Kratos微服务轻松对接EFK日志系统
在早期的单体服务时代,如果想要在生产环境中通过日志去定位业务逻辑的Bug或者性能问题,那么我们需要让运维人员逐个远程登入服务器,逐个服务实例去查询日志文件,这样排查问题的效率是相当的低,当线上发生了紧急状况的时候,人都要急死,却又无法有效率的排查出问题所在,更不用说解决问题。
而在微服务时代,服务实例部署在不同的物理机上,各个微服务的日志也被分散储存在不同的物理机上。当服务集群足够大,成百上千,甚至上万,此时再使用上述的传统方式查阅日志,那已经是不可完成的任务。因此,我们需要集中化管理分布式系统中的日志,其中有开源的组件如Syslog,用于将所有服务器上的所有服务的日志进行收集、汇总。
日志收集是微服务可观测性中不可或缺的一部分。日志对于调试问题和监视集群状况非常有用。
然而,集中化收集日志文件之后,并非就万事大吉了,我们还有一系列的问题需要解决:如何对日志文件进行分析和查询。哪些服务有报警和异常,这些也都需要有详细的统计。所以,以前出现线上故障时,经常会看到开发和运维人员下载服务的日志,并基于 Linux 下的一些命令(如 grep、awk 和 wc 等)进行检索和统计。这样的方式不仅工作量大,并且效率低下,而且对于要求更高的查询、排序和统计等操作,以及庞大的集群机器数量,无法胜任。
EFK(Elasticsearch、Fluentd、Kibana)是当下微服务中比较流行的分布式日志服务解决方案。以下,我们将就EFK应用于Kratos微服务,逐步展开讲解。
EFK 分布式日志系统
EFK 是一个完整的分布式日志收集系统,很好地解决了上述提到的日志收集难,检索和分析难的问题。
EFK 分别是指:
- Elasticsearch 是一个分布式搜索引擎。具有高可伸缩、高可靠、易管理等特点。可以用于全文检索、结构化检索和分析,并能将这三者结合起来。Elasticsearch 基于 Lucene 开发,现在使用最广的开源搜索引擎之一,Wikipedia 、StackOverflow、Github 等都基于它来构建自己的搜索引擎。
- Fluentd 是一个开源的数据收集器,我们可以在微服务集群节点上安装 Fluentd,通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。Fluentd的日志必须以JSON为载体,日志内容没有限制。
