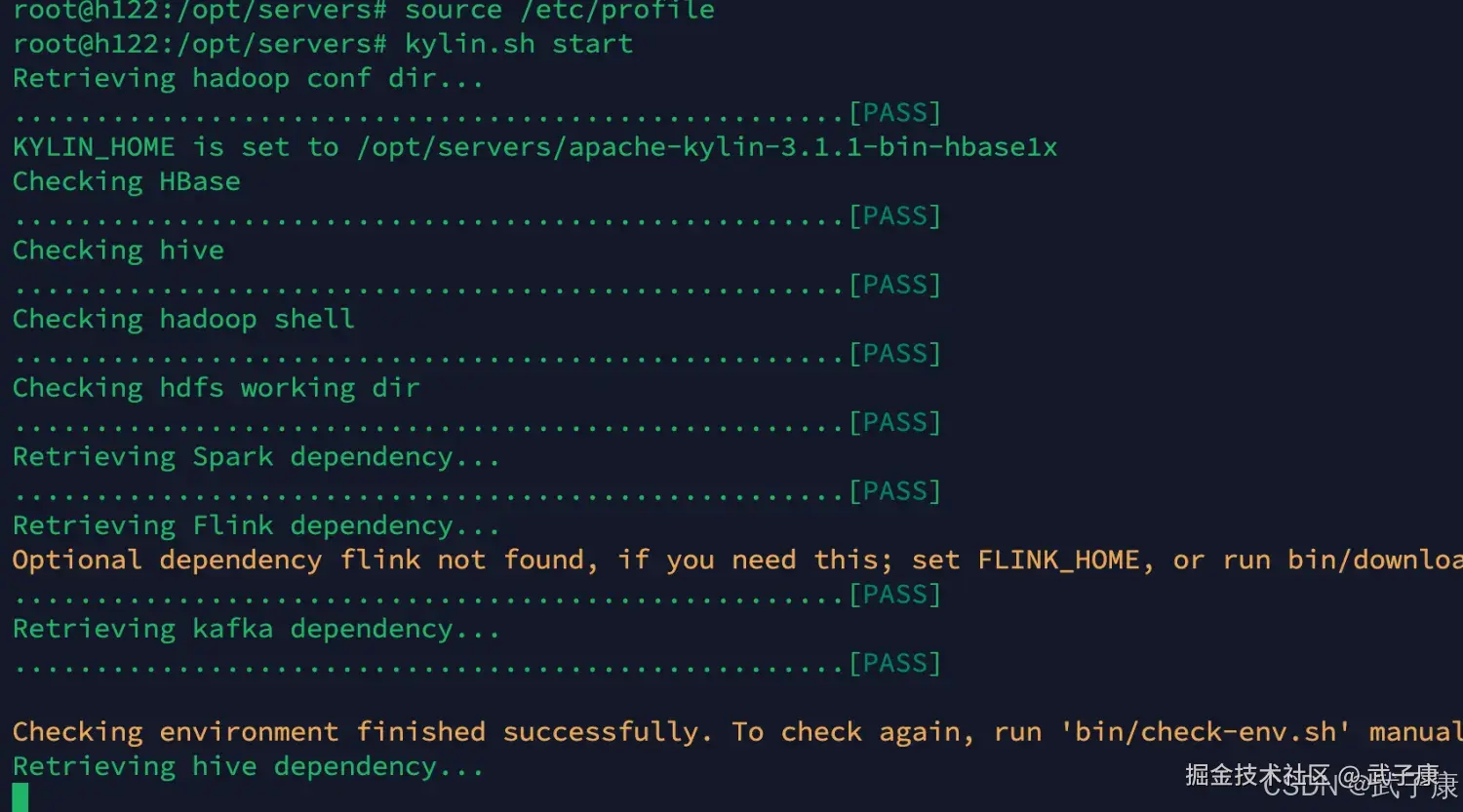
节点详情
h121
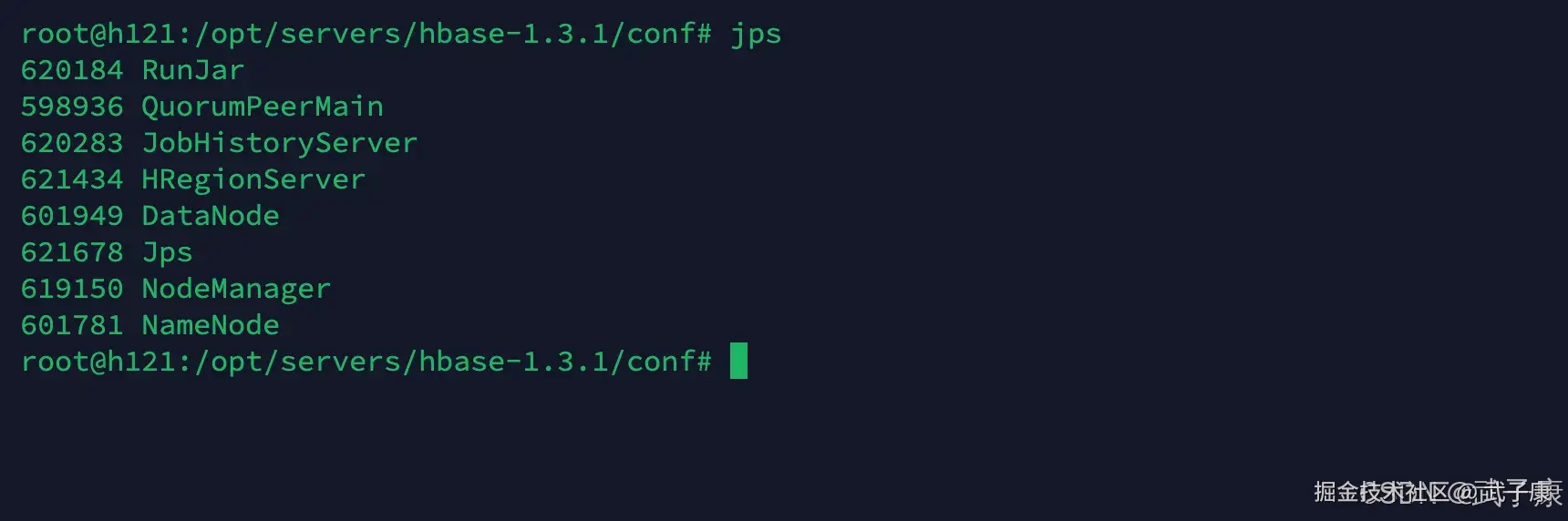 与上图对应一下:
与上图对应一下:
- Metastore
- Zookeeper
- HBase
- HDFS
- JPS跳过
- YARN
- Hadoop
h122
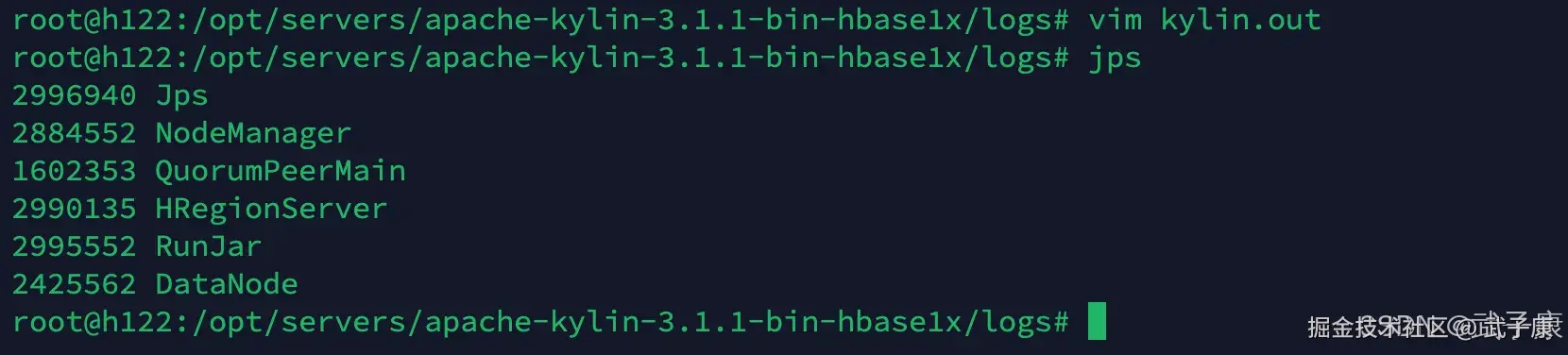
- JPS跳过
- YRAN
- ZooKeeper
- HBase
- 好像是Kylin
- HDFS
h123
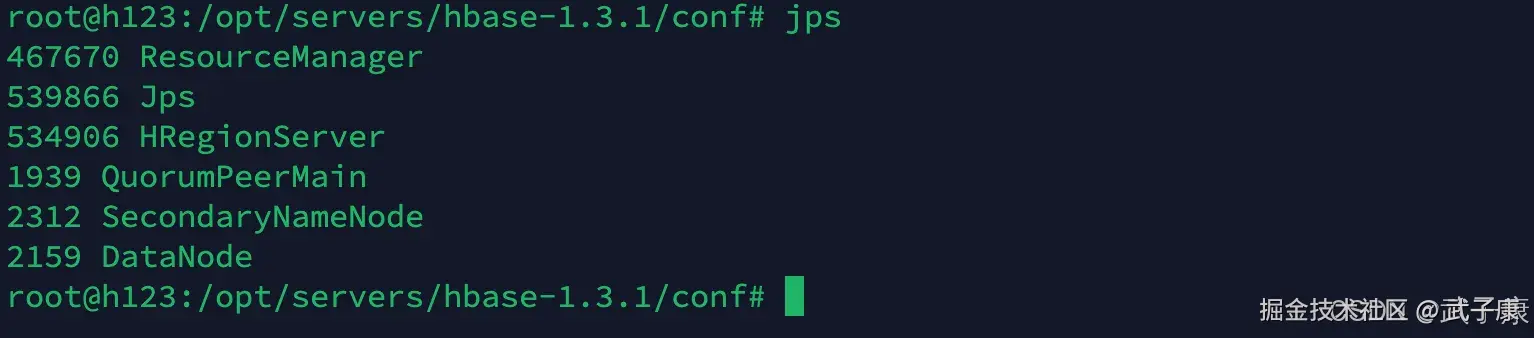
- YARN
- JPS跳过
- HBase
- ZooKeeper
- Hadoop
- HDFS
启动结果
shell
http://h122.wzk.icu:7070/kylin/login我们访问之后可以看到如下的内容: 
登录进入
shell
默认都是大写
