流处理技术的演变
在流处理技术发展的早期,Apache Storm 作为开路先锋,实现了低延迟处理,但在高吞吐与数据准确性方面存在局限,尤其难以提供精确一次的处理保证。
随后,以 Spark Streaming 为代表的微批处理架构登上舞台。该方法通过将数据流划分为细小批次进行处理,实现了精确一次的语义,可靠性显著提升,但其代价是丧失了部分实时性,同时在开发灵活性与运维复杂度上面临挑战。
正是在这样的背景下,Flink 应运而生。它实现了真正的逐事件连续处理,同时兼具低延迟、高吞吐与强一致性的优势,有效弥补了前两代方案的不足,成为现代流处理领域的代表性框架。
Flink起源
Flink起源自柏林技术大学的 Stratosphere 研究项目。该项目由 Volker Markl 教授主导,致力于解决云计算环境下的数据管理挑战。项目于 2014 年捐赠给 Apache 基金会并进入孵化,同年年底即晋升为顶级项目,发展十分迅速。
"Flink"在德语中意为"敏捷、灵巧",其 Logo 是一只尾巴带有 Apache 标志性颜色的松鼠,既呼应了名称的涵义,也巧妙地体现了其作为 Apache 顶级项目的身份。
官网: https://flink.apache.org/
演进里程碑
- 2014.03:进入 Apache 孵化器,开启开源之旅
- 2014.12:晋升 Apache 顶级项目,生态快速成长
- 2015.04:发布革命性 0.9 版本,确立技术方向
- 2019.01:阿里巴巴收购 Data Artisans,注入商业动力
- 2019.08:融合 Blink 引擎,性能实现跨越式提升
产品概述
Apache Flink 作为分布式流处理框架的领军者,在有界与无界数据流上实现了有状态计算的突破性进展。其核心理念"数据流上的状态计算"不仅重新定义了流处理的边界,更为实时数据处理设立了全新标准。
Flink的差异化价值:
- 真正的流处理引擎:毫秒级延迟,非传统的微批处理架构
- 完整的时间语义:支持事件时间、处理时间、摄取时间多维时间处理
- 精确一次一致性:在分布式环境下确保数据处理的不重不漏
- 弹性容错机制:轻量级检查点保障故障瞬间自动恢复
- 多语言生态支持:Java、Scala、Python、SQL全方位覆盖
技术选型:流处理引擎深度对比
| 维度 | Flink | Spark | Storm |
|---|---|---|---|
| 处理模型 | 原生流处理 | 微批处理 | 原生流处理 |
| 延迟级别 | 毫秒级 | 秒级 | 毫秒级 |
| 状态管理 | 内置丰富支持 | 外部依赖 | 有限支持 |
| Exactly-Once | 原生支持 | 支持 | At-Least-Once |
| 吞吐性能 | 极高 | 高 | 中等 |
Flink基本架构
Flink集群的运行时架构遵循经典的主从模式。其中,JobManager 作为"大脑"承担管理职责,而一个或多个 TaskManager 作为"身体"负责执行计算。ResourceManager 和 Dispatcher 则是支撑大脑高效运作的关键职能模块。
JobManager: 是Master角色,是整个Flink应用执行过程的协调者,其核心职责远超"作业调度"。
- 作业调度与执行图管理:接收客户端提交的JobGraph,将其转换为ExecutionGraph,并根据调度策略将具体的Task分配给TaskManager的Slot执行。
- 检查点协调:这是实现容错和精确一次语义的关键。JobManager会定期向所有TaskManager发送"检查点屏障",触发所有算子的状态快照。它负责协调这个全局快照的创建、确认与存储。
- 故障恢复:当TaskManager或任务发生故障时,JobManager会接管恢复流程。它会从最近一次成功的检查点 或保存点 重新启动整个数据流图,将状态回滚到故障前的瞬间,确保数据不丢失、处理不重复。
- 资源管理:与ResourceManager协同工作,为作业申请所需的计算资源。
TaskManager: 是Worker角色,是实际执行计算任务的"苦力",在JVM进程中运行一个或多个线程。
- 任务执行:每个TaskManager包含一定数量的任务槽。实际的数据计算,如map、filter、keyBy等算子逻辑,都在TaskManager的Slot中执行。
- 数据交换:负责在同一个Flink作业内部的不同Task之间进行数据交换。它们之间通过内存、网络进行高效的数据传输,构成了数据流管道。