- Kibana 是一个可视化化平台。Kibana 用于搜索、分析和可视化存储在 Elasticsearch 指标中的日志数据,是一个 Web 网页。Kibana 利用 Elasticsearch 的 REST 接口来检索数据,调用 Elasticsearch 存储的数据,将其可视化。它不仅允许用户自定义视图,还支持以特殊的方式查询和过滤数据。
如果,我们将这一系列组件视为 MVC 模型,那么就是:
- Fluentd 对应逻辑控制 Controller 层
- Elasticsearch 是一个数据模型 Model 层,
- Kibana 则是视图 View 层。
Elasticsearch 基于 Java 编写实现,Kibana 使用的是 node.js 框架,Fluentd 使用Ruby语言编写。
部署EFK
我们使用Docker来部署EFK,首先,让我们先编写一个Docker-Compose的配置文件:
yml
version: '3'
networks:
app-tier:
driver: bridge
services:
elasticsearch:
image: docker.io/bitnami/elasticsearch:latest
networks:
- app-tier
ports:
- "9200:9200"
- "9300:9300"
environment:
- ELASTICSEARCH_USERNAME=elastic
- ELASTICSEARCH_PASSWORD=elastic
- xpack.security.enabled=true
- discovery.type=single-node
- http.cors.enabled=true
- http.cors.allow-origin=http://localhost:13580,http://127.0.0.1:13580
- http.cors.allow-headers=X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
- http.cors.allow-credentials=true
fluentd:
image: docker.io/bitnami/fluentd:latest
networks:
- app-tier
depends_on:
- "elasticsearch"
volumes:
- /data/fluentd/conf:/opt/bitnami/fluentd/conf
- /data/fluentd/log:/opt/bitnami/fluentd/log
ports:
- "24224:24224"
- "24224:24224/udp"
kibana:
