作者:曹霖
本系列文章将围绕东南亚头部科技集团的真实迁移历程展开,逐步拆解 BigQuery 迁移至 MaxCompute 过程中的关键挑战与技术创新。本篇为第十二篇,基于 阿里云MaxCompute 实现BigQuery 10万条SQL智能转写迁移。
注:客户为东南亚头部科技集团,文中用 GoTerra 表示。
一、项目背景
在全球化和数字化加速的浪潮下,越来越多的企业出于成本优化、合规要求和业务协同等原因,考虑将自建或三方大数据平台迁移至阿里云MaxCompute。本案例基于是东南亚头部科技集团 GoTerra,其业务生态覆盖网约车、电商、外卖、物流及金融支付等多个垂直领域,多年运行在 Google Cloud BigQuery 的数仓平台,基于综合优势分析规划全量迁移至阿里云 MaxCompute。
相比数据搬迁本身,迁移过程中一个更为棘手的挑战是:
- 10 万条 SQL 脚本的高质量快速转写。这其中既包含简短的分析 SQL,也包含上万行、嵌套极深的复杂 ETL 逻辑。
- 脚本广泛使用了 BigQuery 特有的语法、函数(如
UNNEST、SAFE_CAST、FORMAT_DATE)、复杂数据类型(ARRAY、STRUCT、BIGNUMERIC)和独有优化模式。 - 在历史业务沉淀下,不少 SQL 逻辑与业务规则、数据模型紧密绑定,稍有不慎便会影响数据产品准确性。
传统人力转写方式显然不现实。内部测算显示:
- 假设工程师日均高质量转写 5 条 SQL,则需 2 万人天;
- 即便 100 人并行,也要近 1 年才能完成,远超半年上线目标。
- 质量一致性无法保障,知识传递和规则固化存在巨大难度,回归测试成本高昂。
在这样背景下,团队必须找到 自动化+协同化的工程化解法,提升 SQL 转换率,实现大规模、可控的迁移。
二、解决方案
整体策略
我们基于阿里云 Cloud Migration Hub(CMH)/ Lake Migration Hub(LMH) 自动化迁移能力,配合自研规则引擎、AST(抽象语法树)转换、大语言模型(LLM)辅助和人工修正,构建"一条龙"的 工具主导+人工兜底 方案,并在迁移过程中沉淀可复用的 迁移知识库。
迁移整体分为两大阶段:
- 数据迁移:将 BigQuery 表数据平滑搬迁到 MaxCompute(包括全量及后续增量),使用在线迁移、MMS(MaxCompute Migration Serverless) 等。
- SQL 转写:借助 CMH/LMH 自动化批量转换 SQL,并通过规则迭代、LLM 增强、人工修正,实现高准确率交付。
数据迁移与SQL转写迁移方案的技术实现与优化
基于阿里云Cloud Migration Hub(CMH)/Lake Migration Hub(LMH)的自动化迁移能力,结合自主研发的规则引擎、抽象语法树(AST)转换技术、大语言模型(LLM)辅助及人工修正机制,我们构建了一套"工具主导+人工兜底"的端到端迁移解决方案。该方案不仅实现了从数据层到应用层的全栈迁移,还通过迁移知识库的持续沉淀,显著提升了迁移效率与准确性。迁移过程分为以下两个核心阶段:
第一阶段:数据迁移------保障数据平滑过渡的全生命周期管理
数据迁移是整个迁移工程的基础,其核心目标是将源端BigQuery的数据无缝迁移到阿里云MaxCompute,并确保迁移过程的高可用性、一致性和可扩展性。
工具与架构:采用阿里云在线迁移工具(Online Migration)和MMS(MaxCompute Migration Serverless)进行全量数据迁移。在线迁移工具通过分布式架构实现高吞吐量传输,支持断点续传和错误重试机制,确保大规模数据(如PB级)的稳定迁移。MMS则通过Serverless服务化模式,按需分配计算资源,降低运维复杂度。
第二阶段:SQL转写------自动化与人工协同的智能转换
SQL转写是迁移过程中技术难度最高的环节,涉及语法、函数、UDF(用户定义函数)及性能优化的复杂转换。我们通过"自动化为主,人工为辅"的分层策略,结合AST分析、规则引擎和LLM技术,实现高准确率的SQL转换。
1. 自动化转换引擎
- AST语法树解析 :基于ANTLR或自研解析器构建BigQuery SQL的抽象语法树(AST),逐层分析语法结构。例如,将BigQuery的
SELECT APPROX_COUNT_DISTINCT(column)转换为MaxCompute的SELECT COUNT(DISTINCT column),并通过AST节点替换实现。 - 规则引擎迭代优化 :
- 内置规则库 :预置超过200条迁移规则,覆盖数据类型映射(如BigQuery的
TIMESTAMP→MaxCompute的DATETIME)、函数替换(如SAFE函数的兼容性处理)、窗口函数调整等场景。 - 动态规则扩展:通过迁移知识库的实时反馈,持续迭代规则库。例如,若发现某类CASE-WHEN嵌套语句转换失败,可立即新增规则并重新运行转换流程。
- 内置规则库 :预置超过200条迁移规则,覆盖数据类型映射(如BigQuery的
- LLM辅助转换 :针对复杂或模糊的SQL语句(如自定义UDF或依赖源端特定语法的查询),利用大语言模型(如通义千问)进行语义解析和意图理解。例如,将BigQuery的
STRUCT类型转换为MaxCompute的LATERAL VIEW表达式,LLM可辅助生成等效逻辑的SQL代码。
2. 人工修正与质量控制
- 自动化缺陷定位:通过静态代码分析工具和动态执行测试(在测试环境中运行转换后的SQL),快速定位转换失败的语句。例如,若转换后的SQL在MaxCompute执行时因类型不匹配报错,系统将标记该SQL并提示可能的修复方向。
- 专家介入流程 :
- 优先级分级:根据错误类型(如语法错误、性能隐患、业务逻辑偏差)和影响范围,将问题分为P0-P3等级,优先处理高风险缺陷。