- 状态存储:算子的状态直接存储在TaskManager的内存中或由它管理的RocksDB实例里。在检查点时,TaskManager将状态快照持久化到远程存储。
ResourceManager: 负责管理整个集群的底层计算资源------Slot。需要注意的是,它与YARN或Kubernetes等外部资源管理器协同工作。
- Slot资源管理:管理所有TaskManager上可用的Slot资源池,像一个资源中介。
- 资源分配与扩缩容:当JobManager为作业申请资源时,ResourceManager从池中提供空闲的Slot。如果没有足够的空闲Slot,它会申请资源,启动新的TaskManager。在资源空闲时,它会释放多余的TaskManager。
- 生命周期管理:负责启动和停止TaskManager实例。
Dispatcher: 为所有提交到集群的作业提供了一个统一的REST接口入口,尤其在Flink应用集群和Session集群模式下扮演重要角色。
- 作业提交入口:提供一个Web UI和REST服务,用于接收和提交客户端作业。
- 作业管理:为每个提交的作业启动一个独立的JobManager,并管理作业会话的生命周期。
- 提供服务发现:它帮助客户端找到并连接到指定作业的JobManager。
实际工作流程
一个典型的作业提交流程可以清晰地展示这四个组件如何协同:
- 提交:客户端通过Dispatcher的REST接口提交作业JAR包和配置。
- 接管:Dispatcher启动一个的JobManager,并将作业移交给它。
- 申请资源:JobManager向ResourceManager申请执行作业所需的Slot。
- 分配资源:ResourceManager从资源池中提供可用的TaskManager Slot;如果资源不足,则向外部资源平台申请启动新的TaskManager。
- 部署任务:JobManager将具体的Task部署到分配好的Slot上。
- 执行与监控:TaskManager执行任务,并向JobManager汇报状态和心跳。JobManager持续监控整个执行过程,负责检查点和故障恢复。
应用场景
- 事件驱动:基于实时事件流触发计算、状态更新或外部动作。典型应用包括反欺诈、异常检测、规则型告警和业务流程监控等。
- 数据分析:从原始数据中提取有价值的信息与指标,结果可写入外部数据库,或作为内部状态持续维护。
- 数据管道:数据管道与ETL作业类似,负责对数据进行转换、丰富,并将其从一个存储系统迁移至另一个。与传统周期性ETL不同,Flink以持续流模式运行,实现更实时的数据处理。
主要组件
- 存储层:Flink本身不提供分布式文件系统,其分析处理多依赖于外部存储系统。
- 调度层:Flink内置一个轻量级资源调度器------独立调度器,可在无外部资源管理器的情况下使用。同时,Flink也支持运行在Hadoop YARN、Apache Mesos等主流集群管理器上。
- 计算层:Flink的核心是一个分布式计算引擎,负责对跨多个工作节点或整个集群的计算任务进行调度、分发与监控,为上层API提供基础运行服务。
- 工具层:在Flink Runtime之上,提供了面向流处理的DataStream API和批处理的DataSet API。
Flink编程模型
Flink提供了一套标准化的编程模式,使开发者能够专注于业务逻辑,而无需处理性能、高可用性等底层复杂问题。
- 有界数据集:具有明确的开始与结束边界,构成有限的数据集合。
- 批处理:针对有界数据集进行的计算通常称为批处理。
- 无界数据集:只有开始而没有结束的数据流,会持续不断地生成新数据,没有边界。
- 流处理:对无界数据集的实时处理称为流处理。
- 有界与无界的统一:有界与无界数据集是相对概念。例如,每分钟、每小时或每天对数据进行处理,可视为在时间窗口内的有界处理;而有界数据也可以逐条发送至计算引擎,模拟无界流的处理方式。Flink正是通过这种机制,将有界与无界数据统一在同一套流式引擎中,实现了批处理与流处理的一体化支持。
Flink快速体验
搭建Maven工程
xml
<properties>
<flink.version>1.17.2</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<artifactId>slf4j-api</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<artifactId>slf4j-api</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.36</version>