image: docker.io/bitnami/kibana:latest
networks:
- app-tier
depends_on:
- "elasticsearch"
ports:
- "5601:5601"
environment:
- KIBANA_ELASTICSEARCH_URL=elasticsearch
- KIBANA_ELASTICSEARCH_PORT_NUMBER=9200然后,我们使用以下命令来创建Docker容器,并且在后台运行:
shell
docker-compose up -d这还不算完,我们还需要修改Fluentd的配置,原始的配置,日志只记录在Fluentd本地的文本文件里面。我们需要修改配置,以使之能够将日志输入到ElasticSearch。
原始的配置文件如下所示:
xml
<source>
@type forward
@id input1
@label @mainstream
port 24224
</source>
<filter **>
@type stdout
</filter>
<label @mainstream>
<match docker.**>
@type file
@id output_docker1
path /opt/bitnami/fluentd/logs/docker.*.log
symlink_path /opt/bitnami/fluentd/logs/docker.log
append true
time_slice_format %Y%m%d
time_slice_wait 1m
time_format %Y%m%dT%H%M%S%z
</match>
<match **>
@type file
@id output1
path /opt/bitnami/fluentd/logs/data.*.log
symlink_path /opt/bitnami/fluentd/logs/data.log
append true
time_slice_format %Y%m%d
time_slice_wait 10m
time_format %Y%m%dT%H%M%S%z
</match>
</label>
# Include config files in the ./config.d directory
@include config.d/*.conf我们需要将<match **>节点修改为如下配置:
xml
<match **>
@type elasticsearch
host host.docker.internal