- 协同开发环境:提供基于IDE的联机调试工具,允许开发者直接修改转换后的SQL,并通过版本控制系统(如Git)管理修改记录,确保可追溯性。
- 迁移知识库的闭环反馈 :每次人工修正后,系统自动提取修正前后的SQL差异,并将其归类为新规则或案例存入知识库。例如,若某次修正解决了BigQuery的
ARRAY_AGG到MaxCompute的COLLECT_SET转换问题,该规则将被优先级提升,并在后续迁移中自动应用。
3. 转换后验证与优化
- 功能验证:在测试集群中执行转换后的SQL,对比源端和目标端的查询结果,确保业务逻辑一致性。
- 性能调优:利用MaxCompute的执行计划分析工具,识别转换后SQL的性能瓶颈(如全表扫描、Join顺序不当),并通过索引优化、分区裁剪或谓词下推等手段提升效率。
- 迁移知识库的持续优化:将验证过程中发现的性能优化策略(如特定函数转换方式)补充至知识库,形成"迁移-修正-优化"的闭环。
迁移知识库的核心价值与应用场景
迁移知识库是整个方案的关键支撑,其价值体现在以下方面:
-
规则复用与加速迭代 :通过积累迁移规则、缺陷案例和最佳实践,新项目可直接调用知识库中的已有规则,减少重复性开发。例如,某金融客户在迁移过程中发现BigQuery的
DATE_TRUNC函数在MaxCompute中需配合DATE_FORMAT使用,该规则可直接复用至其他项目。 -
风险预判与质量提升 :知识库中的历史案例可辅助迁移前的风险评估,例如提前识别BigQuery的
ML_*机器学习函数在MaxCompute中的替代方案,避免迁移后期的返工。 -
跨团队协作与知识传承:知识库采用统一的Markdown格式和分类标签(如按场景、工具、复杂度分类),支持多团队并行查阅与贡献,降低隐性知识流失风险。
技术优势与迁移成效
通过上述技术方案,我们实现了以下显著优势:
- 迁移效率提升:相比纯人工迁移,自动化工具将SQL转写效率提升80%以上,单项目迁移周期从数年缩短至数月。
- 准确性保障:结合规则引擎与LLM的双通道验证,部分场景SQL转换准确率超过90%,人工修正仅需处理约10%的复杂场景。
- 成本优化:通过MMS的Serverless模式和按需计费机制,降低数据迁移成本,同时减少因停机迁移导致的业务损失。
三、核心技术
1. SQL 转换主流技术:AST 驱动
相比复杂且易出错的正则/模板替换,AST 驱动的 SQL 转换具备可扩展、高可维护等优势:
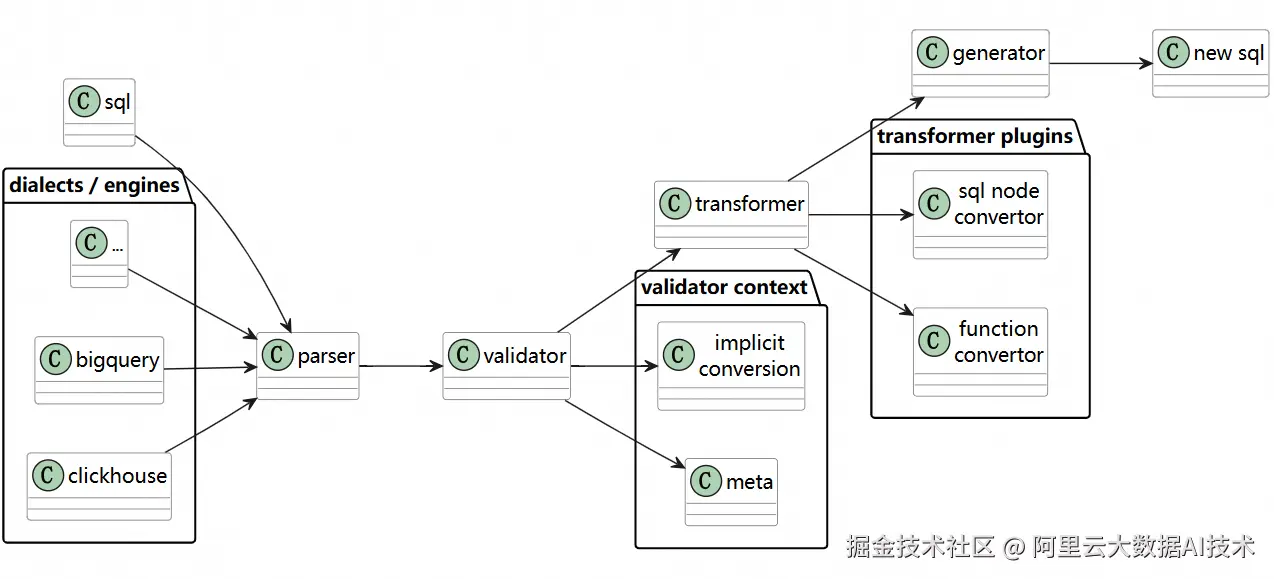
流程:
-
Parse:将 BigQuery SQL 解析为抽象语法树(AST),保留结构和节点类型(SELECT、FROM、FUNCTION_CALL 等)。
-
Transform:按规则库替换/重构 AST 节点,例如:
-
FORMAT_DATE('%Y-%m-%d', col)→TO_CHAR(col, 'yyyy-MM-dd') -