<optional>true</optional>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>3.1.1-1.17</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.7</version>
</dependency>
</dependencies>批处理
java
public class WordCountBatch {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取数据源
DataStream<String> textStream = env.fromCollection(Arrays.asList(
"java,c++,php,java,spring",
"hadoop,scala",
"c++,jvm,html,php"
));
// 3. 数据转换
DataStream<Tuple2<String, Integer>> wordCountStream = textStream
// 对数据源的单词进行拆分,每个单词记为1,然后通过out.collect将数据发射到下游算子
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word : value.split(",")) {
out.collect(new Tuple2<>(word, 1));
}
}
}
)
// 对单词进行分组
.keyBy(value -> value.f0)
// 对某个组里的单词的数量进行滚动相加统计
.reduce((a, b) -> new Tuple2<>(a.f0, a.f1 + b.f1));
// 4. 数据输出。字节输出到控制台
wordCountStream.print("WordCountBatch--->").setParallelism(1);
// 5. 启动任务
env.execute(WordCountBatch.class.getSimpleName());
}
}输出结果
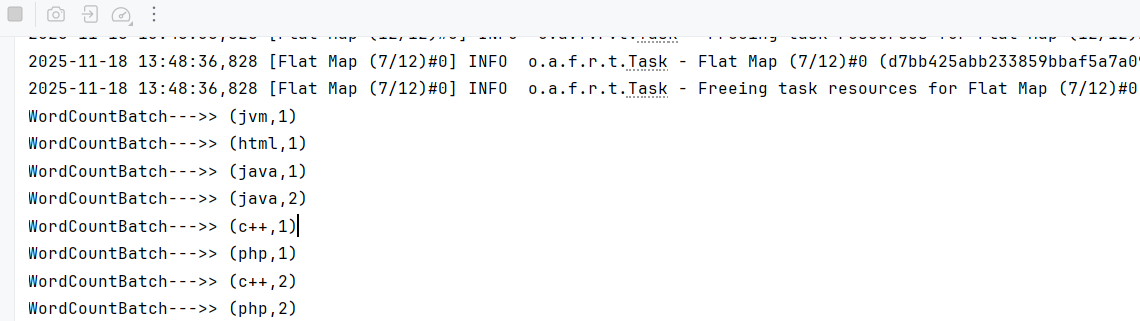
流处理
java
public class WordCountStream {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取数据源
DataStream<String> textStream = env.socketTextStream("localhost", 9999, "\n");
// 3. 数据转换
DataStream<Tuple2<String, Integer>> wordCountStream = textStream
// 对数据源的单词进行拆分,每个单词记为1,然后通过out.collect将数据发射到下游算子
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word : value.split("\s")) {
out.collect(new Tuple2<>(word, 1));
}
}
}
)
// 对单词进行分组
.keyBy(value -> value.f0)
// 对某个组里的单词的数量进行滚动相加统计
.reduce((a, b) -> new Tuple2<>(a.f0, a.f1 + b.f1));
// 4. 数据输出。字节输出到控制台
wordCountStream.print("WordCountStream=======").setParallelism(1);
// 5. 启动任务
env.execute(WordCountStream.class.getSimpleName());
}
}输出结果
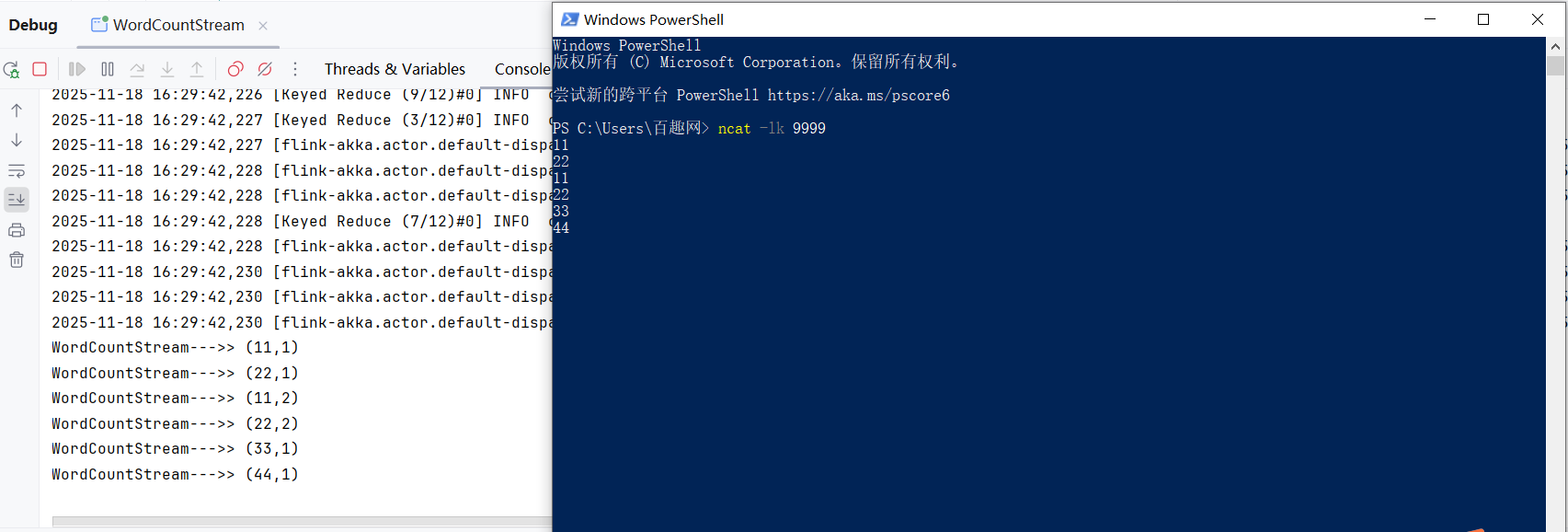
注意:windows环境下需要安装Nmap,然后通过Nmap连接socket。
下载地址:https://nmap.org/download.html 只需要一路点点点即可
注意上面我们都是在本地执行的,并没有放在Flink里面跑。
Flink学习网:https://flink-learning.org.cn/