port 9200
index_name fluentd
type_name log
</match>上述配置,实际上是利用了fluent-plugin-elasticsearch插件,将日志导入到ElasticSearch。
Kratos微服务对接EFK
首先,我们需要下载Fluent的一个封装:
shell
go get github.com/go-kratos/kratos/contrib/log/fluent/v2然后创建日志记录器:
go
fluentLogger "github.com/go-kratos/kratos/contrib/log/fluent/v2"
// NewFluentLogger 创建一个日志记录器 - Fluent
func NewFluentLogger(endpoint string) log.Logger {
wrapped, err := fluentLogger.NewLogger(endpoint)
if err != nil {
panic("create fluent logger failed")
return nil
}
return wrapped
}现在,所有Kratos的日志就都注入到了EFK当中去了。
Kibana查询日志
Kibana的访问端口是5601,因此我们可以访问:http://127.0.0.1:5601/
当我们第一次进入Kibana,一片空白,什么都没有。那么,我们需要添加Data View,相当于创建了一个日志的查询视图。
我们点击:Discover -> Create a data view,之后,我们将看到如下的界面:
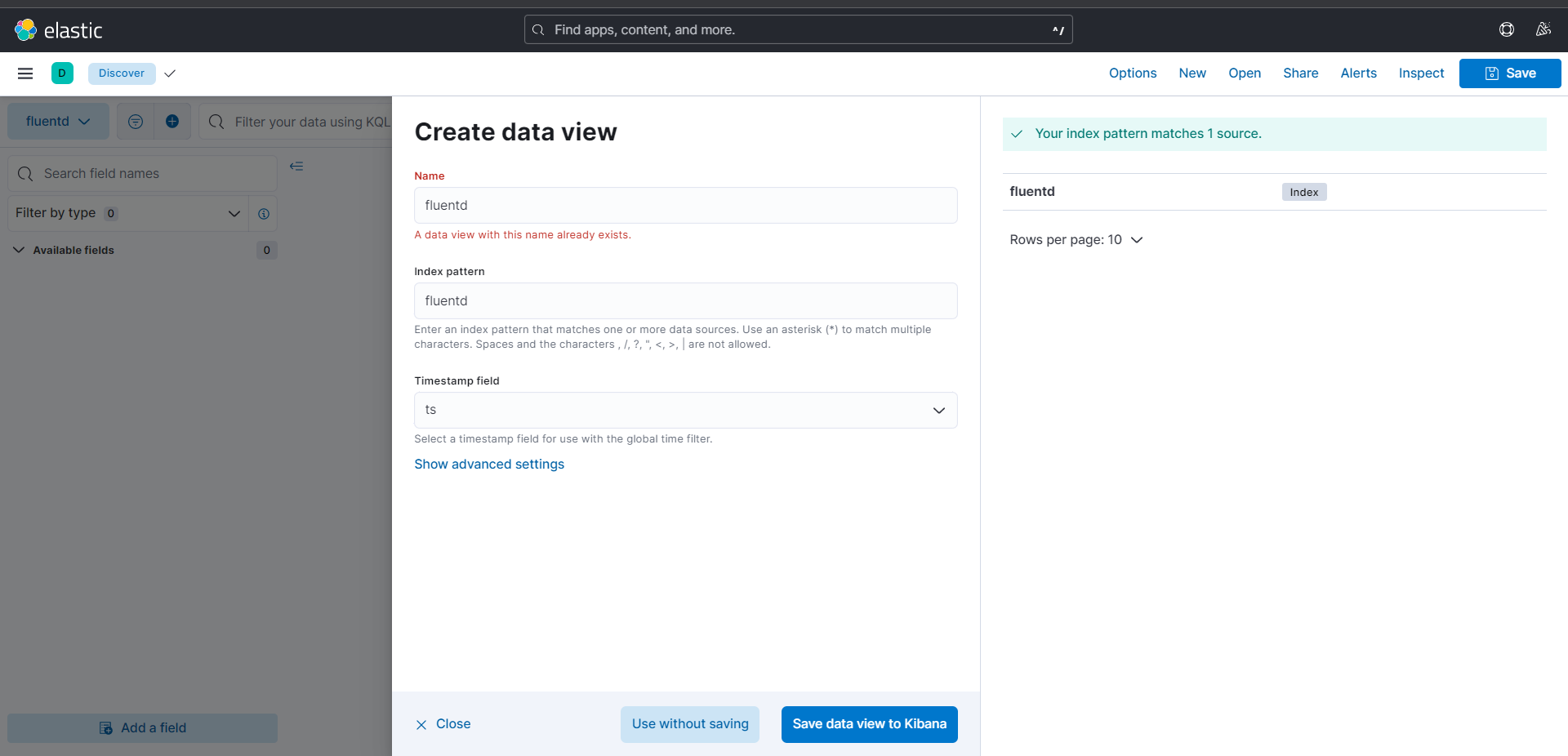
在上面,我们在fluent里面设置了elasticsearch的索引为:fluent,所以,我们在Index pattern里面填写fluent,即可。Timestamp field我们可以从下拉框里面找到ts,选中即可。然后,我们就可以点击Save data view to Kibana创建视图了。
我们将看到日志查询的视图:
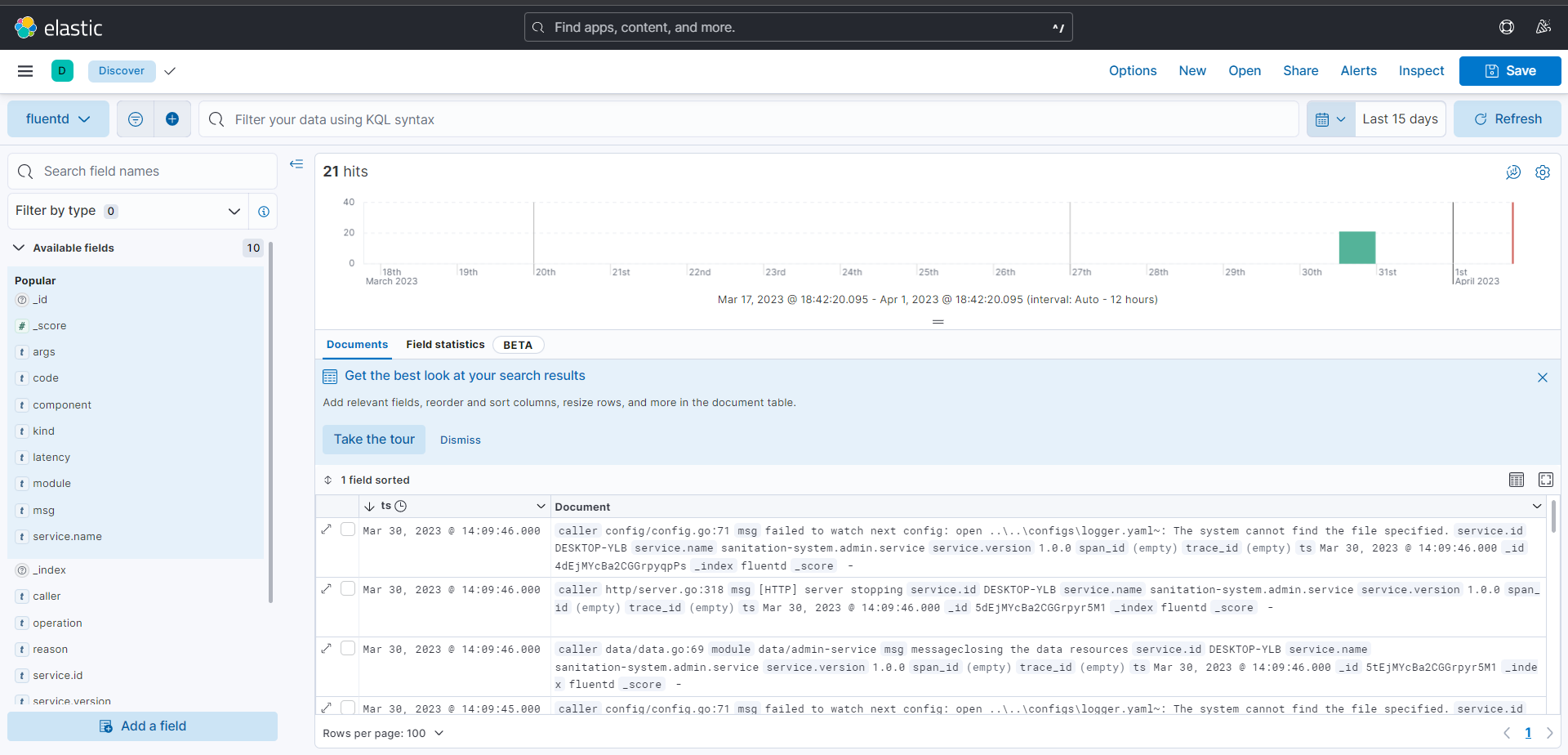
在视图里面,我们看到的还只是最原始的日志信息。我们可以在左边勾选msg或者其他需要关注的字段,Kibana就会过滤出我们关注的信息:
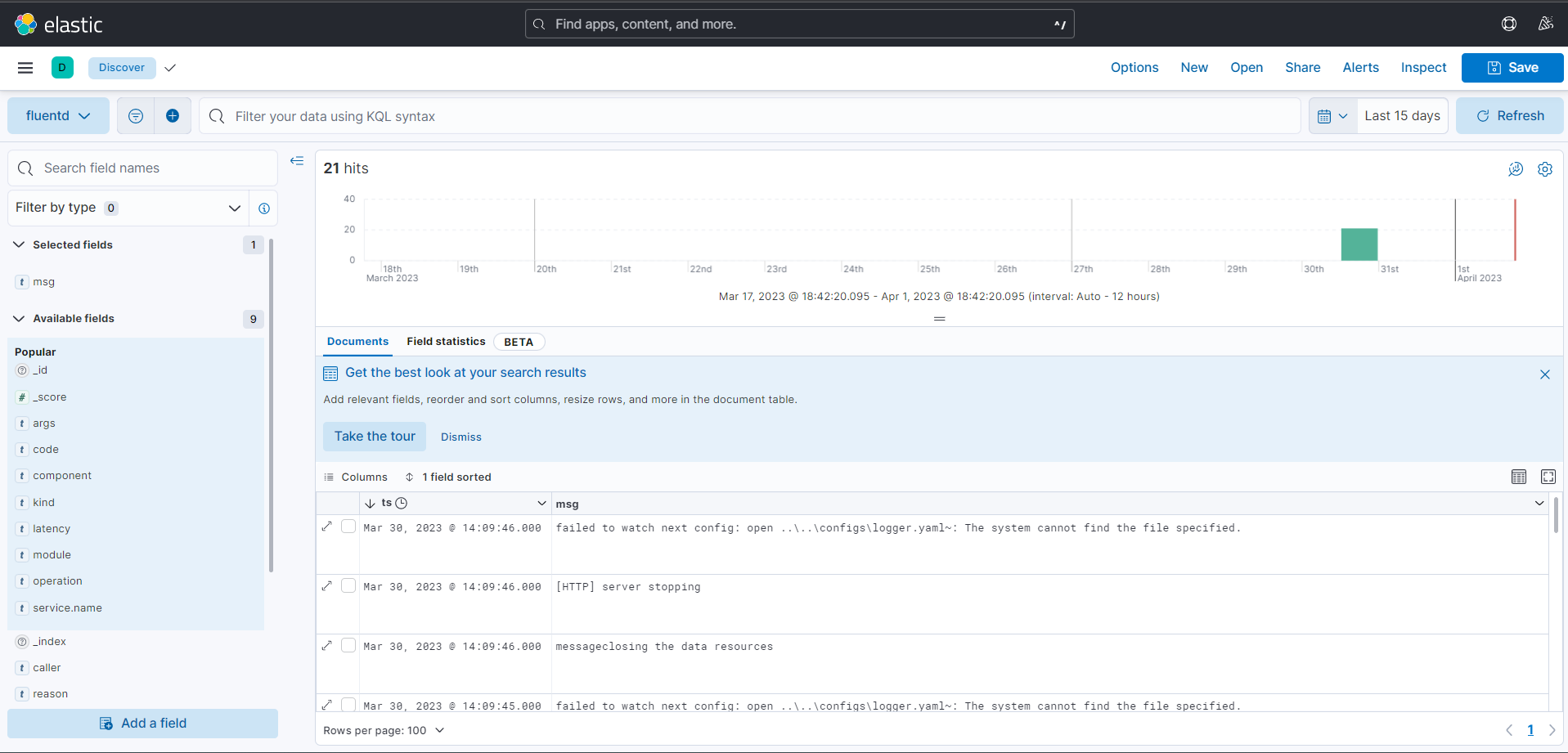
如果需要构建更加复杂的查询,那么可以在最上面的搜索栏里边构建查询语句。