账号 ADMIN
密码 KYLIN登录进入之后,就是如下的结果: 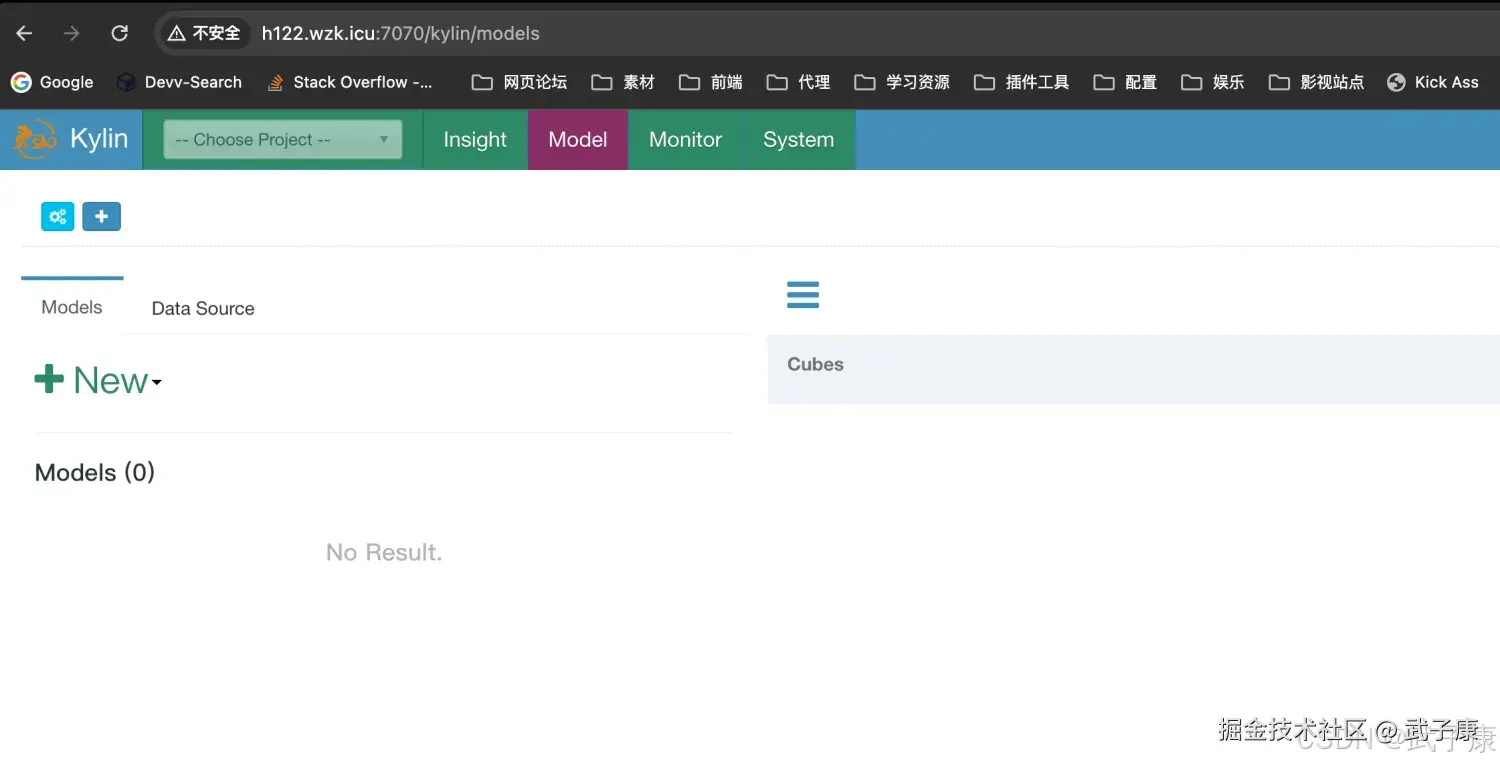
错误速查
| 症状 | 根因定位 | 修复 | |
|---|---|---|---|
| check-env.sh 自检失败,提示找不到 Hadoop 配置 | HADOOP_CONF_DIR 指向 $HADOOP_HOME 而非 .../etc/hadoop | 运行自检脚本输出 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop && export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop && export HADOOP_CLASSPATH=\hadoop classpath`后source /etc/profile` 重新自检 |
|