UNNEST(array_col)→LATERAL VIEW EXPLODE(array_col) -
隐式类型转换规则修正
-
-
Generate:输出目标 MaxCompute SQL。
优势:
- 对复杂嵌套、长 SQL 稳定性高
- 易于增量维护规则
- 可结合类型系统和元数据增强(RAG 思路)
2. SQL 转换示例
BigQuery SQL:
sql
SELECT FORMAT_DATE('%Y-%m-%d', order_time) AS order_date,
COUNT(DISTINCT user_id) AS uv
FROM `project.dataset.orders`
WHERE order_time >= DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)
GROUP BY order_date;MaxCompute SQL:
sql
SELECT TO_CHAR(order_time, 'yyyy-MM-dd') AS order_date,
COUNT(DISTINCT user_id) AS uv
FROM orders
WHERE order_time >= DATEADD(CURRENT_DATE, -30)
GROUP BY order_date;映射规则:
FORMAT_DATE→TO_CHAR(参数位置调整)DATE_SUB→DATEADD(顺序/符号兼容)- 去除 BigQuery 数据集前缀
- 类型映射:DATE 保持一致,BIGINT 替换 INT64
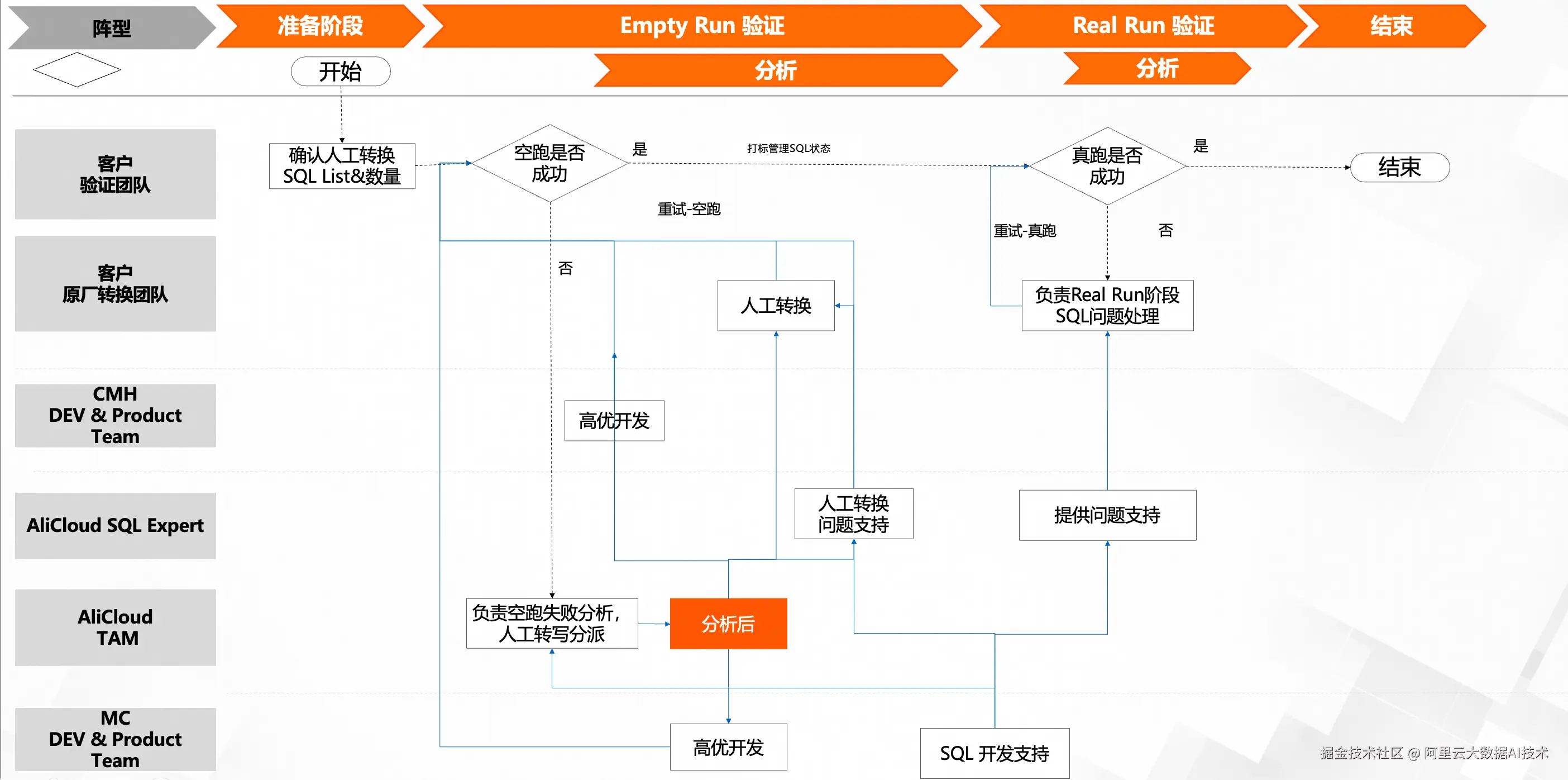
3. SQL转写流程
4. 行业实践与趋势
在多家企业的跨云 SQL 迁移中,总结出几条趋势:
- AST+规则库 是工程实践中相对高效可控的技术路径
- LLM 加持的混合模式 在处理尾部长尾复杂 SQL 时展现价值
- 知识库驱动持续优化 可复用性强,提升 ROI
- 平台自适配增强 比单纯靠转换器更能保障业务一致性
四、小结与未来展望
本项目成果:
- 在 4 个月内完成 SQL 转写任务,比计划提前 1 个月上线
- 工具转换率从 5%→80%,人工成本下降 70%+
- 沉淀上千条规则和案例,形成可复用的 SQL 迁移知识库
- 平台能力增强,提升未来兼容性
展望:
- 推动 CMH/LMH 全自动化迁移平台,支持更多方言(Snowflake、Databricks 等)
- 引入在线实时 SQL 转换 API,支持多云混合分析
- 结合执行计划与成本模型的自动化 SQL 优化器
- 依托知识库与 RAG 提高 LLM 转换一致性与可解释性
参考研究:
- 《Mallet: SQL Dialect Translation with LLM Rule Generation》