| Kylin 启动后连接 HBase 报 ZK 相关异常 | hbase.zookeeper.quorum 误写成 host1:2181,host2:2181 | 将 quorum 改为仅主机名(如 host1,host2),重启 HBase 与 Kylin | |
| 访问 :7070 无响应/拒连 | Kylin 未成功拉起;或防火墙/端口未放行 | ps -ef | grep Kylin、netstat -lntp 检查服务状态与端口 |
| 各类 "No FileSystem for scheme: hdfs"/找不到配置 | $KYLIN_HOME/conf 缺少软链到 Hadoop/HBase/Hive/Spark 配置目录 | 检查 $KYLIN_HOME/conf 依照文中命令补齐 core/hdfs/hbase/hive/spark 的软链并重启 | |
| Hive Metastore 连接拒绝/NoSuchObjectException | 未启动 Metastore 或 9083 被占用 | 检查 /tmp/metastore.log、`netstat -lntp |
grep 9083` |
| 登录失败/账号密码不对 | 账号密码大小写错误或自定义覆盖 | 使用默认大写 ADMIN/KYLIN;如改过,在 conf 内确认账号策略并重置 | |
| 启动时报 JDK 版本不兼容(常见于旧栈) | 使用了非 JDK8 | 切换至 JDK8 并确保 JAVA_HOME 与 PATH 指向一致 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-127 Qwen2.5-Omni 深解:Thinker-Talker 双核、TMRoPE 与流式语音
💻 Java篇持续更新中(长期更新)
Java-174 FastFDS 从单机到分布式文件存储:实战与架构取舍 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 正在更新,深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解